iQiyi의 Apache Spark 현재 상태
Apache Spark는 iQiyi 빅 데이터 플랫폼에서 주로 사용되는 오프라인 컴퓨팅 프레임워크이며 데이터 처리, 데이터 동기화, 데이터 쿼리 분석 및 기타 시나리오를 위한 일부 스트림 컴퓨팅 작업을 지원합니다.
-
데이터 처리 : 데이터 개발 플랫폼은 개발자가 데이터 ETL 처리를 위해 Spark Jar 패키지 작업 또는 Spark SQL 작업을 제출할 수 있도록 지원합니다.
-
데이터 동기화
: iQIYI가 자체 개발한 BabelX 데이터 동기화 도구는 Spark 컴퓨팅 프레임워크를 기반으로 개발되었으며, Hive, MySQL, MongoDB 등 15개 데이터 소스 간의 데이터 교환을 지원하며, 여러 클라우드 간의 데이터 동기화를 지원합니다. 완전히 관리되는 데이터 동기화 작업이 구성되었습니다.
-
데이터 분석 : 데이터 분석가 및 운영 수강생은 Magic Mirror 임시 쿼리 플랫폼에서 SQL을 제출하거나 데이터 지표 쿼리를 구성하고, 쿼리 분석을 위해 Pilot 통합 SQL 게이트웨이를 통해 Spark SQL 서비스를 호출합니다.
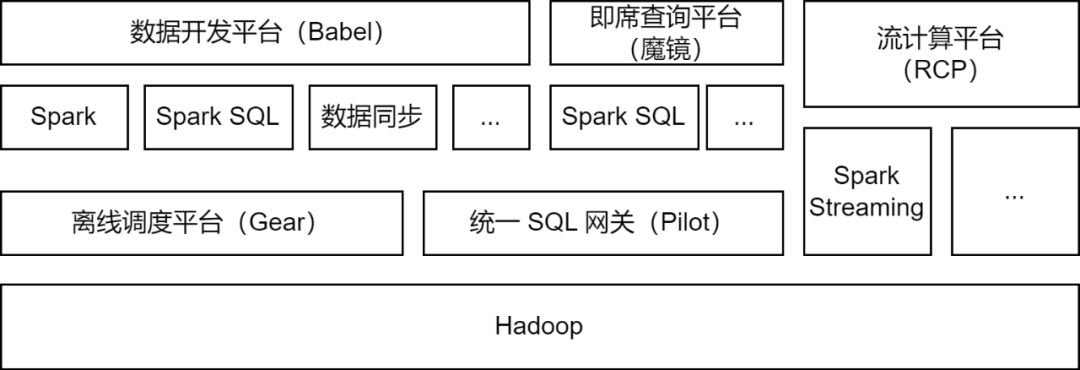
현재 iQiyi Spark 서비스는 매일 200,000개 이상의 Spark 작업을 실행하며 전체 빅 데이터 컴퓨팅 리소스의 절반 이상을 차지합니다.
iQiyi 빅 데이터 플랫폼 아키텍처를 업그레이드하고 최적화하는 과정에서 Spark 서비스는 버전 반복, 서비스 최적화, 작업 SQL화 및 리소스 비용 관리 등을 거쳐 오프라인 작업의 컴퓨팅 효율성과 리소스 절약을 크게 향상시켰습니다.
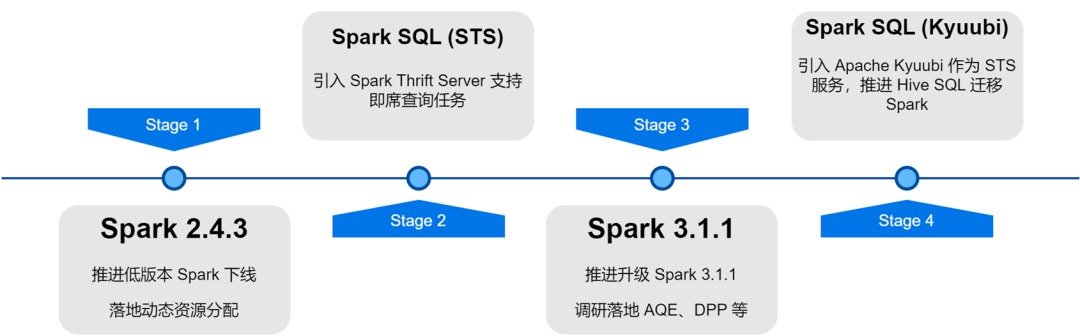
Spark 컴퓨팅 프레임워크 애플리케이션 최적화
내부 Spark 버전의 반복적인 업그레이드를 통해 동적 리소스 할당, 적응형 쿼리 최적화, 동적 파티션 정리 등 새로운 Spark 버전의 몇 가지 뛰어난 기능을 조사하고 구현했습니다.
-
DRA(Dynamic Resource Allocation)
: 사용자의 리소스 적용에 대한 맹점이 있으며 Spark 작업의 각 단계마다 리소스 요구 사항도 다릅니다. 불합리한 리소스 할당으로 인해 작업 리소스가 낭비되거나 실행 속도가 느려집니다. Spark 2.4.3에서 외부 셔플 서비스를 시작하고 DRA(동적 리소스 할당)를 활성화했습니다. 활성화된 후 Spark는 현재 실행 단계의 리소스 요구 사항에 따라 Executor를 동적으로 시작하거나 해제합니다. DRA가 온라인 상태가 된 후 Spark 작업의 리소스 소비가 20% 감소했습니다.
