
이 기사는 QCon 글로벌 소프트웨어 개발 컨퍼런스에서 Volcano Engine의 수석 R&D 엔지니어인 Shao Wei가 한 연설을 바탕으로 작성되었습니다. 연사 │ Shao Wei 연설 시간 │ 2023년 5월 QCon 광저우
1.배경
Byte는 2016년부터 서비스를 클라우드 기반 서비스로 전환하기 시작했습니다. 현재 Byte의 서비스 시스템에는 주로 4가지 범주가 포함됩니다. 기존 마이크로서비스 는 대부분 Golang을 기반으로 하는 RPC 웹 서비스입니다. 프로모션 검색 서비스는 성능이 더 뛰어난 기존 C++ 서비스입니다. 요구 사항 외에도 기계 학습, 빅 데이터 및 다양한 스토리지 서비스 도 있습니다 .
클라우드 네이티브 이후 해결해야 할 핵심 문제는 일반적인 온라인 서비스의 리소스 사용량을 예로 들어 클러스터의 리소스 활용 효율성을 어떻게 향상시킬 것인가이며, 진한 파란색 부분은 비즈니스에서 실제로 사용하는 리소스의 양입니다. , 하늘색 부분은 사업영역에서 제공하는 보안 버퍼로, 완충 영역을 늘려도 사업체에서 신청했지만 사용하지 못한 자원이 여전히 많이 남아있습니다. 따라서 최적화의 초점은 아키텍처 관점에서 이러한 사용되지 않는 리소스를 최대한 활용하는 것입니다.
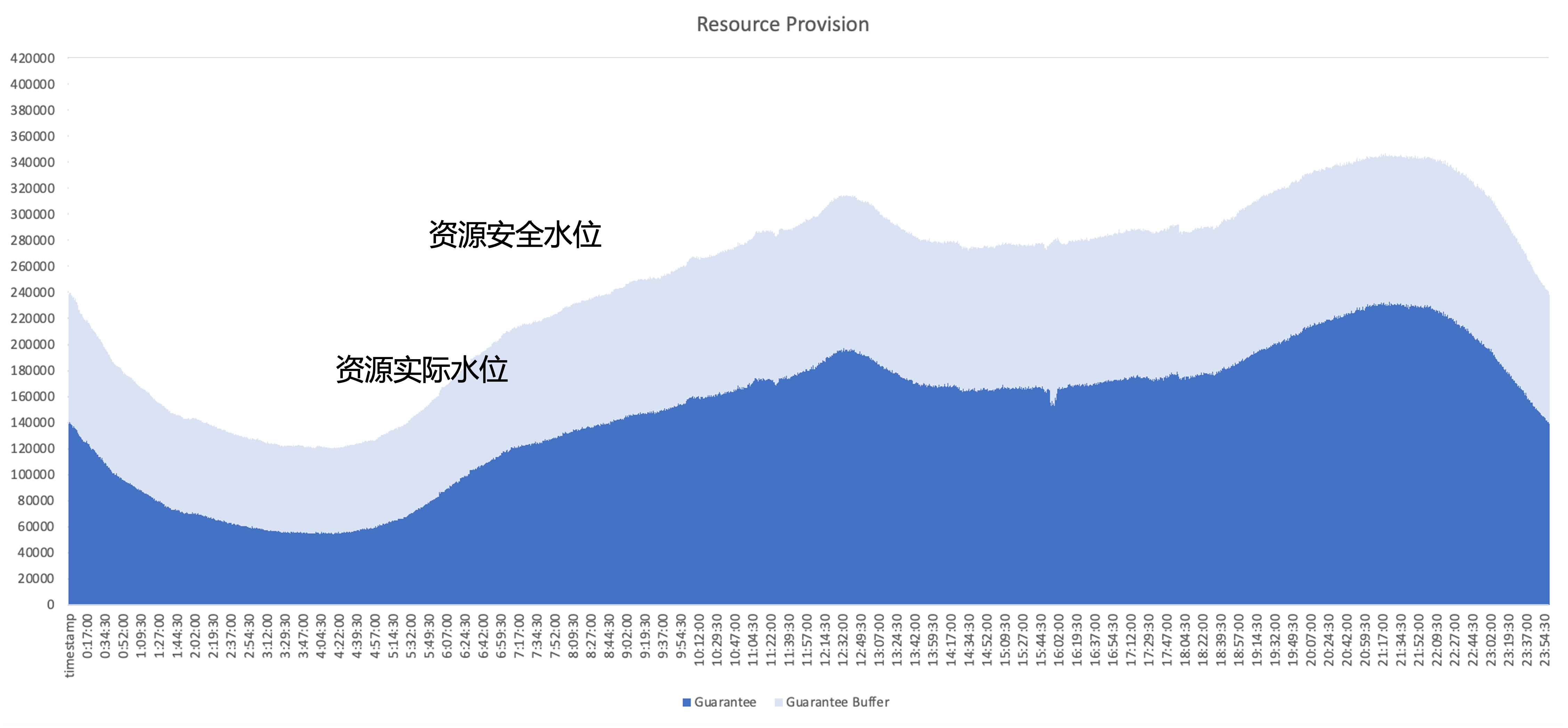
자원 관리 계획
Byte는 내부적으로 다음을 포함하여 여러 가지 유형의 리소스 관리 솔루션을 시도했습니다.
- 자원 운영: 정기적으로 기업의 자원 활용 현황을 지원하고 자원 활용 관리를 촉진합니다. 문제는 운영 및 유지 관리 부담이 크고 활용 문제를 해결할 수 없다는 것입니다.
- 동적 초과 예약: 시스템 측에서 비즈니스 리소스의 양을 평가하고 할당량을 사전에 줄입니다. 문제는 초과 예약 전략이 반드시 정확하지 않고 실행 위험으로 이어질 수 있다는 것입니다.
- 동적 확장: 문제는 온라인 서비스만 확장 대상으로 삼을 경우 온라인 서비스의 트래픽 최고점과 최저점이 비슷하기 때문에 하루 종일 활용도를 완전히 향상시킬 수 없다는 것입니다.
따라서 결국 Byte는 동일한 노드에서 온라인과 오프라인을 동시에 실행하는 하이브리드 배포를 채택하고 온라인과 오프라인 리소스 간의 상호 보완적인 특성을 최대한 활용하여 더 나은 리소스 활용도를 달성할 수 있을 것으로 기대합니다. 즉, 2차 판매는 온라인으로 이루어집니다. 미사용 자원은 오프라인 작업량으로 잘 채워져 하루 종일 높은 수준의 자원 활용 효율을 유지할 수 있습니다.
