

Avec l'exploration approfondie des applications de modèles à grande échelle, la technologie de génération augmentée de récupération a reçu une large attention et a été appliquée dans divers scénarios, tels que les questions et réponses sur les bases de connaissances, les conseillers juridiques, les assistants d'apprentissage, les robots de sites Web, etc.
Cependant, de nombreux amis ne comprennent pas clairement la relation et les principes techniques entre les bases de données vectorielles et RAG. Cet article vous donnera une compréhension approfondie de la nouvelle base de données vectorielles à l'ère RAG.
01.
La large gamme d’applications de RAG et ses avantages uniques
Un cadre RAG typique peut être divisé en deux parties : Récupérateur et Générateur. Le processus de récupération comprend la segmentation des données (telles que les documents), l'intégration de vecteurs (Embedding) et la création d'index (Chunks Vectors), puis les résultats pertinents sont rappelés via la récupération de vecteurs. , et le processus de génération utilise une invite améliorée en fonction des résultats de récupération (contexte) pour activer LLM afin de générer des réponses (résultat).
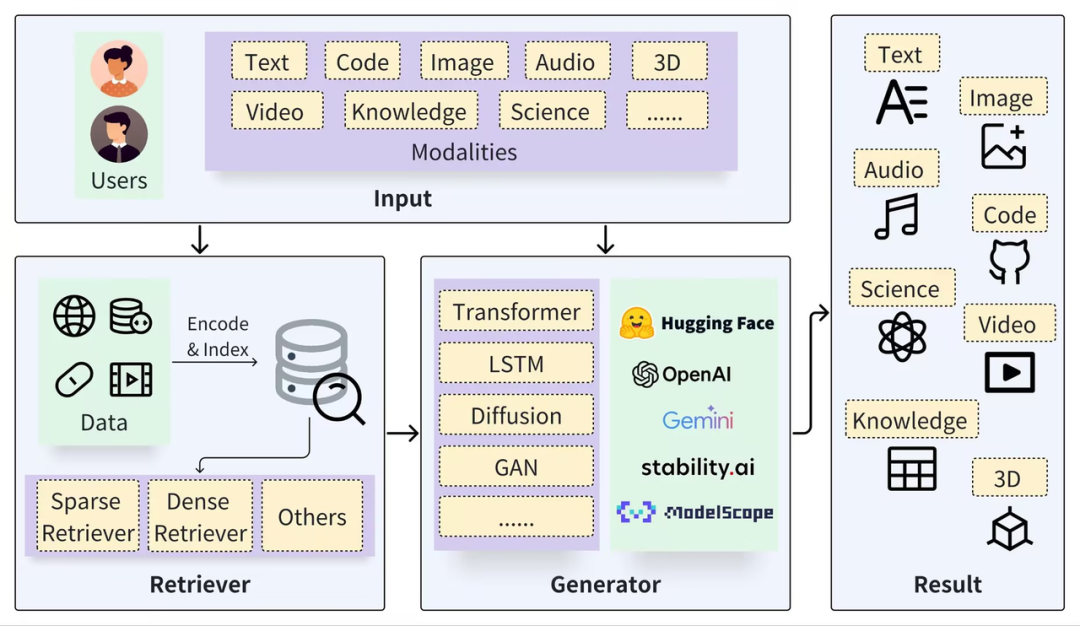
https://arxiv.org/pdf/2402.19473
La clé de la technologie RAG est qu’elle combine le meilleur des deux approches : un système de récupération qui fournit des faits et des données spécifiques et pertinents, et un modèle génératif qui construit de manière flexible des réponses et intègre un contexte et des informations plus larges. Cette combinaison rend le modèle RAG très efficace pour traiter des requêtes complexes et générer des réponses riches en informations, ce qui est très utile dans les systèmes de questions-réponses, les systèmes de dialogue et d'autres applications qui nécessitent la compréhension et la génération d'un langage naturel. Par rapport aux modèles natifs à grande échelle, le couplage avec RAG peut constituer des avantages complémentaires naturels :
Évitez les problèmes d'« hallucination » : RAG aide les grands modèles à répondre aux questions en récupérant des informations externes en entrée. Cette méthode peut réduire considérablement les questions sur les informations générées inexactes et augmenter la traçabilité des réponses.
