これは、OpenCVとPythonに基づくナンバープレート抽出プロジェクトのアイデアとソースコードを紹介する記事です。この記事には、いくつかの人工知能と画像認識技術が含まれます。具体的には、ナンバープレート番号認識(ナンバープレート抽出と文字)に関する研究が含まれます。セグメンテーション)、オンライン見つかったソリューションは、tensorflowとopencvです。Opencvも比較的成熟したソリューションです。簡単なソリューションから始めましょう。以下は、opencvを使用してナンバープレート番号を抽出する部分です。
1ナンバープレートの抽出
1.1実装のアイデア
- カラー写真を読む
- グレースケールに変換
- ガウスぼかし
- エッジ検出用のSobel演算子
- バイナリイメージ
- クローズ操作(腐食および膨張)
- ループしてすべての輪郭を見つける
- ナンバープレートの面積を決定する
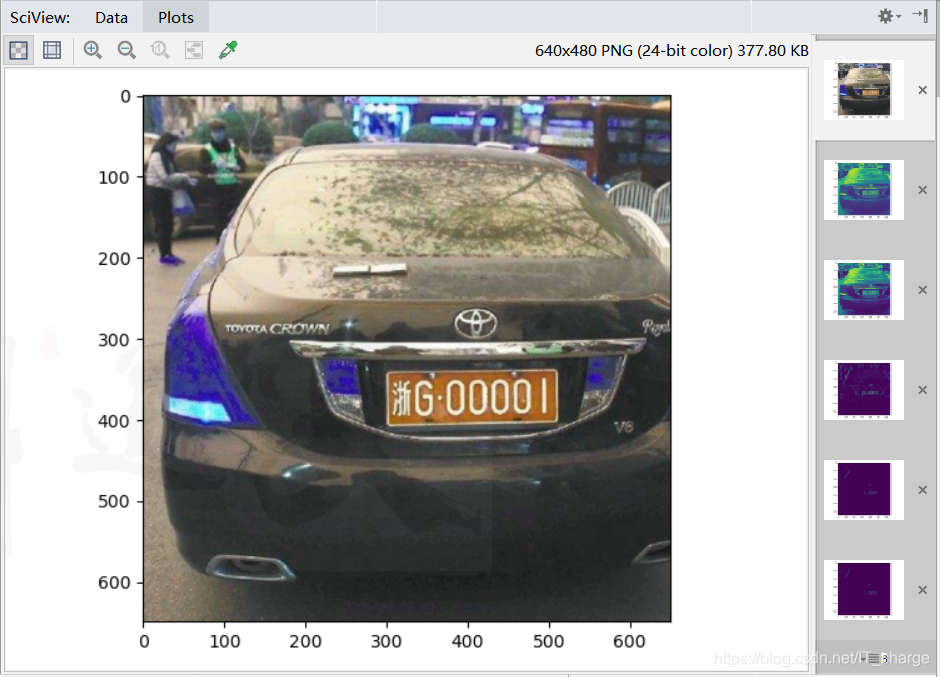
1.2元の画像