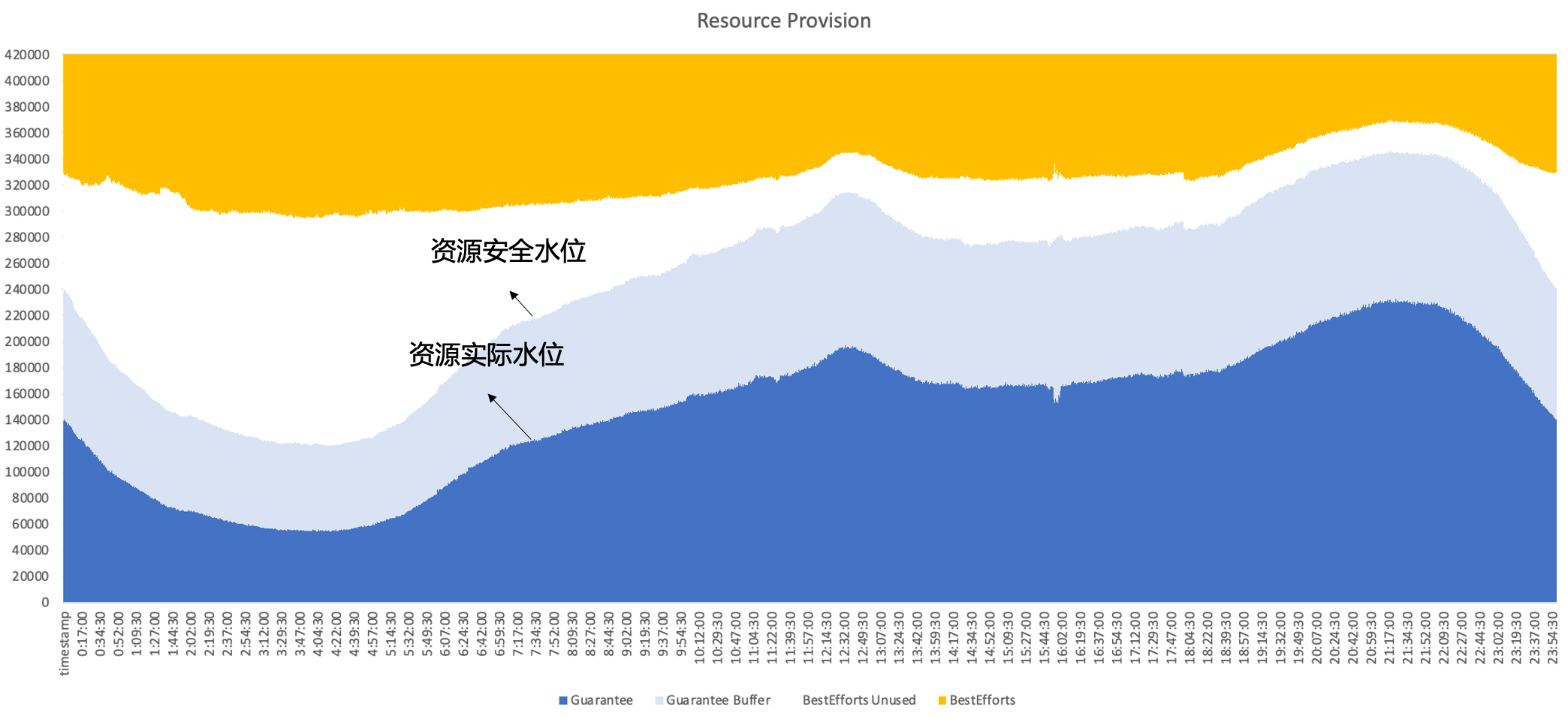
2. 바이트 하이브리드 배포 개발 내역
Byte Cloud가 기본화됨에 따라 우리는 비즈니스 요구 사항과 다양한 단계의 기술적 특성을 기반으로 적절한 하이브리드 배포 솔루션을 선택하고 그 과정에서 하이브리드 시스템을 계속 반복합니다.
2.1 1단계: 오프라인 시분할 혼합
첫 번째 단계에는 주로 온라인 및 오프라인 시분할 하이브리드 배포가 포함됩니다.
- 온라인: 이 단계에서 우리는 온라인 서비스 탄력성 플랫폼을 구축했습니다. 사용자는 비즈니스 지표를 기반으로 수평적 확장 규칙을 구성할 수 있습니다. 예를 들어 이른 아침에 비즈니스 트래픽이 감소하고 비즈니스가 사전에 일부 인스턴스를 축소하는 경우 시스템은 리소스를 수행합니다. 인스턴스 축소를 기준으로 빙 패킹을 수행하면 전체 시스템이 해제됩니다.
- 오프라인의 경우: 이 단계에서 오프라인 서비스는 대량의 현물형 자원을 확보할 수 있으며 공급이 불안정하기 때문에 동시에 비용에 대해 일정한 할인을 받을 수 있습니다. 온라인의 경우 사용하지 않는 자원을 오프라인에 판매할 수 있습니다. 비용에 대해 특정 리베이트를 얻습니다.
이 솔루션의 장점은 복잡한 단일 기계 측면 격리 메커니즘이 필요하지 않으며 기술 구현이 상대적으로 낮다는 것입니다. 그러나 다음과 같은 몇 가지 문제도 있습니다.
- 변환 효율이 높지 않으며 빙 패킹 과정에서 조각화와 같은 문제가 발생할 수 있습니다.
- 오프라인 경험도 좋지 않을 수 있습니다. 온라인 트래픽이 가끔씩 변동되면 오프라인 사용자가 강제로 종료되어 리소스 변동이 심해질 수 있습니다.
- 이로 인해 비즈니스에 인스턴스 변경이 발생하게 됩니다. 실제 운영에서 비즈니스는 일반적으로 상대적으로 보수적인 탄력적 정책을 구성하므로 리소스 개선에 대한 상한이 낮습니다.
