より多くのエンタープライズ データが保存されるにつれて、ストレージ容量、クエリ パフォーマンス、およびストレージ コストの間の矛盾は、技術チームにとって一般的な問題です。この問題は、Elasticsearch と ClickHouse の 2 つのシナリオで特に顕著です. 異なるホット データのクエリ パフォーマンス要件を満たすために、これら 2 つのコンポーネントには、アーキテクチャ設計でデータを階層化するためのいくつかの戦略があります.
同時に、ストレージ メディアに関しては、クラウド コンピューティングの発展に伴い、オブジェクト ストレージは、その低価格と柔軟な拡張スペースにより、企業の支持を得ています。ウォーム データとコールド データをオブジェクト ストレージに移行する企業がますます増えています。ただし、インデックスや分析コンポーネントをオブジェクト ストレージに直接接続すると、クエリのパフォーマンスや互換性などの問題が発生します。
この記事では、これら 2 つのシナリオにおけるホット データ階層化とコールド データ階層化の基本原則と、JuiceFS を使用してオブジェクト ストレージに存在する問題に対処する方法を紹介します。
01- Elasticsearch データ階層の詳細な説明
ES がホットおよびコールド データ レイヤリング戦略を実装する方法を紹介する前に、データ ストリーム、インデックス ライフサイクル管理、およびノード ロールという 3 つの関連する概念を理解しましょう。
データストリーム
データ ストリーム (データ ストリーム) は ES における重要な概念であり、次のような特徴があります。
- ストリーミング書き込み: 固定サイズのコレクションではなく、ストリーム書き込みのデータ セットです。
- 追加のみの書き込み: 追加書き込みの方法でデータを更新し、履歴データを変更する必要はありません。
- タイムスタンプ: 新しい各データには、生成時のタイムスタンプ レコードがあります。
- 複数のインデックス: ES にはインデックスの概念があり、各データは最終的に対応するインデックスに分類されますが、データ フローは上位レベルでより大きな概念であり、データ フローの背後には多くのインデックスが存在する場合があります。さまざまなルールに従って生成されます。データ ストリームは多くのインデックスで構成されていますが、書き込み可能なのは最新のインデックスのみで、過去のインデックスは読み取り専用であり、一度固定化されると変更できません。
ログ データは、データ ストリームの特性に準拠したタイプのデータです。これは、追加されて書き込まれるだけで、タイムスタンプも必要です。ユーザーは、日別やその他のディメンションなど、さまざまなディメンションに基づいて新しいインデックスを生成します。
下の図は、データ フロー インデックス作成の簡単な例です. データ フローを使用するプロセス中に、ES は履歴インデックスではなく最新のインデックスに直接書き込み、履歴インデックスは変更されません。将来、より多くの新しいデータが生成されると、このインデックスも古いインデックスになります。
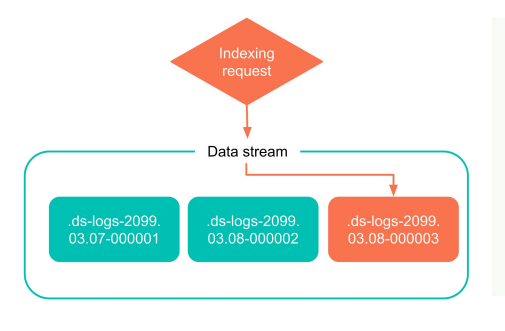
下図に示すように、ユーザーが ES にデータを書き込む場合、大きく 2 つの段階に分けられます。
- フェーズ 1: データは最初にメモリのインメモリ バッファ バッファに書き込まれます。
- フェーズ 2: バッファは、特定のルールと時間に従ってローカル ディスクに落ちます。これは、ES ではセグメントと呼ばれる、下の図の緑色の永続データです。
このプロセスには時間差が生じる場合があります. 永続化プロセス中にクエリをトリガーすると、新しく作成されたセグメントを検索できません. セグメントが永続化されると、上位のクエリ エンジンですぐに検索できます。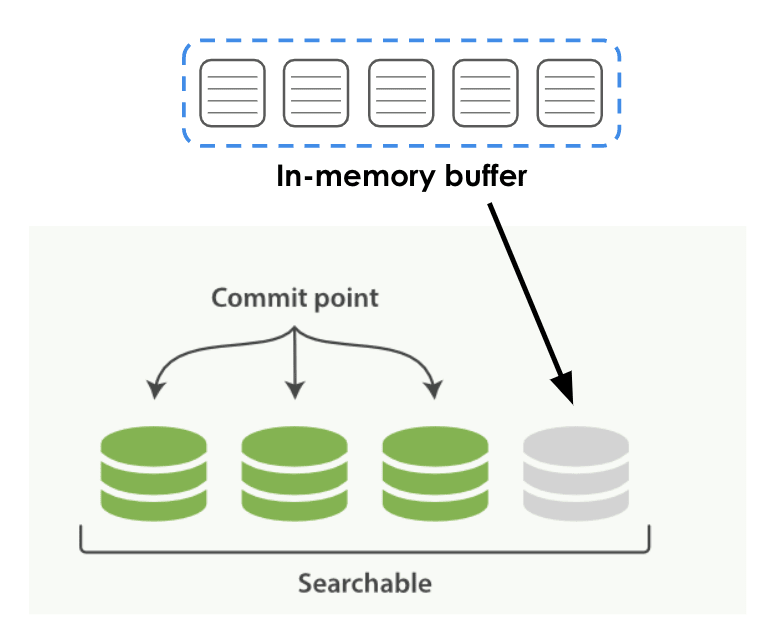
インデックスのライフサイクル管理
ILM と呼ばれるインデックス ライフサイクル管理は、インデックス ライフサイクル管理です。ILM では、インデックスのライフサイクルを 5 つのフェーズとして定義しています。
- ホット データ (ホット): 頻繁に更新またはクエリする必要があるデータ。
- ウォーム データ (ウォーム): 更新されていないが、頻繁にクエリされるデータ。
- コールド データ (Cold): 更新されなくなり、クエリの頻度が低いデータ。
- 凍結されたデータ: 更新されておらず、ほとんどクエリされていないデータ。この種のデータは、比較的低速で安価なストレージ メディアに安全に格納できます。
- データの削除 (Delete): 不要になり、安心して削除できるデータ。
インデックス内のデータは、それがインデックスであろうとセグメントであろうと、これらの段階を経ます. この分類のルールは、ユーザーが ES でデータを非常にうまく管理するのに役立ちます. ユーザーは、さまざまな段階のルールを自分で定義できます.
