私たちが見るデータレイク
iQiyi のデータセンター チームとしての私たちの主な任務は、社内の多数のデータ資産を管理し、サービスを提供することです。データ ガバナンスを実装する過程で、当社は新しい概念を吸収し、最先端のツールを導入してデータ システム管理を改良し続けます。
「データレイク」は近年データ分野で広く議論されている概念であり、その技術的な側面も業界から広く注目されています。私たちのチームは、データ レイクの理論と実践について徹底的な研究を行ってきました。データ レイクはデータ管理の新しい視点であるだけでなく、データを統合および処理するための有望なテクノロジーでもあると考えています。
データレイクはデータガバナンスの考え方です
データ レイクを実装する目的は、データの使いやすさと可用性を新たなレベルに引き上げる、効率的なストレージおよび管理ソリューションを提供することです。
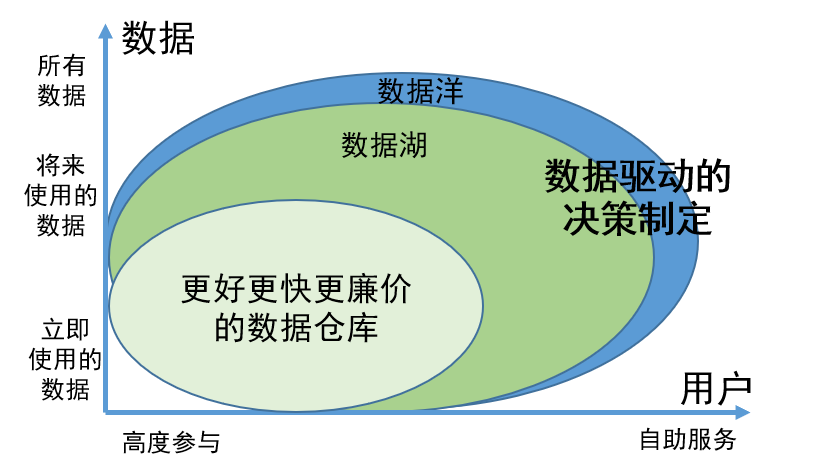
革新的なデータ ガバナンスの概念として、データ レイクの価値は主に次の 2 つの側面に反映されます。
1. データの使用中・一時停止に関わらず、すべてのデータを網羅的に保存できるため、必要なときに必要な情報を簡単に見つけることができ、作業効率が向上します。
2. データレイク内のデータは科学的に管理および整理されており、ユーザーが自分でデータを見つけて使用することが容易になります。この管理モデルにより、データ エンジニアの関与が大幅に軽減され、ユーザーはデータの検索と使用のタスクを自分で完了できるため、人的リソースが大幅に節約されます。
あらゆる種類のデータをより効果的に管理するために、データ レイクは、さまざまな特性とニーズに基づいてデータを 4 つのコア領域、つまり元の領域、製品領域、作業領域、機密領域に分割します。
Raw エリア
: このエリアは、データ エンジニアやプロのデータ サイエンティストのニーズを満たすことに重点を置いており、その主な目的は、未加工の未加工データを保存することです。必要に応じて、特定のアクセス要件をサポートするために部分的に開くこともできます。
製品領域
: 製品領域のデータのほとんどは、標準化と高度なデータ管理を確保するために、データ エンジニア、データ サイエンティスト、ビジネス アナリストによって処理および処理されます。このタイプのデータは通常、ビジネス レポート、データ分析、機械学習などの分野で広く使用されています。