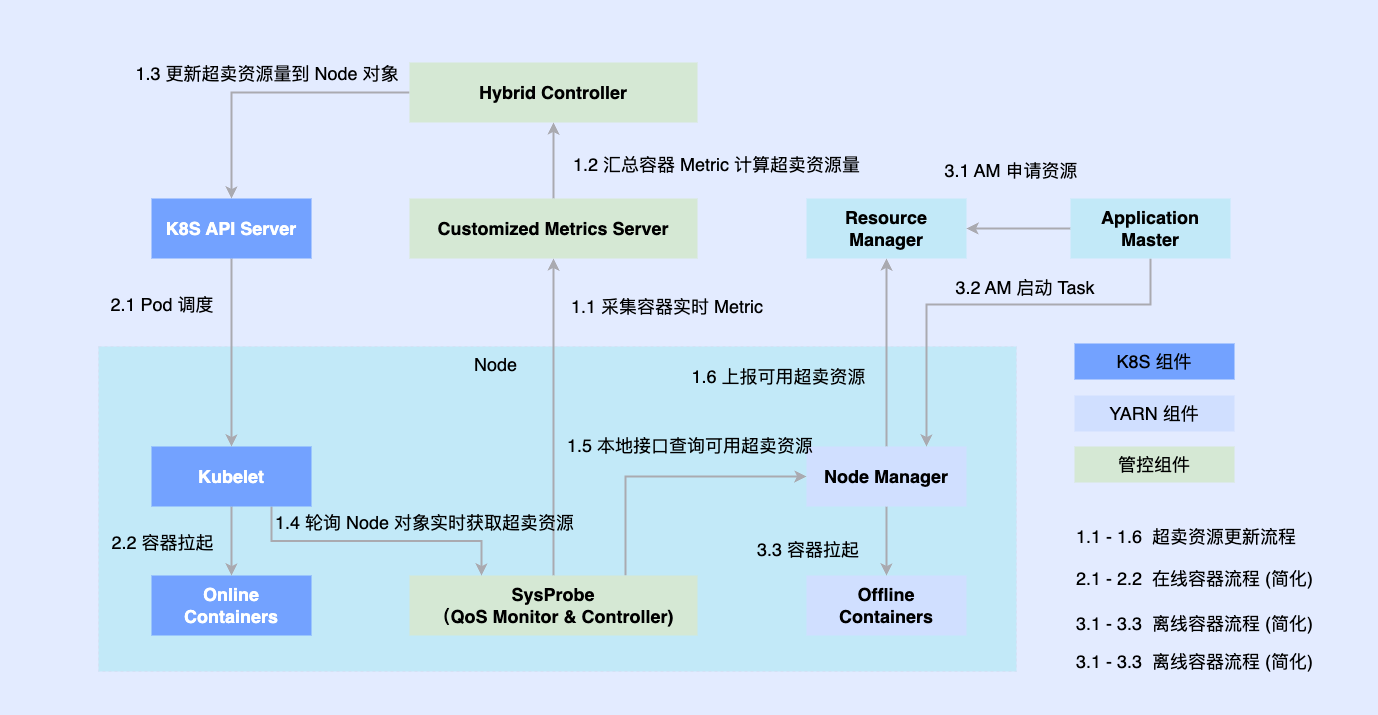
2.2 2단계: Kubernetes/YARN 공동 배포
위의 문제를 해결하기 위해 2단계로 진입하여 하나의 노드에서 오프라인과 온라인을 동시에 실행해 보았습니다.
온라인 부분은 이전에 Kubernetes를 기반으로 기본적으로 변환되었으므로 대부분의 오프라인 작업은 여전히 YARN을 기반으로 실행됩니다. 하이브리드 배포를 촉진하기 위해 단일 시스템에 타사 구성 요소를 도입하여 온라인과 오프라인으로 조정되는 리소스의 양을 결정하고 동시에 Kubelet 또는 Node Manager와 같은 독립형 구성 요소와 연결합니다. 온라인 및 오프라인 워크로드는 노드에 예약되고 노드에 의해 조정됩니다. 조정 구성 요소는 두 워크로드에 대한 리소스 할당을 비동기적으로 업데이트합니다.
이 계획을 통해 코로케이션 역량의 예비 축적을 완료하고 타당성을 검증할 수 있지만 여전히 몇 가지 문제가 있습니다.
- 두 시스템은 비동기식으로 실행되므로 오프라인 컨테이너는 관리 및 제어만 우회할 수 있으며 경합이 발생하고 중간 링크에서 너무 많은 리소스 손실이 발생합니다.
- 오프라인 작업 부하를 간단하게 추상화하므로 복잡한 QoS 요구 사항을 설명할 수 없습니다.
- 오프라인 메타데이터의 단편화로 인해 극단적인 최적화가 어려워지고 글로벌 스케줄링 최적화를 달성할 수 없습니다.
2.3 3단계: 통합 예약 및 오프라인 혼합 배포
두 번째 단계의 문제를 해결하기 위해 세 번째 단계에서는 통합 오프라인 하이브리드 배포를 완전히 실현했습니다.
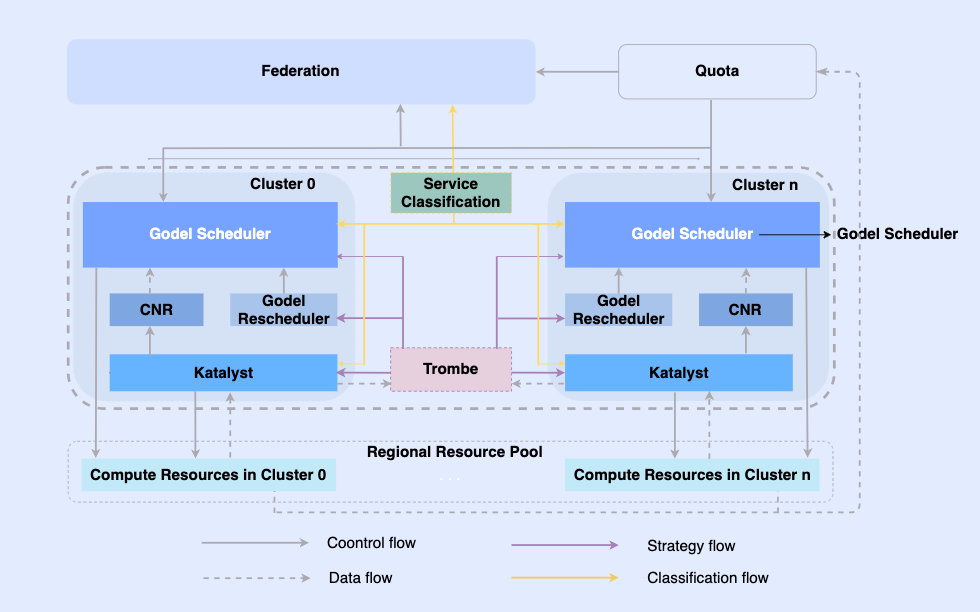
오프라인 작업을 클라우드 네이티브로 만들어 동일한 인프라에서 작업을 예약하고 리소스를 관리할 수 있습니다. 이 시스템에서 최상위 계층은 다중 클러스터 리소스 관리를 실현하기 위한 통합 리소스 연합입니다. 단일 클러스터에는 중앙 통합 스케줄러와 독립형 통합 리소스 관리자가 함께 작동하여 오프라인 통합 리소스 관리 기능을 달성합니다. .
이 아키텍처에서 Katalyst는 핵심 리소스 관리 및 제어 계층 역할을 하며 단일 머신 측에서 실시간 리소스 할당 및 추정을 구현하는 역할을 담당합니다.
- 추상화 표준화: 오프라인 메타데이터를 개방하고 QoS 추상화를 더욱 복잡하고 풍부하게 만들고 비즈니스 성능 요구 사항을 더 잘 충족시킵니다.
- 관리 및 제어 동기화: 관리 및 제어 정책은 시작 후 리소스 조정의 비동기 수정을 방지하기 위해 컨테이너가 시작될 때 발행되며 정책의 무료 확장을 지원합니다.
- 지능형 전략: 서비스 초상화를 구축하면 리소스 수요를 미리 감지하고 보다 스마트한 리소스 관리 및 제어 전략을 구현할 수 있습니다.
- 운영 및 유지보수 자동화 : 통합 납품을 통해 운영 및 유지보수 자동화 및 표준화가 이루어집니다.
3. 카탈리스트 시스템 소개
Katalyst는 원래 촉매를 의미하는 영어 단어 Catalyst에서 파생되었습니다. 첫 글자가 K로 변경되었습니다. 이는 시스템이 Kubernetes 시스템에서 실행되는 모든 로드에 대해 보다 강력한 자동화된 리소스 관리 기능을 제공할 수 있음을 의미합니다.
