

Construire vos applications d'IA autour de modèles open source peut les rendre meilleures, moins chères et plus rapides.
Traduit de Comment battre les LLM propriétaires avec des modèles open source plus petits , auteur Aidan Cooper.
Introduction
Lors de la conception de systèmes utilisant des modèles de génération de texte, de nombreuses personnes se tournent d'abord vers des services propriétaires, tels que GPT-4 d'OpenAI ou Gemini de Google. Après tout, ce sont les modèles les plus grands et les meilleurs, alors pourquoi s’embêter avec autre chose ? Finalement, les applications atteignent une échelle que ces API ne prennent pas en charge, ou leur coût devient prohibitif, ou les temps de réponse sont trop lents. Les modèles open source peuvent résoudre tous ces problèmes, mais si vous essayez de les utiliser de la même manière que vous utilisez des LLM propriétaires, vous n'obtiendrez pas suffisamment de performances.
Dans cet article, nous explorerons les avantages uniques des LLM open source et comment ils peuvent être exploités pour développer des applications d'IA qui sont non seulement moins chères et plus rapides que les LLM propriétaires, mais aussi meilleures.
LLM propriétaire vs LLM Open Source
Le tableau 1 compare les principales caractéristiques des LLM propriétaires et des LLM open source. On pense que LLM open source s'exécute sur une infrastructure gérée par l'utilisateur, que ce soit sur site ou dans le cloud. En résumé : LLM propriétaire est le service géré et offre le modèle source fermé le plus puissant et la plus grande fenêtre de contexte, mais LLM open source est supérieur dans tous les autres domaines importants.
Voici la version chinoise du tableau (format markdown) :
| Grand modèle de langage propriétaire | Grand modèle de langage open source | |
|---|---|---|
| Exemple | GPT-4 (OpenAI)、Gemini (Google)、Claude (Anthropic) | Gemma 2B (Google), Mistral 7B (Mistral AI), Lama 3 70B (Méta) |
| accessibilité des logiciels | Source fermée | Open source |
| Nombre de paramètres | niveau billion | Échelle typique : 2B, 7B, 70B |
| fenêtre contextuelle | Plus long, 100 000 à 1 million de jetons | Jetons plus courts et typiques de 8 000 à 32 000 |
| capacité | Meilleur performer dans tous les classements et benchmarks | Historiquement en retard par rapport aux grands modèles de langage propriétaires |
| Infrastructure | Platform as a Service (PaaS), gérée par le fournisseur. Non configurable. Limites de débit de l'API. | Généralement autogéré sur une infrastructure cloud (IaaS). Entièrement configurable. |
| Coût du raisonnement | plus haut | inférieur |
| vitesse | Plus lent au même prix. Ne peut pas être ajusté. | Cela dépend de l'infrastructure, de la technologie et de l'optimisation, mais plus rapidement. Hautement configurable. |
| Débit | Généralement soumis à la limite de débit de l'API. | Illimité : évolue avec votre infrastructure. |
| Retard | plus haut. Plusieurs cycles de conversations peuvent accumuler une latence réseau importante. | Si vous exécutez le modèle localement, il n'y a pas de latence réseau. |
| Fonction | Expose généralement un ensemble limité de fonctionnalités via son API. | L'accès direct au modèle débloque de nombreuses techniques puissantes. |
| cache | Impossible d'accéder au côté serveur | Politiques configurables côté serveur pour augmenter le débit et réduire les coûts. |
| réglage fin | Services de réglage fin limités (tels que OpenAI) | Contrôle total sur le réglage fin. |
| Projet Invite/Flux | Souvent impossible en raison du coût élevé ou des limites tarifaires ou des retards | Des processus de contrôle illimités et soigneusement conçus ont un impact négatif minime. |
**Tableau 1.** Comparaison des fonctionnalités LLM propriétaires et LLM Open Source
L'objectif de cet article est qu'en tirant parti des atouts des modèles open source, il est possible de créer des applications d'IA qui exécutent mieux les tâches que les LLM propriétaires, tout en obtenant de meilleurs profils de débit et de coûts.
Nous nous concentrerons sur les stratégies pour les modèles open source qui ne sont pas possibles ou moins efficaces avec les LLM propriétaires. Cela signifie que nous ne discuterons pas des techniques qui profitent aux deux, telles que les indices en quelques coups ou la génération augmentée par récupération (RAG).
