
1. 背景の紹介
パラメーター化されたクエリは、同じテンプレートを持ち、述語バインディング パラメーター値のみが異なるタイプのクエリを指し、最新のデータベース アプリケーションで広く使用されています。これらはアクションを繰り返し実行するため、パフォーマンスを最適化する機会が得られます。
ただし、多くの商用データベースでパラメーター化されたクエリを処理する現在の方法では、クエリ内の最初のクエリ インスタンス (またはユーザー指定のインスタンス) のみが最適化され、その最適なプランがキャッシュされ、それが後続のクエリ インスタンスで再利用されます。この方法では時間を最小化するように最適化しますが、クエリ インスタンスごとに最適なプランが異なるため、キャッシュされたプランの実行が任意に準最適になる可能性があり、実際のアプリケーション シナリオには適用できません。
従来の最適化手法のほとんどは、クエリ オプティマイザーに関する多くの前提条件を必要としますが、これらの前提条件は実際のアプリケーション シナリオと一致しないことがよくあります。幸いなことに、機械学習の台頭により、上記の問題は効果的に解決できるようになりました。今号では、VLDB2022 と SIGMOD2023 で発表された 2 つの論文を詳しく紹介します。
论文 1:《パラメトリック クエリ最適化のためのクエリ ログと機械学習の活用》
论文 2:《Kepler: より高速なパラメトリック クエリ最適化のための堅牢な学習》
2. 論文の本質 1
「パラメトリック クエリの最適化のためのクエリ ログと機械学習の活用」 この文書では、パラメータ化されたクエリの最適化を次の 2 つの問題に分割します:
(1) PopulateCache: クエリ テンプレートの K プランをキャッシュします。
(2) getPlan: 各クエリ インスタンスに対して、最適なプランを選択します。キャッシュされた計画。
この論文のアルゴリズム アーキテクチャを次の図に示します。これは主に、PopulateCache モジュールと getPlan モジュールの 2 つのモジュールに分かれています。
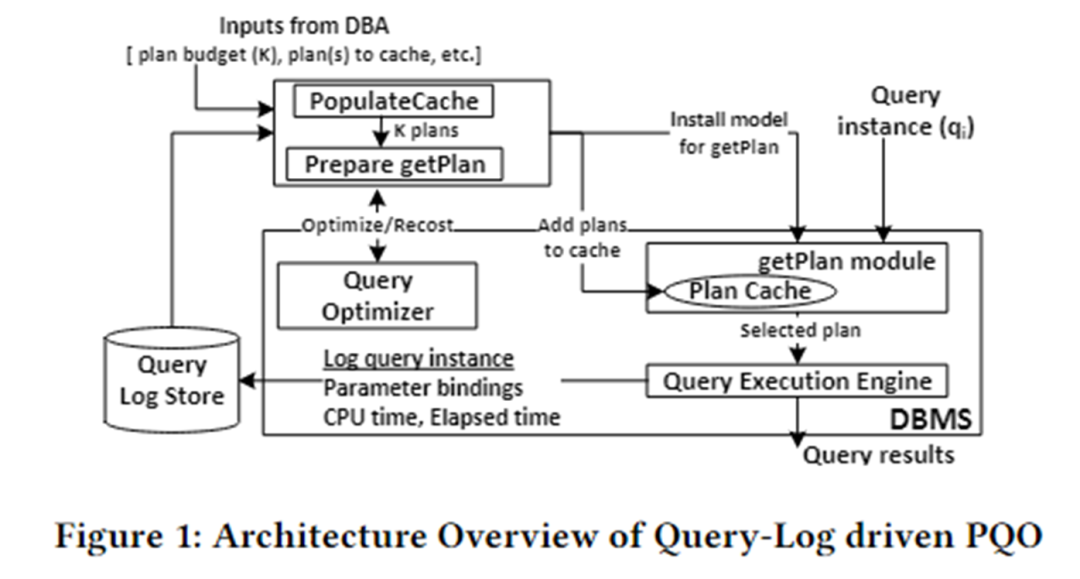
PopulateCache は、クエリ ログ内の情報を使用して、すべてのクエリ インスタンスの K プランをキャッシュします。 getPlan モジュールは、まずオプティマイザーと対話して K プランとクエリ インスタンス間のコスト情報を収集し、この情報を使用して機械学習モデルをトレーニングします。トレーニングされたモデルを DBMS にデプロイします。クエリ インスタンスが到着すると、そのインスタンスに最適なプランをすぐに予測できます。
PopulateCache
PolulateCache モジュールは、特定のパラメーター化されたクエリのキャッシュ プランのセットを識別する役割を果たします。検索フェーズでは、次の 2 つのオプティマイザー API を使用します。
- オプティマイザー呼び出し: クエリ インスタンスに対してオプティマイザーによって選択されたプランを返します。
- 再コスト呼び出し: オプティマイザーによってクエリ インスタンスと対応するプランに対して推定されたコストを返します。
アルゴリズムの流れは次のとおりです。