ワークエリア
: ワークエリアは主に、さまざまなデータ ワーカーによって生成された中間データを保存するために使用されます。ここで、ユーザーは、さまざまなユーザー グループのニーズを満たす柔軟なデータ探索と実験をサポートするためにデータを管理する責任を負います。
機密領域
: 機密領域はセキュリティに重点を置き、主に個人を特定できる情報、財務データ、法令順守データなどの機密データを保存するために使用されます。このエリアは最高レベルのアクセス制御とセキュリティによって保護されています。
この分割により、データ レイクはさまざまな種類のデータをより適切に管理できると同時に、さまざまなニーズを満たす便利なデータ アクセスと利用を提供できます。
データセンターにおけるデータレイクデータガバナンスのアイデアの適用
データセンターの目標は、統計的精度の一貫性のなさ、開発の繰り返し、指標開発ニーズへの対応の遅さ、データの品質の低さ、データの急増やビジネスの拡大に起因するデータコストの高さなどの問題を解決することです。
データセンターとデータレイクの目標は一貫しています。データレイクの概念を組み合わせることで、データシステムとデータセンターの全体的なアーキテクチャが最適化され、アップグレードされました。
データセンター構築の初期段階では、同社のデータウェアハウスシステムを統合し、ビジネスに関する徹底的な調査を実施し、既存の分野と次元情報を整理し、一貫性次元を要約し、統一指標システムを確立し、データウェアハウス構築を策定しました。仕様。この仕様に従って、統合データ ウェアハウスのオリジナル データ レイヤー (ODS)、詳細データ レイヤー (DWD)、および集約データ レイヤー (MID) を構築し、蓄積されたデバイス ライブラリと新しいデバイスを含むデバイス ライブラリを確立しました。図書館。統合データ ウェアハウスに基づいて、データ チームはさまざまな分析と統計の方向性、ビジネス ニーズに基づいてテーマ データ ウェアハウスとビジネス市場を構築しました。対象となるデータ ウェアハウスとビジネス マーケットには、さらに処理された詳細データ、集約データ、およびアプリケーション層データ テーブルが含まれます。データ アプリケーション層は、これらのデータを使用してさまざまなサービスをユーザーに提供します。
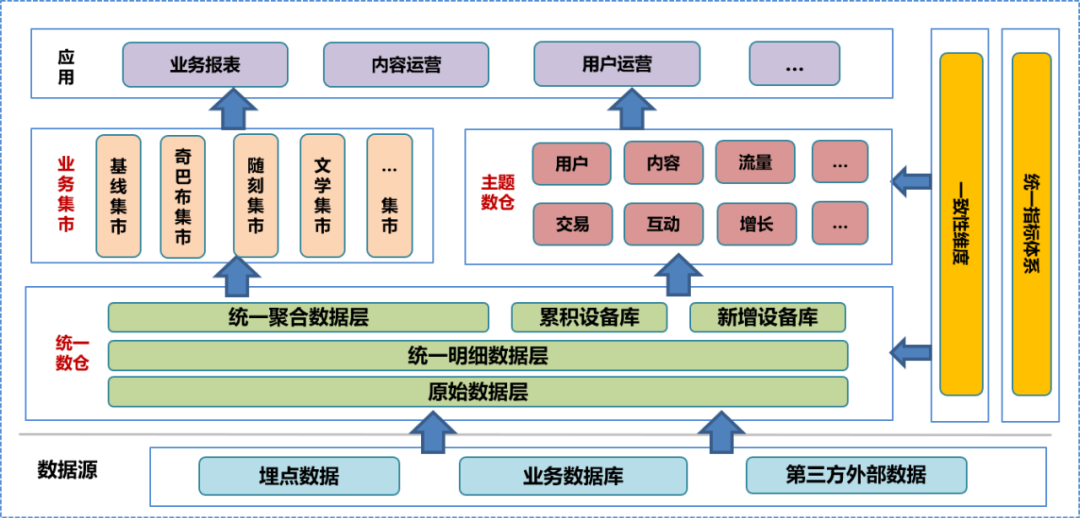
統合データウェアハウスシステムでは、元のデータレイヤー