Exigences pour un système LLM efficace
Lorsque l’on réfléchit à la manière de concevoir des systèmes efficaces autour du LLM, il y a quelques principes importants à garder à l’esprit.
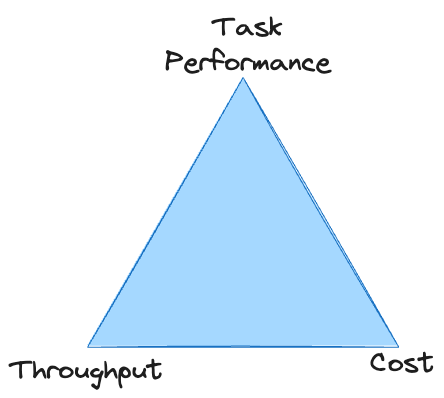
Il existe un compromis direct entre la performance des tâches, le débit et le coût : il est facile d’améliorer l’un d’entre eux, mais généralement au détriment des deux autres. À moins que vous ne disposiez d’un budget illimité, le système doit répondre à des normes minimales dans les trois domaines pour survivre. Avec les LLM propriétaires, vous êtes souvent coincé au sommet du triangle, incapable d’atteindre un débit suffisant à un coût acceptable.
Nous décrirons brièvement les caractéristiques de chacune de ces exigences non fonctionnelles avant d'explorer des stratégies qui peuvent aider à résoudre chaque problème.
Débit
De nombreux systèmes LLM ont du mal à atteindre un débit adéquat simplement parce que LLM est lent.
Lors de l'utilisation de LLM, le débit global du système est presque entièrement déterminé par le temps requis pour générer la sortie texte.
À moins que votre traitement de données soit particulièrement lourd, les facteurs autres que la génération de texte sont relativement peu importants. LLM peut "lire" le texte beaucoup plus rapidement qu'il ne peut le générer - en effet, les jetons d'entrée sont calculés en parallèle, tandis que les jetons de sortie sont générés séquentiellement.
Nous devons maximiser la vitesse de génération de texte sans sacrifier la qualité ni engager des coûts excessifs.
Cela nous donne deux leviers sur lesquels agir lorsque l’objectif est d’augmenter le débit :
- Réduisez le nombre de jetons à générer
- Augmentez la vitesse de génération de chaque jeton individuel
La plupart des stratégies ci-dessous sont conçues pour améliorer l’un ou l’autre de ces domaines.
coût
Pour le LLM propriétaire, vous serez facturé par jeton d’entrée et de sortie. Le prix de chaque jeton sera lié à la qualité (c'est-à-dire la taille) du modèle que vous utilisez. Cela vous donne des options limitées pour réduire les coûts : vous devez réduire le nombre de jetons d'entrée/sortie ou utiliser un modèle moins cher (il n'y aura pas trop de choix).
Avec LLM auto-hébergé, vos coûts sont déterminés par votre infrastructure. Si vous utilisez un service cloud pour l'hébergement, vous serez facturé par unité de temps pendant laquelle vous « louez » la machine virtuelle.

Les modèles plus grands nécessitent des machines virtuelles plus grandes et plus coûteuses. Augmenter le débit sans modifier le matériel réduit les coûts car moins d'heures de calcul sont nécessaires pour traiter une quantité fixe de données. De même, le débit peut être augmenté en faisant évoluer le matériel verticalement ou horizontalement, mais cela entraînera une augmentation des coûts.
Les stratégies de minimisation des coûts se concentrent sur l’utilisation de modèles plus petits pour la tâche, car ceux-ci ont le débit le plus élevé et sont les moins chers à exécuter.
performance des tâches
La performance de la mission est la plus vague des trois exigences, mais aussi celle qui présente la plus grande marge d'optimisation et d'amélioration. L’un des principaux défis pour parvenir à une performance adéquate des tâches est de la mesurer : il est difficile d’obtenir une évaluation fiable et quantitative des résultats du LLM.
Parce que nous nous concentrons sur les technologies qui profitent uniquement au LLM open source, notre stratégie met l'accent sur faire plus avec moins de ressources et sur l'exploitation de méthodes qui ne sont possibles qu'avec un accès direct au modèle.
Stratégies LLM Open Source pour vaincre le LLM propriétaire
Toutes les stratégies suivantes sont efficaces isolément, mais elles sont également complémentaires. Ils peuvent être appliqués à différents degrés pour trouver le juste équilibre entre les exigences non fonctionnelles du système et maximiser les performances globales.
