
écrire devant
Cet article présente principalement l'article « Kepler : Robust Learning for Faster Parametric Query Optimization » publié chez SIGMOD en 2023. Cet article combine l'optimisation des requêtes paramétrées et l'optimisation des requêtes pour les requêtes paramétrées, visant à réduire le temps de planification des requêtes tout en améliorant les performances des requêtes.
À cette fin, l'auteur propose une méthode d'optimisation de requêtes paramétriques de bout en bout basée sur l'apprentissage profond appelée Kepler (K-plan Evolution for Parametric Query Optimization: Learned, Empirical, Robust).
La requête numérique fait référence à un type de requête qui a la même structure SQL et ne diffère que par les valeurs des paramètres liés. À titre d'exemple, considérons la structure de requête suivante :
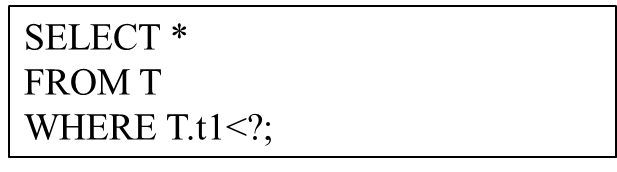
La structure de la requête peut être considérée comme un modèle de requête paramétrée, et le « ? » représente différentes valeurs de paramètre. Les instructions SQL exécutées par l'utilisateur ont toutes cette structure de requête, mais les valeurs réelles des paramètres peuvent être différentes. Il s'agit d'une requête paramétrée. De telles requêtes paramétrées sont très fréquemment utilisées dans les bases de données modernes. Parce qu'il exécute continuellement le même modèle de requête à plusieurs reprises, il offre des opportunités d'améliorer les performances de ses requêtes.
L'optimisation des requêtes paramétrées (PQO) est utilisée pour optimiser les performances des requêtes paramétrées mentionnées ci-dessus. L'objectif est de réduire autant que possible le temps de planification des requêtes tout en évitant la régression des performances. Les approches existantes s'appuient trop sur l'optimiseur de requêtes intégré au système, ce qui les soumet au caractère sous-optimal inhérent de l'optimiseur. L'auteur estime que le système idéal pour les requêtes paramétrées devrait non seulement réduire le temps de planification des requêtes via PQO, mais également améliorer les performances d'exécution des requêtes du système grâce à l'optimisation des requêtes (QO).
L'optimisation des requêtes (QO) est utilisée pour aider une requête à trouver son plan d'exécution optimal. La plupart des méthodes existantes pour améliorer l'optimisation des requêtes appliquent l'apprentissage automatique, comme les estimateurs de cardinalité/coût basés sur l'apprentissage automatique. Cependant, la méthode actuelle d'optimisation des requêtes basée sur l'apprentissage présente certains défauts : (1) Le temps d'inférence est trop long ; (2) La capacité de généralisation est faible (3) L'amélioration des performances n'est pas claire ; et les performances peuvent diminuer.
Les lacunes ci-dessus posent des défis aux méthodes basées sur l’apprentissage, car elles ne peuvent pas garantir l’amélioration du temps d’exécution des résultats de prédiction. Pour résoudre les problèmes ci-dessus, l'auteur propose Kepler : une méthode d'optimisation de requêtes paramétrées basée sur l'apprentissage de bout en bout.
Les auteurs dissocient l'optimisation paramétrique des requêtes en deux problèmes : la génération de plans candidats et les structures de prédiction basées sur l'apprentissage. Il est principalement divisé en trois étapes : la génération de nouveaux plans candidats, la collecte de données de formation et la conception d'un modèle de réseau neuronal robuste. La combinaison des trois réduit le temps de planification des requêtes tout en améliorant les performances d'exécution des requêtes, tout en répondant aux objectifs de PQO et QO. Ensuite, nous présentons d’abord l’architecture globale de Kepler, puis expliquons en détail le contenu spécifique de chaque module.
Architecture globale
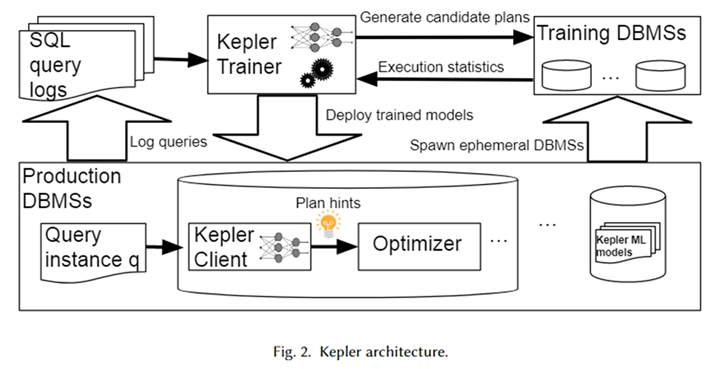
L'architecture globale de Kepler est illustrée dans la figure ci-dessus. Tout d'abord, obtenez le modèle de requête paramétré et l'instance de requête correspondante (c'est-à-dire la requête avec les valeurs de paramètres réelles) à partir du journal système de base de données pour former une charge de travail. Kepler Trainer est utilisé pour former un modèle prédictif de réseau neuronal pour cette charge de travail. Il génère d'abord des plans candidats sur l'ensemble de la charge de travail et les exécute sur un système de base de données temporaire pour obtenir le temps d'exécution réel des requêtes.
