
iQiyi は、会社の運営上の意思決定、ユーザーの増加、ビデオの推奨、メンバーシップ、広告、その他のビジネス ニーズをサポートするために、Hive に基づいて従来のオフライン データ ウェアハウスを構築しました。近年、企業のリアルタイム データに対する要求が高まっています。 Iceberg に基づくデータ レイク テクノロジーを導入し、データ クエリのパフォーマンスと全体的な循環効率を大幅に向上させました。パフォーマンスとコストの観点から、既存の Hive テーブルをデータ レイクに移行することが必要です。しかし、長年にわたり、数百ペタバイトの Hive データがビッグ データ プラットフォームに蓄積されており、Hive をデータ レイクに移行する方法が私たちが直面する大きな課題となっています。この記事では、Hive から Iceberg データ レイクへのスムーズな移行を実現する iQiyi の技術ソリューションを紹介し、企業がデータ プロセスを加速し、効率と収益を向上させるのに役立ちます。
01
ハイブ VS アイスバーグ
Hive は、複雑なデータ処理と分析をサポートする SQL に似た言語を提供する、Hadoop ベースのデータ ウェアハウスおよび分析プラットフォームです。
Iceberg は、分析ワークロードをサポートするためのスケーラブルで安定した効率的なテーブル ストレージを提供するように設計されたオープン ソース データ テーブル形式です。 Iceberg は、従来のデータベースと同様のトランザクション保証とデータ一貫性を提供し、更新や削除などの複雑なデータ操作をサポートします。
表 1-1 に、適時性、クエリ パフォーマンスなどの観点からの Hive と Iceberg の比較を示します。
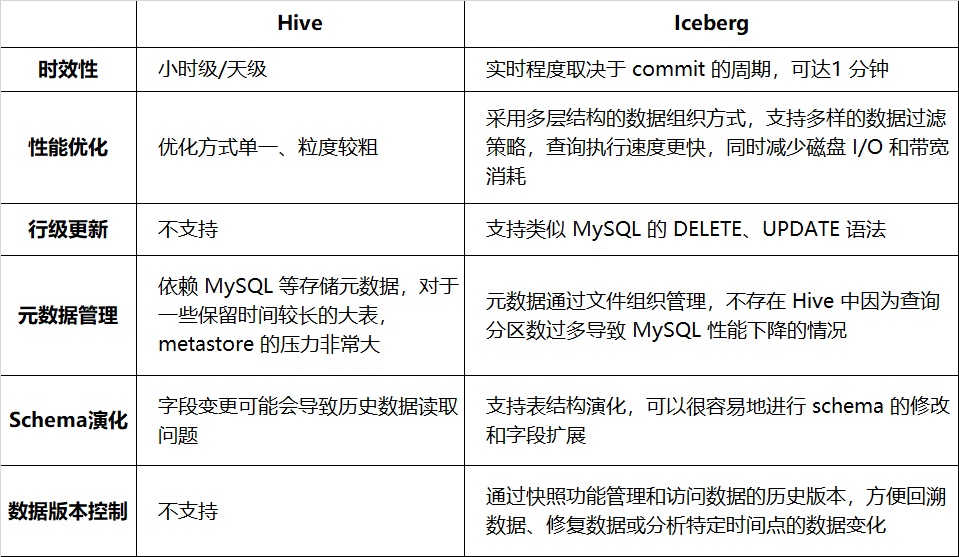
表 1-1 Hive と Iceberg の比較
