개요: 역전파는 신경망 매개변수의 기울기를 계산하는 방법을 말합니다.
이 기사는 Huawei Cloud Community " Detailed Description of Backpropagation and Gradient Descent ", 저자: Embedded Vision에서 공유됩니다.
1. 순전파와 역전파
1.1, 신경망 훈련 과정
신경망 훈련 과정은 다음과 같습니다.
- 먼저 임의의 매개변수를 통해 결과(모델 순방향 전파 프로세스)를 "추측"합니다. 이를 예측 결과라고 합니다 .
- 그런 다음 a 와 샘플 레이블 값 y 사이의 간격을 계산합니다 (즉, 손실 함수의 계산 프로세스).
- 그런 다음 역전파 알고리즘을 통해 뉴런 매개변수를 업데이트하고 새 매개변수로 다시 시도합니다. 이번에는 "추측"이 아니라 기본으로 올바른 방향에 접근합니다. 결국 매개변수의 조정은 전략적입니다(기반 그래디언트 드롭 전략).
위의 단계를 예측 결과와 실제 결과가 거의 차이가 없을 때까지, 즉 |a−y|→0이 될 때까지 여러 번 반복한 다음 훈련을 종료합니다.
1.2, 정방향 전파
순방향 전파(또는 순방향 패스)는 신경망의 각 계층의 결과를 입력 계층에서 출력 계층으로 순서대로 계산하고 저장하는 것을 말합니다.
순방향 전파의 계산 과정을 더 잘 이해하기 위해 네트워크 구조에 따라 네트워크의 순방향 전파 계산 다이어그램을 그릴 수 있습니다. 다음 그림은 간단한 네트워크와 해당 계산 그래프의 예입니다.
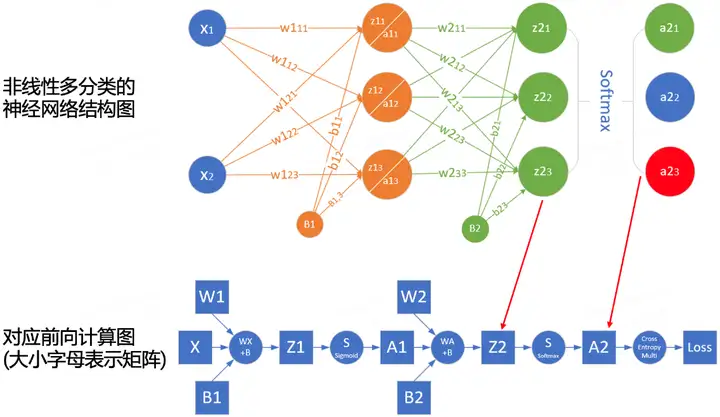
사각형은 변수를 나타내고 원은 연산자를 나타냅니다. 데이터 흐름의 방향은 왼쪽에서 오른쪽으로 순차적으로 계산됩니다.
1.3, 역전파
역전파(backward propagation, BP라고도 함)는 신경망 매개변수의 기울기를 계산하는 방법을 말합니다 . 그 원리는 미적분학의 체인 규칙을 기반으로 하며 출력 레이어에서 입력 레이어까지 역순으로 네트워크를 통과하고 각 중간 변수 및 매개 변수의 그래디언트를 차례로 계산합니다.
기울기의 자동 계산(자동 미분)은 딥 러닝 알고리즘의 구현을 크게 단순화합니다.
역전파 알고리즘은 반복 계산을 피하기 위해 정전파에 저장된 중간 값을 재사용합니다.따라서 정전파의 중간 결과를 보존해야 하므로 모델 학습에 순수한 예측보다 더 많은 메모리가 필요합니다. ( 비디오 메모리). 동시에 이러한 중간 결과가 차지하는 메모리(비디오 메모리) 크기는 네트워크 계층의 수와 배치 크기(batch_size)에 비례하므로 더 깊은 네트워크를 훈련시키기 위해 큰 batch_size를 사용하면 메모리 부족(메모리 부족) 오류!
1.4, 요약
- Forward propagation은 입력 레이어에서 출력 레이어까지 신경망에 의해 정의된 계산 그래프에서 중간 변수를 순차적으로 계산하고 저장합니다.
- 역전파는 신경망의 중간 변수 및 매개변수의 기울기를 역순으로 계산하고 저장합니다(출력 레이어에서 입력 레이어로).