3.1 Katalyst 시스템 개요
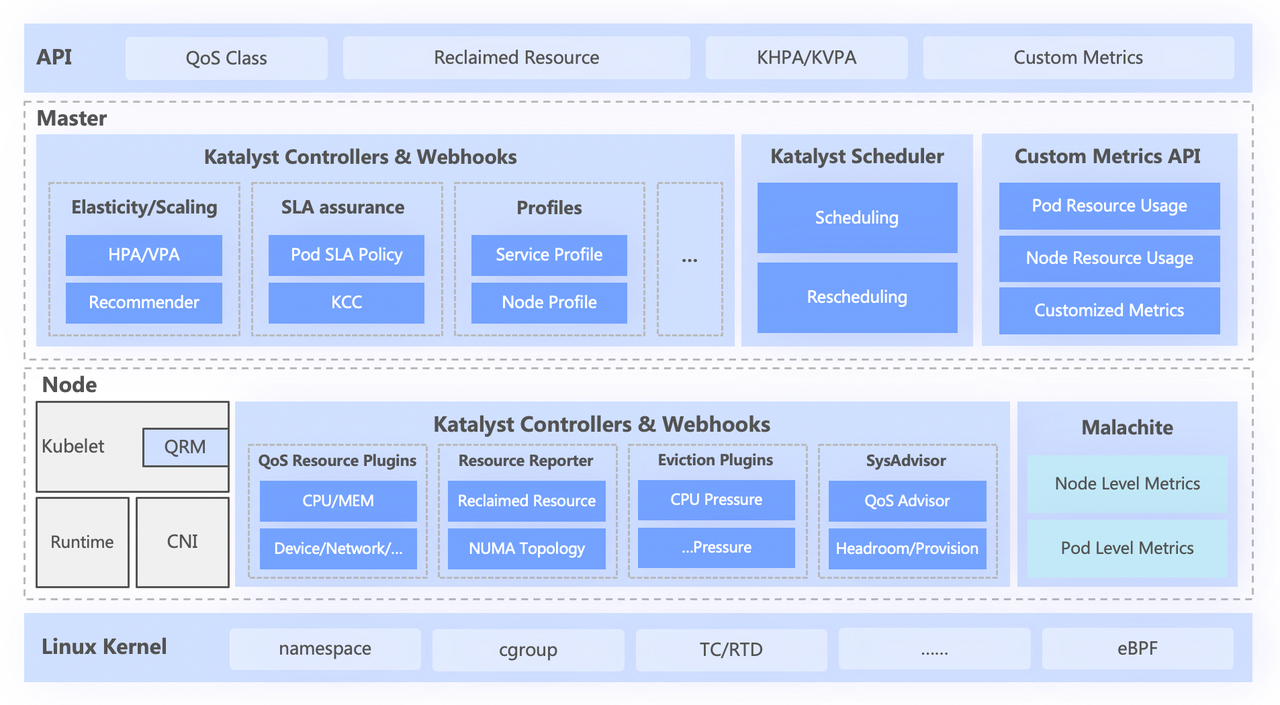
Katalyst 시스템은 대략 다음과 같은 4개 계층으로 나뉩니다.
- 최상위 표준 API는 사용자를 위해 다양한 QoS 수준을 추상화하고 풍부한 리소스 표현 기능을 제공합니다.
- 중앙 계층은 통합 일정 관리, 리소스 추천, 서비스 초상화 구축과 같은 기본 기능을 담당합니다.
- 독립형 레이어에는 자체 개발한 데이터 모니터링 시스템과 실시간 할당 및 리소스 동적 조정을 담당하는 리소스 할당자가 포함됩니다.
- 맨 아래 계층은 바이트 맞춤형 커널로, 커널 패치와 기본 격리 메커니즘을 강화하여 오프라인으로 실행할 때 단일 시스템 성능 문제를 해결합니다.
3.2 추상적인 표준화: QoS 클래스
Katalyst QoS는 거시적 관점과 미시적 관점 모두에서 해석될 수 있습니다.
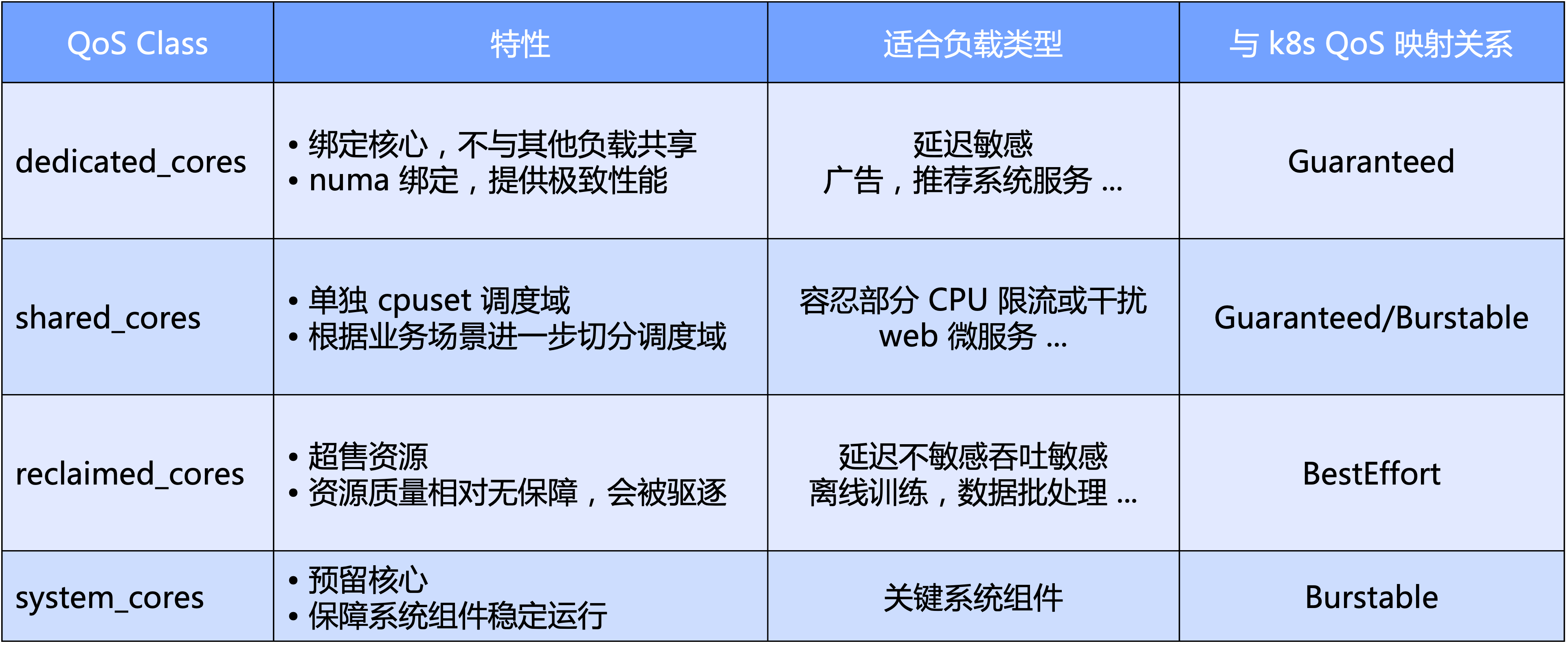
- 거시적 수준에서 Katalyst는 CPU의 기본 차원을 기반으로 표준 QoS 수준을 정의합니다. 특히 QoS를 독점, 공유, 재활용 및 주요 시스템 구성 요소용으로 예약된 시스템 유형의 네 가지 범주로 나눕니다.