以下は
公開されておらず、ユーザーはデータエンジニアを使用して処理されたデータのみを処理できるため、一部のデータの詳細が失われることは避けられません。
日常業務において、データ分析機能を持つユーザーは、パーソナライズされた分析やトラブルシューティングを行うために、基礎となる生データにアクセスしたいと考えることがよくあります。
データレイクのデータ管理概念は、この問題を効果的に解決できます。データレイクのデータガバナンスの考え方を導入した後、既存のデータリソースを整理して統合し、データメタデータを強化および拡張し、メタデータセンターの管理に特化したデータメタデータセンターを構築しました。
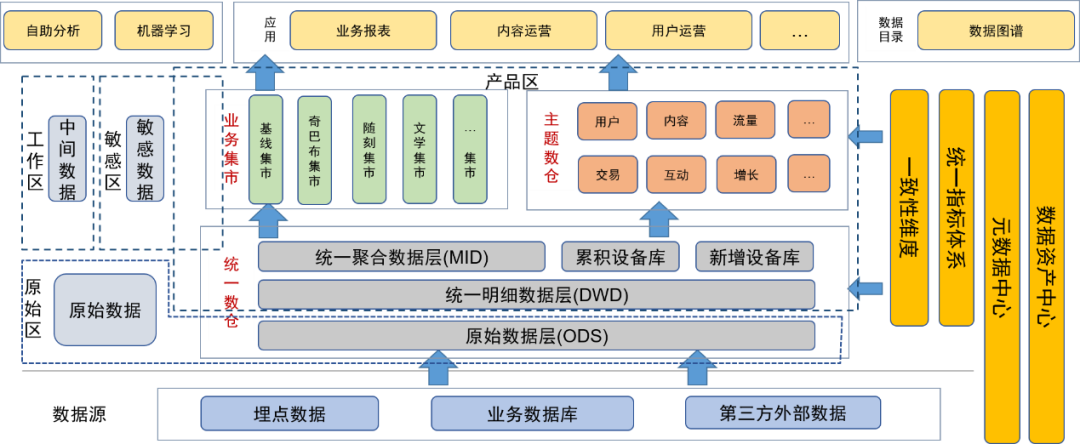
データ ガバナンスのためのデータ レイクの概念を導入した後、元のデータ レイヤーとその他の元のデータ (元のログ ファイルなど) を元のデータ領域に配置し、データ処理機能を持つユーザーはこの領域のデータの使用許可を申請できます。
統合データウェアハウスの詳細レイヤー、集計レイヤー、テーマデータウェアハウス、ビジネスマートはプロダクトエリアに配置され、これらのデータはデータチームのデータエンジニアによって処理され、最終的なデータ製品としてユーザーに提供されます。この領域はデータ管理によって処理されているため、データの品質は保証されています。
また、機密データの機密領域も定義し、アクセス権の制御に重点を置いています。
ユーザーおよびデータ開発者によって毎日生成される一時テーブルまたは個人テーブルは一時領域に配置され、これらのデータ テーブルはユーザー自身の責任であり、条件付きで他のユーザーに公開できます。
各データのメタデータは、テーブル情報、フィールド情報、フィールドに対応するディメンションやインジケーターなど、メタデータ センターを通じて維持されます。同時に、テーブルレベルおよびフィールドレベルのリネージ関係を含むデータリネージも維持します。
データ資産センターを通じて、データレベル、機密性、権限の管理など、データの資産特性を維持します。
ユーザーが独自にデータをより効果的に使用できるようにするために、ユーザーがデータの使用状況、ディメンション、インジケーター、リネージュなどのメタデータを含むデータをクエリできるように、アプリケーション層でデータ ディレクトリとしてデータ マップを提供します。同時に、このプラットフォームは許可申請のポータルとしても利用できます。