-
AQE(Adaptive Query Optimization)
: AQE(Adaptive Query Optimization)는 Spark 3.0에 도입된 뛰어난 기능입니다. 사전 단계의 런타임 중 통계 지표를 기반으로 후속 단계의 실행 계획을 동적으로 최적화하고 자동으로 선택합니다. 적절한 조인 전략 편향된 조인 최적화, 작은 파티션 병합, 큰 파티션 분할 등 Spark 3.1.1을 업그레이드한 후 AQE가 기본적으로 켜져 있어 작은 파일, 데이터 왜곡 등의 문제를 효과적으로 해결하고 Spark의 컴퓨팅 성능을 크게 향상시켰습니다. 전체 성능이 약 10% 향상되었습니다.
-
DPP(동적 파티션 정리)
: SQL 컴퓨팅 엔진에서 조건자 푸시다운은 일반적으로 데이터 소스에서 읽는 데이터 양을 줄여 컴퓨팅 효율성을 향상시키는 데 사용됩니다. Spark3에는 새로운 푸시다운 방법인 동적 파티션 정리 및 런타임 필터가 도입되었습니다. 조인의 작은 테이블을 먼저 계산하면 계산 결과에 따라 조인의 큰 테이블이 필터링되므로 큰 테이블에서 읽는 데이터의 양이 줄어듭니다. 테이블. 우리는 이 두 가지 기능에 대해 연구 및 테스트를 수행했으며 일부 비즈니스 시나리오에서는 기본적으로 DPP를 활성화하여 성능이 33배 향상되었습니다. 그러나 Spark 3.1.1에서 DPP를 켜면 많은 하위 쿼리가 포함된 SQL 구문 분석이 특히 느려지는 것으로 나타났습니다. 따라서 우리는 하위 쿼리 수를 계산하고 5개를 초과하면
DPP 최적화를 끄는 최적화 규칙을 구현했습니다
.
Spark를 사용하는 과정에서 우리는 커뮤니티의 최신 진행 상황을 따라가면서 몇 가지 문제를 발견하고 이를 해결하기 위한 패치를 적용했습니다. 또한 다양한 애플리케이션 시나리오에 적합하고 컴퓨팅 프레임워크의 안정성을 향상시키기 위해 Spark를 자체적으로 일부 개선했습니다.
Spark 3.1.1은 기본적으로 Hive Parquet 형식 테이블을 Spark의 내장 Parquet Writer로 변환하므로 InsertIntoHadoopFsRelationCommand 연산자를 사용하여 데이터를 씁니다(spark.sql.hive.convertMetastoreParquet=true). 정적 파티션을 작성할 때 임시 디렉터리는 테이블 경로 바로 아래에 구축됩니다. 여러 정적 파티션 쓰기 작업이 동일한 테이블의 서로 다른 파티션에 동시에 쓰는 경우 작업 쓰기 실패 또는 데이터 손실 위험이 있습니다(작업이 커밋되면 전체 임시 디렉터리가 정리되어 데이터 손실이 발생함). 다른 작업의 경우).
InsertIntoHadoopFsRelationCommand 연산자에 forceUseStagingDir 매개변수를 추가하고 작업별 Staging 디렉터리를 임시 디렉터리로 사용합니다. 이러한 방식으로 서로 다른 작업은 서로 다른 임시 디렉터리를 사용하여 동시 쓰기 문제를 해결합니다. 관련 문제 [SPARK-37210]를 커뮤니티에 제출했습니다.
Hive를 3.x로 업그레이드한 후에는 기본적으로 Tez 엔진이 사용됩니다. Union 문이 실행되면 HIVE_UNION_SUBDIR 하위 디렉터리가 생성됩니다. Spark는 하위 디렉터리의 데이터를 무시하므로 데이터를 읽을 수 없습니다.
이 문제는 Parquet/Orc Reader를 Hive Reader로 대체하고 다음 매개변수를 추가하여 해결할 수 있습니다.

하지만 Spark에 내장된 Parquet Reader를 사용하면 더 나은 성능을 얻을 수 있으므로 Hive Reader로 대체하려는 계획을 포기하고 대신 Spark를 변형했습니다. Spark는 이미 recursiveFileLookup 매개변수를 통해 분할되지 않은 테이블의 하위 디렉터리 읽기를 지원하므로 분할된 테이블의 하위 디렉터리 읽기를 지원하도록 이를 확장했습니다. 자세한 내용은 [SPARK-40600]을 참조하세요.
데이터 동기화 애플리케이션에는 수많은 JDBC 데이터 소스 작업이 있습니다. 운영 효율성을 향상하고 다양한 애플리케이션 시나리오에 적응하기 위해 Spark의 내장 JDBC 데이터 소스를 다음과 같이 수정했습니다.
샤딩 조건 푸시 다운
:
Spark는 JDBC 데이터 소스를 조각화한 후 하위 쿼리를 통해 샤딩 조건을 삽입합니다. MySQL 5.x에서는 하위 쿼리 조건을 푸시다운할 수 없으므로 자리 표시자가 조건의 위치를 나타냅니다. , 그리고 스파크에 샤딩 조건을 삽입할 때 서브쿼리 내부까지 밀어내려 샤딩 조건을 밀어 내리는 기능을 구현한다.
다중 쓰기 모드
:
Spark에서 JDBC 데이터 소스에 대한 다중 쓰기 모드를 구현했습니다.
-
일반: 일반 모드, 기본 INSERT INTO를 사용하여 쓰기
-
Upsert: INSERT INTO...ON DUPLICATE KEY UPDATE 모드로 작성된 기본 키가 존재할 때 업데이트합니다.
-
무시: 기본 키가 존재할 때 무시하고 INSERT IGNORE INTO 모드로 씁니다.
Silent 모드:
JDBC 작성 중 예외가 발생하면 예외 로그만 인쇄하고 작업은 종료되지 않습니다.
지원되는 맵 유형
: JDBC 데이터 소스를 사용하여 ClickHouse 데이터를 읽고 씁니다. ClickHouse의 맵 유형은 JDBC 데이터 소스에서 지원되지 않으므로 맵 유형에 대한 지원을 추가했습니다.
