

À mesure que le secteur SaaS se développe rapidement, des architectures dynamiques et adaptables sont nécessaires pour gérer l'afflux de données en temps réel. Voici comment les construire.
Traduit de Comment créer une architecture de plate-forme évolutive pour les données en temps réel , auteur Christina Lin.
L'industrie du logiciel en tant que service (SaaS) affiche une croissance imparable, la taille du marché devant atteindre 317,555 milliards de dollars américains en 2024 et presque tripler pour atteindre 1,22887 milliard de dollars américains d'ici 2032 . Cette croissance met en évidence le besoin croissant de stratégies de données robustes et améliorées. Cette tendance est motivée par l’augmentation du volume, de la vitesse et de la diversité des données générées par les entreprises et par l’intégration de l’intelligence artificielle.
Cependant, ce paysage en pleine croissance entraîne plusieurs défis importants, tels que la gestion des pics de trafic, la transition du traitement des transactions en ligne (OLTP) au traitement analytique en ligne (OLAP) en temps réel, la garantie du libre-service et du découplage, et l'indépendance et le multi-cloud. déploiement régional. Relever ces défis nécessite un cadre architectural sophistiqué qui garantit une haute disponibilité et des mécanismes de basculement robustes sans compromettre les performances du système.
L'architecture de référence présentée dans cet article explique comment créer une plate-forme de données évolutive, automatisée et flexible pour prendre en charge le secteur SaaS en pleine croissance. Cette architecture prend en charge les besoins techniques liés au traitement de données à grande échelle tout en s'alignant sur les besoins de l'entreprise en matière d'agilité, de rentabilité et de conformité réglementaire.
Défis techniques des services SaaS gourmands en données
Alors que la demande de services et les volumes de données continuent de croître, plusieurs défis courants se posent dans le secteur SaaS.
La gestion des pics et des rafales de trafic est essentielle pour allouer efficacement les ressources afin de faire face aux modèles de trafic variables. Cela nécessite d'isoler les charges de travail, d'évoluer pendant les charges de travail de pointe et de réduire les ressources de calcul pendant les heures creuses tout en évitant la perte de données.
Maintenir OLTP en temps réel vers OLAP signifie prendre en charge de manière transparente OLTP, qui gère de grands volumes de transactions rapides en mettant l'accent sur l'intégrité des données, et les systèmes OLAP qui prennent en charge des informations analytiques rapides. Cette double prise en charge est essentielle pour prendre en charge les requêtes analytiques complexes et maintenir des performances optimales. Il joue également un rôle clé dans la préparation des ensembles de données pour l'apprentissage automatique (ML).
Pour permettre le libre-service et le découplage, il faut doter les équipes de capacités de libre-service leur permettant de créer et de gérer des sujets et des clusters sans dépendre fortement d'une équipe informatique centrale. Cela accélère le développement tout en permettant aux applications et aux services d'être découplés et d'atteindre une évolutivité indépendante.
La promotion de l'agnosticisme et de la stabilité du cloud permet l'agilité et la capacité d'opérer dans différents environnements cloud tels qu'AWS , Microsoft Azure ou
Comment construire une architecture adaptée au SaaS
Pour relever ces défis, les grandes entreprises SaaS adoptent souvent un cadre architectural qui implique l'exécution de plusieurs clusters couvrant plusieurs régions et gérés par un plan de contrôle développé sur mesure. La conception du plan de contrôle améliore la flexibilité de l'infrastructure sous-jacente tout en simplifiant la complexité des applications qui y sont connectées.
Bien que cette stratégie soit essentielle pour une haute disponibilité et un mécanisme de basculement robuste, elle peut également devenir trop complexe pour maintenir des performances et une intégrité des données uniformes sur un cluster géographiquement distribué, sans parler des impacts sur les performances ni de l'introduction de latence. surgir.
De plus, certains scénarios peuvent nécessiter que les données soient isolées au sein d'un cluster spécifique pour des raisons de conformité ou de sécurité. Pour vous aider à créer une architecture robuste et flexible qui évite ces complexités, je vais vous présenter quelques suggestions.