Confidentialité et sécurité des données : RAG peut utiliser la base de connaissances comme pièce jointe externe pour gérer les données privées d'une entreprise ou d'une institution afin d'éviter toute fuite de données de manière incontrôlable après l'apprentissage du modèle.
Nature des informations en temps réel : RAG permet la récupération en temps réel d'informations à partir de sources de données externes, de sorte que les connaissances les plus récentes et spécifiques au domaine puissent être obtenues et que le problème de l'actualité des connaissances puisse être résolu.
Bien que la recherche de pointe sur les modèles à grande échelle vise également à résoudre les problèmes ci-dessus, tels que le réglage fin basé sur des données privées et l'amélioration des capacités de traitement de texte long du modèle lui-même, ces études contribuent à promouvoir l'avancement des modèles à grande échelle. technologie des modèles réduits. Cependant, dans des scénarios plus généraux, RAG reste un choix stable, fiable et rentable, principalement parce que RAG présente les avantages suivants :
Modèle boîte blanche : par rapport à l'effet "boîte noire" du réglage fin et du traitement de texte long, la relation entre les modules RAG est plus claire et plus étroite, ce qui offre en outre une opérabilité et une interprétabilité supérieures dans le réglage des effets, lorsque la qualité et la confiance ; (Certitude) du contenu récupéré et rappelé ne sont pas élevées, le système RAG peut même interdire l'intervention des LLM et répondre directement « ne sait pas » au lieu d'inventer des bêtises.
Coût et vitesse de réponse : RAG présente les avantages d'un temps de formation court et d'un faible coût par rapport aux modèles affinés, par rapport au traitement de texte long, il a une vitesse de réponse plus rapide et un coût d'inférence beaucoup plus faible ; Au stade de la recherche et de l'expérimentation, l'effet et la précision sont les plus attractifs, mais en termes d'industrie et de mise en œuvre industrielle, le coût est un facteur décisif qui ne peut être ignoré.
Gestion des données privées : en dissociant la base de connaissances des grands modèles, RAG fournit non seulement une base pratique sûre et réalisable, mais peut également mieux gérer les connaissances existantes et nouvelles de l'entreprise et résoudre le problème de la dépendance aux connaissances. Un autre aspect connexe est le contrôle d'accès et la gestion des données, qui sont faciles à réaliser pour la base de données de base de RAG, mais difficiles à réaliser pour les grands modèles.
Par conséquent, à mon avis, à mesure que la recherche sur les modèles à grande échelle continue de s’approfondir, la technologie RAG ne sera pas remplacée, au contraire, elle conservera une place importante pendant longtemps. Ceci est principalement dû à sa complémentarité naturelle avec le LLM, qui permet aux applications construites sur RAG de briller dans de nombreux domaines. La clé de l’amélioration du RAG réside d’une part dans l’amélioration des capacités des LLM, et d’autre part elle s’appuie sur diverses améliorations et optimisations de la récupération (Retrieval).
02.
La base des recherches RAG : les bases de données vectorielles
Dans la pratique industrielle, la récupération RAG est généralement étroitement intégrée aux bases de données vectorielles, ce qui a également donné naissance à une solution RAG basée sur ChatGPT + Vector Database + Prompt, appelée pile technologique CVP. Cette solution s'appuie sur des bases de données vectorielles pour récupérer efficacement les informations pertinentes afin d'améliorer les grands modèles de langage (LLM). En convertissant les requêtes générées par les LLM en vecteurs, le système RAG peut localiser rapidement les entrées de connaissances correspondantes dans la base de données vectorielles. Ce mécanisme de récupération permet aux LLM d'utiliser les dernières informations stockées dans la base de données vectorielles lorsqu'ils sont confrontés à des problèmes spécifiques, résolvant ainsi efficacement les problèmes de retard de mise à jour des connaissances et d'illusion inhérents aux LLM.
