Le lac de données tel que nous le voyons
En tant qu'équipe du centre de données d'iQiyi, notre tâche principale est de gérer et d'entretenir le grand nombre d'actifs de données au sein de l'entreprise. Dans le processus de mise en œuvre de la gouvernance des données, nous continuons à absorber de nouveaux concepts et à introduire des outils de pointe pour affiner la gestion de notre système de données.
Le « lac de données » est un concept qui a été largement discuté dans le domaine des données ces dernières années, et ses aspects techniques ont également retenu l'attention de l'industrie. Notre équipe a mené des recherches approfondies sur la théorie et la pratique des lacs de données. Nous pensons que les lacs de données constituent non seulement une nouvelle perspective sur la gestion des données, mais également une technologie prometteuse pour l'intégration et le traitement des données.
Le lac de données est une idée de gouvernance des données
L’objectif de la mise en œuvre d’un lac de données est de fournir une solution de stockage et de gestion efficace pour amener la facilité d’utilisation et la disponibilité des données à un nouveau niveau.
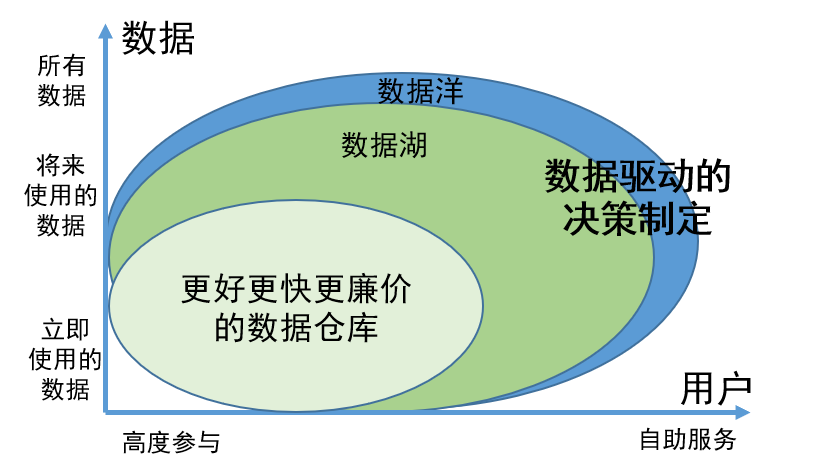
En tant que concept innovant de gouvernance des données, la valeur du lac de données se reflète principalement dans les deux aspects suivants :
1. La capacité de stocker de manière exhaustive toutes les données, que les données soient utilisées ou temporairement indisponibles, garantit que les informations requises peuvent être facilement trouvées en cas de besoin et améliore l'efficacité du travail ;
2. Les données du lac de données ont été gérées et organisées scientifiquement, ce qui permet aux utilisateurs de trouver et d'utiliser plus facilement les données par eux-mêmes. Ce modèle de gestion réduit considérablement l'implication des ingénieurs de données. Les utilisateurs peuvent effectuer eux-mêmes les tâches de recherche et d'utilisation des données, économisant ainsi beaucoup de ressources humaines.
Afin de gérer plus efficacement tous les types de données, le lac de données divise les données en quatre zones principales en fonction de différentes caractéristiques et besoins, à savoir la zone d'origine, la zone produit, la zone de travail et la zone sensible :
Zone brute
: Cette zone vise à répondre aux besoins des ingénieurs de données et des data scientists professionnels, et son objectif principal est de stocker des données brutes et non traitées. Si nécessaire, il peut également être partiellement ouvert pour répondre à des exigences d'accès spécifiques.
Domaine de produit
: La plupart des données de la zone de produit sont traitées et traitées par des ingénieurs de données, des scientifiques de données et des analystes commerciaux pour garantir la standardisation et un degré élevé de gestion des données. Ce type de données est généralement largement utilisé dans les rapports commerciaux, l’analyse des données, l’apprentissage automatique et d’autres domaines.
