
Cet article est partagé par la communauté Huawei Cloud « Statistiques et analyse de texte Python des bases à avancées » par Lemony Hug.
À l’ère numérique d’aujourd’hui, les données textuelles sont omniprésentes et contiennent une multitude d’informations, des publications sur les réseaux sociaux aux articles de presse en passant par les articles universitaires. L'analyse statistique est une exigence courante pour le traitement de ces données textuelles, et Python, en tant que langage de programmation puissant et facile à apprendre, nous offre une multitude d'outils et de bibliothèques pour mettre en œuvre l'analyse statistique des données textuelles. Cet article expliquera comment utiliser Python pour implémenter des statistiques de texte en anglais, y compris des statistiques de fréquence de mots, des statistiques de vocabulaire et une analyse des sentiments du texte.
statistiques de fréquence des mots
Le comptage de la fréquence des mots est l'une des tâches les plus élémentaires de l'analyse de texte. Il existe de nombreuses façons d'implémenter des statistiques de fréquence de mots en Python, la suivante est l'une des méthodes de base :
def count_words(texte) :
# Supprimez la ponctuation du texte et convertissez-la en minuscules
texte = texte.inférieur()
pour char dans '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~' :
texte = texte.replace(char, ' ')
# Divisez le texte en une liste de mots
mots = text.split()
# Créez un dictionnaire vide pour stocker le nombre de mots
nombre_mots = {}
# Parcourez chaque mot et mettez à jour le décompte dans le dictionnaire
pour mot en mots :
si mot dans word_count :
nombre_mot[mot] += 1
autre:
nombre_mot[mot] = 1
retourner word_count
# Code d'essai
si __name__ == "__main__":
text = "Ceci est un exemple de texte. Nous utiliserons ce texte pour compter les occurrences de chaque mot."
word_count = count_words(texte)
pour word, comptez dans word_count.items() :
print(f"{mot} : {compte}")
Ce code définit une fonction qui accepte une chaîne de texte comme paramètre et renvoie un dictionnaire contenant chaque mot du texte et le nombre de fois où il apparaît. Voici une analyse ligne par ligne du code : count_words(text)
def count_words(text):: Définit une fonction qui accepte un paramètre , la chaîne de texte à traiter. count_words text
text = text.lower(): convertit les chaînes de texte en lettres minuscules, ce qui rend les statistiques de mots indépendantes de la casse.
for char in '!"#$%&\'()*+,-./:;<=>?@[\\]^_{|}~':` : Il s'agit d'une boucle qui parcourt tous les signes de ponctuation du texte.
text = text.replace(char, ' '): remplace chaque signe de ponctuation du texte par un espace, ce qui supprime le signe de ponctuation du texte.
words = text.split(): divisez la chaîne de texte traitée en une liste de mots par espaces.
word_count = {}: Crée un dictionnaire vide qui stocke le nombre de mots, où les clés sont des mots et les valeurs sont le nombre de fois que ce mot apparaît dans le texte.
for word in words:: Parcourez chaque mot de la liste de mots.
if word in word_count:: Vérifiez si le mot actuel existe déjà dans le dictionnaire.
word_count[word] += 1: Si le mot existe déjà dans le dictionnaire, ajoutez 1 à son nombre d'occurrences.
else:: Si le mot n'est pas dans le dictionnaire, exécutez le code suivant.
word_count[word] = 1: ajoute un nouveau mot au dictionnaire et définit son nombre d'occurrences sur 1.
return word_count: Renvoie un dictionnaire contenant le nombre de mots.
if __name__ == "__main__":: Vérifiez si le script s'exécute en tant que programme principal.
text = "This is a sample text. We will use this text to count the occurrences of each word.": Définit un texte de test.
word_count = count_words(text): Appelez la fonction en passant le texte de test en paramètre et enregistrez le résultat dans une variable. count_words word_count
for word, count in word_count.items(): : Parcourez chaque paire clé-valeur du dictionnaire. word_count
print(f"{word}: {count}"):Imprimez chaque mot et son nombre d'occurrences.