Spark에서 Shuffle, Cache, Spill과 같은 작업은 일부 로컬 파일을 생성합니다. 너무 많은 로컬 파일이 기록되면 컴퓨팅 노드의 디스크가 가득 차서 클러스터의 안정성에 영향을 줄 수 있습니다.
이에 대해 Spark에 디스크 쓰기 볼륨 표시기를 추가하고, 디스크 쓰기 볼륨이 임계값에 도달하면 예외를 발생시키고, TaskScheduler에서 작업 실패 예외를 판단하고, 디스크 쓰기 제한 예외가 캡처되면 DagScheduler를 호출합니다. 메소드는 과도한 디스크 사용량이 있는 작업을 중지합니다.
동시에 Spark Executor의 현재 디스크 사용량을 노출하기 위해 ExecutorMetric에 Executor Disk Usage 표시기를 추가하여 추세 관찰과 데이터 분석을 더 쉽게 만들었습니다.
Spark 서비스는 많은 컴퓨팅 리소스를 차지합니다. 우리는 Spark 일괄 처리 작업과 스트림 컴퓨팅 작업에 대한 컴퓨팅 리소스를 각각 감사하고 관리하기 위한 예외 관리 플랫폼을 개발했습니다.
일상적인 운영 및 유지 관리에서 우리는 다수의 Spark 작업에 메모리 낭비, 낮은 CPU 사용률 등의 문제가 있음을 발견했습니다. 이러한 문제가 있는 작업을 찾기 위해 Spark 작업이 실행될 때 리소스 표시기를 Prometheus에 전달하여 작업 리소스 활용도를 분석하고 Spark EventLog를 구문 분석하여 리소스 구성 및 계산 세부 정보를 얻습니다.
작업의 리소스 매개변수를 최적화하고 동적 리소스 할당을 활성화함으로써 Spark 작업의 컴퓨팅 리소스 활용도가 효과적으로 향상됩니다. 또한 Spark 버전 업그레이드는 많은 리소스 절약 효과를 제공합니다.
리소스 매개변수 최적화는 메모리 최적화와 CPU 최적화로 구분됩니다. 예외 관리 플랫폼은 지난 7일 동안 작업의 최대 리소스 사용량을 기반으로 합리적인 리소스 매개변수 설정을 권장하여 Spark 작업의 리소스 활용도를 향상시킵니다.
메모리 최적화를 예로 들자면, 사용자들은 메모리를 늘려 메모리 오버플로(OOM) 문제를 해결하면서도 OOM의 원인에 대한 심도 있는 조사를 무시하는 경우가 많습니다. 이로 인해 다수의 Spark 작업에 대한 메모리 매개변수가 너무 높게 설정되고 CPU에 대한 큐 리소스 메모리 비율이 불균형해집니다. Spark Executor 메모리 표시기를 획득하고 예외 작업 명령을 보내 사용자에게 알리고 메모리 매개변수와 파티션 수를 올바르게 구성하도록 안내합니다.
거의 1년 동안 리소스 감사를 관리한 후, 예외 관리 플랫폼은 1,600개 이상의 작업 주문을 발행하여 총 컴퓨팅 리소스의 약 27%를 절약했습니다.
Spark SQL 서비스 구현 및 최적화
iQiyi Spark SQL 서비스는 Spark의 기본 Thrift Server 서비스부터 Kyuubi 0.7, Apache Kyuubi 1.4 버전까지 여러 단계를 거쳐 서비스 아키텍처와 안정성이 크게 향상되었습니다.
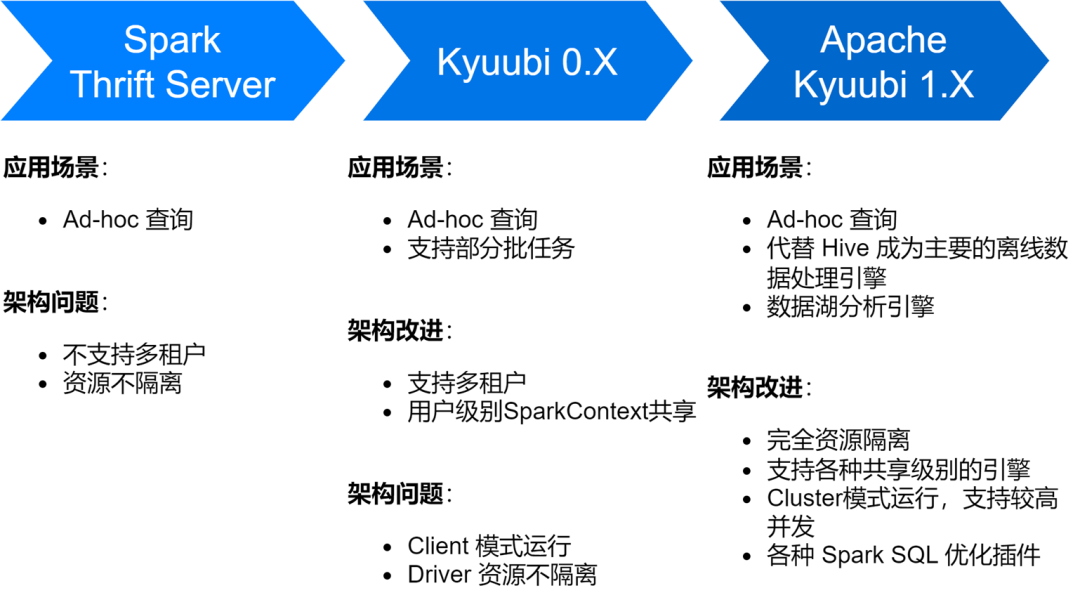
현재 iQiyi의 주요 오프라인 데이터 처리 엔진인 Spark SQL 서비스가 Hive를 대체하여 매일 평균 약 150,000개의 SQL 작업을 실행하고 있습니다.
