
大規模言語モデル (LLM) テクノロジーの発展に伴い、RAG (検索拡張生成) テクノロジーが広く議論および研究され、ますます高度な RAG 検索方法が発見されています。通常の RAG 検索と比較して、高度な RAG はより正確な検索を提供します。より深い技術的詳細とより複雑な検索戦略を通じて、より関連性の高い豊富な情報検索結果が得られます。この記事では、まずこれらのテクノロジーについて説明し、Milvus に基づいた実装事例を示します。
01.ジュニアRAG
プライマリ RAG の定義
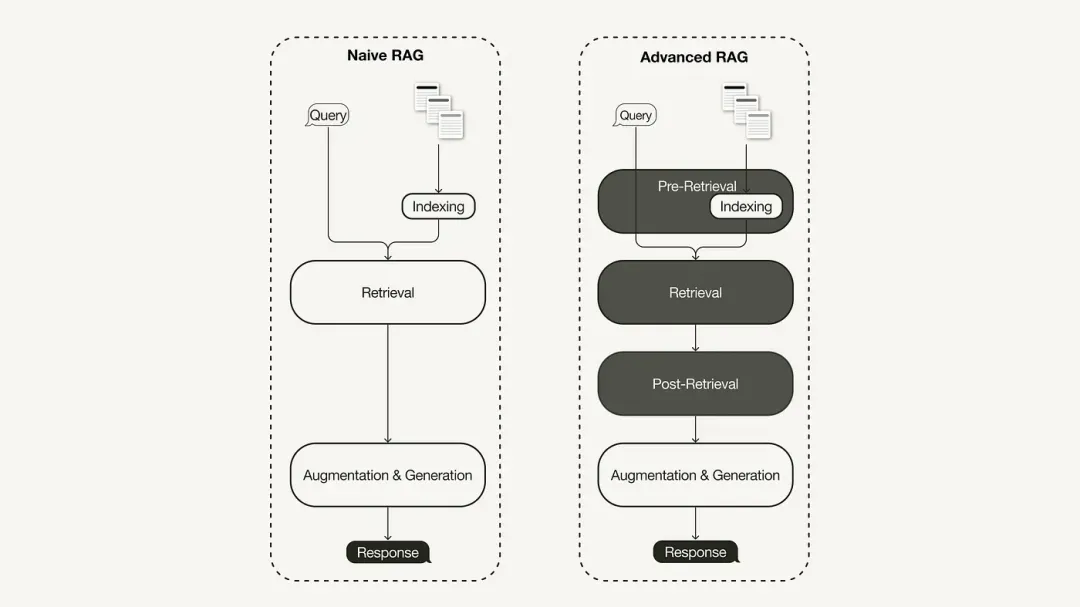
主要な RAG 研究パラダイムは最も初期の方法論を表しており、ChatGPT が広く採用された直後に重要性を獲得しました。プライマリ RAG は、インデックス作成、取得、生成などの従来のプロセスに従います。これは、「取得読み取り」フレームワークとして説明されることが多く、そのワークフローには次の 3 つの主要なステップが含まれます。
-
コーパスは個別のチャンクに分割され、エンコーダー モデルを使用してベクトル インデックスが構築されます。
-
RAG は、クエリとインデックス付きチャンク間のベクトル類似性に基づいてチャンクを識別し、取得します。
-
モデルは、取得されたチャンクで取得されたコンテキスト情報に基づいて回答を生成します。
プライマリ RAG の制限
プライマリ RAG は、「取得」、「生成」、「拡張」という 3 つの主要な領域で重大な課題に直面しています。
一次 RAG の検索品質には、低精度や低再現率など多くの問題があります。精度が低いと、取得したブロックの位置がずれたり、幻覚などの問題が発生したりする可能性があります。再現率が低いと、関連するすべてのブロックを取得できなくなり、LLM からの包括的な応答が不十分になります。さらに、古い情報を使用すると問題がさらに悪化し、不正確な検索結果が得られる可能性があります。
生成される応答の品質は、幻想的な課題に直面しています。つまり、LLM によって生成される応答は、提供されたコンテキストに基づいていないか、コンテキストに関連していないか、生成される応答には有害なコンテンツや差別的なコンテンツが含まれる潜在的なリスクがあります。
強化プロセス中、プライマリ RAG は、取得したパッセージのコンテキストを現在の生成タスクと効果的に統合する方法において、かなりの課題にも直面します。非効率的な統合により、出力が一貫性のない、または断片化されたものになる可能性があります。冗長性と重複も厄介な問題であり、特に取得された複数のパッセージに同様の情報が含まれている場合、生成された応答に重複したコンテンツが表示される可能性があります。
02. アドバンスドRAG
プライマリ RAG の欠点を解決するために、高度な RAG が誕生し、その機能は的を絞った方法で強化されました。まず、取得前最適化、取得中最適化、取得後最適化に分類できるこれらの手法について説明します。
検索前の最適化
取得前の最適化は、データ インデックスの最適化とクエリの最適化に重点を置いています。データ インデックスの最適化テクノロジは、取得効率を向上させる方法でデータを保存することを目的としています。
-
スライディング ウィンドウ: データ ブロック間のオーバーラップを使用します。これは最も単純な手法の 1 つです。
-
データの粒度を強化する: 無関係な情報の削除、事実の正確性の確認、古い情報の更新などのデータ クリーニング手法を適用します。
-
フィルタリングのための日付、目的、章情報などのメタデータを追加します。
-
インデックス構造の最適化には、ブロック サイズの調整やマルチインデックス戦略の使用など、さまざまなデータ インデックス戦略が必要です。この記事で実装する手法の 1 つはセンテンス ウィンドウの取得です。これは、取得時に個々のセンテンスを埋め込み、推論時に大きなテキスト ウィンドウに置き換えます。
検索中に最適化する
