背景の紹介
レンジ (パーティショニング) は、データベースの管理とデータの整理のためのテクノロジーです。分散システムでは、特定のルールに従ってデータを複数の範囲に編成し、分割とマージを通じて動的管理を実現して、クエリのパフォーマンスを最適化し、システムのスケーラビリティと可用性および負荷分散を向上させることができます。このライブ ブロードキャストの主な内容は、KaiwuDB 分散システムにおける範囲の分割と結合です。
以下は内容の一部を抜粋したもので、全内容はクリックしてフルバージョンコンテンツをご覧ください >>フルバージョン動画再生
KaiwuDB 範囲分割
分割の概要
splitQueue は範囲分割を担当します。範囲分割をトリガーする条件は次のとおりです。
- 新しいデータベースまたはテーブルを作成します。
- 範囲サイズが range_max_bytes を超えています。
- Range の QPS が高すぎて、kv.range_split.load_qps_threshold (デフォルト値 250、構成可能) を超えています。
- インデックスまたはパーティションの構成ゾーンを変更して、親レベルから独立させます。特殊な場合には、adminSplit 分割は、splitQueue を経由せずに直接呼び出されます。
- 大量のデータをインポートすると、1 つの範囲が自動的に複数の範囲に分割されます。
- データをインポートするとき、後でインポートされる可能性のあるデータ用に空白の範囲が事前に分割されます。
