現代の深層学習開発では、通常、ビルディング ブロックなどの複雑なソフトウェア システムを構築するために他のモジュールに依存します。このプロセスは多くの場合、高速で効果的です。しかし、システムの複雑さと結合により、ディープ ラーニング システムの設計者と保守者は、問題が発生したときに問題を迅速に特定して解決する方法に常に悩まされてきました。
iQiyi のバックエンド技術チームのメンバーとして、私たちはディープラーニング トレーニングのメモリ関連の問題を解決するプロセスを詳細に記録し、厄介な問題の解決に懸命に取り組んでいる仲間たちにインスピレーションを与えたいと考えています。
背景
過去四半期にわたって、A100 クラスター内でランダムな CPU メモリ OOM 現象が観察されてきました。大規模なモデルのトレーニングの導入により、oom はさらに耐えられなくなったため、私たちはこの問題を解決することを決意しました。
自分がどこから来たのかを振り返ると、突然悟ったように感じました。実際、私たちはかつて問題の真実に非常に近づいていましたが、想像力が足りず、それを見落としていました。
プロセス
非常に最初に、私たちは過去のログの帰納的分析を実施しました。最終的な解決策にとって非常に優れた指針となる重要なルールがいくつか発見されました。
-
これは、A100 クラスターで発生した新しい問題であり、他のクラスターでは発生していません。
-
この問題は pytorch の ddp 分散トレーニングに関連しています。pytorch を使用する他のトレーニング モードでは発生していません。
-
この OOM 問題は非常にランダムであり、3 時間以内に発生するものもあれば、1 週間以上後にのみ発生するものもあります。
-
次の図に示すように、OOM 中にメモリ サージが発生し、基本的に 1 分半以内に 10% から 90% への増加が完了します。
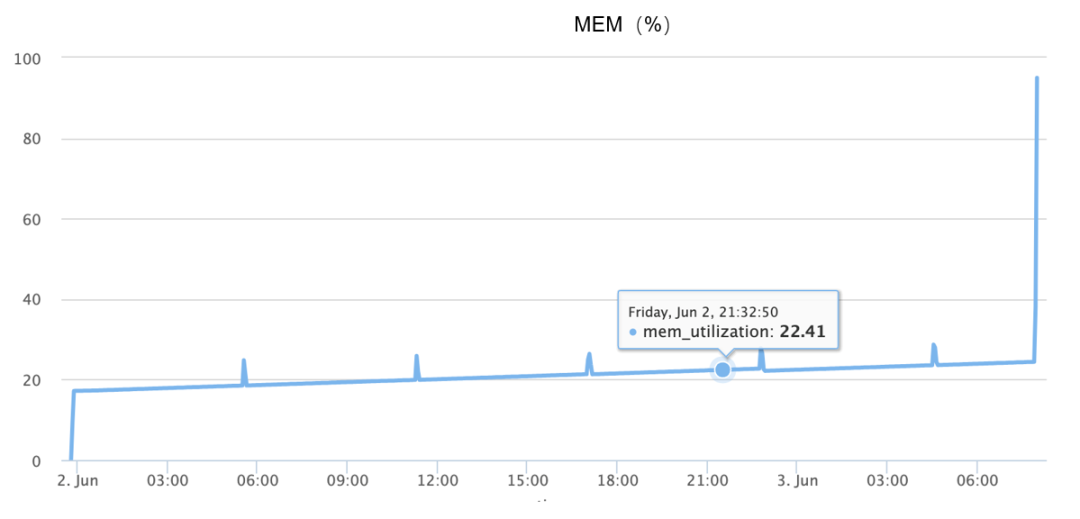
上記の情報は入手可能ですが、問題を確実に再現できないため、最初は完全に想像力に頼って、考えられる原因を次のように推測しました。
-
オブジェクトがリサイクルされず、継続的なメモリ リークが発生するため、コードに問題がある可能性がありますか?
-
これは、glibc の PTMALLOC アロケータにフラグメントが多すぎるため、ある瞬間に突然のメモリ要求が継続的なメモリ割り当てを引き起こすという事実と同様に、基礎となるメモリ アロケータに問題がある可能性がありますか?
