
01
배경
02
비너스 로그 플랫폼 소개
Venus는 iQiyi가 개발한 로그 서비스 플랫폼으로 로그 수집, 처리, 저장, 분석 및 기타 기능을 제공합니다. 이는 주로 회사 내에서 로그 문제 해결, 빅 데이터 분석, 모니터링 및 경고에 사용됩니다. 1. 표시됩니다.
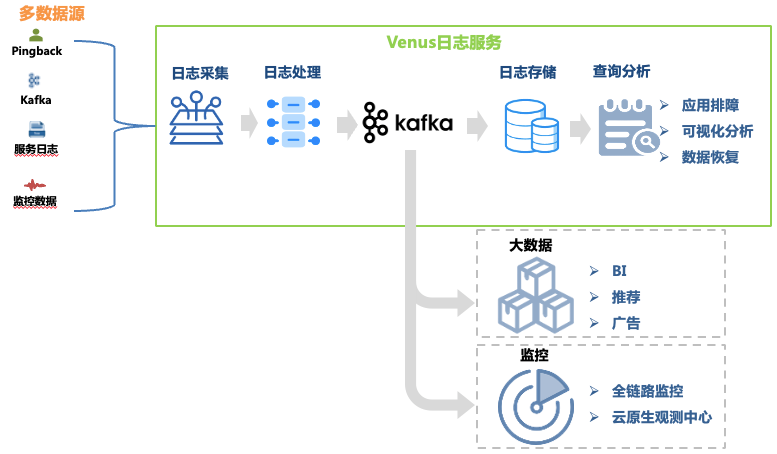 그림 1 금성 링크
그림 1 금성 링크
이 문서에서는 로그 문제 해결 링크의 아키텍처 발전에 중점을 두고 있습니다. 해당 데이터 링크는 다음과 같습니다.
로그 수집 : 머신 및 컨테이너 호스트에 수집 에이전트를 배포하여 각 사업 분야의 프런트엔드, 백엔드, 모니터링 및 기타 소스로부터의 로그를 수집하고, 형식 요구 사항에 맞는 로그를 자체적으로 전달하도록 비즈니스도 지원합니다. . Kafka, MySQL, K8s 및 게이트웨이와 같은 10개의 데이터 소스를 지원하는 30,000개 이상의 에이전트가 배포되었습니다.
로그 처리 : 로그 수집 후 일반 추출, 내장 파서 추출 등 표준화된 처리를 거쳐 JSON 형식으로 Kafka에 일률적으로 작성된 후, 덤프 프로그램에 의해 스토리지 시스템에 작성됩니다.
로그 저장소 : Venus는 약 10,000개의 비즈니스 로그 스트림을 저장하며 최대 쓰기 QPS는 1,000만 QPS가 넘고 일일 새 로그는 500TB를 초과합니다. 스토리지 규모가 변화함에 따라 스토리지 시스템 선택도 ElasticSearch에서 데이터 레이크로 많은 변화를 겪었습니다.
쿼리 분석 : Venus는 시각적 쿼리 분석, 상황별 쿼리, 로그 디스크, 패턴 인식, 로그 다운로드 등의 기능을 제공합니다.
대용량 로그 데이터의 저장 및 신속한 분석을 충족하기 위해 Venus 로그 플랫폼은 세 가지 주요 아키텍처 업그레이드를 거쳐 클래식 ELK 아키텍처에서 데이터 레이크 기반 자체 개발 시스템으로 점차 발전했습니다. 이 기사에서는 직면한 문제를 소개합니다. 금성 아키텍처 및 솔루션의 변화 중.
03
Venus 1.0: ELK 아키텍처 기반
Venus 1.0은 2015년에 시작되었으며 그림 2와 같이 당시 인기가 있었던 ElasticSearch+Kibana를 기반으로 구축되었습니다. ElasticSearch는 로그 저장 및 분석 기능을 담당하며, Kibana는 Kafka를 사용하고 ElasticSearch에 로그를 작성하기만 하면 로그 서비스를 제공할 수 있습니다.
