より多くの技術交流と就職活動の機会については、 ByteDance Data Platform の WeChat 公式アカウントに注目し、[1] を返信して公式交流グループに参加してください。
ByteHouse は、Volcano Engine 上のクラウドネイティブ データ ウェアハウスであり、ユーザーに非常に高速な分析エクスペリエンスを提供し、リアルタイムのデータ分析と大規模なオフライン データ分析をサポートできます。便利な伸縮自在の伸縮機能、極端な分析パフォーマンス、および豊富なエンタープライズ レベルの機能を備えています。 、お客様のデジタルトランスフォーメーションを支援します。
この記事では、ByteHouse のリアルタイム インポート テクノロジの進化を、さまざまなアーキテクチャに基づいて、需要の動機付け、テクノロジの実装、および実用化の観点から紹介します。
社内業務のリアルタイムインポート要件
ByteHouse のリアルタイム インポート テクノロジーの進化の動機は、ByteDance の内部ビジネスのニーズに端を発しています。
ByteHouse 内では、リアルタイム インポートのメイン データ ソースとして主に Kafka を使用します (この記事では、説明を拡張するために例として Kafka インポートを使用します。以下では繰り返されません)。ほとんどの内部ユーザーにとって、データ ボリュームは比較的大きいため、ユーザーはデータ インポートのパフォーマンス、サービスの安定性、およびインポート機能のスケーラビリティにより注意を払います。データの遅延に関しては、数秒で表示される限り、ほとんどのユーザーはニーズを満たすことができます。このようなシナリオに基づいて、ByteHouse はカスタマイズされた最適化を実行しました。
分散アーキテクチャでの高可用性

コミュニティ ネイティブ分散アーキテクチャ
ByteHouse は最初に Clickhouse コミュニティの分散アーキテクチャを踏襲しましたが、分散アーキテクチャにはいくつかの自然なアーキテクチャ上の欠陥があります. これらの問題点は主に次の 3 つの側面で明らかになります:
-
ノード障害: クラスタ マシンの数が一定の規模に達すると、ノード障害を毎週手動で処理する必要があります。シングル コピー クラスターの場合、極端なケースでは、ノードの障害によってデータが失われることさえあります。
