
Auteur : équipe technique SelectDB
De nos jours, les besoins des entreprises en matière de requêtes de données ne cessent d'augmenter. Lorsqu'elles partagent le même cluster, elles doivent souvent faire face à des requêtes simultanées provenant de plusieurs secteurs d'activité ou à plusieurs charges d'analyse en même temps. Dans des conditions de ressources limitées, la préemption des ressources entre les tâches de requête entraînera une dégradation des performances et même une instabilité du cluster. Par conséquent, l'importance de la gestion de la charge est évidente.
À partir de scénarios métier, les exigences en matière de gestion de la charge utilisateur proviennent principalement des aspects suivants :
- Lorsque plusieurs départements métiers ou locataires peuvent partager le même cluster, afin d'éviter les interactions de charge entre différents locataires, il est nécessaire de garantir l'indépendance d'utilisation des ressources et la stabilité des performances de chaque locataire.
- Différentes entreprises ont des exigences différentes en matière de réactivité et de priorité des tâches de requête. Pour les entreprises clés ou les tâches hautement prioritaires, telles que l'analyse des données en temps réel, les transactions en ligne, etc., il est nécessaire de s'assurer que ces tâches peuvent obtenir des ressources et des ressources suffisantes. être exécuté en priorité pour éviter la concurrence des ressources. Avoir un impact sur les performances des requêtes.
- Les utilisateurs se soucient non seulement de l'allocation et de la gestion des ressources, mais également du contrôle des coûts et de l'utilisation des ressources. La solution de gestion de charge doit répondre aux exigences d'isolation tout en répondant aux demandes de l'utilisateur en matière de faible coût d'utilisation et d'utilisation élevée des ressources.
Dans les premières versions, Apache Doris a lancé une solution d'isolation basée sur des balises de ressources, y compris la division des groupes de ressources au niveau des nœuds au sein du cluster et les limites de ressources pour les requêtes individuelles, permettant ainsi une isolation physique des ressources entre différents utilisateurs. Afin de fournir aux utilisateurs une solution de gestion de charge plus complète, Apache Doris a lancé une solution de gestion basée sur Workload Group depuis la version 2.0, qui prend en compte la limite souple des ressources CPU et offre aux utilisateurs une utilisation plus élevée des ressources. La version 2.1 récemment publiée est basée sur la technologie CGroup fournie par le noyau Linux, qui implémente en outre des limites strictes sur les ressources CPU et offre aux utilisateurs une meilleure stabilité des requêtes.
Solution d'isolation physique basée sur Resource Tag
Il existe deux types de nœuds dans Apache Doris, FE et BE. Le nœud FE est responsable du stockage des métadonnées, de la gestion du cluster, de l'accès aux demandes des utilisateurs, de l'analyse du plan de requête, etc., tandis que le nœud BE est responsable du stockage et du calcul des données. La principale consommation de ressources impliquée dans le processus d'exécution des requêtes est le nœud BE, la solution d'isolation de charge Apache Doris est donc conçue pour le nœud BE.
Dans la solution d'isolation physique des ressources Resource Tag, vous pouvez définir des balises sur les nœuds BE dans le même cluster. Les nœuds BE avec les mêmes balises formeront un groupe de ressources (groupe de ressources), et le groupe de ressources peut être considéré comme une unité de stockage de données. et l'informatique. Lorsque les données sont saisies dans la base de données, des copies des données seront écrites dans différents groupes de ressources en fonction de la configuration du groupe de ressources. Lors de l'interrogation, les ressources informatiques du groupe de ressources correspondant seront utilisées pour le calcul en fonction de la division des groupes de ressources.
Documentation de référence : https://doris.apache.org/zh-CN/docs/2.0/admin-manual/resource-admin/multi-tenant
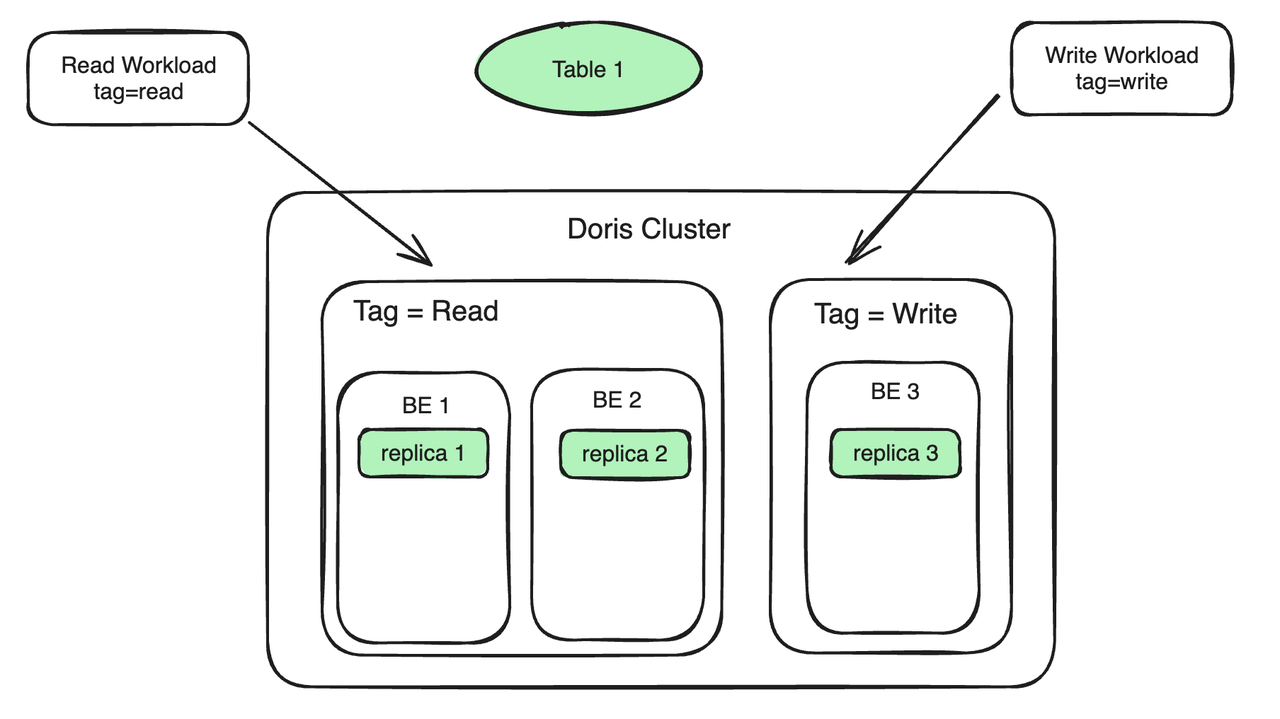
Prenons comme exemple un scénario d'analyse en lecture-écriture courant. Supposons qu'il y ait 3 BE dans le cluster. Les étapes d'utilisation spécifiques sont les suivantes :
- Balise de ressource de liaison de nœud BE : liez deux BE à Tag Read pour servir la charge de lecture ; liez un BE à Tag Write pour servir la charge d'écriture. Les charges de travail de lecture et d'écriture sont situées sur des machines différentes pour obtenir une isolation en lecture et en écriture.