Les résultats en cours d'exécution sont les suivants
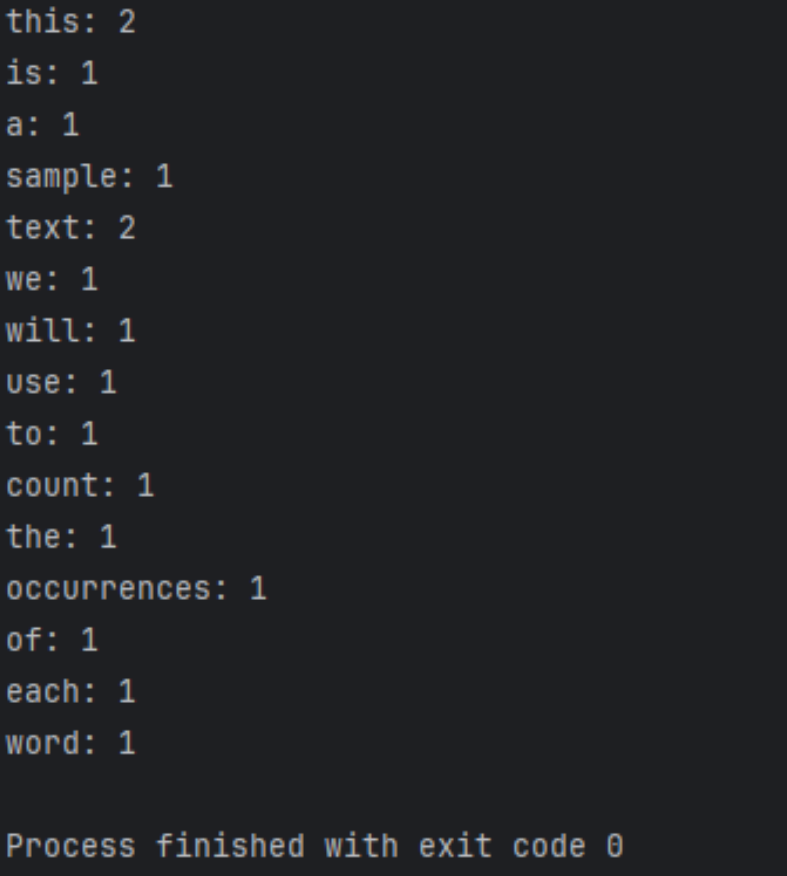
Poursuite de l'optimisation et de l'expansion
importer re
à partir du compteur d'importation de collections
def count_words(texte) :
# Divisez le texte en une liste de mots (y compris les mots avec trait d'union) à l'aide d'expressions régulières
mots = re.findall(r'\b\w+(?:-\w+)*\b', text.lower())
# Utilisez Counter pour compter rapidement le nombre d'occurrences de mots
word_count = Compteur (mots)
retourner word_count
# Code d'essai
si __name__ == "__main__":
text = "Ceci est un exemple de texte. Nous utiliserons ce texte pour compter les occurrences de chaque mot."
word_count = count_words(texte)
pour word, comptez dans word_count.items() :
print(f"{mot} : {compte}")
Ce code diffère de l'exemple précédent des manières suivantes :
- Les expressions régulières sont utilisées pour diviser le texte en listes de mots. Cette expression régulière correspond à des mots, y compris des mots avec trait d'union (comme « high-tech »).
re.findall()\b\w+(?:-\w+)*\b - Les classes de la bibliothèque standard Python sont utilisées pour le comptage de mots, ce qui est plus efficace et le code est plus propre.
Counter
Cette implémentation est plus avancée, plus robuste et gère des cas plus particuliers tels que les mots avec trait d'union.
Les résultats en cours d'exécution sont les suivants
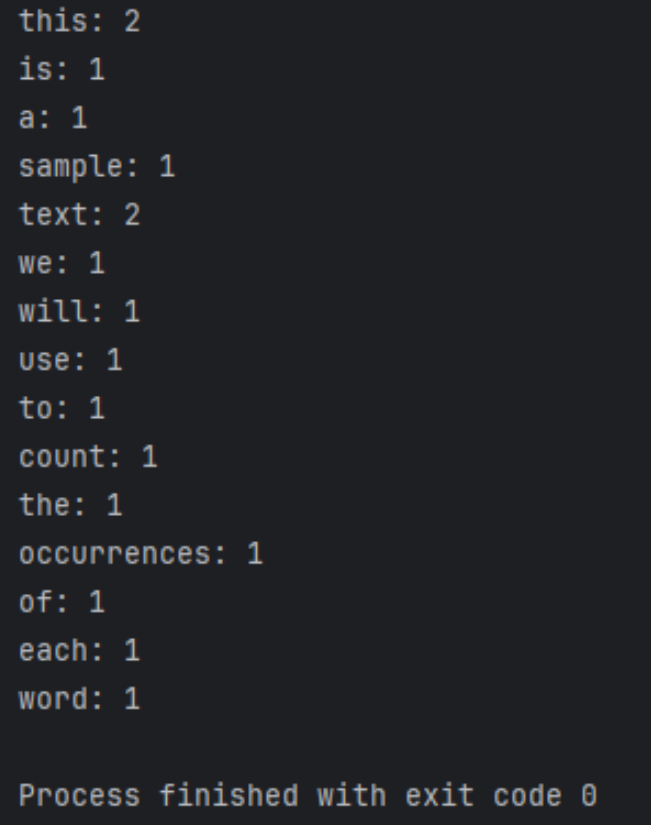
Prétraitement du texte
Avant l'analyse du texte, un prétraitement du texte est généralement requis, y compris la suppression de la ponctuation, le traitement de la casse, la lemmatisation et la radicalisation. Cela peut rendre les données textuelles plus standardisées et plus précises.
