
著者: 伍哲
導入
最新のデータおよびビジネス システムを構築するプロセスにおいて、ログ サービス (SLS) は、ログ/トレース/メトリック データのための大規模、低コスト、高パフォーマンスのワンストップ プラットフォーム サービスを提供します。データの収集、処理、配信、分析、アラーム、可視化などの機能を提供し、研究開発、運用保守、運用とセキュリティなどのさまざまなシーンで企業のデジタル能力を総合的に強化します。
ログデータは当然構造化されていません
ログ データは、観察可能なシナリオにおける最も基本的なデータ タイプの 1 つであり、その最大の特徴は、ログ データが自然に構造化されていないことです。これは、さまざまな要因に関連しています。
- ソースの多様性: ログ データには多くの種類があり、さまざまなソースからのデータに対して統一したスキーマを用意するのは困難です。
- データのランダム性: たとえば、異常なイベント ログやユーザーの行動ログは、多くの場合自然にランダムであり、予測が困難です。
- ビジネスの複雑さ: たとえば、開発プロセスでは、通常、ログを作成するのは開発者ですが、その後のログを分析するのは運用エンジニアやデータ エンジニアであることが多く、特定の分析ニーズを予測するのは困難です。ログ書き込みプロセス中の期間。

これらの要因により、多くの場合、ログ データの前処理に使用できる理想的なデータ モデルが存在しないという事実が生じます。より一般的なアプローチは、元のデータを直接保存することです。これは、スキーマオンと呼ばれます。読み取りアプローチ。いわゆる「寿司原則」: 好きなだけさまざまな方法で調理できるため、調理済みデータよりも生データの方が優れています。また、この種の「乱雑な」生ログ データは、データの構造化された分析をより適切に実行するために、データ モデルについての事前知識が必要になることが多いため、分析者にとっても困難になります。
Unix パイプからインスピレーションを得た: インタラクティブなプローブ
さまざまなログ分析システムやプラットフォームが登場する前は、開発担当者、運用保守担当者にとって最も伝統的なログ分析方法は、ログ ファイルが存在するマシンに直接ログインしてログを grep し、一連の Unix コマンドを使用することでした。ログを分析して処理します。
たとえば、アクセス ログで 404 の送信元ホストを確認する場合は、次のコマンドを使用できます。
grep 404 access.log | tail -n 10 | awk '{print $2}' | tr a-z A-Z
