
1. Introduction générale
Les requêtes paramétrées font référence à un type de requête qui a le même modèle et ne diffère que par les valeurs des paramètres de liaison de prédicat. Elles sont largement utilisées dans les applications de bases de données modernes. Ils effectuent des actions à plusieurs reprises, ce qui offre des opportunités d'optimisation des performances.
Cependant, la méthode actuelle de gestion des requêtes paramétrées dans de nombreuses bases de données commerciales optimise uniquement la première instance de requête (ou instance spécifiée par l'utilisateur) de la requête, met en cache son meilleur plan et le réutilise pour les instances de requête ultérieures. Bien que cette méthode optimise le temps de minimisation, en raison de différents plans optimaux pour différentes instances de requête, l'exécution du plan mis en cache peut être arbitrairement sous-optimale, ce qui n'est pas applicable dans les scénarios d'application réels.
La plupart des méthodes d'optimisation traditionnelles nécessitent de nombreuses hypothèses concernant l'optimiseur de requêtes, mais ces hypothèses ne correspondent souvent pas aux scénarios d'application réels. Heureusement, avec l’essor de l’apprentissage automatique, les problèmes ci-dessus peuvent être résolus efficacement. Ce numéro présentera en détail deux articles publiés dans VLDB2022 et SIGMOD2023 :
Article 1 : 《Exploiter les journaux de requêtes et l’apprentissage automatique pour l’optimisation des requêtes paramétriques》
论文 2:《Kepler : apprentissage robuste pour une optimisation plus rapide des requêtes paramétriques》
2. Essence du document 1
« Tirer parti des journaux de requêtes et de l'apprentissage automatique pour l'optimisation paramétrique des requêtes » Cet article divise l'optimisation des requêtes paramétrées en deux problèmes :
(1) PopulateCache : met en cache K plans pour un modèle de requête
(2) getPlan : pour chaque instance de requête, sélectionne le meilleur plan parmi ; les plans mis en cache.
L'architecture algorithmique de cet article est présentée dans la figure ci-dessous. Il est principalement divisé en deux modules : PopulateCache et le module getPlan.
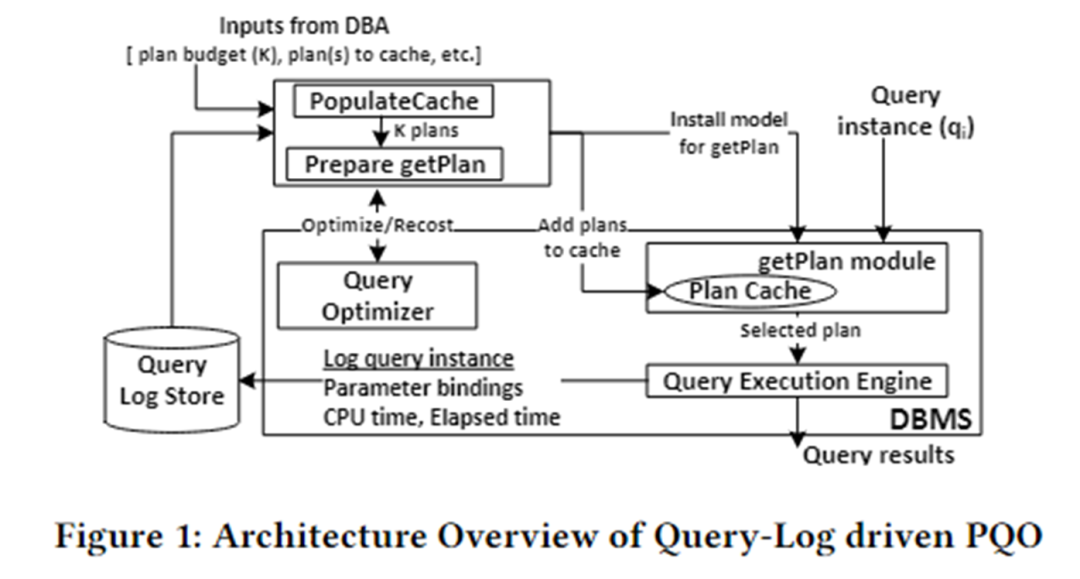
PopulateCache utilise les informations du journal des requêtes pour mettre en cache les plans K pour toutes les instances de requête. Le module getPlan collecte d'abord des informations sur les coûts entre les plans K et les instances de requête en interagissant avec l'optimiseur, et utilise ces informations pour entraîner le modèle d'apprentissage automatique. Déployez le modèle formé dans le SGBD. Lorsqu'une instance de requête arrive, le meilleur plan pour cette instance peut être rapidement prédit.