또한 Spark SQL 서비스를 탐색하는 동안 주로 다수의 작은 파일 생성, 더 큰 스토리지, 느린 계산 등 몇 가지 문제에 직면했습니다. 이러한 이유로 우리는 일련의 스토리지 및 컴퓨팅 효율성 최적화도 수행했습니다.
압축 비율을 향상하려면 ZStandard 압축을 활성화하세요.
Zstd는 Meta의 오픈 소스 압축 알고리즘으로 다른 압축 형식에 비해 압축률과 압축 해제 효율성이 더 높습니다. 실제 측정 결과는 Zstd의 압축률은 Gzip과 동일하고 압축 해제 속도는 Snappy보다 나은 것으로 나타났습니다. 따라서 Spark 업그레이드 과정에서 Zstd 압축 형식을 기본 데이터 압축 형식으로 사용하고 Shuffle 데이터도 Zstd 압축으로 설정하여 클러스터 스토리지를 크게 절약했으며 광고 데이터 시나리오에 적용하면 압축률이 3.3배 향상되었습니다. , 스토리지 비용을 76% 절감합니다.
작은 파일 생성을 방지하려면 재조정 단계를 추가하세요.
작은 파일 문제는 Spark SQL에서 중요한 문제입니다. 작은 파일이 너무 많으면 Hadoop NameNode에 큰 부담을 주고 클러스터의 안정성에 영향을 미칩니다. 기본 Spark 컴퓨팅 프레임워크에는 작은 파일 문제를 해결하기 위한 우수한 자동화 솔루션이 없습니다. 이와 관련하여 우리는 일부 산업 솔루션도 조사했으며 최종적으로 Kyuubi 서비스와 함께 제공되는 작은 파일 최적화 솔루션을 사용했습니다.
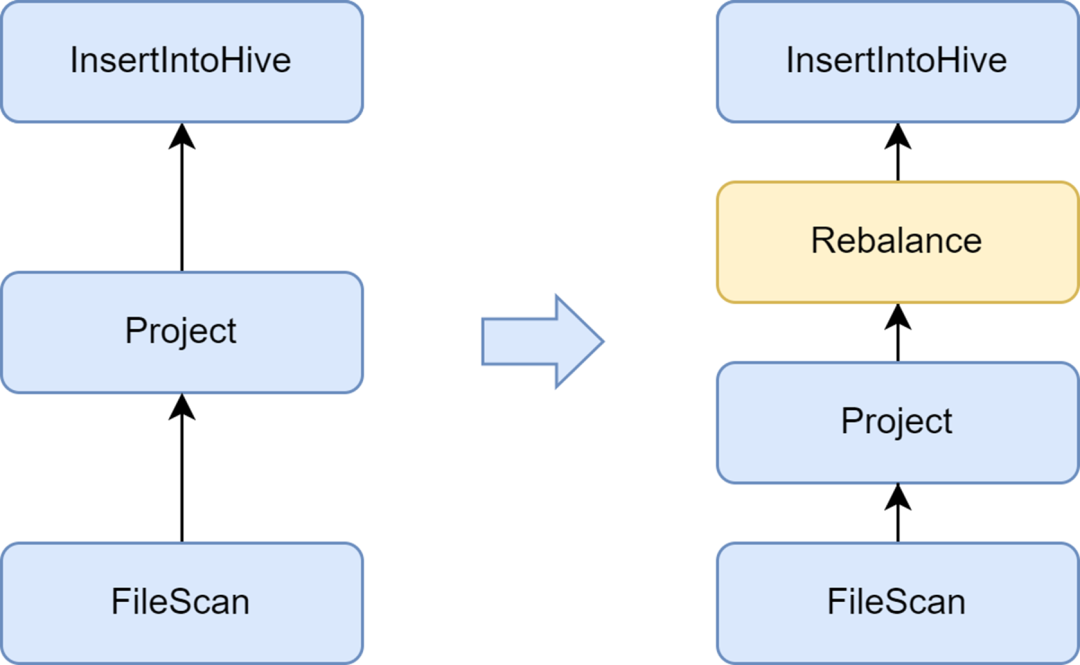
Kyuubi에서 제공하는 insertRepartitionBeforeWrite 최적화 프로그램은 Insert 연산자 앞에 Rebalance 연산자를 삽입할 수 있으며 AQE 논리와 결합하여 자동으로 작은 파티션을 병합하고 큰 파티션을 분할하여 출력 파일 크기 제어를 실현하고 작은 파일 문제를 효과적으로 해결합니다.
활성화한 후에는 Spark SQL의 평균 출력 파일 크기가 10MB에서 262MB로 최적화되어 많은 수의 작은 파일이 생성되는 것을 방지합니다.
압축률을 더욱 향상시키기 위해 재파티션 정렬 추론을 활성화합니다.
작은 파일 최적화를 켠 후 일부 작업의 데이터 저장 공간이 훨씬 더 커졌다는 사실을 발견했습니다. 이는 스몰 파일 최적화에 삽입된 Rebalance 작업이 파티셔닝을 위해 파티션 필드나 무작위 파티션을 사용하고, 데이터가 무작위로 분산되어 Parquet 형식의 파일에 대한 인코딩 효율성이 저하되어 결과적으로 인코딩 효율성이 떨어지기 때문입니다. 파일 압축률에서.