Iceberg に切り替えることで、データ処理の効率と信頼性が向上し、複雑なデータ操作に対するサポートが向上します。現在、広告、メンバーシップ、Venus ログ、監査などの十数のビジネスに接続されています。 iQiyi の Iceberg の実践の詳細については、以前の一連の記事をご覧ください (記事の最後にある引用を参照)。
02
ハイストックデータのスムーズな切り替え Iceberg
Iceberg には Hive に比べて多くの利点がありますが、ビジネス データはすでに Hive 環境で実行されており、企業はインベントリ タスクの変更に多くの人的資源を投資したくありません。私たちは業界で一般的な切り替え方法を調査し[1]、データ レイク プラットフォーム上でセルフサービス Hive と Iceberg をスムーズに切り替える機能を提供しました。このセクションでは、具体的な実装計画について説明します。
1. 互換性を確認する
実際の切り替えの前に、Spark と Hive および Iceberg の互換性を検証しました。
Hive テーブルと Iceberg テーブルに対する Spark のクエリ構文と書き込み構文は基本的に同じです。Hive テーブルをクエリするための SQL ステートメントは、変更せずに Iceberg テーブルをクエリできます。
ただし、DDL に関しては、Iceberg と Hive の間には大きな違いがあり、主にテーブル構造の変更方法が異なります。詳細は表 2-1 に記載されているとおりです。実際のスキーマとデータ ファイルのスキーマは 1 対 1 に対応している必要があります。そうでない場合は、データのクエリに影響を与えるため、DDL ステートメントを処理するときはより慎重になる必要があります。このようなタスクを含む DDL ステートメント。
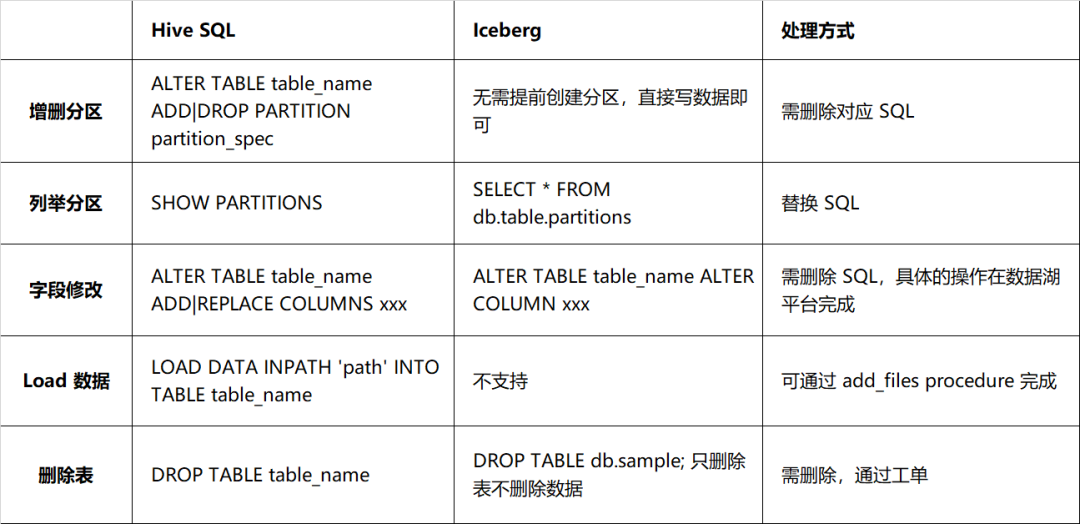
表 2-1 Hive と Iceberg の構文互換性の比較
2. 業界切り替えソリューション
2.1ビジネス二重書き込みスイッチング