ノードの役割
ES では、各展開ノードには、ノード ロールであるノード ロールがあります。各 ES ノードには、マスター、データ、取り込みなど、さまざまな役割が割り当てられます。ユーザーは、データ管理のためにノードの役割と上記のさまざまなライフサイクルの段階を組み合わせることができます。
データ ノードにはさまざまな段階があり、ホット データを格納するノード、ウォーム データ、コールド データ、さらには非常にコールド データを格納するノードなどがあります。機能に応じてノードに異なる役割を割り当て、異なる役割を持つノードには異なるハードウェアを構成する必要があります。
例えば、ホットデータノードの場合は高性能なCPUやディスクを構成する必要があり、ウォームデータノードとコールドデータノードの場合は基本的にデータのクエリ頻度が低いと考えられます.現時点では、特定のコンピューティングリソースのハードウェア要件は次のとおりです.実際にはそれほど高くありません。
ノードの役割は、ライフ サイクルのさまざまな段階に応じて定義されますが、各 ES ノードは複数の役割を持つことができ、これらの役割は 1 対 1 で対応していないことに注意してください。例を挙げます.ESのYAMLファイルで構成する場合,node.rolesはノードの役割の構成です.このノードが持つべき役割に応じて,このノードに複数の役割を構成することができます.
node.roles: ["data_hot", "data_content"]
ライフサイクル ポリシー
データ ストリーム、インデックス ライフサイクル管理、およびノード ロールの概念を理解したら、データのさまざまなライフサイクル ポリシーを作成できます。
インデックスのサイズ、インデックス内のドキュメントの数、インデックスが作成された時間など、ライフ サイクル ポリシーで定義されたさまざまなディメンションのインデックスの特性に従って、ES はユーザーがデータをロールするのを自動的に支援できます。あるライフ サイクル ステージから別のステージへ。ES の用語はロールオーバーです。