1. Établir une base stable
Un défi majeur pour les services SaaS consiste à allouer des ressources pour gérer divers modèles de trafic, notamment les requêtes en ligne à haute fréquence et à volume élevé, l'insertion de données et l'échange de données internes.
La conversion du trafic en processus asynchrones est une solution courante qui permet une mise à l'échelle plus efficace et une allocation rapide des ressources informatiques. Les plateformes de streaming de données telles qu'Apache Kafka sont idéales pour gérer efficacement d'énormes quantités de données. Mais la gestion d’une plateforme de données distribuées comme Kafka comporte son lot de défis. Le système de Kafka est connu pour sa complexité technique, car il nécessite la gestion de la coordination, de la synchronisation et de la mise à l'échelle du cluster, ainsi que des protocoles de sécurité et de récupération supplémentaires. Les défis de Kafka
La machine virtuelle Java (JVM) de Kafka peut également provoquer des pics de latence imprévisibles, principalement dus au processus de récupération de place de la JVM. La gestion de l'allocation de mémoire de la JVM et le réglage des exigences de débit élevé de Kafka sont notoirement fastidieux et peuvent avoir un impact sur la stabilité globale du courtier Kafka.
Un autre obstacle est la gestion de la politique de données de Kafka. Cela inclut la gestion des politiques de conservation des données, la compression des journaux et la suppression des données tout en équilibrant dans une certaine mesure les coûts de stockage, les performances et la conformité.
En bref, gérer efficacement les systèmes basés sur Kafka dans un environnement SaaS est délicat. En conséquence, de nombreuses entreprises SaaS se tournent vers des alternatives Kafka qui fournissent un streaming de données hautement évolutif sans avoir besoin de dépendances externes telles que JVM ou ZooKeeper.
2. Activez les données de streaming en libre-service
Il existe une demande croissante de solutions en libre-service permettant aux développeurs de créer des thèmes du développement à la production. L'infrastructure ou le service de plate-forme doit fournir une solution avec un contrôle centralisé, fournir des informations de connexion et automatiser la création et le déploiement rapides de ressources sur différentes plates-formes et étapes.
Cela soulève la nécessité d’un plan de contrôle, qui se présente sous de nombreuses formes. Certains plans de contrôle ne sont utilisés que pour gérer le cycle de vie d'un cluster ou d'un sujet et attribuer des autorisations sur la plateforme de streaming. D'autres plans de contrôle ajoutent une couche d'abstraction en virtualisant les cibles et en masquant les détails de l'infrastructure aux utilisateurs et aux clients.
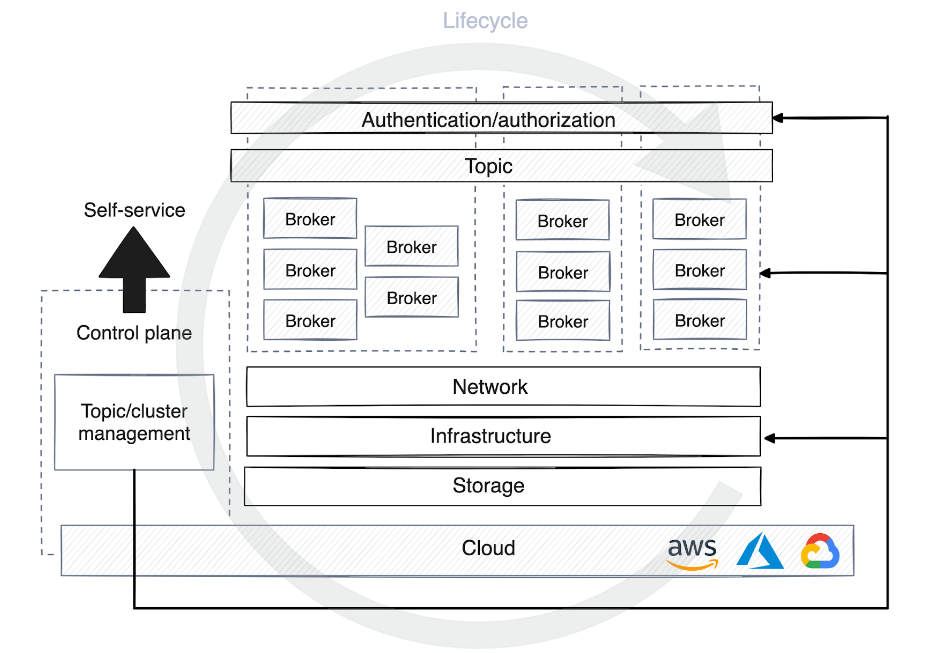
Lorsqu'un sujet est enregistré dans le plan de contrôle de la plateforme de données en libre-service, différentes stratégies d'optimisation des ressources informatiques sont appliquées en fonction de l'étape de l'environnement. En développement, les sujets partagent souvent des clusters avec d'autres processus, la conservation des données est moins mise en avant et la plupart des données sont supprimées en quelques jours.