さらに、データ ユーザーにセルフサービス分析機能を提供するセルフサービス分析プラットフォームも提供します。
データシステムを最適化すると同時に、データレイクの概念に基づいてデータミドルプラットフォームのアーキテクチャもアップグレードしました。
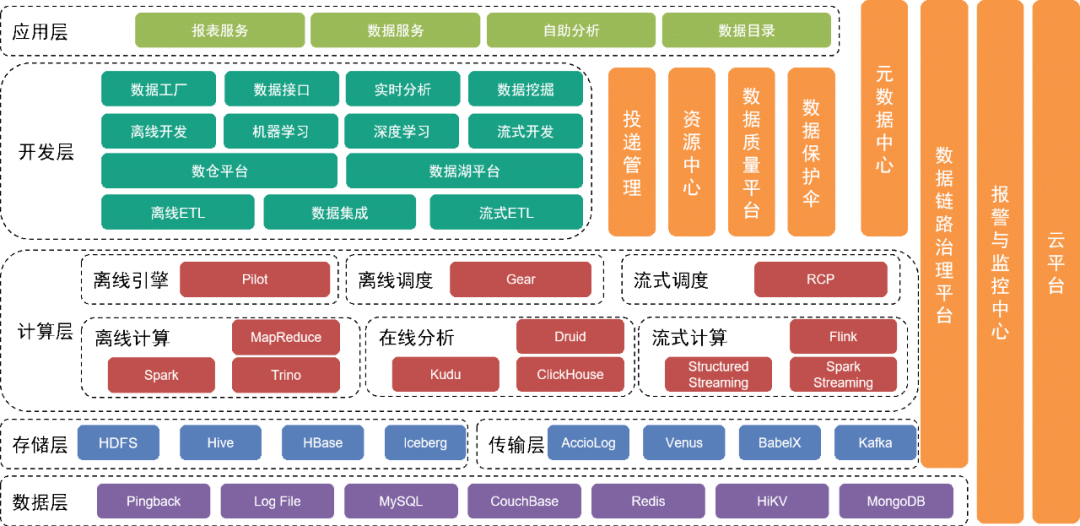
最下層はデータ層で、主にユーザーの行動を収集するために使用されるピンバック データなどのさまざまなデータ ソースが含まれ、さまざまなリレーショナル データベースや NoSQL データベースに保存されます。
これらのデータは、トランスポート層のさまざまな収集ツールを通じてストレージ層に保存されます。
データ層の上には
、主に分散ファイル システムである HDFS に基づいたストレージ層があり、元のファイルを保存します。その他の構造化データまたは非構造化データは、Hive、Iceberg、または HBase に保存されます。
さらに上位にはコンピューティング層があり
、主にオフライン エンジン Pilot を使用してオフライン計算のために Spark または Trino を駆動し、スケジュールされたワークフロー スケジューリングにはスケジューリング エンジン Gear オフライン ワークフロー エンジンを使用します。 RCP リアルタイム コンピューティング プラットフォームは、ストリーム コンピューティングのスケジューリングを担当します。数回の反復を経て、フロー コンピューティングは現在主に Flink をコンピューティング エンジンとして使用しています。
コンピューティング層の上の開発層は、
コンピューティング層と伝送層の各サービス モジュールをさらにカプセル化し、オフライン データ処理ワークフローの開発、データの統合、リアルタイム処理ワークフローの開発、機械学習エンジニアリング ツール スイートおよび中間実装の開発のための機能を提供します。開発作業を完了するためのサービス。データレイクプラットフォームはデータレイク内の各データファイルやデータテーブルの情報を管理し、データウェアハウスプラットフォームはデータウェアハウスのデータモデル、物理モデル、ディメンション、インジケーターなどの情報を管理します。
