
iQiyi는 회사의 운영 결정, 사용자 성장, 비디오 추천, 멤버십, 광고 및 기타 비즈니스 요구를 지원하기 위해 Hive를 기반으로 하는 전통적인 오프라인 데이터 웨어하우스를 구축했습니다. 최근 몇 년 동안 기업은 실시간 데이터에 대한 요구 사항이 높아졌습니다. Iceberg 기반의 데이터 레이크 기술을 도입하여 데이터 쿼리 성능과 전반적인 순환 효율성을 획기적으로 향상시켰습니다. 성능 및 비용 측면에서 기존 Hive 테이블을 데이터 레이크로 마이그레이션하는 것이 필요합니다. 그러나 수년에 걸쳐 수백 페타바이트의 Hive 데이터가 빅 데이터 플랫폼에 축적되었습니다. Hive를 데이터 레이크로 마이그레이션하는 방법은 우리가 직면한 주요 과제가 되었습니다. 이 기사에서는 Hive에서 Iceberg 데이터 레이크로 원활하게 마이그레이션하여 기업이 데이터 프로세스를 가속화하고 효율성과 수익을 향상시키는 데 도움이 되는 iQiyi의 기술 솔루션을 소개합니다.
01
하이브 VS 아이스버그
Hive는 복잡한 데이터 처리 및 분석을 지원하기 위해 SQL과 유사한 언어를 제공하는 Hadoop 기반 데이터 웨어하우스 및 분석 플랫폼입니다.
Iceberg는 분석 워크로드를 지원하기 위해 확장 가능하고 안정적이며 효율적인 테이블 스토리지를 제공하도록 설계된 오픈 소스 데이터 테이블 형식입니다. Iceberg는 기존 데이터베이스와 유사한 트랜잭션 보장 및 데이터 일관성을 제공하며 업데이트, 삭제 등과 같은 복잡한 데이터 작업을 지원합니다.
표 1-1에는 적시성, 쿼리 성능 등의 측면에서 Hive와 Iceberg의 비교가 나열되어 있습니다.
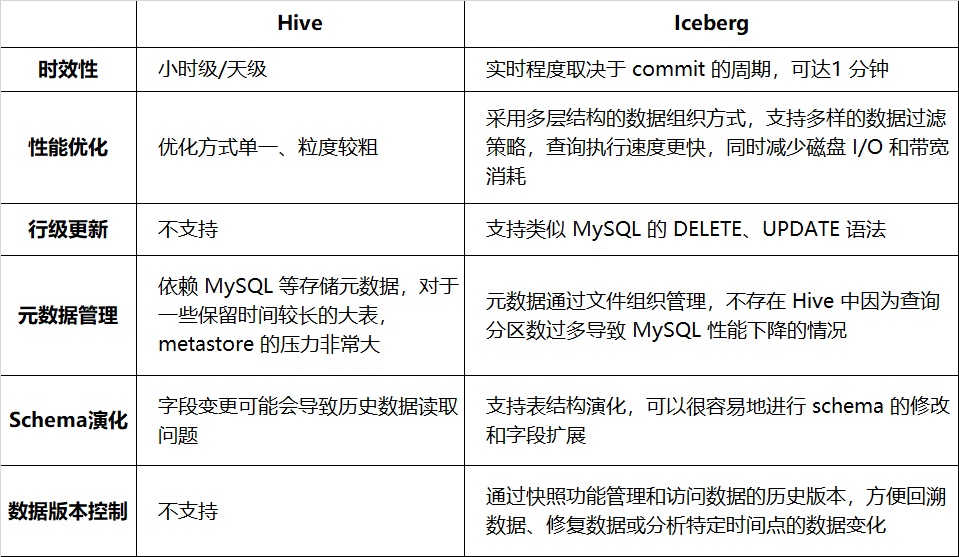
표 1-1 Hive와 Iceberg의 비교
Iceberg로 전환하면 데이터 처리의 효율성과 신뢰성이 향상되고 복잡한 데이터 작업에 대한 더 나은 지원을 제공할 수 있습니다. 현재 광고, 멤버십, Venus 로그, 감사 등 12개 이상의 비즈니스에 연결되어 있습니다. iQiyi의 Iceberg 사례에 대한 자세한 내용을 보려면 이전 기사 시리즈를 읽어보세요(기사 마지막에 있는 인용문 참조).