- Les copies de données sont liées à la balise de ressource : le tableau 1 comporte trois copies, deux copies sont liées à la lecture de balise et une copie est liée à l'écriture de balise. Les données écrites sur la réplique 3 seront automatiquement synchronisées sur la réplique 1 et la réplique 2. Le processus de synchronisation n'occupera pas trop de ressources informatiques du BE 1 et du BE 2.
- La charge de travail est liée au Tag Ressource : Si le Tag porté par la requête SQL est Lu, la requête sera automatiquement acheminée vers la machine (BE 1, BE 2) avec le Tag en Lecture pour exécution si le Stream Load est importé ; dans la charge et que la balise spécifiée est Write , alors le Stream Load sera acheminé vers la machine dont la balise est Write (BE 3). Dans ce processus, outre la surcharge générée lors de la synchronisation des réplicas, il n'y a plus de concurrence pour les ressources entre la requête et l'importation.
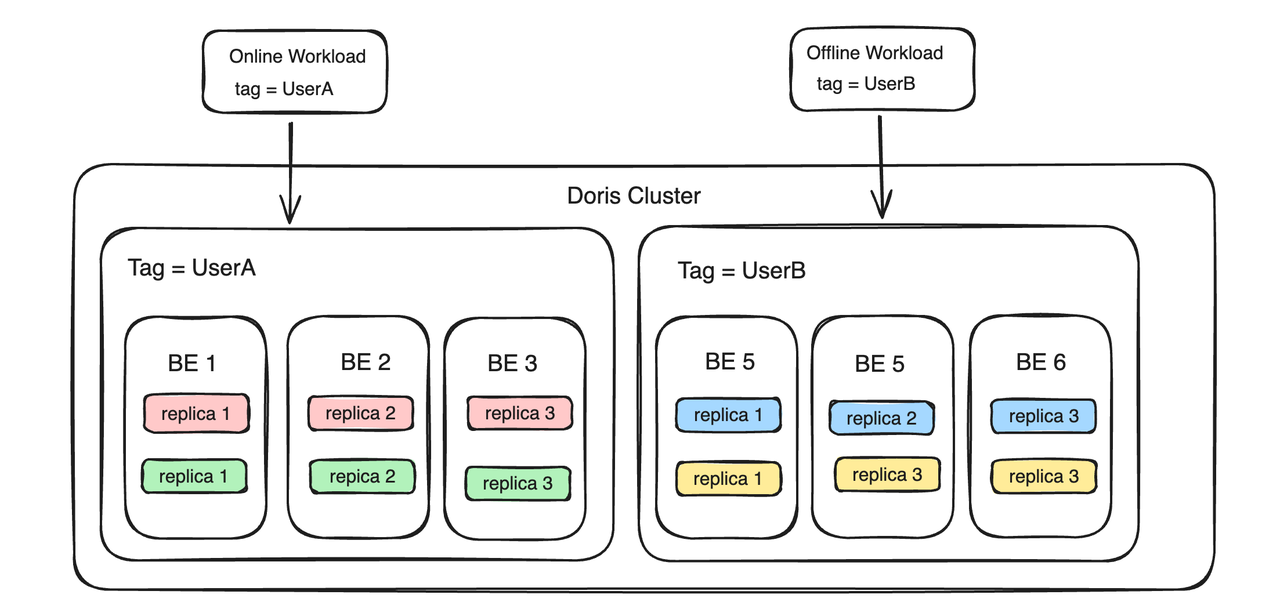
Resource Tag peut également implémenter des fonctions multi-tenant. Par exemple, deux utilisateurs, UserA et UserB, souhaitent créer des locataires indépendants pour éviter toute influence mutuelle. Vous pouvez ensuite lier les ressources informatiques et de stockage de UserA à une balise nommée UserA, et lier les ressources informatiques et de stockage de UserB à une balise nommée UserA. . est la balise de l'utilisateur B, les deux utilisateurs parviennent alors à isoler les ressources entre les locataires du côté BE.
L'essence de Resource Tag est de réaliser l'isolation des ressources en regroupant les nœuds BE. Les avantages de cette solution sont les suivants :
- Bonne isolation, plusieurs locataires sont isolés via des machines physiques et une isolation complète du processeur, de la mémoire et des E/S est obtenue ;
- Isolation des pannes, lorsqu'un problème survient chez un locataire (comme un crash de processus), l'autre locataire n'est pas du tout affecté ;
Sur la base de cette technologie, certains utilisateurs placent différents groupes de ressources dans différentes salles informatiques physiques pour obtenir un fonctionnement actif-actif de deux salles informatiques dans la même ville.