Zone de travail
: La zone de travail est principalement utilisée pour stocker les données intermédiaires générées par différents data Workers. Ici, les utilisateurs sont responsables de la gestion de leurs données pour prendre en charge une exploration et une expérimentation flexibles des données afin de répondre aux besoins des différents groupes d'utilisateurs.
Zone sensible
: La zone sensible se concentre sur la sécurité et est principalement utilisée pour stocker des données sensibles, telles que des informations personnellement identifiables, des données financières et des données de conformité légale. Cette zone est protégée par le plus haut niveau de contrôle d’accès et de sécurité.
Grâce à cette division, le lac de données peut mieux gérer différents types de données tout en offrant un accès et une utilisation pratiques des données pour répondre à divers besoins.
Application des idées de gouvernance des données Data Lake dans le centre de données
L'objectif du centre de données est de résoudre des problèmes tels que des calibres statistiques incohérents, un développement répété, une réponse lente aux besoins de développement d'indicateurs, une faible qualité des données et des coûts de données élevés causés par l'augmentation des données et l'expansion de l'entreprise.
Les objectifs du centre de données et du lac de données sont cohérents. En combinant le concept de lac de données, le système de données et l'architecture globale du centre de données ont été optimisés et mis à niveau.
Dans la phase initiale de la construction du centre de données, nous avons intégré le système d'entrepôt de données de l'entreprise, mené des recherches approfondies sur l'entreprise, trié les informations existantes sur les champs et les dimensions, résumé les dimensions de cohérence, établi un système d'indicateurs unifiés et formulé la construction d'un entrepôt de données. Caractéristiques. Selon cette spécification, nous avons construit la couche de données d'origine (ODS), la couche de données détaillées (DWD) et la couche de données agrégées (MID) de l'entrepôt de données unifié, et avons établi une bibliothèque de périphériques, comprenant une bibliothèque de périphériques accumulée et un nouveau périphérique. bibliothèque. Sur la base de l'entrepôt de données unifié, l'équipe de données a construit un entrepôt de données thématique et un marché commercial basé sur différentes analyses et orientations statistiques et besoins commerciaux. L'entrepôt de données et le marché commercial concernés comprennent des données détaillées traitées ultérieurement, des données agrégées et des tableaux de données de la couche application. La couche application des données utilise ces données pour fournir différents services aux utilisateurs.
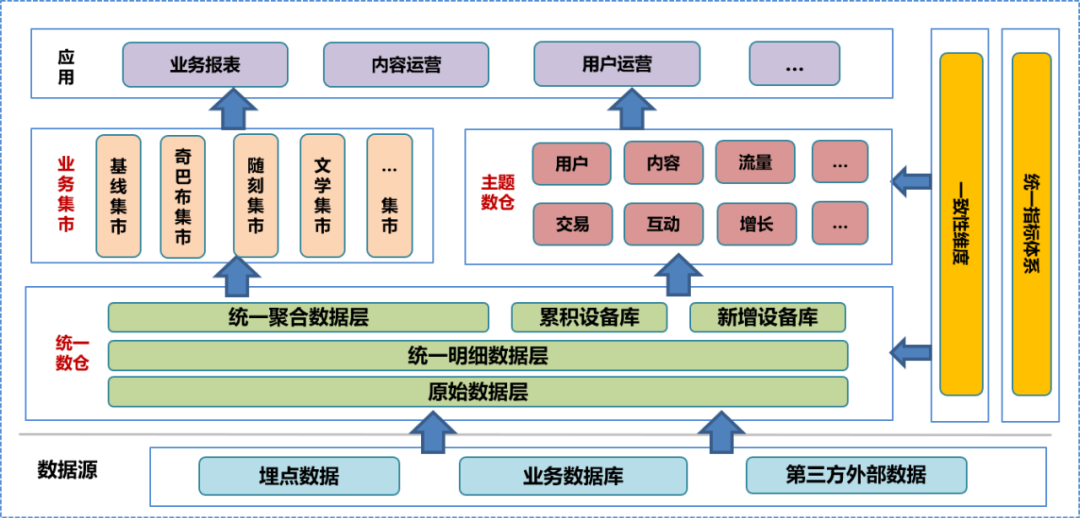
Dans un système d'entrepôt de données unifié, la couche de données d'origine et
les couches inférieures
ne sont pas ouvertes au public. Les utilisateurs ne peuvent faire appel qu'à des ingénieurs de données pour traiter les données traitées, il est donc inévitable que certains détails des données soient perdus.