- プラン収集フェーズ: オプティマイザー呼び出しを呼び出して、クエリ ログ内の n 個のクエリ インスタンスの候補プランを収集します。
- 計画 - 再コスト フェーズ: 各クエリ インスタンスおよび各候補プランに対して、再コスト呼び出しを呼び出して、計画 - 再コスト マトリックスを形成します。
- K セット識別フェーズ: 貪欲なアルゴリズムを採用し、プラン再コスト マトリックスを使用して K プランをキャッシュし、準最適性を最小限に抑えます。
計画を取得する
getPlan モジュールは、特定のクエリ インスタンスに対して実行する K 個のキャッシュされたプランの 1 つを選択する役割を果たします。 getPlan アルゴリズムでは、オプティマイザによって推定されるコストを最小化すること、または K 個のキャッシュ プラン間で実際の実行コストを最小化することの 2 つの目標を考慮できます。
目標 1 を検討してください。計画-再コスト マトリックスを使用して教師あり ML モデルをトレーニングし、分類と回帰を検討します。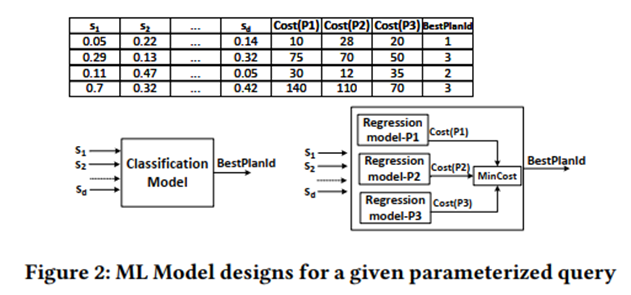
目標 2: Multi-Armed Bandit に基づく強化学習トレーニング モデルを使用することを検討します。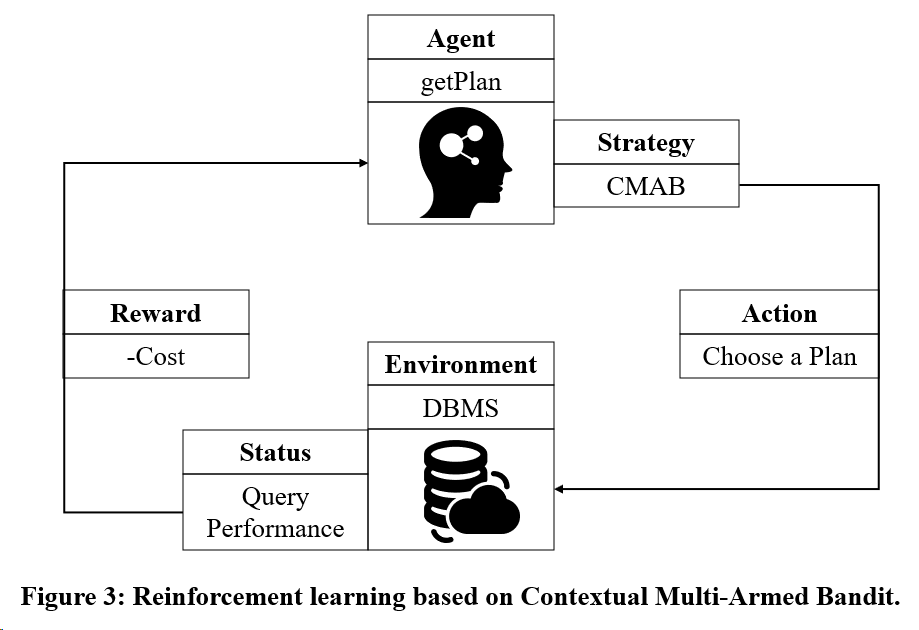
3. 論文の本質 2
「Kepler: より高速なパラメトリック クエリ最適化のための堅牢な学習」 この論文では、クエリの最適化時間を短縮し、クエリの実行パフォーマンスを向上させることを目的とした、エンドツーエンドの学習ベースのパラメトリック クエリ最適化手法を提案します。
Kepler のアルゴリズム アーキテクチャは、問題を計画生成と学習ベースの計画予測の 2 つの部分に分離します。これは主に、プラン生成戦略、トレーニング クエリ実行フェーズ、堅牢なニューラル ネットワーク モデルの 3 つのステージに分かれています。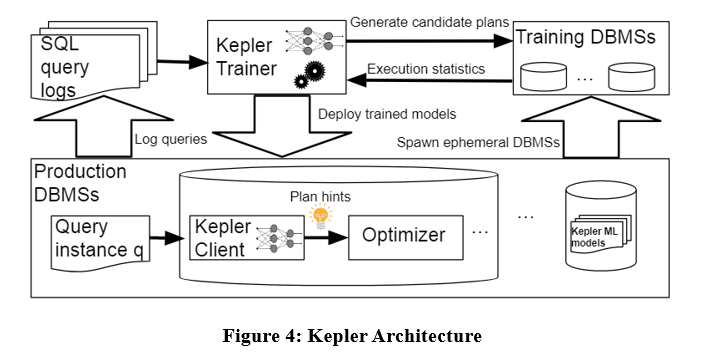
上図のように、Kepler Trainer にクエリログのクエリインスタンスを入力すると、Kepler Trainer は候補プランを生成し、その候補プランに関連する実行情報を学習データとして収集し、学習後に機械学習モデルを学習します。モデルは DBMS にデプロイされます。クエリ インスタンスが到着すると、Kepler クライアントを使用して最適な計画を予測し、それを実行します。
行数の推移
この論文では、オプティマイザのカーディナリティ推定に摂動を加えることによって候補プランを生成する、Row Count Evolution (RCE) と呼ばれる候補プラン生成アルゴリズムを提案します。
このアルゴリズムのアイデアは、カーディナリティの誤った推定がオプティマイザの準最適性の主な原因であり、候補プランの生成段階には、単一の最適プランを選択するのではなく、1 つのインスタンスの最適プランを含めるだけでよいということから来ています。
RCE アルゴリズムは、最初にクエリ インスタンスに最適なプランを生成し、次に指数関数的な間隔の範囲内でそのサブプランの結合カーディナリティを撹乱し、それを複数回繰り返して反復を実行し、最後に生成されたすべてのプランを候補プランとして使用します。具体的な例としては以下のようなものがあります。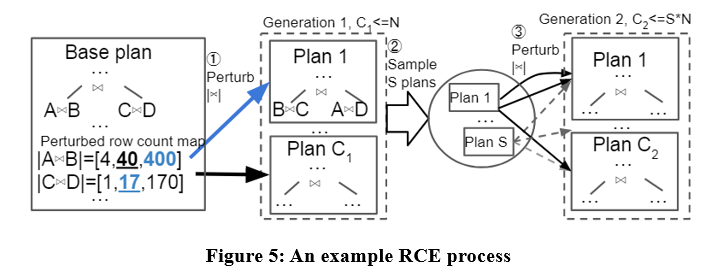