- 신경망을 훈련할 때 모델 매개변수를 초기화한 후 역전파로 계산된 기울기를 기반으로 순전파와 역전파를 교대로 사용하고 확률적 경사하강법 최적화 알고리즘(또는 Adam과 같은 다른 최적화 알고리즘)을 결합하여 모델 매개변수를 업데이트합니다. .
- 딥 러닝 모델 학습에는 예측보다 더 많은 메모리가 필요합니다.
두 번째, 경사하강법
2.1, 딥러닝의 최적화
대부분의 딥 러닝 알고리즘에는 어떤 형태의 최적화가 포함됩니다. 옵티마이저의 목적은 손실 표면에서 손실 값의 최소 지점에 원활하게 도달하도록 네트워크 가중치 매개변수를 업데이트하는 것입니다 .
딥 러닝 최적화에는 많은 문제가 있습니다. 가장 성가신 것 중 일부는 로컬 최소값, 안장점 및 기울기 소실입니다.
- 로컬 최소값 : 임의의 목적 함수 f(x)에 대해 x에서 해당하는 f(x) 값 이 x 보다 작으면 f(x)는 로컬 최소값일 수 있습니다. x 에서 f(x)의 값이 전체 도메인에 대한 목적 함수의 최소값이면 f ( x )는 전역 최소값입니다.
- 안 장점 : 함수의 기울기가 모두 사라지지만 전역 최소값도 지역 최소값도 아닌 모든 위치를 말합니다.
- Vanishing Gradient: 어떤 이유로 목적 함수 f 의 Gradient가 0에 가깝고(즉, Gradient 소멸 문제) ReLU 활성화를 도입하기 전에 딥러닝 모델을 훈련시키는 것이 상당히 어려운 이유 중 하나입니다. 함수와 ResNet.
딥 러닝에서 대부분의 목적 함수는 복잡하고 분석적인 솔루션이 없으므로 수치 최적화 알고리즘을 사용해야 하며 본 논문의 최적화 알고리즘은 SGD와 Adam이 이 범주에 속합니다.
2.2 경사하강법을 이해하는 방법
GD(경사 하강법) 알고리즘은 신경망 모델 훈련에서 가장 일반적인 옵티마이저입니다. 경사하강법이 딥러닝에서 직접 사용되는 경우는 거의 없지만 확률적 경사하강법 및 미니배치 확률적 경사하강법 알고리즘을 이해하려면 경사하강법을 이해하는 것이 기본입니다 .
대부분의 기사에서는 경사 하강법을 이해하기 위해 "사람이 산에 갇혀 계곡 아래로 빠르게 내려갈 필요가 있다"는 예를 사용하지만 이는 완전히 정확하지 않습니다. 자연에서 경사 하강법의 가장 좋은 예는 샘물이 내리막으로 내려가는 과정입니다.
- 물은 중력의 영향을 받아 현재 위치에서 가장 가파른 방향으로 흐르며 때로는 폭포를 형성합니다( 기울기의 반대 방향은 함수 값이 가장 빨리 떨어지는 방향입니다 ).
- 산 아래로 흐르는 물의 경로는 독특하지 않으며, 같은 위치에 같은 경사를 가진 여러 위치가 있을 수 있으므로 전환이 발생합니다(여러 솔루션을 얻을 수 있음).
- 포트홀을 만나면 호수가 형성될 수 있으며 내리막 과정이 종료됩니다(전체 최적 솔루션을 얻을 수 없지만 로컬 최적 솔루션을 얻을 수 있음).
예는 AI-EDU: Gradient Descent를 참조하십시오.
2.3, 경사하강법의 원리
경사하강법의 수학 공식:
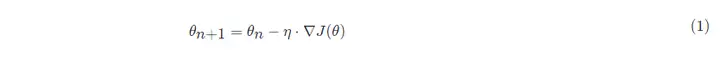
안에:
- θn+1 : 다음 값(신경망에서 매개변수의 업데이트된 값)
- θn : 현재 값(현재 파라미터 값);
- -: 빼기 부호, 기울기의 역방향(기울기의 역방향은 함수 값이 가장 빠르게 감소하는 방향임);
- η: 학습 속도 또는 단계 크기, 각 단계의 이동 거리 제어, 최고의 경치를 놓치지 않도록 너무 빠르지 않게, 너무 오래 걸리지 않도록 너무 느리지 않게(수동으로 조정해야 하는 하이퍼파라미터)
- ∇: 기울기, 함수의 현재 위치에서 가장 빠르게 상승하는 지점(기울기 벡터는 오르막을 가리키고 음의 기울기 벡터는 내리막을 가리킴).