- 手動分割: alter table table_name spatials (key1,key2,…); ここで、Values は主キーの値を表します。結合主キーの場合は、複数の値を書き込むことができます。主キー列。
分割アルゴリズムのフローチャート
KaiwuDB の特定のノードには、関連する Range の分割を処理するためにバックグラウンドで実行される別のスレッド/ワーカーがあります。範囲分割は 2 つのフェーズに分かれています: フェーズ 1 - 範囲分割パラメータの準備; フェーズ 2 - 範囲とそのインデックス構造の更新。

図に示すように、左側のプロセスは主に Range を分割するための準備です。
まず、分割した Range の Key のキー値をロックします。このキー値を見つけた後、システムは現在の範囲範囲を調整し、分割キーのキー値をパーティションの終了キー値として使用します。
このプロセスでは、右側の新しい Range が作成されます。その開始キー値は分割に使用されるキー値であり、終了キー値は元の Range の終了キー値です。同時に、元の Range が分割された後、そのバージョンが 1 ずつ更新され、更新されたバージョンが左右の分割 Range に同時に適用されます。
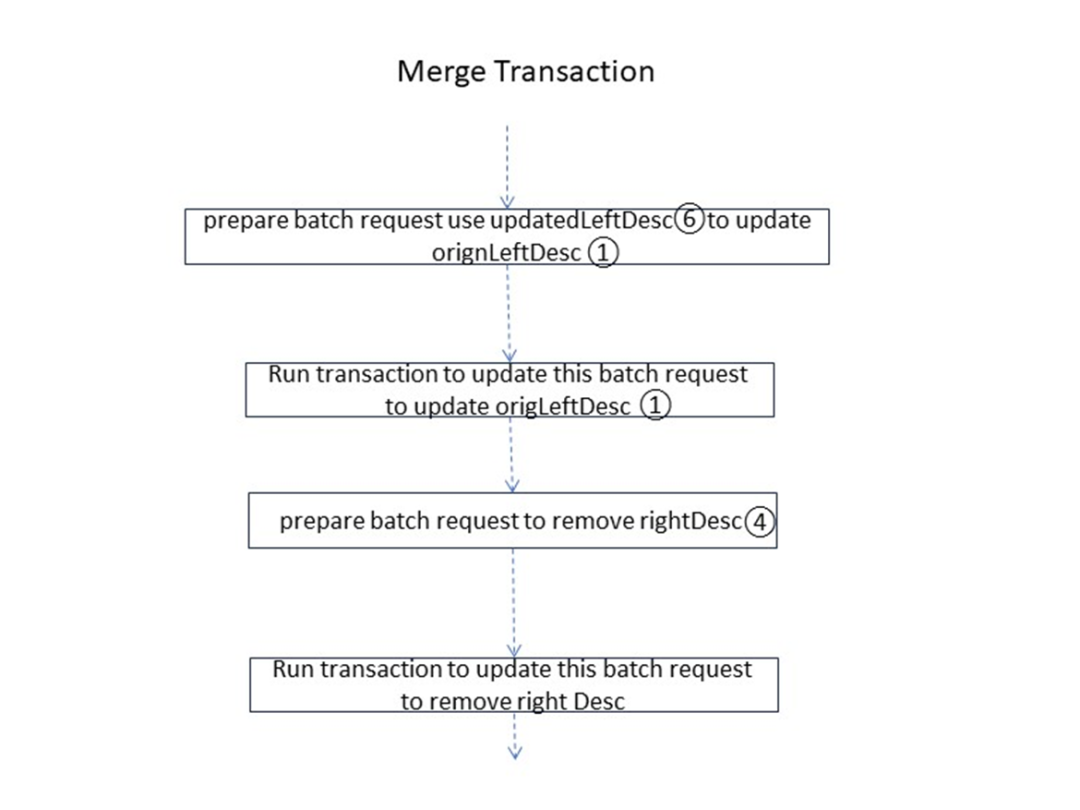
Range の左側と右側の分割パラメータが準備できたら、プロセスはシステム データ更新フェーズに入ります。つまり、書き込みリクエストを準備し、リクエストを処理する必要があります。このプロセスはトランザクション全体に関連付けられます。取引では以下の事項を完了する必要があります。
