

이번 글에서는 생성 AI 관련 기술을 주로 소개하며, 특히 이미지 인식 분야에서의 CNN(Convolutional Neural Network) 적용을 소개한다. 이번 글은 시리즈의 두 번째 글이며,

이전 글에서 신경망과 딥러닝에 대한 소개를 이해했다면, AI 관련 개념과 원리에 대해 점차적으로 더 깊은 이해를 얻는 것은 상대적으로 쉬울 것입니다.
마지막 기사가 모든 사람에게 인상을 줄 수 있기를 바랍니다. AI는 생각만큼 복잡하지 않습니다. AI는 엄청난 양의 정보를 처리할 수 있지만, 인간이 이해하기 어려울 만큼 극도로 복잡한 메커니즘을 갖고 있지는 않습니다. 메커니즘이 상대적으로 단순해야 에너지 소모가 적고, 계산 속도가 빨라지고, 더 많은 정보를 처리할 수 있기 때문이다. 자연에서도 마찬가지다. 만약 뇌의 메커니즘이 지금보다 더 복잡하다면 뇌는 아마도 소진될 것이다.
더 이상 고민하지 않고 가장 기본적인 신경망을 사용하여 동시에 손으로 쓴 숫자를 인식할 수 있다는 것을 지난 기사에서 보았습니다. 또한 신경망이 잘 "학습"하지 못하고 추상적인 이해가 없다는 사실도 발견했습니다. 문제의 일반 법칙에 따라 문제가 발생합니다. 과적합은 종종 데이터와 모델이라는 두 가지 요소와 관련됩니다. 이번 글에서는 과적합을 다루기 위한 이미지 인식 분야의 경험에 대해 이야기하고, 신경망과 딥러닝이 자연어 처리 등 다른 분야로 어떻게 확장될 수 있는지에 대해서도 이야기하겠습니다.

위에서 언급했듯이 신경망은 이미지 인식에 사용될 수 있습니다. 이미지 인식이기 때문에, 컴퓨터 그래픽의 알려진 방법을 결합하여 딥러닝의 효과를 높일 수 있을까요? 대답은 '예'입니다. Convolutional Neural Network는 그래픽 방식을 결합하여 이미지 인식의 효과와 효율성을 크게 최적화하는 네트워크입니다.
▐ 컨벌루션 신경망 원리
-
캡처 기능 - 컨볼루션 작업(convolve): 컨볼루션 레이어는 이미지 처리와 유사한 필터를 통해 개체의 가장자리 및 질감과 같은 기본 기능을 강조하기 위해 전체 이미지를 스캔합니다. 이는 추가 인식을 위해 이미지의 국소적 특징을 포착하기 위한 "선 그리기" 단계로 간주될 수 있습니다. -
단순화 및 강조 - 풀링: 컨볼루션으로 특징을 추출한 후 풀링 레이어는 특징 데이터의 크기를 줄이는 데 도움이 되며 동시에 이미지의 복잡성과 계산 요구 사항을 단순화합니다. 풀링 레이어는 윤곽선과 전체 구조를 강조하기 위해 그림에서 덜 중요한 세부 사항 중 일부를 의도적으로 생략하는 것처럼 작동합니다. -
이 프로세스를 반복하여 추상화 수준을 높입니다. 컨볼루션 신경망에는 종종 둘 이상의 컨볼루션 및 풀링 작업이 있습니다. 일련의 반복되는 컨볼루션과 풀링을 통해 네트워크는 아이들이 선에서 모양을 그리고 캐릭터를 완성하는 과정과 유사하게 단순한 특징을 점차적으로 필터링하고 더 복잡한 모양과 패턴으로 결합합니다. -
특징 합성 - 완전 연결 레이어: 어린이가 사람의 그림을 완성하기 위해 결국 머리, 몸, 팔다리를 적절한 위치에 배치하는 것처럼 컨벌루션 신경망은 여러 수준에서 추상화된 특징을 기반으로 완전 연결 레이어를 사용합니다. 통합 및 분류 작업. 완전 연결 계층은 전체 이미지 수준 특징을 고려하고 이들 사이의 복잡한 관계를 학습하여 특징부터 최종 대상 인식(예: 사진 속 사람 식별)까지의 프로세스를 완료합니다. 위에서 언급한 Dense Layer로 구성된 신경망인 Full Link Layer에 대해서는 누구나 잘 알고 있을 것입니다.
-
여러 라운드의 컨볼루션 작업 후에 후속 완전 연결 계층(위에서 언급한 신경망과 동일)에서 처리해야 하는 객체는 명백한 "현실적인 의미"가 없는 픽셀 및 색상에서 가장자리, 윤곽, 텍스처, 등 특정 "현실적인 의미" 기능을 가지고 있어 이미지 인식의 정확성이 크게 향상됩니다. -
컨볼루션 작업은 완전 연결 계층에서 처리할 최소 단위를 한 단계 증가시킵니다(코드를 작성할 때 한 줄씩 명령문을 작성하는 것이 아니라 원자적 기능을 구성하기 위해 체인을 사용하는 것과 같습니다). 풀링 작업도 이미지 처리에 비해 상대적으로 줄어들지만, 이 두 가지 방법은 이론적으로 효율성을 향상시킬 수 있습니다(비슷한 정확도의 다른 방법에 비해).
▐그래픽은 컨볼루셔널 신경망에서 필터를 의미합니다.
그렇다면 컨볼루션 신경망은 어떤 그래픽 방식을 결합한 걸까요? 그래픽스에서는 필터라고 불리는 컨볼루셔널 신경망에서 컨볼루션 커널(kernel)을 살펴볼 수 있다. 포토샵이나 김프에 익숙한 학생들은 꼭 알아야 할 4가지 필터(사진의 3x3 벡터) 등
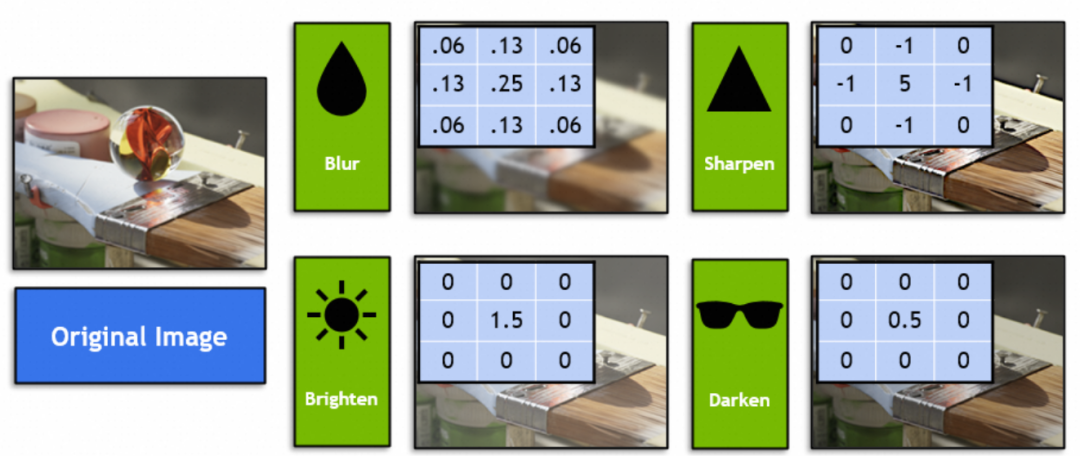
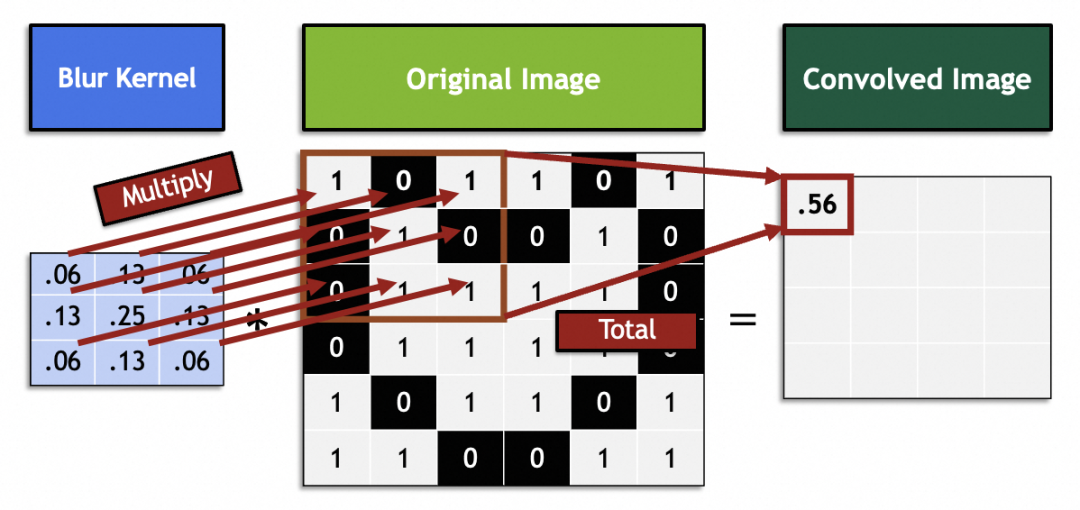
수학에서 필터는 선형 대수 벡터 연산입니다. 원본 이미지의 각 3x3 벡터에 필터의 3x3 벡터를 곱하고 합합니다. 예를 들어, 그림의 이 필터 벡터는 9개의 인접한 픽셀을 중간점에 혼합하여 흐림 효과를 얻습니다.