Utiliser des modèles plus avancés
En plus des méthodes statistiques de base, nous pouvons également utiliser des modèles d'apprentissage automatique et d'apprentissage profond pour l'analyse de texte, tels que la classification de texte, la reconnaissance d'entités nommées et l'analyse des sentiments. Il existe de nombreuses bibliothèques d'apprentissage automatique puissantes en Python, telles que Scikit-learn et TensorFlow, qui peuvent nous aider à créer et à entraîner ces modèles.
Gérer des données à grande échelle
Face à des données textuelles à grande échelle, nous devrons peut-être envisager des technologies telles que le traitement parallèle et l’informatique distribuée pour améliorer l’efficacité du traitement et réduire les coûts informatiques. Il existe certaines bibliothèques et frameworks en Python qui peuvent nous aider à réaliser ces fonctions, comme Dask et Apache Spark.
Combiner avec d'autres sources de données
En plus des données textuelles, nous pouvons également combiner d'autres sources de données, telles que des données d'images, des données de séries chronologiques et des données géospatiales, pour effectuer une analyse plus complète et multidimensionnelle. Il existe de nombreux outils de traitement et de visualisation de données en Python qui peuvent nous aider à traiter et analyser ces données.
Résumer
Cet article fournit une introduction détaillée à la façon d'utiliser Python pour implémenter des statistiques de texte en anglais, notamment des statistiques de fréquence de mots, des statistiques de vocabulaire et une analyse des sentiments du texte. Voici un résumé :
Statistiques de fréquence des mots :
- Grâce aux fonctions Python
count_words(text), le texte est traité et la fréquence des occurrences de mots est comptée. - Le prétraitement du texte comprend la conversion du texte en minuscules, la suppression de la ponctuation, etc.
- Utilisez une boucle pour parcourir les mots du texte et utilisez un dictionnaire pour stocker les mots et leurs occurrences.
Poursuite de l'optimisation et de l'expansion :
- Introduisez des expressions régulières et
Counterdes classes pour rendre votre code plus efficace et plus robuste. - Utilisez des expressions régulières pour diviser le texte en listes de mots, y compris la gestion des mots avec trait d'union.
- L'utilisation
Counterde classes pour le comptage de mots simplifie le code.
Prétraitement du texte :
Le prétraitement du texte est une étape importante dans l'analyse du texte, y compris la suppression de la ponctuation, le traitement de la casse, la lemmatisation et la radicalisation, etc., pour normaliser les données textuelles.
Utilisez des modèles plus avancés :
Les possibilités d'utilisation de modèles d'apprentissage automatique et d'apprentissage profond pour l'analyse de texte, telles que la classification de texte, la reconnaissance d'entités nommées et l'analyse des sentiments, sont présentées.
Gérer des données à grande échelle :
Des considérations techniques lors du traitement de données textuelles à grande échelle sont mentionnées, notamment le traitement parallèle et l'informatique distribuée pour améliorer l'efficacité et réduire les coûts.
Combiné avec d'autres sources de données :
La possibilité de combiner d'autres sources de données pour une analyse plus complète et multidimensionnelle est explorée, telles que les données d'images, les données de séries chronologiques et les données géospatiales.
Résumer :
Le contenu présenté dans cet article est souligné, ainsi que les perspectives de travaux futurs, encourageant des recherches et des explorations plus approfondies pour s'adapter à des tâches d'analyse de données textuelles plus complexes et plus diversifiées.
En étudiant cet article, les lecteurs peuvent maîtriser les méthodes de base d'utilisation de Python pour les statistiques de texte en anglais et comprendre comment optimiser et développer davantage ces méthodes pour faire face à des tâches d'analyse de texte plus complexes.
Cliquez pour suivre et découvrir les nouvelles technologies de Huawei Cloud dès que possible~