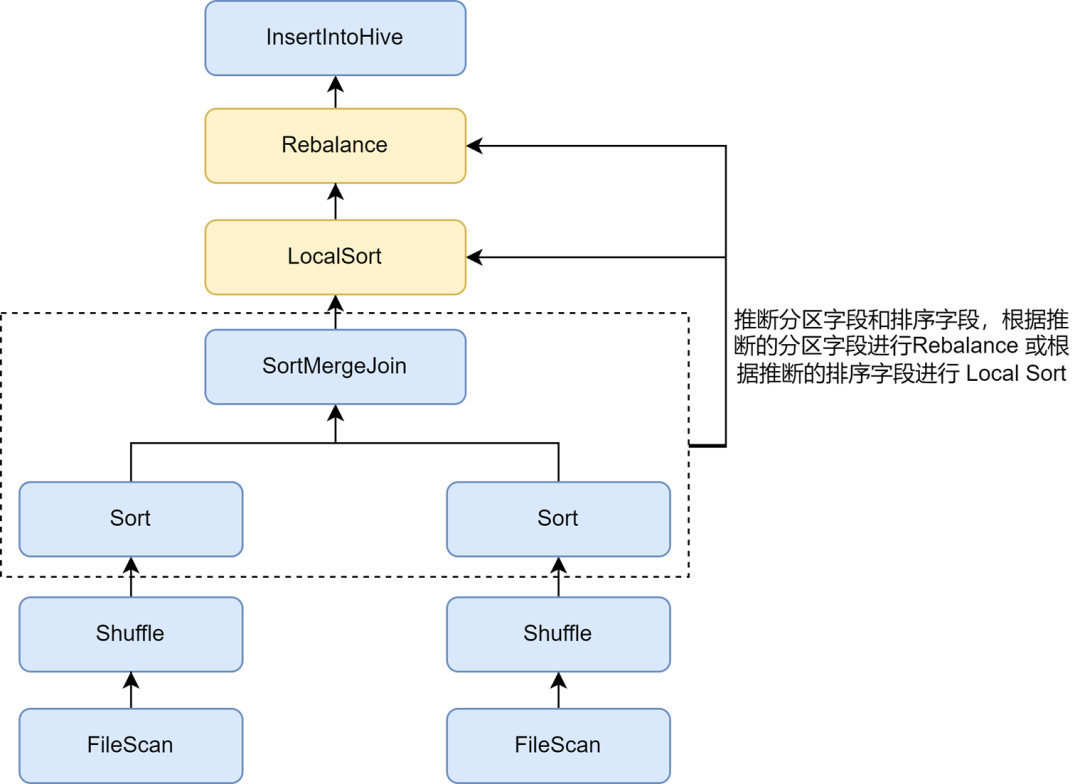
Kyuubi 작은 파일 최적화 규칙에서는 Spark.sql.optimizer.inferRebalanceAndSortOrders.enabled 매개변수를 통해 파티션 및 정렬 필드의 자동 추론을 활성화할 수 있습니다. Pre-execution plan은 Key로부터 partitioning과 sorting 필드를 추론하고, 추론된 partition 필드는 Rebalance에 사용하거나, 추론된 sorting 필드는 Rebalance 전 Local Sort에 사용하여 최종 삽입된 데이터를 분산시킨다. Rebalance 연산자는 사전 계획과 최대한 일치하고 쓰기를 방지합니다. 들어오는 데이터는 무작위로 분산되어 압축률을 효과적으로 향상시킵니다.
Zorder 최적화를 활성화하여 압축률 및 쿼리 효율성 향상
Zorder 정렬은 다차원 정렬 알고리즘입니다. Parquet와 같은 열 기반 저장 형식의 경우 효과적인 정렬 알고리즘을 사용하면 데이터를 더욱 컴팩트하게 만들어 데이터 압축률을 높일 수 있습니다. 또한, 유사한 데이터를 동일한 저장 단위에 모아두기 때문에 최소/최대의 통계적 범위가 작아 질의 과정에서 건너뛰는 데이터의 양이 늘어나 질의 효율성이 효과적으로 향상될 수 있다.
Zorder 클러스터링 정렬 최적화는 Kyuubi에서 구현됩니다. 테이블에 대해 Zorder 필드를 구성할 수 있으며 작성 시 Zorder 정렬이 자동으로 추가됩니다. 기존 작업의 경우 기존 데이터의 Zorder 최적화를 위해 Optimize 명령도 지원됩니다. 일부 주요 비즈니스에 내부적으로 Zorder 최적화를 추가하여 데이터 저장 공간을 13% 줄이고 데이터 쿼리 성능을 15% 향상시켰습니다.
컴퓨팅 병렬성을 높이기 위해 최종 단계에 독립적인 AQE 구성을 도입합니다.
일부 Hive 작업을 Spark로 마이그레이션하는 과정에서 일부 작업의 실행 속도가 실제로 느려지는 것을 발견했으며, 작은 파일을 제어하기 위해 Rebalance 연산자를 쓰기 전에 삽입하고 Spark AQE와 결합했기 때문에 AQE의 Spark를 변경한 것으로 나타났습니다. sql.adaptive.advisoryPartitionSizeInBytes 구성이 1024M으로 설정되어 있어 중간 Shuffle 단계의 병렬 처리가 작아지고 결과적으로 작업 실행이 느려집니다.