Cependant, en production, l’allocation des ressources doit être soigneusement planifiée en fonction du volume de trafic. Cette planification comprend la détermination du nombre de partitions pour les consommateurs, la définition de politiques de conservation des données, le choix de l'emplacement des données et la détermination de la nécessité d'un cluster dédié pour des cas d'utilisation spécifiques.
Pour le plan de contrôle, il est très utile d’automatiser le processus de gestion du cycle de vie de la plateforme de streaming. Cela permet au plan de contrôle de déboguer les agents de manière autonome, de surveiller les mesures de performances et de démarrer ou d'arrêter le rééquilibrage des partitions pour maintenir la disponibilité et la stabilité de la plateforme à grande échelle.
3. Prise en charge en temps réel d'OLTP et OLAP
Le passage du traitement par lots à l'analyse en temps réel rend critique l'intégration des systèmes OLAP dans l'infrastructure existante. Cependant, ces systèmes gèrent généralement de grandes quantités de données et nécessitent des modèles de données complexes pour une analyse multidimensionnelle approfondie.
OLAP s'appuie sur plusieurs sources de données et, en fonction de la maturité de l'entreprise, il existe généralement un entrepôt de données ou un lac de données pour stocker les données, ainsi que des pipelines de traitement par lots qui s'exécutent périodiquement (généralement la nuit) pour déplacer les données des sources de données. . Ce processus fusionne les données de divers systèmes OLTP et d'autres sources - un processus qui peut devenir complexe pour maintenir la qualité et la cohérence des données.
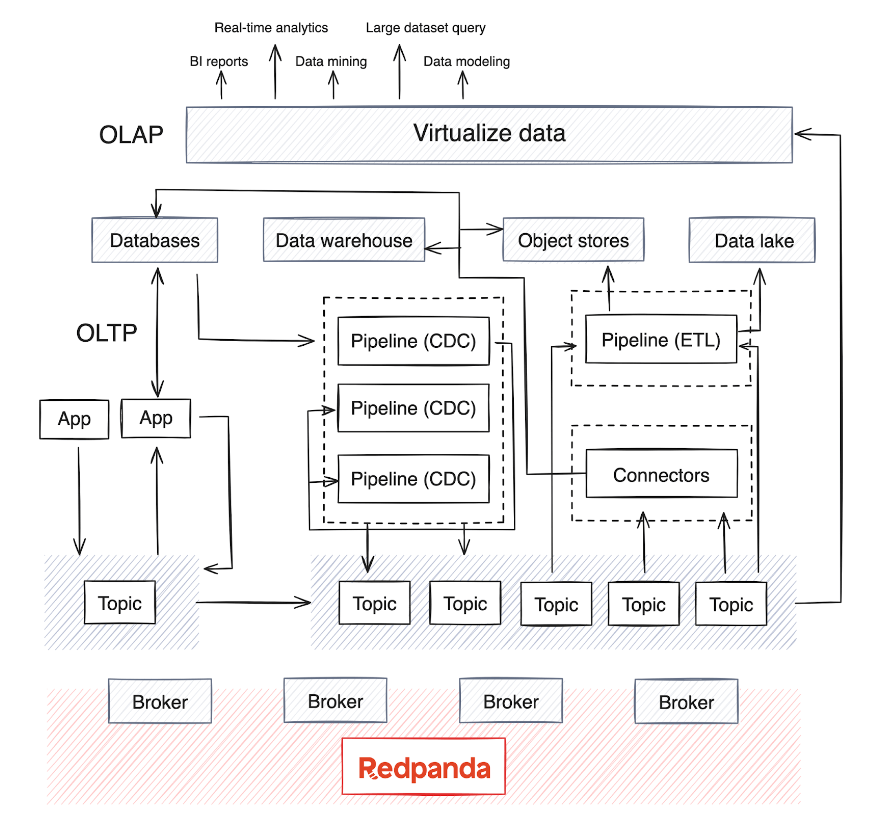
