
前に書く
この記事では、2023 年に SIGMOD で発表された論文「Kepler: Robust Learning for Faster Parametric Query Optimization」を主に紹介します。この記事では、クエリのパフォーマンスを向上させながらクエリの計画時間を短縮することを目的として、パラメータ化されたクエリの最適化とパラメータ化されたクエリのクエリの最適化を組み合わせています。
この目的を達成するために、著者は Kepler (K-plan Evolution for Parametric Query Optimization: Learned, Empirical, Robust) と呼ばれるエンドツーエンドの深層学習ベースのパラメトリック クエリ最適化手法を提案します。
数値クエリは、同じ SQL 構造を持ち、バインドされたパラメータ値のみが異なるタイプのクエリを指します。例として、次のクエリ構造を考えてみましょう。
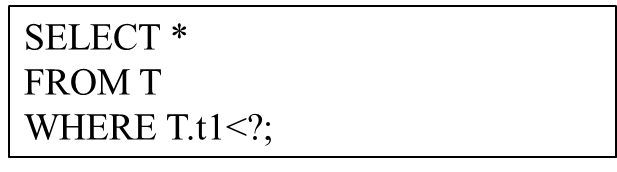
クエリ構造はパラメータ化されたクエリのテンプレートとみなすことができ、「?」はさまざまなパラメータ値を表します。ユーザーが実行する SQL ステートメントはすべてこのクエリ構造を持っていますが、実際のパラメータ値は異なる場合があります。これはパラメータ化されたクエリです。このようなパラメータ化されたクエリは、最新のデータベースで非常に頻繁に使用されます。同じクエリ テンプレートを継続的に繰り返し実行するため、クエリのパフォーマンスを向上させる機会が得られます。
パラメーター化されたクエリの最適化 (PQO) は、前述のパラメーター化されたクエリのパフォーマンスを最適化するために使用され、その目的は、パフォーマンスの低下を回避しながらクエリの計画時間をできるだけ短縮することです。既存のアプローチは、システムの組み込みクエリ オプティマイザーに依存しすぎているため、オプティマイザー固有の準最適性の影響を受けやすくなっています。著者は、パラメータ化されたクエリの理想的なシステムは、PQO によってクエリの計画時間を短縮するだけでなく、クエリの最適化 (QO) によってシステムのクエリ実行パフォーマンスも向上させる必要があると考えています。
クエリ最適化 (QO) は、クエリが最適な実行プランを見つけられるようにするために使用されます。クエリの最適化を改善するための既存の方法のほとんどは、機械学習ベースのカーディナリティ/コスト推定器などの機械学習を適用しています。しかし、現在の学習に基づくクエリ最適化手法には、(1) 推論時間が長すぎる、(2) 汎化能力が低い、(3) パフォーマンスの向上が不明確である、(4) 性能が向上しない、などの欠点があります。そしてパフォーマンスが低下する可能性があります。
上記の欠点は、予測結果の実行時間の改善を保証できないため、学習ベースの方法に課題をもたらします。上記の問題を解決するために、著者は、エンドツーエンドの学習ベースのパラメータ化されたクエリ最適化手法である Kepler を提案します。
著者らは、パラメトリック クエリの最適化を、候補計画の生成と学習ベースの予測構造という 2 つの問題に分離します。これは主に、新しい候補プランの生成、トレーニング データの収集、および堅牢なニューラル ネットワーク モデルの設計の 3 つのステップに分かれています。 3 つを組み合わせることで、クエリの実行パフォーマンスを向上させながらクエリの計画時間を短縮し、PQO と QO の目標を達成します。次に、まず Kepler の全体的なアーキテクチャを紹介し、次に各モジュールの具体的な内容を詳しく説明します。
全体的なアーキテクチャ
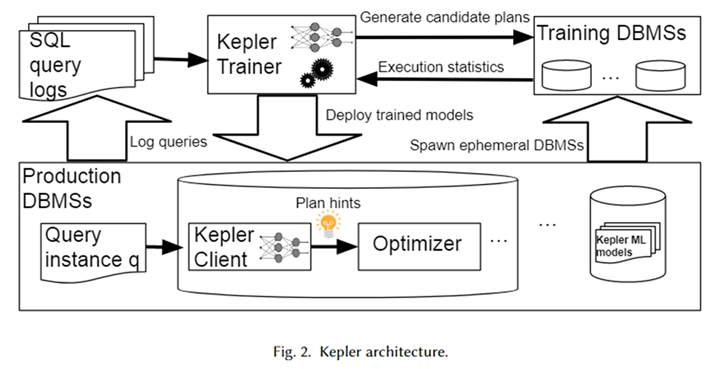