Mais il existe également certaines limites :
- Dans le scénario d'isolation en lecture-écriture, lorsque la charge d'écriture s'arrête, la machine avec Tag Write sera dans un état inactif, réduisant ainsi l'utilisation des ressources de l'ensemble du cluster, ce qui ne peut évidemment pas répondre aux attentes de l'utilisateur en matière d'utilisation complète des ressources.
- Dans un scénario multi-locataire, les charges de plusieurs parties commerciales au sein du même locataire s’influenceront également mutuellement. Même si l'isolation peut être obtenue en configurant des machines physiques distinctes pour chaque partie commerciale, cela entraînera des problèmes tels qu'un coût élevé et une faible utilisation des ressources.
- La flexibilité est médiocre. Le nombre de locataires est en fait lié au nombre de réplicas. Si vous souhaitez établir 5 locataires, vous avez besoin d'au moins 5 réplicas, ce qui entraîne dans une certaine mesure un gaspillage d'espace de stockage.
Solution de gestion de charge basée sur Workload Group
Afin de résoudre les problèmes ci-dessus, Apache Doris a lancé une solution de gestion basée sur Workload Group, qui prend en charge un mécanisme d'isolation des ressources plus fin - une isolation des ressources intra-processus, ce qui signifie que plusieurs salles de requêtes dans le même BE peuvent également obtenir un Dans une certaine mesure, l'isolement évite effectivement la concurrence entre les ressources au sein du processus et améliore l'utilisation des ressources.
Workload Group gère les charges de travail en groupes pour obtenir une gestion et un contrôle raffinés de la mémoire et des ressources CPU. Limitez le pourcentage de ressources CPU et mémoire d'une seule requête sur un seul nœud BE en associant la requête exécutée par l'utilisateur au groupe de charge de travail. Dans le même temps, vous pouvez configurer et activer les limites de ressources mémoire lorsque les ressources du cluster sont limitées, les requêtes ayant une utilisation élevée de la mémoire dans le groupe seront automatiquement terminées pour soulager la pression. Lorsque les ressources sont inactives, plusieurs groupes de charge de travail partagent des ressources inactives et dépassent automatiquement les limites pour garantir une exécution stable des requêtes.
Les limites des ressources du processeur peuvent être subdivisées en limites souples et limites strictes. Les limites logicielles du processeur ont les caractéristiques d'une utilisation plus élevée des ressources et permettent une allocation flexible des ressources lorsque les ressources sont inactives, tandis que les limites strictes du processeur se concentrent davantage sur la stabilité des performances et la garantie que les groupes le feront. n'interfèrent pas les uns avec les autres en raison des changements de charge.
( Les deux méthodes d'isolation de la limite stricte et de la limite logicielle du processeur peuvent correspondre à différents scénarios d'utilisation, mais ne peuvent pas être appliquées en même temps. Les utilisateurs peuvent choisir de manière flexible en fonction de leurs propres besoins)
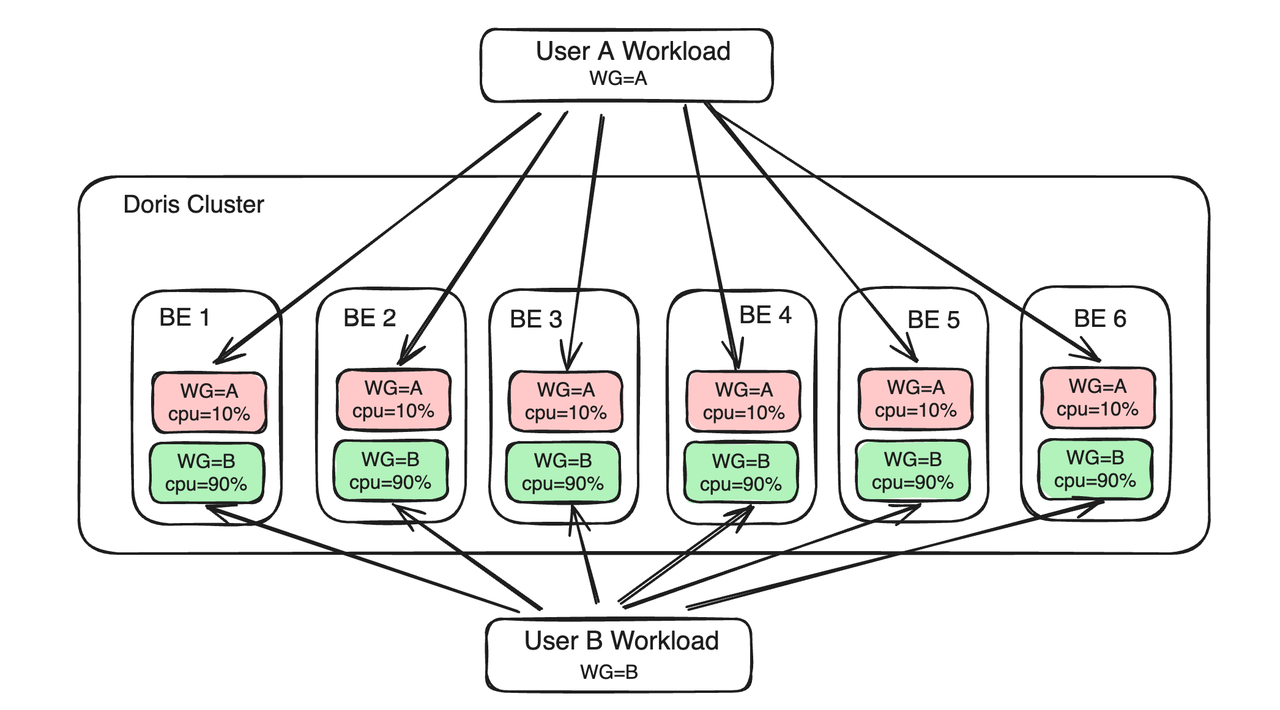
Les principales différences entre les solutions Workload Group et Resource Tag sont les suivantes :
- Du point de vue des ressources informatiques, Workload Group divise davantage les ressources CPU et mémoire au sein du processus BE. Plusieurs groupes de charge de travail doivent rivaliser pour les ressources sur le même BE. L'étiquette de ressource regroupe les nœuds BE et les charges des différentes parties commerciales sont envoyées aux BE dans différents groupes pour obtenir une isolation des ressources. Il n'y aura pas de compétition directe de ressources entre les charges commerciales dans différents groupes BE.