-
読み取りと書き込みの競合: 分散アーキテクチャの読み取りと書き込みの結合により、クラスターの負荷が特定のレベルに達すると、ユーザー クエリとリアルタイムのインポートでリソースの競合が発生します。特に CPU と IO、インポートが影響を受けます。消費ラグが発生します。
-
拡張コスト: 分散アーキテクチャのデータは基本的にローカルに保存されるため、拡張後にデータを再編成することはできません. 新しく拡張されたマシンにはほとんどデータがなく、古いマシンのディスクはほとんどいっぱいになる可能性があり、結果として不均一なクラスターが発生します.負荷がかかると、膨張につながり、有効な効果を発揮できません。
これらは分散アーキテクチャの自然な問題点ですが、その自然な同時実行特性と、ローカル ディスク データの読み取りと書き込みの極端なパフォーマンスの最適化により、長所と短所があると言えます。
コミュニティ リアルタイム インポート デザイン
-
高レベル消費モード: 消費ロード バランシングのための Kafka 独自のリバランス メカニズムに依存します。
-
2 レベルの同時実行
分散アーキテクチャに基づくリアルタイム インポート コア設計は、実際には 2 レベルの同時実行です。
通常、CH クラスターには複数のシャードがあり、各シャードは同時に消費およびインポートします。これは、第 1 レベルのシャード間のマルチプロセス同時実行性です。
各シャードは、複数のスレッドを使用して同時に消費することもできるため、高いパフォーマンスのスループットを実現できます。
-
一括書き込み
単一のスレッドに関する限り、基本的な消費モードはバッチで書き込むことです。つまり、一定量のデータを消費するか、一定期間後に一度に書き込むことです。バッチ書き込みは、パフォーマンスの最適化を達成し、クエリのパフォーマンスを向上させ、バックグラウンドの Merge スレッドの負荷を軽減することができます。
満たされていないニーズ
上記のコミュニティの設計と実装は、まだユーザーの高度なニーズを満たすことができません。
-
まず、一部の上級ユーザーは、データ配布に関して比較的厳しい要件を持っています. たとえば、特定のデータに対して特定のキーを持ち、同じキーを持つデータが同じシャードに配置されることを望んでいます (一意のキー要件など)。この場合、コミュニティハイレベルの消費モデルを満たすことはできません。