Kepler の全体的なアーキテクチャを上の図に示します。まず、データベース システム ログからパラメータ化されたクエリ テンプレートと対応するクエリ インスタンス (つまり、実際のパラメータ値を含むクエリ) を取得して、ワークロードを形成します。 Kepler Trainer は、このワークロードのニューラル ネットワーク予測モデルをトレーニングするために使用されます。まず、ワークロード全体に対して候補プランを生成し、それらを一時データベース システム上で実行して、実際のクエリ実行時間を取得します。
このクエリ時間を使用して、ニューラル ネットワーク モデルをトレーニングします。トレーニングが完了すると、Kepler クライアントと呼ばれる運用環境のデータベース システムにデプロイされます。ユーザーがクエリ インスタンスを入力すると、Kepler クライアントはその最適な実行プランを予測し、それをプラン ヒントの形式でオプティマイザに渡し、最適なプランを生成して実行します。
候補プランの生成: 行数の進化
候補プラン生成の目標は、ワークロード内の各クエリ インスタンスに対して最適に近い実行プランを含む一連のプランを構築することです。さらに、後続のトレーニング データ収集プロセスでの過剰なオーバーヘッドを避けるために、可能な限り小さくする必要があります。この 2 つは相互に制約し合うため、これら 2 つの目標のバランスをどう取るかが、候補計画を作成する際の大きな課題となります。
式 1 は、具体的な計画生成の目標を定式化します。このうち、 はワークロード W 上のクエリ インスタンス、 はオプティマイザによって選択された実行プラン、 は理想的な環境下でのプラン セット内の最適なプラン、 ExecTime はインスタンス上の対応するプランの実行時間です。したがって、式 1 の意味は、ワークロード全体にわたってオプティマイザーによって生成されたプラン セットと比較した、候補プラン セットの実行時間の加速です。アルゴリズムは、この高速化を最大化するように設計されています。
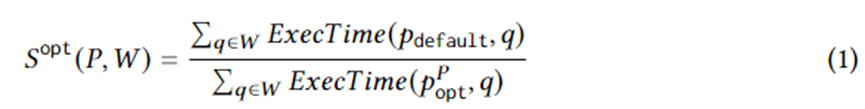
この目的を達成するために、この文書では、オプティマイザのカーディナリティ推定をランダムに変動させることによって新しいプランを生成するアルゴリズムである Row Count Evolution (RCE) を提案します。各クエリ インスタンスの一連のプランを生成し、ワークロード全体の候補プランのセットに結合します。このアルゴリズムの背後にある考え方は、ベースの誤った推定がオプティマイザーの準最適性の主な原因であるというものです。同時に、候補プランの生成段階では、クエリ インスタンスごとに特定の単一の (ほぼ) 最適なプランを見つける必要はなく、(ほぼ) 最適なプランを含めるだけで済みます。
RCE アルゴリズムは、反復を通じて新しい計画を継続的に生成します。まず、最初の反復計画は、オプティマイザーによって生成された計画です。後続の反復を構築するには、まず、前の世代計画からの一様ランダム サンプリングが必要です。サンプリングされたプランごとに、その結合サブプランのカーディナリティを摂動 (変更) します。
摂動法では、現在の推定カーディナリティの指数区間内でランダムにサンプリングします。摂動されたカーディナリティはオプティマイザに渡され、対応する最適なプランが生成されます。各プランをN回繰り返すことで多数の実行プランが生成され、その中でまだ出現していない実行プランは次世代のプランとして残され、上記の処理が繰り返されます。
以下の図に示すように、上記のアルゴリズムを視覚的に説明するために、具体的な例を示します。まず、基本プランは、オプティマイザーによって選択された最適なプランです。これには、A 結合 B と C 結合 D という 2 つの結合サブプランがあります。それらの推定ベースはそれぞれ 40 と 17 です。
