
01
뒤쪽에장면그리고 현 상태
1. 광고분야 데이터의 특성
광고 분야의 데이터 는 연속 가치 특성과 이산 가치 특성으로 나눌 수 있습니다. AI 이미지, 영상, 음성 등 기타 분야와 달리 광고 분야 대부분 사용자 ID, 광고 ID, 사용자와 상호작용하는 광고 ID 시퀀스 등 ID 형식으로 제시되며, 규모가 커서 광고 분야를 형성합니다. 고차원 희소 데이터의 독특한 특성.
-
사용자의 연령과 같은 정적 특성과 특정 업계에서 사용자가 광고를 클릭하는 횟수와 같은 사용자 행동에 따른 동적 특성이 모두 있습니다 -
장점은 일반화 능력이 좋다는 것이다. 특정 산업에 대한 사용자의 선호도는 해당 산업과 동일한 통계적 특성을 가진 다른 사용자에게 일반화될 수 있습니다. -
단점은 기억력이 부족하여 변별력이 낮다는 것입니다. 예를 들어 동일한 통계적 특성을 가진 두 사용자의 행동이 크게 다를 수 있습니다. 또한 연속 가치 특성에는 수동 특성 엔지니어링도 많이 필요합니다.
-
이산 가치 특성은 세분화된 특성입니다. 열거 가능한 것(예: 사용자 성별, 산업 ID)이 있고 고차원적인 것(예: 사용자 ID, 광고 ID)도 있습니다. -
장점은 기억력이 강하고 식별력이 높다는 점이다. 이산 가치 기능을 결합하여 교차 및 협업 정보를 학습할 수도 있습니다. -
단점은 일반화 능력이 상대적으로 약하다는 점이다.
-
원-핫 인코딩 -
특징 임베딩(Embedding)
-
기능 충돌: vocabulary_size를 너무 크게 설정하면 훈련 효율성이 급격히 떨어지며 메모리 OOM으로 인해 훈련이 실패합니다. 따라서 10억 수준의 사용자 ID 이산 값 기능에 대해서도 100,000 수준의 ID 해시 공간만 설정합니다. 해시 충돌률이 높고 기능 정보가 손상되어 오프라인 평가에서 긍정적인 이점이 없습니다. -
비효율적인 IO: 사용자 ID 및 광고 ID와 같은 기능은 고차원적이고 희박합니다. 즉, 학습 중에 업데이트되는 매개변수는 전체의 작은 부분만을 차지하므로 TensorFlow의 원래 정적 임베딩 메커니즘에서는 모델 액세스를 처리해야 합니다. 전체 밀도가 높은 Tensor는 막대한 IO 오버헤드를 가져오고 희박한 대규모 모델의 교육을 지원할 수 없습니다.
02
광고 희소 대형 모델 실습
-
TFRA API는 Tensorflow 생태계와 호환됩니다(원래 최적화 프로그램 및 초기화 프로그램 재사용, API는 동일한 이름과 일관된 동작을 가짐). TensorFlow는 보다 기본적인 방식으로 ID 유형 희소 대형 모델의 훈련 및 추론을 지원할 수 있습니다. 학습 및 사용 비용이 낮으며 알고리즘 엔지니어 모델링 습관을 바꾸지 않습니다. -
동적 메모리 확장 및 축소는 훈련 중에 리소스를 절약하며 해시 충돌을 효과적으로 방지하고 기능 정보가 손실되지 않도록 보장합니다.
-
정적 임베딩이 동적 임베딩으로 업그레이드되었습니다. 이산 값 기능의 인공 해시 논리의 경우 TFRA 동적 임베딩을 사용하여 매개변수를 저장, 액세스 및 업데이트함으로써 모든 이산 값 기능의 임베딩이 알고리즘 프레임워크에서 충돌이 없도록 보장합니다. 모든 이산 값을 보장합니다. 무손실 기능 학습. -
고차원 희소 ID 기능 사용: 위에서 언급한 것처럼 TensorFlow의 정적 Embedding 기능을 사용할 때 사용자 ID 및 광고 ID 기능은 해시 충돌로 인해 오프라인 평가에서 이익이 없습니다. 알고리즘 프레임워크가 업그레이드된 후 사용자 ID와 광고 ID 기능이 다시 도입되며 오프라인과 온라인 모두에서 긍정적인 이점이 있습니다. -
고차원 희소 결합 ID 기능 사용: 사용자 ID와 산업 ID, 앱 패키지 이름을 각각 결합하는 등 사용자 ID와 광고 조잡한 ID의 결합된 이산 값 기능을 소개합니다. 동시에 기능 액세스 기능과 결합되어 더 희박한 사용자 ID와 광고 ID를 조합한 개별 기능이 도입됩니다.