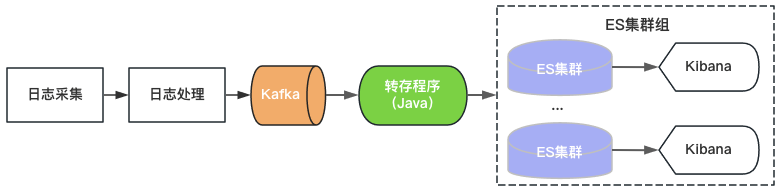 그림 2 Venus 1.0 아키텍처
그림 2 Venus 1.0 아키텍처
단일 ElasticSearch 클러스터의 처리량, 저장 용량 및 인덱스 샤드 수에는 상한이 있으므로 Venus는 증가하는 로그 수요에 대처하기 위해 계속해서 새로운 ElasticSearch 클러스터를 추가하고 있습니다. 비용을 조절하기 위해 각 ElasticSearch의 부하를 높게 하고, 인덱스는 0개로 구성합니다. 갑작스러운 트래픽 쓰기, 대용량 데이터 쿼리, 클러스터 사용 불가로 이어지는 시스템 장애 등의 문제가 자주 발생합니다. 동시에 클러스터의 인덱스 수가 많고 데이터 양이 많고 복구 시간이 길기 때문에 오랫동안 로그를 사용할 수 없으며 Venus 사용 경험이 점점 더 악화됩니다.
04
Venus 2.0: ElasticSearch + Hive 기반
클러스터 분류: ElasticSearch 클러스터는 고품질과 저품질의 두 가지 범주로 나뉩니다. 주요 기업은 고품질 클러스터를 사용하고, 클러스터의 로드는 낮은 수준으로 제어되며, 인덱스는 1-복사 구성으로 활성화되어 단일 노드 장애를 허용합니다. 높은 수준에서 제어되며 인덱스는 여전히 0-복사본 구성을 사용합니다.
스토리지 분류: 장기 스토리지 로그를 위해 ElasticSearch 및 Hive를 이중 쓰기합니다. ElasticSearch는 최근 7일 동안의 로그를 저장하고, Hive는 더 오랜 기간 동안 로그를 저장하므로 ElasticSearch의 스토리지 부담이 줄어들고 대용량 데이터 쿼리로 인해 ElasticSearch가 중단될 위험도 줄어듭니다. 그러나 Hive는 대화형 쿼리를 수행할 수 없기 때문에 Hive의 로그는 오프라인 컴퓨팅 플랫폼을 통해 쿼리해야 하므로 쿼리 환경이 좋지 않습니다.
통합 쿼리 포털: Kibana와 유사한 통합된 시각적 쿼리 및 분석 포털을 제공하여 기본 ElasticSearch 클러스터를 보호합니다. 클러스터에 장애가 발생하면 새 로그의 쿼리 및 분석에 영향을 주지 않고 새로 작성된 로그가 다른 클러스터에 예약됩니다. 클러스터 로드가 불균형할 때 클러스터 간 트래픽을 투명하게 예약합니다.
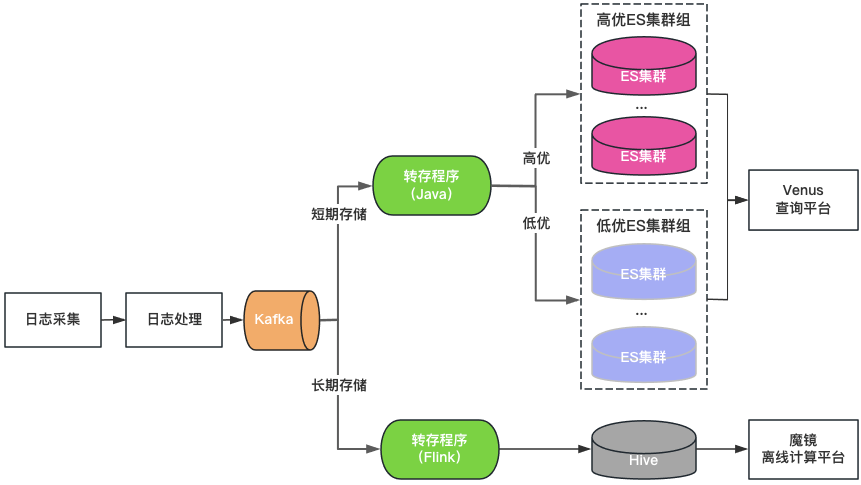
그림 3 Venus 2.0 아키텍처
Venus 2.0은 주요 비즈니스를 보호하고 장애로 인한 위험과 영향을 줄이기 위한 절충 솔루션이지만 여전히 높은 비용과 열악한 안정성이라는 문제를 안고 있습니다.
ElasticSearch는 저장 시간이 짧습니다. 로그 양이 많기 때문에 ElasticSearch는 7일만 저장할 수 있어 일상적인 비즈니스 요구를 충족할 수 없습니다.
입구가 많고 데이터 단편화가 많습니다. ElasticSearch 클러스터 20개 이상 + Hive 클러스터 1개, 쿼리 입구가 많아 쿼리 및 관리가 매우 불편합니다.