Utilisez ce temps de requête pour entraîner un modèle de réseau neuronal. Une fois la formation terminée, elle est déployée dans le système de base de données de l'environnement de production, appelé Kepler Client. Lorsque l'utilisateur saisit une instance de requête, Kepler Client peut prédire le meilleur plan d'exécution et le transmettre à l'optimiseur sous la forme d'un indice de plan pour générer et exécuter le meilleur plan.
Génération de plans candidats : évolution du nombre de lignes
L'objectif de la génération de plans candidats est de construire un ensemble de plans contenant un plan d'exécution presque optimal pour chaque instance de requête de la charge de travail. De plus, il doit être aussi petit que possible pour éviter une surcharge excessive lors du processus ultérieur de collecte de données de formation. Les deux se contraignent mutuellement, et la manière d’équilibrer ces deux objectifs constitue un défi majeur dans la génération de plans candidats.
L'équation 1 formule des objectifs spécifiques de génération de plan. Parmi eux, se trouve une instance de requête sur la charge de travail W, le plan d'exécution sélectionné par l'optimiseur, le plan optimal dans le plan défini dans des circonstances idéales et ExecTime est le temps d'exécution du plan correspondant sur l'instance. Par conséquent, la connotation de l'équation 1 est l'accélération du temps d'exécution de l'ensemble de plans candidats par rapport à l'ensemble de plans généré par l'optimiseur sur l'ensemble de la charge de travail. L'algorithme est conçu pour maximiser cette accélération.
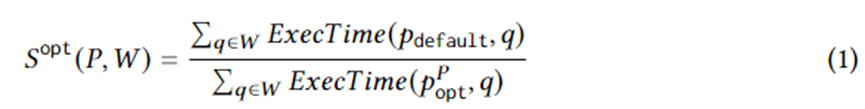
À cette fin, cet article propose Row Count Evolution (RCE), un algorithme qui génère de nouveaux plans en perturbant aléatoirement l'estimation de cardinalité de l'optimiseur. Il génère une série de plans pour chaque instance de requête, combinés en un ensemble de plans candidats pour l'ensemble de la charge de travail. L’idée derrière cet algorithme est qu’une estimation incorrecte de la base est la principale raison du sous-optimisme de l’optimiseur. Dans le même temps, l’étape de génération du plan candidat n’a pas besoin de trouver un plan unique (quasi) optimal spécifique pour chaque instance de requête, mais doit uniquement inclure le plan (quasi) optimal.
L'algorithme RCE génère en permanence de nouveaux plans par itération. Premièrement, le plan d'itération initial est le plan généré par l'optimiseur. Pour construire les itérations suivantes, un échantillonnage aléatoire uniforme à partir du plan de génération précédent est d'abord requis. Pour chaque plan échantillonné, perturbez (modifiez) la cardinalité de son sous-plan de jointure.
La méthode de perturbation consiste à échantillonner aléatoirement dans l'intervalle exponentiel de sa cardinalité estimée actuelle. La cardinalité perturbée est transmise à l'optimiseur pour générer le plan optimal correspondant. Répétez chaque plan N fois pour générer de nombreux plans d'exécution, parmi lesquels les plans d'exécution qui ne sont pas apparus sont conservés comme plan de génération suivante, et le processus ci-dessus est répété.
Nous donnons un exemple spécifique pour illustrer visuellement l'algorithme ci-dessus, comme le montre la figure ci-dessous. Tout d'abord, le plan de base est le meilleur plan sélectionné par l'optimiseur. Il comporte deux sous-plans de jointure, A joint B et C joint D. Leurs bases estimées sont respectivement 40 et 17.
Ensuite, des ensembles de perturbations sont générés pour les deux sous-plans de jointure à partir de la plage d'intervalles exponentiels 10-1~101, qui sont respectivement [4,40,400] et [1,17,170]. Des échantillons aléatoires sont prélevés dans l'ensemble de perturbations et transmis à l'optimiseur pour la sélection du plan. Le plan 1 est le nouveau plan sélectionné par l'optimiseur lorsque la cardinalité est respectivement de 400 et 17. Répétés N fois, les plans C1 sont finalement générés comme génération suivante. Ensuite, échantillonnez-en des plans S et répétez le processus ci-dessus pour chaque plan afin de former le plan de 2e génération.