Aujourd'hui, OLAP intègre également des modèles d'IA avec de grands ensembles de données. La plupart des moteurs de traitement de données distribués et des bases de données de streaming prennent désormais en charge la consommation, l'agrégation, la synthèse et l'analyse en temps réel des données de streaming provenant de sources telles que Kafka ou Redpanda. Cette tendance a conduit à l'essor des pipelines d'extraction, de transformation, de chargement (ETL) et d'extraction, de chargement, de transformation (ELT) pour les données en temps réel, ainsi que des pipelines de capture de données modifiées (CDC) qui diffusent en continu les journaux d'événements à partir de bases de données.
Les pipelines en temps réel, généralement implémentés en Java , Python ou Golang, nécessitent une planification minutieuse. Pour optimiser le cycle de vie de ces pipelines, les entreprises SaaS intègrent la gestion du cycle de vie des pipelines dans leurs plans de contrôle afin d'optimiser la surveillance et l'alignement des ressources.
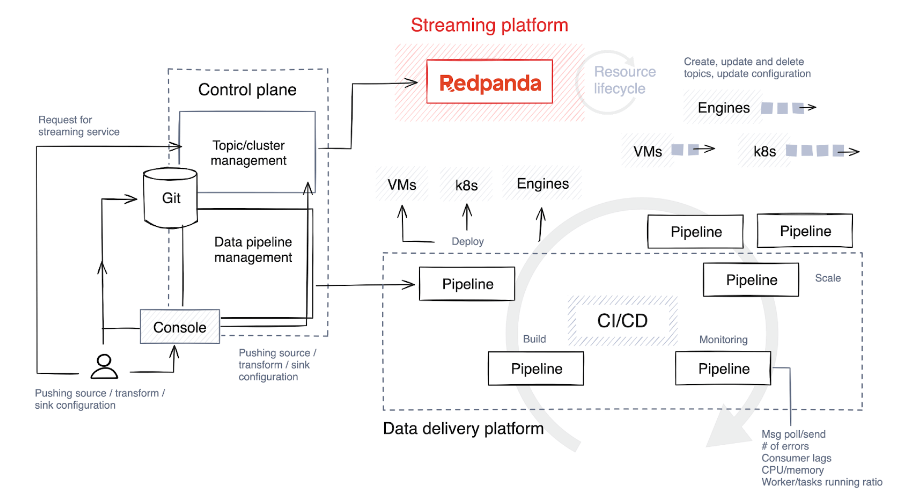
4. Comprendre (et optimiser) le cycle de vie du pipeline de données
La première étape consiste à choisir une pile technologique et à déterminer le niveau de liberté et de personnalisation dont bénéficieront les utilisateurs créant des pipelines. Idéalement, permettez-leur de sélectionner diverses technologies pour différentes tâches et de mettre en place des garde-corps pour limiter la construction et l’expansion des pipelines.
Ce qui suit est un bref aperçu des étapes impliquées dans le cycle de vie du pipeline.
Construire et tester
Le code source est transféré vers un référentiel Git, soit directement par les développeurs de pipelines, soit via des outils personnalisés dans le plan de contrôle. Ce code est ensuite compilé en code binaire ou en programme exécutable à l'aide d'un langage tel que C++, Java ou C#. Après compilation, le code est regroupé dans un artefact, un processus qui peut également impliquer le regroupement de dépendances autorisées et de fichiers de configuration.
