
編集者注:現在、検索拡張生成 (RAG) システムは、膨大な知識を大規模なモデルに組み込むための重要なテクノロジーの 1 つとなっています。ただし、半構造化データと非構造化データ、特にドキュメント内の表形式データを効率的に処理する方法は、依然として RAG システムが直面する大きな問題です。
この記事の著者は、この問題点に対処するために表形式データを処理するための新しいソリューションを提案しています。著者はまず、テーブル解析、インデックス構造設計などを含む、RAG システムにおけるテーブル処理のコア テクノロジを系統的に整理し、既存のオープン ソース ソリューションをいくつかレビューします。これに基づいて、著者は独自のイノベーションを提案しました。Nougat ツールを使用して文書内の表の内容を正確かつ効率的に解析し、言語モデルを使用して表とそのタイトルを要約し、最後に新しい文書要約索引構造を構築しました。完全なコード実装の詳細を示します。
この方法の利点は、テーブルを効果的に解析し、テーブルの概要とテーブルの関係を十分に考慮できることです。マルチモーダル LLM を使用する必要がなく、解析コストを節約できることです。このスキームが実際にさらに応用され、発展していくのを待ちましょう。
著者 | フロリアン・ジューン
編集済み | ユエ・ヤン
RAG システムの実装は、特に非構造化ドキュメント内のテーブルを解析して理解する必要がある場合、困難な作業です。スキャン操作によってデジタル化されたドキュメント (スキャンされたドキュメント) またはイメージ形式のドキュメント (イメージ形式のドキュメント) の場合、これらの操作を実装することはさらに困難です。少なくとも 3 つの課題があります。
- スキャン操作によってデジタル化された文書 (スキャンされた文書) またはイメージ形式の文書 (イメージ形式の文書) は、文書構造の多様性など比較的複雑であり、文書にはテキスト以外の要素が含まれている可能性があり、また、文書にはテキスト以外の要素が同時に存在することもあります。手書きおよび印刷されたコンテンツは、フォーム情報の正確かつ自動化された抽出に課題をもたらします。不正確なドキュメント解析により、テーブル構造が破壊されます。不完全なテーブル情報をベクトル表現に変換 (埋め込み) すると、テーブルのセマンティック情報を効果的に取得できないだけでなく、RAG の最終出力で問題が発生しやすくなります。
- 各テーブルのタイトルを抽出し、それらを対応する特定のテーブルに関連付ける方法。
- 合理的なインデックス構造設計を通じて、主要なセマンティック情報をテーブルに効率的に整理して格納する方法。
この記事では、まず、検索拡張生成 (RAG) モデルで表形式データを管理および処理する方法を紹介します。次に、いくつかの既存のオープンソース ソリューションがレビューされ、最後に、現在のテクノロジーに基づいて新しい表形式のデータ管理方法が設計および実装されます。
01 RAGテーブルデータに関するコア技術の紹介
1.1 テーブル解析 テーブルデータの解析
このモジュールの主な機能は、非構造化ドキュメントまたは画像からテーブル構造を正確に抽出することです。
追加の要件: 開発者がテーブル タイトルをテーブルに関連付けやすくするために、対応するテーブル タイトルを抽出することが最善です。
私の現在の理解によれば、図 1 に示すように、いくつかの方法があります。
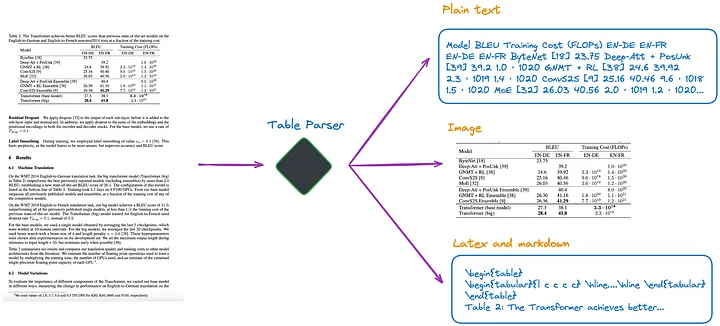
図 1: テーブルパーサー。画像は原作者提供。
(a). マルチモーダル LLM (GPT-4V[1] など) を使用して表を認識し、各 PDF ページから情報を抽出します。
- 入力: 画像形式の PDF ページ
- 出力: JSON またはその他の形式の表形式のデータ。マルチモーダル LLM が表形式データを抽出できない場合は、PDF 画像を要約してコンテンツの概要を返す必要があります。
(b).専門的なテーブル検出モデル (Table Transformer[2] など) を使用してテーブル構造を識別します。
- 入力: PDF ページ画像
- 出力: テーブル画像
(c). 非構造化[3]、または同様にオブジェクト検出モデルを使用する他のフレームワークなどのオープンソース フレームワークを使用します (非構造化のテーブル検出プロセスについては、この記事[4]で詳しく説明します)。これらのフレームワークは、ドキュメント全体を完全に解析し、解析結果からテーブル関連のコンテンツを抽出できます。
- 入力: PDF または画像形式のドキュメント
