p537 ~ 578.
개요
이 장에서는 시스템의 방법과 아이디어를 많이 확장을 설명 데이터베이스에 한정되는 것은 아니다.
확장 기계 업그레이드의 복잡성을 가지고 있기 때문에 우선은, 독립형 최적화 (SQL 또는 하드웨어의 최적화)을 수행하려고합니다. 둘째, 별도의 읽기 및 쓰기를 고려 , 즉, 마스터 멀티 전략 제조 데이터베이스 마스터 쓰기가 라이브러리에 의해 판독. 또, 데이터 조각, 메모리 단편화의 다른 유형의 데이터를 고려한다.
용량 계획
많은 서버가 필요 어떻게 확장을위한 준비, 계획 피크, 계산.
독립형 확장
- SQL 최적화, 인덱스를 추가 할 수 있습니다.
- 향상된 하드웨어
독립적 인 최적화는 한계가있다
하위 라이브러리 조각
- 다른 라이브러리에 상대적으로 독립적 인 사업 분할
- 조각으로 잘라의 종류에 따른 데이터
글로벌 고유 ID를 생성
- 자기 통전 ID 레디 스를 사용하여 생성
- 사용 눈송이 ID (눈송이), 시스템 클럭에 의존
- 성능 저하 질서 GUID 간주 될 수 삽입 사용 GUID는 길고 무질서, GUID를 사용하지 않는 것이 좋습니다.
MySQL의 경우 하나 이상의 기계
때로는 기계의 한 예는 모든 성능, 빌드 여러 인스턴스를 재생할 수 없습니다
MySQL 클러스터를 사용하여
NDB 클러스터, Percona XtraDB 클러스터, Clustrix 등
사용되는 NoSQL
데이터 구조의 간단한 일부 태스크의 고성능이 요구되는 NoSQL로 구현 될
아카이브 데이터
비활성 데이터는 정리 보관
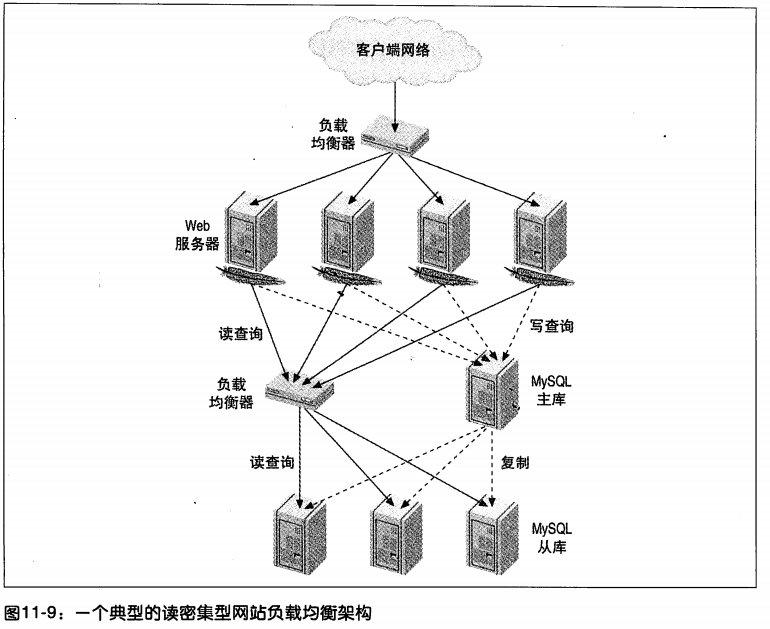
로드 균형 조정
Nginx의 부하 분산 장치를 사용하여처럼