新しいトランザクションを開始します。ステータスは保留中です
- 左の範囲を更新
- 新しい右の範囲を書き込む
- 左側の Big Mac インデックスの 2 レベルのツリー構造の対応する検索パスを更新します。
- Big Mac インデックスの 2 レベルのツリー構造の対応する検索パスを右側の範囲に挿入します。
- 更新トランザクションのステータスは「コミット済み」です
- 左右のRangeのMVCCを更新
- 執筆意図を整理する
この時点で、Range 全体の分割が完了します。
スプリットトリガーの例
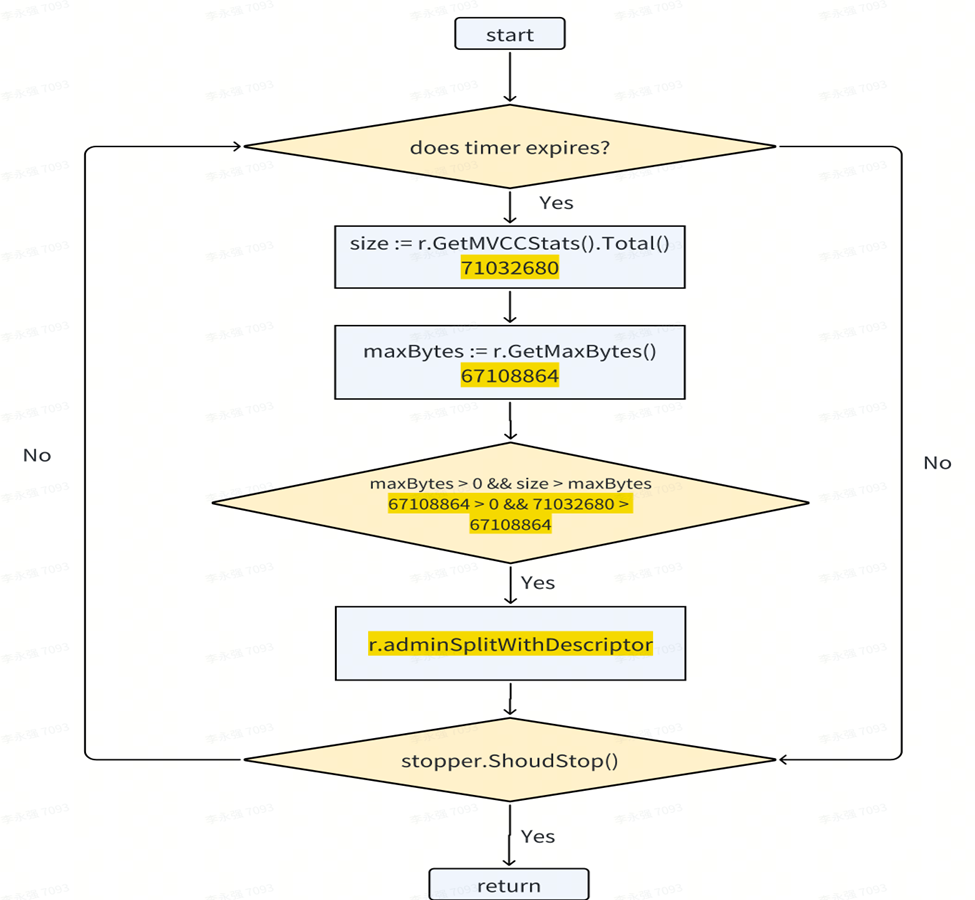
次のデバッグ トリガー シナリオは、範囲サイズが所定の臨界値を超えた後に発生します。各範囲は、タイマー待ちのシリアル方式で処理されます。クロックが起動した後、範囲サイズがチェックされ、範囲サイズが約 70MB で、事前に設定された範囲の 64M を超えていることが判明した場合、システムは範囲分割機能をトリガーして、容量制限を超える範囲を分割します。
バックグラウンド スレッドまたはワーカーは、ループ内で処理するためにすべての Range を継続的にチェックします。
KaiwuDB 範囲のマージ (マージ)
マージの例
図に示すように、ユーザーが大量のデータを削除すると、隣接する 2 つの範囲のサイズが急激に減少し、システムによってそれらが結合されます。

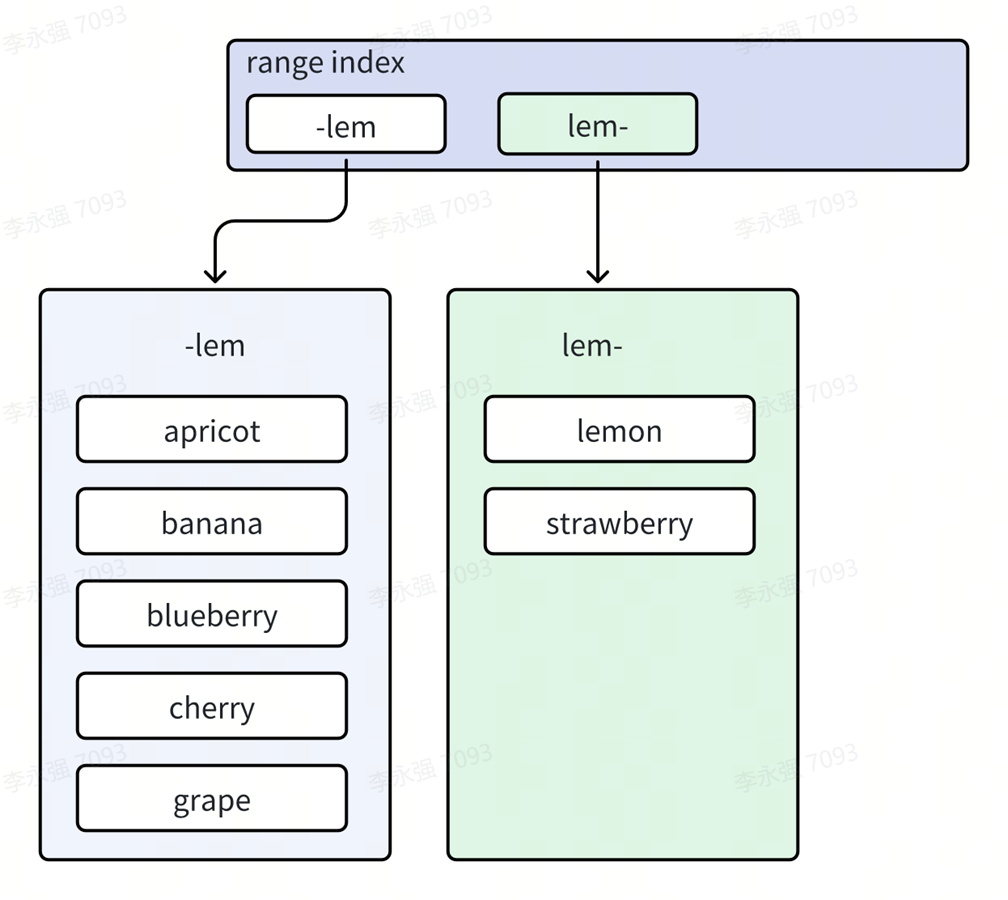