1.3詳細コード
1.3.1パッケージライブラリのインポート
import cv2 as cv
import matplotlib.pyplot as plt
1.3.2カラー写真を読む
cv.imread("E:/car.png")
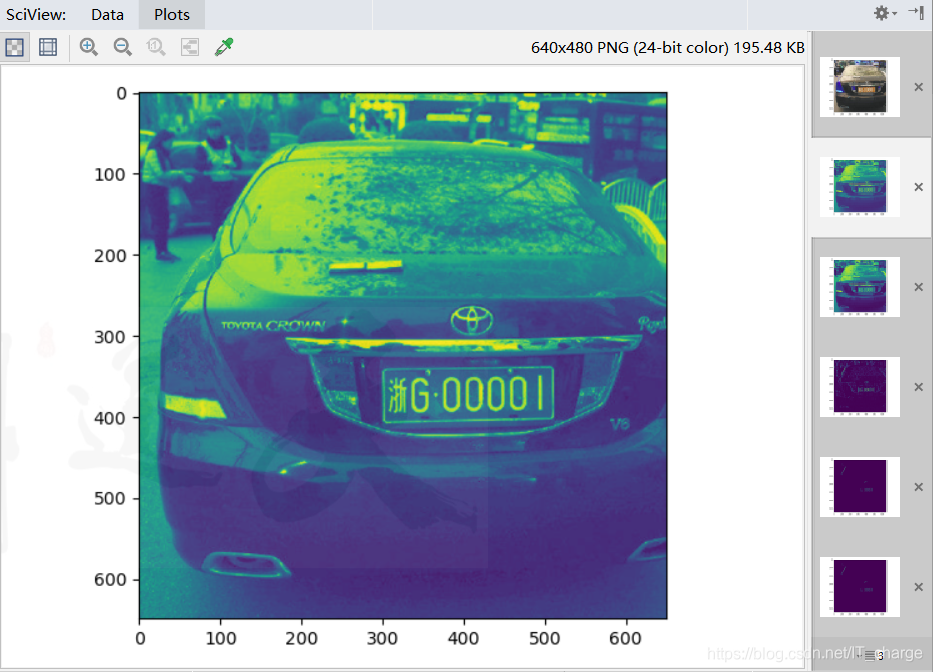
1.3.3グレースケールに変換する
cv.cvtColor(img, cv.COLOR_BGR2GRAY)
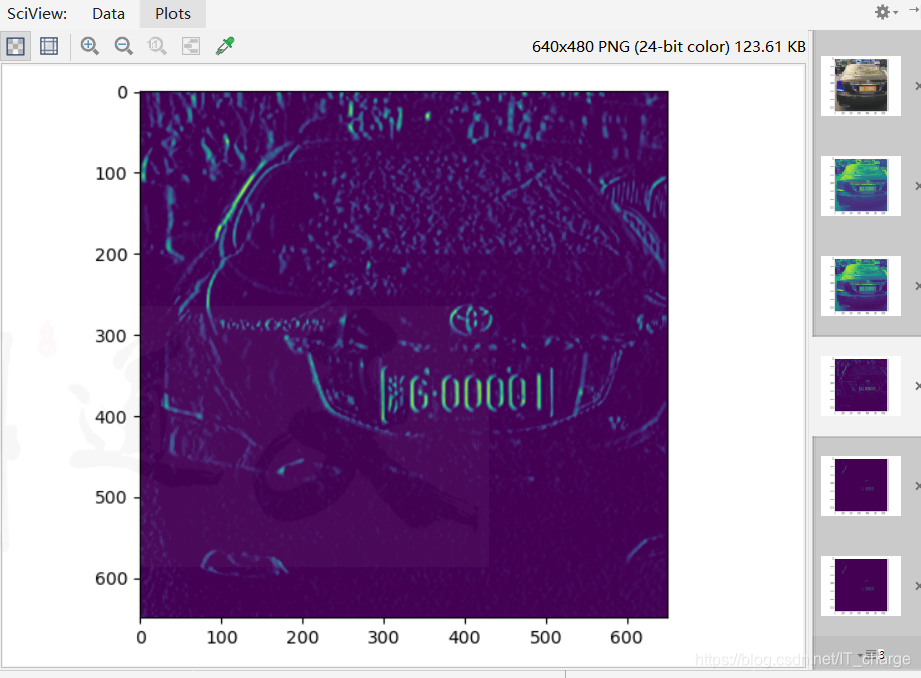
1.3.4ガウスぼかし
ガウスぼかしにより、干渉の一部を除去して、認識をより正確にすることができます。
cv.GaussianBlur(img1,(5,5),10)

1.3.5Sobel演算子によるエッジ検出
輪郭の抽出を容易にします
cv.Sobel(img2,cv.CV_8U,1,0,ksize=1)
cv.Canny(img3,250,100)
1.3.6二値化処理を実行する
画像のピクセルのグレー値を0または255に設定すると、画像は白黒でのみ表示されます。
cv.threshold(img4,0,255,cv.THRESH_BINARY)
1.3.7クローズ操作
腐食と膨張が順番に実行されます。このステップでは、ターゲット領域を全体に接続できます。これは、後続の輪郭抽出に便利です。
cv.getStructuringElement(cv.MORPH_RECT,(43,33))
cv.dilate(img5,kernel)
1.3.8輪郭を見つける
i,j = cv.findContours(img6,cv.RETR_TREE,cv.CHAIN_APPROX_SIMPLE)
1.3.9ナンバープレートの面積を決定する
result = None
for i1 in i:
x,y,w,h = cv.boundingRect(i1)
if w>2*h:
print(1)
plt.imshow(img[y:y+h,x:x+w])
plt.show()
result = img[y:y+h,x:x+w]