たとえば、ユーザーはインデックス サイズ ディメンションに基づいて機能を指定したり、ホット データをウォーム データにロールしたり、ウォーム データをコールド データにロールしたりすることができます。このようにして、インデックスがライフ サイクルのさまざまな段階間でロールされると、対応するインデックス付きデータも移行およびロールされます。ES はこれらのタスクを自動的に完了できますが、ライフサイクル ポリシーはユーザーが定義する必要があります。
以下のスクリーンショットは、ユーザーがライフサイクル ポリシーをグラフィカルに構成できる Kibana の管理インターフェイスです。上からホットデータ、ウォームデータ、コールドデータの 3 つの段階があることがわかります。
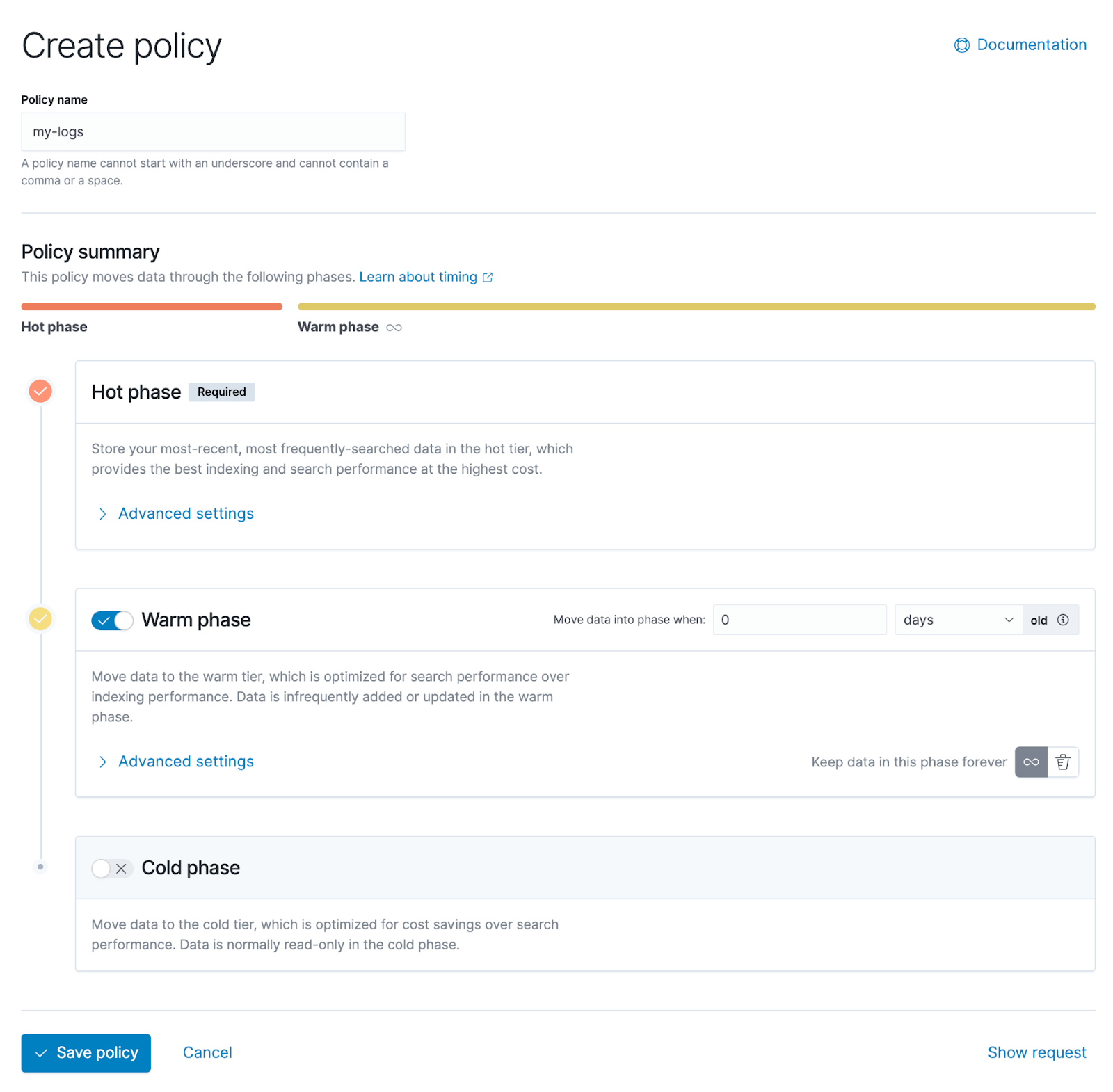
ホット データ ステージの詳細設定を展開すると、下の図の右側に示されている 3 つのオプションなど、さまざまな次元の特性に基づいた上記のポリシー構成の詳細を確認できます。
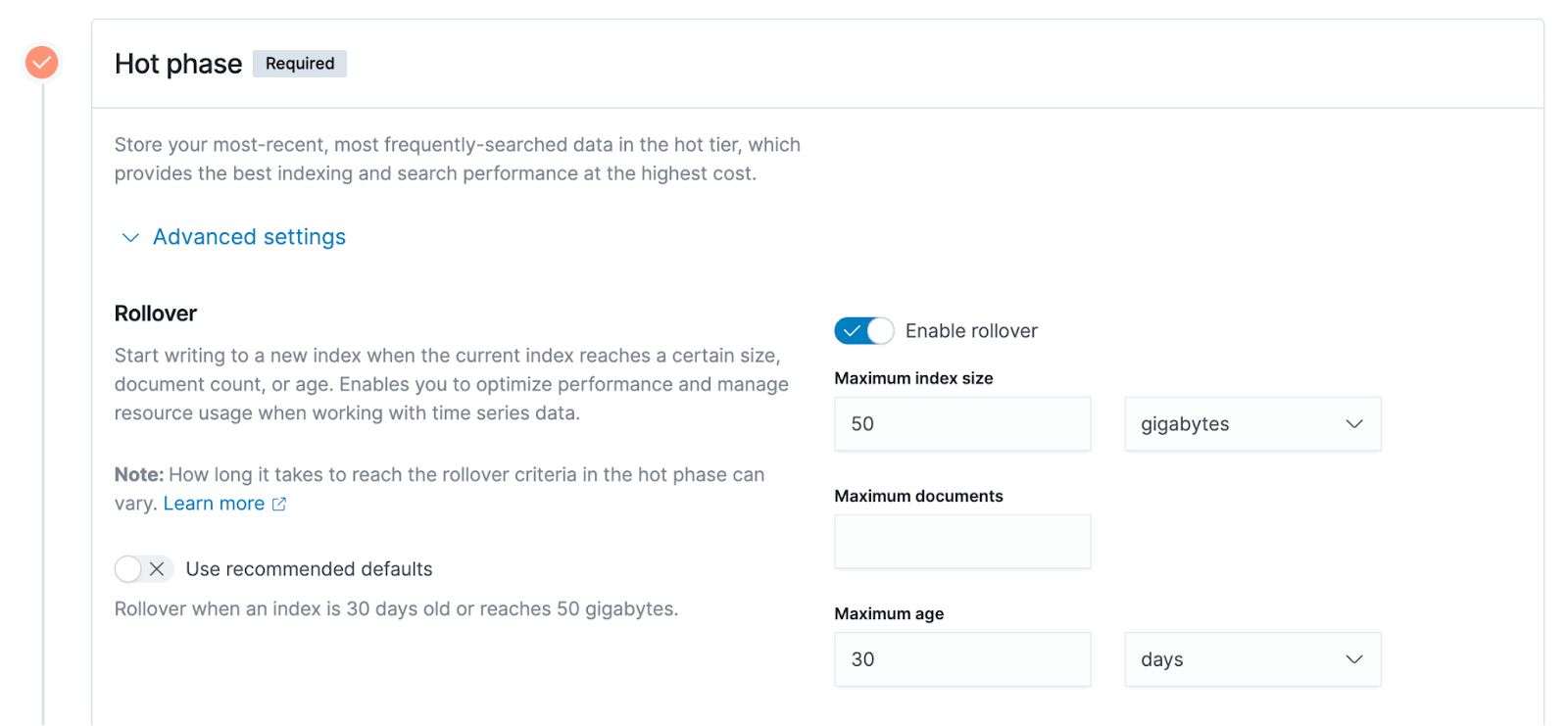
- インデックスのサイズは、図の例では 50GB です。インデックスのサイズが 50GB を超えると、ホット データ ステージからウォーム データ ステージにロールされます。
- ドキュメントの最大数、ES のインデックス単位はドキュメントであり、ユーザー データはドキュメントの形式で ES に書き込まれるため、ドキュメントの数も測定可能な指標です。
- インデックス作成の最大時間. この例では 30 日です. インデックスが 30 日間作成されたとします. この時点で、前述のホット データ ステージからウォーム データへのロールオーバーがトリガーされます.