- 出力: プレーン テキストまたは HTML 形式のテーブル (ドキュメント全体を解析して取得)
(d). Nougat[5] や Donut[6] などのエンドツーエンド モデルを使用してドキュメント全体を解析し、テーブル関連のコンテンツを抽出します。このアプローチには OCR モデルは必要ありません。
- 入力: PDF または画像形式のドキュメント
- 出力: LaTeX または JSON 形式のテーブル (ドキュメント全体を解析して取得)
どの方法で表情報を抽出する場合でも、表タイトルも抽出する必要があることに注意してください。ほとんどの場合、表のタイトルは文書作成者または論文著者による表の簡単な説明であり、表全体の内容の大部分を要約することができるからです。
上記 4 つの方法のうち、(d) の方法の方が簡単に表タイトルを取得できます。テーブルのタイトルをテーブルに関連付けることができるため、これは開発者にとって大きな利点です。以下の実験でこれをさらに説明します。
1.2 インデックス構造が表形式データにインデックスを付ける方法
インデックスの作成方法には大きく分けて以下のような種類があります。
(e). イメージ形式のインデックステーブルのみ。
(f). プレーン テキストまたは JSON 形式のテーブルのみにインデックスを付けます。
(g) LaTeX 形式のテーブルのみをインデックスします。
(h) テーブルの要約のみがインデックス付けされます。
(i) 小規模から大規模 (翻訳者注: これには、各行またはテーブルの概要のインデックス作成などのきめの細かいインデックス作成と、画像、プレーン テキスト、または LaTeX のテーブル全体のインデックス作成などの粗いインデックス作成の両方が含まれます。データ型を使用して、小規模から大規模までの階層的なインデックス構造を形成します。) または、図 2 に示すように、テーブルの概要を使用してインデックス構造を構築します。
小さなチャンク (翻訳者注: 粒度の細かいインデックス レベルに対応するデータ ブロック) の内容。テーブルまたは概要情報の各行を独立した小さなデータ ブロックとして扱うなど。
大きなチャンク (翻訳者注: 粗粒度のインデックス レベルに対応するデータ ブロック) の内容は、画像形式、プレーン テキスト形式、または LaTeX 形式のテーブル全体である可能性があります。
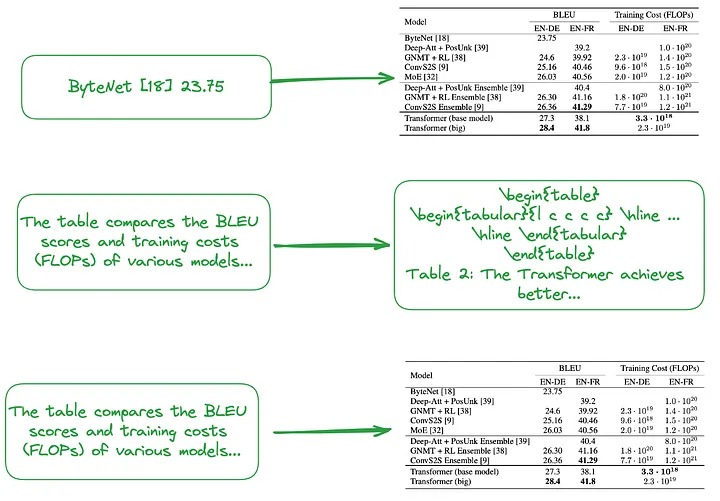
図 2: 小から大へのインデックス付け (上) とテーブルの概要の使用 (中、下)。画像は原作者提供。
前述したように、表形式の概要は通常、LLM 処理を使用して生成されます。
- 入力: 画像形式、テキスト形式、または LaTeX 形式の表
- 出力: テーブルの概要
1.3 テーブルの解析、インデックスの構築、または RAG テクノロジーの使用を必要としないアプローチ
一部のアルゴリズムは表形式データの解析を必要としません。
(j) 関連する画像 (PDF ドキュメント ページ) とユーザーのクエリを VQA モデル (DAN [7] など) に送信します (訳者注: Visual Question Answering モデルの略。コンピューター モデルの組み合わせです)。画像コンテンツに関する自然言語の質問に答えるために使用できる視覚および自然言語処理技術、またはマルチモーダル LLM を使用して回答を返します。
- インデックス付けするコンテンツ: 画像形式のドキュメント
- VQA モデルまたはマルチモーダル LLM に送信するもの: クエリ + 対応するドキュメント ページ (画像)
(k). 関連するテキスト形式の PDF ページとユーザーのクエリを LLM に送信し、回答を返します。
- インデックス付けするコンテンツ: テキスト形式のドキュメント
- LLM に送信されるコンテンツ: クエリ + テキスト形式の対応するドキュメント ページ
(l). 関連するドキュメント画像 (PDF ドキュメント ページ)、テキスト ブロック、およびユーザーのクエリをマルチモーダル LLM (GPT-4V など) に送信し、回答を直接返します。
- インデックス付けされるコンテンツ: 画像形式のドキュメントとテキスト形式のドキュメント チャンク
- マルチモーダル LLM に送信されるコンテンツ: クエリ + 対応する画像形式のドキュメント + 対応するテキスト チャンク
さらに、図 3 と図 4 に示すように、インデックス作成を必要としないメソッドをいくつか紹介します。
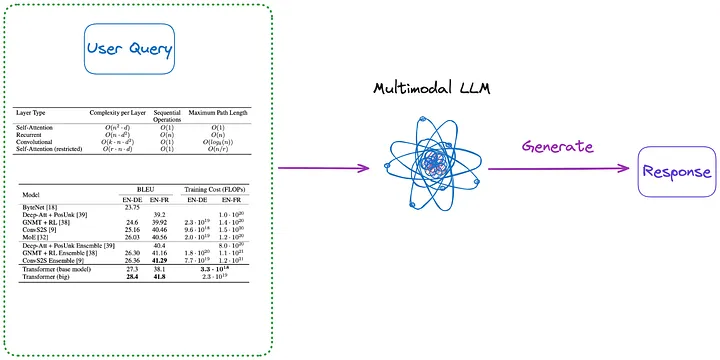
図 3: カテゴリ (m) (訳者注: 以下の最初の段落で紹介されている内容)。画像は原作者提供。