- 미시적 관점에서 Katalyst의 최종 기대치는 어떤 종류의 워크로드이든 하드 커팅을 통해 클러스터를 격리할 필요 없이 동일한 노드의 풀에서 실행될 수 있어 더 나은 리소스 트래픽 효율성과 리소스 활용도를 달성할 수 있다는 것입니다. 능률.
QoS를 기반으로 Katalyst는 CPU 코어 외에 다른 리소스 요구 사항을 표현하기 위한 풍부한 확장 기능 향상도 제공합니다.
- QoS 향상: NUMA/네트워크 카드 바인딩, 네트워크 카드 대역폭 할당, IO 가중치 등과 같은 다차원 리소스에 대한 비즈니스 요구 사항의 확장된 표현입니다.
- Pod 향상: CPU 스케줄링 지연이 비즈니스 성능에 미치는 영향 등 다양한 시스템 지표로 비즈니스 민감도 표현을 확장합니다.
- 노드 향상: 기본 TopologyPolicy를 확장하여 여러 리소스 차원에서 마이크로 토폴로지의 결합된 요구 사항을 표현합니다.
3.3 관리 및 제어 동기화: QoS 자원 관리자
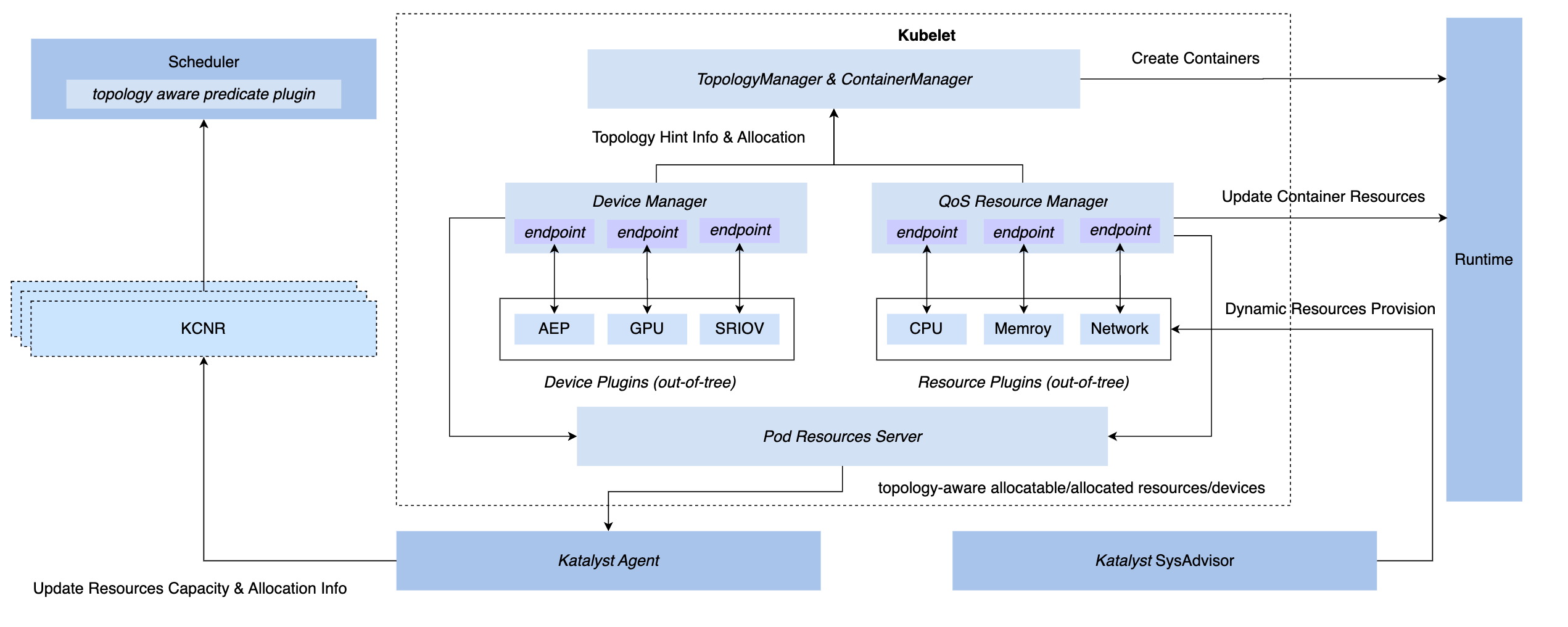
为在 K8s 体系下实现同步管控的能力,我们有三种 hook 方式:CRI 层插、OCI 层、Kubelet 层;最终 Katalyst 选择在 Kubelet 侧实现管控,即实现和原生的 Device Manager 同层级的 QoS Resource Manager,该方案的优势包括
- 在 admit 阶段实现拦截,无需在后续步骤靠兜底措施来实现管控
- 与 Kubelet 进行元数据对接,将单机微观拓扑信息通过标准接口报告到节点 CRD,实现与调度器的对接
- 在此框架上,可以灵活实现可插拔的 plugin,满足定制化的管控需求
3.4 策略智能化:服务画像和资源预估
通常,选择使用业务指标构建服务画像比较直观,例如服务 P99 延迟或者下游的错误率。但其也存在一些问题,比如相对系统指标而言,业务指标的获取通常更不容易;业务通常会集成多个的框架,他们生产的业务指标含义并不完全相同,如果强依赖这些指标,整个管控的实现就会变得非常复杂。