-
第 2 に、高レベルの消費フォームのリバランスは制御不能であり、最終的にさまざまなシャード間で Clickhouse クラスターにインポートされたデータが不均一に分散される可能性があります。
-
もちろん、消費タスクの割り当ては不明であり、一部の異常な消費シナリオでは、問題のトラブルシューティングが非常に困難になります。これは、エンタープライズ レベルのアプリケーションでは受け入れられません。
自社開発の分散アーキテクチャ消費エンジン HaKafka
上記の要件を解決するために、ByteHouse チームは分散アーキテクチャに基づく消費エンジン、HaKafka を開発しました。
高可用性 (Ha)
HaKafka は、コミュニティ内の元の Kafka テーブル エンジンの消費の利点を継承し、高可用性の Ha 最適化に焦点を当てています。
実際、分散アーキテクチャに関する限り、各シャードに複数のコピーが存在する可能性があり、各コピーに HaKafka テーブルを作成できます。しかし、ByteHouse は ZK を介してリーダーのみを選択し、リーダーに実際に消費プロセスを実行させ、他のノードはスタンバイ状態になります。リーダー ノードが使用できない場合、ZK は数秒でリーダーをスタンバイ ノードに切り替えて消費を継続できるため、高可用性を実現できます。
低 - レベル消費モード
HaKafka の消費モードが高レベルから低レベルに調整されました。低レベル モードでは、トピック パーティションがクラスター内の各シャードに整然と均等に分散されるようにすることができます。同時に、マルチスレッドをシャード内で再度使用して、各スレッドが異なるパーティションを使用できるようにすることもできます。したがって、コミュニティ Kafka テーブル エンジンの 2 レベルの同時実行性の利点を完全に継承します。
低レベル消費モードでは、アップストリーム ユーザーがトピックへの書き込み時にデータの偏りがないことを確認する限り、HaKafka を介して Clickhouse にインポートされたデータは、シャード間で均等に分散される必要があります。
同時に、特別なデータ分散要件 (同じキーのデータを同じシャードに書き込む) を持つ上級ユーザーの場合、アップストリームが同じキーのデータが同じパーティションに書き込まれることを保証し、ByteHouse をインポートする場合に限ります。ユーザーのニーズを完全に満たすことができ、非常に簡単です 一意のキーなどのシナリオをサポートします。