(m) まず、(a) ~ (d) のいずれかの方法を使用して、ドキュメント内のすべてのテーブルをイメージ形式に解析します。次に、すべてのテーブル画像とユーザーのクエリがマルチモーダル LLM (GPT-4V など) に直接送信され、回答が返されます。
- インデックス付けされるコンテンツ: なし
- マルチモーダル LLM に送信されるコンテンツ: クエリ + 画像形式に変換されたすべてのテーブル
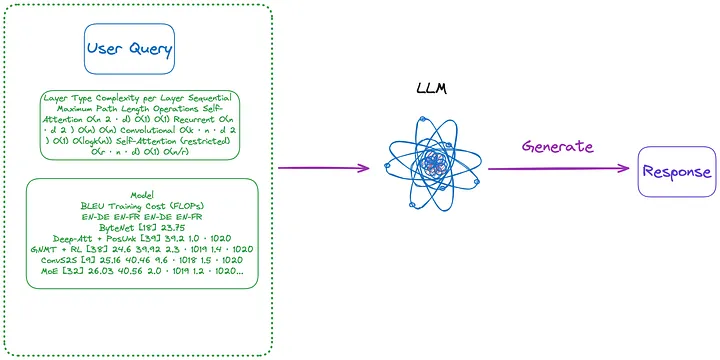
図 4: カテゴリ (n) (翻訳者注: 以下の最初の段落で紹介されている内容)。画像は原作者提供。
(n) (m) の方法で抽出された画像形式のテーブルを使用し、OCR モデルを使用してテーブル内のすべてのテキストを識別し、テーブル内のすべてのテキストとユーザーのクエリを LLM に直接送信します。と答えを直接返します。
- インデックス付けされるコンテンツ: なし
- LLM に送信されるコンテンツ: ユーザーのクエリ + すべてのテーブルの内容 (テキスト形式で送信)
ドキュメント内のテーブルを処理する場合、一部のメソッドでは RAG (検索拡張生成) テクノロジが使用されないことに注意してください。
- 最初のタイプの方法では、LLM を使用しませんが、特定のデータセットでトレーニングします。これにより、AI モデル (Transformer アーキテクチャに基づく、BERT からインスピレーションを得た他の言語モデルなど) が、次のようなテーブル理解タスクの処理をより適切にサポートできるようになります。タパス [8]。
- 2 番目のタイプの方法は、LLM が GPT4Table [9] などのテーブル理解タスクを完了できるように、事前トレーニング、微調整方法、またはプロンプト ワード エンジニアリングを使用して LLM を使用することです。
02 テーブル処理のための既存のオープンソース ソリューション
前のセクションでは、RAG システムにおける表形式データ処理の主要なテクノロジを要約および分類しました。この記事で実装するソリューションを提案する前に、いくつかのオープンソース ソリューションを検討してみましょう。
LlamaIndex は 4 つの方法 [10] を提案しており、そのうち最初の 3 つはすべてマルチモーダル モデルを使用します。
- 関連する PDF ページ画像を取得し、ユーザーの Query に応答して GPT-4V に送信します。
- 各 PDF ページを画像形式に変換し、GPT-4V に各ページで画像推論を実行させます。画像推論プロセス用の Text Vector Store インデックスを確立し (翻訳者注: 画像から推論されたテキスト情報をベクトル形式に変換してインデックスを作成します)、その後、Image Reasoning Vector Store (翻訳者注: 以前のインデックスである必要があります) を使用します。 , 前に作成した Text Vector Store インデックスをクエリして、答えを見つけます。
- Table Transformer を使用して、取得した画像からテーブル情報を切り出し、これらの切り取ったテーブル画像を GPT-4V に送信してクエリ応答を取得します (翻訳者注: クエリをモデルに送信し、モデルから返される応答を取得します)。
- トリミングされたテーブル画像に OCR を適用し、データを GPT4/GPT-3.5 に送信してユーザーのクエリに答えます。
上記 4 つの方法を要約すると、次のようになります。
- 最初の方法は、この記事で紹介した方法 (j) に似ており、テーブル解析を必要としません。しかし、答えは画像の中にあるにもかかわらず、正しい答えは得られないことがわかりました。
- 2 番目の方法にはテーブルの解析が含まれ、方法 (a) に対応します。インデックス コンテンツは、GPT-4V によって返される結果に完全に応じて、表形式のコンテンツまたはコンテンツの概要になる場合があり、方法 (f) または (h) に対応する場合があります。このアプローチの欠点は、特に文書画像に表、テキスト、その他の画像 (PDF 文書では一般的) が含まれている場合、表を識別してその内容を文書画像から抽出する GPT-4V の機能が一貫性がないことです。
- 3 番目の方法は方法 (m) に似ており、インデックス作成は必要ありません。
- 4 番目の方法は方法 (n) に似ており、やはりインデックス作成を必要としません。その結果、誤った回答の理由は、画像から表形式の情報を効果的に抽出できないことであることがわかりました。