경험적 데이터: 컨볼루션 신경망에서는 3x3 크기의 컨볼루션 커널을 선택하면 좋은 결과를 얻을 수 있습니다.
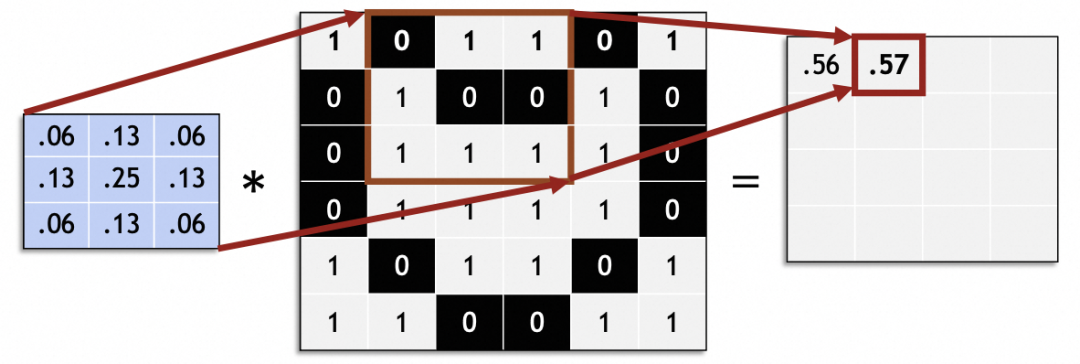
슬라이드하여 전체 원본 이미지를 처리하고 새 이미지를 생성합니다.
컨벌루션 신경망에서 슬라이딩 스텝 크기(스트라이드)는 일반적으로 1입니다. 1 이외의 값을 사용하면 원본 이미지 크기를 스트라이드로 균등하게 나눌 수 없는 등의 문제가 발생할 수 있습니다.
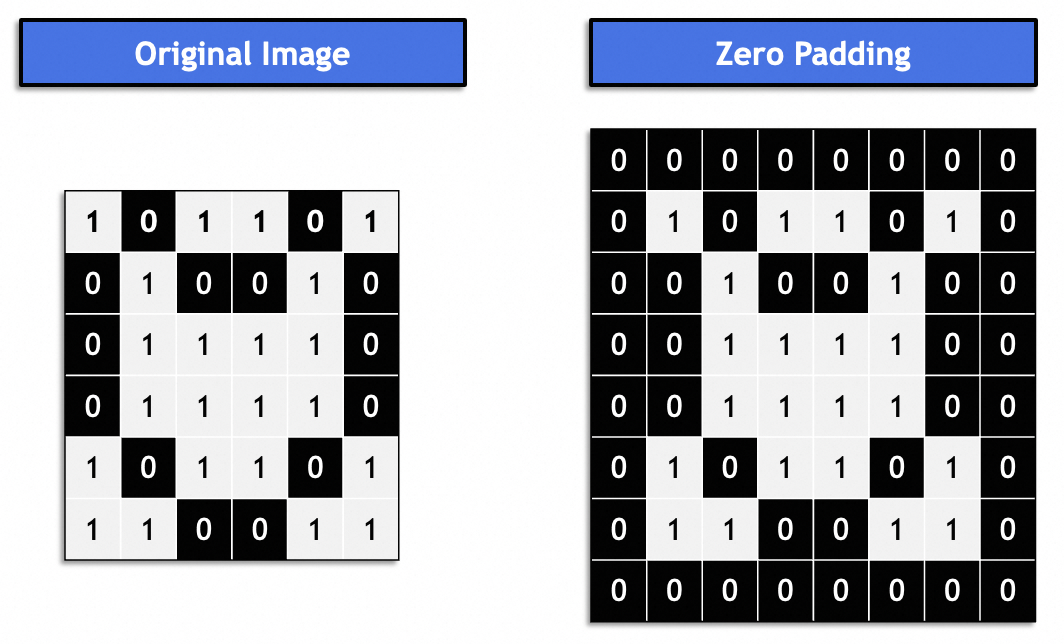
일반적으로 이는 "동일한 패딩"이므로 결과 이미지는 원본 이미지와 일관성을 유지합니다. 일반적으로 0으로 채워집니다.
그렇다면 컨볼루션 커널이나 필터는 어떤 문제를 해결하는 데 사용됩니까? 아래에서 컨볼루션 커널을 살펴볼 수 있습니다. 이들은 특정 벡터 값을 사용하여 원본 이미지의 수직 및 수평 가장자리를 향상시킵니다. 그림에서 볼 수 있듯이 컨볼루션 커널은 실제로 원본 이미지에서 특징을 추출하는 데 사용될 수 있습니다.

마지막으로 그래픽의 필터는 신경망에 어떻게 적용됩니까?
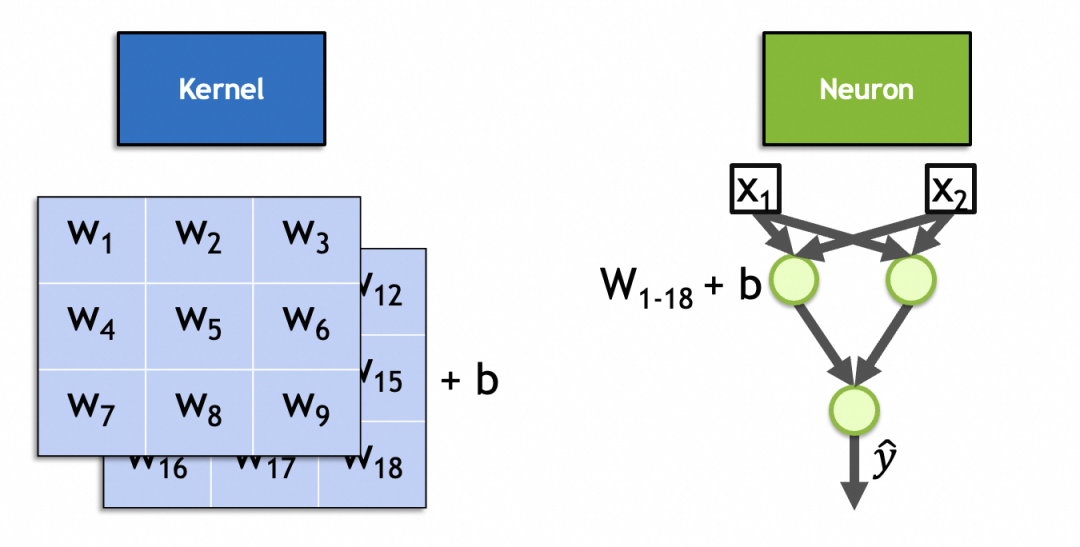
먼저 컨볼루션 커널 벡터와 원본 이미지 벡터를 곱하고 합산(재활성화)하는데, 이는 뉴런 매개변수와 입력을 곱하고 합산하고 다시 활성화하는 것과 유사하게 컨볼루션 커널을 신경망의 뉴런으로 표현할 수 있다.