次に、指数区間範囲 10-1 ~ 101 (それぞれ [4,40,400] と [1,17,170]) から 2 つの結合サブプランに対して摂動セットが生成されます。摂動セットからランダムなサンプルが取得され、プラン選択のためにオプティマイザーに渡されます。プラン 1 は、カーディナリティがそれぞれ 400 と 17 の場合にオプティマイザによって選択される新しいプランです。これをN回繰り返し、最終的に次世代のC1プランが生成されます。次に、その中から S プランをサンプリングし、プランごとに上記のプロセスを繰り返して、第 2 世代のプランを作成します。
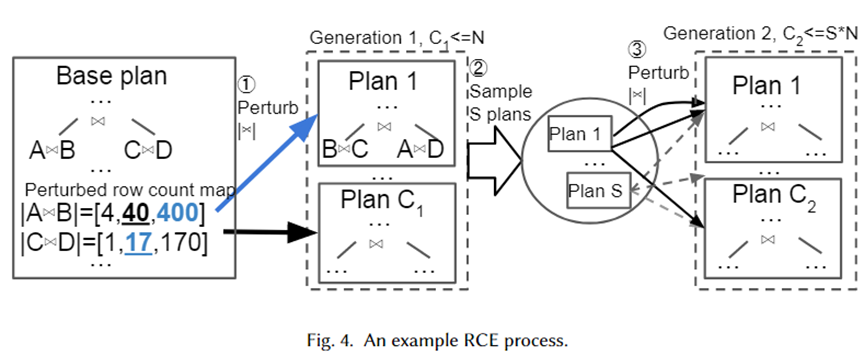
著者らが摂動セットとして指数関数的な間隔範囲を採用した理由は、オプティマイザのカーディナリティ推定誤差の分布に適合させるためです。上記のアルゴリズムから、摂動の数が十分に大きい限り、多数のカーディナリティとそれに対応するプランが生成されることがわかります。このようにして、クエリ インスタンスが到着すると、プラン セット内に真のカーディナリティに近いプランが存在するはずです。これは、インスタンスにとって (ほぼ) 最適なプランと見なすことができます。
トレーニングデータの収集
候補プランのセットを生成した後、各プランがワークロード上で実行され、教師付き最適プラン予測のための実行時間データが生成されます。オプティマイザーによって推定されたコストではなく、実際の実行データを使用すると、オプティマイザーの準最適性によって引き起こされる制限を回避できます。実行プロセスは並列化可能です。ただし、すべての計画を実行するには多大な費用がかかります。したがって、著者らは、不必要な次善の計画の実行によって引き起こされるリソースの無駄を削減するための 2 つの戦略を提案します。
適応型タイムアウトとプラン実行の並べ替え、適応型タイムアウトとプラン実行の並べ替え。作成者は、最適ではない計画の実行を制限するためにタイムアウト メカニズムを採用しています。各クエリ インスタンスについて、各プランを実行するときに、現在の最小実行時間を記録できます。
プランの実行時間が最小実行時間の一定範囲を超えると、それは明らかに最適な実行プランではないため、実行できなくなります。同時に、最小実行時間は常に更新されます。さらに、他のクエリ インスタンスでの各プランの実行に基づいてクエリ プランを実行時間の昇順に実行することをヒューリスティックとして使用して、タイムアウト メカニズムを高速化することができます。
剪定をカバーするオンライン プラン、剪定を設定したオンライン プラン。最初の N 個のクエリ インスタンスに対してすべてのプランが実行された後、Set Cover 問題を使用してそれらのプランが K 個のプランに切り詰められます。その後のデータ収集とモデルのトレーニングでは、これらの K プランが使用されます。セットカバー問題は以下のように定義されます。
この記事のコンテキストでは、 はすべてのクエリ インスタンスを表し、さまざまなプランとして表すことができます。各プランは、あるクエリ インスタンスにとって最適に近いプランです。したがって、問題は、すべてのクエリ インスタンスに対して最適に近い状態を提供するために、可能な限り最小のプランのセットを使用するものとして定式化できます。問題は NP であるため、著者は貪欲なアルゴリズムを使用してそれを解決します。

堅牢な最適計画予測