テストを通じて、3 番目の方法が総合的な効果が最も優れていることがわかりました。ただし、私が実施したテストによると、3 番目の方法では、テーブルのタイトルとテーブルの内容を正しく抽出して関連付けることはおろか、テーブルを検出するのにも苦労しました。
Langchain は、半構造化データ RAG (Semi Structured RAG) [11] テクノロジーに対するいくつかのソリューションも提案しました。コア テクノロジーには次のようなものがあります。
- テーブル解析にはクラス (c) メソッドである非構造化を使用します。
- 索引方式は文書要約索引 (訳者注: 文書要約情報を索引内容として使用する) であり、クラス (i) の方式に属します。詳細なインデックス レベルに対応するデータ ブロック: テーブルの概要コンテンツ、および粗いインデックス レベルに対応するデータ ブロック: 元のテーブル コンテンツ (テキスト形式)。
図 5 に示すように:
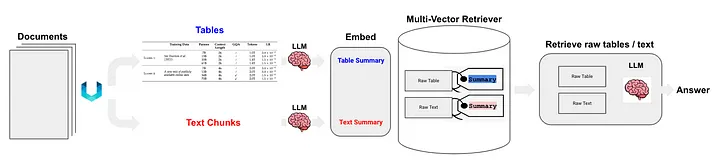
図 5: Langchain の半構造化 RAG ソリューション。出典: 半構造化 RAG[11]
半構造化およびマルチモーダル RAG [12] は 3 つのソリューションを提案しており、そのアーキテクチャを図 6 に示します。
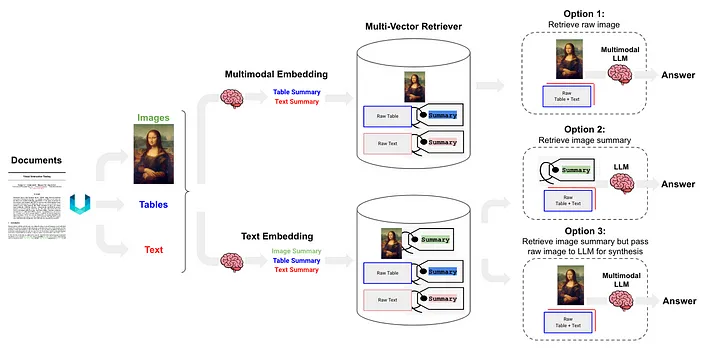
図 6: Langchain の半構造化およびマルチモーダル RAG スキーム。出典: 半構造化およびマルチモーダル RAG[12]。
オプション 1 は 、上記の方法 (l) と似ています。このアプローチには、マルチモーダル埋め込み (CLIP [13] など) を使用して画像とテキストを埋め込みベクトルに変換し、その後、類似性検索アルゴリズムを使用して両方を取得し、未処理の画像とテキスト データを変換することが含まれます。一緒に処理され、質問に対する回答が生成されます。
オプション 2 では、マルチモーダル LLM (GPT-4V[14]、LLaVA[15]、FUYU-8b[16] など) を使用して画像を処理し、テキストの概要を生成します。次に、テキスト データは埋め込みベクトルに変換され、これらのベクトルは、ユーザーが提示したクエリに一致するテキスト コンテンツを検索または取得するために使用され、LLM に渡されて回答が生成されます。
- テーブル データは、クラス (d) メソッドに属する非構造化を使用して解析されます。
- 索引付け方法は文書要約索引 (翻訳者注: 文書要約情報は索引内容として使用されます) であり、(i) クラス・メソッドに属する、きめ細かい索引レベル: 表要約内容に対応するデータ・ブロックです。粗粒度のインデックス レベルに対応するブロック: text テーブルの内容をフォーマットします。
オプション 3 は 、マルチモーダル LLM (GPT-4V [14]、LLaVA [15]、または FUYU-8b [16] など) を使用して画像データからテキスト要約を生成し、これらの埋め込みベクトルを使用して、これらのテキスト要約をベクトルに埋め込みます。 , 画像アブストラクトを効率的に取得(取得)することができます。取得された各画像アブストラクトには、対応する生画像への参照(生画像への参照)が保持されます。これは、最後に、未処理の画像データに属します。そしてテキスト ブロックは、回答を生成するためにマルチモーダル LLM に渡されます。
03 この記事で提案する解決策
主要なテクノロジーと既存のソリューションは、前の記事で要約、分類、説明されています。これに基づいて、図 7 に示すように、次の解決策を提案します。わかりやすくするために、再ランキングやクエリ書き換えなどの一部の RAG モジュールは図から省略されています。
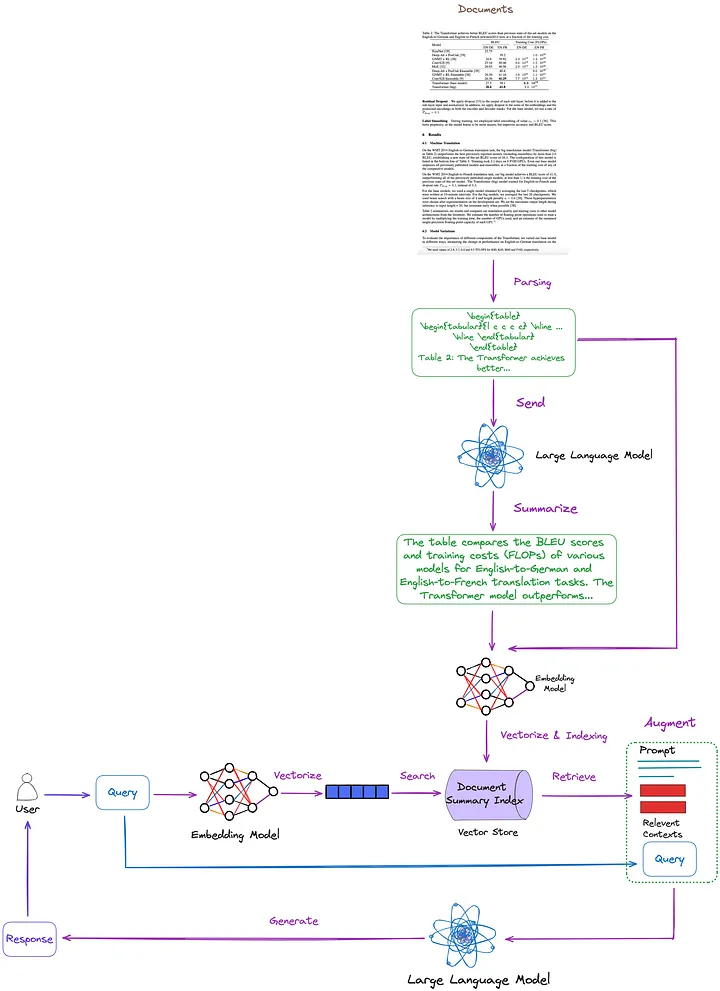
図 7: この記事で提案するソリューション。画像は原作者提供。
- テーブル解析手法: Nougat を使用します ((d) クラス メソッド)。私のテストによると、このツールのテーブル検出機能は、非構造化 (タイプ (c) 手法) よりも効果的です。さらに、Nougat はテーブルのタイトルを非常にうまく抽出できるため、テーブルとの関連付けが非常に便利です。
- 文書概要の索引付けおよび取得のための索引構造 (クラス (i) のメソッド):きめの細かい索引レベルには表形式のコンテンツ要約が含まれ、粗い索引レベルには LaTeX 形式の対応する表とテキスト形式の表タイトルが含まれます。これを実現するために、マルチベクトル リトリーバー [17] (翻訳者注: クエリに関連する文書概要を効率的に取得するために、複数のベクトルを同時に処理できる、文書概要インデックス内のコンテンツを取得するためのリトリーバー) を使用します。