Dialogue multi-tours et flux de contrôle
- Améliorer les performances des tâches
- Réduire le débit
- Ajouter le coût par entrée
Même si un large éventail de stratégies de dialogue multitours peuvent être utilisées avec les LLM propriétaires, ces stratégies ne sont souvent pas réalisables car elles :
- Peut être coûteux lorsqu'il est facturé par jeton
- Peut épuiser les limites de débit de l'API car elles nécessitent plusieurs appels d'API par entrée
- Peut être trop lent si l'échange implique de générer de nombreux jetons ou d'accumuler une latence réseau importante
Cette situation est susceptible de s'améliorer avec le temps, à mesure que les LLM propriétaires deviennent plus rapides, plus évolutifs et plus abordables. Mais pour l’instant, les LLM propriétaires se limitent souvent à une seule stratégie à invite unique qui peut être appliquée à grande échelle à des cas d’utilisation réels. Ceci est cohérent avec la fenêtre contextuelle plus large fournie par les LLM propriétaires : la stratégie privilégiée consiste souvent simplement à regrouper un grand nombre d'informations et d'instructions dans une seule invite (ce qui, soit dit en passant, a des impacts négatifs sur les coûts et la vitesse).
Avec un modèle auto-hébergé, ces inconvénients des conversations à plusieurs tours sont moins préoccupants : le coût par jeton est moins pertinent ; il n'y a pas de limite de débit API et la latence du réseau peut être minimisée ; La fenêtre contextuelle plus petite et les capacités d'inférence plus faibles des modèles open source devraient également vous empêcher d'utiliser un seul indice. Cela nous amène à la stratégie de base pour vaincre les LLM propriétaires :
La clé pour surmonter le LLM propriétaire est d’utiliser des modèles open source plus petits pour accomplir davantage de travail dans une série de sous-tâches plus fines.
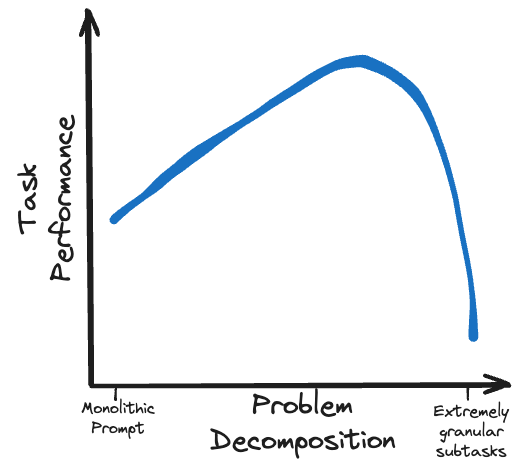
Des stratégies d’incitation à plusieurs tours soigneusement formulées sont réalisables pour les modèles locaux. Des techniques telles que Chain of Thoughts (CoT), Trees of Thought (ToT) et ReAct permettent aux modèles moins performants de fonctionner à égalité avec des modèles plus grands.
Un autre niveau de complexité est l'utilisation du flux de contrôle et du branchement pour guider dynamiquement le modèle le long du chemin d'inférence correct et décharger certaines tâches de traitement vers des fonctions externes. Ceux-ci peuvent également être utilisés comme mécanisme pour préserver le budget des jetons de la fenêtre contextuelle en divisant les sous-tâches dans des branches en dehors du flux d'invite principal, puis en rejoignant les résultats agrégés de ces forks.
Plutôt que de surcharger un petit modèle open source avec une tâche trop complexe, décomposez le problème en un flux logique de sous-tâches réalisables.
décodage restreint
- Améliorer le débit
- réduire les coûts
- Améliorer les performances des tâches
Pour les applications qui impliquent de générer une sortie structurée (telles que des objets JSON), le décodage restreint est une technique puissante qui peut :
- Sortie garantie conforme à la structure requise
- Améliorez considérablement le débit en accélérant la génération de jetons et en réduisant le nombre de jetons à générer
- Améliorer les performances des tâches en guidant les modèles
J'ai écrit un article séparé expliquant ce sujet en détail : Un guide de génération structurée avec décodage restreint. Le comment, le pourquoi, les capacités et les pièges de la génération de sorties de modèle de langage.