높은 비용: ElasticSearch는 7일 동안만 로그를 저장하지만 여전히 500대 이상의 시스템을 사용합니다.
통합 읽기 및 쓰기: ElasticSearch 서버는 동시에 읽고 쓰기를 담당하며 서로 영향을 미칩니다.
많은 결함: ElasticSearch 결함은 Venus 전체 결함의 80%를 차지합니다. 결함이 발생한 후에는 읽기 및 쓰기가 차단되고 로그가 쉽게 손실되며 처리가 어렵습니다.
05
Venus 3.0: 데이터 레이크 기반의 새로운 아키텍처
데이터 레이크 도입을 고려 중
비너스의 로그 시나리오를 심층적으로 분석한 후 그 특징을 정리하면 다음과 같습니다.
대용량 데이터 : 1,000만 QPS의 최대 쓰기 용량과 PB급 데이터 저장 공간을 갖춘 약 10,000개의 비즈니스 로그 스트림.
더 많이 쓰고 덜 확인하십시오 . 비즈니스에서는 일반적으로 문제 해결이 필요할 때만 로그를 쿼리합니다. 대부분의 로그에는 하루 이내에 쿼리 요구 사항이 없으며 전체 쿼리 QPS도 매우 낮습니다.
대화형 쿼리 : 로그는 여러 개의 연속 쿼리가 필요하고 두 번째 수준의 대화형 쿼리 환경이 필요한 긴급 시나리오 문제를 해결하는 데 주로 사용됩니다.
ElasticSearch를 사용하여 로그를 저장하고 분석할 때 발생하는 문제와 관련하여 다음과 같은 이유로 Venus 로그 시나리오와 완전히 일치하지 않는다고 생각합니다.
단일 클러스터는 쓰기 QPS와 스토리지 규모가 제한되어 있으므로 여러 클러스터가 트래픽을 공유해야 합니다. 클러스터 크기, 쓰기 트래픽, 저장 공간, 인덱스 수 등 복잡한 스케줄링 전략 문제를 고려해야 하므로 관리의 어려움이 가중됩니다. 비즈니스 로그 트래픽은 매우 다양하고 예측할 수 없기 때문에 갑작스러운 트래픽이 클러스터 안정성에 미치는 영향을 해결하려면 더 많은 유휴 리소스를 예약해야 하므로 클러스터 리소스가 크게 낭비되는 경우가 많습니다.
쓰기 중 전체 텍스트 인덱싱은 많은 CPU를 소비하므로 데이터가 확장되고 컴퓨팅 및 저장 비용이 크게 증가합니다. 많은 시나리오에서 분석 로그를 저장하려면 백그라운드 서비스 리소스보다 더 많은 리소스가 필요합니다. 쓰기가 많고 쿼리가 적은 로그와 같은 시나리오의 경우 전체 텍스트 인덱스를 미리 계산하는 것이 더 고급스럽습니다.
스토리지 데이터와 계산이 동일한 시스템에 있습니다. 대용량 데이터 볼륨 쿼리 또는 집계 분석은 쓰기에 쉽게 영향을 미쳐 쓰기 지연 또는 클러스터 오류를 유발할 수 있습니다.
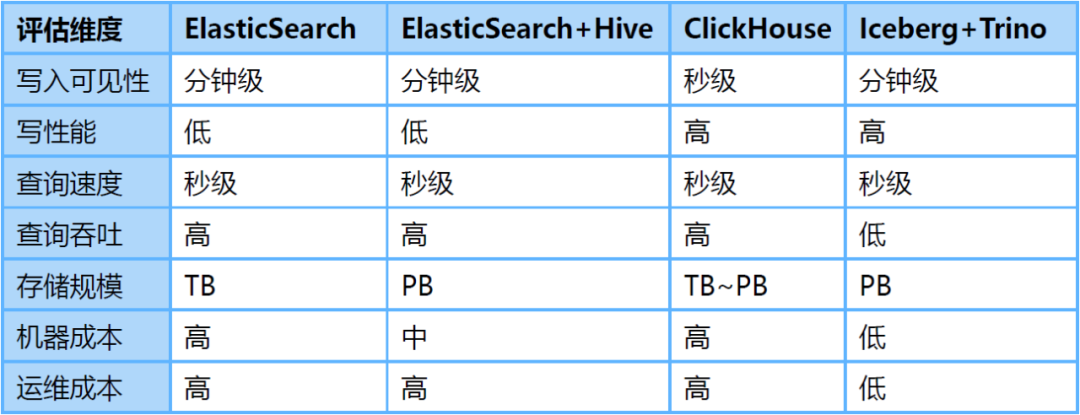
为了解决上述问题,我们调研了ClickHouse、Iceberg数据湖等替代方案。其中,Iceberg是爱奇艺内部选择的数据湖技术,是一种存储在HDFS或对象存储之上的表结构,支持分钟级的写入可见性及海量数据的存储。Iceberg对接Trino查询引擎,可以支持秒级的交互式查询,满足日志的查询分析需求。