- テーブルの内容の概要を取得する方法: 内容の概要を得るために、テーブルとテーブルのタイトルを LLM に送信します。
この方法の利点は、テーブルを効果的に解析し、テーブルの概要とテーブルの関係を十分に考慮できることです。マルチモーダル LLM を使用する必要がなくなり、コストが削減されます。
3.1 ヌガーの仕組み
Nougat [18] は、Donut [19] アーキテクチャに基づいて開発されており、OCR 関連の入力やモジュールを使用せずに暗黙的な方法でテキストを自動的に認識できるアルゴリズムを使用します。
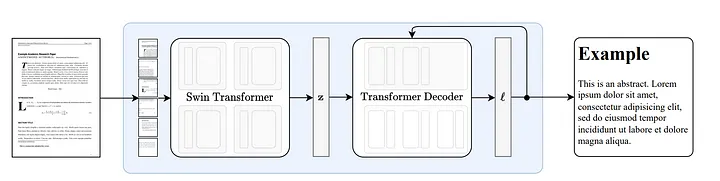
図 8: Donut [19] に従ったエンドツーエンドのアーキテクチャ。 Swin Transformer エンコーダは、ドキュメント画像を取得して潜在埋め込み (翻訳者注: 画像の情報は潜在空間にエンコードされます) に変換し、それを自己回帰的に一連のトークンに変換します。出典: Nougat: 学術文書のための神経光学的理解。[18]
Nougat の数式を解析する能力は優れています [20] が、テーブルを解析する能力も例外的です。図 9 に示すように、テーブル タイトルと関連付けることができ、非常に便利です。

図 9: Nougat の実行結果 結果ファイルは Mathpix Markdown 形式であり (vscode プラグインを通じて開くことができます)、表は LaTeX 形式で表示されます。
十数の論文に対して私が行ったテストでは、表のタイトルが常に表の次の行に固定されていることがわかりました。この一貫性は、これが偶然ではなかったことを示しています。したがって、私たちは Nougat がこの機能をどのように実現するかにさらに興味を持っています。
これが中間結果のないエンドツーエンドのモデルであることを考えると、そのパフォーマンスはトレーニング データに大きく依存する可能性があります。
コード分析に基づくと、テーブル ヘッダー セクションが格納される場所と方法は、トレーニング データ内のテーブルの構成形式 (およびその直後)\end{table} と 一致しているようです 。caption_parts
def format_element(
element: Element, keep_refs: bool = False, latex_env: bool = False
) -> List[str]:
"""
Formats a given Element into a list of formatted strings.
Args:
element (Element): The element to be formatted.
keep_refs (bool, optional): Whether to keep references in the formatting. Default is False.
latex_env (bool, optional): Whether to use LaTeX environment formatting. Default is False.
Returns:
List[str]: A list of formatted strings representing the formatted element.
"""
...
...
if isinstance(element, Table):
parts = [
"[TABLE%s]\n\begin{table}\n"
% (str(uuid4())[:5] if element.id is None else ":" + str(element.id))
]
parts.extend(format_children(element, keep_refs, latex_env))
caption_parts = format_element(element.caption, keep_refs, latex_env)
remove_trailing_whitespace(caption_parts)
parts.append("\end{table}\n")
if len(caption_parts) > 0:
parts.extend(caption_parts + ["\n"])
parts.append("[ENDTABLE]\n\n")
return parts
...
...