このコマンドは、3 つのパイプ演算子を使用して、4 つの Unix コマンド ライン ツール (キーワード検索、ログの切り捨て、フィールド抽出、大文字と小文字の変換) を完全な処理スタックに接続します。
このようなコマンドを使用する場合、多くの場合、完全なコマンドを一度に作成するのではなく、コマンドを作成した後に Enter キーを押し、実行出力結果を確認し、パイプラインを通じて次の処理コマンドを追加することに注意してください。実行されるなど。
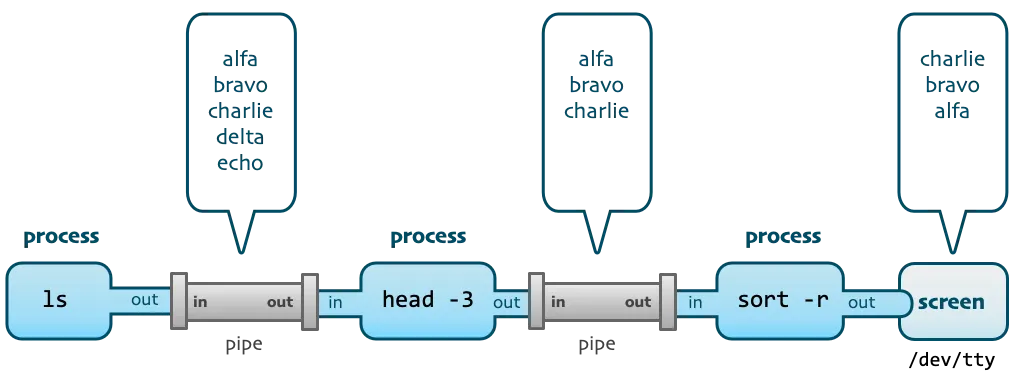
このプロセスは、小さくて美しいツールをパイプラインを通じて強力なプログラムに結合するという Unix の設計哲学を完全に体現しています。同時に、ログ分析の観点からは、次のようなインスピレーションが得られます。
1) インタラクティブかつプログレッシブな探索。各実行は前の実行に基づいて重ねられます。
2) 探査プロセス中、多くの場合、データの全量が処理されませんが、サンプル データのごく一部が分析のために傍受されます。
3) 探索プロセス中に実行されるさまざまな処理操作は、このクエリの出力にのみ影響し、元のデータは変更されません。
このインタラクティブな探索操作は、ログ データを探索するための優れた方法であると考えられるため、SLS のようなクラウド ログ プラットフォームでは、Unix パイプラインと同様に、大量の生のログ データに直面したときにこれを使用できることが期待されます。クエリを実行すると、まずデータが探索され、マルチレベルのパイプラインを通じて段階的に処理されます。これにより、乱雑で無秩序なログ内のデータ パターンを掘り出すことができるため、後続の処理とクリーニング、消費、および処理をより目的を持って完了できます。配信、SQL 集計分析、その他の操作。
SPL-Unified ログの処理構文
SPL (詳細については SPL の概要[ 1]を参照)、または SLS 処理言語は、ログ クエリ、ストリーミング消費、データ処理、Logtail コレクション、データ インジェストなどのデータ処理を必要とするシナリオ向けに SLS によって提供される統合データ処理構文です。この一体性により、SPL はログ処理ライフ サイクル全体を通じて「一度書き込めばどこでも実行できる」効果を実現できます。
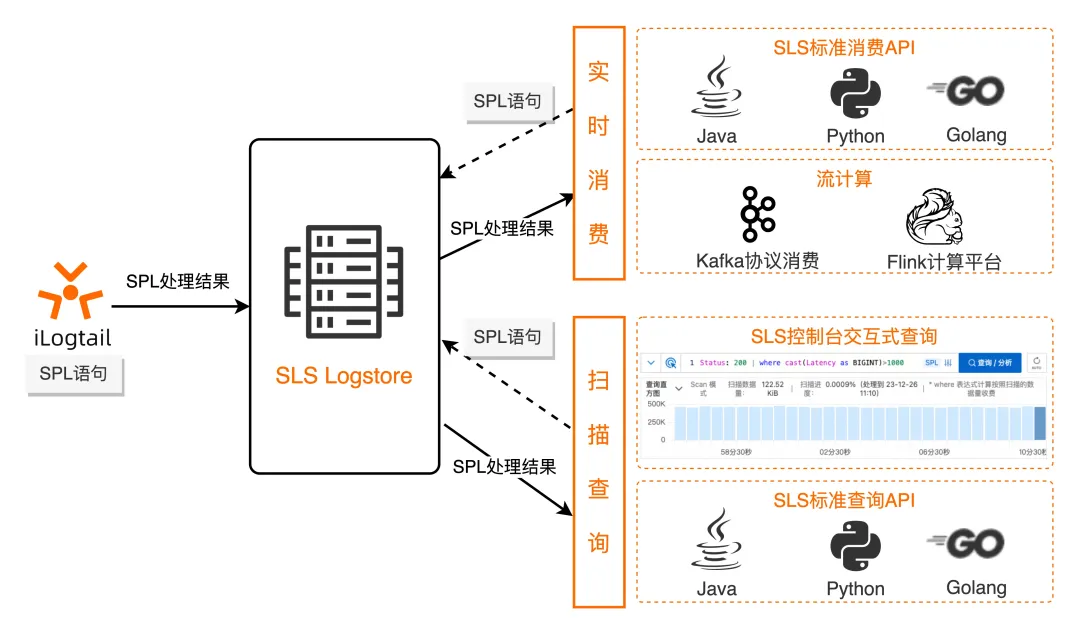
SPL の基本的な構文は次のとおりです。
<data-source> | <spl-expr> ... | <spl-expr> ...