02- ClickHouse データ階層化アーキテクチャの詳細な説明
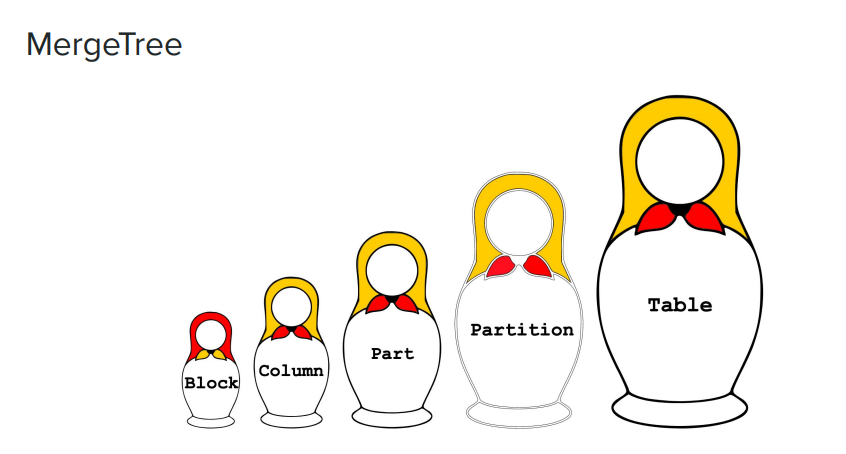
下の写真は、大きなものから小さなものまでロシアの入れ子人形のセットで、MergeTree エンジンである ClickHouse のデータ管理モードを鮮明に示しています。
- 表: 写真の右端にあるのは最大の概念です。ユーザーが最初に作成したり、直接アクセスしたりしたいのは表です。
- パーティション: より小さな次元またはより小さな粒度です。ClickHouse では、データはストレージ用のパーティションに分割され、各パーティションには識別子があります。
- パート: 各パーティションでは、さらに複数のパートに分割されます。ClickHouse ディスクに保存されているデータ形式を見ると、各サブディレクトリがパーツであると考えることができます。
- 列: パートには、粒度の細かいデータ、つまり列が表示されます。ClickHouse のエンジンは列型ストレージを使用し、すべてのデータは列型ストレージに編成されます。パーツ ディレクトリには多くの列が表示されます。たとえば、テーブルに 100 列ある場合、100 列のファイルがあります。
- ブロック: 各列ファイルは、ブロックの粒度に従って編成されます。
次の例では、テーブル ディレクトリの下に 4 つのサブディレクトリがあり、各サブディレクトリが上記のパーツです。
$ ls -l /var/lib/clickhouse/data/<database>/<table>
drwxr-xr-x 2 test test 64B Aug 8 13:46 202208_1_3_0
drwxr-xr-x 2 test test 64B Aug 8 13:46 202208_4_6_1
drwxr-xr-x 2 test test 64B Sep 8 13:46 202209_1_1_0
drwxr-xr-x 2 test test 64B Sep 8 13:46 202209_4_4_
図の右端の列では、各サブディレクトリの名前の前に 202208 のような時間が付いている場合があり、これはこのようなプレフィックスであり、202208 は実際にはパーティションの名前です。パーティション名はユーザー自身が定義しますが、慣習や慣行に従って、通常は時間を使用して名前を付けます。
たとえば、パーティション 202208 には 2 つのサブディレクトリがあり、サブディレクトリはパーツです。通常、パーティションは複数のパーツで構成されます。ユーザーがClickHoueにデータを書き込むと、データは最初にメモリに書き込まれ、次にメモリ内のデータ構造に従ってディスクに永続化されます。同じパーティション内のデータが比較的大きい場合、ディスク上で多くの部分になります。ClickHouse は公式に、テーブルの下にあまりにも多くのパーツを作成しないことを推奨しています. パーツの総数を減らすために、定期的または不定期にパーツをマージします. Merge の概念は、MergeTree エンジンの名前の由来の 1 つである Part をマージすることです。
例を通して Part を理解しましょう。Part には多くの小さなファイルがあり、その中にはインデックス情報などのメタ情報があり、ユーザーがデータをすばやく見つけるのに役立ちます。
$ ls -l /var/lib/clickhouse/data/<database>/<table>/202208_1_3_0
-rw-r--r-- 1 test test ?? Aug 8 14:06 ColumnA.bin
-rw-r--r-- 1 test test ?? Aug 8 14:06 ColumnA.mrk
-rw-r--r-- 1 test test ?? Aug 8 14:06 ColumnB.bin