Surtout, le décodage par contraintes ne fonctionne qu'avec des modèles de génération de texte qui fournissent un accès direct à la distribution complète de probabilité du prochain jeton, qui n'est disponible auprès d'aucun fournisseur LLM propriétaire majeur au moment de la rédaction.
OpenAI fournit un schéma JSON , mais ce décodage strictement contraint ne garantit pas les avantages structurels ou de débit de la sortie JSON.
Le décodage par contraintes va de pair avec les stratégies de flux de contrôle, car il vous permet de diriger de manière fiable un grand modèle de langage vers un chemin prédéfini en limitant sa réponse à différentes options de branchement. Demander à un modèle de produire des réponses courtes et contraintes à une série de longues questions de dialogue à plusieurs tours est très rapide et peu coûteux (rappelez-vous : la vitesse de débit est déterminée par le nombre de jetons générés).
Le décodage par contraintes ne présente aucun inconvénient notable, donc si votre tâche nécessite une sortie structurée, vous devez l'utiliser.
Mise en cache, quantification de modèle et autres optimisations backend
- Améliorer le débit
- réduire les coûts
- N'affecte pas l'exécution des tâches
La mise en cache est une technique qui accélère les opérations de récupération de données en stockant les paires entrée/sortie d'un calcul et en réutilisant les résultats si la même entrée est rencontrée à nouveau.
Dans les systèmes non LLM, la mise en cache est généralement appliquée aux requêtes qui correspondent exactement aux requêtes vues précédemment. Certains systèmes LLM peuvent également bénéficier de cette forme stricte de mise en cache, mais en général, lors de la construction avec LLM, nous ne voulons pas rencontrer trop souvent exactement la même entrée.
Heureusement, il existe des techniques sophistiquées de mise en cache clé-valeur, spécifiques au LLM, qui sont beaucoup plus flexibles. Ces techniques peuvent considérablement accélérer la génération de texte pour les requêtes qui correspondent partiellement, mais pas exactement, aux entrées vues précédemment. Cela améliore le débit du système en réduisant la quantité de jetons à générer (ou au moins en les accélérant, en fonction de la technologie de mise en cache et du scénario spécifiques).
Avec un LLM propriétaire, vous n'avez aucun contrôle sur la façon dont la mise en cache est ou n'est pas effectuée sur vos requêtes. Mais pour le LLM open source, il existe différents frameworks backend pour les services LLM qui peuvent améliorer considérablement le débit d'inférence et peuvent être configurés en fonction des exigences personnalisées de votre système.
Outre la mise en cache, il existe d'autres optimisations LLM qui peuvent être utilisées pour améliorer le débit d'inférence, telles que la quantification du modèle . En réduisant la précision utilisée pour les poids des modèles, la taille du modèle (et donc ses besoins en mémoire) peut être réduite sans compromettre de manière significative la qualité de sa sortie. Les modèles populaires ont souvent un grand nombre de variantes quantifiées disponibles sur Hugging Face, fournies par la communauté open source, ce qui vous évite d'avoir à effectuer vous-même le processus de quantification.
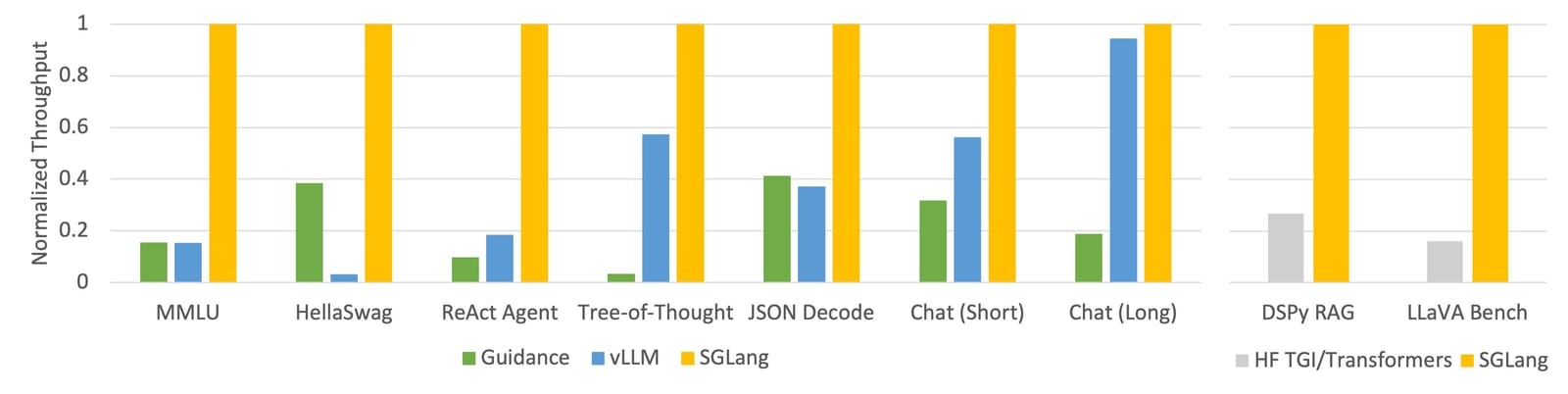
Annonce du débit incroyable de SGLang (voir le billet de blog sur la version SGLang)
vLLM est probablement le framework de service le plus mature, avec divers mécanismes de mise en cache, de parallélisation, d'optimisation du noyau et de quantification de modèle. SGLang est un lecteur plus récent avec des fonctionnalités similaires à vLLM, ainsi qu'une méthode de mise en cache RadixAttention innovante qui revendique des performances particulièrement impressionnantes.