针对海量日志场景,我们对ElasticSearch、ElasticSearch+Hive、ClickHouse、Iceberg+Trino等方案做了对比评估:
-
存储空间大:Iceberg底层数据存储在大数据统一的存储底座HDFS上,意味着可以使用大数据的超大存储空间,不需要再通过多个集群分担存储,降低了存储的维护代价。 -
存储成本低:日志写入到Iceberg不做全文索引等预处理,同时开启压缩。HDFS开启三副本相比于ElasticSearch的三副本存储空间降低近90%,相比ElasticSearch的单副本存储空间仍然降低30%。同时,日志存储可以与大数据业务共用HDFS空间,进一步降低存储成本。 -
计算成本低:对于日志这种写多查少的场景,相比于ElasticSearch存储前做全文索引等预处理,按查询触发计算更能有效利用算力。 -
存算隔离:Iceberg存储数据,Trino分析数据的存算分离架构天然的解决了查询分析对写入的影响。
基于数据湖架构的建设
通过上述评估,我们基于Iceberg和Trino构建了Venus 3.0。采集到Kafka中的日志由转存程序写入Iceberg数据湖。Venus查询平台通过Trino引擎查询分析数据湖中的日志。架构如图4所示。
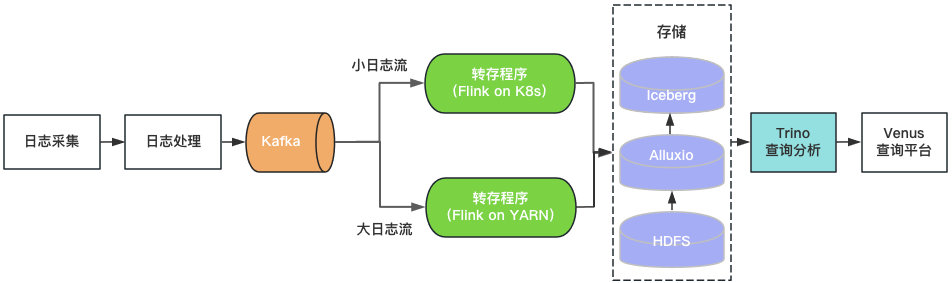 图4 Venus 3.0架构
图4 Venus 3.0架构
-
日志存储
-
查询分析
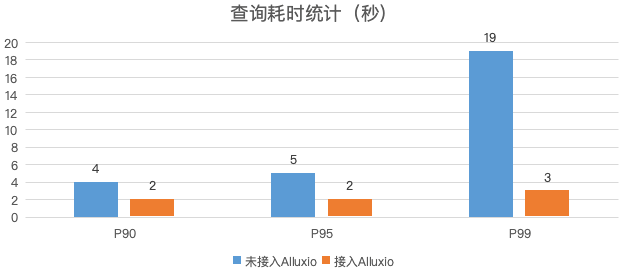
图5 日志查询性能对比
-
转存程序
-
落地效果
-
存储空间 :日志的物理存储空间降低30%,考虑到ElasticSearch集群的磁盘存储空间利用率较低,实际存储空间降低50%以上。 -
计算资源 :Trino使用的CPU核数相比于ElasticSearch减少80%,转存程序资源消耗降低70%。 -
稳定性提升:迁移到数据湖后,故障数降低了85%,大幅节省运维人力。
06
总结与规划
-
Iceberg+Trino的数据湖架构支持的查询并发较低,我们将尝试使用Bloomfilter、Zorder等轻量级索引提升查询性能,提高查询并发,满足更多的实时分析的需求。 -
目前Venus存储了近万个业务日志流,日新增日志超过500TB。计划引入基于数据热度的日志生命周期管理机制,及时下线不再使用的日志,进一步节省资源。 -
如图1所示,Venus同时也承载了大数据分析链路的Pingback用户数据的采集与处理,该链路与日志数据链路比较类似,参考日志入湖经验,我们对Pingback数据的处理环节进行基于数据湖的流批一体化改造。目前已完成一期开发与上线,应用于直播监控、QOS、DWD湖仓等场景,后续将继续推广至更多的湖仓场景。详细技术细节将在后续的数据湖系列文章中介绍。

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。