
디지털 시대에 데이터는 기업의 가장 귀중한 자산 중 하나입니다. 그러나 데이터 양이 증가함에 따라 데이터베이스 관리도 복잡해졌습니다. 데이터베이스 오류는 비즈니스 중단을 초래하고 회사에 막대한 재정적 손실과 평판 손실을 초래할 수 있습니다. 이 블로그에서는 KaiwuDB가 결함 진단 도구를 설계하는 방법과 구체적인 예제 데모를 공유합니다.
01 디자인 아이디어
핵심 원칙을 따르세요
- 사용자 친화적: 다양한 기술 수준을 가진 사용자라도 우리 도구를 쉽게 사용할 수 있습니다.
- 포괄적인 모니터링: 성능 지표, 시스템 리소스 및 쿼리 효율성을 포함하여 데이터베이스 시스템의 모든 측면을 포괄적으로 모니터링합니다.
- 지능형 진단: 고급 알고리즘을 활용하여 문제의 근본 원인을 식별합니다.
- 자동 복구: 원클릭 복구 제안을 제공하고 가능한 경우 이러한 복구를 자동으로 적용합니다.
- 확장성: 사용자가 특정 요구 사항에 맞게 도구 기능을 확장하고 사용자 지정할 수 있습니다.
주요 지표 수집 지원
포괄적인 진단을 보장하기 위해 이 도구는 다음을 포함하되 이에 국한되지 않는 일련의 주요 지표를 수집합니다.
- 시스템 구성: 데이터베이스 버전, 운영 체제, CPU 아키텍처 및 번호, 메모리 용량, 디스크 유형 및 용량, 마운트 지점, 파일 시스템 유형
- 배포 상황: 베어메탈 배포인지 컨테이너 배포인지, 데이터베이스 인스턴스의 배포 모드 및 노드 수 데이터 구성: 데이터 디렉터리 구조, 로컬 및 클러스터 구성, 시스템 테이블 및 매개변수
- 데이터베이스 통계: 비즈니스 데이터베이스 수, 각 데이터베이스 및 테이블 구조 아래의 테이블 수
- 컬럼 특성: 숫자 컬럼 및 열거 컬럼의 통계적 특성, 문자열 컬럼의 길이 및 특수문자 검출;
- 로그 파일: 관계 로그, 타이밍 로그, 오류 로그, 감사 로그;
- PID 정보: 데이터베이스 프로세스에 의해 열린 핸들 수, 열린 MMAP 수, 통계 및 기타 정보
- 성능 데이터: SQL 실행 계획, 시스템 모니터링 데이터(CPU, 메모리, I/O), 인덱스 사용량 및 효율성, 데이터 액세스 패턴, 잠금(트랜잭션 충돌 및 대기 이벤트), 시스템 이벤트 등
다양한 작동 모드 지원
이 도구는 다양한 시나리오의 요구 사항을 충족하기 위해 두 가지 작동 모드를 제공합니다.
- 일회성 수집: 즉각적인 문제 진단에 적합한 현재 시스템 상태 및 성능 데이터를 신속하게 캡처합니다.
- 예약 수집: 장기적인 성능 모니터링 및 추세 분석을 위해 미리 설정된 계획에 따라 정기적으로 데이터를 수집합니다.
다양한 트렌드 분석에 적응
수집된 데이터는 다음과 같은 기능을 통해 추세 분석을 수행하는 데 사용됩니다.
- 성능 추세: 시간 경과에 따른 데이터베이스 성능 추세를 식별하고 잠재적인 성능 병목 현상을 예측합니다.
- 리소스 사용량: 시스템 리소스 사용량을 추적하고 리소스 할당 최적화를 돕습니다.
- 로그 분석: 로그 파일을 분석하여 비정상적인 패턴과 빈번한 오류를 식별합니다.
- 쿼리 최적화: SQL 실행 계획을 분석하여 쿼리 최적화 제안을 제공합니다.
- 모범 사례: 데이터 배포 및 하드웨어 리소스에 대한 포괄적인 분석을 통해 최적의 구성 권장 사항을 제공합니다.
02 전체 아키텍처
결함 진단 도구는 수집과 분석의 두 부분으로 나뉩니다.
- 수집 부분은 대상 운영 체제/데이터베이스/모니터링 서버에 연결되어 로컬 규칙의 단순화된 분석을 지원하고 일반 텍스트 보고서를 출력합니다.
- 분석 부분은 수집된 데이터를 읽어 형식화한 후 분석 서버에 업로드하여 지속성을 위해 온라인 규칙에 대한 상세 분석 및 예측을 지원하고 UI를 통해 상세 보고서를 출력합니다.