1.4概要コード
import cv2 as cv
import matplotlib.pyplot as plt
# 读取彩色的图片
img = cv.imread("E:/car.png")
plt.imshow(img)
plt.show()
# 转换为灰度图
img1 = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
plt.imshow(img1)
plt.show()
# 用Sobel进行边缘检测
# # 高斯模糊
img2 = cv.GaussianBlur(img1,(5,5),10)
plt.imshow(img2)
plt.show()
# Laplacian进行边缘检测
img3 = cv.Sobel(img2,cv.CV_8U,1,0,ksize=1)
plt.imshow(img3)
plt.show()
img4 = cv.Canny(img3,250,100)
plt.imshow(img4)
plt.show()
# 进行二值化处理
i,img5 = cv.threshold(img4,0,255,cv.THRESH_BINARY)
plt.imshow(img5)
plt.show()
# 可以侵蚀和扩张
kernel = cv.getStructuringElement(cv.MORPH_RECT,(43,33))
img6 = cv.dilate(img5,kernel)
plt.imshow(img6)
plt.show()
# # 循环找到所有的轮廓
i,j = cv.findContours(img6,cv.RETR_TREE,cv.CHAIN_APPROX_SIMPLE)
result = None
for i1 in i:
x,y,w,h = cv.boundingRect(i1)
if w>2*h:
print(1)
plt.imshow(img[y:y+h,x:x+w])
plt.show()
result = img[y:y+h,x:x+w]
1.5最終効果

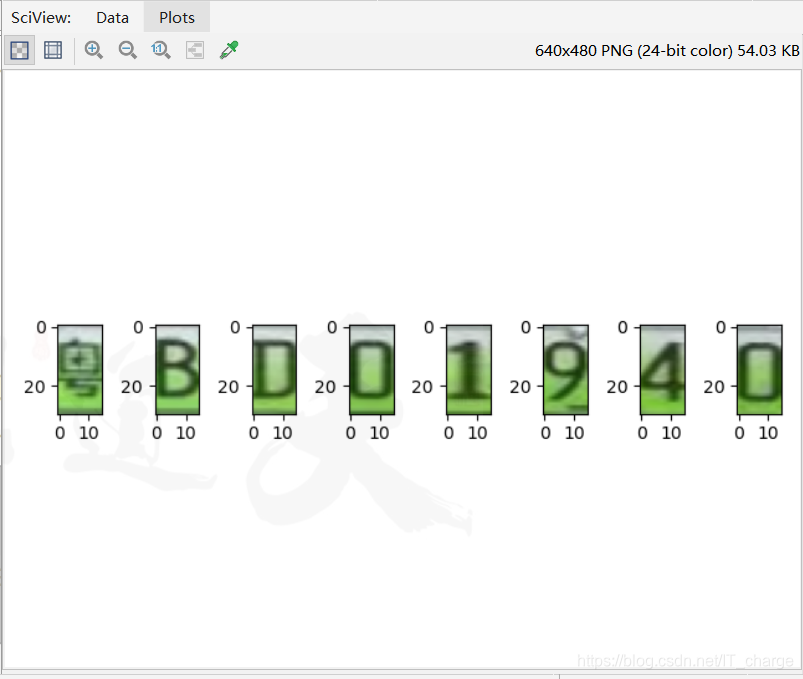
2ナンバープレート認識のための文字セグメンテーション
ナンバープレートの抽出について詳しく説明します。これと同様に、ナンバープレートの文字セグメンテーションも非常に重要な部分であり、文字セグメンテーションのアイデアは他のプロジェクトでも重要な役割を果たします。したがって、文字セグメンテーションのアイデアと実装プロセスを記録する必要があります。
2.1実装のアイデア
一般的には、ピクセルヒストグラムに基づく文字セグメンテーションによって実現されます。まず、画像が2値化され、水平方向と垂直方向の各行と列の黒いピクセルの数がカウントされ、セグメンテーション位置が特性に従って決定されます。ピクセルの、そして完全な文字セグメンテーション。
2.2元の画像