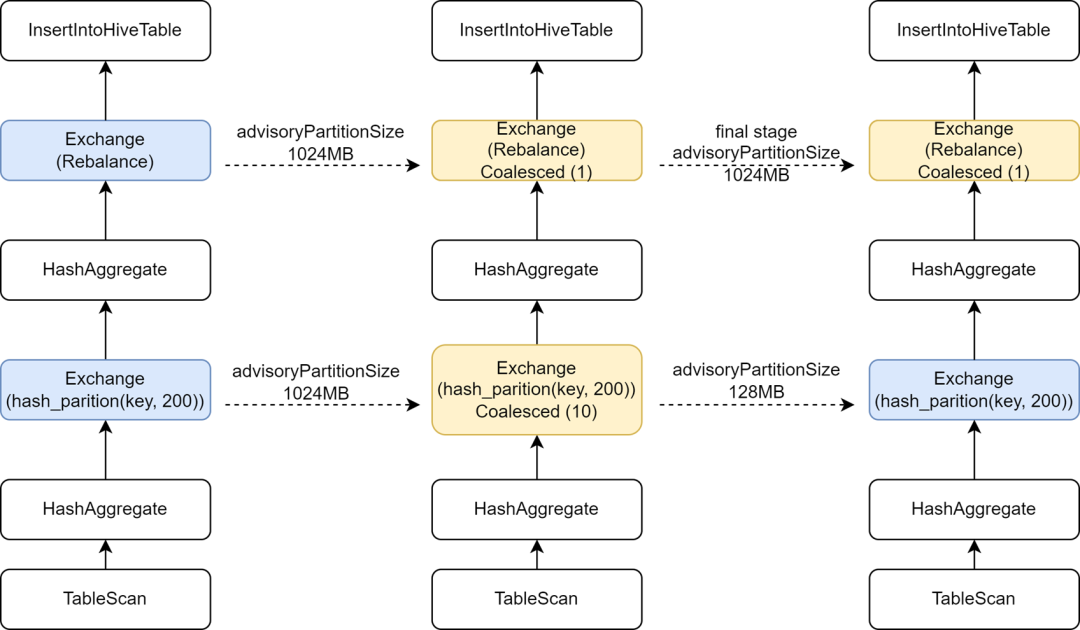
Kyuubi는 최종 단계 구성의 최적화를 제공하여 최종 단계에 대해 별도로 일부 구성을 추가할 수 있으므로 작은 파일을 제어하는 마지막 단계에 더 큰 AdvisoryPartitionSizeInBytes를 추가하고 이전 단계에 더 작은 AdvisoryPartitionSizeInBytes를 사용하여 병렬성을 높일 수 있습니다. Shuffle 단계에서 디스크 오버플로를 줄여 컴퓨팅 효율성을 효과적으로 향상시킵니다. 이 구성을 추가하면 Spark SQL 작업의 전체 실행 시간이 25% 단축되고 리소스가 약 9% 절약됩니다.
지나치게 큰 Shuffle 파티션을 방지하기 위해 단일 파티션 작업의 동적 쓰기를 추론합니다.
동적 파티션 쓰기의 경우 Kyuubi 작은 파일 최적화는 재조정을 위해 동적 파티션 필드를 사용합니다. 동적 분할을 사용하여 단일 파티션에 쓰는 작업의 경우 모든 Shuffle 데이터는 동일한 Shuffle 파티션에 기록됩니다. iQIYI는 내부적으로 Apache Uniffle을 원격 셔플 서비스로 사용합니다. 대규모 파티션은 셔플 서버에 단일 압력을 유발하고 심지어 전류 제한을 유발하여 쓰기 속도를 저하시킵니다. 이를 위해 우리는 작성된 파티션 필터 조건을 캡처하고 단일 파티션의 데이터가 이러한 작업을 위해 동적 파티셔닝 방식으로 작성되었는지 추론하는 최적화 규칙을 개발했습니다. 더 이상 재조정을 위해 동적 파티션 필드를 사용하지 않고 무작위를 사용합니다. Rebalance를 사용하면 더 큰 Shuffle 파티션이 생성되는 것을 방지할 수 있습니다. 자세한 내용은 [KYUUBI-5079]를 참조하세요.
데이터 품질에 문제가 있거나 사용자가 데이터 분산에 익숙하지 않은 경우 비정상적인 SQL을 제출하기 쉬우며 이로 인해 심각한 자원 낭비와 컴퓨팅 효율성 저하가 발생할 수 있습니다. Spark SQL 서비스에 일부 모니터링 표시기를 추가하고 일부 비정상적인 컴퓨팅 시나리오를 감지하고 차단했습니다.
iQiyi에서 데이터 분석가는 사용자에게 2단계 쿼리 기능을 제공하는 Magic Mirror 임시 쿼리 플랫폼을 통해 임시 쿼리 분석용 SQL을 제출합니다. 우리는 Kyuubi의 공유 엔진을 백엔드 처리 엔진으로 사용하여 각 쿼리에 대해 새 엔진을 시작하는 것을 방지합니다. 이로 인해 시작 시간과 컴퓨팅 리소스가 낭비됩니다. 공유 엔진이 백그라운드에 영구적으로 존재하므로 사용자에게 더 빠른 대화형 경험을 제공할 수 있습니다.
공유 엔진의 경우 여러 요청이 서로 리소스를 점유합니다. 동적 리소스 할당을 활성화하더라도 일부 대규모 쿼리가 리소스를 점유하여 다른 쿼리가 차단되는 상황이 여전히 있습니다. 이에 대해 Kyuubi의 Spark 플러그인에는 SQL 실행 계획에서 Table Scan과 같은 작업을 구문 분석하여 쿼리된 파티션 수와 스캔된 데이터의 양을 계산할 수 있는 기능을 구현했습니다. 지정된 임계값을 초과하는 경우 대규모 쿼리 및 인터셉트 실행에 대해 결정됩니다.
Magic Mirror 플랫폼은 판단 결과에 따라 대용량 쿼리를 독립 엔진으로 전환하여 실행합니다. 또한 Magic Mirror는 공유 엔진을 사용하여 초과 근무를 실행하는 작업이 취소되고 자동으로 독립 엔진 실행으로 변환되는 분 단위 제한 시간을 정의합니다. 전체 프로세스는 사용자에게 영향을 미치지 않으므로 일반 쿼리가 차단되는 것을 효과적으로 방지하고 독립적인 리소스를 사용하여 대규모 쿼리를 계속 실행할 수 있습니다.
Spark SQL의 Explode, Join, Count Distinct와 같은 일부 작업은 데이터 확장을 유발합니다. 데이터 확장이 매우 클 경우 디스크 오버플로, Full GC 또는 심지어 OOM이 발생할 수 있으며 계산 효율성도 저하됩니다. Spark UI의 SQL 탭 페이지에 있는 SQL 실행 계획 다이어그램에서 전후 노드의 출력 행 개수 표시를 통해 데이터 확장이 발생했는지 쉽게 확인할 수 있습니다.