<data-source> はデータ ソースです。ログ クエリ シナリオの場合、インデックス クエリ ステートメントを指します。
< spl-expr > は、通常の値の取得、フィールド分割、フィールド投影、数値計算などの演算をサポートする SPL 命令です。詳細については、SPL 命令の概要を参照してください[ 2]。
構文定義からわかるように、SPL は当然ながらマルチステージ パイプラインをサポートします。ログ クエリ シナリオでは、クエリ ステートメントのインデックスを作成した後、必要に応じてパイプ文字を介して SPL 命令を継続的に追加でき、各ステップでクエリをクリックして現在の処理結果を表示できるため、Unix パイプライン処理と同様のエクスペリエンスが得られます。 。また、Unix 命令と比較して、SPL には豊富な演算子と関数があり、より柔軟なデバッグとログの探索分析が可能になります。
SPL を使用してログをクエリする
ログ クエリのシナリオでは、SPL はスキャン モードで動作し、インデックスを作成するかどうかやインデックスの種類に制限されることなく、非構造化生データを直接処理できます。スキャンの場合、請求はスキャンされた実際のデータ量に基づいて行われます。詳細については、「スキャン クエリの概要[ 3]」を参照してください。
統合されたクエリインタラクション
スキャン クエリとインデックス クエリの背後にある動作原理は異なりますが、ユーザー インターフェイス (コンソール クエリ、GetLogs API) では完全に統一された対話です。
ログをクエリする場合、インデックス クエリ ステートメントを入力すると、インデックスを介してクエリが実行されます。
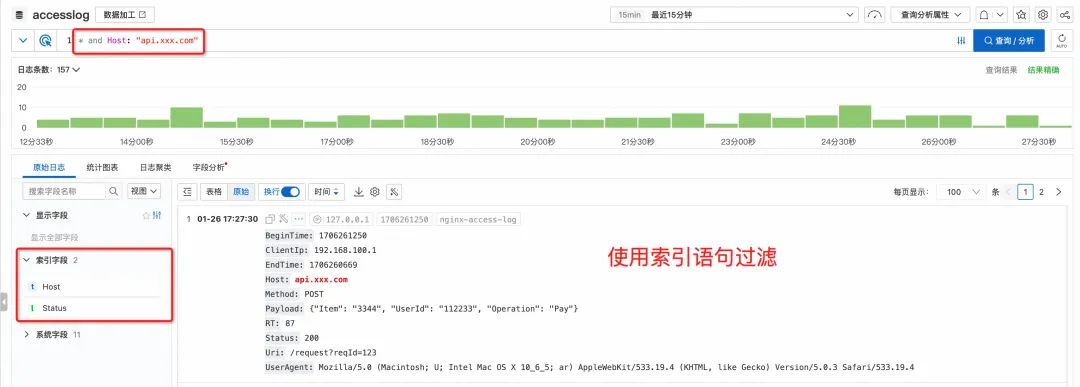
パイプ文字と SPL コマンドを入力し続けると、インデックス フィルタリングの結果がスキャン モードに従って自動的に処理され ([スキャン モード] ボタンを使用して追加で指定する必要はありません)、現在実行中であることを確認するメッセージが表示されます。 SPL入力モード。
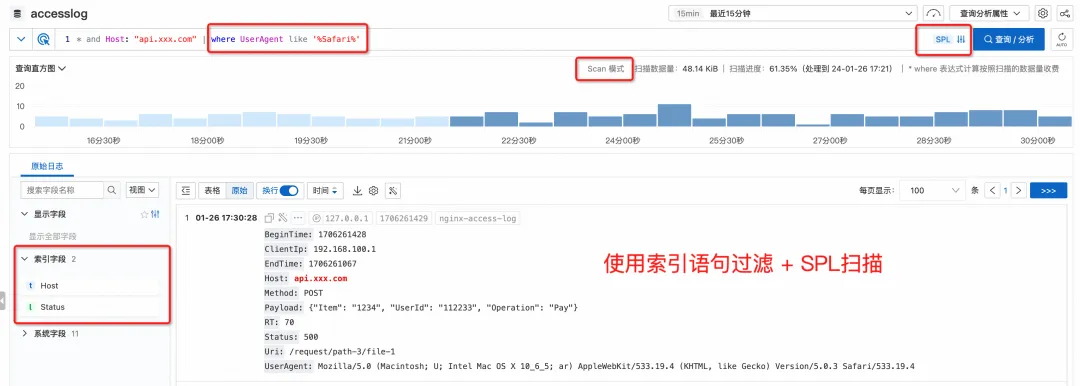
よりわかりやすい構文のヒント
さらに、コンソールでクエリを実行すると、現在の構文モードが自動的に識別され、SPL 関連の指示と機能に対するインテリジェントなプロンプトが表示されます。
入力すると、ドロップダウン ボックスに、対応する文法上のキーワードと関数が自動的に表示されます。
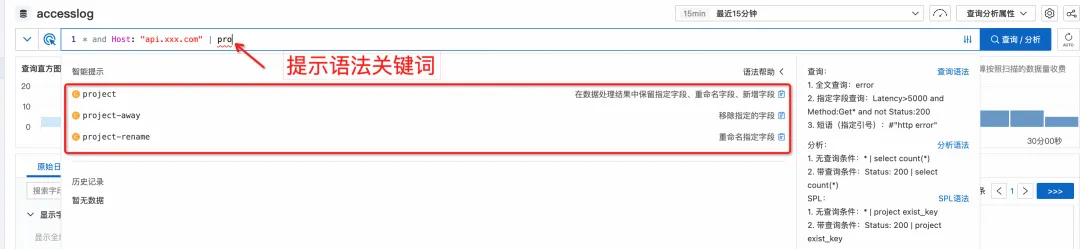
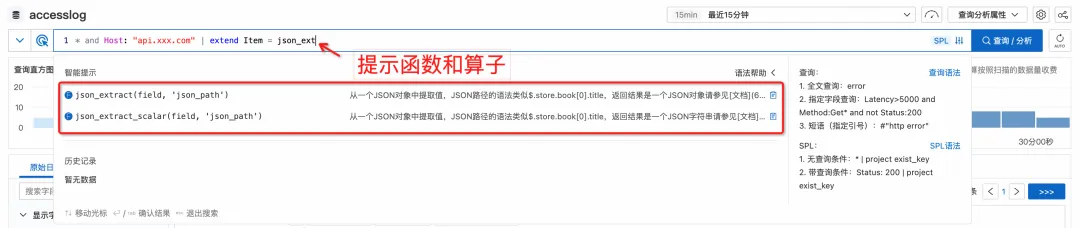
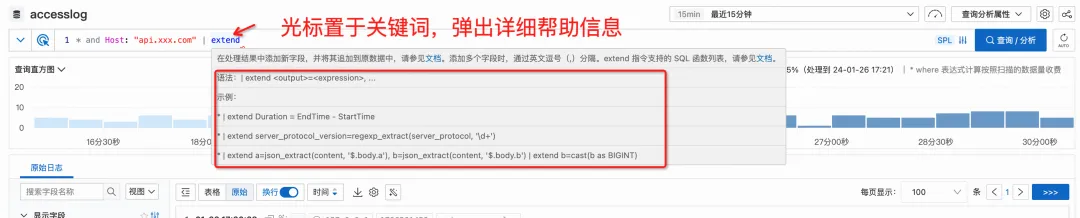