Si vous hébergez vous-même votre modèle, cela vaut la peine d'utiliser ces frameworks et techniques d'optimisation, car vous pouvez raisonnablement vous attendre à améliorer le débit d'au moins un ordre de grandeur.
Affinement du modèle et distillation des connaissances
- Améliorer l’efficacité de l’exécution des tâches
- N'affecte pas les coûts de raisonnement
- N'affecte pas le débit
Le réglage fin englobe une variété de techniques permettant d'ajuster un modèle existant afin de mieux fonctionner sur une tâche spécifique. Je vous recommande de consulter le billet de blog de Sebastian Raschka sur les méthodes de réglage fin comme introduction au sujet. La distillation des connaissances est un concept connexe dans lequel un modèle « étudiant » plus petit est formé pour simuler le résultat d'un modèle « enseignant » plus grand sur la tâche qui l'intéresse.
Certains fournisseurs LLM propriétaires, notamment OpenAI , offrent des capacités de réglage minimes. Mais seuls les modèles open source offrent un contrôle total sur le processus de réglage fin et un accès à des technologies complètes de réglage fin.
Des modèles de réglage précis peuvent améliorer considérablement les performances des tâches sans affecter le coût ou le débit d'inférence. Mais la mise au point nécessite du temps, des compétences et de bonnes données à mettre en œuvre, et le processus de formation a un coût. Les techniques de réglage efficace des paramètres (PEFT) telles que LoRA sont particulièrement intéressantes car elles offrent les rendements de performances les plus élevés par rapport à la quantité de ressources requises.
Le réglage fin et la distillation des connaissances font partie des techniques les plus puissantes pour maximiser les performances du modèle. Tant qu’ils sont correctement mis en œuvre, ils ne présentent aucun inconvénient, à l’exception de l’investissement initial initial requis pour leur exécution. Cependant, vous devez veiller à ce que le réglage fin soit effectué d'une manière cohérente avec d'autres aspects du système, tels que le flux de repères et les structures de sortie de décodage restreintes. S'il existe des différences entre ces technologies, un comportement inattendu peut en résulter.
Optimiser la taille du modèle
Petit modèle :
- Améliorer le débit
- réduire les coûts
- Réduire les performances d’exécution des tâches
Cela peut également être considéré comme un « modèle plus large », avec des avantages et des inconvénients opposés. Les points clés sont :
Rendez votre modèle aussi petit que possible tout en conservant une capacité suffisante pour comprendre et accomplir la tâche de manière fiable.
La plupart des fournisseurs LLM propriétaires proposent un certain niveau de taille/capacité de modèle. Et lorsqu'il s'agit d'open source, il existe des options de modèles vertigineuses dans toutes les tailles souhaitées, jusqu'à plus de 100 milliards de paramètres.
Comme mentionné dans la section Conversation à plusieurs tours, nous pouvons simplifier les tâches complexes en les décomposant en une série de sous-tâches plus gérables. Mais il y aura toujours un problème qui ne pourra pas être approfondi, ou qui compromettrait des aspects de la mission qui doivent être abordés de manière plus approfondie. Cela dépend fortement du cas d'utilisation, mais la granularité et la complexité des tâches auront un juste équilibre qui dictera la taille correcte du modèle, comme le montre l'obtention de performances de tâche adéquates avec la plus petite taille de modèle.