同時に、メタデータセンターやリソースセンターなどのモジュールのピンバック埋め込み仕様、フィールド、辞書、配信タイミングなどのメタ情報を管理する配信管理ツールなど、さまざまな管理ツールやサービスを垂直的に提供しています。データテーブルまたはデータファイルを維持し、データセキュリティを確保するために使用されます。データ品質センターとリンク管理プラットフォームは、データ品質とデータリンクの生産ステータスを監視し、保護のために関連チームに迅速に通知し、オンラインの問題や障害に迅速に対応します。既存の計画に基づいて。
基盤となるサービスはクラウド サービス チームによって提供され、プライベート クラウドとパブリック クラウドのサポートを提供します。
アーキテクチャの上位層は、ユーザーが必要なデータを見つけるためのデータ ディレクトリとしてデータ マップを提供します。さらに、セルフサービス データ作業に対するさまざまなレベルのユーザーのニーズを満たすために、Magic Mirror や Beidou などのセルフサービス アプリケーションを提供しています。
アーキテクチャ システム全体の変革後、データの統合と管理はより柔軟かつ包括的になります。セルフサービスツールを最適化することでユーザーの敷居を下げ、さまざまなレベルのユーザーのニーズに応え、データ利用効率を向上させ、データ価値を高めます。
データセンターにおけるデータレイク技術の適用
広義ではデータレイクはデータガバナンスの概念であり、狭義ではデータ処理技術も指します。
データ レイク テクノロジーは、データ テーブルの保存形式と、レイクに入った後のデータの処理テクノロジーをカバーします。
業界のデータ レイクには、Delta Lake、Hudi、Iceberg の 3 つの主要なストレージ ソリューションがあります。これら 3 つの比較は次のとおりです。
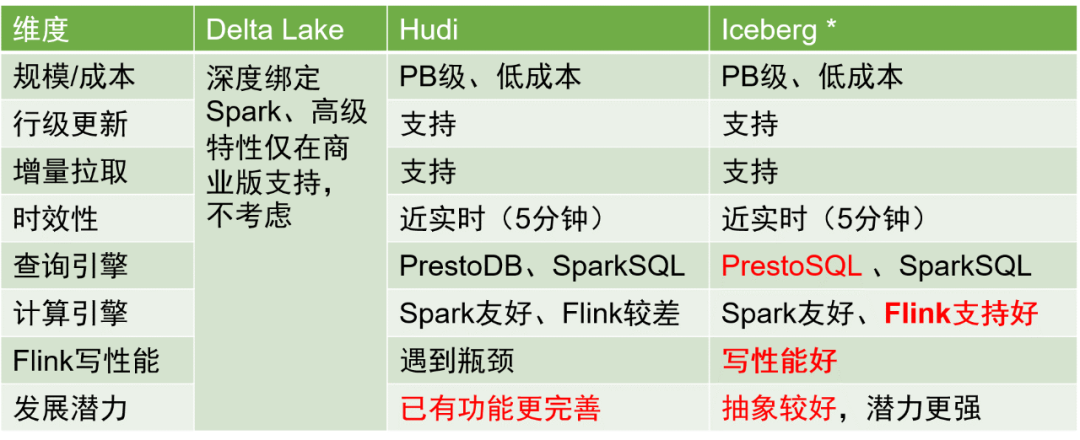
総合的な検討の結果、データテーブルの保存形式として Iceberg を選択しました。
Iceberg は、基盤となるファイル システムまたはオブジェクト ストア内のデータ ファイルを編成するテーブル ストレージ形式です。
Iceberg と Hive の主な比較は次のとおりです。
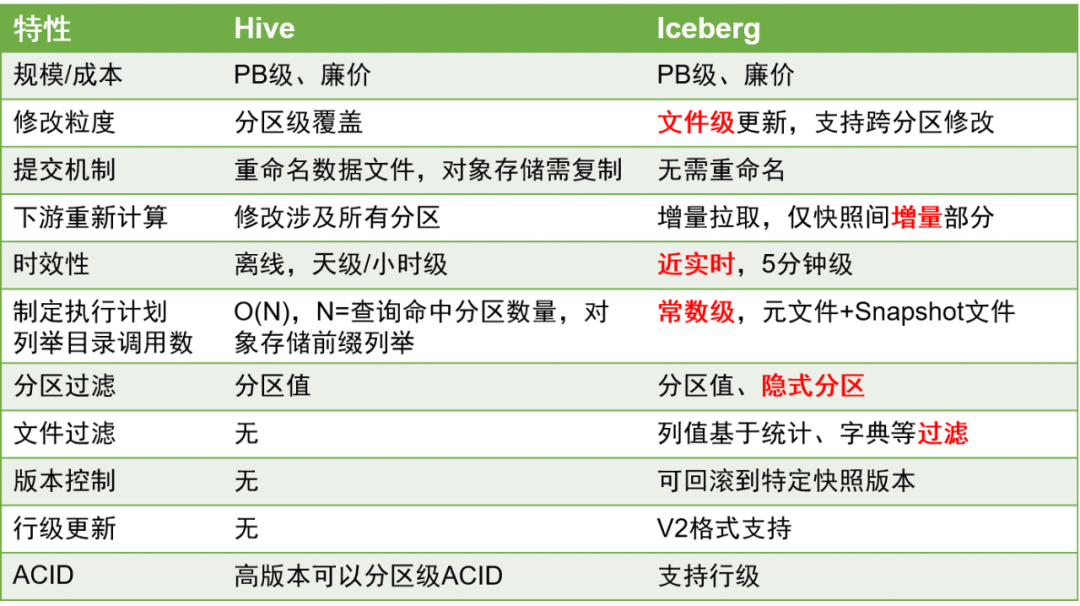
Hive テーブルと比較すると、Iceberg テーブルには行レベルの更新をより適切にサポートでき、データの適時性を分レベルまで向上できるため、大きな利点があります。
データの適時性の向上によりデータ処理 ETL の効率が大幅に向上するため、これはデータ処理において非常に重要です。