Spark SQL 실행 계획 그래프의 지표는 Task 실행 이벤트 및 Executor Heartbeat 이벤트를 통해 드라이버에 보고되고 드라이버에 집계됩니다.
보다 시기적절하게 런타임 지표를 수집하기 위해 Kyuubi에서 SQLOperationListener를 확장하고 SparkPlanInfo를 유지하기 위해 SparkListenerSQLExecutionStart 이벤트를 수신하는 동시에 SparkListenerExecutorMetricsUpdate 이벤트를 수신하여 실행 중인 노드의 SQL 통계 지표의 변경 사항을 캡처했습니다. , 현재 실행 중인 노드의 출력 행 수 지표와 이전 하위 노드의 출력 행 수 지표를 비교하여 데이터 확장 비율을 계산하여 심각한 데이터 확장이 발생하는지 여부를 판단하고, 비정상적인 이벤트를 수집하거나 비정상적인 작업을 차단합니다. 데이터 확장이 발생합니다.
데이터 편향 문제는 Spark SQL의 일반적인 문제이며 성능에 영향을 미칩니다. Spark AQE에는 데이터 편향을 자동으로 최적화하는 몇 가지 규칙이 있지만 항상 효과적인 것은 아닙니다. 데이터에 대한 오해. 이해가 깊지 않아서 잘못된 분석 로직이 작성되었거나, 데이터 자체에 데이터 품질 문제가 있어서 데이터 왜곡 작업을 분석하고 왜곡된 Key 값을 찾는 것이 필요합니다.

Spark UI의 Stage Tasks 통계를 통해 해당 작업에 데이터 왜곡이 발생했는지 여부를 쉽게 확인할 수 있습니다. 위 그림과 같이 Task의 Duration 및 Shuffle Read의 Max 값이 75번째 백분위수 값을 초과하므로 데이터가 명확하게 나타납니다. 왜곡이 발생했습니다.
그러나 편향 작업에서 편향을 일으키는 Key 값을 계산하려면 일반적으로 SQL을 수동으로 분할한 다음 Count Group By Keys를 사용하여 각 단계에서 Key 분포를 계산하여 편향된 Key 값을 결정해야 합니다. 일반적으로 상대적으로 시간이 많이 걸리는 작업입니다.
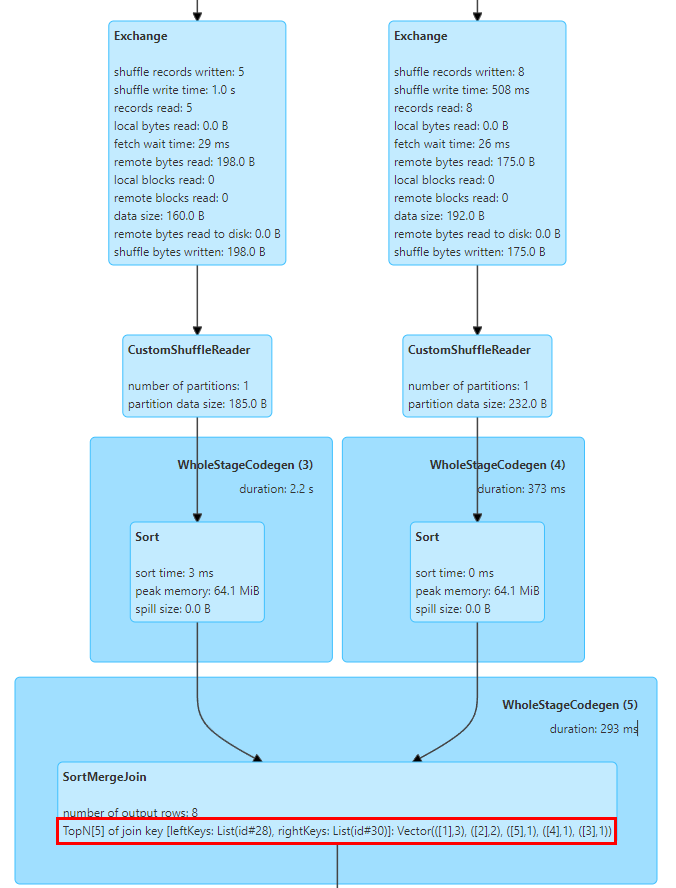
이와 관련하여 SortMergeJoinExec에서 TopN Keys 통계를 구현했습니다.
SortMergeJoin의 구현은 Key를 먼저 정렬한 후 Join 작업을 수행하는 것이므로 누적을 통해 Key의 TopN 값을 쉽게 계산할 수 있습니다.
우리는 Map[String, Long] 유형 객체를 내부적으로 유지하는 TopNAccumulator 누산기를 구현했습니다. 이는 Join의 Key 값을 Map의 Key로 사용하고 SortMergeJoinExec에서 각 데이터 행에 대한 Key의 Count 값을 유지합니다. 누적 계산을 위해서는 데이터가 정돈되어 있으므로 삽입된 Key만 누적하면 되고, 새로운 Key를 삽입할 때에는 N 값에 도달했는지 판단하여 가장 작은 Key를 제거하면 된다.
또한 Spark는 Long 유형의 통계 지표 표시만 지원하며, Map 유형 값에 맞게 SQL 통계 지표의 표시 로직도 수정했습니다.
위 그림은 Join을 위한 두 테이블의 Top 5 Join Key 값을 보여줍니다. 여기서 키는 id 필드이고 id=1인 행이 3개 있습니다.
일련의 연구와 테스트를 통해 Spark SQL이 Hive에 비해 성능과 리소스 사용량이 크게 향상되었음을 확인했습니다. 그러나 Hive SQL을 Spark로 마이그레이션하는 동안에도 많은 문제에 직면했습니다. Spark SQL 서비스에 대한 일부 호환성 수정 및 조정을 통해 대부분의 Hive SQL 작업을 Spark로 성공적으로 마이그레이션했습니다.