因此,我们希望最终的资源调控或服务画像是基于系统指标而非业务指标来实现;其中最关键的就是如何找到业务最关心的系统指标,我们的做法是使用一套离线的 pipeline 去发现业务指标和系统指标之间的匹配。例如,对于图中服务来说,最核心的业务指标是 P99 延迟,通过分析发现与其相关度最高的系统指标是 CPU 调度延迟,我们会不断调整服务的资源供应量,尽可能地逼近它的目标 CPU 调度延迟。
在服务画像的基础上,Katalyst 针对 CPU、内存、磁盘和网络等方面提供了丰富的隔离机制,必要时还对内核进行了定制以提供更强的性能要求;然而对于不同的业务场景和类型,这些手段并不一定适用,因此需要强调的是隔离更多是一种手段而不是目的,我们在承接业务的过程中需要根据具体的需求和场景来选择不同的隔离方案。
3.5 运维自动化:多维度动态配置管理
尽管我们希望所有的资源都在一个资源池系统下,但是对于在大规模生产环境中,不可能把所有节点都放在一个集群里;此外,一个集群中可能同时有 CPU 与 GPU 的机器,虽然可以共享控制面,但在数据面上需要一定的隔离;在节点级别,我们也经常需要修改节点维度配置以进行灰度验证,导致在同一节点上运行的不同服务的 SLO 存在差异。
为解决这些问题,我们需要在业务部署时,考虑节点的不同配置对服务的影响。为此,Katalyst 针对标准交付提供了动态配置管理的能力,通过自动化的方法评估不同节点的性能和配置,并根据这些结果来选择最适合该服务的节点。
4. Katalyst 混部应用与案例分析
在该部分我们将结合字节内部的案例分享一些最佳的实践。
4.1 利用率效果
从 Katalyst 实施效果上来说,基于字节内部业务的实践,我们在季度周期内,资源都可以保持在相对较高的状态;在单个集群中,每天的各个时间段内资源利用率也呈现出比较稳定的分布;同时,集群中大部分机器利用率也比较集中,我们的混合部署系统在所有节点上运行都比较稳定。
| 资源预估算法 | Reclaimed 资源比例 | 天级平均 cpu 利用率 | 天级峰值 cpu 利用率 |
|---|---|---|---|
| 利用率固定 buffer | 0.26 | 0.33 | 0.58 |
| k-means 聚类算法 | 0.35 | 0.48 | 0.6 |