Remplir le cache
Le module PolulateCache est chargé d'identifier un ensemble de plans de cache pour une requête paramétrée donnée. La phase de recherche utilise deux API d'optimisation :
- Appel de l'optimiseur : renvoie le plan sélectionné par l'optimiseur pour une instance de requête ;
- Appel de recost : renvoie le coût estimé par l'optimiseur pour une instance de requête et le plan correspondant ;
Le déroulement de l'algorithme est le suivant :
- Phase de collecte de plans : appel de l'optimiseur pour collecter les plans candidats pour n instances de requête dans le journal des requêtes ;
- Phase plan-recost : pour chaque instance de requête et chaque plan candidat, appelez l'appel recost pour former une matrice plan-recost ;
- Phase d'identification de K-set : adopte un algorithme glouton et utilise la matrice plan-recost pour mettre en cache K plans afin de minimiser la sous-optimalité.
obtenirPlan
Le module getPlan est chargé de sélectionner l'un des K plans mis en cache à exécuter pour une instance de requête donnée. L'algorithme getPlan peut considérer deux objectifs : minimiser le coût estimé par l'optimiseur ou minimiser le coût d'exécution réel parmi K plans de cache.
Considérez l'objectif 1 : utiliser la matrice plan-recoût pour former un modèle de ML supervisé et envisager la classification et la régression.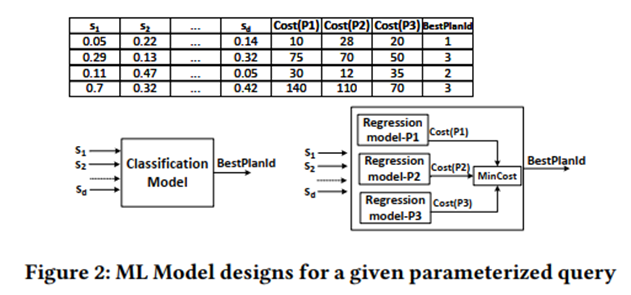
Considérez l'objectif 2 : Utiliser un modèle de formation par apprentissage par renforcement basé sur Multi-Armed Bandit.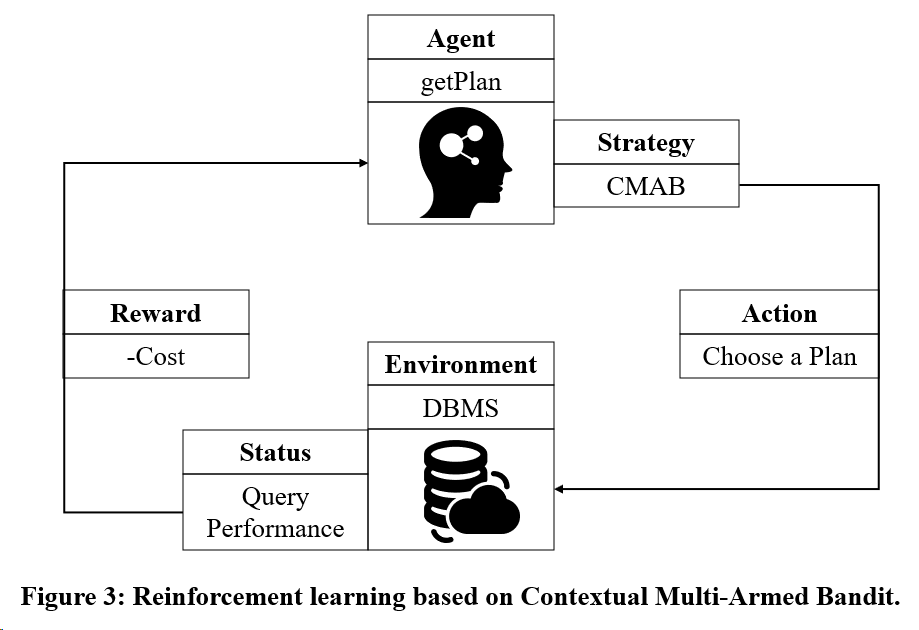
3. Essence du document 2
"Kepler : apprentissage robuste pour une optimisation paramétrique des requêtes plus rapide" Cet article propose une méthode d'optimisation des requêtes paramétriques de bout en bout, basée sur l'apprentissage, qui vise à réduire le temps d'optimisation des requêtes et à améliorer les performances d'exécution des requêtes.