- J(θ): 함수(최적화되기를 기다리는 목적 함수).
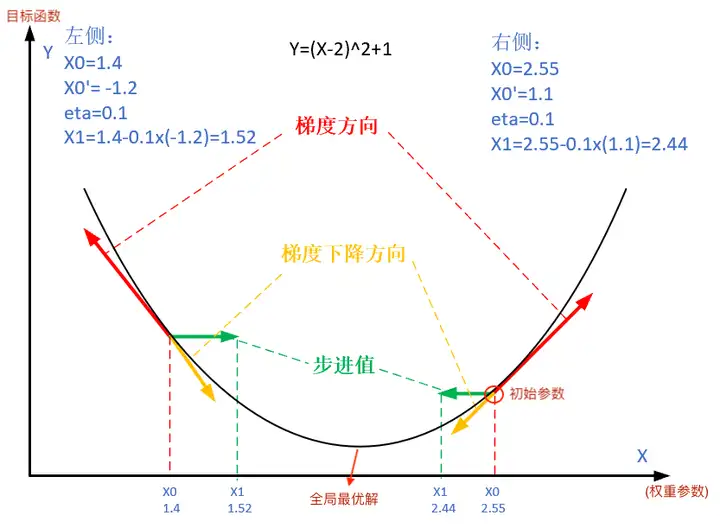
아래 그림은 경사하강법의 단계를 보여줍니다. 경사하강법의 목적은 x 값이 극점에 접근하도록 만드는 것입니다.

이변량이므로 경사하강법의 반복 과정을 3차원 플롯으로 설명해야 합니다. 표 2는 3D 공간에서 경사 하강 과정을 시각화합니다.
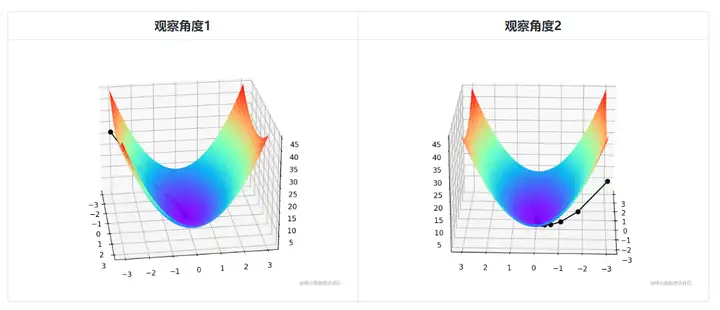
그림 중앙의 희미한 검은색 선은 빨간색 고지에서 파란색 우울증까지 기울기 아래로 내려가는 경사 하강 과정을 나타냅니다.
이변량 볼록 함수 J(x,y)=x2+2y2의 경사하강법 최적화 과정과 시각화 코드는 다음과 같습니다.
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
def target_function(x,y):
J = pow(x, 2) + 2*pow(y, 2)
return J
def derivative_function(theta):
x = theta[0]
y = theta[1]
return np.array([2*x, 4*y])
def show_3d_surface(x, y, z):
fig = plt.figure()
ax = Axes3D(fig)
u = np.linspace(-3, 3, 100)
v = np.linspace(-3, 3, 100)
X, Y = np.meshgrid(u, v)
R = np.zeros((len(u), len(v)))
for i in range(len(u)):
for j in range(len(v)):
R[i, j] = pow(X[i, j], 2)+ 4*pow(Y[i, j], 2)
ax.plot_surface(X, Y, R, cmap='rainbow')
plt.plot(x, y, z, c='black', linewidth=1.5, marker='o', linestyle='solid')
plt.show()
if __name__ == '__main__':
theta = np.array([-3, -3]) # 输入为双变量
eta = 0.1 # 学习率
error = 5e-3 # 迭代终止条件,目标函数值 < error
X = []
Y = []
Z = []
for i in range(50):
print(theta)
x = theta[0]
y = theta[1]
z = target_function(x,y)
X.append(x)
Y.append(y)
Z.append(z)
print("%d: x=%f, y=%f, z=%f" % (i,x,y,z))
d_theta = derivative_function(theta)
print(" ", d_theta)
theta = theta - eta * d_theta
if z < error:
break
show_3d_surface(X,Y,Z)알아채다! 요약하면, 단계 크기 η가 다르면 반복 횟수가 증가함에 따라 최적화된 함수 J의 값이 다르게 변경됩니다.