-rw-r--r-- 1 test test ?? Aug 8 14:06 ColumnB.mrk
-rw-r--r-- 1 test test ?? Aug 8 14:06 checksums.txt
-rw-r--r-- 1 test test ?? Aug 8 14:06 columns.txt
-rw-r--r-- 1 test test ?? Aug 8 14:06 count.txt
-rw-r--r-- 1 test test ?? Aug 8 14:06 minmax_ColumnC.idx
-rw-r--r-- 1 test test ?? Aug 8 14:06 partition.dat
-rw-r--r-- 1 test test ?? Aug 8 14:06 primary.id
例の右側で、Column という接頭辞が付いているファイルは実際のデータ ファイルであり、通常、メタ情報に比べてサイズが大きくなります。この例では、A と B の 2 つの列しかありませんが、実際のテーブルには多くの列が存在する場合があります。メタ情報やインデックス情報を含むこれらのファイルはすべて連携して機能するため、ユーザーは異なるファイル間をすばやく移動したり検索したりできます。
ClickHouse ストレージ戦略
ClickHouse でホット データとコールド データを階層化する場合は、ES で言及されているのと同様のライフサイクル ポリシーを使用します。これは、ClickHouse のストレージ ポリシーと呼ばれます。
ES とは少し異なり、ClickHouse は正式にはデータをホット データ、ウォーム データ、コールド データなどの異なる段階に分けません. ClickHouse はいくつかのルールと構成方法を提供し、ユーザーは自分で層化戦略を策定する必要があります.
各 ClickHouse ノードは同時に複数のディスクの構成をサポートし、ストレージ メディアはさまざまです。たとえば、一般ユーザーはパフォーマンスのために ClickHouse ノード用に SSD ディスクを構成します; 一部のウォーム データとコールド データについては、ユーザーは機械ディスクなどの低コストのメディアにデータを保存できます。ClickHouse ユーザーは、基になるストレージ メディアを認識していません。
ES と同様に、ClickHouse ユーザーは、各部分サブディレクトリのサイズ、ディスク全体の残りのスペースの割合など、データのさまざまな次元特性に基づいてストレージ戦略を策定する必要があります。特定の次元特性によって設定された条件が満たされると、ストレージがトリガーされます 戦略の実行。この戦略は、あるディスクから別のディスクにパーツを移行します。ClickHouseでは、ノードによって構成された複数のディスクが優先されます. デフォルトでは、データは最も優先度の高いディスクに配置されます. これにより、ある記憶媒体から別の記憶媒体にパーツを転送できます。
MOVE PARTITION/PART コマンドなど、ClickHouse の一部の SQL コマンドは、データ移行を手動でトリガーでき、ユーザーはこれらのコマンドを使用して機能検証を行うこともできます。第 2 に、場合によっては、現在のストレージ メディアから別のストレージ メディアに、自動転送ではなく手動でパーツを明示的に転送することが望ましい場合もあります。
ClickHouse は、ストレージ ポリシーとは独立した概念である、時間ベースの移行ポリシーもサポートしています。データが書き込まれた後、ClickHouse は、各テーブルの TTL 属性によって設定された時間に従って、ディスク上のデータ移行をトリガーします。たとえば、TTL が 7 日に設定されている場合、ClickHouse は現在のディスク (デフォルトの SSD など) から優先度の低い別のディスク (JuiceFS など) に、テーブル内のデータを 7 日以上書き込みます。