- Du point de vue des ressources de stockage, Workload Group n'a pas besoin de prêter attention aux ressources de stockage, mais se concentre uniquement sur l'allocation des ressources informatiques au sein d'un seul BE. Resource Tag nécessite le regroupement de copies de données pour garantir que les données métier qui doivent être isolées sont distribuées sur différents BE.
01 Limite logicielle du processeur
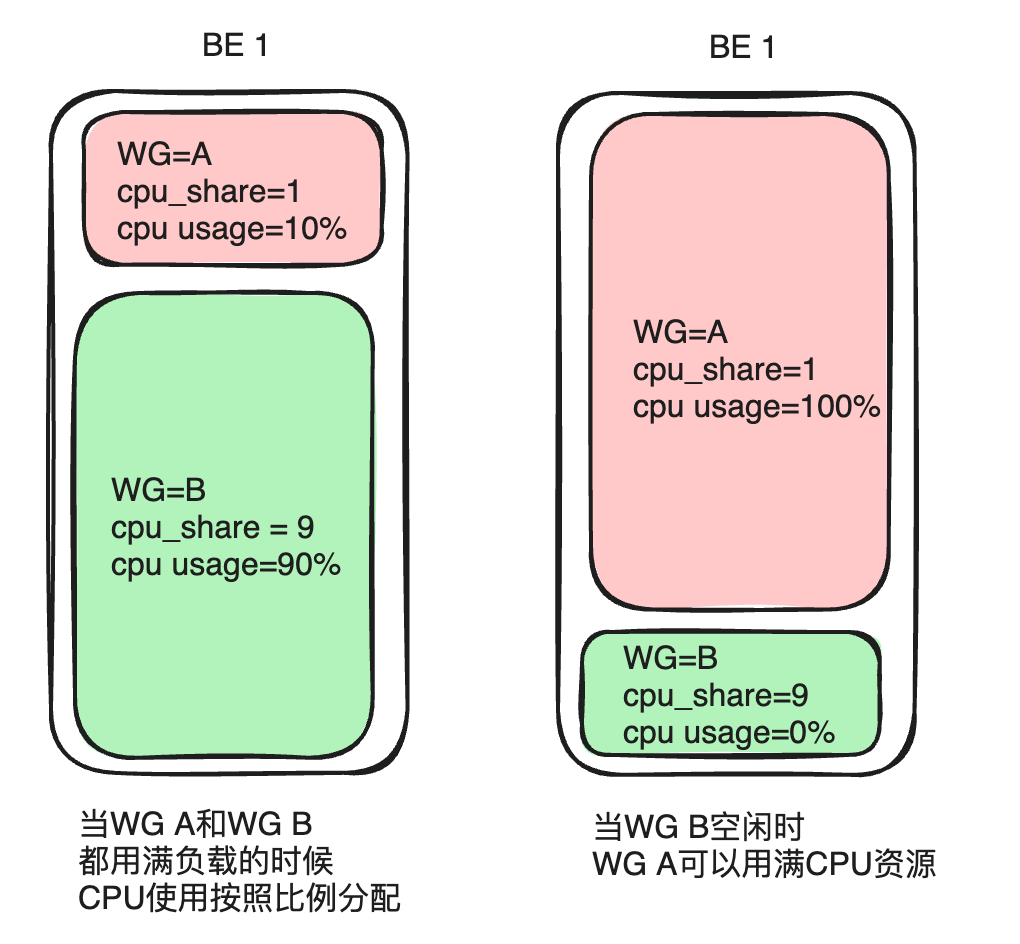
La priorité du CPU se reflète principalement cpu_shareau travers de paramètres, que l'on peut comparer à la notion de poids. Dans la même période, un groupe avec un poids plus élevé peut obtenir plus de temps CPU.
Prenons l'exemple du groupe A et du groupe B. Si le groupe A est configuré cpu_sharesur 1 et que le groupe B est configuré cpu_sharesur 9, une période de temps de 10 secondes est donnée. Lorsque les deux charges sont saturées, le groupe B avec un poids plus élevé peut obtenir du temps CPU pendant 9 secondes (90 % de toutes les ressources) et le groupe A peut obtenir du temps CPU pendant 1 seconde (10 % de toutes les ressources). En utilisation réelle, tous les services ne fonctionnent pas à pleine charge. Si la charge du groupe B est faible ou nulle, le groupe A peut monopoliser le temps CPU pendant 10 secondes. Cette méthode peut offrir une plus grande flexibilité d'allocation de ressources, améliorant ainsi l'utilisation globale des ressources CPU du cluster.