Dans leur travail quotidien, les utilisateurs disposant de capacités d'analyse de données souhaitent souvent accéder aux données brutes sous-jacentes pour effectuer une analyse ou un dépannage personnalisé.
Le concept de gestion des données du lac de données peut résoudre efficacement ce problème. Après avoir introduit l'idée de gouvernance des données du lac de données, nous avons trié et intégré les ressources de données existantes, enrichi et étendu les métadonnées des données et construit un centre de métadonnées de données spécifiquement pour la gestion du centre de métadonnées.
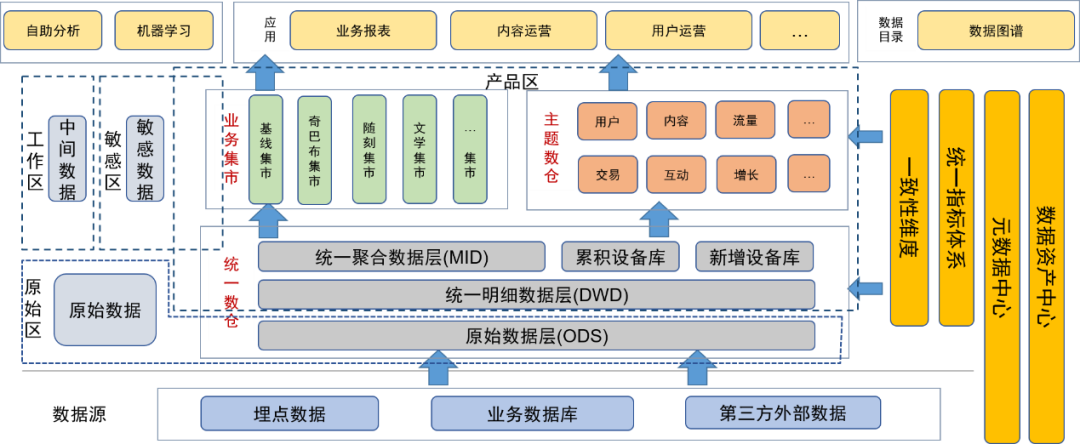
Après avoir introduit le concept de lac de données pour la gouvernance des données, nous avons placé la couche de données d'origine et d'autres données d'origine (telles que les fichiers journaux d'origine) dans la zone de données d'origine. Les utilisateurs disposant de capacités de traitement de données peuvent demander l'autorisation d'utiliser les données dans cette zone.
La couche détaillée, la couche d'agrégation, l'entrepôt de données thématique et le magasin d'affaires de l'entrepôt de données unifié sont placés dans la zone de produit. Ces données ont été traitées par les ingénieurs de données de l'équipe de données et fournies aux utilisateurs en tant que produits de données finaux. dans ce domaine a été traité par la gestion des données, la qualité des données est donc garantie.
Nous avons également défini des zones sensibles pour les données sensibles et nous sommes concentrés sur le contrôle des droits d'accès.
Les tables temporaires ou tables personnelles générées quotidiennement par les utilisateurs et les développeurs de données sont placées dans la zone temporaire. Ces tables de données sont sous la responsabilité des utilisateurs eux-mêmes et peuvent être ouvertes à d'autres utilisateurs sous condition.