03- ウォーム データ ストレージとコールド データ ストレージ: オブジェクト ストレージ + JuiceFS を使用する理由
企業がウォーム データとコールド データをクラウドに保存すると、従来の SSD アーキテクチャに比べてストレージ コストが大幅に削減されます。企業はまた、クラウド上の柔軟なスケーリング スペースを利用できます。拡張と縮小などのデータ ストレージの操作と保守操作、またはデータ クリーニング作業を行う必要はありません。ウォーム データとコールド データに必要なストレージ容量は、ホット データに比べてはるかに大きく、特に時間の経過とともに、長期間保存する必要のある大量のデータが生成されます.これらのデータをローカルに保存すると、対応する運用と保守作業が圧倒されます。
しかし、Elasticsearch や ClickHouse などのデータアプリケーション コンポーネントをオブジェクト ストレージ上で使用すると、書き込みパフォーマンスの低下や互換性の低下などの問題が発生します。クエリのパフォーマンスを考慮したい企業は、クラウド上のソリューションを探し始めました。この文脈において、JuiceFS はデータ階層化アーキテクチャでますます使用されています。
以下のClickHouseの書き込み性能テストを通じて、SSD、JuiceFS、オブジェクトストレージへの書き込みの性能差を直感的に理解することができます。
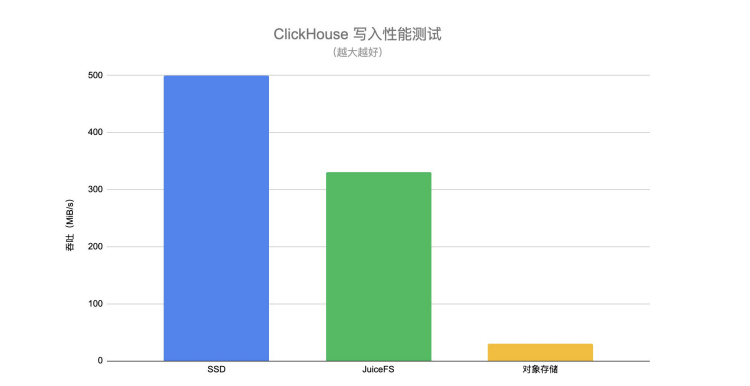
JuiceFS の書き込みスループットは、直接接続されたオブジェクト ストレージよりもはるかに高く、SSD に近い値です。ユーザーがホット データをウォーム データ レイヤーに転送する場合、書き込みパフォーマンスに関する特定の要件もあります。移行プロセス中、基盤となるストレージ メディアの書き込みパフォーマンスが低い場合、移行プロセス全体が長時間に及ぶことになり、パイプライン全体またはデータ管理にもいくつかの課題が生じます。
下の図の ClickHouse クエリ パフォーマンス テストでは、実際のビジネス データを使用し、テスト用にいくつかの典型的なクエリ シナリオを選択します。このうち、q1~q4 はテーブル全体をスキャンするクエリであり、q5~q7 は主キー インデックスにヒットするクエリです。テスト結果は次のとおりです。
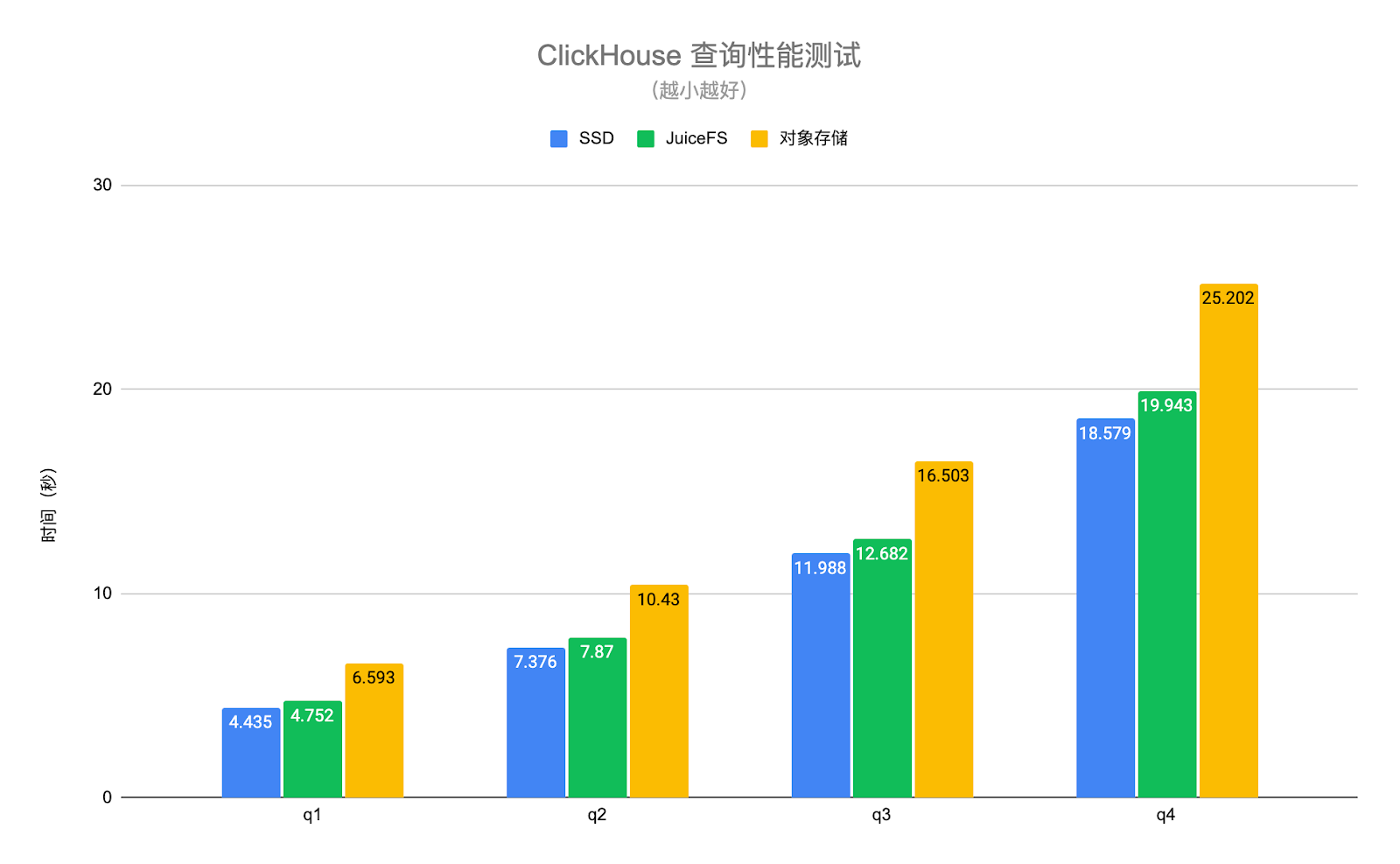
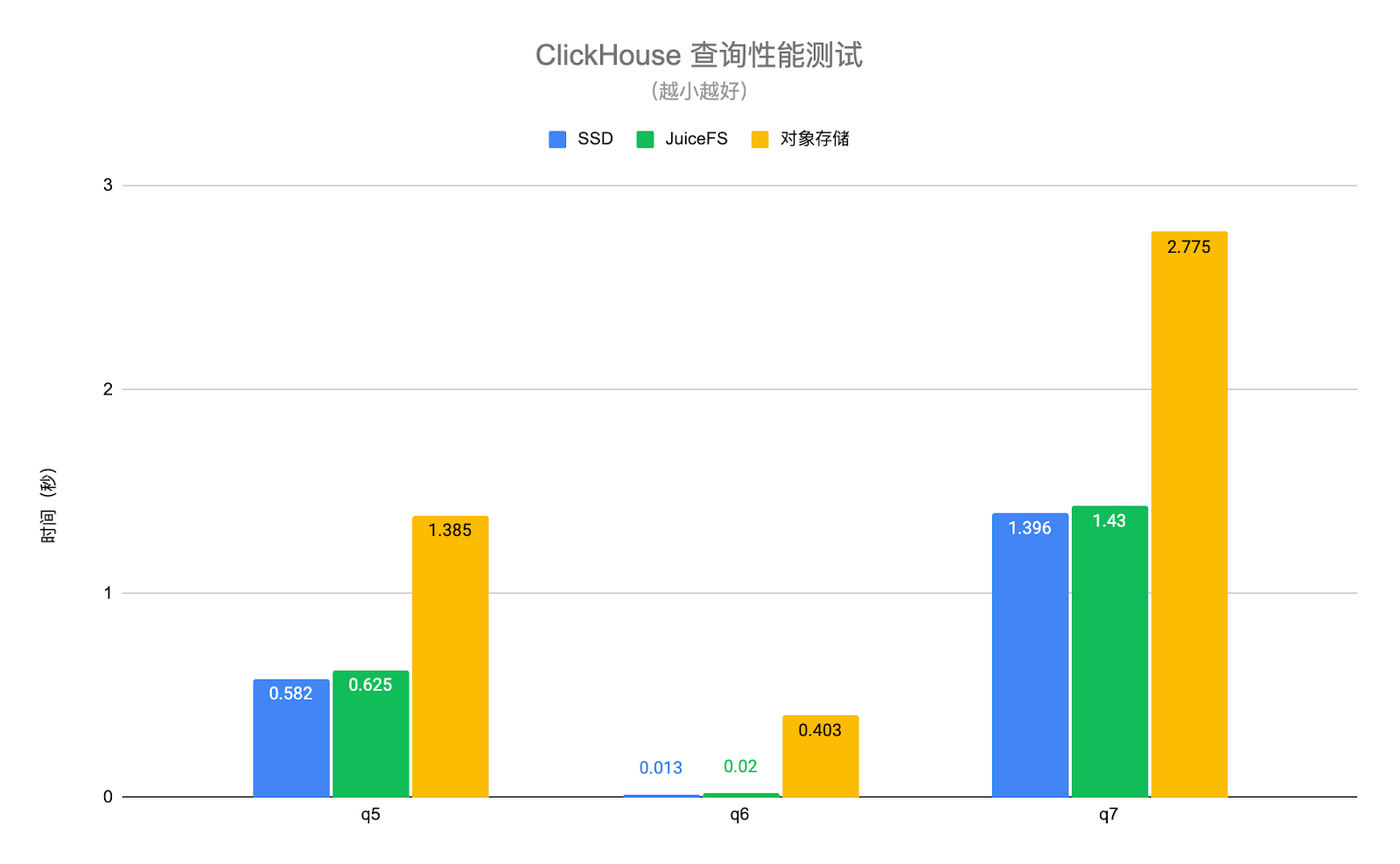
JuiceFS ディスクと SSD ディスクのクエリ パフォーマンスは基本的に同じで、平均で約 6% の差がありますが、オブジェクト ストレージのパフォーマンスは SSD ディスクの 1.4 倍から 30 倍低くなります。JuiceFS の高性能メタデータ操作とローカル キャッシング機能のおかげで、クエリ リクエストに必要なホット データを自動的に ClickHouse ノードにローカルにキャッシュできます。これにより、ClickHouse のクエリ パフォーマンスが大幅に向上します。上記のテストのオブジェクト ストレージは、ClickHouse の S3 ディスク タイプを介してアクセスされることに注意してください. このようにして、データのみがオブジェクト ストレージに保存され、メタデータはローカル ディスクに残ります. オブジェクト ストレージが S3FS と同様の方法でローカルにマウントされている場合、パフォーマンスはさらに低下します。
また、JuiceFS は完全に POSIX 互換のファイル システムであり、上位層のアプリケーション (Elasticsearch、ClickHouse など) との互換性が高いことにも言及する価値があります。ユーザーは、基盤となるストレージが分散ファイル システムなのかローカル ディスクなのかを認識していません。オブジェクトストレージをそのまま使用すると、上位層のアプリケーションとの互換性がうまくとれません。