둘째, 위에 주어진 블러, 샤픈, 수평 및 수직 에지 필터의 알려진 벡터 값과 달리 컨볼루션 커널의 벡터 값은 훈련 가능하고 입력 특징 및 뉴런 매개변수를 동적으로 캡처하는 데 사용됩니다. 사용법은 일관적입니다.
실제로 컨볼루션 커널은 컨볼루션 계층의 뉴런입니다. 완전 연결 계층 뉴런과 유사하게 해당 매개변수도 입력 가중치 + x * y * n편향 상수입니다. 여기서 입력 가중치 수는 입력 이미지 수와 같습니다. 입력 가중치 수는 입니다. 1로 고정되어 있으며, x * y * n + 1총 1개 입니다 . 이 2스택, 3x3 커널의 그림에서 볼 수 있듯이 매개변수 개수는 입니다 3 * 3 * 2 + 1 = 19.
▐컨벌루션 신경망 계산 과정
컨벌루션 신경망의 계산은 이전 신경망의 순전파(forward propagation)와 역전파(back propagation)와 동일하므로 자세한 설명은 생략한다.
아래 그림에서 이미지 입력은 28x28 크기, 1개의 스택(1개의 회색조 레이어)입니다. 커널은 컨볼루셔널 레이어입니다. 쌓인 이미지는 네트워크 레이어가 아니라 마지막으로 쌓인 컨벌루션 레이어입니다. 그림 이미지는 후속 완전 연결 계층 네트워크(완전 연결 계층에 대해서는 위에서 설명했습니다)에서 사용하기 위해 평탄화된 계층을 통해 1차원 배열(그림에서 평탄화된 이미지 벡터)로 평탄화됩니다.
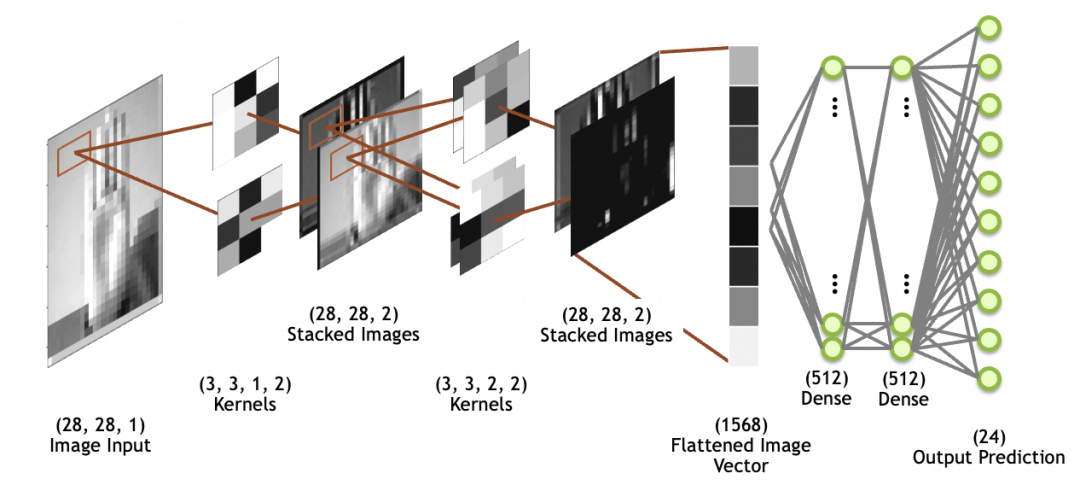
회선
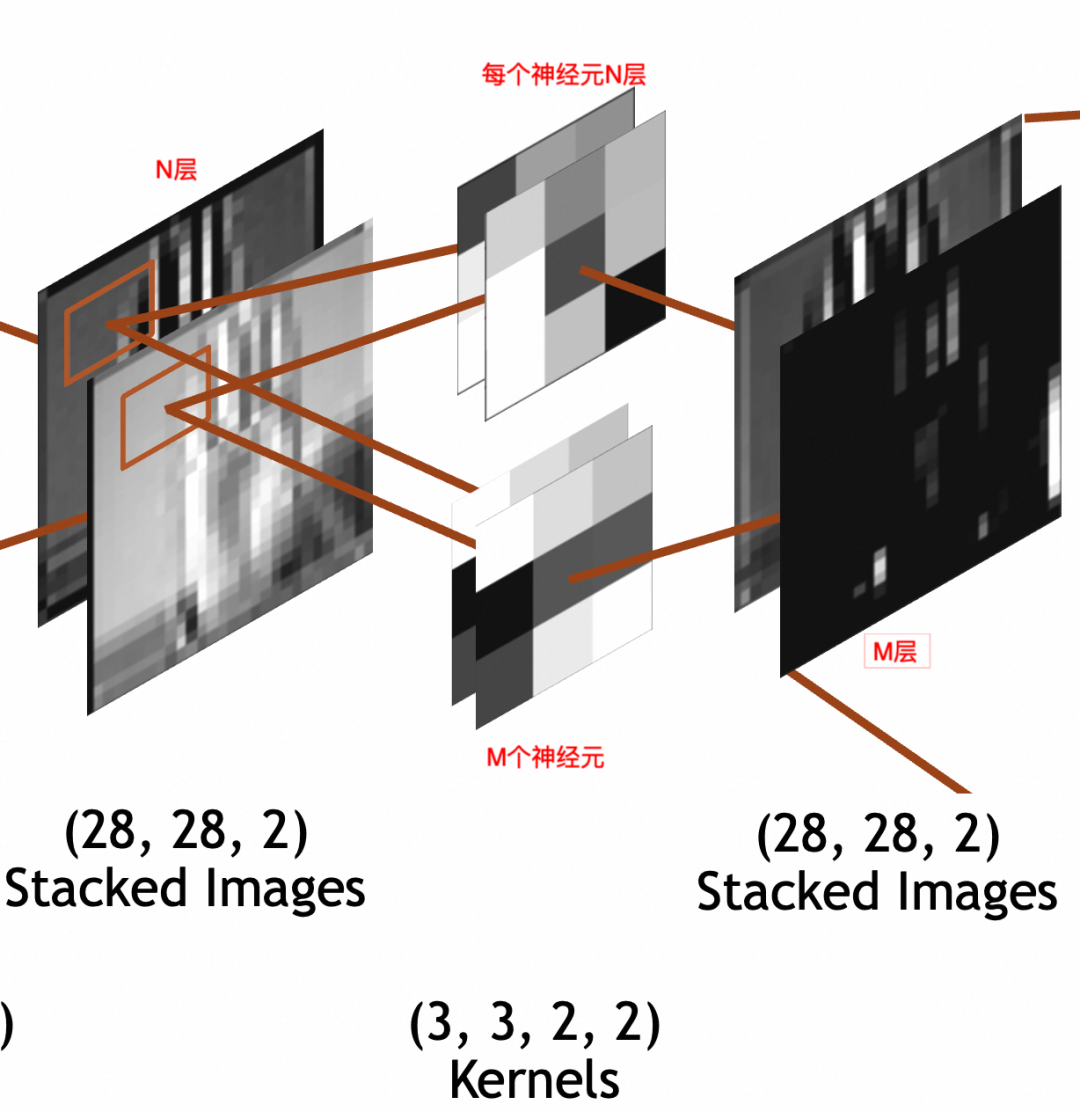
숫자 값인 이전의 완전 연결 계층(Dense) 뉴런 출력과 달리 매번 컨볼루션 커널 뉴런이 곱해지고 활성화되어 두 방향을 결합하고 연속적으로 슬라이딩하면 최종적으로 2차원 맵이 생성될 수 있습니다. 얻을 수 있습니다.