特定の構文の書き方を一時的に忘れた場合でも、現在のインターフェイスを離れてドキュメントを再度見つける必要はありません。キーワードの上にカーソルを移動するだけで、詳細なヘルプ情報がポップアップ表示されます。
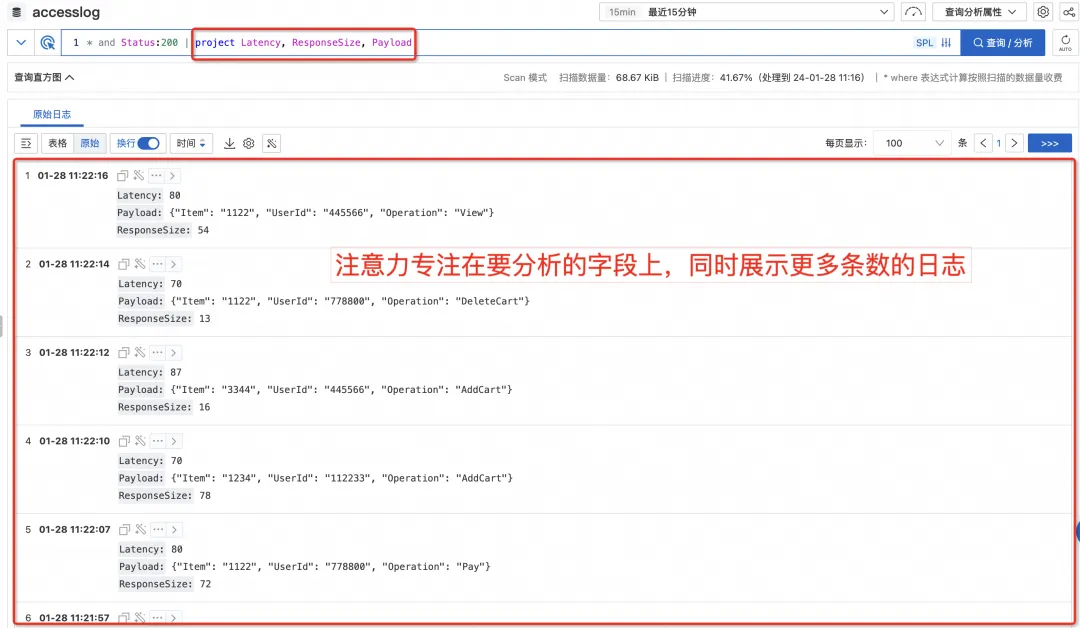
フィールドをフィルタリングしてより合理化されたビューを実現
ログを記録するとき、私たちは一般に、将来の潜在的な分析ニーズに備えて、可能な限り多くの関連情報をログに書き込もうとするため、最終的な 1 つのログにはさらに多くのフィールドが存在することがよくあります。
この場合、SLS コンソールにクエリを実行すると、1 つのログが多くのスペースを占有し、上部の棒グラフと横のクイック分析バーを折りたたんだ場合でも、元のログ領域に同時に表示できるログは 1 つまたは 2 つだけになります。 . ログの場合、他のログを表示するにはマウスをスクロールしてページを切り替える必要があり、使用が不便です。

ただし、実際には、ログをクエリするときは、特定の目的で検索することがよくありますが、現時点では通常、一部のフィールドのみに注目します。現時点では、SPL の project コマンドを使用して、関心のあるフィールドのみを保持することができます (または、project-away コマンドを使用して、表示する必要のないフィールドを削除できます。これにより、干渉が除去されるだけでなく、次のフィールドに注意を集中することができます)注目したい現在のフィールド、およびフィールドが合理化されているため、より多くのログを同時にプレビューできます。)
新しいフィールドはリアルタイムで計算されます
前述したように、ログの書き込み時に分析ニーズを完全に予測することはできないため、ログを分析する際には、多くの場合、既存のフィールドを処理して新しいフィールドを抽出する必要があります。これは、SPL の Extend コマンドを使用して実現できます。
Extend ディレクティブを使用すると、スカラー処理用の豊富な関数セット (そのほとんどは SQL 構文に共通) を呼び出すことができます。
Status:200 | extend urlParam=split_part(Uri, '/', 3)
同時に、2 つの数値フィールドの差を計算するなど、複数のフィールドに基づいて新しいフィールドを計算することもできます。 (フィールドはデフォルトでは varchar として扱われることに注意してください。数値型の計算を実行する場合は、まずキャストによって型を変換する必要があります)
Status:200 | extend timeRange = cast(BeginTime as bigint) - cast(EndTime as bigint
柔軟な多次元フィルタリング