02
Hive 주식 데이터 원활한 전환 Iceberg
Iceberg는 Hive에 비해 많은 장점을 가지고 있지만 비즈니스 데이터는 이미 Hive 환경에서 실행되고 있으며 비즈니스는 인벤토리 작업 수정에 많은 인력을 투자하고 싶지 않습니다. 우리는 업계에서 일반적인 전환 방법을 조사했으며[1] 데이터 레이크 플랫폼에서 셀프 서비스 Hive와 Iceberg 사이를 원활하게 전환하는 기능을 제공했습니다. 이 섹션에서는 구체적인 구현 계획을 설명합니다.
1. 호환성 확인
실제 전환에 앞서 Spark의 Hive 및 Iceberg와의 호환성을 확인했습니다.
Hive 테이블과 Iceberg 테이블에 대한 Spark의 쿼리 및 쓰기 구문은 기본적으로 동일합니다. Hive 테이블 쿼리를 위한 SQL 문은 수정 없이 Iceberg 테이블을 쿼리할 수 있습니다.
그러나 DDL 측면에서 Iceberg와 Hive는 큰 차이가 있는데, 주로 테이블 구조를 수정하는 방식에서 자세한 내용은 표 2-1과 같다. 실제 스키마와 데이터 파일의 스키마 사이에는 일대일 대응이 있어야 하며, 그렇지 않으면 데이터 쿼리에 영향을 미치므로 DDL 문을 처리할 때 더 주의해야 합니다. 작업이 포함된 DDL 문입니다.
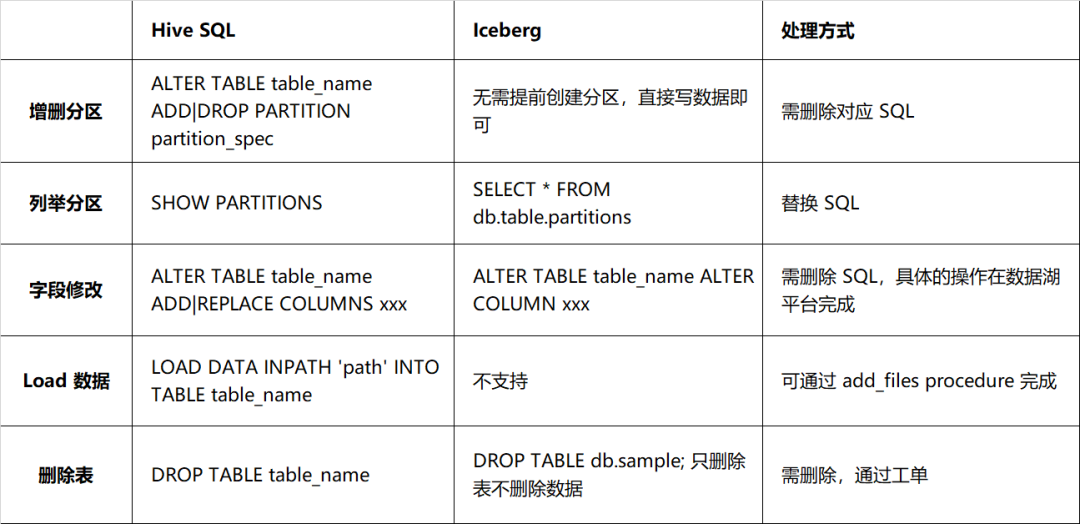
표 2-1 Hive와 Iceberg의 구문 호환성 비교
2. 산업 전환 솔루션
2.1 비즈니스 이중 쓰기 전환
비즈니스는 Hive와 Iceberg의 이중 쓰기를 구현하기 위해 기존 파이프라인을 복제합니다. 이전 채널과 새 채널 쌍이 일치하면 Iceberg 채널로 전환하고 원래 채널에서 로그오프합니다. 이 솔루션을 사용하려면 기업이 개발 및 계산에 인력을 투자해야 하는데, 이는 시간이 많이 걸리고 노동 집약적입니다.
2.2 스위치가 제자리에 있으면 클라이언트가 쓰기를 중지합니다.
기업이 일정 기간 동안 글쓰기를 중단하고 전환하는 것이 허용되는 경우 다음 방법을 사용할 수 있습니다.
-
Spark 마이그레이션 절차 는 Iceberg에서 공식적으로 제공하는 기능으로, Hive 테이블을 Iceberg로 전환할 수 있습니다. 예시는 다음과 같습니다.