Les métadonnées de chaque donnée sont conservées via le centre de métadonnées, y compris les informations de table, les informations de champ, ainsi que les dimensions et indicateurs correspondant aux champs. Dans le même temps, nous maintenons également le lignage des données, y compris les relations de lignage au niveau des tables et des champs.
Maintenez les caractéristiques des actifs de données via le centre d’actifs de données, y compris la gestion du niveau de données, de la sensibilité et des autorisations.
Afin de permettre aux utilisateurs de mieux utiliser les données par eux-mêmes, nous fournissons une carte de données en tant que répertoire de données au niveau de la couche application permettant aux utilisateurs d'interroger les données, y compris les métadonnées telles que l'utilisation des données, les dimensions, les indicateurs et le lignage. Dans le même temps, la plateforme peut également être utilisée comme portail pour les demandes d’autorisation.
En outre, nous proposons également une plateforme d'analyse en libre-service pour offrir aux utilisateurs de données des capacités d'analyse en libre-service.
Tout en optimisant le système de données, nous avons également mis à niveau l’architecture de la plateforme data middle basée sur le concept de lac de données.
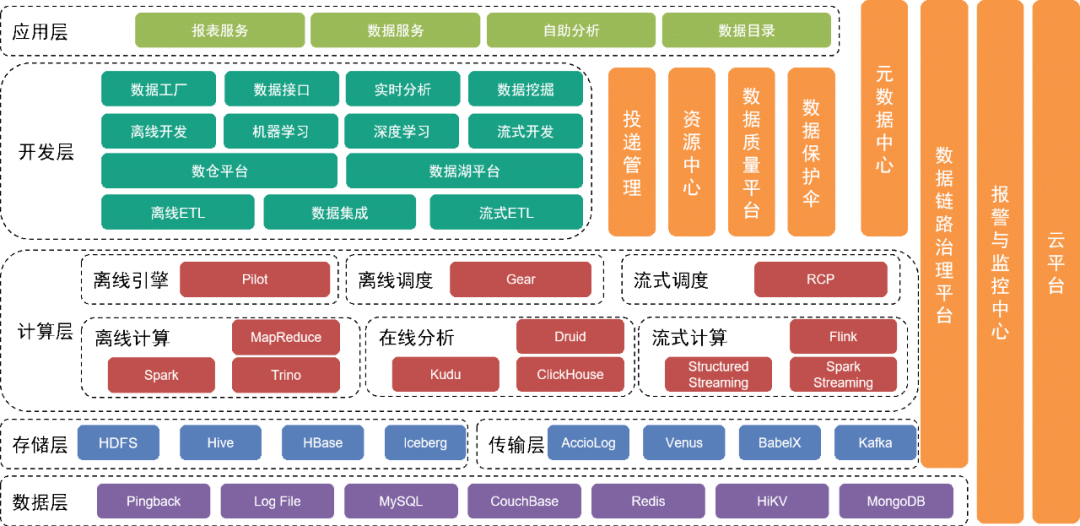
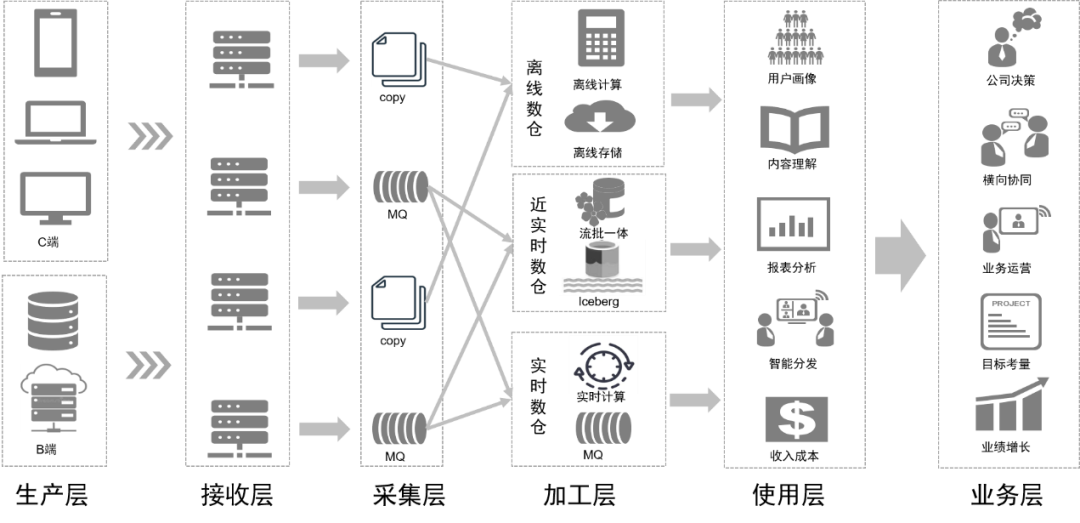
La couche inférieure est la couche de données , qui comprend diverses sources de données, telles que les données Pingback, qui sont principalement utilisées pour collecter le comportement des utilisateurs. Les données commerciales sont stockées dans diverses bases de données relationnelles et bases de données NoSQL.