このビジネスは、既存のパイプラインを複製して、Hive と Iceberg の二重書き込みを実装します。古いチャネルと新しいチャネルのペアが一致したら、Iceberg チャネルに切り替えて、元のチャネルからログオフします。このソリューションでは、企業は開発と計算に人的資源を投資する必要があり、時間と労力がかかります。
2.2スイッチが所定の位置にあると、クライアントは書き込みを停止します
ビジネスが一定期間書き込みを停止して切り替えることが許可されている場合は、次の方法を使用できます。
-
Spark移行手順は、Icebergが公式に提供している機能で、HiveテーブルをIcebergに切り替えることができます。例は次のとおりです。
CALL カタログ名.system.merge('db.sample'); |
このプログラムは元のデータを変更せず、元のテーブルのデータをスキャンするだけで、元のファイルを参照して Iceberg メタ情報を構築します。したがって、移行プログラムは非常に高速に実行されますが、既存のデータはファイル インデックスなどの機能を使用してクエリを高速化できません。既存のデータも高速化したい場合は、Spark のrewrite_data_filesメソッドを使用して履歴データを書き換えることができます。
移行プログラムは Hive テーブルを削除しませんが、このテーブルの名前をsample__BACKUP__ に変更します。ロールバックする必要がある場合は、新しく作成した Iceberg テーブルを削除し、Hive テーブルの名前を元に戻すことができます。
-
CTASステートメントを使用したSpark の例は次のとおりです。
CREATE TABLE db.sample_iceberg 氷山の使用 dt で分割 場所「qbfs://....」 TBLPROPERTIES('書き込み.ターゲット ファイル サイズ バイト' = '512m', ...) AS SELECT * FROM db.sample; |
書き込み完了後、対数計算を行い、条件を満たした後、リネームを行うことで切り替えが完了します。