CALL Catalog_name.system. migration('db.sample'); |
이 프로그램은 원본 데이터를 수정하지 않고 원본 테이블의 데이터만 스캔한 다음 원본 파일을 참조하여 Iceberg 메타정보를 구성합니다. 따라서 마이그레이션 프로그램은 매우 빠르게 실행되지만 기존 데이터는 파일 인덱스와 같은 기능을 사용하여 쿼리 속도를 높일 수 없습니다. 기존 데이터도 가속화하려면 Spark의 rewrite_data_files 메서드를 사용하여 기록 데이터를 다시 쓸 수 있습니다.
마이그레이션 프로그램은 Hive 테이블을 삭제하지 않지만 이름을 Sample__BACKUP__으로 바꿉니다. 여기서 __BACKUP__ 접미사는 하드 코딩되어 있습니다. 롤백해야 하는 경우 새로 생성된 Iceberg 테이블을 삭제하고 Hive 테이블의 이름을 다시 바꿀 수 있습니다.
-
CTAS 문을 사용하는 Spark 예시는 다음과 같습니다.
CREATE TABLE db.sample_iceberg 빙산 사용 dt로 분할됨 위치 'qbfs://....' TBLPROPERTIES('write.target-file-size-bytes' = '512m', ...) AS SELECT * FROM db.sample; |
쓰기가 완료된 후, 요구 사항이 충족되면 이름 변경으로 전환이 완료됩니다.
ALTER TABLE db.sample RENAME TO db.sample_backup; ALTER TABLE db.sample_iceberg RENAME TO db.sample; |
마이그레이션에 비해 CTAS의 장점은 기존 데이터를 다시 작성하므로 파티셔닝, 열 정렬, 파일 형식, 작은 파일 등을 최적화할 수 있다는 것입니다. 단점은 기존 데이터가 많은 경우 다시 작성하는 데 시간이 많이 걸리고 리소스 집약적이라는 점입니다.