| 系统指标 PID 算法 | 0.39 | 0.54 | 0.66 |
| 系统指标 模型预估 + PID 算法 | 0.42 | 0.57 | 0.67 |
4.2 实践:离线无感接入
在进入第三阶段后,我们需要对离线进行云原生化改造。改造方式主要有两种,一种是已经在 K8s 体系中的服务,我们将基于 Virtual Kubelet 的方式实现资源池的直接打通;另外一种 YARN 架构下的服务,如果直接基于 Kubernetes 体系对业务接入框架进行彻底的改造,则对于业务来说成本非常高,理论上会导致所有业务都滚动升级,这显然不是一个理想的状态。
为了解决这个问题,字节引用 Yodel 的胶水层,即业务接入仍然使用标准的 Yarn API;但在这个胶水层中,我们将与底层 K8s 语义对接,将用户对资源的请求抽象为像 Pod 或容器的描述。这种方法使得我们在底层使用更成熟的 K8s 技术来管理资源,实现对离线的云原生化改造,同时又保证了业务的稳定性。
4.3 实践:资源运营治理
在混部过程中,我们需要对大数据和训练框架进行适配改造,做好各种重试、checkpoint 和分级,才能确保在我们将这些大数据和训练作业切到整个混部资源池之后,它们的使用体验不至于太差。
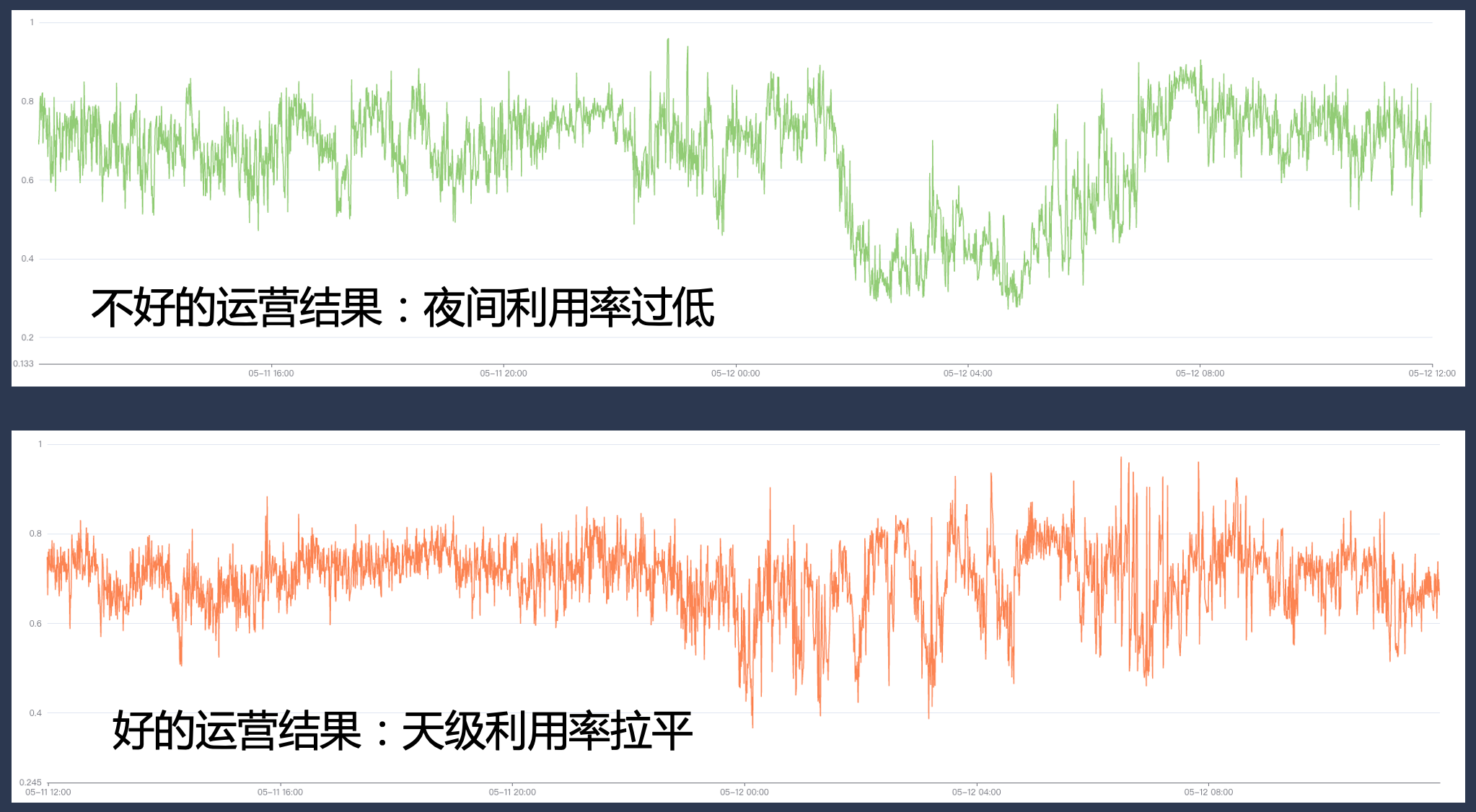
同时,在系统上我们需要具备完善的资源商品、业务分级、运营治理以及配额管理等方面的基础能力。如果运营做得不好,可能使得在某些高峰时段将利用率拉得很高,但在其他时段可能会出现较大的资源缺口,从而导致利用率无法达到预期。
4.4 实践:极限资源效率提升
在构建服务画像时我们采用的是基于系统指标去做管控,但基于离线分析得到的静态系统指标无法实时跟上业务侧的变化,需要在一定时间周期内分析业务性能的变化来调整静态值。
为此,Katalyst 引入了模型来微调系统指标。例如,如果我们认为 CPU 调度延迟可能是 x 毫秒,过一段时间后,通过模型算出业务目标延迟可能是 y 毫秒,我们就可以动态地调整该目标的值,以更好地评估业务性能。
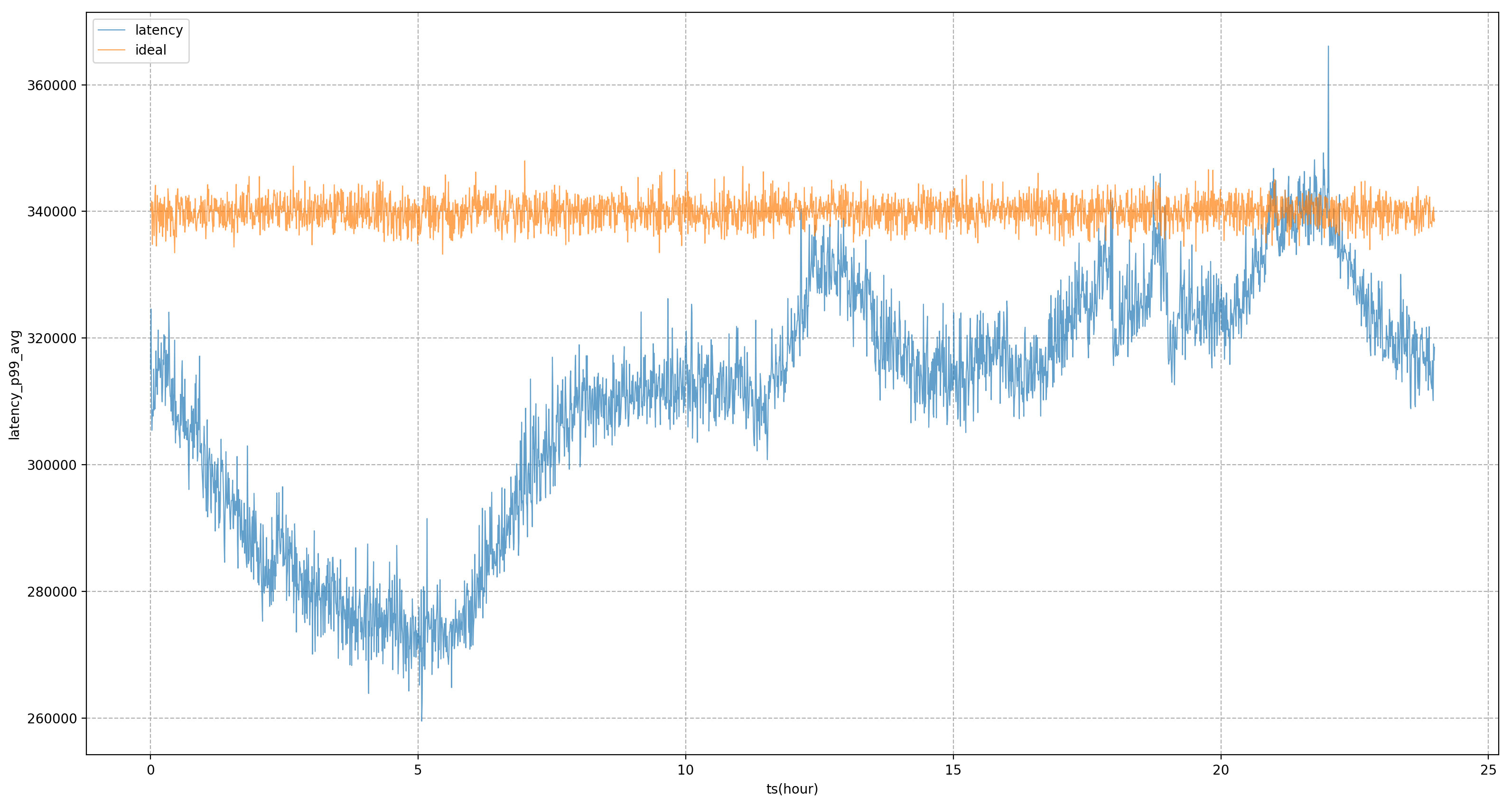
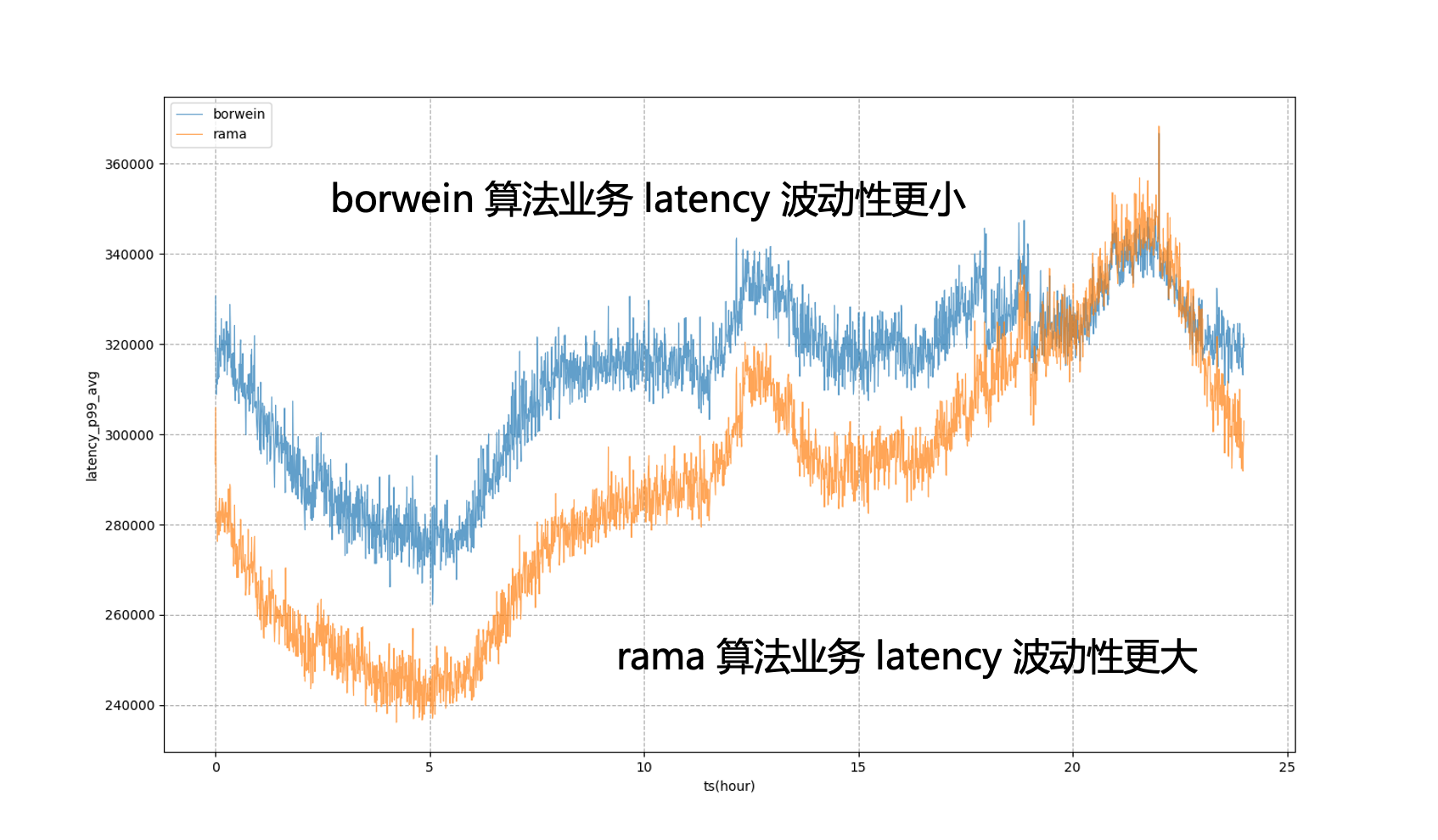