候補プラン セットの実際の実行時間に関するトレーニング データを収集した後、教師あり機械学習を使用してクエリ インスタンスに対する最適なプランを予測します。トレーニング目標は、次の式で論理的に表現できます。ここで、 はクエリ インスタンスのモデルによって選択された最適なプランを表します。この式の意味は、オプティマイザによって選択されたプランと比較して、モデルによって選択されたプランによってもたらされる高速化です。その上限は式 1 です。言い換えれば、モデルは、RCE によって生成された候補計画によってもたらされる加速を可能な限りキャプチャする必要があります。
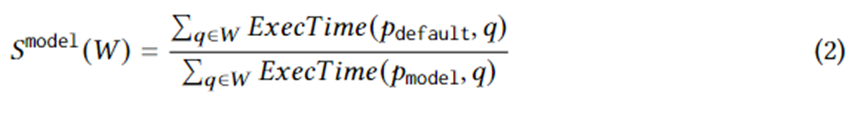
モデルの構造はフォワード ニューラル ネットワークを採用し、機械学習の不確実性における最新の進歩、つまりスペクトル正規化ニューラル ガウス プロセス (SNGP) を適用します。これをニューラル ネットワークに組み合わせると、モデルの収束性が向上し、同時にニューラル ネットワークが予測の不確実性を出力できるようになります。不確実性がしきい値よりも高い場合、計画予測の作業はオプティマイザーに返され、最適な計画が決定されます。
モデルは、各パラメーターの実際の値を使用して特徴付けられます。パラメータの実際の値をニューラル ネットワークに入力するには、特に文字列型データの場合、いくつかの前処理が必要です。文字列型データの場合、作成者は固定サイズのボキャブラリとそのボキャブラリにないバケットを使用してワンホット ベクトルとして表現し、埋め込み層を追加してワンホット ベクトルの埋め込みを学習し、文字列型のデータを扱えるようになります。
実験効果
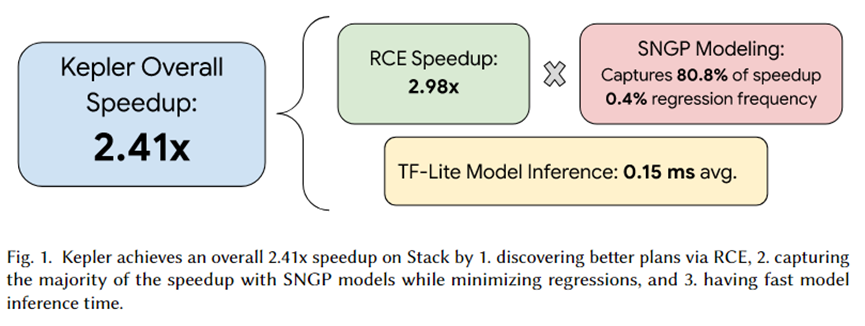
この記事の著者は Kepler を PostgreSQL に統合し、一連の実験を組織しました。実験の概要を上図に示します。ケプラーによる合計加速効果は 2.41 倍です。このうち、RCE によって生成された候補プラン セットは約 2.92 倍の高速化を実現でき、80.8% は SNGP 予測モデルによって捕捉され、回帰は 0.4% のみ達成されます。さらに、モデルの推論時間は平均でわずか 0.15 ミリ秒です。
要約する
この論文では、パラメータ化されたクエリを強力に高速化する学習ベースのアプローチである Kepler を提案します。 Row Count Evolution (RCE) アルゴリズムを通じて候補プラン セットを生成し、それをワークロード上で実行して実際の実行時間を取得し、その実際の実行時間を使用して予測モデルをトレーニングします。
予測モデルには、機械学習の不確実性推定における最新の進歩であるスペクトル正規化ニューラル ガウス プロセス (SNGP) が採用されており、この不確実性に基づいて予測の不確実性を出力しながら収束を向上させ、モデルまたはオプティマイザーが予測を完了するかどうかが選択されます。計画の予測。実験により、RCE が高い加速効果をもたらすことが証明されており、SNGP は回帰を回避しながら、RCE によってもたらされる加速効果を可能な限り捉えることができます。したがって、PQO と QO の目標は同時に達成されます。つまり、クエリの計画時間を短縮しながら、クエリの実行パフォーマンスが向上します。
私はオープンソースの産業用ソフトウェアを諦めることにしました - OGG 1.0 がリリースされ、Huawei がすべてのソース コードを提供しました。Google Python Foundation チームは「コード クソ マウンテン」によって解雇されました 。 Fedora Linux 40が正式リリース。有名ゲーム会社がリリース 新規定:従業員の結婚祝儀は10万元を超えてはならない。チャイナユニコム、世界初のオープンソースモデルLlama3 8B中国語版をリリース。Pinduoduoに賠償判決国内のクラウド入力方式に500万元の罰金- クラウドデータアップロードのセキュリティ問題がないのはファーウェイだけ