3.2 ヌガーの長所と短所
アドバンテージ:
- Nougat は、数式や表など、以前の解析ツールでは解析が困難だったセクションを LaTeX ソース コードに正確に解析できます。
- Nougat の解析結果は、Markdown に似た半構造化ドキュメントになります。
- テーブルのタイトルを簡単に取得し、テーブルに簡単に関連付けることができます。
欠点:
- Nougat の解析速度は遅いため、大規模なアプリケーションでは問題が発生する可能性があります。
- Nougat のトレーニング データ セットは基本的に科学論文であるため、この手法は同様の構造を持つドキュメントに対してうまく機能します。非ラテン語テキスト文書を処理するとパフォーマンスが低下します。
- Nougat モデルは、一度に科学論文の 1 ページのみをトレーニングし、他のページについての知識はありません。これにより、解析されたコンテンツに不整合が生じる可能性があります。したがって、認識効果が良好でない場合は、PDF を個別のページに分割し、ページごとに解析することを検討できます。
- 2 列の論文での表の解析は、1 列の論文ほど良好ではありません。
3.3 コードの実装
まず、関連する Python パッケージをインストールします。
pip install langchain
pip install chromadb
pip install nougat-ocr
インストールが完了したら、Python パッケージのバージョンを確認する必要があります。
langchain 0.1.12
langchain-community 0.0.28
langchain-core 0.1.31
langchain-openai 0.0.8
langchain-text-splitters 0.0.1
chroma-hnswlib 0.7.3
chromadb 0.4.24
nougat-ocr 0.1.17
作業環境をセットアップし、パッケージをインポートします。
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
import subprocess
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
論文「Attending Is All You Need」[21] を path にダウンロードし YOUR_PDF_PATH、nougat を実行して PDF ファイルを解析し、解析結果から latex 形式の表データとテキスト形式の表タイトルを取得します。プログラムを初めて実行すると、必要なモデル ファイルがローカル環境にダウンロードされます。
def june_run_nougat(file_path, output_dir):
# Run Nougat and store results as Mathpix Markdown
cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"]
res = subprocess.run(cmd)
if res.returncode != 0:
print("Error when running nougat.")
return res.returncode
else:
print("Operation Completed!")
return 0
def june_get_tables_from_mmd(mmd_path):
f = open(mmd_path)
lines = f.readlines()
res = []
tmp = []
flag = ""
for line in lines:
if line == "\begin{table}\n":
flag = "BEGINTABLE"
elif line == "\end{table}\n":
flag = "ENDTABLE"
if flag == "BEGINTABLE":
tmp.append(line)
elif flag == "ENDTABLE":
tmp.append(line)
flag = "CAPTION"
elif flag == "CAPTION":
tmp.append(line)
flag = "MARKDOWN"
print('-' * 100)
print(''.join(tmp))
res.append(''.join(tmp))
tmp = []
return res
file_path = "YOUR_PDF_PATH"
output_dir = "YOUR_OUTPUT_DIR_PATH"
if june_run_nougat(file_path, output_dir) == 1:
import sys
sys.exit(1)
mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"
tables = june_get_tables_from_mmd(mmd_path)
図 10 に示すように、関数 june_get_tables_from_mmd は、mmd ファイルからすべての内容 ( から まで \begin{table} 、 ただし その後の最初の行\end{table}も含む ) を抽出するために使用されます。\end{table}

図 10: Nougat の実行結果 結果ファイルは Mathpix Markdown 形式であり (vscode プラグインを通じて開くことができます)、解析されたテーブルのコンテンツは Latex 形式です。関数 june_get_tables_from_mmd の機能は、赤枠内のテーブル情報を抽出することです。画像は原作者提供。
ただし、表のタイトルを表の下に配置する必要があること、または表が \begin{table} で始まり \end{table} で終わる必要があることを記載した公式文書はありません。したがって、june_get_tables_from_mmd はヒューリスティックな方法です。
PDF ドキュメントのテーブル解析の結果は次のとおりです。
Operation Completed!
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{l c c c} \hline \hline Layer Type & Complexity per Layer & Sequential Operations & Maximum Path Length \ \hline Self-Attention & (O(n^{2}\cdot d)) & (O(1)) & (O(1)) \ Recurrent & (O(n\cdot d^{2})) & (O(n)) & (O(n)) \ Convolutional & (O(k\cdot n\cdot d^{2})) & (O(1)) & (O(log_{k}(n))) \ Self-Attention (restricted) & (O(r\cdot n\cdot d)) & (O(1)) & (O(n/r)) \ \hline \hline \end{tabular}
\end{table}
Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types. (n) is the sequence length, (d) is the representation dimension, (k) is the kernel size of convolutions and (r) the size of the neighborhood in restricted self-attention.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{l c c c c} \hline \hline \multirow{2}{*}{Model} & \multicolumn{2}{c}{BLEU} & \multicolumn{2}{c}{Training Cost (FLOPs)} \ \cline{2-5} & EN-DE & EN-FR & EN-DE & EN-FR \ \hline ByteNet [18] & 23.75 & & & \ Deep-Att + PosUnk [39] & & 39.2 & & (1.0\cdot 10^{20}) \ GNMT + RL [38] & 24.6 & 39.92 & (2.3\cdot 10^{19}) & (1.4\cdot 10^{20}) \ ConvS2S [9] & 25.16 & 40.46 & (9.6\cdot 10^{18}) & (1.5\cdot 10^{20}) \ MoE [32] & 26.03 & 40.56 & (2.0\cdot 10^{19}) & (1.2\cdot 10^{20}) \ \hline Deep-Att + PosUnk Ensemble [39] & & 40.4 & & (8.0\cdot 10^{20}) \ GNMT + RL Ensemble [38] & 26.30 & 41.16 & (1.8\cdot 10^{20}) & (1.1\cdot 10^{21}) \ ConvS2S Ensemble [9] & 26.36 & **41.29** & (7.7\cdot 10^{19}) & (1.2\cdot 10^{21}) \ \hline Transformer (base model) & 27.3 & 38.1 & & (\mathbf{3.3\cdot 10^{18}}) \ Transformer (big) & **28.4** & **41.8** & & (2.3\cdot 10^{19}) \ \hline \hline \end{tabular}
\end{table}