위의 두 가지 솔루션은 다음과 같은 특징을 가지고 있습니다.
이점:
해결책은 간단합니다. 기존 SQL을 실행하면 됩니다.
롤백 가능, 원래 Hive 테이블은 그대로 유지됨
결점:
쓰기/리더가 검증되지 않음: Iceberg 테이블로 전환한 후 쓰기 또는 쿼리 예외가 발생할 수 있습니다.
쓰기를 중지하기 위해 전환 프로세스를 요구하는 것은 일부 기업에서는 허용되지 않습니다.
3. iQiyi 원활한 마이그레이션 계획
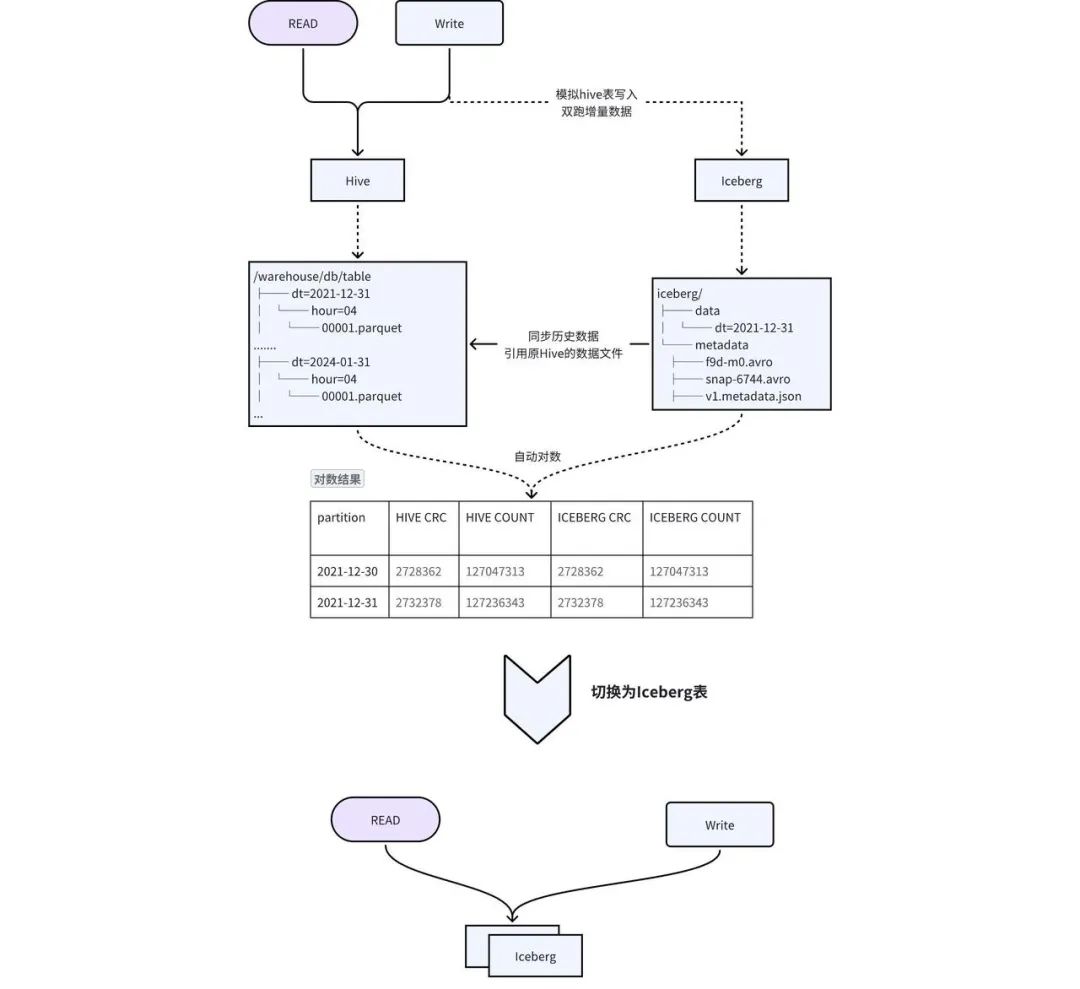
위 솔루션의 단점을 고려하여 그림 2-1과 같이 원활한 마이그레이션을 달성하기 위해 이중 쓰기 및 투명 스위칭 솔루션을 설계했습니다.
-
테이블 생성 : Hive와 동일한 스키마로 Iceberg 테이블을 생성하고, Hive 테이블의 TTL, 권한 등의 메타 정보를 Iceberg 테이블에 동기화합니다. -
기록 데이터를 Iceberg 로 마이그레이션 : Hive 기록 데이터는 add_file 프로시저를 통해 Iceberg에 추가됩니다 . 실제로 Iceberg의 메타데이터는 Hive의 데이터 파일을 가리키므로 데이터 중복성과 기록 데이터 동기화 시간이 줄어듭니다. -
증분 데이터 이중 쓰기 : iQIYI가 자체 개발한 파일럿 SQL 게이트웨이는 Hive 테이블의 쓰기 작업을 감지하고 자동으로 SQL을 복사 및 쓰기하며 출력을 Iceberg 테이블로 대체하여 이중 쓰기를 구현합니다. -
数据一致性 校验: 当历史数据同步完成且增量双写到一定次数之后,后台会自动发起对数,校验 Hive 和 Iceberg 中的数据是否一致。对于历史数据与增量数据会选取一部分数据进行 count 以及字段 CRC 数值校验。 -