输入是
x * y * N
的堆叠图像。其中,x=28,y=28(
28 * 28 * N
)。卷积层每个神经元因为要和输入相乘,所以也是N叠,假设神经元采用
3 * 3
大小,则每个神经元是
3 * 3 * N
。输出经过padding,每叠大小和输入保持一致,
28 * 28
。输出堆叠图像的每一叠为输入堆叠图像x单个神经元的结果,所以叠数和卷积层神经元个数一致。假设卷积层有M个神经元,则输出堆叠图像为
28 * 28 * M
。这里强调一下,卷积层每个神经元的叠数=输入图像的叠数。输出图像的叠数=卷积层神经元的个数。
3 * 3 * N
的卷积核,每次要和N叠输入图像的
3 * 3
部分相乘,所以权重参数(weights)个数为
3 * 3 * N
,此外还通过一个偏置(bias)整体左右移。所以总参数个数为
3 * 3 * N + 1
,激活结果计算公式还是和上文普通神经元一样
output = activation_function(W * X + b)
。
为了神经网络整体处理方便,网络的输入图像、中间的堆叠图像都被统一成了 x * y * Z三维数组结构,但是两者关于叠/层的语义是不同的。输入图像的语义是图像的图层,不管是灰阶图像的1层,RGB的3层,还是RGBA的4层,是有现实关联性的。堆叠图像的各层分别是输入图像和单个神经元计算的结果,是一个特征,相互之间没有关联性,比如一层可能是纵边特征,另一层可能是横边特征。
讲原理时已经提到过,一般会有多轮卷积,主要目的分别是从原图提取最小的特征,从最小特征中提取中等特征,……,如下图所示:
池化
池化层的作用,主要是通过缩小图像,丢弃次要特征,保留主要特征:
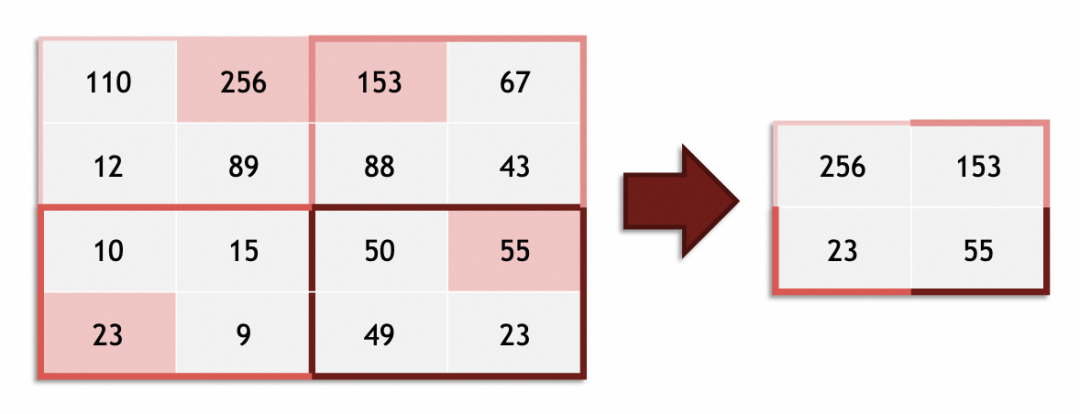
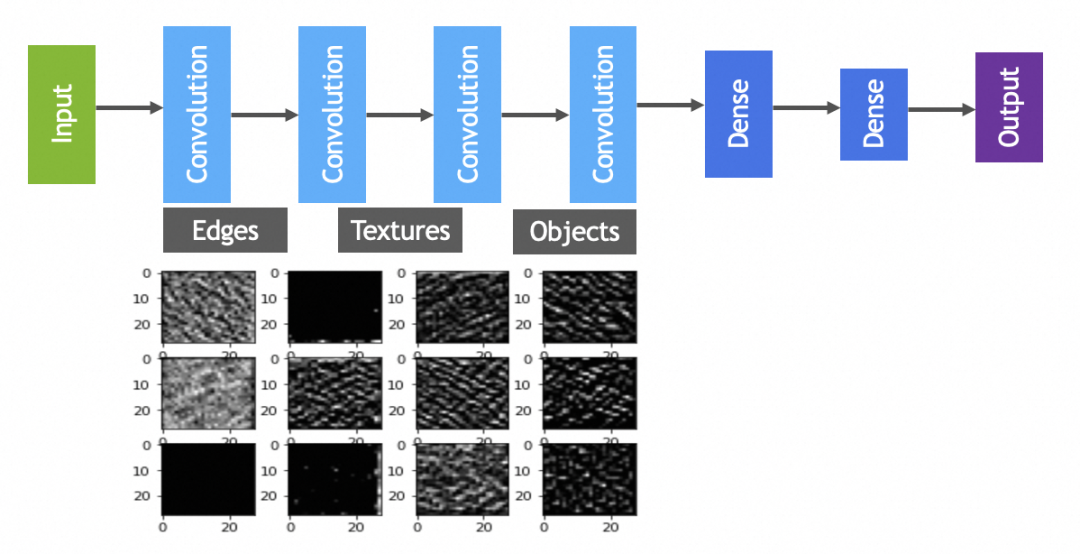
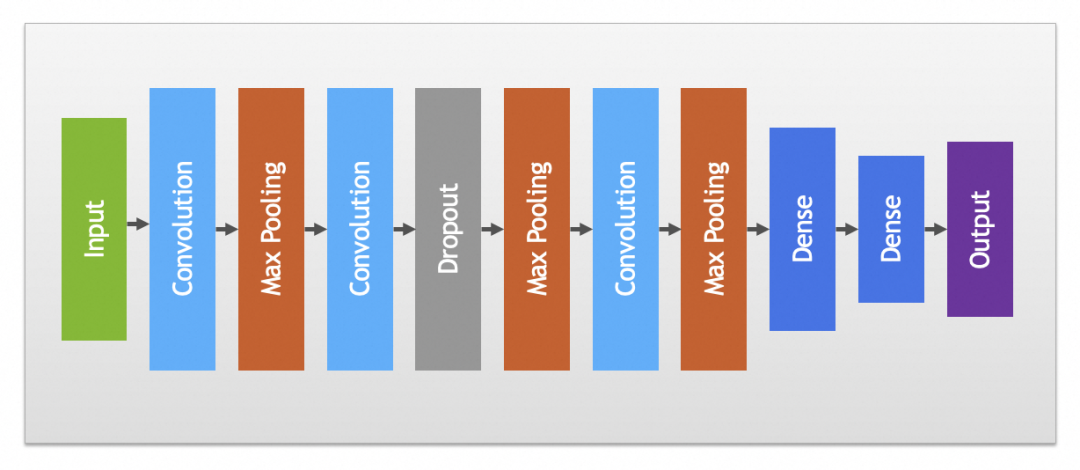
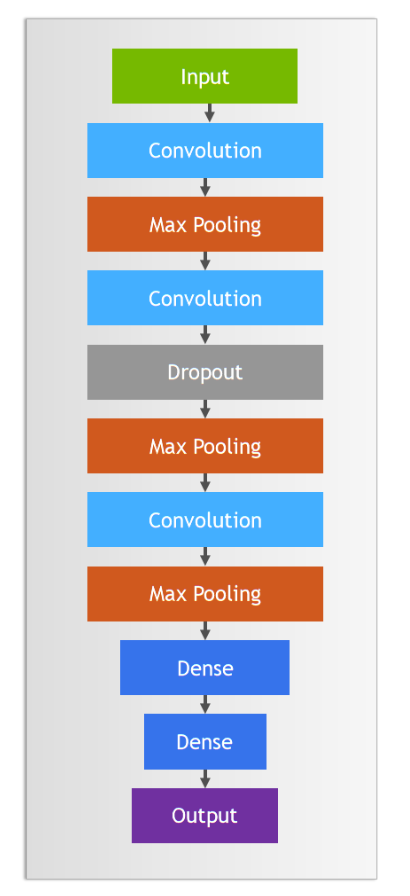
实践中卷积和池化层一般会搭配使用,完整卷积神经网络如下图:
其它
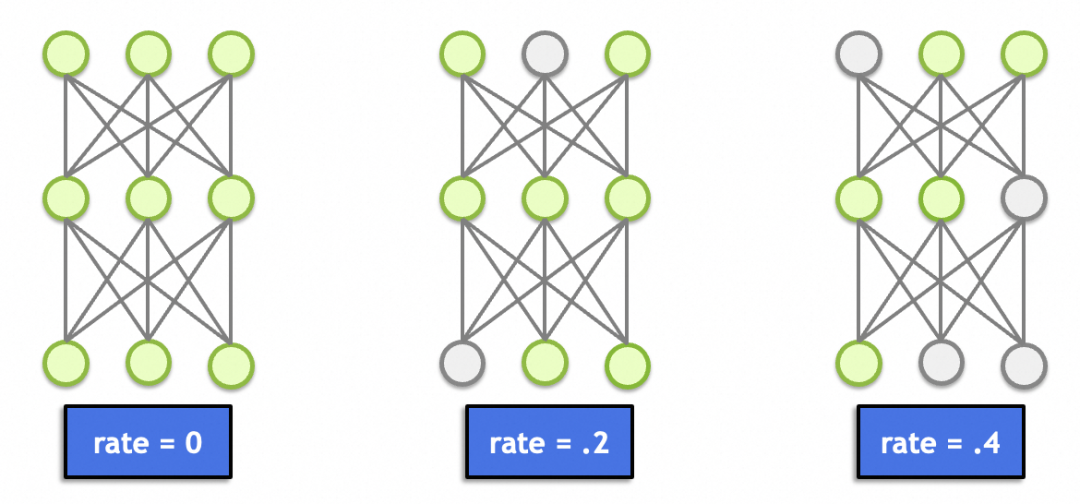