Ces données sont stockées dans la couche de stockage via différents outils de collecte dans la couche transport.
Au-dessus de la couche de données se trouve la couche de stockage
, qui repose principalement sur HDFS, un système de fichiers distribué, pour stocker les fichiers originaux. D'autres données structurées ou non structurées sont stockées dans Hive, Iceberg ou HBase.
Plus haut se trouve la couche informatique
, qui utilise principalement le moteur hors ligne Pilot pour piloter Spark ou Trino pour les calculs hors ligne, et utilise le moteur de planification hors ligne Gear pour la planification planifiée des flux de travail. La plate-forme informatique en temps réel RCP est responsable de la planification du flux informatique. Après plusieurs séries d’itérations, le flow computing utilise actuellement principalement Flink comme moteur de calcul.
La couche de développement située au-dessus de la couche informatique
encapsule en outre chaque module de service de la couche informatique et de la couche de transmission pour fournir des fonctions permettant de développer des flux de travail de traitement de données hors ligne, d'intégrer des données, de développer des flux de travail de traitement en temps réel et de développer des implémentations d'outils d'ingénierie d'apprentissage automatique et des suites d'outils intermédiaires. services pour mener à bien les travaux de développement. La plateforme du lac de données gère les informations de chaque fichier de données et table de données du lac de données, tandis que la plateforme de l'entrepôt de données gère le modèle de données de l'entrepôt de données, le modèle physique, les dimensions, les indicateurs et d'autres informations.
Dans le même temps, nous fournissons une variété d'outils et de services de gestion verticalement. Par exemple, l'outil de gestion des livraisons gère les méta-informations telles que les spécifications enfouies Pingback, les champs, les dictionnaires et les délais de livraison ; sont utilisés pour conserver des tables de données ou des fichiers de données et garantir la sécurité des données ; le centre de qualité des données et la plate-forme de gestion des liens surveillent la qualité des données et l'état de production des liaisons de données, informent rapidement les équipes concernées des mesures de protection et répondent rapidement aux problèmes et aux pannes en ligne. sur la base des plans existants.
Les services sous-jacents sont fournis par l'équipe de service cloud pour fournir une prise en charge du cloud privé et du cloud public.
La couche supérieure de l'architecture fournit une carte de données en tant que répertoire de données permettant aux utilisateurs de trouver les données dont ils ont besoin. De plus, nous proposons des applications en libre-service telles que Magic Mirror et Beidou pour répondre aux besoins des utilisateurs à différents niveaux en matière de travail de données en libre-service.
Après la transformation de l'ensemble du système d'architecture, l'intégration et la gestion des données sont plus flexibles et complètes. Nous réduisons le seuil des utilisateurs en optimisant les outils en libre-service, répondons aux besoins des utilisateurs à différents niveaux, améliorons l'efficacité de l'utilisation des données et améliorons la valeur des données.