ALTER TABLE db.sample RENAME TO db.sample_backup; ALTER TABLE db.sample_iceberg RENAME TO db.sample; |
移行と比較した CTAS の利点は、既存のデータが書き換えられるため、パーティション分割、列の並べ替え、ファイル形式、小さなファイルなどを最適化できることです。欠点は、既存のデータが大量にある場合、再書き込みに時間がかかり、リソースが大量に消費されることです。
上記 2 つのソリューションには次の特徴があります。
アドバンテージ:
解決策は簡単で、既存の SQL を実行するだけです。
ロールバック可能、元の Hive テーブルはまだ存在します
欠点:
書き込み/読み取りが検証されていません: Iceberg テーブルに切り替えた後、書き込みまたはクエリの例外が発生する可能性があります
切り替えプロセスに書き込みの停止を要求することは、一部の企業では受け入れられません。
3.iQiyi スムーズな移行計画
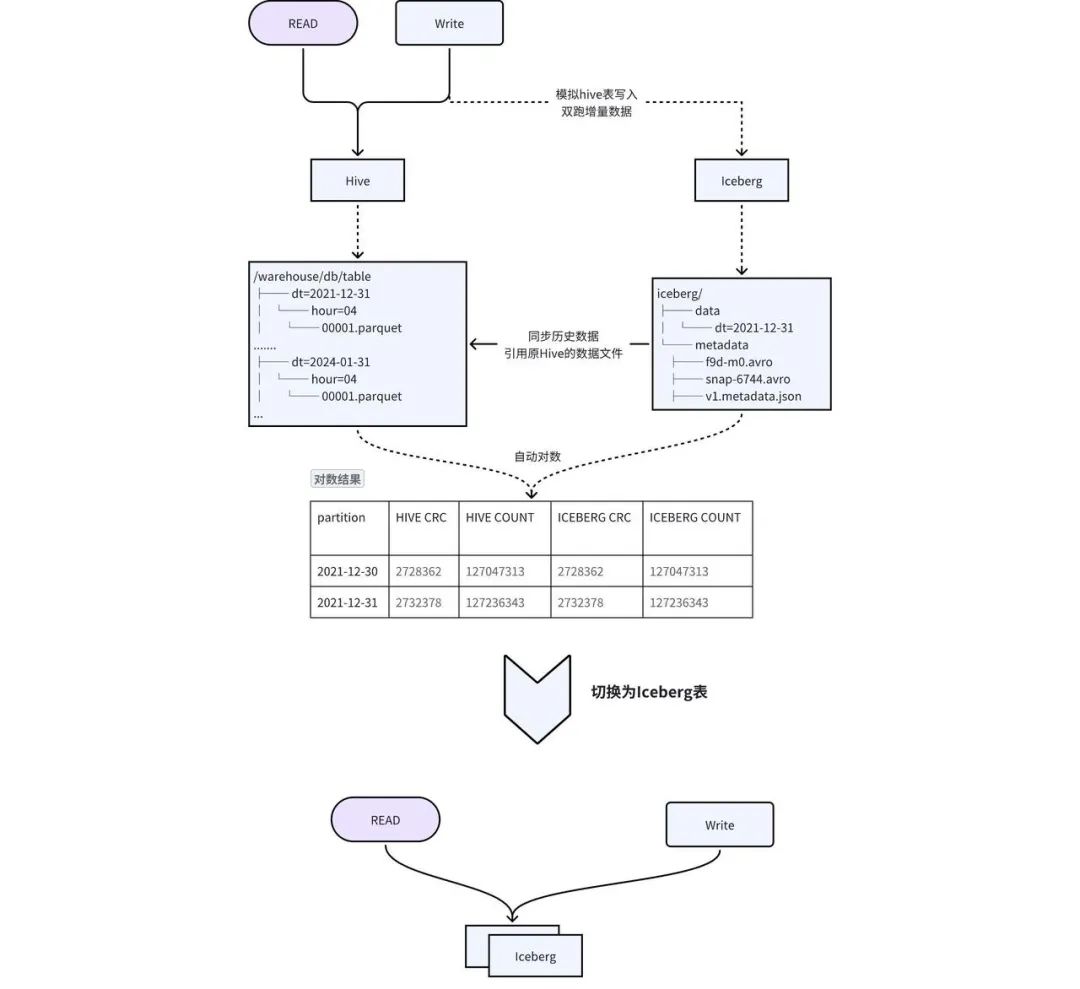
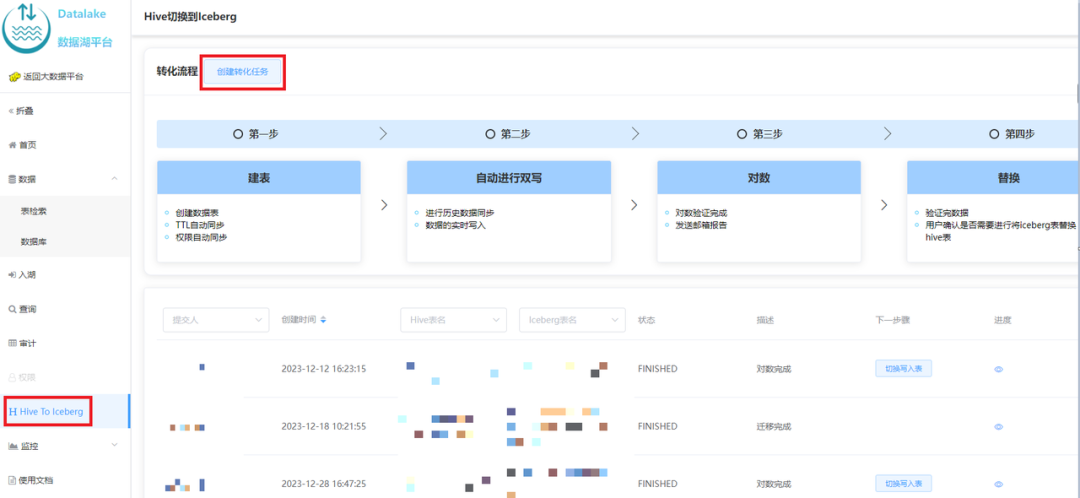
上記のソリューションの欠点を考慮して、図 2-1 に示すように、スムーズな移行を実現するために、インプレース二重書き込み + 透過的スイッチングのソリューションを設計しました。
-
テーブル作成: Hive と同じスキーマで Iceberg テーブルを作成し、Hive テーブルの TTL や権限などのメタ情報を Iceberg テーブルに同期します。 -
履歴データを Icebergに移行する: Hive の履歴データは、 add_fileプロシージャによって Iceberg に追加されます。実際、Iceberg のメタデータは Hive のデータ ファイルを指し、データの冗長性と履歴データの同期時間を短縮します。 -
増分データの二重書き込み : iQIYI が自社開発した Pilot SQL ゲートウェイは、Hive テーブルへの書き込みタスクを検出し、SQL を自動的にコピーして書き込み、出力を Iceberg テーブルに置き換えて二重書き込みを実現します。 -