インデックス クエリは、キーワード、複数のキーワードで構成されるフレーズ、最後にあるあいまいなキーワードなどの検索方法にのみ基づいて実行できます。スキャン モードでは、現在のスキャン クエリがすでに備えている機能を使用して、さまざまな条件に従ってフィルタリングできます。 SPL にアップグレードした後、計算された新しいフィールドをフィルターするためにパイプラインの任意のレベルに配置できるため、より柔軟で強力なフィルター機能が得られます。
たとえば、BeginTime と EndTime に基づいて TimeRange を計算した後、計算された値を判断してフィルタリングできます。
Status:200
| where UserAgent like '%Chrome%'
| extend timeRange = cast(BeginTime as bigint) - cast(EndTime as bigint)
| where timeRange > 86400
半構造化データを自由に拡張
ログでは、特定のフィールド自体が json や csv などの半構造化データである場合がありますが、分析するサブフィールドが多数ある場合は、extend コマンドを使用してサブフィールドの 1 つを抽出する必要があります。 json_extract_scalar や regexp_extract などのフィールド抽出関数を多数作成する必要がありますが、これはさらに不便です。
SPL は、json および csv タイプのフィールドを独立したフィールドに直接完全に拡張し、これらのフィールドを直接操作できる parse-json や parse-csv などの命令を提供します。これにより、フィールド抽出関数の作成コストが節約され、対話型のクエリ シナリオでより便利になります。
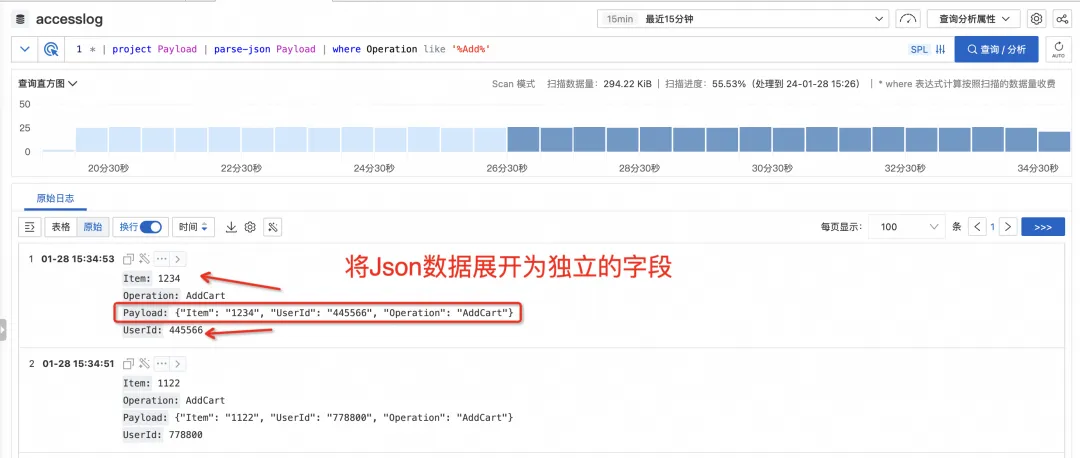
あなたが考えているすべてがあなたが見ているものになる、没入型の探検体験
ログを探索するプロセスでは、パイプラインを介して SPL 命令が継続的に入力され、各ステップでデータが処理されます。クエリ結果ページ ビューに具体化され、あなたが考えるものは、あなたが見るものであり、あなたが見るものは、あなたが得るものです。ステップバイステップのインタラクティブな探索では、最終的に分析する必要がある構造化情報を抽出します。
要約する
データ ソースの多様性と分析要件の不確実性により、ログ データは非構造化生データとして直接保存されることが多く、クエリ分析に特定の課題をもたらします。
SLS は、統合ログ処理言語 SPL を起動します。ログ クエリ シナリオでは、データの特徴をより便利に発見し、その後の構造化された分析と処理および消費プロセスをより適切に実行できるように、データをマルチレベル パイプラインを通じて対話的かつ段階的に探索できます。