Le système exécute ensuite des tests automatisés pour vérifier le code. Pendant les tests, le plan de contrôle crée des sujets temporaires spécifiquement à cet effet, et ces sujets sont détruits dès que les tests sont terminés.
déployer
Les artefacts sont déployés sur des machines virtuelles (telles que Kubernetes ) ou des bases de données de streaming, en fonction de la pile technologique. Certaines plates-formes proposent des approches plus créatives en matière de stratégies de publication, telles que les déploiements bleu/vert, qui permettent une restauration rapide et minimisent les temps d'arrêt. Une autre stratégie est la version Canary, dans laquelle une nouvelle version n'est appliquée qu'à une petite partie des données, réduisant ainsi l'impact des problèmes potentiels.
Les inconvénients de ces stratégies sont que les restaurations peuvent être difficiles et qu'il peut être difficile d'isoler les données affectées par la nouvelle version. Parfois, il est plus simple d'effectuer une version complète et de restaurer l'intégralité de l'ensemble de données.
Développer
De nombreuses plates-formes prennent en charge la mise à l'échelle automatique, par exemple en ajustant le nombre d'instances en cours d'exécution en fonction de l'utilisation du processeur, mais le niveau d'automatisation varie. Certaines plates-formes fournissent cette fonctionnalité de manière native, tandis que d'autres nécessitent une configuration manuelle, telle que la définition du nombre maximum de tâches parallèles ou de processus de travail par tâche.
Pendant le déploiement, le plan de contrôle fournit des paramètres par défaut en fonction de la demande anticipée, mais continue de surveiller de près les métriques. Il alloue ensuite des ressources supplémentaires au sujet en augmentant le nombre de processus de travail, de tâches ou d'instances selon les besoins.
moniteur
La surveillance des bonnes mesures dans votre pipeline et le maintien de l'observabilité sont les principaux moyens de détecter les problèmes le plus tôt possible. Voici quelques indicateurs clés que vous devez surveiller de manière proactive pour garantir l’efficacité et la fiabilité de votre pipeline de traitement de données.
Indicateurs de ressources
- L'utilisation du processeur et de la mémoire est essentielle pour comprendre comment les ressources sont consommées.
- Les E/S disque sont importantes pour évaluer l’efficacité des opérations de stockage et de récupération de données.
Débit et latence
- Les enregistrements d'entrée/sortie mesurent le taux de traitement des données par seconde.
- Les enregistrements traités par seconde représentent la puissance de traitement du système.
- La latence de bout en bout correspond au temps total nécessaire entre l'entrée et la sortie des données, ce qui est essentiel aux performances de traitement en temps réel.
Contre-pression et hystérésis
- Ceux-ci aident à identifier les goulots d’étranglement dans le traitement des données et à prévenir les ralentissements potentiels.
Taux d'erreur
- Le suivi des taux d'erreur permet de maintenir l'intégrité des données et la fiabilité du système
5. Améliorer la fiabilité, la redondance et la résilience
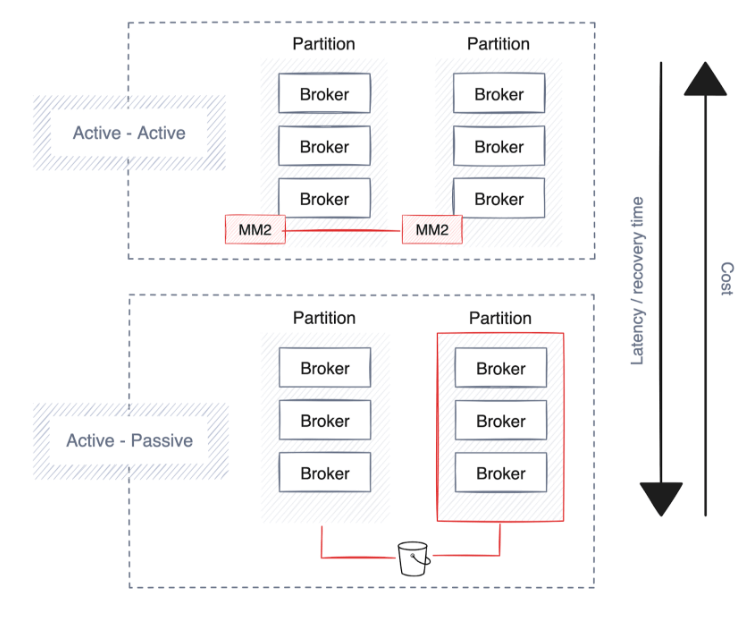
Les entreprises donnent la priorité à la haute disponibilité, à la reprise après sinistre et à la résilience pour maintenir la continuité des opérations en cas de perturbations. La plupart des plates-formes de streaming de données intègrent déjà de solides protections et stratégies de déploiement, principalement en étendant les clusters sur plusieurs partitions, centres de données et zones de disponibilité indépendantes du cloud.