Pour certaines tâches, cela signifie utiliser le modèle le plus grand et le plus performant que vous puissiez trouver ; pour d'autres tâches, vous pourrez peut-être utiliser un très petit modèle (même un non-LLM).
Dans tous les cas, choisissez d’utiliser le meilleur modèle de sa catégorie pour n’importe quelle taille de paramètre donnée. Cela peut être identifié en référence aux références et classements publics , qui changent régulièrement en fonction du rythme rapide du développement dans le domaine. Certains benchmarks sont plus adaptés à votre cas d'utilisation que d'autres, il vaut donc la peine de découvrir lesquels fonctionnent le mieux.
Mais ne pensez pas que vous pouvez simplement remplacer le nouveau meilleur modèle et obtenir une amélioration immédiate des performances. Différents modèles ont des modes de défaillance et des caractéristiques différents, donc un système optimisé pour un modèle ne fonctionnera pas nécessairement pour un autre, même s'il devrait être meilleur.
feuille de route technologique
Comme mentionné précédemment, toutes ces stratégies sont complémentaires et, lorsqu’elles sont combinées, elles se combinent pour produire un système robuste et complet. Mais il existe des dépendances entre ces technologies, et il est important de garantir leur cohérence pour éviter tout dysfonctionnement.
La figure suivante est un diagramme de dépendances montrant la séquence logique de mise en œuvre de ces technologies. Cela suppose que le cas d'utilisation nécessite de générer une sortie structurée.
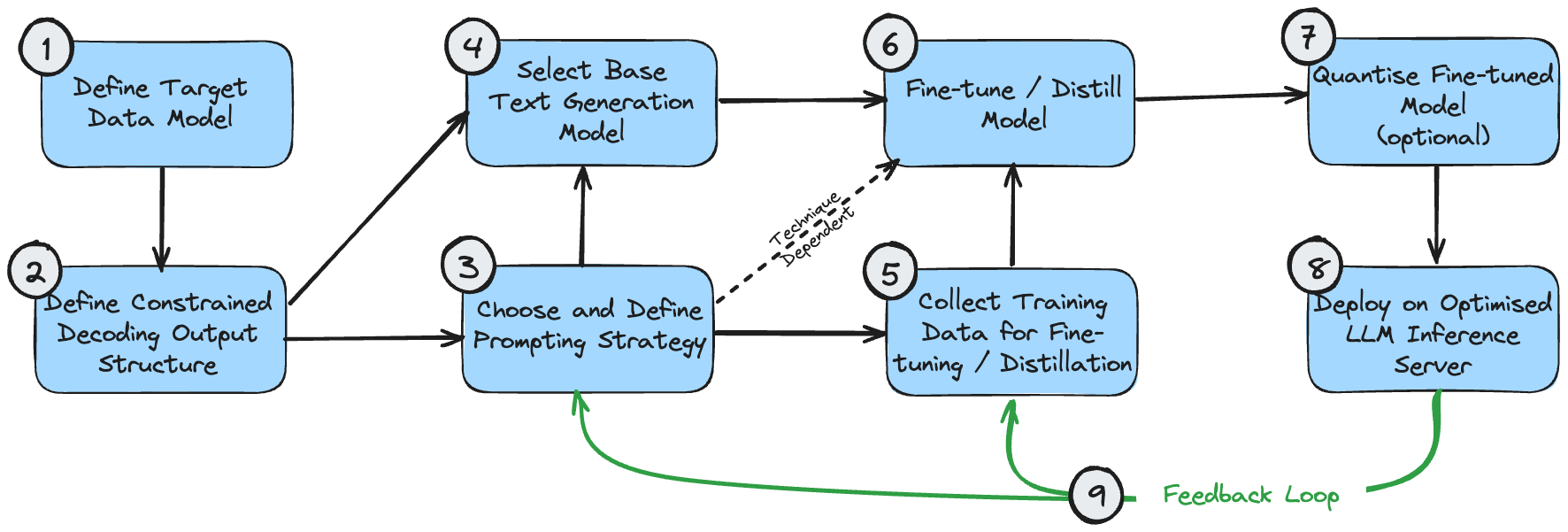
Ces étapes peuvent être comprises comme suit :
- Le modèle de données cible est le résultat final que vous souhaitez créer. Ceci est déterminé par votre cas d'utilisation et les exigences plus larges du système global au-delà de la génération de traitement de texte.