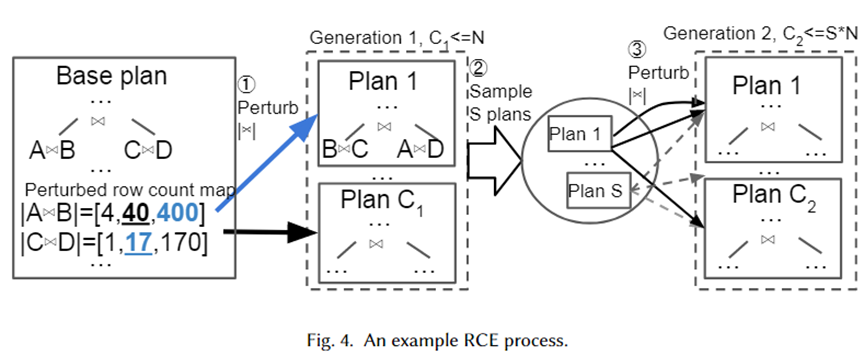
La raison pour laquelle les auteurs ont adopté une plage d'intervalles exponentiels comme ensemble de perturbations est de s'adapter à la distribution de l'erreur d'estimation de cardinalité de l'optimiseur. L’algorithme ci-dessus montre que tant que le nombre de perturbations est suffisamment grand, beaucoup de cardinalité et les plans correspondants seront générés. De cette façon, lorsqu'une instance de requête arrive, notre ensemble de plans doit contenir un plan proche de la véritable cardinalité, qui peut être considéré comme le plan (presque) optimal pour l'instance.
Collecte de données de formation
Après avoir généré l'ensemble de plans candidats, chaque plan est exécuté sur la charge de travail, et des données de temps d'exécution ont été générées pour une prédiction de plan optimale supervisée. L'utilisation des données d'exécution réelles plutôt que du coût estimé par l'optimiseur peut éviter les limitations causées par la sous-optimalité de l'optimiseur. Le processus d'exécution est parallélisable. Cependant, l’exécution de tous les plans représente une dépense importante. Par conséquent, les auteurs proposent deux stratégies pour réduire le gaspillage de ressources causé par une exécution sous-optimale inutile d’un plan.
Délais d'attente adaptatifs et réorganisation de l'exécution du plan, délais d'attente adaptatifs et réorganisation de l'exécution du plan. Les auteurs utilisent un mécanisme de délai d'attente pour limiter l'exécution de plans sous-optimaux. Pour chaque instance de requête, lors de l'exécution de chaque plan, le temps d'exécution minimum actuel peut être enregistré.
Une fois que le temps d'exécution d'un plan dépasse une certaine plage du temps d'exécution minimum, il ne peut plus être exécuté car ce n'est certainement pas le plan d'exécution optimal. Dans le même temps, le temps d'exécution minimum est constamment mis à jour. De plus, l'exécution de plans de requête par ordre croissant de temps d'exécution en fonction de l'exécution de chaque plan sur d'autres instances de requête peut être utilisée comme heuristique pour accélérer le mécanisme de délai d'attente.
Plan en ligne couvrant la taille, plan en ligne défini pour la taille. Une fois que tous les plans ont été exécutés pour les N premières instances de requête, ils sont élagués en K plans à l’aide du problème Set Cover. La collecte de données ultérieure et la formation du modèle utilisent ces plans K. Le problème Set Cover est défini comme indiqué ci-dessous.
Dans le contexte de cet article, représente toutes les instances de requête, qui peuvent être représentées sous forme de plans différents, chaque plan étant un plan quasi optimal pour une instance de requête. Par conséquent, le problème peut être formulé en utilisant le plus petit ensemble de plans possible pour fournir une quasi-optimalité à toutes les instances de requête. Le problème est NP, l’auteur utilise donc un algorithme glouton pour le résoudre.

Prédiction robuste du meilleur plan
Après avoir collecté des données de formation sur le temps d'exécution réel de l'ensemble de plans candidats, l'apprentissage automatique supervisé est utilisé pour prédire le meilleur plan pour n'importe quelle instance de requête. L’objectif de formation peut être logiquement exprimé par l’équation suivante. où représente le meilleur plan choisi par le modèle pour l'instance de requête. La signification de cette équation est l'accélération résultant du plan choisi par le modèle par rapport au plan choisi par l'optimiseur. Sa limite supérieure est l'équation 1. En d’autres termes, le modèle doit capturer autant que possible l’accélération apportée par les plans candidats générés par le RCE.