Spark SQL의 Hive UDF 지원은 실제 사용 시 몇 가지 문제가 있습니다. 예를 들어 기업에서는 Reflect 함수를 사용하여 Java 정적 메서드를 호출하여 데이터를 처리하는 경우가 많습니다. 리플렉션 호출에서 예외가 발생하면 Hive는 NULL 값을 반환하고 Spark SQL에서는 예외가 발생하여 작업이 실패하게 됩니다. 이를 위해 우리는 Hive와 일치하게 반사 호출 예외를 캡처하고 NULL 값을 반환하도록 Spark의 반영 함수를 수정했습니다.
또 다른 문제는 Spark SQL이 Hive UDAF의 전용 생성자를 지원하지 않아 일부 비즈니스의 UDAF가 초기화되지 않는다는 것입니다. Hive UDAF 개인 생성자를 지원하도록 Spark의 함수 등록 논리를 변환했습니다.
Spark SQL과 Hive 버전 1.2 간에는 내장된 GROUPING_ID 함수의 계산 논리에 차이가 있어 이중 실행 단계에서 데이터 불일치가 발생합니다. Hive 3.1 버전에서는 이 함수의 계산 논리가 Spark의 논리와 일치하도록 변경되었으므로 사용자가 SQL 논리를 업데이트하고 Spark에서 이 함수의 논리를 조정하여 계산 논리의 정확성을 보장할 것을 권장합니다.
또한 Spark SQL의 해시 함수는 Hive의 구현 로직과 다른 Murmur3 Hash 알고리즘을 사용합니다. 마이그레이션 전후의 데이터 일관성을 보장하려면 사용자가 Hive의 내장 해시 함수를 수동으로 등록하는 것이 좋습니다.
Spark SQL은 버전 3.0부터 ANSI SQL 사양을 도입했습니다. Hive SQL에 비해 유형 일관성에 대한 요구 사항이 더 엄격합니다. 예를 들어 문자열과 숫자 유형 간의 자동 변환이 금지됩니다. 비즈니스에서 비표준 데이터 유형 정의로 인해 발생하는 자동 변환 변칙을 방지하려면 사용자가 명시적 변환을 위해 SQL에 CAST를 추가하는 것이 좋습니다. 대규모 변환의 경우 spar.sql.storeAssignmentPolicy=LEGACY 구성을 일시적으로 추가할 수 있습니다. 마이그레이션 예외를 방지하기 위해 Spark SQL 수준의 유형 검사를 줄입니다.
Hive의 str_to_map 함수는 반복되는 키의 마지막 값을 자동으로 유지하지만 Spark에서는 예외가 발생하고 작업이 실패합니다. 이와 관련하여 사용자는 업스트림 데이터의 품질을 감사하거나 Spark.sql.mapKeyDedupPolicy=LAST_WIN 구성을 추가하여 Hive와 일치하게 마지막 중복 값을 유지하는 것이 좋습니다.
Spark SQL과 Hive SQL의 힌트 구문은 호환되지 않으며 사용자는 마이그레이션 중에 관련 구성을 수동으로 삭제해야 합니다. 일반적인 Hive 힌트에는 작은 테이블 브로드캐스팅이 포함됩니다. Spark AQE 기능은 작은 테이블을 브로드캐스팅하고 작업 기울기를 최적화하는 데 더 지능적이므로 일반적으로 사용자가 추가 구성을 요구하지 않습니다.
또한 Spark SQL과 Hive의 DDL 문 간에는 몇 가지 호환성 문제가 있습니다. 일반적으로 사용자는 플랫폼을 사용하여 Hive 테이블에서 DDL 작업을 수행하는 것이 좋습니다. 존재하지 않는 파티션 삭제 [KYUUBI-1583], 동일하지 않은 Alter Partition 문 및 기타 호환성 문제와 같은 일부 파티션 작업 명령의 경우 호환성을 위해 Spark 플러그인도 확장했습니다.
요약 및 전망
현재 회사 내 Hive 작업 대부분을 Spark로 마이그레이션하여 Spark가 iQiyi의 주요 오프라인 처리 엔진이 되었습니다. 우리는 Spark 엔진에 대한 예비 리소스 감사 및 성능 최적화 작업을 완료하여 회사에 상당한 비용 절감 효과를 가져왔습니다. 앞으로도 Spark 서비스와 컴퓨팅 프레임워크의 성능과 안정성을 지속적으로 최적화할 예정입니다. 우리는 또한 극소수의 Hive 작업에 대한 마이그레이션을 더욱 촉진할 것입니다.
회사의 데이터 레이크 구현으로 점점 더 많은 기업이 Iceberg 데이터 레이크로 마이그레이션하고 있습니다. Iceberg가 Spark DataSourceV2의 기능을 지속적으로 개선함에 따라 Spark 3.1은 더 이상 새로운 데이터 레이크 분석 요구 사항을 충족할 수 없으므로 Spark 3.4로 업그레이드하려고 합니다. 동시에 우리는 비즈니스 요구에 따라 Spark 컴퓨팅 프레임워크의 성능을 더욱 향상시키기 위해 런타임 필터, Storage Partitioned Join 등과 같은 몇 가지 새로운 기능에 대한 연구도 수행했습니다.
또한, 클라우드 네이티브 빅데이터 컴퓨팅 프로세스를 촉진하기 위해 원격 셔플 서비스(RSS)인 Apache Uniffle을 도입했습니다. 사용 중에 BroadcastHashJoin 왜곡 최적화 [SPARK-44065]와 같은 Spark AQE와 결합할 때 성능 문제가 있음을 발견했으며, 앞서 언급한 대규모 파티션 문제와 AQE 파티션 계획을 더 잘 수행하는 방법에 대해 계속해서 노력할 것입니다. 앞으로는 더욱 심층적인 연구와 최적화로 이어질 것입니다.