Table 2: The Transformer achieves better BLEU scores than previous state-of-the-art models on the English-to-German and English-to-French newstest2014 tests at a fraction of the training cost.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{c|c c c c c c c c|c c c c} \hline \hline & (N) & (d_{\text{model}}) & (d_{\text{ff}}) & (h) & (d_{k}) & (d_{v}) & (P_{drop}) & (\epsilon_{ls}) & train steps & PPL & BLEU & params \ \hline base & 6 & 512 & 2048 & 8 & 64 & 64 & 0.1 & 0.1 & 100K & 4.92 & 25.8 & 65 \ \hline \multirow{4}{*}{(A)} & \multicolumn{1}{c}{} & & 1 & 512 & 512 & & & & 5.29 & 24.9 & \ & & & & 4 & 128 & 128 & & & & 5.00 & 25.5 & \ & & & & 16 & 32 & 32 & & & & 4.91 & 25.8 & \ & & & & 32 & 16 & 16 & & & & 5.01 & 25.4 & \ \hline (B) & \multicolumn{1}{c}{} & & \multicolumn{1}{c}{} & & 16 & & & & & 5.16 & 25.1 & 58 \ & & & & & 32 & & & & & 5.01 & 25.4 & 60 \ \hline \multirow{4}{*}{(C)} & 2 & \multicolumn{1}{c}{} & & & & & & & & 6.11 & 23.7 & 36 \ & 4 & & & & & & & & 5.19 & 25.3 & 50 \ & 8 & & & & & & & & 4.88 & 25.5 & 80 \ & & 256 & & 32 & 32 & & & & 5.75 & 24.5 & 28 \ & 1024 & & 128 & 128 & & & & 4.66 & 26.0 & 168 \ & & 1024 & & & & & & 5.12 & 25.4 & 53 \ & & 4096 & & & & & & 4.75 & 26.2 & 90 \ \hline \multirow{4}{*}{(D)} & \multicolumn{1}{c}{} & & & & & 0.0 & & 5.77 & 24.6 & \ & & & & & & 0.2 & & 4.95 & 25.5 & \ & & & & & & & 0.0 & 4.67 & 25.3 & \ & & & & & & & 0.2 & 5.47 & 25.7 & \ \hline (E) & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} & & \multicolumn{1}{c}{} & & & & & 4.92 & 25.7 & \ \hline big & 6 & 1024 & 4096 & 16 & & 0.3 & 300K & **4.33** & **26.4** & 213 \ \hline \hline \end{tabular}
\end{table}
Table 3: Variations on the Transformer architecture. Unlisted values are identical to those of the base model. All metrics are on the English-to-German translation development set, newstest2013. Listed perplexities are per-wordpiece, according to our byte-pair encoding, and should not be compared to per-word perplexities.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{c|c|c} \hline
**Parser** & **Training** & **WSJ 23 F1** \ \hline Vinyals & Kaiser et al. (2014) [37] & WSJ only, discriminative & 88.3 \ Petrov et al. (2006) [29] & WSJ only, discriminative & 90.4 \ Zhu et al. (2013) [40] & WSJ only, discriminative & 90.4 \ Dyer et al. (2016) [8] & WSJ only, discriminative & 91.7 \ \hline Transformer (4 layers) & WSJ only, discriminative & 91.3 \ \hline Zhu et al. (2013) [40] & semi-supervised & 91.3 \ Huang & Harper (2009) [14] & semi-supervised & 91.3 \ McClosky et al. (2006) [26] & semi-supervised & 92.1 \ Vinyals & Kaiser el al. (2014) [37] & semi-supervised & 92.1 \ \hline Transformer (4 layers) & semi-supervised & 92.7 \ \hline Luong et al. (2015) [23] & multi-task & 93.0 \ Dyer et al. (2016) [8] & generative & 93.3 \ \hline \end{tabular}
\end{table}
Table 4: The Transformer generalizes well to English constituency parsing (Results are on Section 23 of WSJ)* [5] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. _CoRR_, abs/1406.1078, 2014.
次に、LLM を使用して表形式のデータを要約します。
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Get table summaries
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
print(table_summaries)
以下は、図 11 に示されている「Attendance Is All You Need」[21] の 4 つの表の内容の要約です。
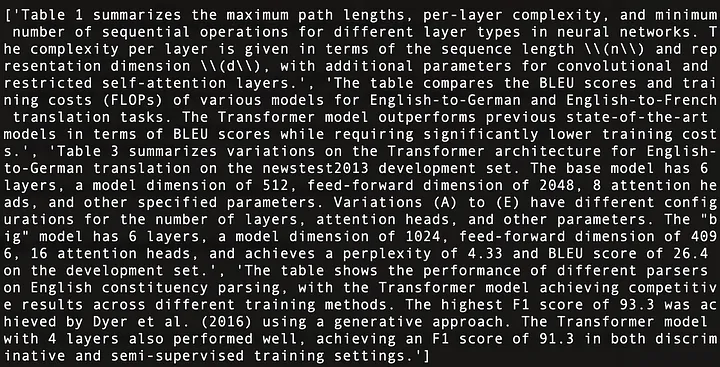
図 11: 「Attendance Is All You Need」[21] の 4 つの表の内容の概要。
Multi-Vector Retriever を使用する (翻訳者注: ドキュメント概要インデックス内のコンテンツを取得するためのリトリーバ。このレトリバは複数のベクトルを同時に処理して、クエリに関連するドキュメント概要を効果的に取得できます。) ドキュメント概要インデックス構造を構築する [17] (翻訳者注: 文書の概要情報を保存するために使用されるインデックス構造。これらの概要情報は必要に応じて取得またはクエリできます)。
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key = id_key,
search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1
)
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content = s, metadata = {id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
すべての準備ができたら、単純な RAG パイプラインをセットアップし、ユーザーのクエリを実行します。
# Prompt template
template = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
# Simple RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1
print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2
print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
図 12 に示すように、実行結果は次のとおりです。

図 12: 3 つのユーザー クエリに対する回答。 「注意だけで十分」の最初の行はテーブル 1、2 行目はテーブル 2、3 行目はテーブル 4 に対応します。
全体的なコードは次のとおりです。
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
import subprocess
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
def june_run_nougat(file_path, output_dir):
# Run Nougat and store results as Mathpix Markdown
cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"]
res = subprocess.run(cmd)
if res.returncode != 0:
print("Error when running nougat.")