这里面还有一个丢弃层(Dropout),这个理论上跟图形学、图像处理没啥关系。主要作用是随机丢弃一定比例节点的输入(置0),避免因为节点过多(总参数过多、记忆能力太强)导致记忆效应,产生过拟合。
▐ 卷积神经网络实例讲解
本文卷积神经网络讲解的实例是对美国手语的识别,因为是手语照片,相对上文手写文字的案例来讲干扰因素过多,比如背景、衣服、掌纹等,所以采用普通神经网络过拟合比较严重。后面可以看到,改用卷积神经网络后,结果提升了不少。
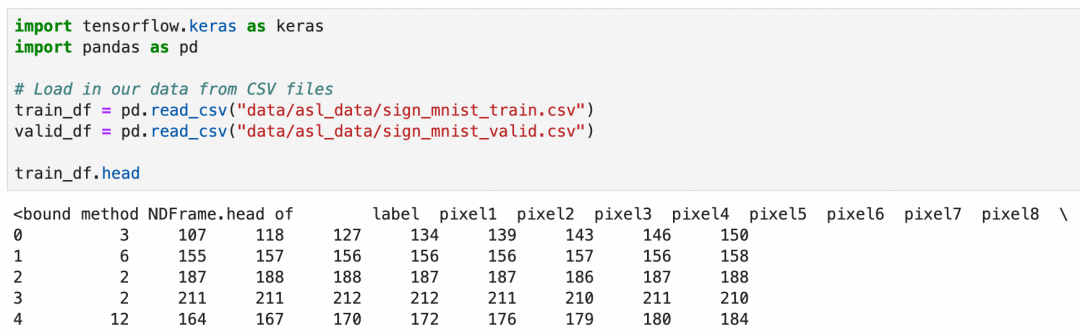
美国手语一共26个字母,其中2个字母带动作,这里只识别24个静止的字母。这次的数据集是使用csv文件存储的,可以加载后查看一下数据概貌:
csv文件一共785列,第一列是label,值是1-24,表示24种字母。第2到785列分别存放的灰阶值,值是0-255,表示从黑到白的颜色。
处理一下加载的值,将标签存入y_train和y_valid,784个像素值保留到x_train和x_valid:
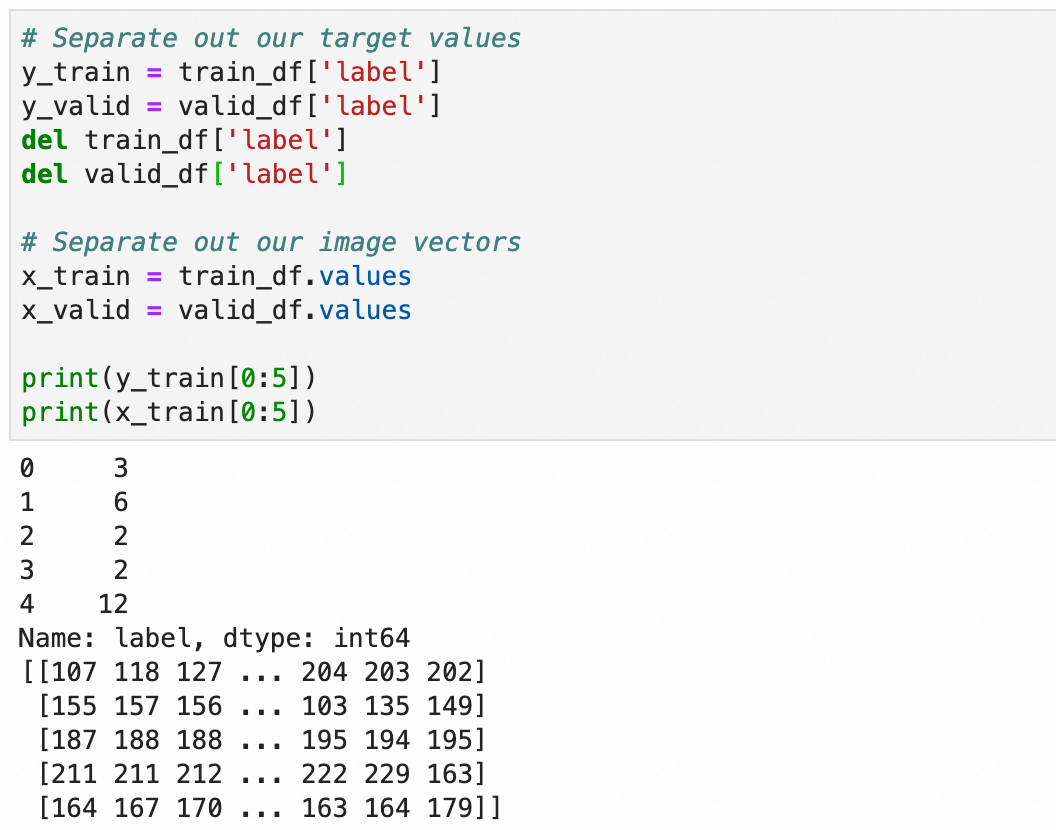
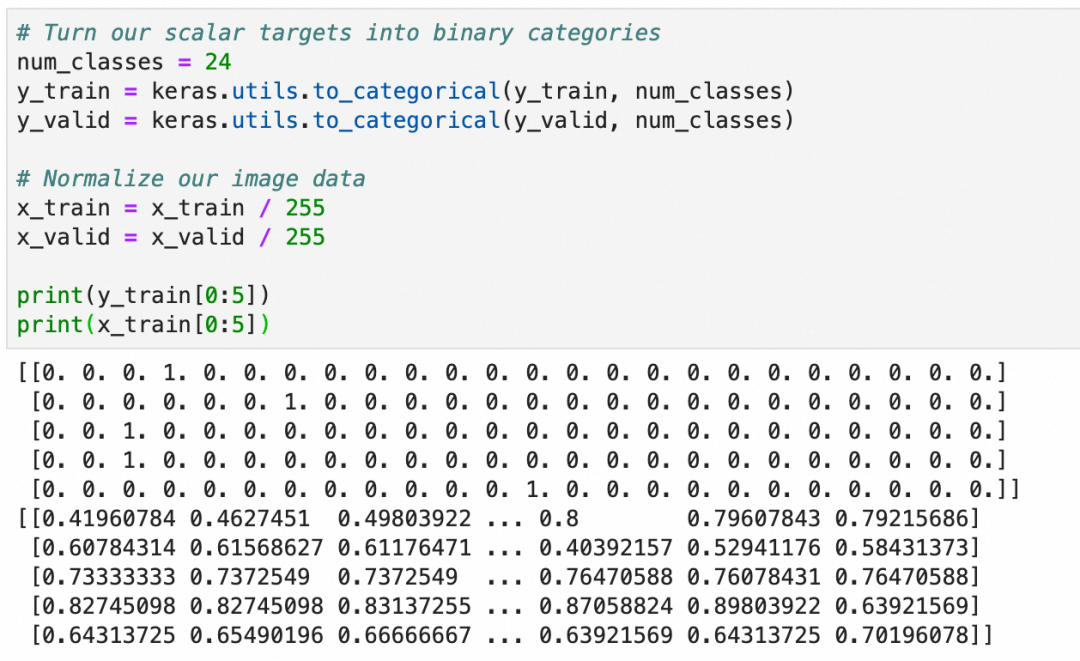
和上文一致,将y转成one-hot编码,用于分类算法,x转成0.0-1.0之间的浮点数:


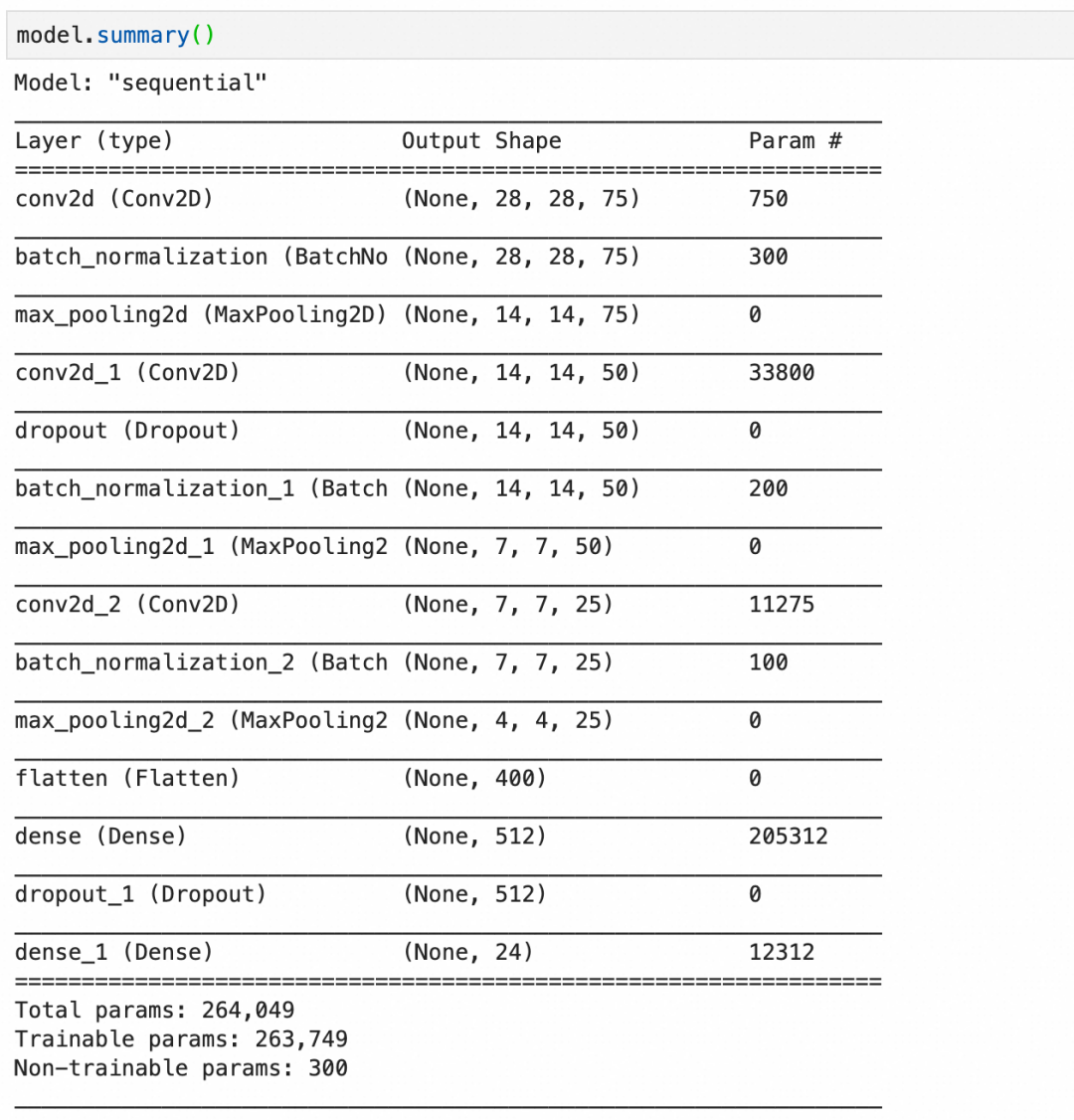
构建语句,其中:
Conv2D(75, (3, 3), stride=1, padding="same", activation="relu", input_shape=(28, 28, 1))创建一个卷积层,输入是28*28*1,75个神经元,每层大小3*3,因为输入是1层,所以每个神经元只有1层。BatchNormalization()创建一个批量标准化层,标准化上层输出平均激活值接近于0,激活值的标准差接近于1。MaxPool2D((2, 2), strides=2, padding="same")创建一个池化层,每2*2像素保留1像素,即长宽各缩小1倍。Dropout(0.2)创建一个丢弃层,丢弃20%输入。

第1层,卷积层,75个神经元,每个神经元 3*3*1+1 个参数,一共750个参数。