02 Limite stricte du processeur
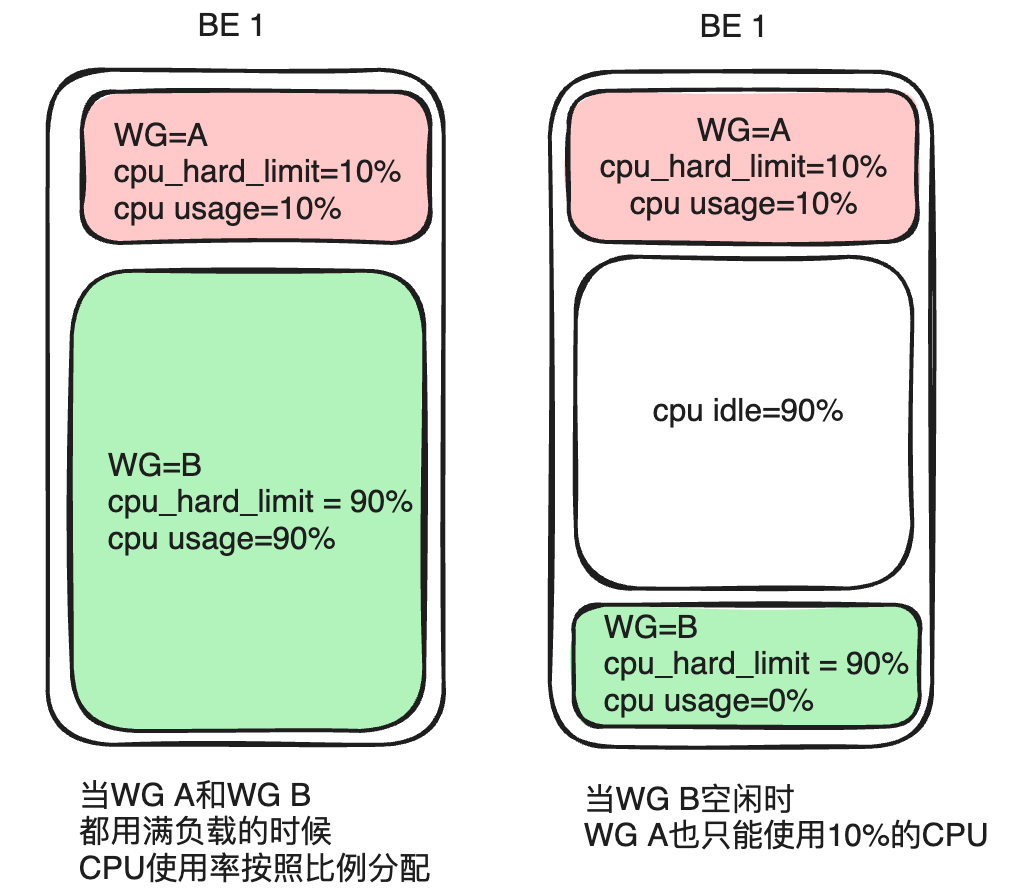
L'utilisation de la limite de temps logicielle du processeur peut entraîner des fluctuations dans les performances des requêtes si la charge du système est élevée ou si les ressources du processeur sont limitées. Afin de répondre aux exigences élevées des utilisateurs en matière de performances de requête stables, Apache Doris a implémenté la limite stricte du CPU du Workload Group dans la dernière version 2.1 - que le CPU global de la machine physique actuelle soit inactif ou non, l'utilisation maximale du CPU de le groupe configuré avec la limite stricte ne peut pas dépasser la valeur limite préconfigurée.
Prenons l'exemple du groupe A et du groupe B. Si vous configurez le groupe A cpu_hard_limit=10%, le groupe B. cpu_hard_limit=90%Lorsque les ressources CPU des deux machines atteignent saturation, l'utilisation du CPU du groupe A est de 10 % et celle du groupe B est de 90 %, ce qui est identique à la limite logicielle du CPU. Cependant, lorsque la charge du groupe B diminue ou qu'il n'y a pas de charge, même si le groupe A augmente la charge de requête, son utilisation maximale du processeur est toujours strictement limitée à 10 % et il ne peut pas obtenir plus de ressources. Bien que cette approche sacrifie la flexibilité de l’allocation des ressources, elle garantit également la stabilité des performances des requêtes.
03 Limitations des ressources mémoire
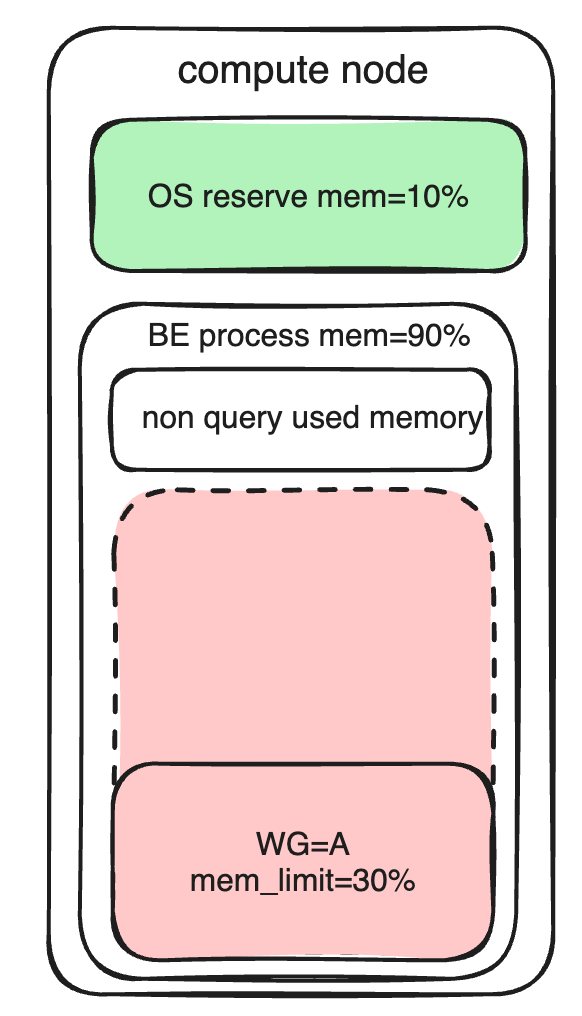
Mode d'emploi : la mémoire du nœud BE est principalement divisée en les parties suivantes :
- Le système d'exploitation réserve de la mémoire
- La partie non-requête de la mémoire dans le processus BE ne peut pas être comptabilisée par le groupe de charge de travail pour le moment.
- La mémoire de la partie requête au sein du processus BE (y compris les opérations d'importation) peut être comptée et gérée par le Workload Group.
Les limites des ressources mémoire sont principalement memory_limitlimitées par des paramètres (définissant le pourcentage de mémoire BE pouvant être utilisé). Non seulement vous pouvez définir l'utilisation de la mémoire préconfigurée, mais cela peut également affecter la priorité de restitution de la mémoire après une surcharge.