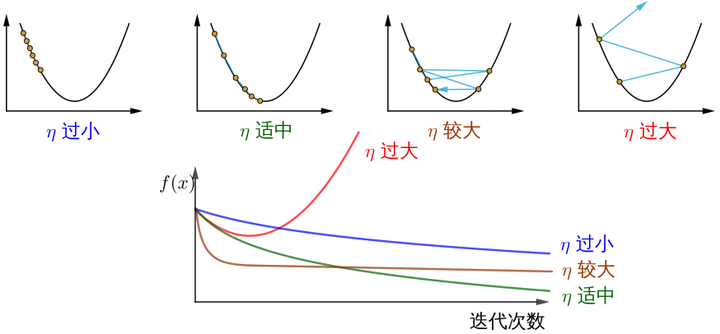
이미지 소스는 경사하강법을 어떻게 이해합니까? .
세 가지, 확률적 경사하강법 및 작은 배치 확률적 경사하강법
3.1, 확률적 경사하강법
딥 러닝에서 목적 함수는 일반적으로 훈련 데이터 세트의 각 샘플에 대한 손실 함수의 평균입니다. 경사하강법을 사용하는 경우 독립 변수 반복당 계산 비용은 O(n)이며 n(샘플 수)에 따라 선형으로 증가합니다. 따라서 훈련 데이터 세트가 크면 반복당 경사하강법의 계산 비용이 높아집니다.
Stochastic Gradient Descent(SGD)는 각 반복에서 계산 비용을 줄입니다. 확률적 경사하강법의 각 반복에서 인덱스 i(i ∈ 1,...,n)에서 무작위로 데이터 샘플을 균일하게 샘플링하고 기울기 ∇J(θ)를 계산하여 가중치 매개변수 θ를 업데이트합니다.

반복당 계산 비용은 경사 하강법의 경우 O(n)에서 상수 O(1)로 떨어집니다. 또한 확률적 기울기 ∇J(θ)는 전체 기울기 ∇J(θ)의 편향되지 않은 추정치라는 점을 강조할 가치가 있습니다.
편향되지 않은 추정은 샘플 통계가 모집단 모수를 추정하는 데 사용될 때 편향되지 않은 추론입니다.
실제 응용에서는 확률적 경사하강법 SGD 방법을 동적 학습률 방법과 함께 사용해야 합니다 . 그렇지 않으면 고정 학습률 + SGD의 조합으로 인해 모델 수렴 프로세스가 더 복잡해집니다.
3.2, 미니배치 확률적 경사하강법
위에서 언급한 경사하강법(GD) 및 확률적 경사하강법(SGD) 방법은 전체 데이터 세트를 사용하여 경사도를 계산하고 매개변수를 업데이트하거나 한 번에 하나의 훈련 샘플만 처리하여 매개변수를 업데이트하는 등 너무 극단적입니다. 실제 프로젝트에서는 둘 사이의 절충, 즉 미니배치 경사하강법을 사용하게 되는데, 미니배치 경사하강법을 사용하면 연산 효율도 높일 수 있다.
미니 배치의 모든 샘플 데이터 요소는 트레이닝 세트에서 무작위로 추출되며 샘플 수는 batch_size(약칭 bs)입니다.
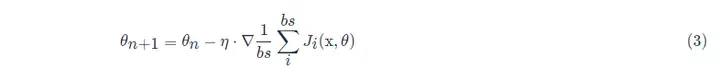
또한 일반 프로젝트에서 사용되는 SGD 최적화 알고리즘은 기본적으로 작은 배치 확률적 경사 하강법을 사용합니다. 즉, 그래픽 카드 메모리가 부족하지 않으면 batch_size = 1로 설정됩니다.
참조
- 경사하강법을 이해하는 방법은 무엇입니까?
- AI-EDU: 경사하강법
- "실습 딥 러닝 11장 - 최적화 알고리즘"
처음으로 Huawei Cloud의 새로운 기술에 대해 알아보고 팔로우하려면 클릭하세요~