2. 모델 업데이트
-
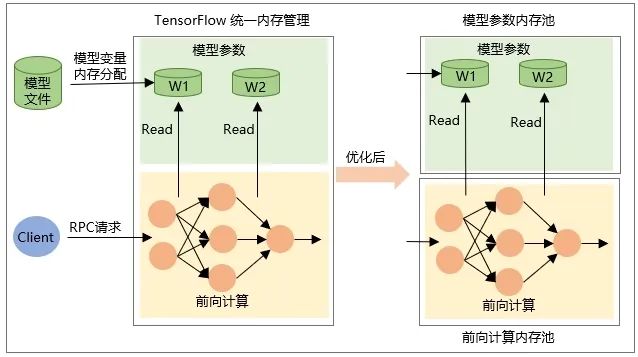
모델이 복원될 때 변수 자체의 Tensor 할당, 즉 모델이 로드될 때 메모리가 할당되고, 모델이 언로드될 때 메모리가 해제됩니다. -
중간 출력 Tensor의 메모리는 RPC 요청 중 네트워크 순방향 계산 중에 할당되고 요청 처리가 완료된 후 해제됩니다.
0삼
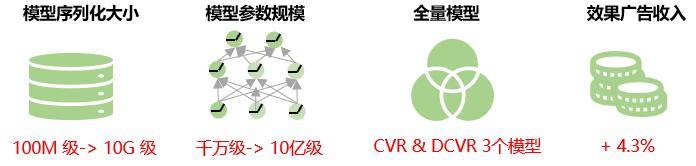
전반적인 이점
04
미래 전망
현재 대규모 광고 희소 모델의 동일한 특성에 대한 모든 특성 값에는 동일한 Embedding 차원이 부여됩니다. 실제 비즈니스에서는 고차원 특징의 데이터 분포가 극도로 고르지 않고, 매우 적은 수의 고주파 특징이 매우 높은 비율을 차지하며, 모든 특징 값에 대해 고정된 임베딩 차원을 사용하는 롱테일 현상이 심각합니다. Embedding 표현 학습 능력이 저하됩니다. 즉, 저주파 특성의 경우 Embedding 차원이 너무 크고, 고주파 특성의 경우 모델이 과적합될 위험이 있습니다. 왜냐하면 Embedding을 표현하고 학습해야 하는 정보가 많기 때문입니다. 차원이 너무 작아서 모델이 과소적합될 위험이 있습니다. 따라서 앞으로는 모델 예측의 정확도를 더욱 향상시키기 위해 Embedding 차원 특성을 적응적으로 학습하는 방법을 모색할 것입니다.
동시에 우리는 모델의 증분 내보내기 솔루션을 탐색할 것입니다. 즉, 증분 학습 중에 변경되는 매개변수만 TensorFlow Serving에 로드하여 모델 업데이트 중 네트워크 전송 및 로딩 시간을 줄이고 분 단위 업데이트를 달성합니다. 희소 대형 모델의 개선 및 모델의 실시간 특성 개선.

이 기사는 WeChat 공개 계정인 iQIYI 기술 제품 팀(iQIYI-TP)에서 공유되었습니다.
침해가 있는 경우 [email protected]에 연락하여 삭제를 요청하세요. 이 글은 " OSC 소스 생성 계획
" 에 참여하고 있습니다 . 이 글을 읽고 계신 여러분의 많은 참여와 공유 부탁드립니다.
{{o.이름}}
{{이름}}