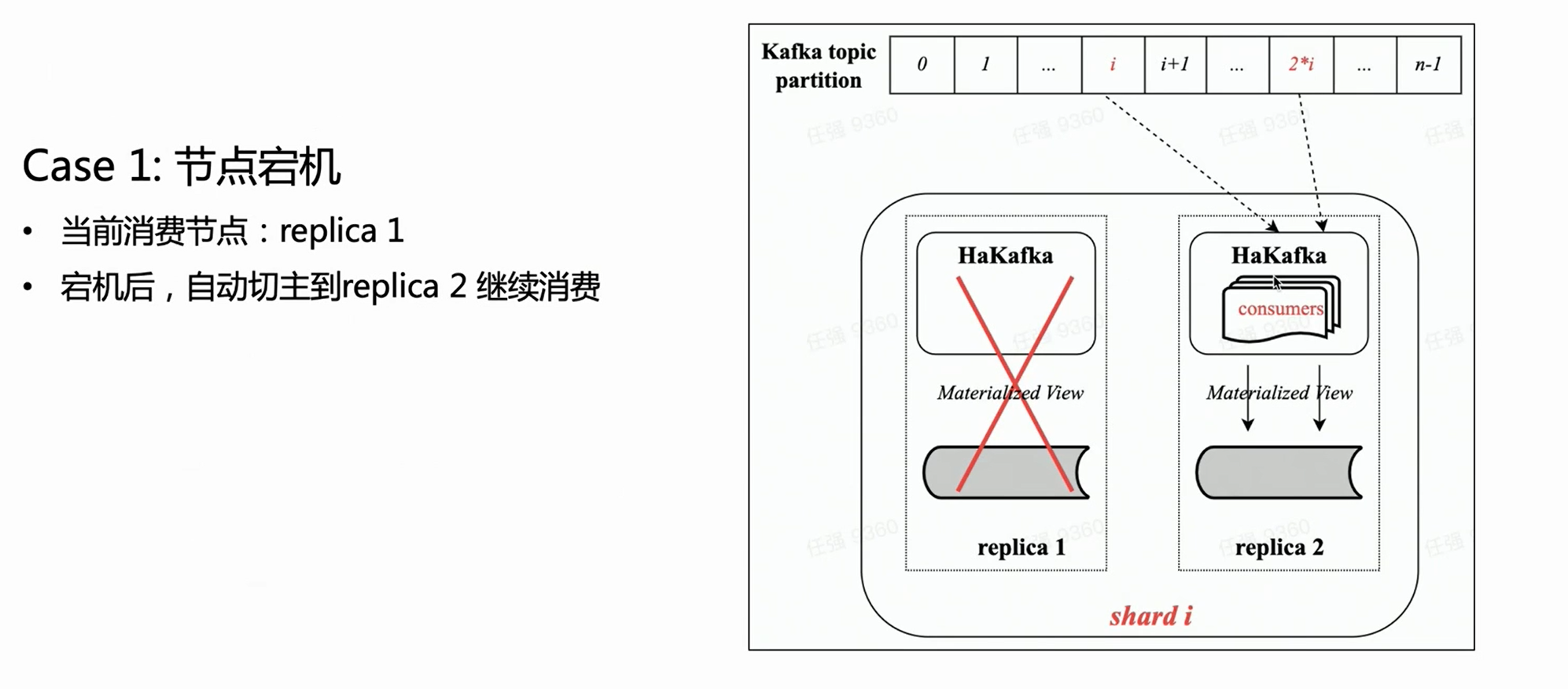
シーン 1:
上の図に基づいて、2 つのコピーを持つシャードがあると仮定すると、各コピーは Ready 状態の同じ HaKafka テーブルを持ちます。ただし、ZK を介して首尾よくリーダーを選出したリーダー ノードでのみ、HaKafka は対応する消費プロセスを実行します。リーダー ノードがダウンすると、レプリカ レプリカ 2 が新しいリーダーとして自動的に再選択され、消費が継続されるため、高可用性が確保されます。
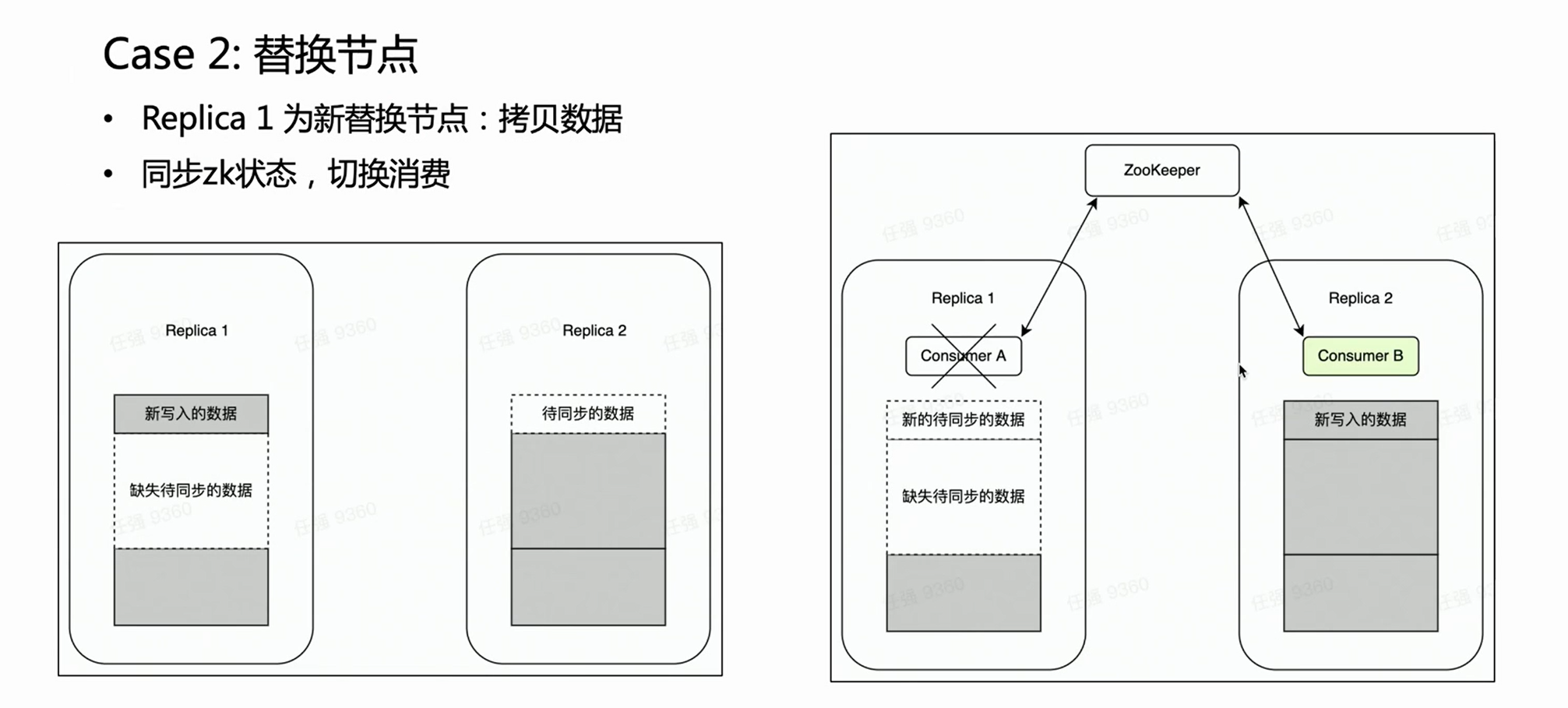
シーン 2:
ノードに障害が発生した場合、通常、ノードを交換するプロセスを実行する必要があります。分散ノードの交換には、データのコピーという非常に負荷の高い操作があります。
マルチレプリカ クラスターの場合、1 つのコピーが失敗し、もう 1 つのコピーはそのままです。古いデータが完全であるため、ノード交換フェーズでは、無傷のレプリカ Replica 2 に Kafka の消費が配置されることを当然期待しています。このように、レプリカ 2 は常に完全なデータ セットであり、外部サービスを正常に提供できます。ハカフカはこれを保証できます。HaKafka がリーダーを選出する際に、特定のノードがノードの置き換え中であると判断された場合、そのノードはリーダーとして選出されないようにします。
インポート パフォーマンスの最適化: メモリ テーブル
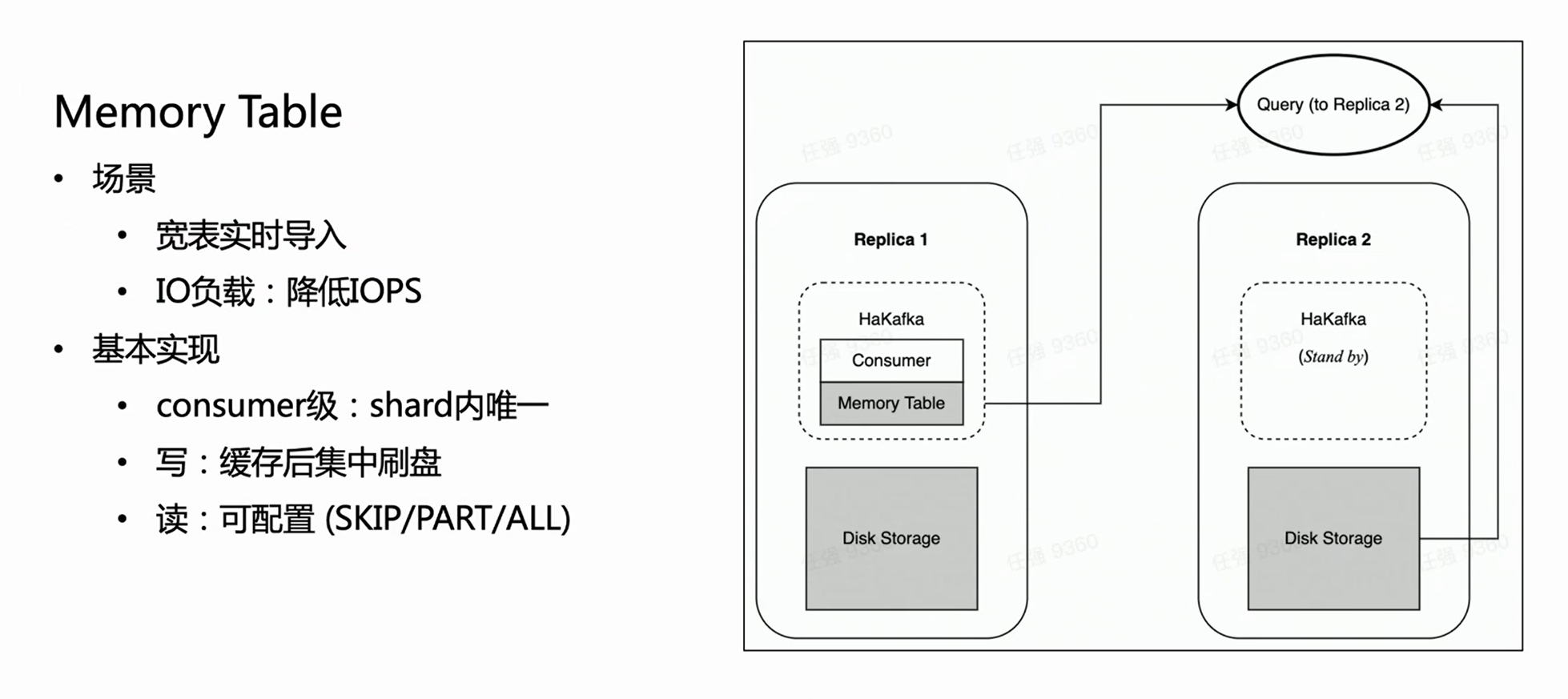
HaKafka はメモリ テーブルも最適化します。
このようなシナリオを考えてみましょう。このビジネスには、数百のフィールドまたは数千のマップキーが含まれる可能性がある大きくて幅の広いテーブルがあります。ClickHouse の各列は特定のファイルに対応するため、列が多いほど、インポートごとにより多くのファイルが書き込まれます。すると、同じ消費時間内に大量の断片化されたファイルが頻繁に書き込まれ、マシンの IO に大きな負担がかかると同時に、MERGE に大きな圧力がかかります; 深刻な場合には、クラスタが使用できなくなります。このシナリオを解決するために、インポート パフォーマンスを最適化するようにメモリ テーブルを設計しました。