数据一致性 校验: 当历史数据同步完成且增量双写到一定次数之后,后台会自动发起对数,校验 Hive 和 Iceberg 中的数据是否一致。对于历史数据与增量数据会选取一部分数据进行 count 以及字段 CRC 数值校验。 -
切换 : 数据一致性校验完成后,进行 Hive 和 Iceberg 的切换,用户不需要修改任务,直接使用原来的表名进行访问即可。正常切换过程耗时在几分钟之内。
03
核心收益 - 加速查询
1. Iceberg 查询加速技术
2. Iceberg 加速技巧
-
配置分区:使用分区剪裁的方式使查询只针对特定分区的数据执行,而不需要扫描整个数据集。 -
指定排序列:通过对数据分布进行合理的组织,最大限度的发挥文件级别的过滤效果,使得查询只集中在特定的文件。例如通过下面的方式使得写入 sample 表的数据按照 category, id 降序写入,注意由于多了一个排序的环节,这种方式会比非排序的写入耗时长。
|
|
-
高基数列应用布隆过滤器:在查询数据时,会自动应用布隆过滤器来快速验证查询数据是否存在于某个数据块,避免不必要的磁盘访问。
|
|
-
使用 Trino 代替 Spark:由于 Trino 自身 MPP 的架构,在查询上相较于 Spark 更有优势,并且 Trino 自身对 Iceberg 也有相应的优化,因此如果有秒级查询的需求,可将引擎由 Spark 切换到 Trino。 -
Alluxio 缓存:使用 Alluxio 作为数据缓存层,将数据缓存在内存中。在查询时可以直接从内存中获取数据,避免从磁盘读取数据的开销,可大大提高查询速度,也可防止 HDFS 抖动对任务的影响。 -
ORC 代替 Parquet:由于 Trino 对 ORC 格式有特定的优化,使得 ORC 的读取性能要优于 Parquet,可以将文件格式设置为 ORC 加速查询。 -