L'architecture de l'algorithme est la suivante. Kepler divise également le problème en deux parties : la génération de plans et la prédiction de plans basée sur l'apprentissage. Il est principalement divisé en trois étapes : stratégie de génération de plan, phase d'exécution des requêtes de formation et modèle de réseau neuronal robuste.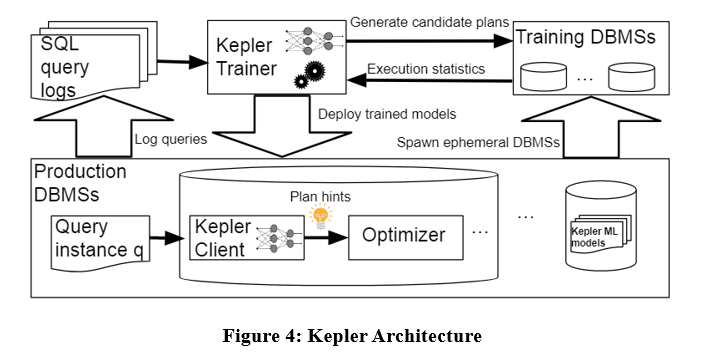
Comme le montre la figure ci-dessus, saisissez l'instance de requête dans le journal de requête dans Kepler Trainer. Kepler Trainer génère d'abord un plan candidat, puis collecte les informations d'exécution liées au plan candidat en tant que données d'entraînement pour entraîner le modèle d'apprentissage automatique. le modèle est déployé dans le SGBD. Lorsqu'une instance de requête arrive, Kepler Client est utilisé pour prédire le meilleur plan et l'exécuter.
Évolution du nombre de lignes
Cet article propose un algorithme de génération de plans candidats appelé Row Count Evolution (RCE), qui génère des plans candidats en perturbant l'estimation de cardinalité de l'optimiseur.
L'idée de cet algorithme vient de : une estimation incorrecte de la cardinalité est la principale cause de la sous-optimalité de l'optimiseur, et l'étape de génération du plan candidat n'a besoin que de contenir le plan optimal d'une instance, plutôt que de sélectionner un seul plan optimal.
L'algorithme RCE génère d'abord le plan optimal pour l'instance de requête, puis perturbe la cardinalité de jointure de ses sous-plans dans la plage d'intervalles exponentiels, le répète plusieurs fois et effectue plusieurs itérations, et enfin utilise tous les plans générés comme plans candidats. Des exemples spécifiques sont les suivants :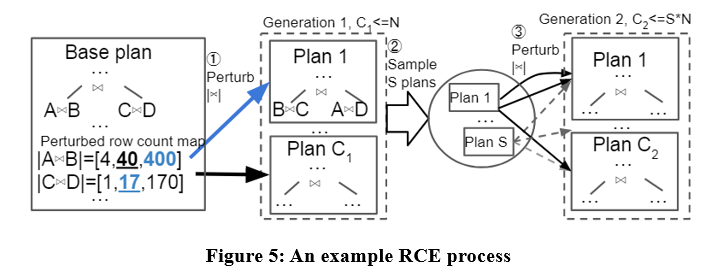
Avec l'algorithme RCE, les plans candidats générés peuvent être meilleurs que le plan produit par l'optimiseur. Parce que l'optimiseur peut avoir des erreurs d'estimation de cardinalité, et RCE peut produire un plan optimal correspondant à la cardinalité correcte en perturbant continuellement l'estimation de cardinalité.
