
01
dosscèneet le statu quo
1. Caractéristiques des données dans le domaine publicitaire
Les données dans le domaine de la publicité peuvent être divisées en : caractéristiques de valeur continue Différentes des domaines de l'image, de la vidéo, de la voix et d'autres domaines de l'IA , les données originales dans le domaine sont principalement présentées sous forme d'identifiant, tel que l'identifiant utilisateur, l'identifiant publicitaire, la séquence d'identifiant publicitaire interagissant avec l'utilisateur, etc., et l'identifiant. l'échelle est grande, formant le champ publicitaire Les caractéristiques distinctives des données clairsemées de haute dimension.
-
Il existe des caractéristiques à la fois statiques (comme l'âge de l'utilisateur) et dynamiques basées sur le comportement de l'utilisateur (comme le nombre de fois qu'un utilisateur clique sur une publicité dans un certain secteur). -
L’avantage est qu’il possède une bonne capacité de généralisation. La préférence d'un utilisateur pour une industrie peut être généralisée à d'autres utilisateurs présentant les mêmes caractéristiques statistiques de l'industrie. -
L’inconvénient est que le manque de capacité de mémoire entraîne une faible discrimination. Par exemple, deux utilisateurs ayant les mêmes caractéristiques statistiques peuvent avoir des différences de comportement significatives. De plus, les fonctionnalités à valeur continue nécessitent également beaucoup d’ingénierie manuelle des fonctionnalités.
-
Les fonctionnalités à valeur discrète sont des fonctionnalités à granularité fine. Il en existe d'énumérables (tels que le sexe de l'utilisateur, l'identifiant de l'industrie), et il existe également des éléments de grande dimension (tels que l'identifiant de l'utilisateur, l'identifiant publicitaire). -
L’avantage est qu’il possède une forte mémoire et une haute distinction. Des fonctionnalités de valeur discrète peuvent également être combinées pour apprendre des informations croisées et collaboratives. -
L’inconvénient est que la capacité de généralisation est relativement faible.
-
Encodage à chaud -
Intégration de fonctionnalités (Intégration)
-
Conflit de fonctionnalités : si le paramètre vocabulaire_size est trop grand, l'efficacité de la formation diminuera fortement et la formation échouera en raison du MOO de la mémoire. Par conséquent, même pour les fonctionnalités à valeur discrète d'ID utilisateur de plusieurs milliards, nous ne configurerons qu'un espace de hachage d'ID de 100 000 niveaux. Le taux de conflit de hachage est élevé, les informations sur les fonctionnalités sont endommagées et il n'y a aucun avantage positif à tirer d'une évaluation hors ligne. -
E/S inefficaces : étant donné que les fonctionnalités telles que l'ID utilisateur et l'ID publicitaire sont de grande dimension et clairsemées, c'est-à-dire que les paramètres mis à jour pendant la formation ne représentent qu'une petite partie du total. Dans le cadre du mécanisme d'intégration statique d'origine de TensorFlow, l'accès au modèle doit être traité. L'ensemble du Tensor dense entraînera une énorme surcharge d'E/S et ne pourra pas prendre en charge la formation de grands modèles clairsemés.
02
Pratique de grand modèle clairsemée
-
L'API TFRA est compatible avec l'écosystème Tensorflow (en réutilisant l'optimiseur et l'initialiseur d'origine, l'API a le même nom et un comportement cohérent), permettant à TensorFlow de prendre en charge la formation et l'inférence de grands modèles clairsemés de type ID de manière plus native ; le coût d'apprentissage et d'utilisation est faible et ne modifie pas les habitudes de modélisation des ingénieurs en algorithmes. -
L'expansion et la contraction dynamiques de la mémoire permettent d'économiser des ressources pendant l'entraînement ; elles évitent efficacement les conflits de hachage et garantissent que les informations sur les fonctionnalités sont sans perte.