したがって、既存の Lambda アーキテクチャを簡単に変換して、ストリーミング バッチ統合アーキテクチャを実現できます。
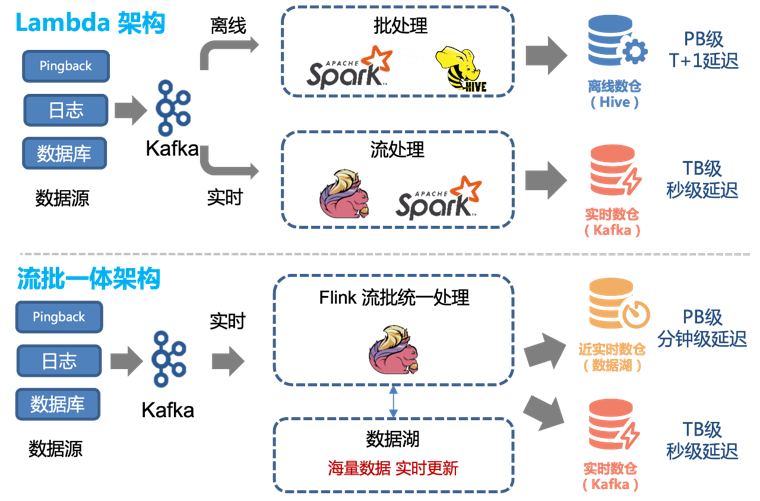
データ レイク テクノロジーが導入される前は、オフライン処理とリアルタイム処理を組み合わせて、オフライン データ ウェアハウスとリアルタイム データ ウェアハウスを提供していました。
従来のオフライン分析および処理方法を通じて、
全量のデータがデータウェアハウス データに構築され、
Hive テーブルの形式でクラスターに保存されます。
リアルタイム要件の高いデータについては、リアルタイム リンクを通じて個別に生成し、Kafka のトピックの形式でユーザーに提供します。
ただし、このアーキテクチャには次の問題があります。
-
リアルタイムとオフラインの 2 つのチャネルは、2 つの異なるコード ロジック セットを維持する必要があります。処理ロジックが変更されると、リアルタイム チャネルとオフライン チャネルの両方を同時に更新する必要があります。そうしないと、データの不整合が発生します。
-
オフライン リンクは 1 時間ごとに更新され、約 1 時間の遅延があるため、00:01 のデータは 02:00 までクエリされない可能性があります。リアルタイム要件が高い一部のダウンストリーム サービスでは、これは受け入れられないため、リアルタイム リンクをサポートする必要があります。
-
リアルタイム リンクのリアルタイム パフォーマンスは第 2 レベルに達する可能性がありますが、コストは高くなります。ほとんどのユーザーにとって、5 分間の更新で十分です。同時に、Kafka ストリームの使用は、データ テーブルを直接操作するほど便利ではありません。
これらの問題は、Iceberg テーブルとストリーミング バッチの統合データ処理方法を使用することで、より適切に解決できます。

最適化プロセスでは、主に ODS レイヤーと DWD レイヤーのテーブルに対して Iceberg 変換を実行し、解析とデータ処理を Flink タスクに再構築しました。
変換プロセス中にデータ生成の安定性と精度が影響を受けないようにするために、次の措置を講じました。
1. 非コアデータで切り替えを開始します。実際のビジネスの状況に基づいて、QOS 配信とカスタマイズされた配信をパイロット プロジェクトとして使用します。