切换 : 数据一致性校验完成后,进行 Hive 和 Iceberg 的切换,用户不需要修改任务,直接使用原来的表名进行访问即可。正常切换过程耗时在几分钟之内。
03
核心收益 - 加速查询
1. Iceberg 查询加速技术
2. Iceberg 加速技巧
-
配置分区:使用分区剪裁的方式使查询只针对特定分区的数据执行,而不需要扫描整个数据集。 -
指定排序列:通过对数据分布进行合理的组织,最大限度的发挥文件级别的过滤效果,使得查询只集中在特定的文件。例如通过下面的方式使得写入 sample 表的数据按照 category, id 降序写入,注意由于多了一个排序的环节,这种方式会比非排序的写入耗时长。
|
|
-
高基数列应用布隆过滤器:在查询数据时,会自动应用布隆过滤器来快速验证查询数据是否存在于某个数据块,避免不必要的磁盘访问。
|
|
-
使用 Trino 代替 Spark:由于 Trino 自身 MPP 的架构,在查询上相较于 Spark 更有优势,并且 Trino 自身对 Iceberg 也有相应的优化,因此如果有秒级查询的需求,可将引擎由 Spark 切换到 Trino。 -
Alluxio 缓存:使用 Alluxio 作为数据缓存层,将数据缓存在内存中。在查询时可以直接从内存中获取数据,避免从磁盘读取数据的开销,可大大提高查询速度,也可防止 HDFS 抖动对任务的影响。 -
ORC 代替 Parquet:由于 Trino 对 ORC 格式有特定的优化,使得 ORC 的读取性能要优于 Parquet,可以将文件格式设置为 ORC 加速查询。 -
配置合并:写 Iceberg 的任务往往会出现写入文件较小但数量较多的情况,通过将小文件合并成一个或少量更大的文件,有利于减少读取的文件数,降低磁盘 I/O。
3. 性能评测
3.1 文件内过滤性能提升
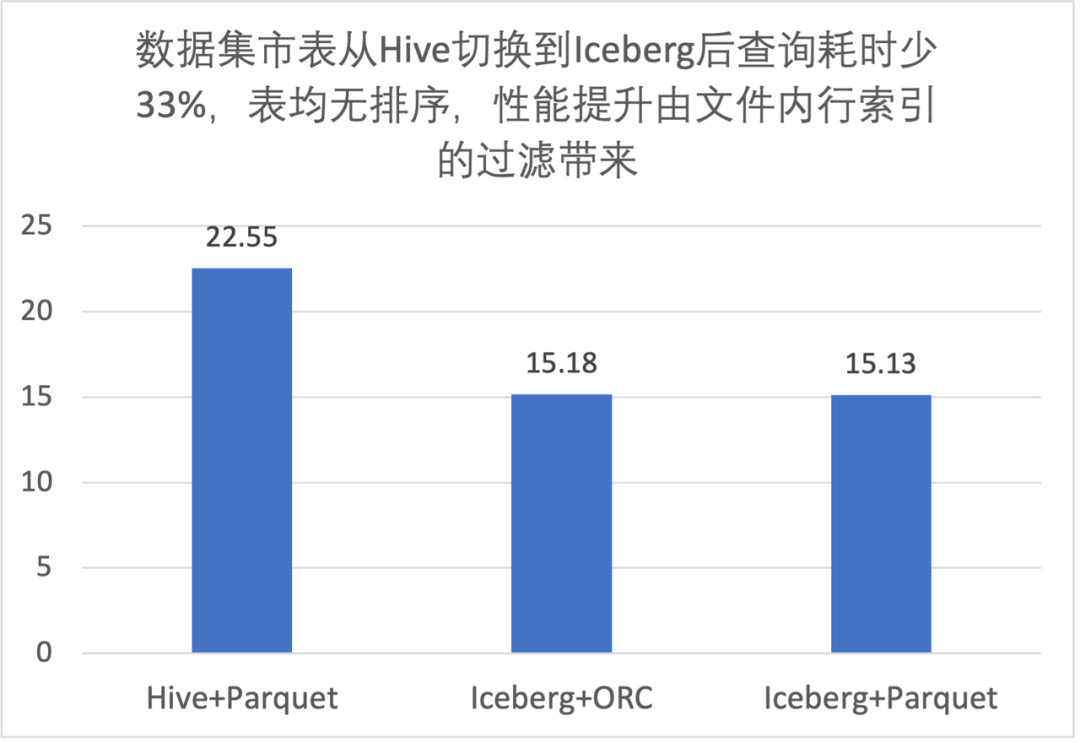