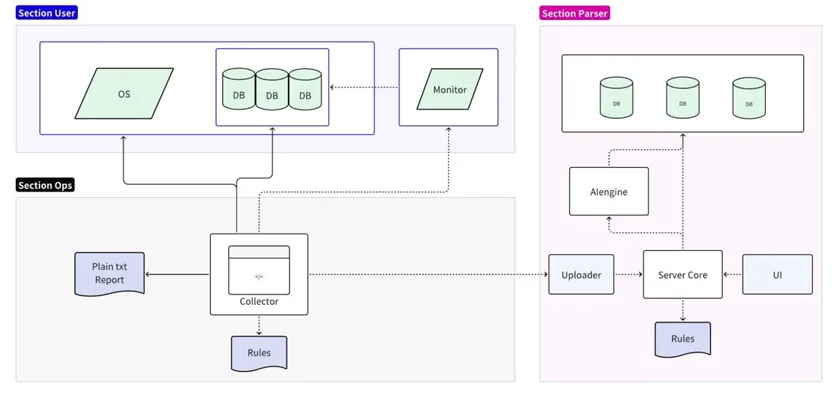
수집기 구현
수집기는 운영 및 유지보수 담당자가 현장에서 직접 사용하는 도구로 운영 체제, 데이터베이스, 모니터링 서비스를 통해 현장의 다양한 원본 정보를 얻습니다. 기본적으로 수집 후 압축 및 직접 내보내기가 지원됩니다. 또한 로컬 규칙을 사용하여 모든 오류 메시지 찾기 및 인쇄와 같은 가장 기본적인 분석을 수행할 수도 있습니다.

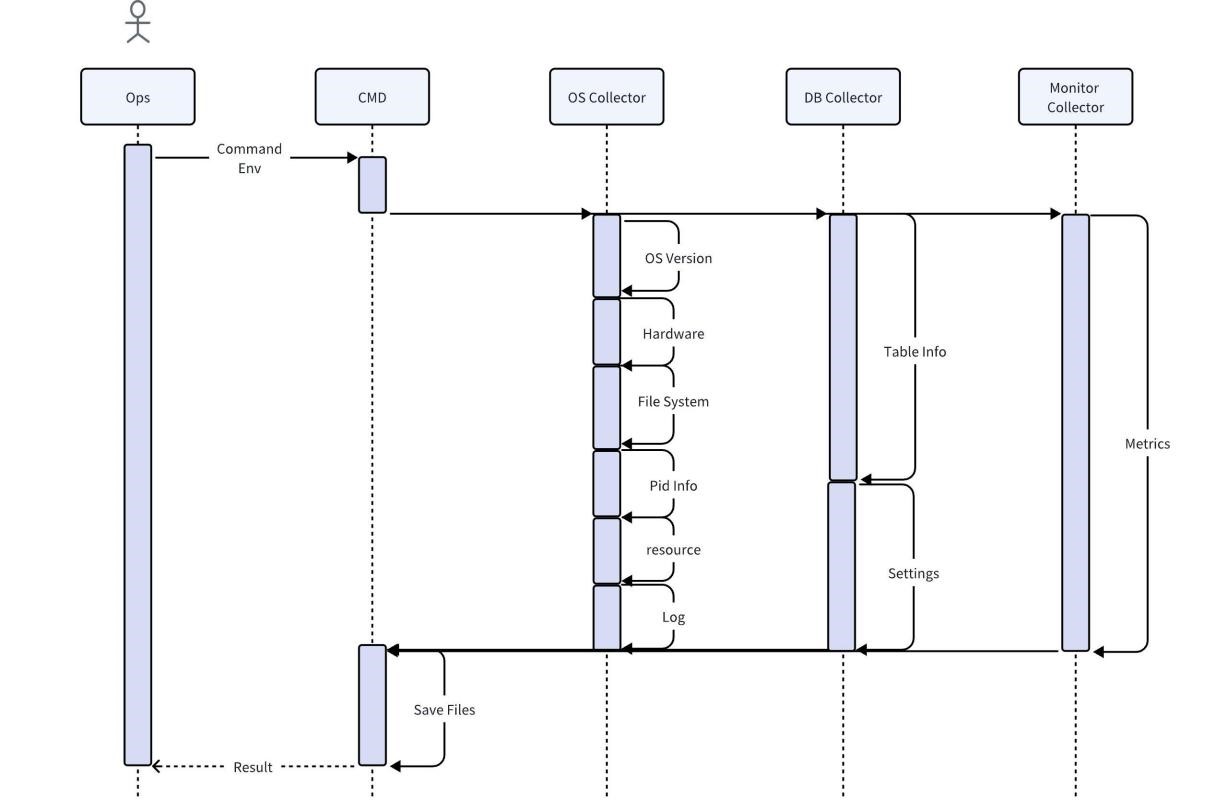
사용자 비즈니스 데이터를 직접 수집할 경우 사용자 정보가 노출될 위험이 있다는 점을 고려하여, 데이터베이스 수집기의 수집 과정에서는 사용자의 데이터 특성만 캡처하고 데이터는 복사하지 않습니다. 기타 데이터의 완전성과 정확성을 보장하기 위해 수집된 데이터는 분석 전에 어떠한 방식으로도 처리되지 않으며, 완전한 정보 제공을 위해 필요한 데이터는 유지됩니다. 공간을 절약하려면 수집된 데이터를 압축해야 합니다. 동시에 수집기는 대부분의 운영 체제와 호환되어야 하며 추가 종속성이 필요하지 않습니다.