- La structure de sortie du décodage restreint peut être la même que votre modèle de données cible, ou elle peut être légèrement modifiée pour des performances optimales lors du décodage restreint. Consultez mon article sur le décodage restreint pour comprendre pourquoi cela se produit. S'il est différent, une étape de post-traitement est nécessaire pour le transformer en modèle de données cible final.
- Vous devez faire une première estimation de la stratégie d’invite appropriée pour votre cas d’utilisation. Si le problème est simple ou ne peut pas être décomposé intuitivement, choisissez une stratégie d’invite unique. Si le problème est très complexe et comporte de nombreux sous-composants à granularité fine, choisissez une stratégie à invites multiples.
- Votre sélection initiale de modèle consiste principalement à optimiser la taille et à garantir que les propriétés du modèle répondent aux exigences fonctionnelles du problème. Les tailles de modèle optimales sont discutées ci-dessus. Les propriétés du modèle telles que la longueur de fenêtre contextuelle requise peuvent être calculées sur la base de la structure de sortie attendue ((1) et (2)) et de la stratégie d'invite (3).
- Les données de formation utilisées pour le réglage fin du modèle doivent être cohérentes avec la structure de sortie (2). Si une stratégie multi-indices est utilisée pour construire le résultat étape par étape, les données d'entraînement doivent également refléter chaque étape de ce processus.
- Le réglage/distillation du modèle dépend naturellement de la sélection de votre modèle, de la conservation des données d'entraînement et du flux d'invites.
- La quantification des modèles affinés est facultative. Vos options de quantification dépendront du modèle de base que vous choisissez.
- Le serveur d'inférence LLM ne prend en charge que des architectures de modèles et des méthodes de quantification spécifiques. Assurez-vous donc que votre sélection précédente est compatible avec la configuration backend souhaitée.
- Une fois que vous avez mis en place un système de bout en bout, vous pouvez créer une boucle de rétroaction pour une amélioration continue. Vous devez ajuster périodiquement les invites et les exemples succincts (si vous les utilisez) pour tenir compte des exemples dans lesquels le système ne parvient pas à produire un résultat acceptable. Une fois que vous avez accumulé un échantillon raisonnable de cas d’échec, vous devez également envisager d’utiliser ces échantillons pour effectuer des réglages plus précis du modèle.
En réalité, le processus de développement n’est jamais complètement linéaire et, selon le cas d’utilisation, vous devrez peut-être donner la priorité à l’optimisation de certains de ces composants plutôt que d’autres. Mais c’est une base raisonnable à partir de laquelle concevoir une feuille de route basée sur vos besoins spécifiques.
en conclusion
Les modèles open source peuvent être plus rapides, moins chers et meilleurs que les LLM propriétaires. Cela peut être accompli en concevant des systèmes plus complexes qui exploitent les atouts uniques des modèles open source et font des compromis appropriés entre le débit, le coût et les performances de la mission.
Ce choix de conception troque la complexité du système contre des performances globales. Une alternative valable consiste à disposer d’un système plus simple et tout aussi puissant, alimenté par un LLM propriétaire, mais à un coût plus élevé et à un débit inférieur. La bonne décision dépend de votre application, de votre budget et de la disponibilité de vos ressources d'ingénierie.
Mais n’abandonnez pas trop rapidement les modèles open source sans adapter votre stratégie technologique pour les prendre en compte : vous pourriez être surpris par ce qu’ils peuvent faire.
J'ai décidé d'abandonner les logiciels industriels open source. OGG 1.0 est sorti, Huawei a contribué à tout le code source. Ubuntu 24.04 LTS a été officiellement publié. L'équipe de Google Python Foundation a été tuée par la "montagne de merde de code" . ". Fedora Linux 40 a été officiellement lancé. Une société de jeux bien connue a publié de nouvelles réglementations : les cadeaux de mariage des employés ne doivent pas dépasser 100 000 yuans. China Unicom lance la première version chinoise Llama3 8B au monde du modèle open source. Pinduoduo est condamné à compenser 5 millions de yuans pour concurrence déloyale Méthode de saisie dans le cloud domestique - seul Huawei n'a aucun problème de sécurité de téléchargement de données dans le cloud.Cet article a été publié pour la première fois sur Yunyunzhongsheng ( https://yylives.cc/ ), tout le monde est invité à le visiter.