-
-
以下では、最初の 2 つの仮定を詳しく紹介します。
コードの問題かどうかを判断するために、問題が発生したシーンにデバッグ コードを追加し、定期的に呼び出しました。次のコードは、現在の Python gc モジュールでリサイクルできないすべてのオブジェクトを出力します。
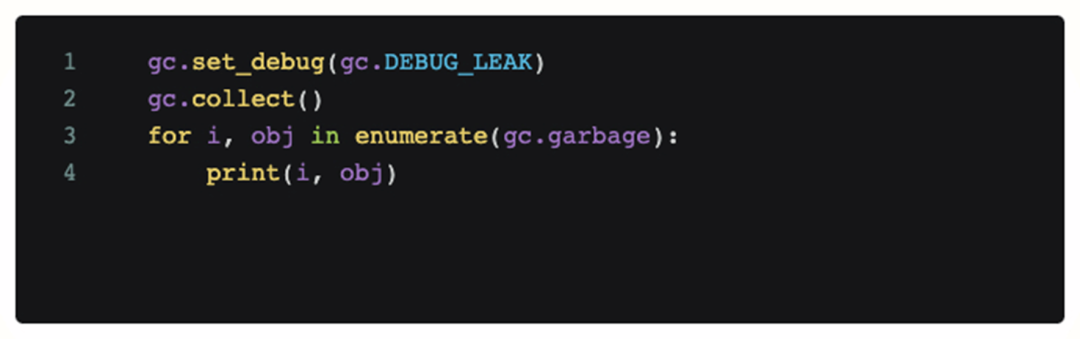 ただし、このコードを追加した後、取得されたログ分析では、OOM 中に大量のメモリを占有する到達不能なオブジェクトはなく、継続的な gc では OOM 自体を軽減できないことがわかります。したがって、この時点で最初の推測は破綻しており、問題の原因はコード (メモリ リーク) ではありません。
ただし、このコードを追加した後、取得されたログ分析では、OOM 中に大量のメモリを占有する到達不能なオブジェクトはなく、継続的な gc では OOM 自体を軽減できないことがわかります。したがって、この時点で最初の推測は破綻しており、問題の原因はコード (メモリ リーク) ではありません。
この段階で、jemalloc メモリ アロケータを導入しました。glibc のデフォルトの PTMALLOC と比較して、その利点は、より効率的なメモリ割り当てとメモリ割り当て自体のデバッグのサポートを向上できることです。
-
デフォルトのメモリ アロケータに問題があるのでしょうか?
-
トーチ コード自体を変更せずに Python で jemalloc の現在のステータスを直接表示するために、ctypes を使用して jemalloc インターフェイスを Python で直接公開しました。
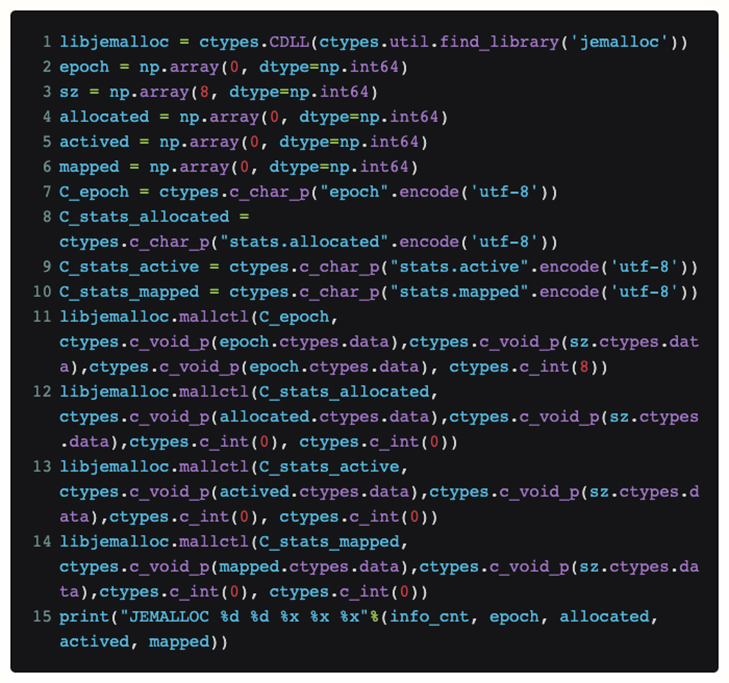
このようにして、このコードを関数に入れると、jemalloc が上位層から現在受信している [割り当てられている] リクエストと、システムから要求している [マッピングされた] 実際の物理メモリ サイズを定期的に知ることができます。
実際の再現プロセスの後、OOM が発生したときに割り当ておよびマッピングされた 2 つの値が非常に近いことが最終的に判明しました。したがって、記憶の断片化に関する私たちの仮説は破綻します。