규칙 엔진 구현
후속 데이터 분석을 위해서는 규칙 엔진이 데이터 수집기와 호환되어 표준화된 데이터 출력을 제공하고 특정 확장성을 가져야 합니다. 예를 들어, 특정 SQL이 실행될 때 CPU 사용량 증가를 분석하려면 SQL 쿼리의 메타데이터(SQL 텍스트, 실행 시간 등)와 성능 지표(CPU 사용량 등)를 출력해야 합니다. 성능 병목 현상을 분석하기 위한 타이밍 엔진의 형식.
충분한 확장성을 제공하고 오류 코드 검사와 같은 기능적 문제를 포함하여 끊임없이 확장되는 규칙 세트를 처리할 수 있도록 규칙 엔진은 외부 파일에서 규칙을 읽은 다음 이러한 규칙을 적용하여 데이터를 분석합니다. 다음은 몇 가지 코드 예입니다.
Python
import pandas as pd
import json
# 加载规则
def load\_rules(rule\_file):
with open(rule_file, 'r') as file:
return json.load(file)
# 自定义规则函数,这个函数将检查特定SQL执行时CPU使用率是否有显著增加
def sql\_cpu\_bottleneck(row, threshold):
# 比较当前行的CPU使用率是否超过阈值
return row\['sql\_query'\] == 'SELECT * FROM table\_name' and row\['cpu_usage'\] > threshold
# 应用规则
def apply\_rules(data, rules\_config, custom_rules):
for rule in rules_config:
data\[rule\['name'\]\] = data.eval(rule\['expression'\])
for rule\_name, custom\_rule in custom_rules.items():
data\[rule\_name\] = data.apply(custom\_rule, axis=1)
return data
# 读取CSV数据
df = pd.read\_csv('sql\_performance_data.csv')
# 加载规则
rules\_config = load\_rules('rules.json')
# 定义自定义规则
custom_rules = {
'sql\_cpu\_bottleneck': lambda row: sql\_cpu\_bottleneck(row, threshold=80)
}
# 应用规则并得到结果
df = apply\_rules(df, rules\_config, custom_rules)
# 输出带有规则检查结果的数据
df.to\_csv('evaluated\_sql_performance.csv', index=False)
규칙 파일은 버전 반복을 통해 지속적으로 확장되어야 하며 핫 업데이트를 지원해야 합니다. 다음은 JSON 형식의 규칙 구성 파일의 예입니다. 규칙은 각각 Pandas DataFrame에서 이해하는 이름과 표현식을 포함하는 JSON 개체로 정의됩니다.
JSON
\[
{
"name": "high\_execution\_time",
"expression": "execution_time > 5"
},
{
"name": "general\_high\_cpu_usage",
"expression": "cpu_usage > 80"
},
{
"name": "slow_query",
"expression": "query_time > 5"
},
{
"name": "error\_code\_check",
"expression": "error_code not in \[0, 200, 404\]"
}
// 其他规则可以在此添加
\]
예측 실현
진단 도구를 예측 엔진에 연결하여 잠재적인 위험을 사전에 감지할 수 있습니다. 다음 예에서는 scikit-learn 의사결정 트리 분류자를 사용하여 모델을 훈련하고 모델을 사용하여 예측합니다.