取得フェーズでは、最も関連性の高いコンテキストを特定することに重点が置かれます。通常、検索はベクトル検索に基づいており、クエリとインデックス付きデータの間の意味的な類似性が計算されます。したがって、ほとんどの検索最適化テクニックは埋め込みモデルを中心に展開されます。
-
埋め込みモデルを微調整する: 埋め込みモデルを特定のドメイン コンテキスト、特に開発用語や珍しい用語を使用するドメインに合わせてカスタマイズします。たとえば、
BAAI/bge-small-en微調整可能な高性能の埋め込みモデルです。 -
動的埋め込み: 単語ごとに 1 つのベクトルを使用する静的埋め込みとは異なり、単語が使用されるコンテキストに適応します。たとえば、OpenAI は、
embeddings-ada-02コンテキストの理解を捉える複雑な動的埋め込みモデルです。ベクトル検索に加えて、ハイブリッド検索などの他の検索手法もあります。これは通常、ベクトル検索とキーワードベースの検索を組み合わせた概念を指します。この検索手法は、検索でキーワードの完全一致が必要な場合に役立ちます。
取得後の最適化
取得されたコンテキスト コンテンツでは、ウィンドウの制限を超えるコンテキストやコンテキストによって導入されるノイズなどのノイズが発生し、重要な情報から注意が逸れてしまいます。
-
プロンプトの圧縮: 無関係なコンテンツを削除し、重要なコンテキストを強調表示することで、プロンプト全体の長さを短縮します。
-
再ランキング: 機械学習モデルを使用して、取得したコンテキストの関連性スコアを再計算します。
検索後の最適化手法には次のようなものがあります。
03. Milvus + LlamaIndex に基づいた高度な RAG の実装
私たちが実装した高度な RAG は、OpenAI の言語モデル、Hugging Face でホストされている BAAI 再配置モデル、および Milvus ベクトル データベースを使用します。
ミルバスインデックスの作成
from llama_index.core import VectorStoreIndex
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import StorageContext
vector_store = MilvusVectorStore(dim=1536,
uri="http://localhost:19530",
collection_name='advance_rag',
overwrite=True,
enable_sparse=True,
hybrid_ranker="RRFRanker",
hybrid_ranker_params={"k": 60})
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex(
nodes,
storage_context=storage_context
)
インデックス最適化の例: センテンスウィンドウの検索
LlamaIndex の SentenceWindowNodeParser を使用して、センテンス ウィンドウ取得テクノロジを実装します。
from llama_index.core.node_parser import SentenceWindowNodeParser
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
SentenceWindowNodeParser は 2 つの操作を実行します。
文書を個別の文に分割し、埋め込みます。
文ごとにコンテキスト ウィンドウが作成されます。 window_size = 3 を指定すると、結果のウィンドウには、埋め込まれた文の前の文から始まり、埋め込まれた文の後の文までの 3 つの文が含まれます。このウィンドウはメタデータとして保存されます。検索時には、クエリに最もよく一致する文が返されます。取得後、 を定義しMetadataReplacementPostProcessorてリスト内で使用することでnode_postprocessors、メタデータの文をウィンドウ全体に置き換える必要があります。