限界に達したとき、既存の OOM ログをもう一度整理したところ、これまで注目されていなかった方向があることがわかりました。つまり、複数のマシンが同じような時間 (1 ~ 2) で動作していたということです。隣接する分)OOM が数回発生します。
それでは、この魔法のようなシンクロニシティにはどのような論理的な説明があるのでしょうか?通常のバグによってこのような一貫性が再発することはありません。したがって、それらの間には必然的なつながりがあるかもしれません。
では、この相関関係はどこから来るのでしょうか?この問題を調査するために、分析の視点は分散トレーニングにおけるネットワーク通信に移ります。
通信に関する最初の疑惑は、OOM が発生したマシンに焦点が当てられており、何らかの理由で相互に通信し、相互に問題が発生する可能性があると考えられました。そのため、ネットワーク トラフィックを監視するために tcpdump が毎日のトレーニングに追加されました。
最後に、tcpdump に参加した後、OOM 中に最も疑わしい通信を捕捉しました。つまり、OOM マシンは問題が発生する数分前にセキュリティ スキャン トラフィックを受信しました。
最終的な位置決め
疑わしいオブジェクトをスキャンしているセキュリティ チームを捕まえた後、私たちはセキュリティ チームと協力して分析を実施し、最終的にスキャンに基づいて OOM 問題を安定して再現できることがわかり、トリガーの原因がほぼ確実であることがわかりました。ただし、現時点では、OOM 問題を回避するためにセキュリティ スキャン戦略を再現して変更することしかできません。また、コードをさらに分析して、最終的にその場所を特定する必要もあります。
コードを分析して特定した結果、問題は pytorch の DDP 分散トレーニング プロトコルにあることが最終的に判明しました。関連するコードは次のとおりです。
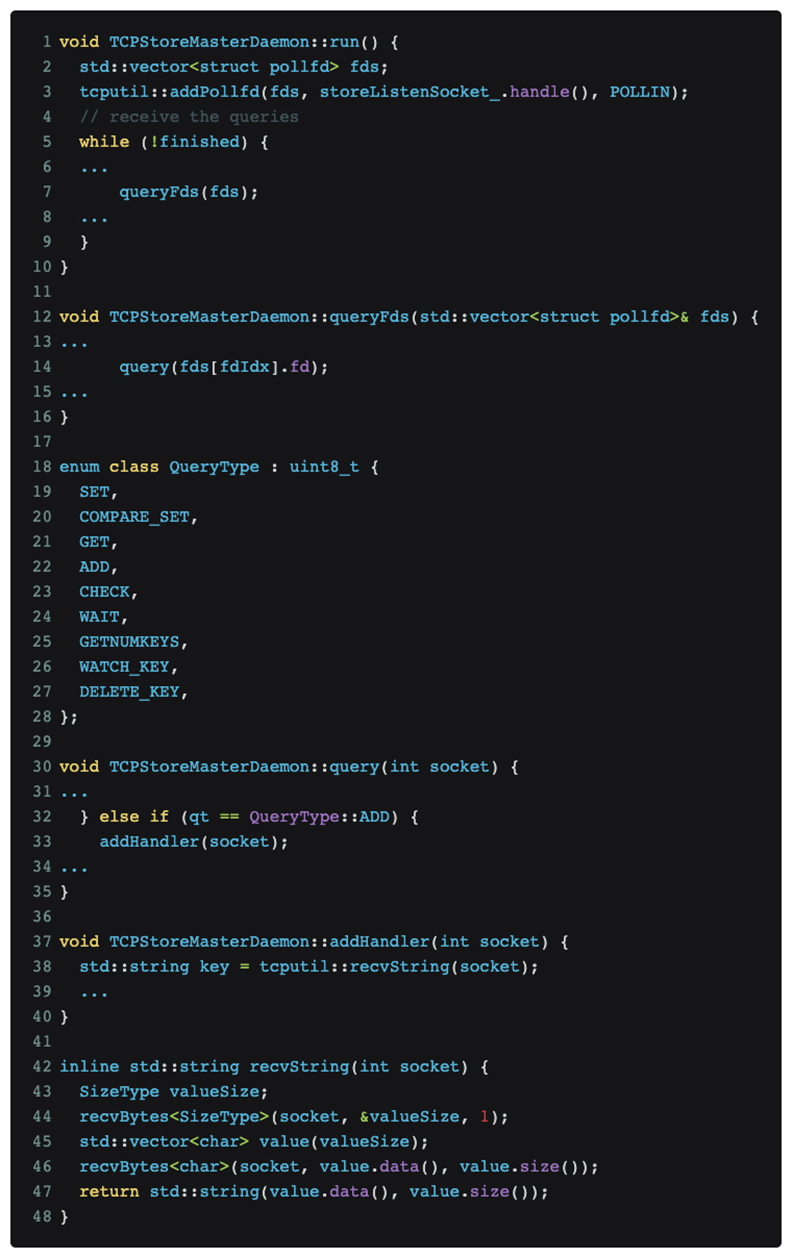
上の図に示すように、pytorch 分散トレーニングはマスター ポート上のメッセージをリッスンし続けます。