3.2 列排序对文件内过滤性能提升
-
同样的文件格式,排序后文件内过滤效果更好,大致能快 40%; -
ORC 查询性能优于 Parquet; -
使用 Trino 查询,我们推荐 Iceberg 表 + ORC 文件格式 + 列排序;
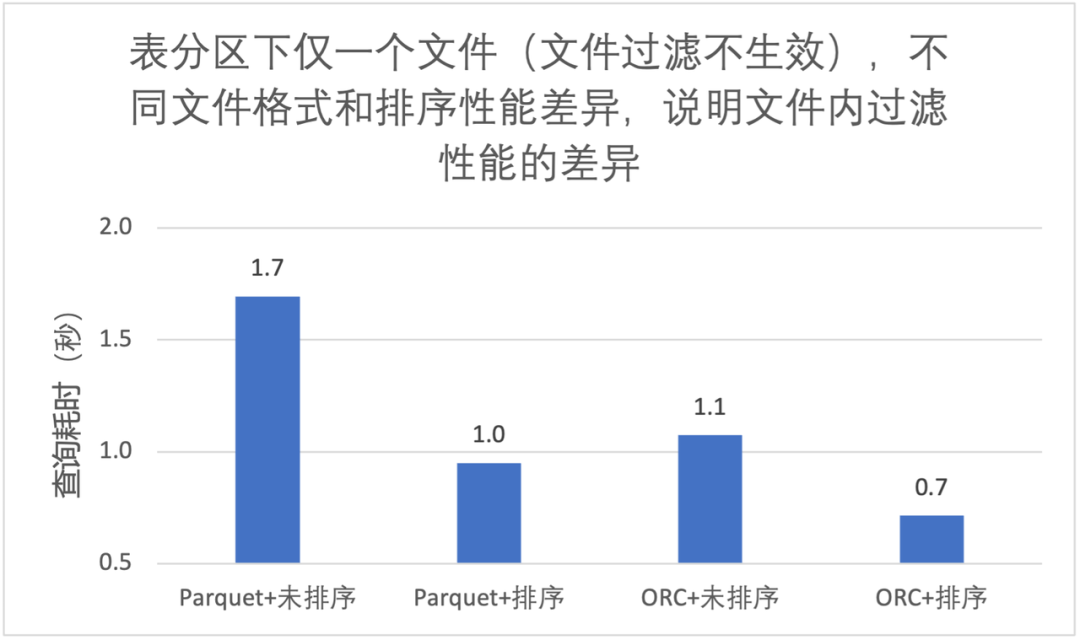
3.3 列排序对文件级过滤性能提升
|
|
-
按照 prov 排序查询读取数据量是不排序的 25%,耗时是 66%; -
按照 isp 排序提升不明显,这是因为 isp 数据量有明显的倾斜,条件中 isp 值占比高达 90%;
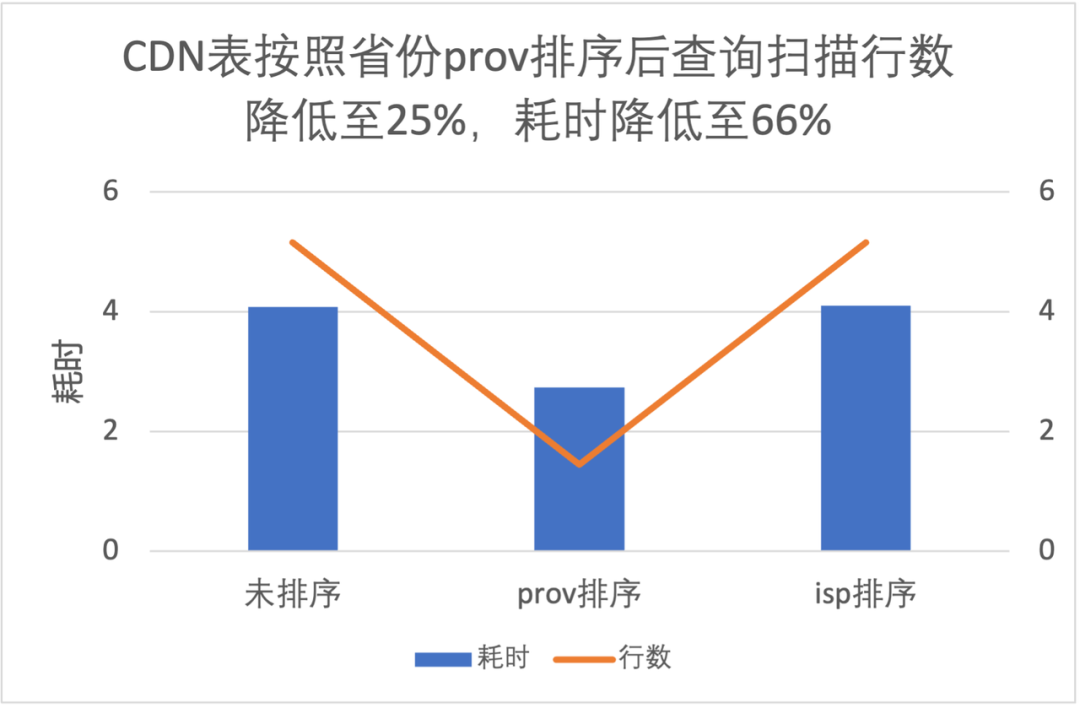
3.4 布隆过滤器的性能提升
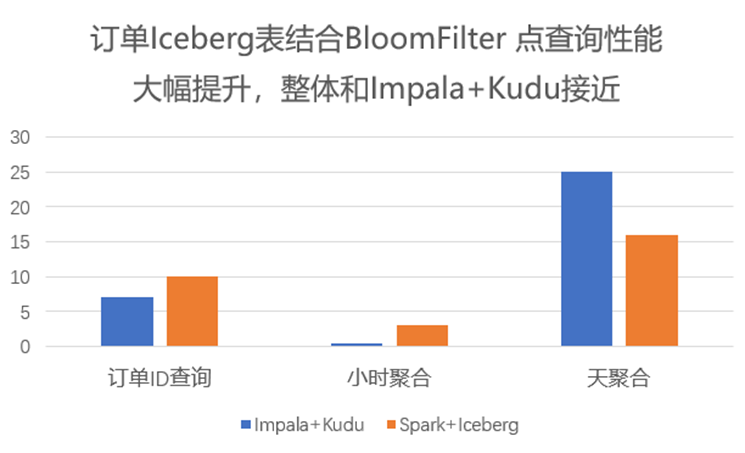
3.5 Spark 和 Trino 性能比较
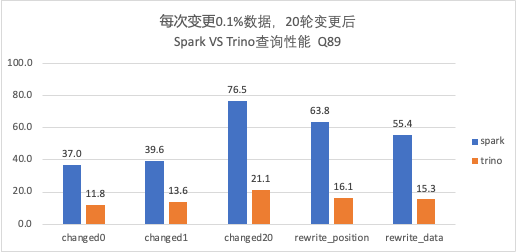
-
Trino 对于 V2 表查询结果与 Spark 一致,且在相同核数性能优于 Spark,耗时是 Spark 的 1/3 左右; -
随着变更轮次的增加(Data File 和 Postition Delete File 数量增加),Trino 查询性能也会逐渐变慢,需要定期进行合并。
04
核心收益 - 支持变更
1. 变更在业务使用场景
-
ETL 计算:如广告计费,通过接入 Iceberg 实现变更,简化业务逻辑,实现了更长时间范围的转化回收; -
数据修正:批量修正,如对某个数据的状态进行修改、批量删除等; -
隐私相关:如播放记录、搜索记录,用户需要删除历史条目等; -
CDC 同步:如订单业务,需要将 MySQL 中的数据进行大数据分析,通过 Flink CDC 技术很方便地将 MySQL 数据入湖,实时性可达到分钟级。
2. Hive 如何实现变更
-