Application de la technologie des lacs de données dans les centres de données
Au sens large, le lac de données est un concept de gouvernance des données. Au sens étroit, le lac de données fait également référence à une technologie de traitement de données.
La technologie des lacs de données couvre le format de stockage des tableaux de données et la technologie de traitement des données après leur entrée dans le lac.
Il existe trois principales solutions de stockage dans les lacs de données du secteur : Delta Lake, Hudi et Iceberg. Une comparaison des trois est la suivante :
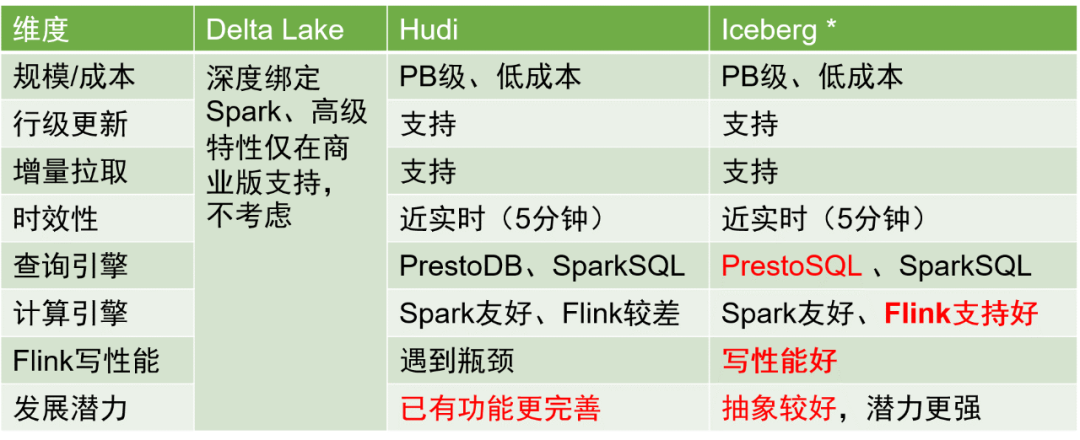
Après un examen approfondi, nous avons choisi Iceberg comme format de stockage du tableau de données.
Iceberg est un format de stockage de tables qui organise les fichiers de données dans le système de fichiers ou le magasin d'objets sous-jacent.
Voici les principales comparaisons entre Iceberg et Hive :
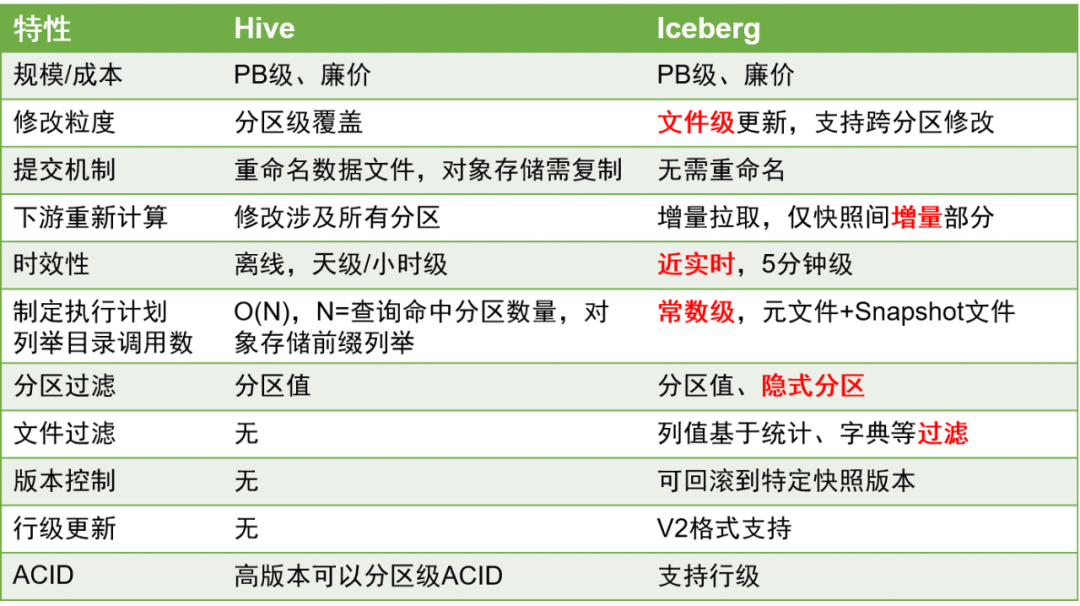
Par rapport aux tables Hive, les tables Iceberg présentent des avantages significatifs car elles peuvent mieux prendre en charge les mises à jour au niveau des lignes et la rapidité des données peut être améliorée à la minute près.