Dans l'état initial, les groupes de ressources à haute priorité se verront allouer plus de mémoire et les groupes de ressources à faible priorité se verront allouer moins de mémoire. Afin d'améliorer l'utilisation de la mémoire, vous pouvez enable_memory_overcommitactiver la limite logicielle de mémoire du groupe de ressources. Si le système dispose de ressources mémoire libres, elles peuvent être utilisées au-delà de la limite.
Afin d'assurer le fonctionnement stable du système, lorsque les ressources mémoire globales du système sont insuffisantes, le système donnera la priorité à l'annulation des tâches qui occupent de grandes quantités de mémoire pour récupérer les ressources mémoire surchargées. Au cours de ce processus, le système tentera de réserver les ressources mémoire des groupes de ressources à haute priorité et la mémoire excédentaire des groupes de ressources à faible priorité sera récupérée plus rapidement.
04 File d'attente des requêtes
Lorsque la charge métier dépasse la limite supérieure du système, continuer à soumettre de nouvelles requêtes non seulement ne pourra pas être exécutée efficacement, mais affectera également les requêtes en cours d'exécution. Pour éviter ce problème, Workload Group prend en charge la mise en file d'attente des requêtes. Lorsque la requête atteint la simultanéité maximale prédéfinie, le nouveau plan de soumission entrera dans la logique de file d'attente. Lorsque la file d'attente est pleine ou que le délai d'attente est écoulé, la requête sera rejetée pour soulager la pression sur le système en cas de charge élevée.
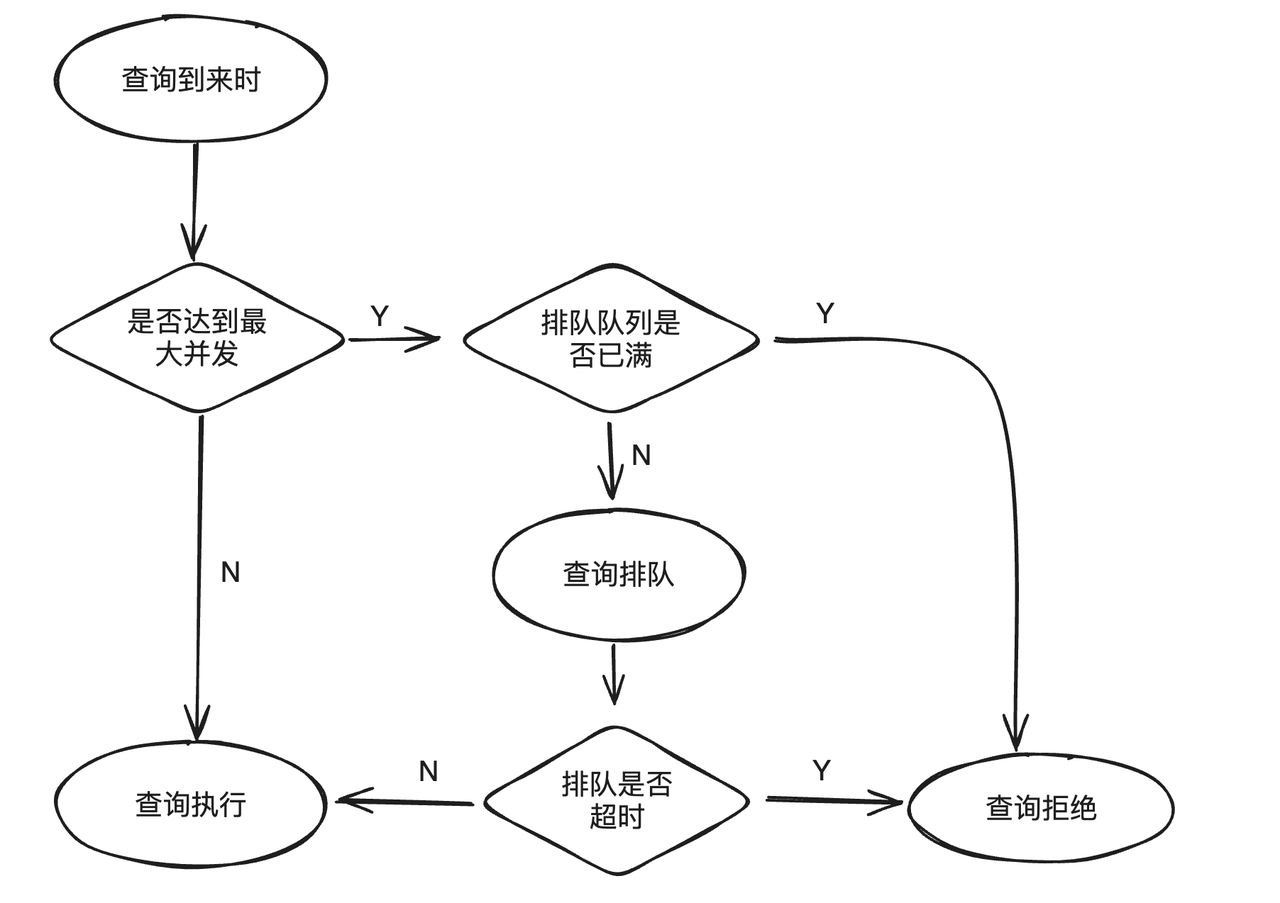
La fonction de mise en file d'attente des requêtes a principalement trois attributs :
max_concurrency: Le nombre maximum d'instructions SQL autorisées à s'exécuter simultanément dans le groupe actuel. Si le nombre maximum est dépassé, une logique de file d'attente sera entrée.max_queue_size: Le nombre maximum de requêtes autorisées dans la file d'attente. Si la file d'attente est pleine, la requête sera rejetée et l'exécution échouera.queue_timeout: Le délai de mise en file d'attente dans la file d'attente. S'il expire, il échouera directement. L'unité est en millisecondes.