2. オフライン解析ロジックを抽象化することで、統合されたピンバック解析ストレージ SDK が形成され、リアルタイムとオフラインの統合展開が実現され、コードがより標準化されます。
3. Iceberg テーブルと新しい運用プロセスを導入した後、デュアルリンクの並列操作を 2 か月間実行し、データの定期的な比較モニタリングを実行しました。
4. データや本番環境に問題がないことを確認した後、目立たないように上位層へ切り替えます。
5. コアデータに関わる起動・再生データについては、全体検証が安定した後に統合ストリーミング・一括変換を実施します。
1. QOS とカスタマイズされた配信データ リンクは、全体としてほぼリアルタイムで実装されています。 1 時間ごとの遅延があるデータは 5 分レベルで更新できます。
2. 特別な状況を除いて、統合されたストリーミングおよびバッチ リンクはリアルタイムのニーズを満たすことができます。したがって、QOS とカスタマイズに関連する既存のリアルタイム リンクとオフライン分析リンクをオフラインにすることができ、それによってリソースを節約できます。
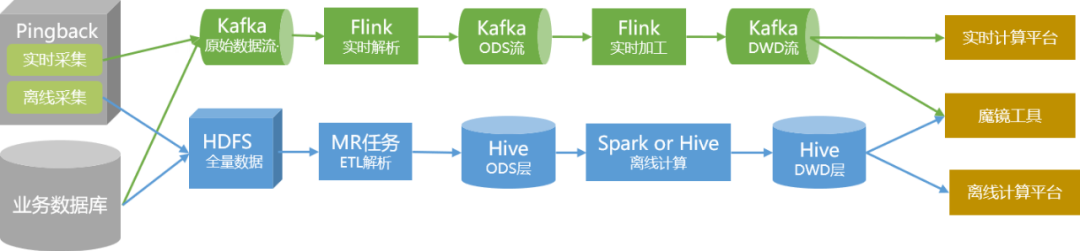
データ処理の変革により、将来のデータリンクは次の図のようになります。
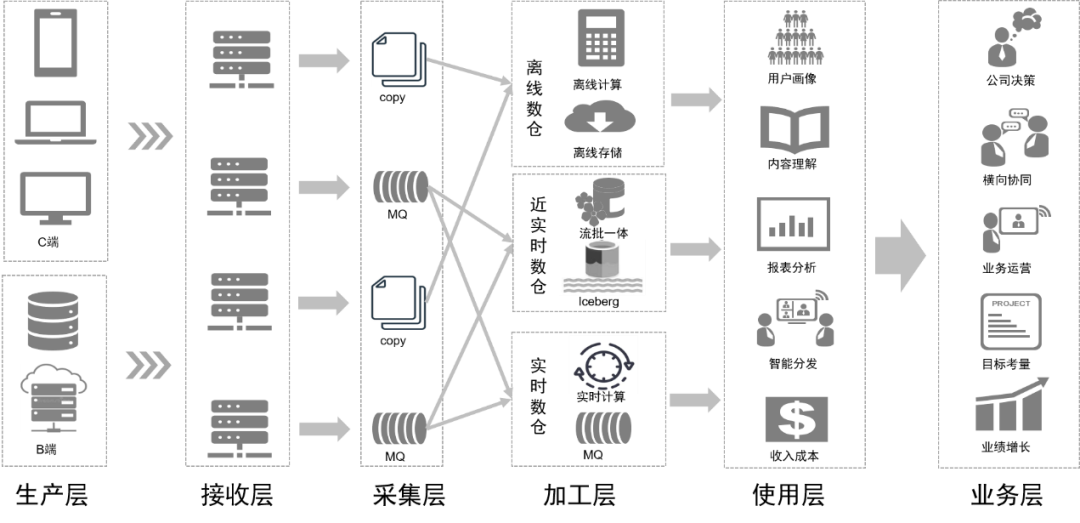
フォローアップ計画
データセンターでのデータ レイク アプリケーションのその後の計画には、主に次の 2 つの側面があります。
データセンターが提供するデータとサービスをより包括的かつ使いやすくするために、アーキテクチャ レベルから各モジュールの開発を継続的に改良し、さまざまなユーザーが便利に使用できるようにしていきます。
技術レベルでは、引き続きデータリンクをストリームとバッチの統合に変換し、同時に適切なデータテクノロジーを積極的に導入して、データの生成と利用効率を向上させ、生成コストを削減していきます。
6. アレックス・ゴレリック。エンタープライズビッグデータレイク。
この記事は、WeChat パブリック アカウント - iQIYI テクノロジー製品チーム (iQIYI-TP) から共有されたものです。
侵害がある場合は、削除について [email protected] までご連絡ください。
この記事は「OSC ソース作成計画」に参加していますので、読んでいる方もぜひ参加して共有してください。