RCE アルゴリズムを使用すると、生成された候補プランが、オプティマイザーによって生成されたプランよりも優れている可能性があります。オプティマイザにはカーディナリティ推定エラーがある可能性があり、RCE はカーディナリティ推定を継続的に変動させることで、正しいカーディナリティに対応する最適なプランを生成できるためです。
トレーニングデータの収集
候補プラン セットを取得した後、各クエリ インスタンスのワークロードで各プランが実行され、教師付き最適プラン予測モデルのトレーニングのために実際の実行時間が収集されます。上記のプロセスは比較的面倒ですが、この記事では、並列実行、適応型タイムアウト メカニズムなど、トレーニング データの収集を高速化するためのいくつかのメカニズムを提案します。
堅牢なベストプラン予測
結果として得られる実際の実行データは、各クエリ インスタンスに最適なプランを予測するニューラル ネットワークのトレーニングに使用されます。使用されるニューラル ネットワークは、スペクトル正規化ガウス ニューラル プロセスです。このモデルは、ネットワークの安定性とトレーニングの収束を保証し、予測の不確実性の推定を提供します。不確実性の推定値が特定のしきい値より大きい場合、実行計画の選択はオプティマイザーに委ねられます。パフォーマンスの低下はある程度回避されます。
4. まとめ
上記 2 つの論文は両方とも、パラメーター化されたクエリを PopulateCache と getPlan に分離しています。両者の比較を以下の表に示します。
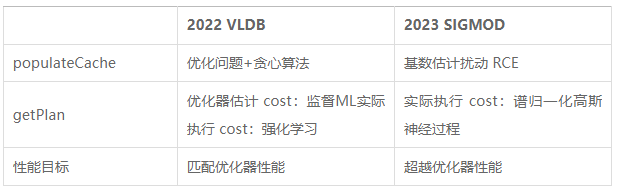
機械学習モデルに基づくアルゴリズムは計画予測では優れたパフォーマンスを発揮しますが、トレーニング データ収集プロセスは高価であり、モデルを一般化して更新するのは簡単ではありません。したがって、既存のパラメーター化されたクエリ最適化方法には、まだ改善の余地があります。
本文図示出典: 1)Kapil Vaidya & Anshuman Dutt、《Leveraging Query Logs and Machine Learning for Parametric Query Optimization》、2022 VLDB、https://dl.acm.org/doi/pdf/10.14778/3494124.3494126 2)LYRIC DOSHI & VINCENT ZHUANG、《Kepler: より高速なパラメトリック クエリ最適化のためのロバスト学習》、2023 SIGMOD、https://dl.acm.org/doi/pdf/10.1145/3588963
私はオープンソースの産業用ソフトウェアを諦めることにしました - OGG 1.0 がリリースされ、Huawei がすべてのソース コードを提供しました。Google Python Foundation チームは「コード クソ マウンテン」によって解雇されました 。 Fedora Linux 40が正式リリース。有名ゲーム会社がリリース 新規定:従業員の結婚祝儀は10万元を超えてはならない。チャイナユニコム、世界初のオープンソースモデルLlama3 8B中国語版をリリース。Pinduoduoに賠償判決国内のクラウド入力方式に500万元の罰金- クラウドデータアップロードのセキュリティ問題がないのはファーウェイだけ