分区覆写 例如修改某个 id 的相关内容,先筛选出要修改的目标行,更新后与历史数据进行合并,最后覆盖原表。这种方式对不需要修改的数据进行了重写,浪费计算资源;且覆写的粒度最小是分区级别,数据无法进一步细分,任务耗时相对较长。 -
标记删除 通常的做法是添加标志位,数据初始写入时标志位置 0,需要删除时,插入相同的数据,且标志位置 1,查询时过滤掉标志位为 1 的数据即可。这种方式在语义上未实现真正的删除,历史数据仍然保存在 Hive 中,浪费空间,而且查询语句较为复杂。
3. Iceberg 支持的变更类型
-
Delete:删除符合指定条件的数据,例如
|
|
-
Update:更新指定范围的数据,例如
|
|
-
MERGE:若数据已存在 UPDATE,不存在执行 INSERT,例如
|
|
4. Iceberg 变更策略
-
Copy on Write(写时合并):当进行删除或更新特定行时,包含这些行的数据文件将被重写。写入耗时取决于重写的数据文件数量,频繁变更会面临写放大问题。如果更新数据分布在大量不同的文件,那么更新的执行速度比较慢。这种方式由于结果文件数较少,读取的速度会比较快,适合频繁读取、低频批次更新的场景。 -
Merge on Read(读时合并):文件不会被重写,而是将更改写入新文件,当读取数据时,将新文件合并到原始数据文件得到最终结果。这使得写入速度更快,但读取数据时必须完成更多工作。写入新文件有两种方式,分别是记录删除某个文件对应的行(position delete)、记录删除的数据(equality detete)。 -
Position Delete:当前 Spark 的实现方式,记录变更对应的文件及行位置。这种方式不需要重写整个数据文件,只需找到对应数据的文件位置并记录,减少了写入的延迟,读取时合并的代价较小。 -
Equality Delete:当前 Flink 的实现方式,记录了删除数据行的主键。这种方式要求表必须有唯一的主键,写入过程无需查询数据文件,延迟最低;然而它的读取代价最大,这是由于读取时需要将 equality delete 记录和所有的原始文件进行 JOIN。