第2层,批量标准化层,75层输入,每层4个参数,其中2个可训练参数:缩放和偏移,还有2个不可训练参数,存储本批数据的统计值。一共300个参数。
第3层,池化层,池化层都是运算,没有参数。
第4层,卷积层,50个神经元,每个神经元3*3*75+1个参数(每个神经元有75层,分别对应输入的75层),一共33800个参数。
第5层,丢弃层,丢弃层只有运算,没有参数。
第11层,flatten层,只有转化,没有参数。
最后,总的参数个数里,有300个不可训练参数,这是由3个批量标准化层的不可训练参数加在一起构成。

本卷积神经网络校验集的准确度最后能到92%左右,算是比较好的结果:
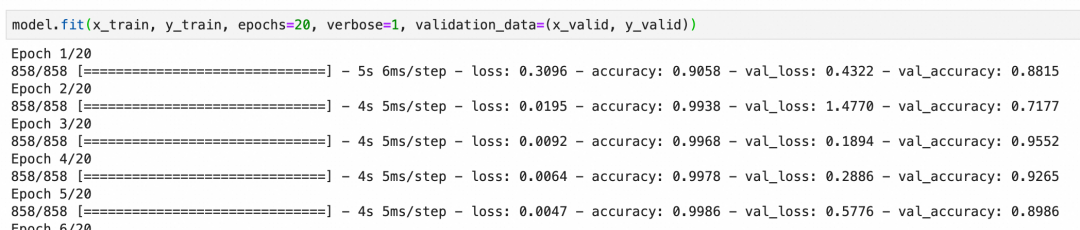

上面一章我们看了如何通过优化模型来降低过拟合,下面我们来看看如何通过数据增强来提升整体准确度。
数据增强通俗的理解就是通过丰富训练集数据、增加样本数量,减少模型对具体实例的“记忆”、增加模型抽象一般规律的能力。比如我们要训练识别狗的图片,能提供的训练样本当然是越全越好,即需要很多正例(比如金毛、边牧等不同品种的狗),也需要尽可能多的反例(比如猫、狼)。
道理很好理解,但是准备足够多样的训练样本是一件很费事的事情。数据增强是深度学习框架提供的一套工具,通过对现有训练集进行细微变化,比如(适度的)缩放、旋转、位移等等,来批量生产新的训练样本。
需要注意的是,需要根据数据集的特征来决定要进行怎样的变化,比如上一章的手语图片,样本是可以左右翻转的,因为左撇子的手势刚好左右翻转,但是垂直翻转则没有意义;同理,上文中的手写数字,则既不能垂直翻转,也不能左右翻转。
另外,样本的变化也要注意范围,因为网络接收的图片尺寸从一开始就是确定的,这些变化不会改变接收图片的尺寸。比如图片放大缩小,超出图片大小的部分会被裁剪,缺失的部分会被填充。所以,需要考虑变化后的图片是否还有意义,比如手语图片过分放大,放大到只剩一根手指,细节部分是清晰了,但是整体已经完全看不出所代表的手语字母了。
本章不涉及原理,因为这符合人们的一般理解。重点讲一下数据增强的过程:
第1步,还是上一章所用的训练集和模型不变。
train_df = pd.read_csv(...)...model = Sequential()model.add(...)...model.compile(...)