Cependant, cela implique des compromis, tels qu’une latence accrue, une duplication potentielle des données et des coûts plus élevés. Voici quelques suggestions lors de la planification de la haute disponibilité, de la reprise après sinistre et de la résilience.
La haute disponibilité
Un processus de déploiement automatisé géré par le plan de contrôle joue un rôle clé dans l'établissement d'une stratégie robuste de haute disponibilité . Cette stratégie garantit que les pipelines, les connecteurs et les plates-formes de streaming sont répartis stratégiquement entre les zones ou partitions de disponibilité en fonction du fournisseur de cloud ou du centre de données.

Il est essentiel que les plateformes de données répartissent tous les pipelines de données sur plusieurs zones de disponibilité (AZ) afin de réduire les risques. La continuité est prise en charge par l'exécution de copies redondantes de pipelines dans différentes zones de disponibilité pour maintenir un traitement ininterrompu des données en cas de panne de partition.
Les plates-formes de streaming sous-jacentes à l'architecture de données devraient emboîter le pas et répliquer automatiquement les données sur plusieurs zones de disponibilité pour améliorer la résilience. Des solutions telles que Redpanda peuvent automatiser la distribution des données entre les partitions, améliorant ainsi la fiabilité et la tolérance aux pannes de la plateforme.
Cependant, tenez compte des coûts potentiels associés à la bande passante du réseau, en tenant compte de l'emplacement de vos applications et services. Par exemple, garder les pipelines à proximité des magasins de données peut réduire la latence et les frais généraux du réseau tout en réduisant les coûts.
reprise après sinistre
Une reprise après panne plus rapide entraîne des coûts plus élevés en raison de la réplication accrue des données, ce qui entraîne une surcharge de bande passante plus élevée et nécessite un paramètre toujours actif (actif-actif), doublant ainsi l'utilisation du matériel. Toutes les technologies de streaming n'offrent pas cette fonctionnalité, mais les plates-formes d'entreprise telles que Redpanda prennent en charge la sauvegarde des données et des métadonnées du cluster sur le stockage d'objets cloud.
élasticité
Outre la haute disponibilité et la reprise après sinistre, certaines entreprises mondiales ont besoin de stratégies de déploiement régional pour garantir que le stockage et le traitement de leurs données sont conformes aux réglementations géographiques spécifiques. Au lieu de cela, les entreprises qui souhaitent partager des données en temps réel entre différentes régions avec un minimum de gestion créent souvent un cluster partagé qui permet aux agents de répliquer et de distribuer les données entre les régions.
Cependant, cette approche entraîne un coût réseau et une latence importants, car les données sont continuellement transférées vers les partitions suivantes. Pour réduire le trafic de données, la récupération des suiveurs demande au consommateur de données de lire les données de la partition suiveuse géographiquement la plus proche.