配置合并:写 Iceberg 的任务往往会出现写入文件较小但数量较多的情况,通过将小文件合并成一个或少量更大的文件,有利于减少读取的文件数,降低磁盘 I/O。
3. 性能评测
3.1 文件内过滤性能提升
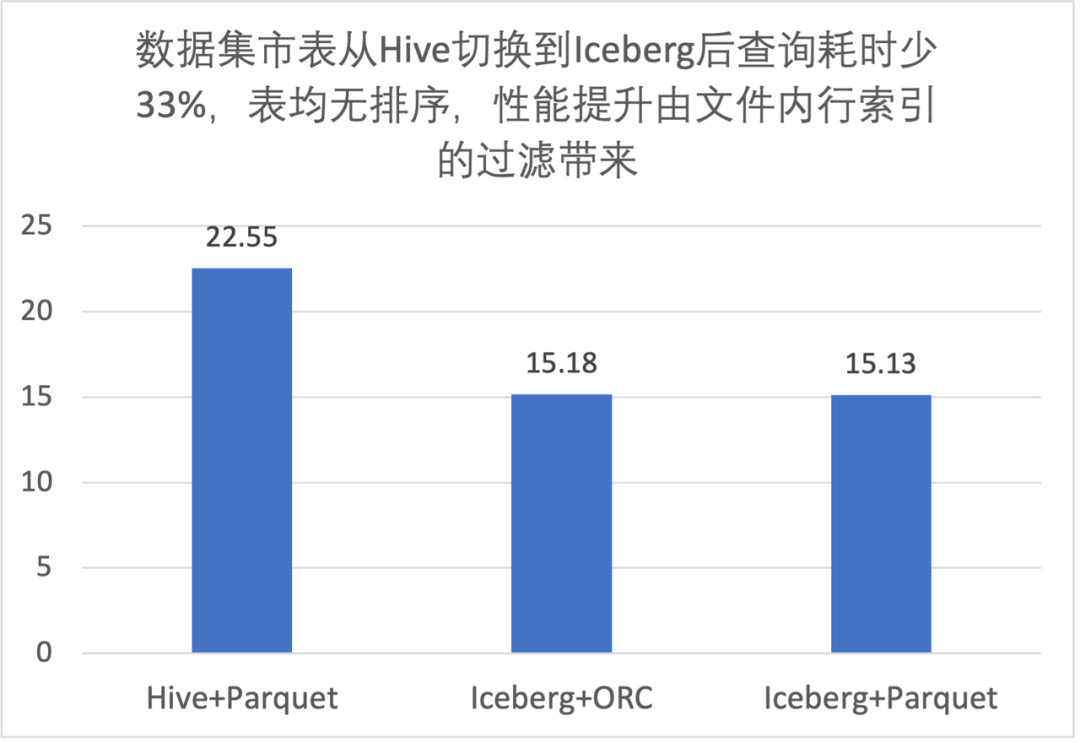
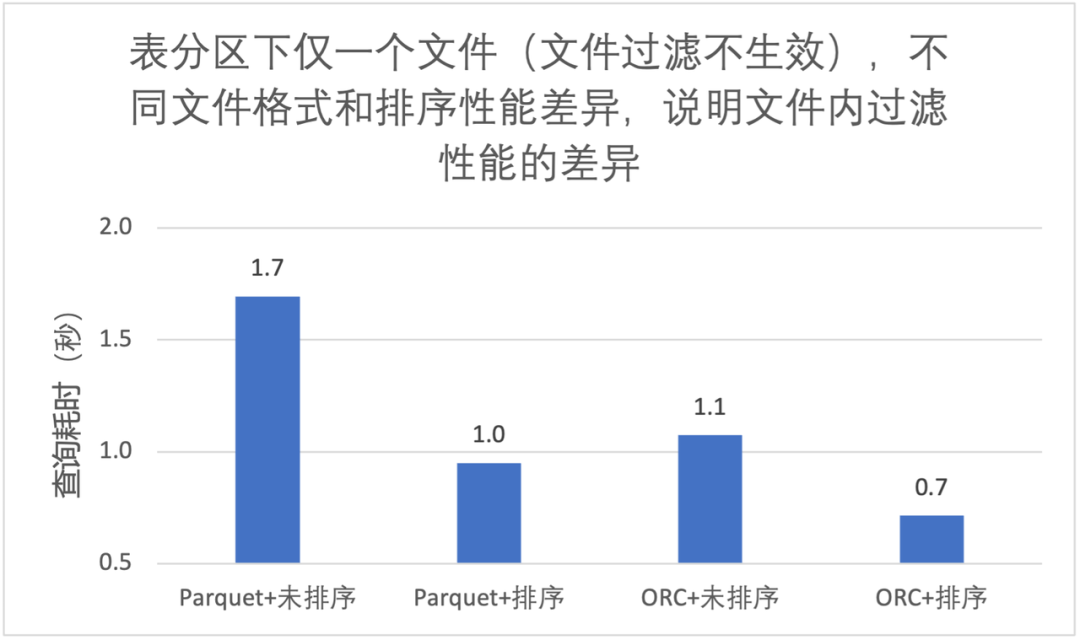
3.2 列排序对文件内过滤性能提升
-
同样的文件格式,排序后文件内过滤效果更好,大致能快 40%; -
ORC 查询性能优于 Parquet; -
使用 Trino 查询,我们推荐 Iceberg 表 + ORC 文件格式 + 列排序;
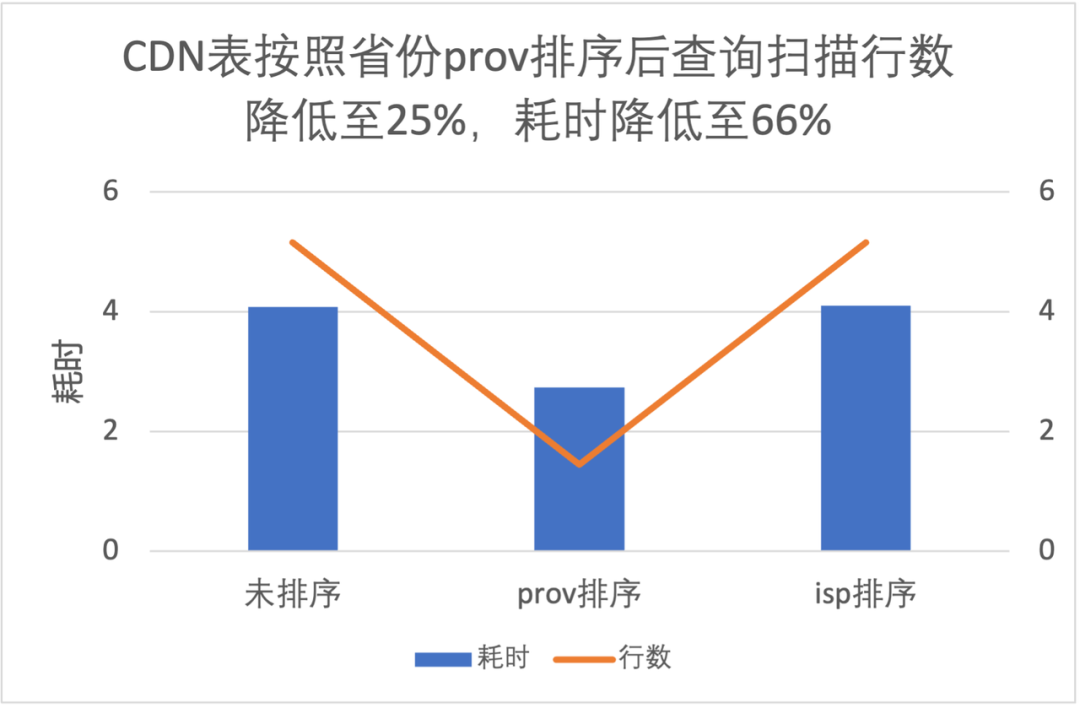
3.3 列排序对文件级过滤性能提升
|
|
-
按照 prov 排序查询读取数据量是不排序的 25%,耗时是 66%; -
按照 isp 排序提升不明显,这是因为 isp 数据量有明显的倾斜,条件中 isp 值占比高达 90%;
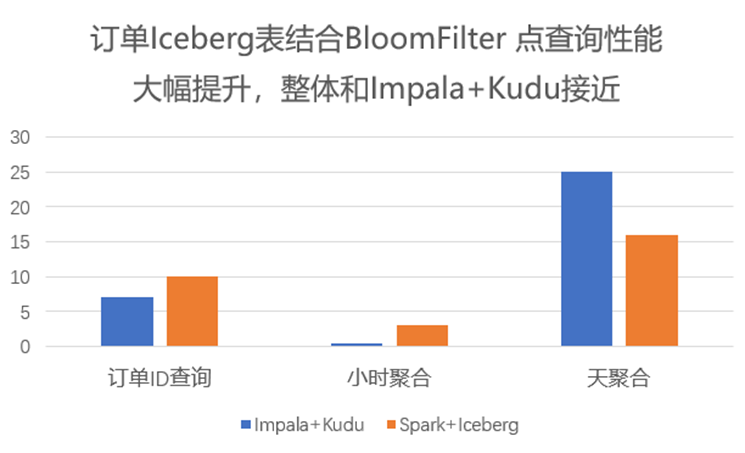
3.4 布隆过滤器的性能提升
3.5 Spark 和 Trino 性能比较
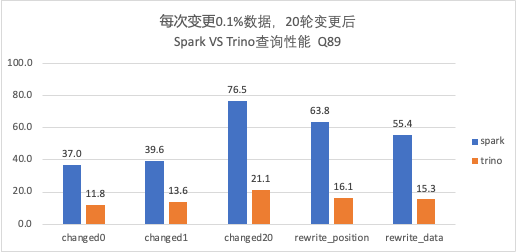
-
Trino 对于 V2 表查询结果与 Spark 一致,且在相同核数性能优于 Spark,耗时是 Spark 的 1/3 左右; -
随着变更轮次的增加(Data File 和 Postition Delete File 数量增加),Trino 查询性能也会逐渐变慢,需要定期进行合并。
04
核心收益 - 支持变更
1. 变更在业务使用场景
-
ETL 计算:如广告计费,通过接入 Iceberg 实现变更,简化业务逻辑,实现了更长时间范围的转化回收; -
数据修正:批量修正,如对某个数据的状态进行修改、批量删除等; -
隐私相关:如播放记录、搜索记录,用户需要删除历史条目等; -
CDC 同步:如订单业务,需要将 MySQL 中的数据进行大数据分析,通过 Flink CDC 技术很方便地将 MySQL 数据入湖,实时性可达到分钟级。