以下图为例,完全使用静态的系统目标来进行调控,业务 P99 将处于剧烈波动状态,这意味着在非晚高峰时段,我们无法将业务资源使用压榨到更极致的状态,使其更接近业务在晚高峰时可承受的量;引入模型后,可以看到业务延迟会更加平稳,使得我们可以全天将业务的性能拉平到一个相对平稳的水平,获得资源的收益。
4.5 实践:解决单机问题
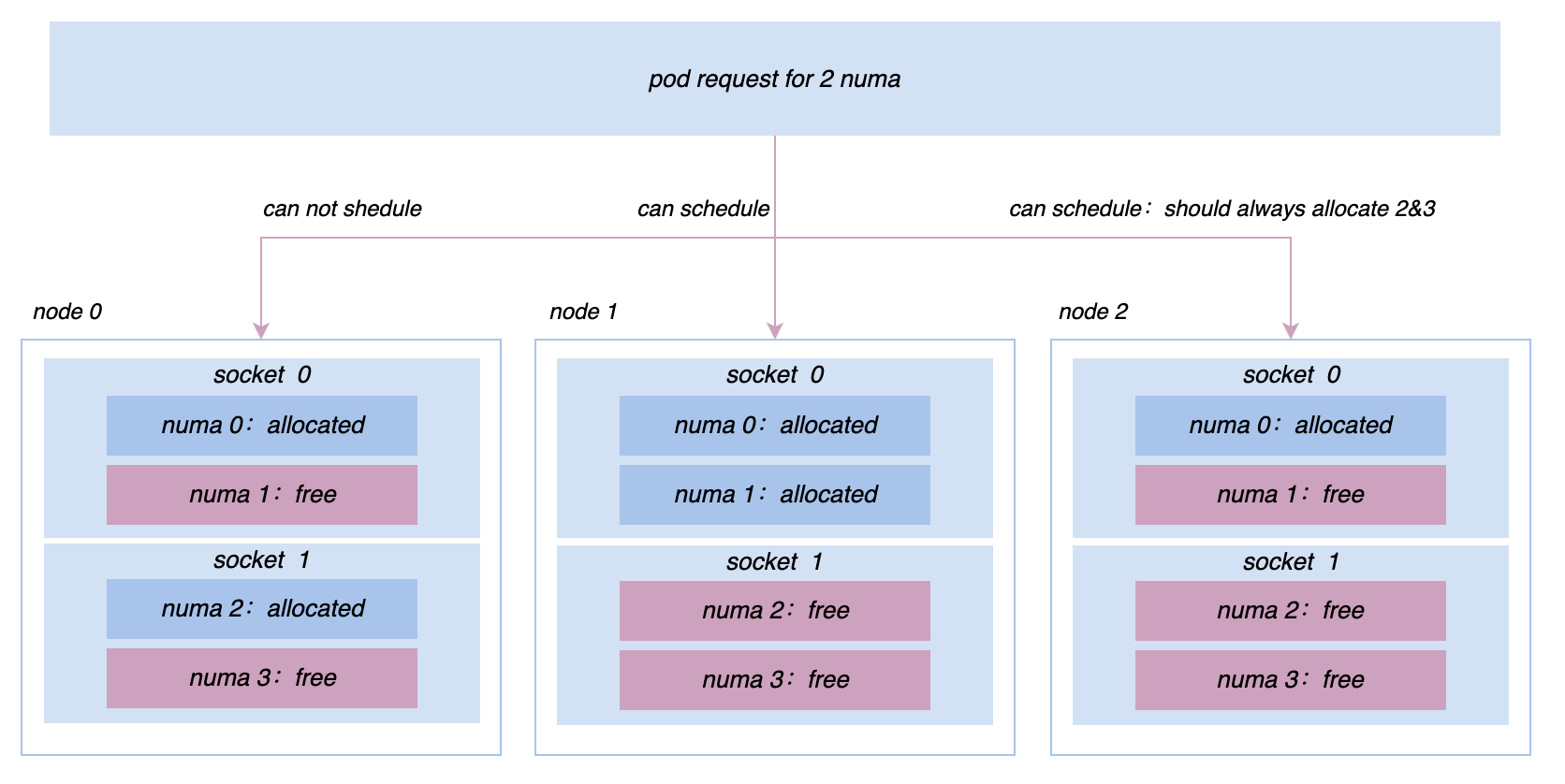
在混部推进的过程中,我们会不断遇到在线和离线各种性能问题和微拓扑管理的诉求。例如,最初所有机器都是基于cgroup V1 进行管控,然而由于 V1 的结构会使得系统需要遍历很深的目录树,消耗大量 内核态 CPU,为了解决该问题,我们在将整个集群中的节点切换到 cgroup V2 架构,使得我们能够更加高效地进行资源隔离和监控;对于推广搜等服务来说,为追求更加极致的性能,我们需要在 Socket/NUMA 级别实现更加复杂的亲和与反亲和策略等等,这些更加高阶的资源管理需求,在 Katalyst 中都可以更好地实现。
5 总结展望
Katalyst 已正式开源并发布 v0.3.0 版本,后续将会持续投入更多精力进行迭代;社区将在资源隔离、流量画像、调度策略、弹性策略、异构设备管理等多方面进行能力建设和系统增强,欢迎大家关注、参与该项目并提供反馈意见。
동료 치킨 "오픈 소스" deepin-IDE 및 마침내 부트스트랩을 달성했습니다! 좋은 친구, Tencent는 Switch를 "생각하는 학습 기계"로 전환했습니다. Tencent Cloud의 4월 8일 실패 검토 및 상황 설명 RustDesk 원격 데스크톱 시작 재구성 웹 클라이언트 WeChat의 SQLite 기반 오픈 소스 터미널 데이터베이스 WCDB의 주요 업그레이드 TIOBE 4월 목록: PHP 사상 최저치로 떨어졌고 FFmpeg의 아버지인 Fabrice Bellard는 오디오 압축 도구인 TSAC를 출시했으며 Google은 대규모 코드 모델인 CodeGemma를 출시했습니다 . 오픈소스라서 너무 좋아요 - 오픈소스 사진 및 포스터 편집기 도구