Ceci est d'une grande importance dans le traitement des données, car l'amélioration de l'actualité des données peut grandement améliorer l'efficacité du traitement des données ETL.
Par conséquent, nous pouvons facilement transformer l’architecture Lambda existante pour obtenir une architecture intégrée de streaming-batch :
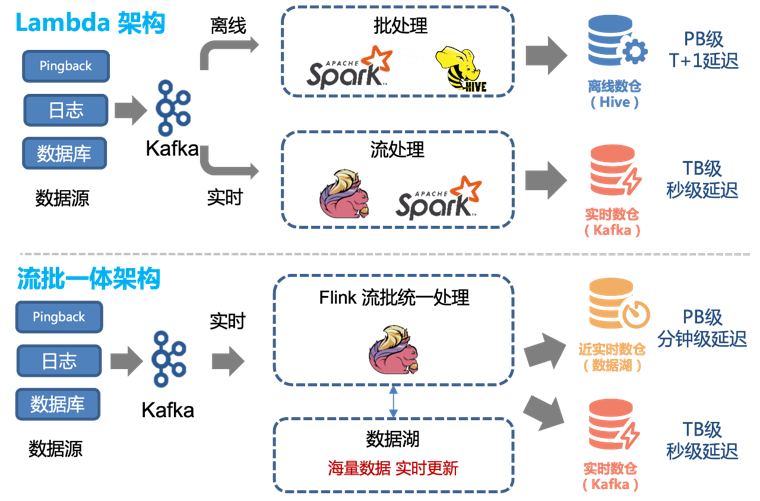
Avant l'introduction de la technologie des lacs de données, nous utilisions une combinaison de traitement hors ligne et de traitement en temps réel pour fournir un entrepôt de données hors ligne et un entrepôt de données en temps réel.
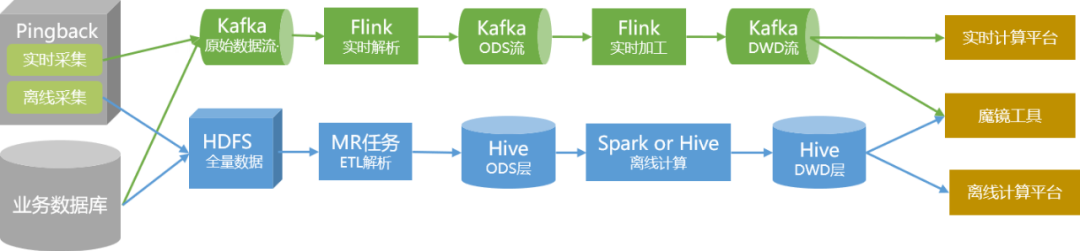
La quantité totale de données est intégrée dans les données de l'entrepôt de données via des méthodes traditionnelles d'analyse et de traitement hors ligne,
et est stockée dans le cluster sous la forme de tables Hive.
Pour les données nécessitant des exigences élevées en temps réel, nous les produisons séparément via des liens en temps réel et les fournissons aux utilisateurs sous forme de sujets dans Kafka.
