대규모 언어 모델은 자연어 처리 분야의 최첨단 기술을 발전시킵니다. 그러나 이들은 주로 영어 또는 제한된 언어 세트용으로 설계되었으므로 리소스가 부족한 언어에 대한 효율성에는 큰 차이가 있습니다. 이러한 격차를 해소하기 위해 뮌헨 대학, 헬싱키 대학의 연구원 및 기타 연구원들은 광범위한 534개 언어를 포괄하는 것을 목표로 하는 MaLA-500을 공동으로 오픈 소스로 공개했습니다.
MaLA-500은 LLaMA 2 7B를 기반으로 제작되었으며 언어 확장 훈련을 위해 다국어 데이터 세트 Glot500-c를 사용합니다. SIB-200에 대한 연구원의 실험 결과는 MaLA-500이 최첨단 상황 학습 결과를 달성했음을 보여줍니다.
Glot500-c에는 47개 민족 언어를 포괄하는 534개 언어가 포함되어 있으며 데이터 양은 최대 2조 토큰입니다. 연구원들은 Glot500-c 데이터 세트를 선택한 이유는 기존 언어 모델의 언어 적용 범위를 크게 확장할 수 있고 매우 풍부한 언어군을 포함하고 있어 모델이 고유한 문법과 의미를 학습하는 데 큰 도움이 되기 때문이라고 말했습니다. 언어의 규칙.
또한, 일부 고자원 언어의 비율은 상대적으로 낮지만, Glot500-c의 전체 데이터 양은 대규모 언어 모델을 훈련하는 데 충분합니다. 후속 전처리에서는 훈련 데이터에서 자원이 적은 언어의 비율을 높이고 모델이 특정 언어에 더 집중할 수 있도록 코퍼스 데이터 세트에 대해 가중치가 있는 무작위 샘플링을 수행했습니다.
LLaMA 2-7B를 기반으로 MaLA-500은 두 가지 주요 기술 혁신을 이루었습니다.
- 어휘력을 향상시키기 위해 연구원들은 Glot500-c 데이터 세트를 통해 다국어 단어 분할기를 훈련하여 LLaMA 2의 원래 영어 어휘를 260만 개로 확장하여 영어가 아닌 언어와 자원이 적은 언어에 적응하는 모델의 능력을 크게 향상시켰습니다.

- 모델 향상은 LoRA 기술을 사용하여 LLaMA 2 기반의 하위 적응을 수행합니다. 적응 행렬을 훈련하고 기본 모델 가중치를 동결하는 것만으로도 모델의 원래 지식을 유지하면서 새로운 언어에서 모델의 지속적인 학습 능력을 효과적으로 실현할 수 있습니다.
훈련 과정
훈련 측면에서 연구원들은 훈련을 위해 24개의 N-card A100 GPU를 사용했으며 Transformers, PEFT 및 DeepSpeed를 포함한 세 가지 주류 딥 러닝 프레임워크를 사용했습니다.
그중 DeepSpeed는 분산 훈련을 지원하고 모델 병렬성을 달성할 수 있으며, PEFT는 효율적인 모델 미세 조정을 구현하고, Transformers는 텍스트 생성, 신속한 단어 이해 등과 같은 모델 기능 구현을 제공합니다.
MaLA-500은 훈련의 효율성을 높이기 위해 GPU 컴퓨팅 자원의 활용을 극대화할 수 있는 ZeRO 중복 최적화, 혼합 정밀도 훈련을 위한 bfloat16 숫자 형식 등 다양한 메모리 및 컴퓨팅 최적화 알고리즘을 사용하여 학습 속도를 가속화합니다. 훈련 과정.
또한 연구원들은 모델이 너무 크거나 과적합되거나 불안정한 것을 방지하기 위해 학습률 2e-4의 기존 SGD 훈련과 L2 가중치 감쇠 0.01을 사용하여 모델 매개변수에 대한 많은 최적화를 수행했습니다. 콘텐츠 출력 등 조건.
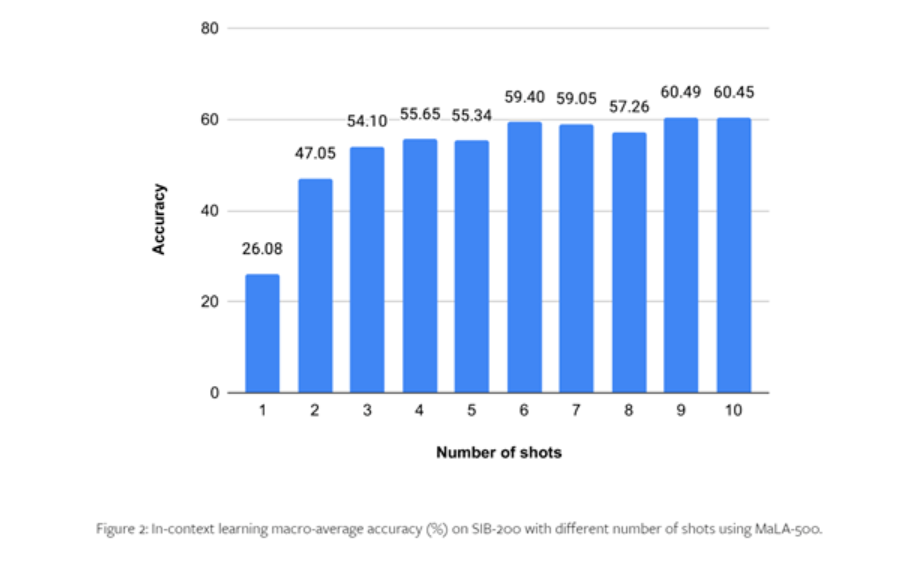
연구진은 MaLA-500의 성능을 테스트하기 위해 SIB-200 등의 데이터세트를 대상으로 포괄적인 실험을 진행했다.
결과는 원래 LLaMA 2 모델과 비교하여 주제 분류 등 평가 작업에 대한 MaLA-500의 정확도가 12.16% 증가한 것으로 나타났습니다. 이는 MaLA-500의 다국어가 기존의 많은 오픈 소스 대형 언어 모델보다 우수함을 나타냅니다. .
자세한 내용은 전체 문서에서 확인할 수 있습니다 .