2. Hive 如何实现变更
-
分区覆写 例如修改某个 id 的相关内容,先筛选出要修改的目标行,更新后与历史数据进行合并,最后覆盖原表。这种方式对不需要修改的数据进行了重写,浪费计算资源;且覆写的粒度最小是分区级别,数据无法进一步细分,任务耗时相对较长。 -
标记删除 通常的做法是添加标志位,数据初始写入时标志位置 0,需要删除时,插入相同的数据,且标志位置 1,查询时过滤掉标志位为 1 的数据即可。这种方式在语义上未实现真正的删除,历史数据仍然保存在 Hive 中,浪费空间,而且查询语句较为复杂。
3. Iceberg 支持的变更类型
-
Delete:删除符合指定条件的数据,例如
|
|
-
Update:更新指定范围的数据,例如
|
|
-
MERGE:若数据已存在 UPDATE,不存在执行 INSERT,例如
|
|
4. Iceberg 变更策略
-
Copy on Write(写时合并):当进行删除或更新特定行时,包含这些行的数据文件将被重写。写入耗时取决于重写的数据文件数量,频繁变更会面临写放大问题。如果更新数据分布在大量不同的文件,那么更新的执行速度比较慢。这种方式由于结果文件数较少,读取的速度会比较快,适合频繁读取、低频批次更新的场景。 -
Merge on Read(读时合并):文件不会被重写,而是将更改写入新文件,当读取数据时,将新文件合并到原始数据文件得到最终结果。这使得写入速度更快,但读取数据时必须完成更多工作。写入新文件有两种方式,分别是记录删除某个文件对应的行(position delete)、记录删除的数据(equality detete)。 -
Position Delete:当前 Spark 的实现方式,记录变更对应的文件及行位置。这种方式不需要重写整个数据文件,只需找到对应数据的文件位置并记录,减少了写入的延迟,读取时合并的代价较小。 -
Equality Delete:当前 Flink 的实现方式,记录了删除数据行的主键。这种方式要求表必须有唯一的主键,写入过程无需查询数据文件,延迟最低;然而它的读取代价最大,这是由于读取时需要将 equality delete 记录和所有的原始文件进行 JOIN。