Documentation de référence : https://doris.apache.org/zh-CN/docs/admin-manual/workload-group
Test d'utilisation du groupe de charge de travail
Ensuite, nous effectuons des tests détaillés sur la limite logicielle et la limite matérielle du processeur du groupe de charge de travail pour démontrer clairement aux utilisateurs l'effet de gestion de la charge et les performances de ces deux limites dans les mêmes conditions matérielles.
- Environnement de test : machine physique unique à mémoire de 16 cœurs et 64 Go
- Méthode de déploiement : 1 FE, 1 BE
- Ensemble de données de test : Clickbench, TPCH
- Outil de mesure des contraintes : JMeter
01 Test de limite logicielle du processeur
Démarrez deux clients (1, 2) pour tester l'effet de la limite logicielle du processeur sur la gestion de la charge sans utiliser/utiliser la limite logicielle du processeur respectivement. Il convient de noter que dans ce test, Page Cache affectera les résultats du test et que Page Cache doit être désactivé pour obtenir les résultats de test idéaux.
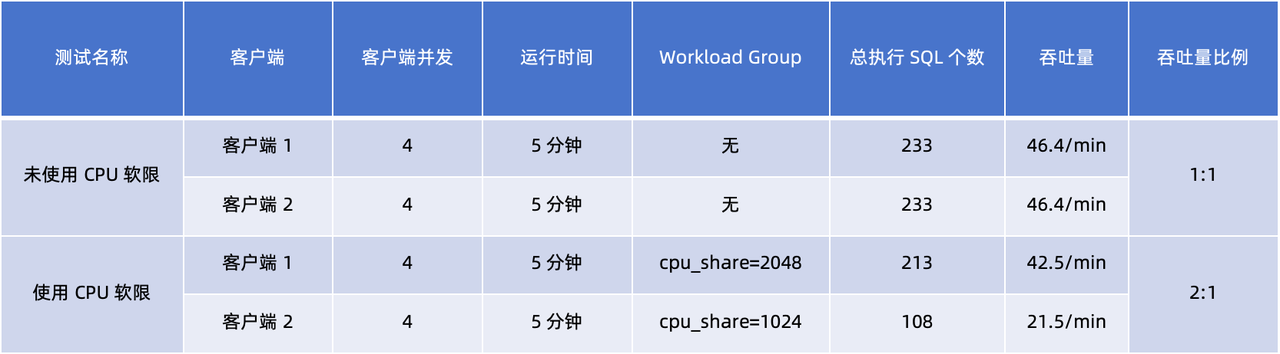
En comparant et en analysant les données de débit client dans les deux tests, nous pouvons tirer les conclusions suivantes :
- Sans Workload Group , le rapport de débit des deux clients est de 1:1, ce qui indique qu'ils reçoivent les mêmes ressources CPU pendant la même durée d'exécution.
- Après avoir utilisé Workload Group et les avoir définis respectivement
cpu_sharesur 2048 et 1024 , les résultats montrent que le rapport de débit devient 2:1. Cela montre quecpu_sharele client 1 avec des paramètres plus élevés obtient une proportion plus élevée de ressources CPU dans le même temps d'exécution .
02 Test de limite stricte du processeur
Comme le montre l'introduction ci-dessus, la limite stricte du processeur peut garantir une bonne isolation lorsque la charge est élevée. Par conséquent, nous utilisons une limite stricte pour limiter l'utilisation du processeur à 50 % ( cpu_hard_limit=50%) et utilisons le même client pour exécuter le test de requête q23 lorsque le nombre de simultanéités est de 1, 2 et 4 (simulant des charges différentes. Chaque test s'exécute). pendant 5 minutes. .

D'après les résultats des tests ci-dessus, nous pouvons voir qu'à mesure que le nombre de requêtes simultanées augmente, l'utilisation du processeur est toujours stable à environ 800 % (sur une machine à 16 cœurs, 800 % signifie utiliser 8 cœurs, et l' utilisation réelle du processeur est de 50). % ). Les ressources CPU étant fortement limitées, on s'attend à ce que la latence tp99 augmente à mesure que la concurrence augmente.
03 Simuler les tests de l'environnement de production
Dans les environnements de production réels, les utilisateurs accordent souvent plus d’attention aux performances de latence des requêtes qu’au débit pur. Afin d'être plus proches des scénarios d'application réels et d'évaluer avec précision les performances, nous avons sélectionné une série de requêtes SQL avec une latence d'environ 1 seconde (y compris les q15, q17, q23 de CKBench et les q3, q7, q19 de TPCH) pour former un ensemble SQL. Ces requêtes couvrent diverses fonctionnalités telles que l'agrégation d'une table unique et le calcul de jointure, et la taille de l'ensemble de données TPCH utilisée est de 100 Go.
Nous avons conçu deux ensembles de tests pour simuler des scénarios respectivement sans Workload Group et avec Workload Group. Quatre tests ont été réalisés sur le Client 1 et le Client 2, en se concentrant sur la latence du tp90 et du tp99.