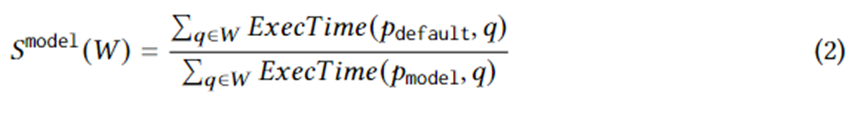
La structure du modèle adopte un réseau neuronal avancé et applique les derniers progrès en matière d'incertitude d'apprentissage automatique, à savoir les processus gaussiens neuronaux normalisés spectraux (SNGP). Le combiner dans le réseau neuronal peut améliorer la convergence du modèle et en même temps permettre au réseau neuronal de générer l'incertitude de prédiction. Lorsque l'incertitude est supérieure à un seuil, le travail de prédiction du plan est renvoyé à l'optimiseur qui détermine le meilleur plan.
Le modèle est caractérisé à l'aide des valeurs réelles de chaque paramètre. Afin de saisir les valeurs réelles des paramètres dans le réseau neuronal, un certain prétraitement est nécessaire, en particulier pour les données de type chaîne. Pour les données de type chaîne, l'auteur utilise un vocabulaire de taille fixe et des compartiments qui ne sont pas dans le vocabulaire pour les représenter comme un vecteur one-hot, et ajoute une couche d'intégration pour apprendre l'incorporation du vecteur one-hot, puis être capable de gérer des données de type chaîne.
Effet expérimental
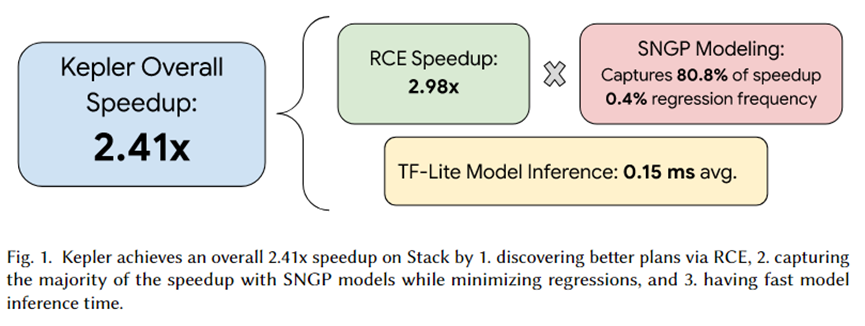
L'auteur de cet article a intégré Kepler dans PostgreSQL et a organisé une série d'expériences. Le résumé de l'expérience est présenté dans la figure ci-dessus. L'effet d'accélération total apporté par Kepler est de 2,41 fois. Parmi eux, l'ensemble de plans candidats générés par RCE peut entraîner une accélération d'environ 2,92 fois, 80,8 % sont capturés par le modèle de prédiction SNGP et seulement 0,4 % de la régression est réalisée. De plus, le temps d’inférence du modèle n’est que de 0,15 ms en moyenne.
Résumer
Cet article propose Kepler, une approche basée sur l'apprentissage qui accélère de manière robuste les requêtes paramétrées. Il génère un plan candidat défini via l'algorithme Row Count Evolution (RCE), l'exécute sur la charge de travail pour obtenir le temps d'exécution réel et utilise le temps d'exécution réel pour entraîner le modèle de prédiction.
Le modèle de prédiction adopte les processus gaussiens neuronaux normalisés spectraux (SNGP), la dernière avancée en matière d'estimation de l'incertitude de l'apprentissage automatique, pour améliorer la convergence tout en produisant l'incertitude de la prédiction. Sur la base de cette incertitude, il est sélectionné si le modèle ou l'optimiseur complète la prédiction. planifier la prédiction. Des expériences ont prouvé que le RCE peut apporter des effets d'accélération élevés, et SNGP peut capturer autant que possible les effets d'accélération apportés par le RCE tout en évitant la régression. Par conséquent, les objectifs de PQO et QO sont atteints en même temps, c'est-à-dire que tout en réduisant le temps de planification des requêtes, les performances d'exécution des requêtes sont améliorées.
J'ai décidé d'abandonner les logiciels industriels open source. OGG 1.0 est sorti, Huawei a contribué à tout le code source. Ubuntu 24.04 LTS a été officiellement publié. L'équipe de Google Python Foundation a été tuée par la "montagne de merde de code" . ". Fedora Linux 40 a été officiellement lancé. Une société de jeux bien connue a publié de nouvelles réglementations : les cadeaux de mariage des employés ne doivent pas dépasser 100 000 yuans. China Unicom lance la première version chinoise Llama3 8B au monde du modèle open source. Pinduoduo est condamné à compenser 5 millions de yuans pour concurrence déloyale Méthode de saisie dans le cloud domestique - seul Huawei n'a aucun problème de sécurité de téléchargement de données dans le cloud.