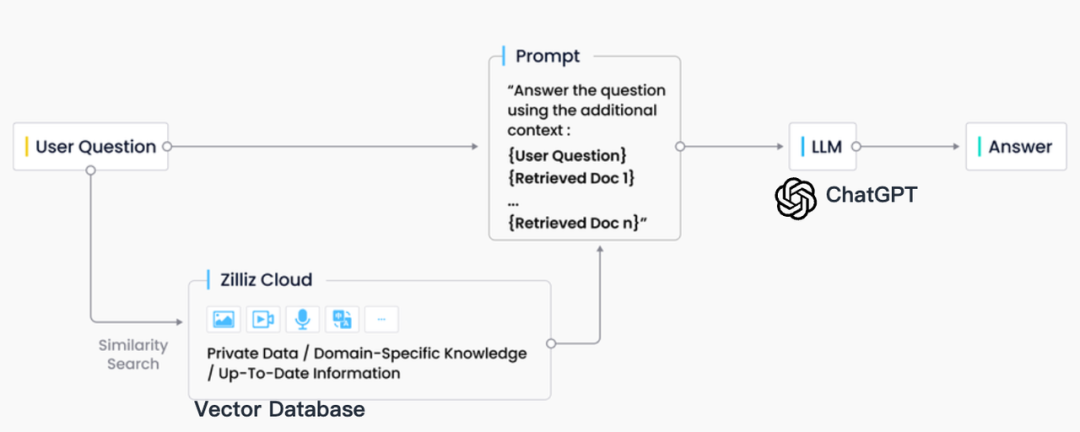
Bien qu'il existe de nombreuses technologies de stockage et de récupération dans le domaine de la recherche d'informations, notamment les moteurs de recherche, les bases de données relationnelles, les bases de données documentaires, etc., les bases de données vectorielles sont devenues le premier choix de l'industrie dans les scénarios RAG. Derrière ce choix se cache l’excellente capacité des bases de données vectorielles à stocker et récupérer efficacement un grand nombre de vecteurs intégrés. Ces vecteurs d'intégration sont générés par des modèles d'apprentissage automatique et sont non seulement capables de caractériser plusieurs types de données tels que le texte et les images, mais également de capturer leurs informations sémantiques approfondies. Dans le système RAG, la tâche de récupération consiste à trouver rapidement et avec précision les informations qui correspondent le mieux à la sémantique de la requête d'entrée, et les bases de données vectorielles se distinguent par leurs avantages significatifs dans le traitement de données vectorielles de grande dimension et dans l'exécution de recherches de similarité rapides.
Ce qui suit est une comparaison horizontale des bases de données vectorielles représentées par la récupération vectorielle avec d'autres options techniques, ainsi qu'une analyse des facteurs clés qui en font un choix courant dans les scénarios RAG :
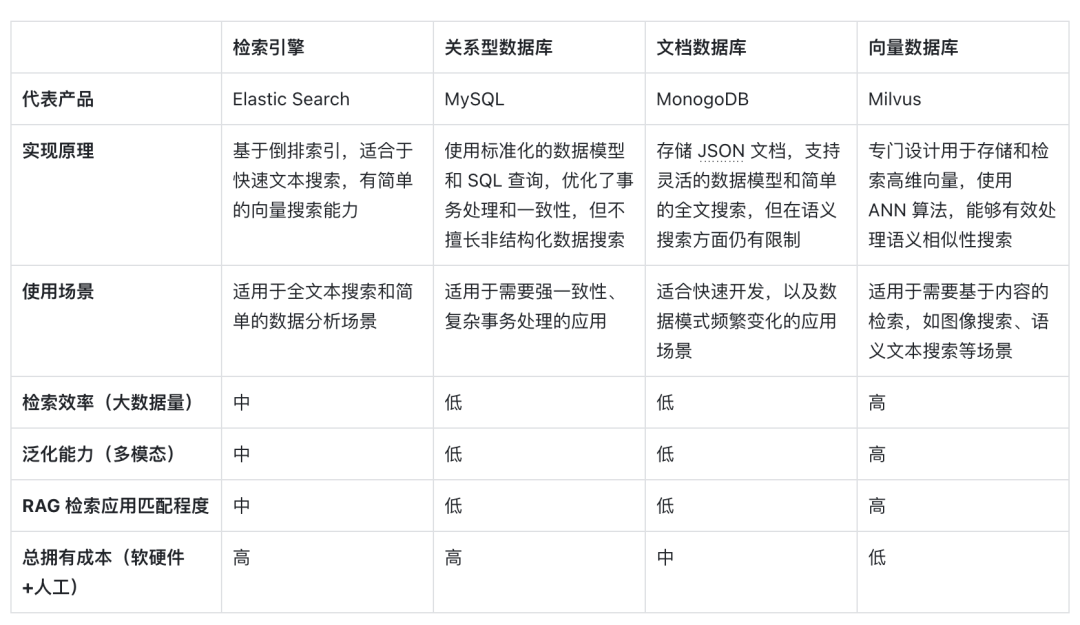
Tout d'abord, en termes de principes de mise en œuvre , les vecteurs sont la forme d'encodage de la signification sémantique du modèle. Les bases de données vectorielles peuvent mieux comprendre le contenu sémantique des requêtes car elles exploitent la capacité des modèles d'apprentissage profond à encoder la signification du texte, et pas seulement la correspondance de mots clés. . Grâce au développement des modèles d'IA, la précision sémantique qui la sous-tend s'améliore également régulièrement. L'utilisation de la similarité de distance vectorielle pour exprimer la similarité sémantique est devenue la forme courante de la PNL. Par conséquent, l'intégration idéographique est devenue le premier choix pour le traitement des supports d'information.