Cependant, cette architecture présente les problèmes suivants :
-
Les deux canaux, en temps réel et hors ligne, doivent maintenir deux ensembles différents de logique de code. Lorsque la logique de traitement change, les canaux en temps réel et hors ligne doivent être mis à jour en même temps, sinon une incohérence des données se produira.
-
Les mises à jour horaires des liens hors ligne et un délai d'environ 1 heure signifient que les données à 00h01 ne peuvent être interrogées qu'à 02h00. Pour certains services en aval ayant des exigences élevées en temps réel, cela est inacceptable et les liaisons en temps réel doivent donc être prises en charge.
-
Bien que les performances en temps réel de la liaison en temps réel puissent atteindre le deuxième niveau, son coût est élevé. Pour la plupart des utilisateurs, une mise à jour de cinq minutes suffit. Dans le même temps, consommer des flux Kafka n’est pas aussi pratique que d’exploiter directement des tables de données.
Ces problèmes peuvent être mieux résolus en utilisant la méthode intégrée de traitement des données des tables Iceberg et des lots de streaming.

Au cours du processus d'optimisation, nous avons principalement effectué la transformation Iceberg sur les tables de couche ODS et de couche DWD, et reconstruit l'analyse et le traitement des données en tâches Flink.
Afin de garantir que la stabilité et l'exactitude de la production des données ne soient pas affectées pendant le processus de transformation, nous avons pris les mesures suivantes :
1. Commencez à basculer avec des données non essentielles. En fonction des conditions commerciales réelles, nous utilisons la livraison QOS et la livraison personnalisée comme projets pilotes.
2. En faisant abstraction de la logique d'analyse hors ligne, un SDK de stockage d'analyse Pingback unifié est formé, qui réalise un déploiement unifié en temps réel et hors ligne et rend le code plus standardisé.
3. Après le déploiement de la table Iceberg et du nouveau processus de production, nous avons mené des opérations parallèles à double liaison pendant deux mois et effectué une surveillance comparative régulière des données.
4. Après avoir confirmé qu'il n'y a aucun problème de données et de production, nous effectuons un passage imperceptible à la couche supérieure.
5. Pour les données de démarrage et de lecture liées aux données de base, nous effectuerons la transformation intégrée en streaming et par lots une fois que la vérification globale sera stable.
Après la transformation, les bénéfices sont les suivants :
1. Les qos et les liaisons de données de livraison personnalisées ont été mises en œuvre en temps quasi réel dans leur ensemble. Les données avec un retard horaire peuvent être mises à jour au niveau de cinq minutes.
2. Sauf circonstances particulières, le lien de streaming et de traitement par lots intégré peut répondre aux besoins en temps réel. Par conséquent, nous pouvons mettre hors ligne les liens en temps réel existants et les liens d'analyse hors ligne liés à la qualité de service et à la personnalisation, économisant ainsi des ressources.
Grâce à la transformation du traitement des données, notre liaison de données sera à l'avenir comme le montre la figure ci-dessous :
Planification du suivi
Pour la planification ultérieure de l'application du lac de données dans le centre de données, il y a deux aspects principaux :
Du niveau architectural, nous continuerons à affiner le développement de chaque module pour rendre les données et services fournis par le centre de données plus complets et plus faciles à utiliser, afin que différents utilisateurs puissent les utiliser facilement ;
Au niveau technique, nous continuerons à transformer la liaison de données en une intégration flux-batch, tout en continuant à introduire activement des technologies de données appropriées pour améliorer l'efficacité de la production et de l'utilisation des données et réduire les coûts de production.
6. Alex Gorélik. Le lac Big Data d’entreprise.
Peut-être que tu veux aussi voir
Cet article est partagé à partir du compte public WeChat - Équipe produit technologique iQIYI (iQIYI-TP).
En cas d'infraction, veuillez contacter [email protected] pour suppression.
Cet article participe au « Plan de création de sources OSC ». Vous qui lisez, êtes invités à vous joindre et à partager ensemble.