04- 実運用 : ES + JuiceFS
ステップ 1: 複数のタイプのノードを準備し、異なるロールを割り当てます。各 ES ノードには、ホット データ、ウォーム データ、コールド データの保存など、さまざまな役割を割り当てることができます。ユーザーは、さまざまな役割のニーズに合わせて、さまざまなモデルのノードを準備する必要があります。
ステップ 2: JuiceFS ファイル システムをマウントします。一般に、ユーザーはウォーム データ ストレージとコールド データ ストレージに JuiceFS を使用します. ユーザーは、JuiceFS ファイル システムを ES ウォーム データ ノードまたはコールド データ ノードにローカルにマウントする必要があります. ユーザーは、シンボリック リンクまたはその他の方法で ES へのマウント ポイントを構成できます。これにより、ES はデータがローカル ディレクトリに格納されていると認識しますが、このディレクトリの背後には実際には JuiceFS ファイル システムがあります。
ステップ 3: ライフサイクル ポリシーを作成します。これは、各ユーザーがカスタマイズする必要があります. ユーザーは、ES API または Kibana を介して作成できます. Kibana には、ライフサイクル ポリシーを作成および管理するための比較的便利な方法がいくつか用意されています。
ステップ 4: インデックスのライフサイクル ポリシーを設定します。ライフサイクル ポリシーを作成した後、ユーザーはこのポリシーをインデックスに適用する必要があります。つまり、新しく作成したポリシーをインデックスに設定します。ユーザーは、インデックス テンプレートを介して Kibana でインデックス テンプレートを作成するか、index.lifycycle.name を介して API を介して明示的に構成できます。
いくつかのヒントを次に示します。
ヒント 1: ウォーム ノードまたはコールド ノードのコピー (レプリカ) の数は 1 に設定できます。すべてのデータは基本的に JuiceFS に配置され、その最下層はオブジェクト ストレージであるため、データの信頼性はすでに十分に高く、ES 側でコピーの数を適切に減らしてストレージ スペースを節約できます。
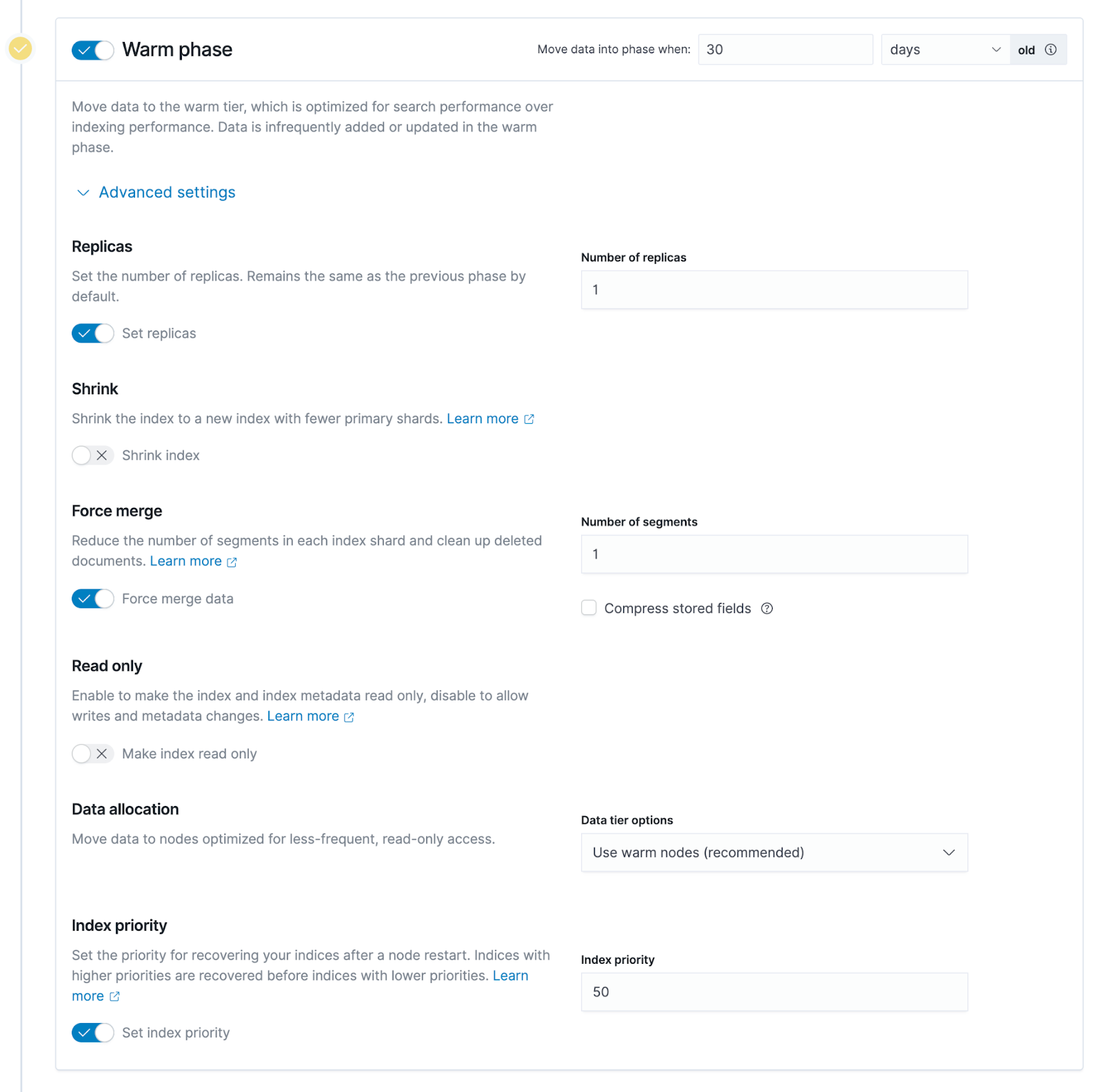
ヒント 2: Force merge をオンにすると、ノードの CPU が継続的に占有される可能性があるため、必要に応じてオフにします。ホット データからウォーム データに転送する場合、ES はすべてのホット データ インデックスに対応する基になるセグメントをマージします。強制マージ機能が有効になっている場合、ES はまずこれらのセグメントをマージしてから、ウォーム データの基盤となるシステムに格納します。ただし、セグメントのマージは非常に CPU を集中的に使用するプロセスです. ウォーム データのデータ ノードもいくつかのクエリ リクエストを実行する必要がある場合は、必要に応じてこの機能をオフにすることができます。保管所。
ヒント 3: ウォーム フェーズまたはコールド フェーズのインデックスは、読み取り専用に設定できます。ウォーム データとコールド データ ステージのインデックスを作成する場合、基本的にこれらのデータは読み取り専用であると見なすことができ、これらのステージのインデックスは変更されません。読み取り専用に設定すると、一部のメモリを解放するなど、ウォーム データ ノードとコールド データ ノードのリソースを適切に削減できるため、ウォーム ノードまたはコールド ノードのハードウェア リソースを節約できます。