Deuxièmement, en termes d' efficacité de récupération , puisque les informations peuvent être exprimées sous forme de vecteurs de grande dimension, des méthodes spéciales d'optimisation d'index et de quantification peuvent être ajoutées aux vecteurs, ce qui peut considérablement améliorer l'efficacité de la récupération et comprimer les coûts de stockage à mesure que la quantité de données augmente. La base de données vectorielles peut être étendue horizontalement, en maintenant le temps de réponse aux requêtes, ce qui est crucial pour les systèmes RAG qui doivent traiter d'énormes quantités de données. Les bases de données vectorielles sont donc plus efficaces pour traiter des données non structurées à très grande échelle.
En ce qui concerne la dimension de la capacité de généralisation , la plupart des moteurs de recherche traditionnels, des bases de données relationnelles ou documentaires ne peuvent traiter que du texte et ont de faibles capacités de généralisation et d'expansion. Les bases de données vectorielles ne se limitent pas aux données textuelles, mais peuvent également traiter des images, de l'audio et d'autres données non structurées. . type de vecteur d'intégration, ce qui rend le système RAG plus flexible et polyvalent.
Enfin, en termes de coût total de possession , par rapport à d'autres options, les bases de données vectorielles sont plus pratiques à déployer et plus faciles à utiliser. Elles fournissent également des API riches, ce qui les rend faciles à intégrer aux cadres et flux de travail d'apprentissage automatique existants, ce qui les rend populaires. parmi eux. Un favori parmi de nombreux développeurs d’applications RAG.
La récupération de vecteurs est devenue un récupérateur RAG idéal à l'ère des grands modèles en raison de sa capacité de compréhension sémantique, de sa grande efficacité de récupération et de sa prise en charge de la généralisation de plusieurs modalités. Avec le développement ultérieur de l'IA et des modèles d'intégration, ces avantages pourraient devenir plus importants. à l'avenir.
03.