メモリテーブルの方法は、インポートしたデータをその都度直接フラッシュするのではなく、メモリに格納し、データが一定量に達するとディスクに集中させて IO 操作を削減します。メモリ テーブルは外部クエリ サービスを提供できます。クエリは、メモリ テーブル内のデータを読み取るためにコンシューマ ノードが配置されているコピーにルーティングされます。これにより、データ インポートの遅延が影響を受けないことが保証されます。内部の経験から、Memory Table は大規模で幅の広いテーブルのビジネス インポート要件を満たすだけでなく、インポート パフォーマンスを最大 3 倍向上させます。
クラウド ネイティブの新しいアーキテクチャ
上記の分散型アーキテクチャの自然な欠陥を考慮して、ByteHouse チームはアーキテクチャのアップグレードに取り組んできました。ビジネスの主流であるクラウドネイティブ アーキテクチャを選択しました. 新しいアーキテクチャは、2021 年初頭に Byte の内部ビジネスにサービスを提供し始め、 2023 年初頭にコード (ByConity) をオープンソース化します.
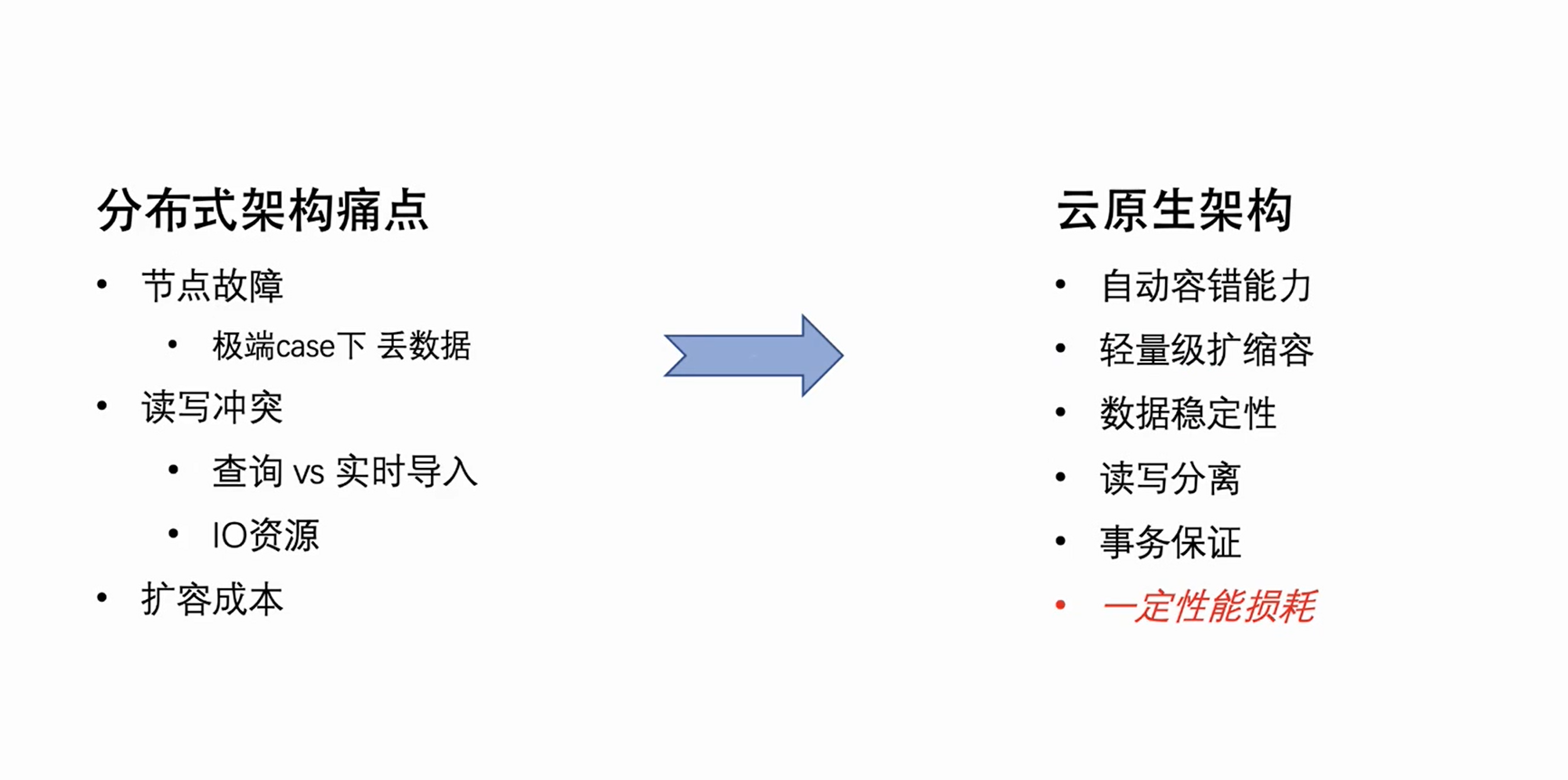
クラウドネイティブ アーキテクチャ自体には、自然な自動フォールト トレランスと軽量スケーリング機能があります。同時に、そのデータはクラウドに保存されるため、ストレージとコンピューティングの分離を実現するだけでなく、データのセキュリティと安定性も向上します。もちろん、クラウド ネイティブ アーキテクチャには欠点がないわけではなく、元のローカルの読み取りと書き込みをリモートの読み取りと書き込みに変更すると、読み取りと書き込みのパフォーマンスがある程度低下することは避けられません。ただし、ある程度のパフォーマンスの低下をアーキテクチャの合理性と交換し、運用と保守のコストを削減することは、実際にはデメリットを上回ります。
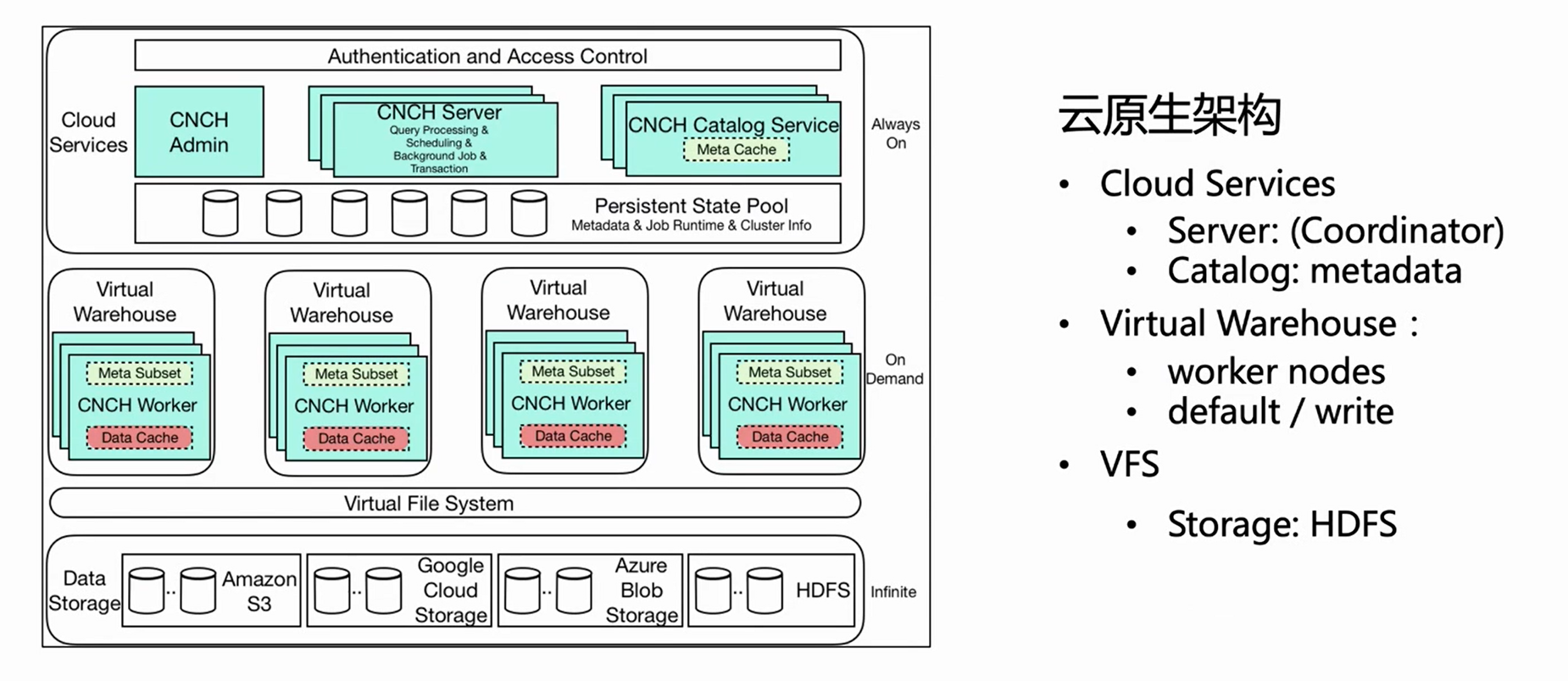
上の図は、ByteHouse クラウドネイティブ アーキテクチャのアーキテクチャ図です. この記事では、リアルタイム インポートに関連するいくつかの重要なコンポーネントを紹介します.