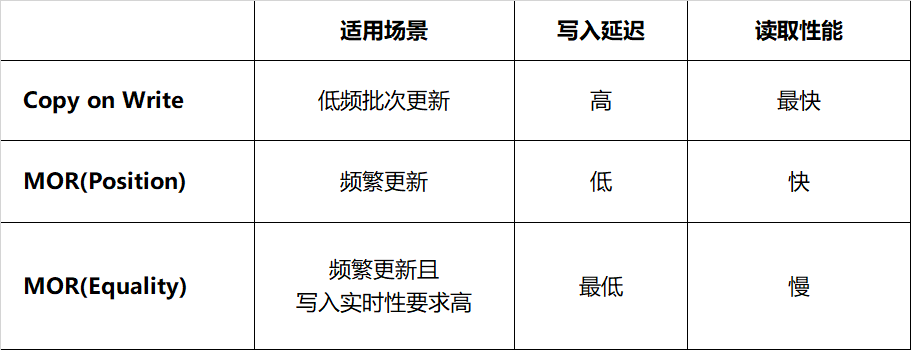 表 4-1 Iceberg 不同变更策略对比
表 4-1 Iceberg 不同变更策略对比
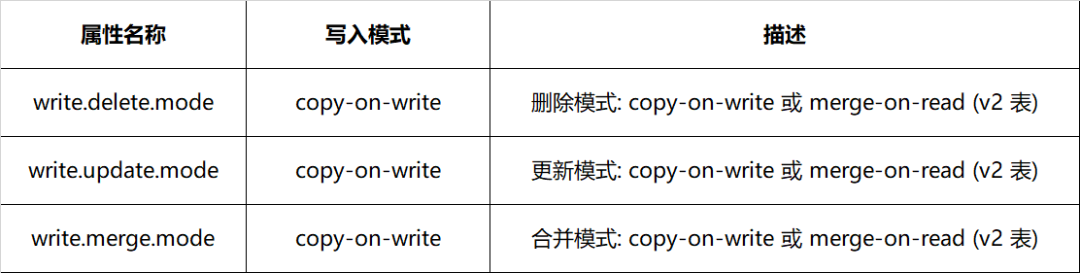 表 4-2 Iceberg 变更属性配置方式
表 4-2 Iceberg 变更属性配置方式
5. 业务接入
5.1 广告计费转换
-
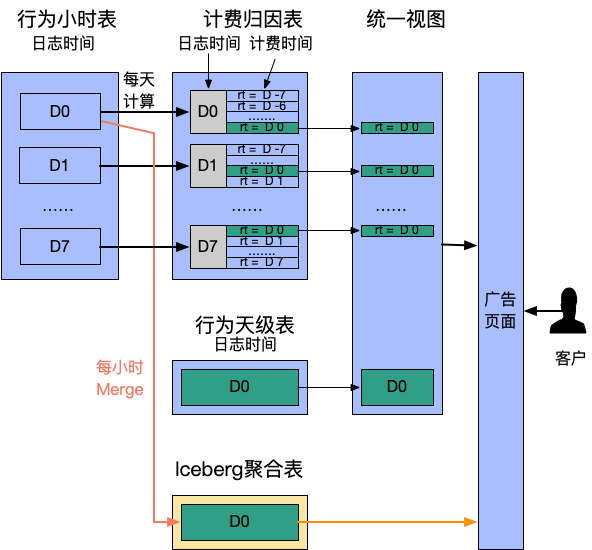
每天触发一次计算,从行为表聚合出过去 7 天的“计费时间”数据。此处用 rt 字段代表计费时间 -
提供统一视图合并行为数据和计费时间数据,计费归因表 rt as dt 作为分区过滤查询条件,满足同时检索曝光和计费转化的需求
|
|
-
时效性提升:从天级缩短到小时级,客户更实时观察成本,有利于预算引入; -
计算更长周期数据:原先为计算效率仅提供 7 日内转换,而真实场景转换周期可能超过 1 个月; -
表语义清晰:多表联合变为单表查询。
5.2 数据修正
|
|
05
总结
06
引用
-
From Hive Tables to Iceberg Tables: Hassle-Free -
通过数据组织优化加速基于Apache Iceberg的大规模数据分析 -
Row-Level Changes on the Lakehouse: Copy-On-Write vs. Merge-On-Read in Apache Iceberg -
《爱奇艺数据湖实战 - 综述》 -
《爱奇艺数据湖实战 - 广告》 -
《爱奇艺数据湖实战 - 基于数据湖的日志平台架构演进》 -
《爱奇艺数据湖实战 - 数据湖技术在爱奇艺BI场景的应用》 -
《爱奇艺在Iceberg落地相关性能优化与实践》

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。