return res.returncode
else:
print("Operation Completed!")
return 0
def june_get_tables_from_mmd(mmd_path):
f = open(mmd_path)
lines = f.readlines()
res = []
tmp = []
flag = ""
for line in lines:
if line == "\begin{table}\n":
flag = "BEGINTABLE"
elif line == "\end{table}\n":
flag = "ENDTABLE"
if flag == "BEGINTABLE":
tmp.append(line)
elif flag == "ENDTABLE":
tmp.append(line)
flag = "CAPTION"
elif flag == "CAPTION":
tmp.append(line)
flag = "MARKDOWN"
print('-' * 100)
print(''.join(tmp))
res.append(''.join(tmp))
tmp = []
return res
file_path = "YOUR_PDF_PATH"
output_dir = "YOUR_OUTPUT_DIR_PATH"
if june_run_nougat(file_path, output_dir) == 1:
import sys
sys.exit(1)
mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"
tables = june_get_tables_from_mmd(mmd_path)
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Get table summaries
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
print(table_summaries)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key = id_key,
search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1
)
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content = s, metadata = {id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
# Prompt template
template = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
# Simple RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1
print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2
print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
04 まとめ
この文書では、RAG システムにおけるテーブル処理操作の主要なテクノロジと既存のソリューションについて説明し、ソリューションとその実装を提案します。
この記事では、Nougat を使用してテーブルを解析しました。ただし、より高速で効率的な解析ツールが利用可能になった場合は、Nougat の置き換えを検討します。私たちのツールに対する姿勢は、特定のツールに依存するのではなく、まず正しいアイデアを持ち、それを実現するツールを見つけることです。
この記事では、すべてのテーブルの内容を LLM に入力します。ただし、実際のシナリオでは、テーブル サイズが LLM コンテキストの長さを超える状況を考慮する必要があります。この問題は、効率的なチャンキング手法を使用することで解決できます。
読んでくれてありがとう!
——
フロリアン・ジューン
人工知能の研究者で、主に大規模言語モデル、データ構造とアルゴリズム、NLP に関する記事を執筆しています。
終わり
参考文献
[1] https://openai.com/research/gpt-4v-system-card
[2] https://github.com/microsoft/table-transformer
[3] https://un Structured-io.github.io/unstruction/best_practices/table_extraction_pdf.html
[4] https://pub.towardsai.net/advanced-rag-02-unveiling-pdf-parsing-b84ae866344e
[5] https://github.com/facebookresearch/nougat
[6] https://github.com/clovaai/donut/
[7] https://arxiv.org/pdf/1611.00471.pdf
[8] https://aclanthology.org/2020.acl-main.398.pdf
[9] https://arxiv.org/pdf/2305.13062.pdf
[10] https://docs.llamaindex.ai/en/stable/examples/multi_modal/multi_modal_pdf_tables.html
[13] https://openai.com/research/clip
[14] https://openai.com/research/gpt-4v-system-card
[16] https://www.adept.ai/blog/fuyu-8b
[17] https://python.langchain.com/docs/modules/data_connection/retrievers/multi_vector
[18] https://arxiv.org/pdf/2308.13418.pdf
[19] https://arxiv.org/pdf/2111.15664.pdf
[21] https://arxiv.org/pdf/1706.03762.pdf
この記事は、原著者の許可を得て、Baihai IDP によって編集されました。翻訳を転載する必要がある場合は、許可を得るため当社までご連絡ください。
元のリンク:
https://ai.plainenglish.io/advanced-rag-07-exploring-rag-for-tables-5c3fc0de7af6
未知のオープンソースプロジェクトはどれくらいの収益をもたらすのでしょうか? Microsoftの中国AIチームは数百人を巻き込んでまとめて米国に向かいましたが、 Yu Chengdong氏の転職は 15年間の「恥の柱」に釘付けになったと正式に発表されました。前に、しかし今日、彼は私たちに感謝しなければなりません— Tencent QQ Video は過去の屈辱を晴らしますか? 華中科技大学のオープンソース ミラー サイトが外部アクセス向けに正式にオープン レポート: 開発者の 74% にとって Django が依然として第一候補であるZed エディターは、 有名なオープンソース企業の元従業員 によって開発されました。 ニュースを伝えた: 部下から異議を申し立てられた後、技術リーダーは激怒し無礼になり、女性従業員は解雇され、妊娠した。 Alibaba Cloud が Tongyi Qianwen 2.5 を正式リリース Microsoft が Rust Foundation に 100 万米ドルを寄付