-
クラウド サービス
まず、全体のアーキテクチャは 3 つのレイヤーに分かれており、最初のレイヤーは Cloud Service で、主に Server と Catlog の 2 つのコンポーネントで構成されています。この層はサービスの入り口であり、クエリのインポートを含むすべてのユーザー要求がサーバーから入ります。サーバーは要求を前処理するだけで、実行はしません。Catlog がメタ情報を照会した後、前処理された要求とメタ情報を仮想ウェアハウスに送信して実行します。
-
仮想倉庫
Virtual Warehouse は実行レイヤーです。リソースの分離を実現するために、さまざまな企業が独立した仮想ウェアハウスを持つことができます。現在、Virtual Warehouse は主に Default と Write の 2 つのカテゴリに分けられ、Default は主にクエリに使用され、Write はインポートに使用され、読み取りと書き込みの分離を実現しています。
-
VFS
最下層は VFS (データ ストレージ) で、HDFS、S3、aws などのクラウド ストレージ コンポーネントをサポートします。
クラウド ネイティブ アーキテクチャに基づくリアルタイム インポート設計
クラウドネイティブ アーキテクチャでは、サーバーは特定のインポートの実行を実行せず、タスクの管理のみを行います。したがって、サーバー側では、各消費テーブルにマネージャーがあり、すべての消費実行タスクを管理し、仮想ウェアハウスで実行されるようにスケジュールします。
HaKafka の低レベル消費モードを継承しているため、マネージャーは設定された消費タスク数に従って各タスクにトピック パーティションを均等に分配します; 消費タスク数は設定可能で、上限はトピック パーティション数です。
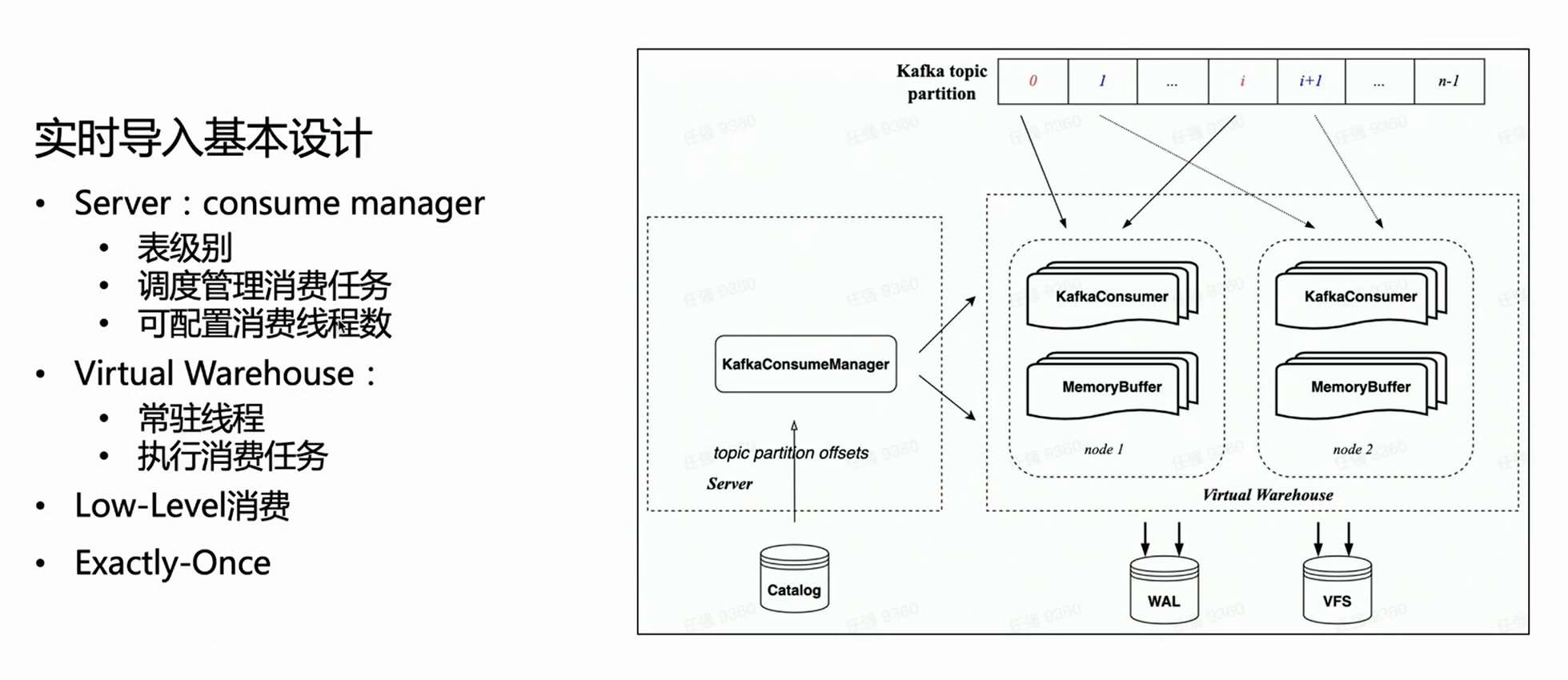
上の図に基づいて、左側のマネージャーがカタログから対応するオフセットを取得し、指定された数の消費タスクに従って対応する消費パーティションを割り当て、それらを仮想ウェアハウスのさまざまなノードにスケジュールすることがわかります。実行。
新しい消費実行プロセス
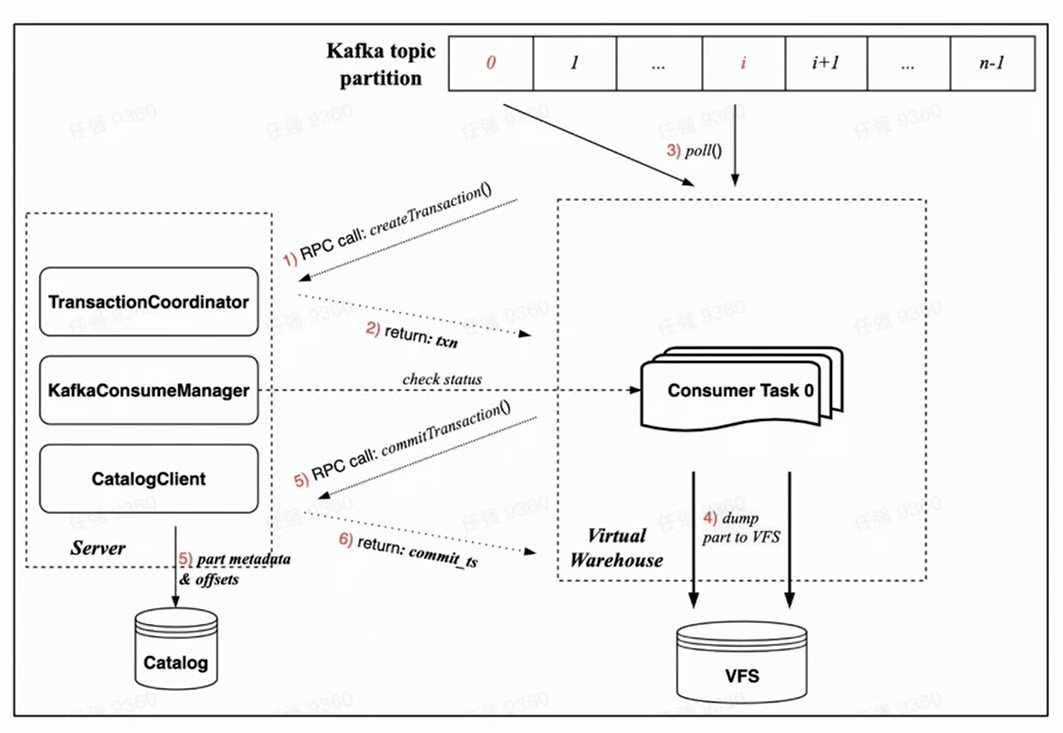
新しいクラウドネイティブ アーキテクチャはトランザクションによって保証されるため、すべての操作は 1 つのトランザクション内で完了することが期待され、より合理的です。
新しいクラウドネイティブ アーキテクチャでのトランザクションの実装に依存するため、各消費タスクの消費プロセスには主に次の手順が含まれます。
-