現在、SPL のサポートを問い合わせる機能がさまざまな地域で開始されており、どなたでもご利用いただけます。ご質問やニーズがある場合は、作業指示書やサポート グループを通じてフィードバックをお寄せください。 SLS は、より使いやすく、より安定し、より強力な観察可能な分析プラットフォームを作成するために引き続き努力していきます。
関連リンク:
[1] SPLの概要
https://help.aliyun.com/zh/sls/user-guide/spl-overview
[2] SPL命令の紹介
https://help.aliyun.com/zh/sls/user-guide/spl-instruction?spm=a2c4g.11186623.0.0.197c59d4pRrjml
[3] スキャンクエリの概要
https://help.aliyun.com/zh/sls/user-guide/scan-based-query-overview
参考リンク:
[1] 寿司の原則
https://www.datasapiens.co.uk/blog/the-sushi-principle
[2] Unix コマンド、パイプ、プロセス
https://itnext.io/unix-commands-pipes-and-processes-6e22a5fbf749
[3] SPLの概要
https://help.aliyun.com/zh/sls/user-guide/spl-overview
[4] スキャンクエリの概要
https://help.aliyun.com/zh/sls/user-guide/scan-based-query-overview
[5] SLS アーキテクチャのアップグレード - コストの削減、パフォーマンスの向上、安定性の向上、使いやすさの向上
ライナスは、カーネル開発者がタブをスペースに置き換えるのを防ぐことに自ら取り組みました。 彼の父親はコードを書くことができる数少ないリーダーの 1 人であり、次男はオープンソース テクノロジー部門のディレクターであり、末息子はオープンソース コアです。寄稿者Robin Li: 自然言語 は 新しいユニバーサル プログラミング言語になるでしょう。オープン ソース モデルは Huawei にますます後れをとっていきます 。一般的に使用されている 5,000 のモバイル アプリケーションを Honmeng に完全に移行するには 1 年かかります。 リッチテキスト エディタ Quill 2.0 が リリースされ、機能、信頼性、開発者は「恨みを取り除く 」 ために握手を交わしました。 Laoxiangji のソースはコードではありませんが、その背後にある理由は非常に心温まるものです。Googleは大規模な組織再編を発表しました。