Python
from sklearn.tree import DecisionTreeClassifier
from sklearn.model\_selection import train\_test_split
from sklearn.metrics import accuracy_score
# 读取CSV数据
df = pd.read\_csv('performance\_data.csv')
# 假设我们已经有了一个标记了性能问题的列 'performance_issue'
# 这个列可以通过规则引擎或历史数据分析得到
# 特征和标签
X = df\[\['cpu\_usage', 'disk\_io', 'query_time'\]\]
y = df\['performance_issue'\]
# 分割数据集为训练集和测试集
X\_train, X\_test, y\_train, y\_test = train\_test\_split(X, y, test\_size=0.2, random\_state=42)
# 创建决策树模型
model = DecisionTreeClassifier()
# 训练模型
model.fit(X\_train, y\_train)
# 预测测试集
y\_pred = model.predict(X\_test)
# 打印准确率
print(f'Accuracy: {accuracy\_score(y\_test, y_pred)}')
# 保存模型,以便以后使用
import joblib
joblib.dump(model, 'performance\_predictor\_model.joblib')
# 若要使用模型进行实时预测
def predict\_performance(cpu\_usage, disk\_io, query\_time):
model = joblib.load('performance\_predictor\_model.joblib')
prediction = model.predict(\[\[cpu\_usage, disk\_io, query_time\]\])
return 'Issue' if prediction\[0\] == 1 else 'No issue'
# 示例:使用模型预测一个新的数据点
print(predict_performance(85, 90, 3))
03 샘플 시연
가상 시나리오: 당신은 사물 인터넷 회사의 IT 전문가이며 장치 상태 데이터를 처리하기 위한 시계열 데이터베이스의 쿼리 응답 시간이 특정 기간에 매우 느린 것을 발견했습니다.
데이터 수집
귀하가 사용하는 데이터베이스 진단 도구는 다음과 같은 데이터를 수집하기 시작합니다.
1. 쿼리 로그: 자주 나타나는 쿼리가 발견되고 다른 쿼리보다 실행 시간이 훨씬 길어집니다.
Plaintext
SELECT avg(temperature) FROM device_readings
WHERE device_id = ? AND time > now() - interval '1 hour'
GROUP BY time_bucket('5 minutes', time);Plaintext
2. 실행 계획: 이 쿼리의 실행 계획은 이 SQL이 전체 테이블을 스캔한 다음 device_id를 필터링한다는 것을 보여줍니다.
3. 인덱스 사용법: device_readings 테이블의 device_id에는 TAG 인덱스가 없습니다.
4. 리소스 사용량: 이 쿼리를 실행할 때 CPU 및 I/O 피크입니다.
5. 잠금 및 대기 이벤트 : 비정상적인 잠금 이벤트는 발견되지 않았습니다.
분석 및 패턴 인식
진단 도구는 쿼리 및 실행 계획을 분석하여 다음 패턴을 식별합니다.
- 빈번한 전체 테이블 스캔으로 인해 I/O 및 CPU 로드가 증가합니다.
- 적절한 인덱스가 없으면 쿼리는 데이터를 효율적으로 찾을 수 없습니다.
문제 진단
이 도구는 다음 진단과 일치하는 기본 제공 규칙을 사용합니다. 쿼리 비효율성은 적절한 인덱스가 부족하여 발생합니다.
제안 생성
이 패턴을 기반으로 진단 도구는 다음 권장 사항을 생성합니다. device_readings 테이블의 device_id 필드에 TAG 인덱스를 생성합니다.
권장 사항 구현
데이터베이스 관리자는 다음 SQL 문을 실행하여 인덱스를 생성합니다.
SQL
ALTER TABLE device\_readings ADD TAG device\_id;
검증 결과
인덱스가 생성된 후 데이터베이스 진단 도구는 데이터를 다시 수집하여 다음을 발견했습니다.
- 이 특정 쿼리의 실행 시간이 크게 단축되었습니다.
- 쿼리 실행 중에 CPU 및 I/O 로드가 정상 수준으로 떨어집니다.
- 홈페이지의 상품 카탈로그 페이지 로딩 시간이 정상으로 돌아왔습니다.
알고리즘 설명
이 예에서 진단 도구는 다음 알고리즘과 논리를 사용합니다.
- 패턴 인식: 쿼리 빈도 및 실행 시간을 감지합니다.
- 상관 분석: 실행 시간이 긴 쿼리를 실행 계획 및 인덱스 사용량과 연관시킵니다.
- 의사결정 트리 또는 규칙 엔진: 전체 테이블 스캔이 발견되고 해당 필드에 인덱스가 없는 경우 인덱스를 생성하는 것이 좋습니다.
- 성능 변화 모니터링: 인덱스를 생성한 후 성능 개선을 모니터링하여 권장 사항의 효과를 확인합니다.