消費が開始される前に、ワーカー側のタスクはまずサーバー側に RPC リクエストを介してトランザクションの作成をリクエストします。
-
rdkafka::poll() を実行して、一定の時間 (デフォルトでは 8 秒) または十分なサイズのブロックを消費します。
-
ブロックをパーツに変換し、VFS にダンプします (この時点ではデータは表示されません)。
-
トランザクションを開始する RPC リクエストを介してサーバーにリクエストをコミットする
(トランザクションのコミット データには、完了した部分のメタデータのダンプと対応する Kafka オフセットが含まれます)
-
トランザクションが正常にコミットされました (データが表示されます)
耐障害性の保証
上記の消費プロセスから、新しいクラウドネイティブ アーキテクチャでのフォールト トレラントな消費の保証は、主に Manager と Task の双方向ハートビートと高速障害戦略に基づいていることがわかります。
-
Manager 自体が定期的にプローブを実行し、スケジュールされたタスクが RPC を介して正常に実行されているかどうかを確認します。
-
同時に、各タスクはトランザクション RPC リクエストを使用して、消費中にその有効性を検証します。検証が失敗すると、自動的に強制終了できます。
-
マネージャーが活性の検出に失敗すると、すぐに新しい消費タスクを開始して、第 2 レベルのフォールト トレランス保証を実現します。
消費力
消費容量に関しては、スケーラブルであり、トピックのパーティションの数まで、消費タスクの数をユーザーが構成できることが前述されています。仮想倉庫のノード負荷が高い場合、ノードも非常に軽く拡張できます。
もちろん、Manager スケジューリング タスクは、基本的な負荷分散の保証を実装します。つまり、Resource Manager を使用してタスクを管理およびスケジュールします。
セマンティック拡張: 正確に - 1 回
最後に、新しいクラウド ネイティブ アーキテクチャの下での消費セマンティクスも強化されました。
分散アーキテクチャにはトランザクションがないため、At-Least-Once しか実現できません。つまり、どのような状況でもデータが失われることはありませんが、極端な場合には、消費が繰り返される可能性があります。クラウドネイティブ アーキテクチャでは、Transaction の実装のおかげで、消費ごとに Part と Offset がトランザクションを通じてアトミックにコミットされ、Exactly-Once のセマンティック拡張を実現できます。
メモリバッファ
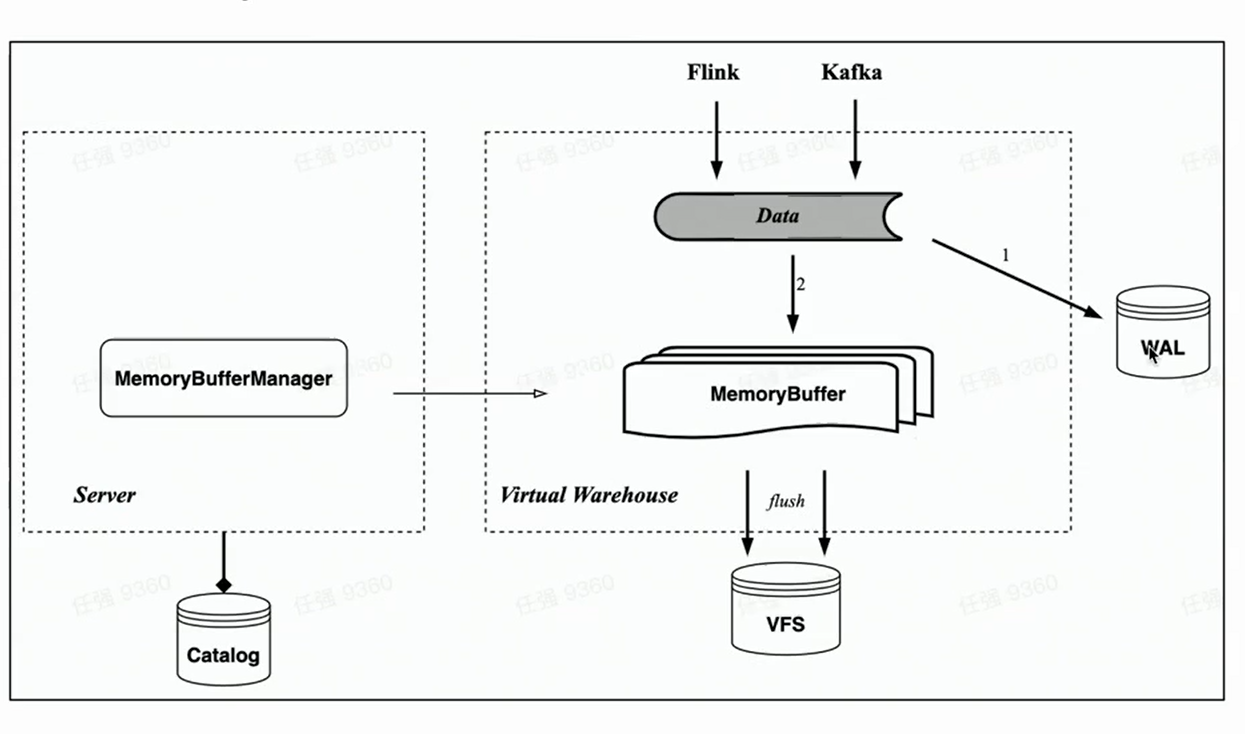