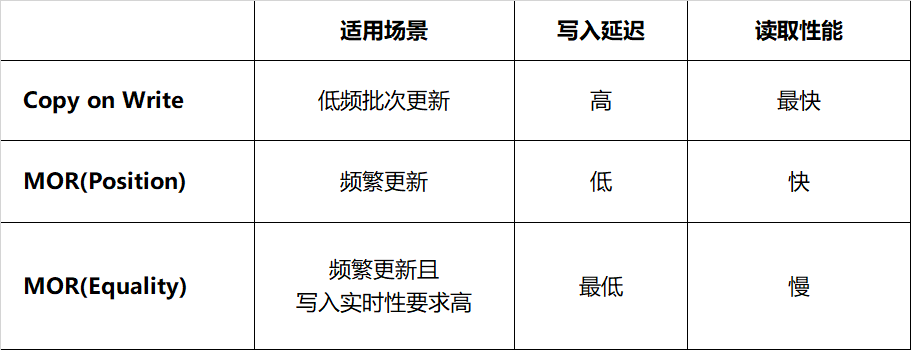 表 4-1 Iceberg 不同变更策略对比
表 4-1 Iceberg 不同变更策略对比
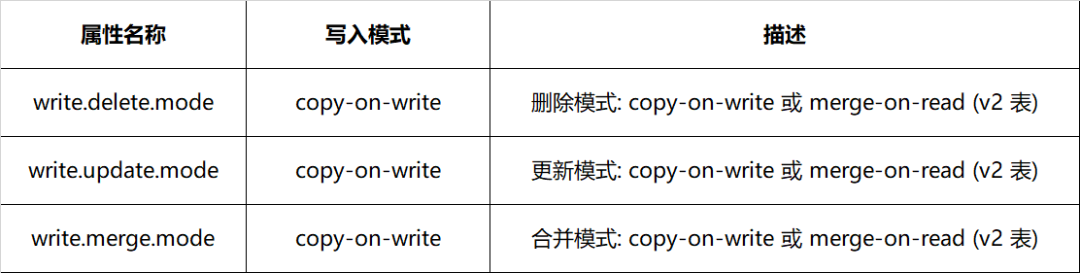 表 4-2 Iceberg 变更属性配置方式
表 4-2 Iceberg 变更属性配置方式
5. 业务接入
5.1 广告计费转换
-
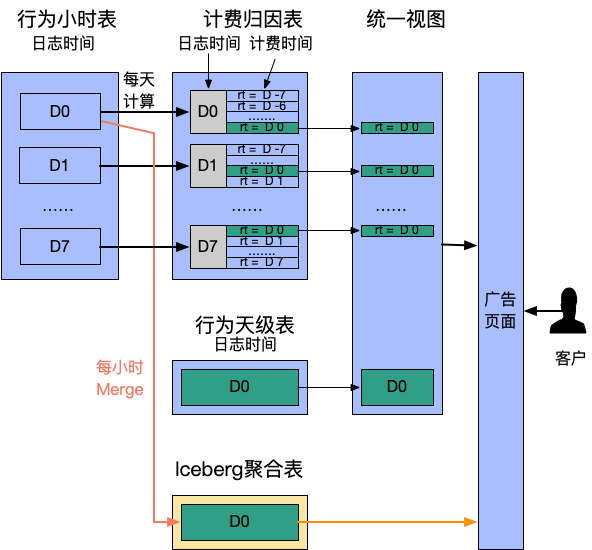
每天触发一次计算,从行为表聚合出过去 7 天的“计费时间”数据。此处用 rt 字段代表计费时间 -
提供统一视图合并行为数据和计费时间数据,计费归因表 rt as dt 作为分区过滤查询条件,满足同时检索曝光和计费转化的需求
|
|
-
时效性提升:从天级缩短到小时级,客户更实时观察成本,有利于预算引入; -
计算更长周期数据:原先为计算效率仅提供 7 日内转换,而真实场景转换周期可能超过 1 个月; -
表语义清晰:多表联合变为单表查询。
5.2 数据修正
|
|
05
总结
06
引用
-
From Hive Tables to Iceberg Tables: Hassle-Free -
通过数据组织优化加速基于Apache Iceberg的大规模数据分析 -
Row-Level Changes on the Lakehouse: Copy-On-Write vs. Merge-On-Read in Apache Iceberg -
《爱奇艺数据湖实战 - 综述》 -
《爱奇艺数据湖实战 - 广告》 -
《爱奇艺数据湖实战 - 基于数据湖的日志平台架构演进》 -
《爱奇艺数据湖实战 - 数据湖技术在爱奇艺BI场景的应用》 -
《爱奇艺在Iceberg落地相关性能优化与实践》

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。