Exigences relatives aux bases de données vectorielles dans les scénarios RAG
虽然向量数据库成为了检索的重要方式,但随着 RAG 应用的深入以及人们对高质量回答的需求,检索引擎依旧面临着诸多挑战。这里以一个最基础的 RAG 构建流程为例:检索器的组成包括了语料的预处理如切分、数据清洗、embedding 入库等,然后是索引的构建和管理,最后是通过 vector search 找到相近的片段提供给 prompt 做增强生成。大多数向量数据库的功能还只落在索引的构建管理和搜索的计算上,进一步则是包含了 embedding 模型的功能。
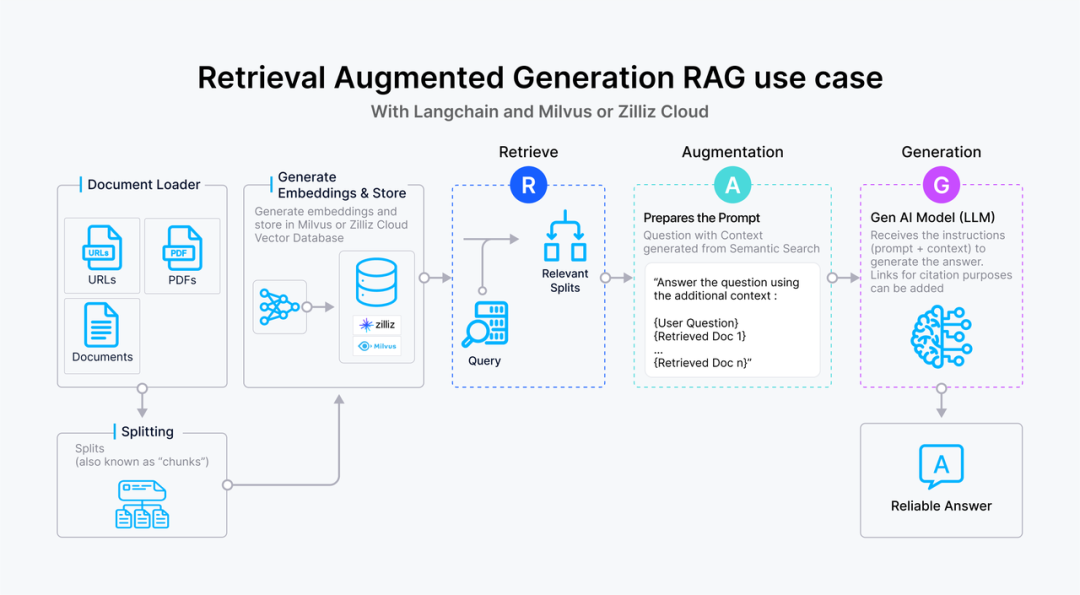
但在更高级的 RAG 场景中,因为召回的质量将直接影响到生成模型的输出质量和相关性,因此作为检索器底座的向量数据库应该更多的对检索质量负责。为了提升检索质量,这里其实有很多工程化的优化手段,如 chunk_size 的选择,切分是否需要 overlap,如何选择 embedding model,是否需要额外的内容标签,是否加入基于词法的检索来做 hybrid search,重排序 reranker 的选择等等,其中有不少工作是可以纳入向量数据库的考量之中。而检索系统对向量数据库的需求可以抽象描述为:
高精度的召回:向量数据库需要能够准确召回与查询语义最相关的文档或信息片段。这要求数据库能够理解和处理高维向量空间中的复杂语义关系,确保召回内容与查询的高度相关性。这里的效果既包括向量检索的数学召回精度也包括嵌入模型的语义精度。
快速响应:为了不影响用户体验,召回操作需要在极短的时间内完成,通常是毫秒级别。这要求向量数据库具备高效的查询处理能力,以快速从大规模数据集中检索和召回信息。此外,随着数据量的增长和查询需求的变化,向量数据库需要能够灵活扩展,以支持更多的数据和更复杂的查询,同时保持召回效果的稳定性和可靠性。
处理多模态数据的能力:随着应用场景的多样化,向量数据库可能需要处理不仅仅是文本,还有图像、视频等多模态数据。这要求数据库能够支持不同种类数据的嵌入,并能根据不同模态的数据查询进行有效的召回。
可解释性和可调试性:在召回效果不理想时,能够提供足够的信息帮助开发者诊断和优化是非常有价值的。因此,向量数据库在设计时也应考虑到系统的可解释性和可调试性。
RAG 场景中对向量数据库的召回效果有着严格的要求,不仅需要高精度和快速响应的召回这类基础能力,还需要处理多模态数据的能力以及可解释性和可调试性这类更高级的功能,以确保生成模型能够基于高质量的召回结果产生准确和相关的输出。在多模态处理、检索的可解释性和可调试性方面,向量数据库仍有许多工作值得探索和优化,而 RAG 应用的开发者也急需一套端到端的解决方案来达到高质量的检索效果。
本文作者


本文分享自微信公众号 - ZILLIZ(Zilliztech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。