第2步,准备数据增强用的图像数据生成器:随机旋转10度、缩放10%、左右上下位移10%以内,随机水平翻转,但不垂直翻转。
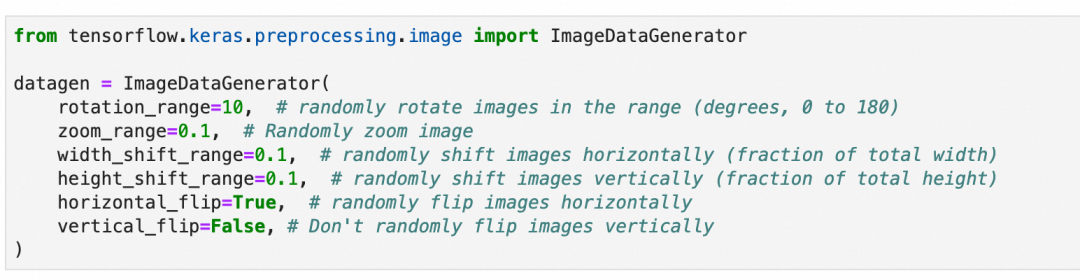
第3步,设置分批生成数据的大小:设置每批生成32张图片。

上面得到的是一个生成数据的迭代器,可以可视化一下第一批数据的样子:
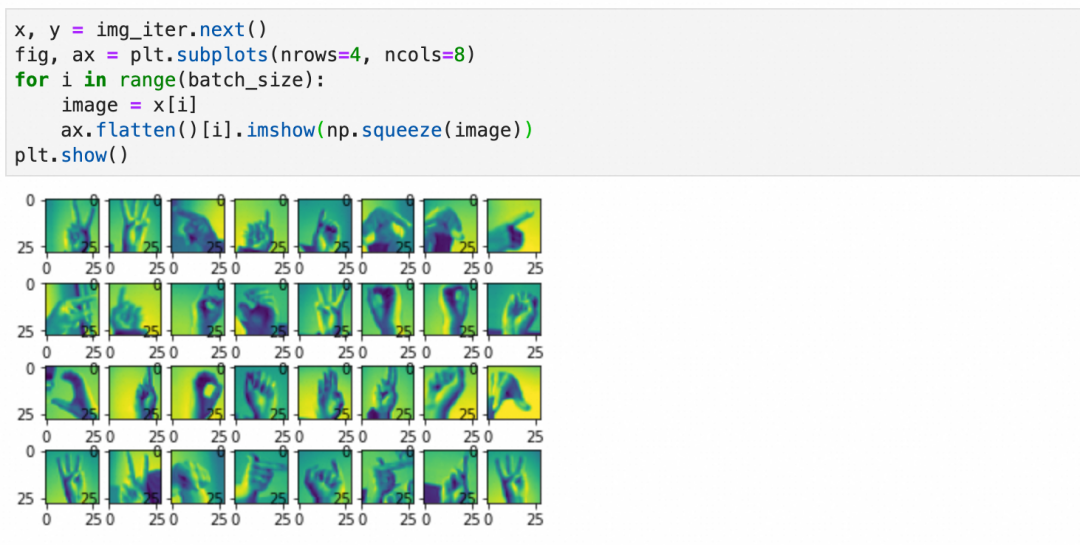
对训练样本的变化除了上面提到的旋转、缩放、位移等,还有基于原训练样本统计值的变化(本案例没用到)。
这一步是统计整个原训练样本,并记录必要的统计信息到数据生成器。

第5步,用数据生成器进行训练:
和上一章案例直接使用原始样本不同model.fit(x_train, y_train, epochs=20, verbose=1, validation_data=(x_valid, y_valid))。这里使用数据生成器生成的内容。
还是20个周期,但是每个周期里训练的样本数等于steps_per_epoch * batch_size,基于丰富度和训练时长兼顾考虑,这里采用steps_per_epoch=len(x_train)/batch_size,每周期样本数和原训练集差不多(但是都是经过数据生成器,随机变化过后的新样本)。
最后结果可以看出,准确度很快就上去了,数据增强有非常明显的效果。


▐ 迁移学习
迁移学习就是通过将已经训练好的模型的一部分摘出来,重新和其它网络层组成新的网络,从而复用网络能力和提升网络效果的过程。
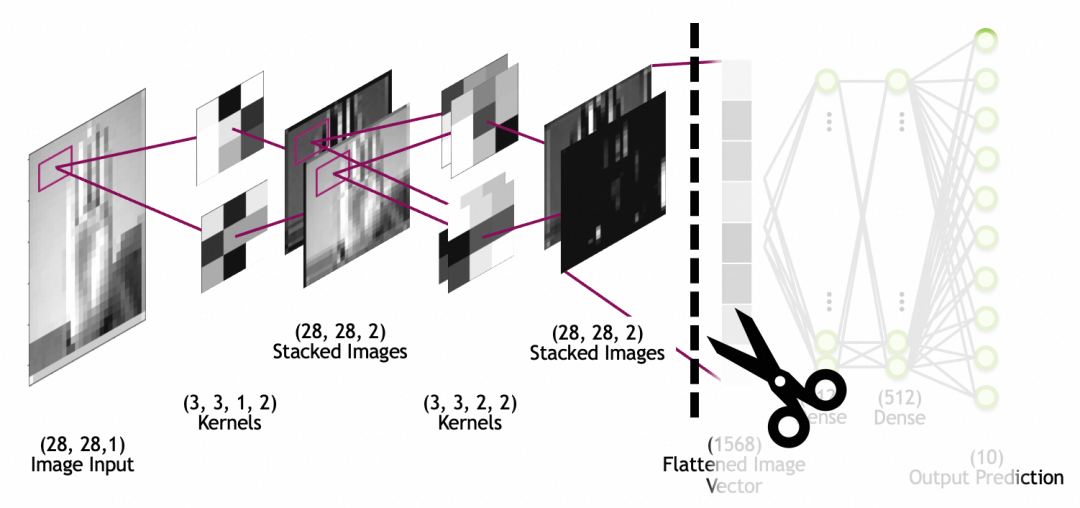
比如,我们可以拿google已经训练好的,进行动物分类的模型,拿来识别自家的猫主子,做一个自动猫门。
为什么要这么做?简单的说就是你自己的训练集不够,你给自家猫拍一千张照片来从头训练一个模型,也可能把外面的流浪猫放进来,因为你缺少足够的正负样本。
因为篇幅原因,这里不详细展开,只讲一下关键步骤。细节可以参考Transfer learning and fine-tuning官方教程:
第1步,摘取预训练模型的前半段(卷积层+池化层),去掉后半部分(include_top=False)。
第2步,拼接模型的后半段为新的、未经训练的全连接层。
第3步,设置前半部分参数不动(trainable=False),拿新的正负样本训练模型的后半段。
你会发现,有了预训练模型的前半段,很快就可以取得不错的结果。
这里我们也可以得出结论,网络前半段的参数,包含了比较通用的特征,比如一般的猫狗,网络后半段则包含了比较具体的特征,比如你家的猫主子。
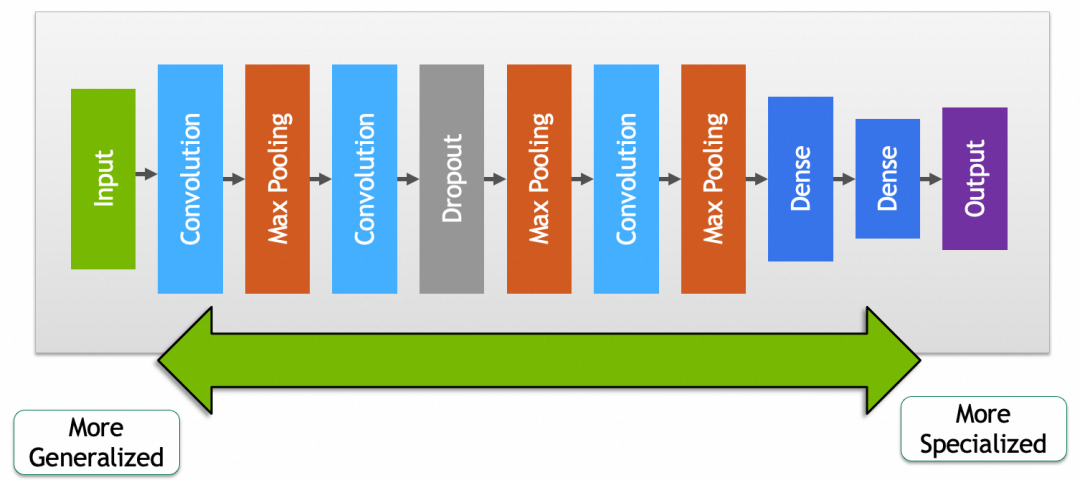
▐ 微调
如果复用网络后,发现效果没有特别满意,可能是因为预训练模型和你要求解的问题没有完全匹配,或者现有模型参数里缺少一些针对性的特征。微调就是通过稍微调整一下预训练模型部分的参数,提升被复用网络效果的过程。
微调的过程很简单,前面3步保持不变,增加下面的步骤:
第4步,设置前半部分参数可训练(trainable=True),同时设置训练步长为一个非常小的值。
第5步,继续训练几个周期,这样整个网络的参数,包括预训练的前半段,和你新加入的后半段,都会按新的数据进行调整,针对特定问题的结果也会更好。
这里要注意两点:
第4步训练步长一定要小,这样每次参数的变化非常小,尽可能的保持预训练模型中的参数(一般特征)。
第3步一定要训练完成,即后半部分已经基于新数据训练过。否则,如果后半部分参数很随机,反向传播时,就算训练步长非常小,前半部分的参数也会发生非常大的波动,导致模型的基础特征被破坏。

高级神经网络不仅包括卷积神经网络,还涵盖了循环神经网络。卷积神经网络主要应用于图像识别的领域,而循环神经网络则广泛用于处理自然语言。随着Transformer模型的出现,自然语言处理的技术有了新的发展。关于自然语言处理的更多细节,将在后续关于Transformer原理的文章中详细介绍,故在此不作过多阐述。
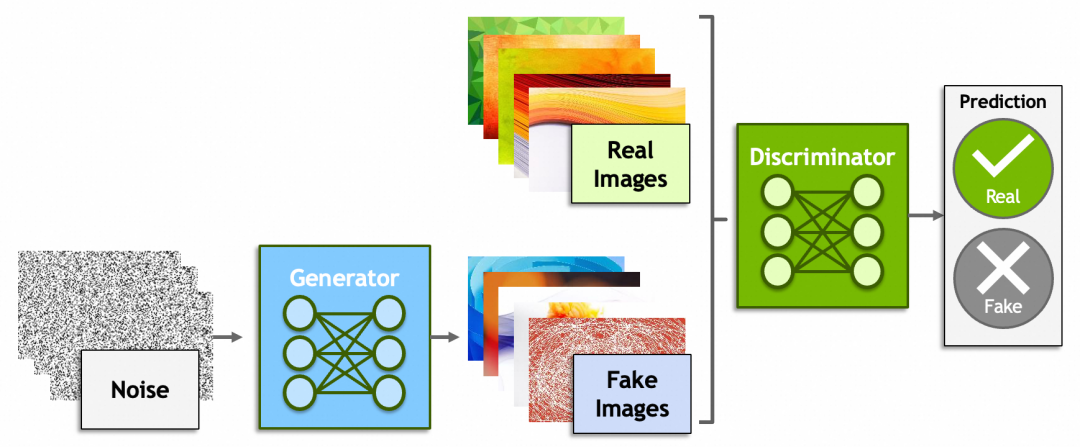
除了神经网络,深度学习里还有一些概念比较有意思,比如生成式对抗网络(Generative Adversarial Networks)、强化学习(Reinforcement Learning)。
生成式对抗网络一方是生成器(Generator)从一堆噪音里生成出假的图片,企图骗过鉴别器(Discriminator);而另一方鉴别器则尽可能的识别出真假图片。原理上还是脱离不了之前讲过的内容,鉴别器会给出一个分数,生成器会根据这个分数反向传播,修改由噪音生成图片的参数。
还记得“前GPT时代”,2022年Google研究员Blake Lemoine爆料AI有自我意识,被公司开除的新闻吗[捂脸哭]?谁说ChatGPT、MidJourney、Sora不是一些骗过了研究员、非常成功的生成式对抗网络呢?然而另一方面,就像【中文房间】描述的问题一样,哪里才是生成式对抗和真正理解的边界?大模型究竟能不能走向通用人工智能?
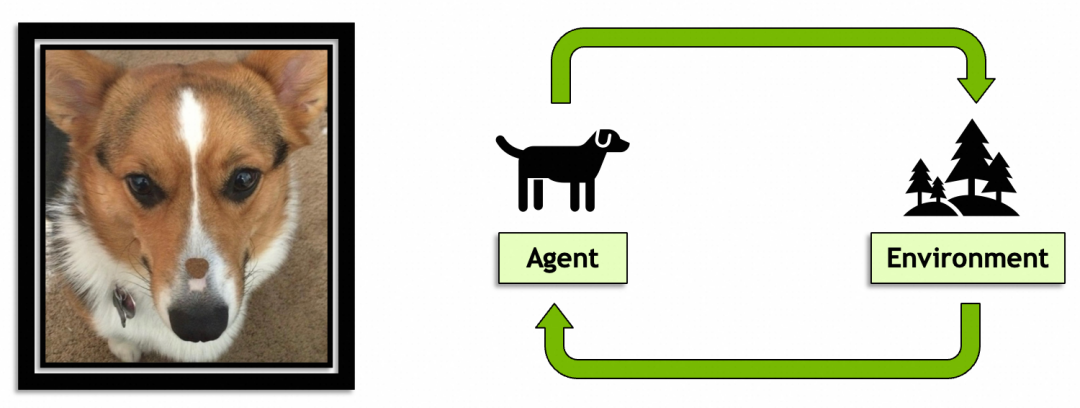
后一个概念,强化学习就是AI从环境中学习的过程和能力,目前机器人领域用得比较多。个人认为这个概念有意思是因为它是通向通用人工智能的必经之路,预计未来会扮演比较重要的角色。
本系列头两篇文章到这里就结束了,希望能激起大家学习AI原理的好奇心和勇气。个人水平有限,如果文章有什么问题,欢迎留言探讨。

团队介绍
天猫国际是中国领先的进口电商平台, 也是阿里巴巴-淘天集团电商技术体系中链路最完整且最为复杂的技术产品之一,也是淘天集团拥有最完整业务形态(平台+直营、跨境、大贸、免税等多业务模式)的业务。在这里我们参与到阿里电商体系的绝大部分核心系统(导购、商家、商品、交易、营销、履约等),同时借助区块链、大数据、AI算法等前沿技术助力业务高速增长。作为贴近业务前沿的技术团队,我们对于电商行业特性、跨境市场研究、未来交易趋势以及未来技术布局等都有着深度的理解。
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。