-
L'intégration statique est mise à niveau vers l'intégration dynamique : pour la logique de hachage artificielle des fonctionnalités à valeur discrète, l'intégration dynamique TFRA est utilisée pour stocker, accéder et mettre à jour les paramètres, garantissant ainsi que l'intégration de toutes les fonctionnalités à valeur discrète est sans conflit dans le cadre de l'algorithme et garantissant que toutes les valeurs discrètes Apprentissage sans perte des fonctionnalités. -
Utilisation de fonctionnalités d'identification clairsemées de grande dimension : comme mentionné ci-dessus, lors de l'utilisation de la fonction d'intégration statique de TensorFlow, les fonctionnalités d'identification utilisateur et d'identification publicitaire ne profitent pas de l'évaluation hors ligne en raison de conflits de hachage. Une fois le cadre algorithmique mis à niveau, les fonctionnalités d'identification utilisateur et d'identification publicitaire sont réintroduites, et il existe des avantages positifs à la fois hors ligne et en ligne. -
L'utilisation de fonctionnalités d'identification combinées clairsemées de haute dimension : présentation des fonctionnalités combinées de valeur discrète de l'ID utilisateur et de l'ID publicitaire à gros grain, telles que la combinaison de l'ID utilisateur avec l'ID de l'industrie et le nom du package d'application, respectivement. Dans le même temps, combinées à la fonction d'accès aux fonctionnalités, des fonctionnalités discrètes utilisant une combinaison d'identifiants utilisateur et d'identifiants publicitaires plus clairsemés sont introduites.

2. Mise à jour du modèle
-
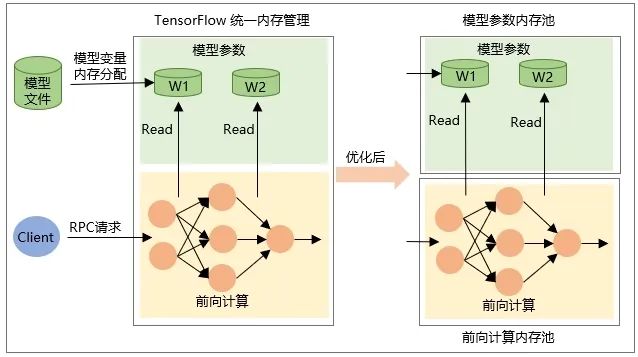
L'allocation de la variable elle-même Tensor lorsque le modèle est restauré, c'est-à-dire que la mémoire est allouée lorsque le modèle est chargé et la mémoire est libérée lorsque le modèle est déchargé. -
La mémoire du Tensor de sortie intermédiaire est allouée lors du calcul du transfert de réseau lors de la requête RPC et est libérée une fois le traitement de la requête terminé.
03
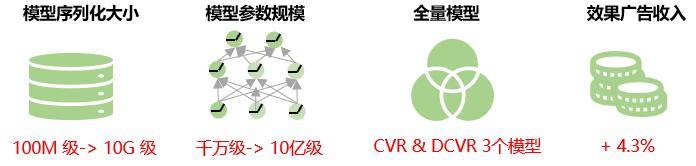
bénéfice global
04
perspectives d'avenir
Actuellement, toutes les valeurs de fonctionnalité de la même fonctionnalité dans le modèle clairsemé de grande publicité reçoivent la même dimension d'intégration. Dans les affaires réelles, la distribution des données des caractéristiques de grande dimension est extrêmement inégale, un très petit nombre de caractéristiques à haute fréquence représentent une proportion très élevée et le phénomène de longue traîne est grave en utilisant des dimensions d'intégration fixes pour toutes les valeurs de caractéristiques ; réduira la capacité d’apprentissage de la représentation intégrée. Autrement dit, pour les fonctionnalités à basse fréquence, la dimension d'intégration est trop grande et le modèle risque d'être sur-ajusté ; pour les fonctionnalités à haute fréquence, car il existe une multitude d'informations qui doivent être représentées et apprises, l'intégration ; La dimension est trop petite et le modèle risque d'être sous-ajusté. Par conséquent, à l’avenir, nous explorerons des moyens d’apprendre de manière adaptative la dimension d’intégration de la fonctionnalité pour améliorer encore la précision de la prédiction du modèle.
Dans le même temps, nous explorerons la solution d'exportation incrémentielle du modèle, c'est-à-dire charger uniquement les paramètres qui changent lors de la formation incrémentielle vers TensorFlow Serving, réduisant ainsi la transmission réseau et le temps de chargement lors de la mise à jour du modèle, obtenant ainsi des mises à jour à la minute près. de grands modèles clairsemés et l'amélioration de la nature en temps réel du modèle.

Processus d'optimisation des doubles enchères de publicité de performance iQIYI
Cet article est partagé à partir du compte public WeChat - Équipe produit technologique iQIYI (iQIYI-TP).
En cas d'infraction, veuillez contacter [email protected] pour suppression.
Cet article participe au « Plan de création de sources OSC ». Vous qui lisez, êtes invités à vous joindre et à partager ensemble.
{{o.name}}
{{m.nom}}