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
postproc = MetadataReplacementPostProcessor(
target_metadata_key="window"
)
...
query_engine = index.as_query_engine(
node_postprocessors = [postproc],
)
検索最適化の例: ハイブリッド検索
LlamaIndex でハイブリッド検索を実装するには、基礎となるベクトル データベースがハイブリッド検索クエリをサポートしている場合、クエリ エンジンに対する 2 つのパラメータ変更のみが必要です。 Milvus バージョン 2.4 は以前はハイブリッド検索をサポートしていませんでしたが、最近リリースされたバージョン 2.4 ではこの機能がすでにサポートされています。
query_engine = index.as_query_engine(
vector_store_query_mode="hybrid", #Milvus 2.4开始支持, 在2.4版本之前使用 Default
)
取得後の最適化例: 再ランキング
高度な RAG に再ランキングを追加するには、次の 3 つの簡単な手順のみが必要です。
まず、 Hugging Face を使用して再ランキング モデルを定義しますBAAI/bge-reranker-base。
クエリ エンジンで、並べ替えモデルをnode_postprocessorsリストに追加します。
より多くのコンテキスト フラグメントを取得するためにクエリ エンジンが増加しますsimilarity_top_k。再配置後は、top_n に減らすことができます。
from llama_index.core.postprocessor import SentenceTransformerRerank
rerank = SentenceTransformerRerank(
top_n = 3,
model = "BAAI/bge-reranker-base"
)
...
query_engine = index.as_query_engine(
similarity_top_k = 3,
node_postprocessors = [rerank],
...,
)
詳細な実装コードについては、Baidu Netdisk リンクを参照してください: https://pan.baidu.com/s/1Cj_Fmy9-SiQFMFNUmO0OZQ?pwd=r2i1抽出コード: r2i1
「Qing Yu Nian 2」の海賊版リソースが npm にアップロードされたため、npmmirror は unpkg サービスを停止せざるを 得なくなりました。 周宏儀: すべての製品をオープンソースにすることを提案します 。ここで time.sleep(6) はどのような役割を果たしますか? ライナスは「ドッグフードを食べる」ことに最も積極的! 新しい iPad Pro は 12GB のメモリ チップを使用していますが、8GB のメモリを搭載していると主張しています。People 's Daily Online は、オフィス ソフトウェアのマトリョーシカ スタイルの充電についてレビューしています。「セット」を積極的に解決することによってのみ、 Flutter 3.22 と Dart 3.4 のリリース が可能になります。 Vue3 の新しい開発パラダイム、「ref/reactive」、「ref.value」不要 MySQL 8.4 LTS 中国語マニュアルリリース: データベース管理の新しい領域の習得に役立ちます Tongyi Qianwen GPT-4 レベルのメイン モデルの価格が値下げされました97%、1元と200万トークン