2.3コードの詳細
2.3.1パッケージライブラリのインポート
import cv2
from matplotlib import pyplot as plt
2.3.2画像を読み取り、画像をグレースケール画像に変換して表示する
cv2.imread('E:/3.png') # 读取图片
cv2.cvtColor(img_, cv2.COLOR_BGR2GRAY) # 转换了灰度化

2.3.3グレースケール画像を二値化し、しきい値を100に設定します
cv2.threshold(img_gray, 100, 255, cv2.THRESH_BINARY_INV)

2.3.4文字の分割
水平方向:各行の黒いピクセル数nを数え、記録します。セグメンテーションの開始と終了は、各行の黒いピクセルの数に応じて決定できます。図から、nを特定のしきい値に減らすと、文字のエッジであることがわかります。
垂直方向:同様に、各列の黒いピクセルの数を数えますv、そして記録します。セグメンテーションの開始と終了は、各列の黒いピクセル数の変化に応じて決定できます。
white = [] # 记录每一列的白色像素总和
black = [] # ..........黑色.......
height = img_thre.shape[0]
width = img_thre.shape[1]
white_max = 0
black_max = 0
# 计算每一列的黑白色像素总和
for i in range(width):
s = 0 # 这一列白色总数
t = 0 # 这一列黑色总数
for j in range(height):
if img_thre[j][i] == 255:
s += 1
if img_thre[j][i] == 0:
t += 1
white_max = max(white_max, s)
black_max = max(black_max, t)
white.append(s)
black.append(t)
2.3.5分割画像
def find_end(start_):
end_ = start_ + 1
for m in range(start_ + 1, width - 1):
if (black[m] if arg else white[m]) > (0.95 * black_max if arg else 0.95 * white_max): # 0.95这个参数请多调整,对应下面的0.05(针对像素分布调节)
end_ = m
break
return end_
2.4概要コード
import cv2
from matplotlib import pyplot as plt
## 根据每行和每列的黑色和白色像素数进行图片分割。
# 1、读取图像,并把图像转换为灰度图像并显示
img_ = cv2.imread('E:/3.png') # 读取图片
img_gray = cv2.cvtColor(img_, cv2.COLOR_BGR2GRAY) # 转换了灰度化
# cv2.imshow('gray', img_gray) # 显示图片
# cv2.waitKey(0)
# 2、将灰度图像二值化,设定阈值是100
ret, img_thre = cv2.threshold(img_gray, 100, 255, cv2.THRESH_BINARY_INV)
# cv2.imshow('white_black image', img_thre) # 显示图片
# cv2.waitKey(0)
# 4、分割字符
white = [] # 记录每一列的白色像素总和
black = [] # ..........黑色.......
height = img_thre.shape[0]
width = img_thre.shape[1]
white_max = 0
black_max = 0
# 计算每一列的黑白色像素总和
for i in range(width):
s = 0 # 这一列白色总数
t = 0 # 这一列黑色总数
for j in range(height):
if img_thre[j][i] == 255:
s += 1
if img_thre[j][i] == 0:
t += 1
white_max = max(white_max, s)
black_max = max(black_max, t)
white.append(s)
black.append(t)
# print(s)
# print(t)
arg = False # False表示白底黑字;True表示黑底白字
if black_max > white_max:
arg = True
# 分割图像
def find_end(start_):
end_ = start_ + 1
for m in range(start_ + 1, width - 1):
if (black[m] if arg else white[m]) > (0.95 * black_max if arg else 0.95 * white_max): # 0.95这个参数请多调整,对应下面的0.05(针对像素分布调节)
end_ = m
break
return end_
n = 1
start = 1
end = 2
word = []
while n < width - 2:
n += 1
if (white[n] if arg else black[n]) > (0.05 * white_max if arg else 0.05 * black_max):
# 上面这些判断用来辨别是白底黑字还是黑底白字
# 0.05这个参数请多调整,对应上面的0.95
start = n
end = find_end(start)
n = end
if end - start > 5:
cj = img_[1:height, start:end]
cj = cv2.resize(cj, (15, 30))
word.append(cj)
print(len(word))
for i,j in enumerate(word):
plt.subplot(1,8,i+1)
plt.imshow(word[i],cmap='gray')
plt.show()
2.5最終的な効果