Collecte de données de formation
Après avoir obtenu l'ensemble de plans candidats, chaque plan est exécuté sur la charge de travail pour chaque instance de requête, et le temps d'exécution réel est collecté pour l'entraînement du modèle de prédiction de plan optimal supervisé. Le processus ci-dessus est relativement lourd.Cet article propose certains mécanismes pour accélérer la collecte des données d'entraînement, tels que l'exécution parallèle, un mécanisme de délai d'attente adaptatif, etc.
Prédiction robuste du meilleur plan
Les données d'exécution réelles résultantes sont utilisées pour entraîner un réseau neuronal afin de prédire le plan optimal pour chaque instance de requête. Le réseau neuronal utilisé est un processus neuronal gaussien spectralement normalisé. Ce modèle garantit la stabilité du réseau et la convergence de l'entraînement, et peut fournir des estimations d'incertitude pour les prédictions. Lorsque l'estimation de l'incertitude est supérieure à un certain seuil, il appartient à l'optimiseur de sélectionner un plan d'exécution. La régression des performances est évitée dans une certaine mesure.
4. Résumé
Les deux articles ci-dessus dissocient les requêtes paramétrées en populateCache et getPlan. La comparaison entre les deux est présentée dans le tableau ci-dessous.
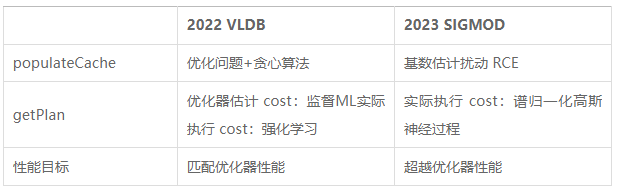
Bien que les algorithmes basés sur des modèles d'apprentissage automatique fonctionnent bien dans la prédiction de plans, leur processus de collecte de données de formation est coûteux et les modèles ne sont pas faciles à généraliser et à mettre à jour. Par conséquent, les méthodes d’optimisation de requêtes paramétrées existantes peuvent encore être améliorées.
本文图示来源: 1)Kapil Vaidya & Anshuman Dutt, 《Exploiter les journaux de requêtes et l'apprentissage automatique pour l'optimisation des requêtes paramétriques》, 2022 VLDB,https://dl.acm.org/doi/pdf/10.14778/3494124.3494126 2)LYRIC DOSHI & VINCENT ZHUANG, 《Kepler : apprentissage robuste pour une optimisation plus rapide des requêtes paramétriques》, 2023 SIGMOD,https://dl.acm.org/doi/pdf/10.1145/3588963
J'ai décidé d'abandonner les logiciels industriels open source. OGG 1.0 est sorti, Huawei a contribué à tout le code source. Ubuntu 24.04 LTS a été officiellement publié. L'équipe de Google Python Foundation a été tuée par la "montagne de merde de code" . ". Fedora Linux 40 a été officiellement lancé. Une société de jeux bien connue a publié de nouvelles réglementations : les cadeaux de mariage des employés ne doivent pas dépasser 100 000 yuans. China Unicom lance la première version chinoise Llama3 8B au monde du modèle open source. Pinduoduo est condamné à compenser 5 millions de yuans pour concurrence déloyale Méthode de saisie dans le cloud domestique - seul Huawei n'a aucun problème de sécurité de téléchargement de données dans le cloud.