次の図は、前の 2 つの範囲 (lem-str、str-) がマージされ、str- が消え、元の 2 つの範囲のキー値だけが同じ範囲 lem- にマージされた後の効果を示しています。 。 -。これに対応して、ビッグ マック インデックスの第 2 レベルのデータ構造も調整され、第 1 レベルのツリー インデックス構造のエンドウは消えています。
結合条件
範囲を結合するための条件は比較的厳密で、主に次のようなものがあります。 結合が無効になっていない 次の範囲と同じ構成ゾーンがある 結合される 2 つの範囲のサイズが range_min_bytes 未満である 結合後に QPS の範囲分割がトリガーされない
最後の方法は、データが配置されている範囲にホット データがある場合、マージは実行されないことを意味します。マージによって分割がトリガーされ、システムが正常に動作しなくなるためです。
マージアルゴリズムのフローチャート
図に示すように、マージも分割と同様に 2 つの段階に分かれています。第 1 段階 - 範囲パラメーターの準備 - 第 2 段階 - 範囲更新処理のトランザクションの有効化。完全なコンテンツについては、クリックしてフルバージョンのコンテンツを表示 >> [フルバージョンのビデオ再生] ( https://www.bilibili.com/video/BV11y421z7jH/?spm_id_from=333.999.0.0 )
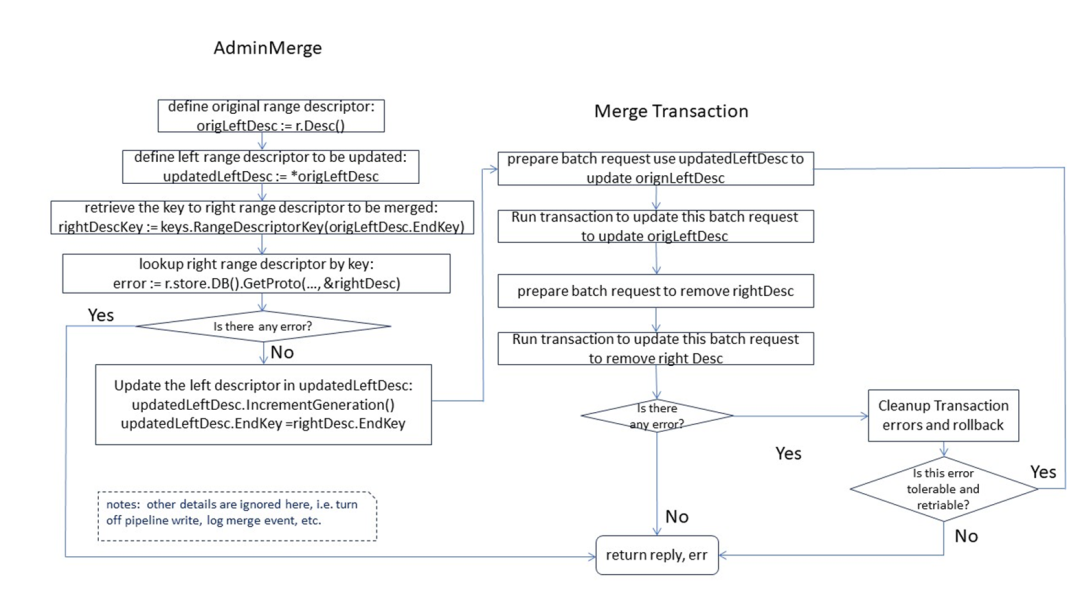
マージのデバッグ例 次の 2 つの概略図は、Range マージのデバッグの具体的なプロセスと、対応する Range 関連パラメーターを示しています。