HaKafka のメモリ テーブルに対応して、クラウド ネイティブ アーキテクチャはメモリ キャッシュ Memory Buffer のインポートも実装します。
Memory Table とは異なり、Memory Buffer は Kafka の消費タスクにバインドされなくなりましたが、ストレージ テーブルのキャッシュ レイヤーとして実装されます。このように、Memory Buffer はより汎用性が高く、Kafka のインポートだけでなく、Flink のような小さなバッチのインポートにも使用できます。
同時に、新しいコンポーネント WAL を導入しました。データがインポートされると、まず WAL に書き込み、書き込みが成功する限り、データのインポートが成功したと見なすことができます - サービスが開始されると、最初に WAL からフラッシュされていないデータを復元できます。メモリバッファに書き込むと、書き込みが成功した後にデータが表示されます -メモリバッファはユーザーがクエリできるためです。メモリバッファのデータも定期的にフラッシュされ、フラッシュ後に WAL からクリアできます。
ビジネスへの応用と今後の考え方
最後に、Byte でのリアルタイム インポートの現状と、次世代のリアルタイム インポート テクノロジの可能な最適化の方向性を簡単に紹介します。
ByteHouse のリアルタイム インポート テクノロジーは Kafka に基づいており、毎日のデータ スループットは PB レベルであり、インポートされたシングル スレッドまたはシングル コンシューマ スループットの経験値は 10-20MiB/s です。(ここでは経験値が強調されています。この値は固定値でもピーク値でもないためです。消費スループットは、ユーザー テーブルの複雑さに大きく依存します。テーブル列の数が増えると、インポートのパフォーマンスが大幅に低下する可能性があります。削減, 正確な計算式が使えない. したがって, ここでの経験値はバイト内のほとんどのテーブルのインポートパフォーマンス経験値よりも多くなります.)
Kafka に加えて、Byte は RocketMQ、Pulsar、MySQL (MaterializedMySQL)、Flink 直接書き込みなどを含む他のデータ ソースのリアルタイム インポートを実際にサポートしています。
次世代のリアルタイム インポート テクノロジーに関する簡単な考え:
-
より一般的なリアルタイム インポート テクノロジにより、ユーザーはより多くのインポート データ ソースをサポートできます。
-
データの可視性は、レイテンシとパフォーマンスの間のトレードオフです。
詳細については、クリックしてByteHouse クラウド ネイティブ データ ウェアハウスにジャンプしてください