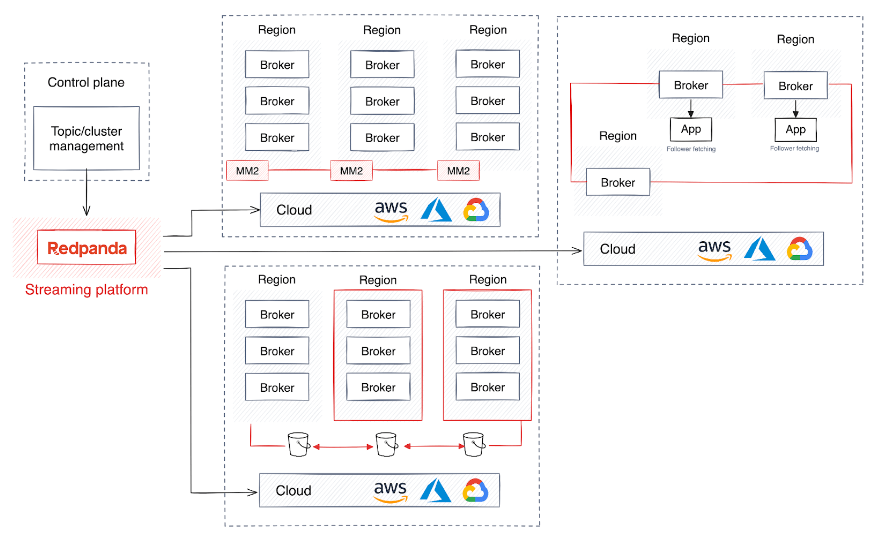
De plus, la mise à l'échelle des clusters pour le remplissage des données améliore l'équilibrage de charge entre les centres de données. Cette évolutivité est essentielle pour gérer des volumes de données et un trafic réseau croissants, aidant ainsi les entreprises à évoluer sans sacrifier les performances ou la fiabilité.
en conclusion
À mesure que les entreprises se transforment grâce à la transformation numérique, les données en temps réel deviennent de plus en plus essentielles pour orienter la prise de décision. Cela implique d'extraire des informations plus approfondies à partir d'ensembles de données massifs , de permettre des prévisions plus précises, de rationaliser les processus décisionnels automatisés et de fournir des services plus personnalisés, tout en optimisant les coûts et les opérations.
Une option consiste à adopter une architecture de référence qui inclut une plate-forme de streaming de données évolutive telle que Redpanda , un remplacement plug-and-play de Kafka implémenté en C++. Il permet aux entreprises d'éviter le temps réel en facilitant une mise à l'échelle transparente, une API de gestion qui prend en charge l'automatisation du cycle de vie , un stockage hiérarchisé pour réduire les coûts de stockage , des réplicas en lecture à distance pour simplifier la configuration de clusters en lecture seule rentables et une géodistribution transparente des données. complexité du traitement.
Avec la bonne technologie, les fournisseurs SaaS peuvent améliorer leurs services, améliorer l’expérience client et accroître leur avantage concurrentiel sur le marché numérique. Les stratégies futures devraient continuer à optimiser ces systèmes pour une plus grande efficacité et adaptabilité afin que les plates-formes SaaS puissent prospérer dans un monde axé sur les données.
Un programmeur né dans les années 1990 a développé un logiciel de portage vidéo et en a réalisé plus de 7 millions en moins d'un an. La fin a été très éprouvante ! Des lycéens créent leur propre langage de programmation open source en guise de cérémonie de passage à l'âge adulte - commentaires acerbes des internautes : s'appuyant sur RustDesk en raison d'une fraude généralisée, le service domestique Taobao (taobao.com) a suspendu ses services domestiques et repris le travail d'optimisation de la version Web Java 17 est la version Java LTS la plus utilisée Part de marché de Windows 10 Atteignant 70 %, Windows 11 continue de décliner Open Source Daily | Google soutient Hongmeng pour prendre le relais des téléphones Android open source pris en charge par Docker ; Electric ferme la plate-forme ouverte Apple lance la puce M4 Google supprime le noyau universel Android (ACK) Prise en charge de l'architecture RISC-V Yunfeng a démissionné d'Alibaba et prévoit de produire des jeux indépendants pour les plates-formes Windows à l'avenirCet article a été publié pour la première fois sur Yunyunzhongsheng ( https://yylives.cc/ ), tout le monde est invité à le visiter.