Nmap スキャン [nmap -sS -sV] がたまたま QueryType::ADD メッセージ タイプをトリガーしました。これは、上の tcpdump の図に示されているデータ部分の緑色のボックス番号 [03] であり、これにより pytorch が recvString を使用しようとしました。フォローアップメッセージとみなされるものを受信するためにバッファを事前に割り当てる関数。ただし、このバッファ長は、[03] 以降の uint64_t[little-endian] タイプを使用して解析されます。これは、赤いボックス番号 [e0060b0000] であり、962174058496 バイトです。この値は、1T データが受信されることを意味すると理解され、pytorch で解析されます。メモリ アロケータが対応するメモリを要求した後、メモリ アロケータはさらにカーネルに対応する物理ページを要求します。 GPU トレーニング クラスターは巨大なページ テーブルで構成されていないため、Linux は 4K 粒度に従ってページ欠落割り込みでメモリ アロケーターの 1T メモリ要求を段階的にしか満たせません。つまり、すべてのメモリを割り当てるには約 1 分かかります。以前に観察された OOM は、おそらく約 1 分間の急速なメモリ増加に反応して発生したと考えられます。
解決
原因と結果がわかれば、解決策は自然になります。
1. 短期的: セキュリティ スキャン ポリシーを変更して回避する
2. 長期: コミュニティと通信して、pytorch DDP プロトコルの堅牢性[ 1 ]
要約する
OOM 問題調査プロセスのバックトラックを完了した後、このプロセス中にメモリ関連のツールとデバッグ方法について効果的なテストを実際に実施していたことがわかりました。
この過程で、その後の研究開発の参考となるいくつかの共通点があることを発見しました。
-
Jemalloc は、メモリ問題の非常に効果的な定量分析を提供し、Python+C などのハイブリッド プログラミング システムにおける根本的なメモリ関連の問題を捕捉できます。
-
メモリア。私たちはデバッグ プロセス中にこれに大きな期待を寄せていましたが、最終的に、memray が最高のパフォーマンスを発揮できる領域は依然として純粋な Python 側にあり、pytorch DDP などのハイブリッド プログラミング システムには対応していないことがわかりました。
場合によっては、より大きな次元から問題を考える必要があります。たとえば、関係のない外部サービスとの通信プロセスが考慮に含まれていない場合、本当の根本原因は発見されません。