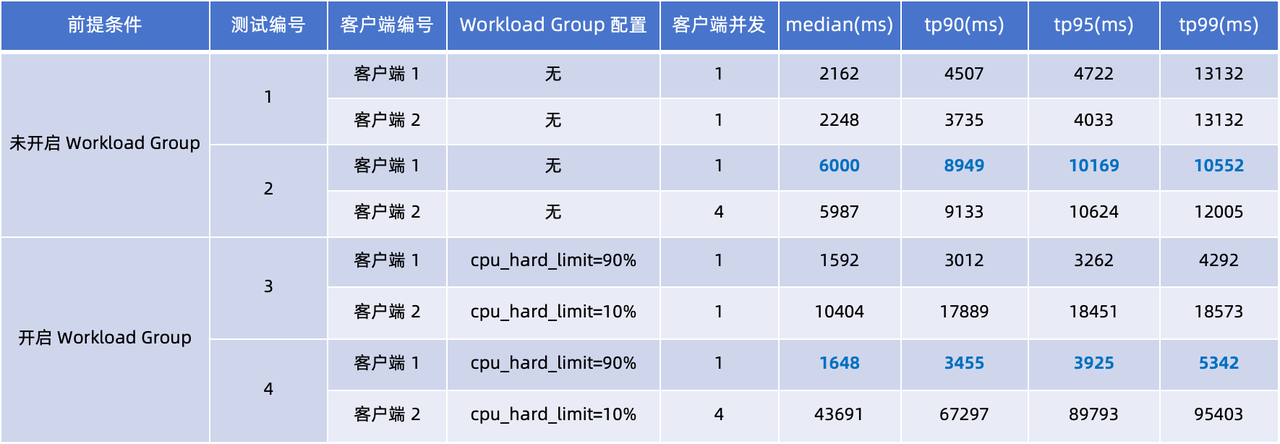
En observant les délais de requête dans les quatre tests du tableau ci-dessus, nous pouvons tirer les conclusions suivantes :
- Le Workload Group n'est pas utilisé (tests 1 et 2) : Lorsque la concurrence du client 2 passe de 1 à 4, les délais de requête des clients 1 et 2 augmentent significativement. En comparant les performances du client 1, les temps de réponse médians aux requêtes tp90 et tp95 ont augmenté de 2 à 3 fois.
- Utilisation du groupe de charge de travail (test 3, 4) : des limites strictes du processeur ont été appliquées dans ces deux tests : Set Client 1
cpu_hard_limit=90%, Client 2cpu_hard_limit=90%. Les résultats du test montrent que même si la concurrence du client 2 augmente, le délai de requête du client 1 n'augmente que légèrement, ce qui est nettement meilleur que les performances du test 2. Ce résultat démontre pleinement l’efficacité de Workload Group en matière d’isolation de charge et de garantie de stabilité des performances.
Conclusion
À l'heure actuelle, les fonctions Resource Tag et Workload Group ont été lancées dans les services de production de plusieurs utilisateurs communautaires et ont été vérifiées à grande échelle. Elles sont recommandées pour les utilisateurs ayant des besoins d'isolation des ressources.
Qu'il s'agisse d'une balise de ressource ou d'un groupe de charge de travail, l'objectif est d'équilibrer l'indépendance de l'isolation et de l'utilisation des ressources . Le premier adopte une solution d'isolation plus approfondie, tandis que le second atteint l'isolement tout en garantissant une utilisation complète des ressources et en garantissant davantage la stabilité du système. scénarios de charge de travail élevée grâce à des mécanismes de file d’attente de requêtes et de file d’attente de tâches.
Dans l'utilisation réelle de l'isolation des ressources, nous recommandons que les deux solutions puissent être combinées et appliquées selon des scénarios métiers :
- Si le même cluster est partagé entre les systèmes/départements inter-entreprises et que vous souhaitez obtenir une isolation physique des ressources et des données, vous pouvez adopter la solution Resource Tag ;
- Si vous êtes confronté à plusieurs types de charges de requêtes en même temps dans le même cluster, vous pouvez distinguer différentes charges via Workload Group et vous assurer que diverses charges de requêtes peuvent obtenir des ressources appropriées grâce à une allocation flexible des ressources ;
Nous avons encore de nombreux projets d’améliorations fonctionnelles ultérieures :
- La limite de mémoire actuelle est utilisée pour libérer de la mémoire via Cancel Query. À l'avenir, le placement des opérateurs peut améliorer encore la stabilité des requêtes volumineuses et éviter les échecs des tâches de requête lorsque les ressources sont limitées.
- Actuellement, dans le modèle de mémoire du processus BE, une partie de la mémoire non liée aux requêtes n'est pas prise en compte, ce qui peut entraîner des différences entre la mémoire du processus BE et la mémoire utilisée par le groupe de charge de travail vue par les utilisateurs. Nous allons essayer de résoudre ce problème. problème dans les versions futures.
- La fonction de mise en file d'attente des requêtes ne prend en charge que la mise en file d'attente basée sur le nombre maximum de requêtes simultanées. À l'avenir, le nombre maximum de requêtes simultanées sera limité par l'utilisation des ressources de BE, formant ainsi une contre-pression automatique sur le client et améliorant la disponibilité de Doris. lorsque le client continue de soumettre des charges élevées.
- La fonction Resource Tag consiste à diviser les ressources de la machine BE, et le groupe de charge de travail consiste à diviser les ressources au sein d'un seul processus machine. Ces deux méthodes de division des ressources exposent le concept de nœuds BE aux utilisateurs. Lorsque les utilisateurs utilisent la fonction de gestion des ressources, ils n'ont essentiellement qu'à prêter attention à la quantité de ressources disponibles et à la priorité d'allocation des ressources pour leurs propres charges de travail dans l'ensemble. À l’avenir, de nouvelles façons de diviser les ressources seront explorées afin de réduire les coûts de compréhension et d’utilisation pour les utilisateurs.
Remerciements
La fonction Workload Group est un projet développé conjointement par la communauté open source. Merci aux étudiants suivants pour leurs contributions : Luo Zenglin (luozenglin), Liu Lijia (liutang123), Zhao Liwei (levy5307).
J'ai décidé d'abandonner l'open source Hongmeng Wang Chenglu, le père de l'open source Hongmeng : L'open source Hongmeng est le seul événement logiciel industriel d'innovation architecturale dans le domaine des logiciels de base en Chine - OGG 1.0 est publié, Huawei contribue à tout le code source. Google Reader est tué par la "montagne de merde de code" Fedora Linux 40 est officiellement publié Ancien développeur Microsoft : les performances de Windows 11 sont "ridiculement mauvaises" Ma Huateng et Zhou Hongyi se serrent la main pour "éliminer les rancunes" Des sociétés de jeux bien connues ont publié de nouvelles réglementations : les cadeaux de mariage des employés ne doivent pas dépasser 100 000 yuans Ubuntu 24.04 LTS officiellement publié Pinduoduo a été condamné pour concurrence déloyale Indemnisation de 5 millions de yuans