05- 実際の操作: ClickHouse + JuiceFS
**ステップ 1: すべての ClickHouse ノードに JuiceFS ファイル システムをマウントします。**ClickHouseにはマウントポイントを指す構成ファイルがあるため、このパスは任意のパスにすることができます.
**ステップ 2: ClickHouse 構成を変更し、JuiceFS ディスクを追加します。** ClickHouse に新しくマウントされた JuiceFS ファイル システム マウント ポイントを追加して、ClickHouse が新しいディスクを認識できるようにします。
**ステップ 3: ストレージ ポリシーを追加し、シンク データのルールを設定します。**このストレージ ポリシーは、ユーザーのルールに従って、既定のディスクから特定のディスク (JuiceFS など) に不定期かつ自動的にデータをシンクします。
**ステップ 4: 特定のテーブルのストレージ ポリシーと TTL を設定します。**ストレージ戦略が定式化されたら、特定のテーブルに適用する必要があります。テストと検証の初期段階では、比較的大きなテーブルをテストと検証に使用できます.ユーザーが時間ディメンションに基づいてデータをシンクしたい場合は、テーブルにTTLも設定する必要があります. シンクプロセス全体は自動メカニズムです. ClickHouseのシステムテーブルを介して、現在データ移行中の部分と移行の進行状況を確認できます.
**ステップ 5: 検証のためにパーツを手動で移動します。** MOVE PARTITION コマンドを手動で実行して、現在の構成またはストレージ ポリシーが有効かどうかを確認できます。
下の図は具体的な例です. ClickHouse には という storage_configuration 設定項目があり, これにはディスクの設定が含まれています. ここではディスクとして JuiceFS を追加します. ここでは "jfs" という名前を付けますが, 任意の名前でマウントできます. . ドットは /jfsディレクトリです。
<storage_configuration> <disks> <jfs> <path>/jfs</path> </jfs> </disks> <policies> <hot_and_cold> <volumes> <hot> <disk>default</disk> <max_data_part_size_bytes>1073741824</max_data_part_size_bytes> </hot> <cold> <disk>jfs</disk> </cold> </volumes> <move_factor>0.1</move_factor> </hot_and_cold> </policies></storage_configuration>
さらに下にはポリシー構成項目があり、これは hot_and_cold と呼ばれるストレージ ポリシーを定義します。ユーザーは特定のルールを定義する必要があります。たとえば、ボリュームは最初にホット、次にコールドの優先度に従って配置され、データは最初にボリュームディスクで最初にホットし、デフォルトのClickHouseディスク、通常はローカルSSDです。
ボリュームの max_data_part_size_bytes 構成は、特定の部分のサイズが設定サイズを超えると、ストレージ ポリシーの実行がトリガーされ、対応する部分が次のボリューム、つまりコールド ボリュームにシンクされることを示します。上記の例では、コールド ボリュームは JuiceFS です。
下部の 構成move_factor は、ClickHouse が現在のディスクの残りのスペース比率に従ってストレージ ポリシーの実行をトリガーすることを意味します。
CREATE TABLE test ( d DateTime, ...) ENGINE = MergeTree...TTL d + INTERVAL 1 DAY TO DISK 'jfs'SETTINGS storage_policy = 'hot_and_cold';
上記のコードに示すように、ストレージ ポリシーを設定した後、テーブルを作成するか、このテーブルのスキーマを変更するときに、SETTINGS の storage_policy を以前に定義した hot_and_cold ストレージ ポリシーに設定できます。上記のコードの最後から 2 番目の行の TTL は、前述の時間ベースの階層化ルールです。In this example, a column named d in the specified table is of DateTime type. INTERVAL 1 DAY を組み合わせると、新しいデータが 1 日以上書き込まれると、そのデータが JuiceFS に転送されます。
06- 見通し
**まず、共有をコピーします。**ES であろうと ClickHouse であろうと、データの可用性と信頼性を確保するために複数のコピーがあります。JuiceFS は基本的に共有ファイル システムであるため、データの一部が JuiceFS に書き込まれた後は、複数のコピーを維持する必要はありません。たとえば、ユーザーが 2 つの ClickHouse ノードを持っていて、どちらにも特定のテーブルまたは特定の部分のコピーがあり、両方のノードが JuiceFS に沈められている場合、同じデータが 2 回書き込まれる可能性があります。** 将来的には、下位層が共有ストレージを使用していることを上位層エンジンに認識させ、データがシンクするときにコピーの数を減らして、異なるノード間でコピーを共有できるようにすることはできますか。** アプリケーション レイヤーの観点から、ユーザーがテーブルを表示するとき、パーツの数はまだ複数のコピーですが、データは本質的に共有できるため、実際には 1 つのコピーのみが下層のストレージに保持されます。
** 2点目、障害回復。**データがリモート共有ストレージに沈められた後、ES または ClickHousle ノードに障害が発生した場合、障害から迅速に回復するにはどうすればよいですか? ホット データを除くほとんどのデータは、実際にリモートの共有ストレージに転送されています.この時点で、復元または新しいノードを作成する場合、コストは、従来のローカル ディスク ベースの障害回復方法よりもはるかに軽くなります。 ES または ClickHouse のシナリオで検討する価値があります。
**3点目は、記憶と計算の分離です。** ES や ClickHouse に関係なく、コミュニティ全体が、これらの従来のローカル ディスク ベースのストレージ システムを、クラウド ネイティブ環境で実際のストレージ コンピューティング分離システムにする方法を試したり、検討したりしています。ただし、ストレージとコンピューティングの分離は、単にデータをコンピューティングから分離するだけではなく、クエリ性能の要件、書き込み性能の要件、さまざまなディメンションのチューニングの要件など、上位層のさまざまな複雑な要件を満たす必要があります。株式分離の一般的な方向性について検討する価値のある多くの技術的な問題がまだあります。
**第 4 のポイント、他の上位レベルのアプリケーション コンポーネントのデータ階層化調査。**ES と ClickHouse の 2 つのシナリオに加えて、最近、Apache Pulsar のウォーム データとコールド データを JuiceFS にシンクする試みもいくつか行いました.使用される戦略とソリューションのいくつかは、この記事で説明したものと似ています. Apache Pulsar では、シンクする必要があるデータ型またはデータ形式が異なります。さらに成功した練習の後、それは共有されます。
関連資料: