

대규모 모델 응용 프로그램에 대한 심층적인 탐구를 통해 검색 증강 생성 기술은 광범위한 주목을 받았으며 지식 기반 Q&A, 법률 고문, 학습 보조자, 웹 사이트 로봇 등과 같은 다양한 시나리오에 적용되었습니다.
그러나 많은 친구들은 벡터 데이터베이스와 RAG의 관계와 기술 원리에 대해 명확하지 않습니다. 이 기사를 통해 RAG 시대의 새로운 벡터 데이터베이스에 대한 심층적인 이해를 얻을 수 있습니다.
01.
RAG의 광범위한 응용 분야와 고유한 장점
일반적인 RAG 프레임워크는 Retriever와 Generator의 두 부분으로 나눌 수 있습니다. 검색 프로세스에는 데이터 분할(예: Documents), 임베딩 벡터(Embedding) 및 인덱스 구축(Chunks Vector)이 포함되며, 이후 벡터 검색을 통해 관련 결과가 호출됩니다. , 생성 프로세스에서는 검색 결과(Context)를 기반으로 향상된 프롬프트를 사용하여 LLM을 활성화하여 답변(Result)을 생성합니다.
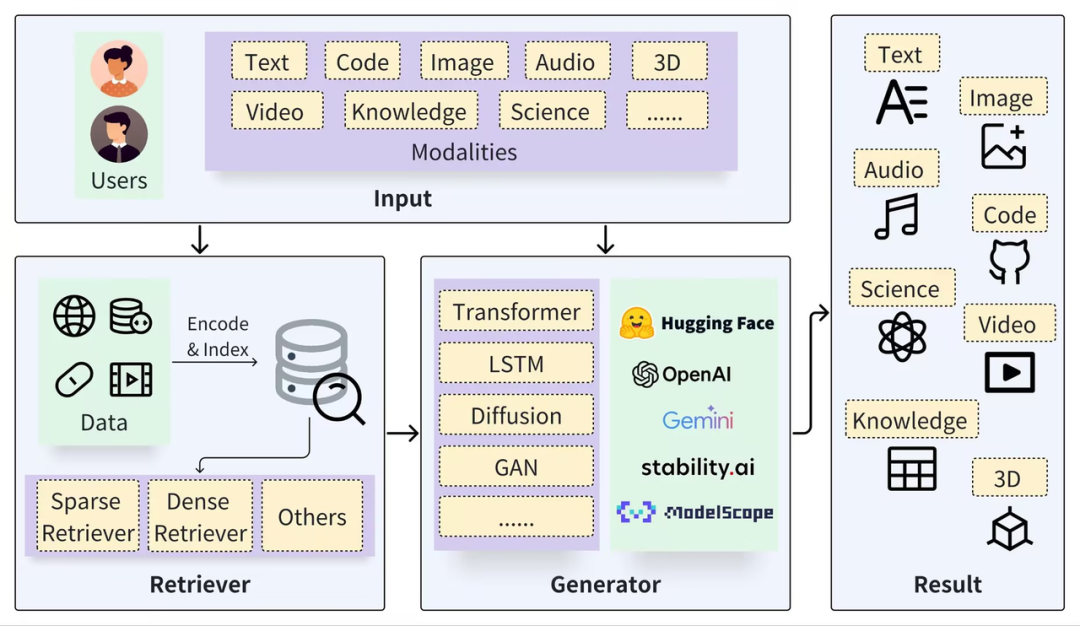
https://arxiv.org/pdf/2402.19473
RAG 기술의 핵심은 구체적이고 관련성 있는 사실과 데이터를 제공하는 검색 시스템과 답변을 유연하게 구성하고 더 넓은 맥락과 정보를 통합하는 생성 모델이라는 두 가지 접근 방식의 장점을 결합한다는 것입니다 . 이러한 조합을 통해 RAG 모델은 복잡한 쿼리를 처리하고 정보가 풍부한 답변을 생성하는 데 매우 효과적입니다. 이는 질문 응답 시스템, 대화 시스템 및 자연어를 이해하고 생성해야 하는 기타 애플리케이션에 매우 유용합니다. 기본 대규모 모델과 비교할 때 RAG와의 페어링은 자연스러운 보완적 이점을 형성할 수 있습니다.
"환각" 문제 방지: RAG는 외부 정보를 입력으로 검색하여 대형 모델이 질문에 답하도록 지원합니다. 이 방법은 부정확하게 생성된 정보에 대한 질문을 크게 줄이고 답변의 추적성을 높일 수 있습니다.
데이터 개인 정보 보호 및 보안: RAG는 지식 기반을 외부 첨부 파일로 사용하여 기업이나 기관의 개인 데이터를 관리함으로써 모델 학습 후 통제할 수 없는 방식으로 데이터가 유출되는 것을 방지할 수 있습니다.
정보의 실시간 특성: RAG를 사용하면 외부 데이터 소스에서 정보를 실시간으로 검색할 수 있으므로 최신 도메인별 지식을 얻을 수 있고 지식 적시성 문제를 해결할 수 있습니다.
위의 문제를 해결하기 위해 개인 데이터를 기반으로 한 미세 조정, 모델 자체의 장문 처리 능력 향상 등 대규모 모델에 대한 최첨단 연구도 진행되고 있지만, 이러한 연구는 대형 모델의 고도화를 촉진하는 데 도움이 됩니다. 스케일 모델 기술. 그러나 보다 일반적인 시나리오에서는 RAG가 여전히 안정적이고 신뢰할 수 있으며 비용 효과적인 선택입니다. 주로 RAG에는 다음과 같은 장점이 있기 때문입니다.
화이트박스 모델 : 미세 조정 및 긴 텍스트 처리의 "블랙박스" 효과와 비교하여 RAG 모듈 간의 관계가 더 명확하고 긴밀하여 품질과 신뢰성이 향상될 때 효과 조정 시 더 높은 조작성과 해석성을 제공합니다. 검색 및 회수된 콘텐츠의 (확실성)이 높지 않은 경우 RAG 시스템은 LLM의 개입을 금지하고 말도 안되는 내용을 만드는 대신 "모르겠습니다"라고 직접 응답할 수도 있습니다.
비용 및 응답 속도: RAG는 미세 조정 모델에 비해 훈련 시간이 짧고 비용이 저렴하며 긴 텍스트 처리에 비해 응답 속도가 빠르고 추론 비용이 훨씬 낮다는 장점이 있습니다. 연구 및 실험 단계에서는 효과와 정확성이 가장 매력적이지만 산업 및 산업 구현 측면에서는 비용이 무시할 수 없는 결정적인 요소입니다.
개인 데이터 관리: RAG는 대규모 모델에서 지식 기반을 분리함으로써 안전하고 구현 가능한 실용적인 기반을 제공할 뿐만 아니라 기업의 기존 지식과 새로운 지식을 더 잘 관리하고 지식 의존성 문제를 해결할 수 있습니다. 또 다른 관련 각도는 액세스 제어 및 데이터 관리로, RAG의 기본 데이터베이스에서는 쉽지만 대규모 모델에서는 어렵습니다.
따라서 대형 모델에 대한 연구가 계속 심화되면서 RAG 기술은 대체되지 않고 오히려 오랫동안 중요한 위치를 유지할 것이라고 생각합니다. 이는 주로 RAG를 기반으로 구축된 응용 프로그램이 여러 분야에서 빛을 발할 수 있도록 하는 LLM과의 자연스러운 보완성 때문입니다. RAG 개선의 핵심은 한편으로는 LLM 기능의 개선이고, 다른 한편으로는 검색(Retrieval)의 다양한 개선 및 최적화에 의존합니다.
02.
RAG 검색의 기초: 벡터 데이터베이스
업계 실무에서 RAG 검색은 일반적으로 벡터 데이터베이스와 긴밀하게 통합되며, 이로 인해 CVP 기술 스택이라고 하는 ChatGPT + 벡터 데이터베이스 + 프롬프트를 기반으로 한 RAG 솔루션도 탄생했습니다. 이 솔루션은 벡터 데이터베이스를 사용하여 관련 정보를 효율적으로 검색하여 LLM(대형 언어 모델)을 향상시킵니다. RAG 시스템은 LLM에서 생성된 쿼리를 벡터로 변환하여 벡터 데이터베이스에서 해당 지식 항목을 빠르게 찾을 수 있습니다. 이 검색 메커니즘을 통해 LLM은 특정 문제에 직면할 때 벡터 데이터베이스에 저장된 최신 정보를 활용하여 LLM에 내재된 지식 업데이트 지연 및 착각 문제를 효과적으로 해결할 수 있습니다.
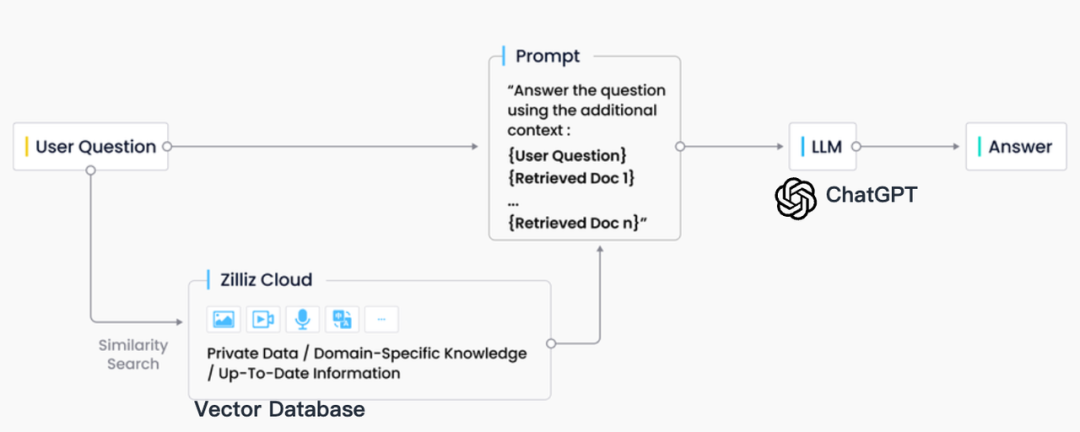
검색 엔진, 관계형 데이터베이스, 문서 데이터베이스 등을 포함하여 정보 검색 분야에는 많은 저장 및 검색 기술이 있지만 벡터 데이터베이스는 RAG 시나리오에서 업계의 첫 번째 선택이 되었습니다. 이러한 선택의 이면에는 많은 수의 삽입된 벡터를 효율적으로 저장하고 검색할 수 있는 벡터 데이터베이스의 뛰어난 기능이 있습니다. 이러한 임베딩 벡터는 기계 학습 모델에 의해 생성되며 텍스트 및 이미지와 같은 여러 데이터 유형을 특성화할 수 있을 뿐만 아니라 심층적인 의미 정보도 캡처할 수 있습니다. RAG 시스템에서 검색 작업은 입력 쿼리의 의미와 가장 잘 일치하는 정보를 빠르고 정확하게 찾는 것이며, 벡터 데이터베이스는 고차원 벡터 데이터 처리 및 빠른 유사 검색 수행에 큰 장점이 있습니다.
다음은 벡터 검색으로 표현되는 벡터 데이터베이스를 다른 기술 옵션과 수평적으로 비교한 것뿐만 아니라 RAG 시나리오에서 이를 주류 선택으로 만드는 주요 요소에 대한 분석입니다.
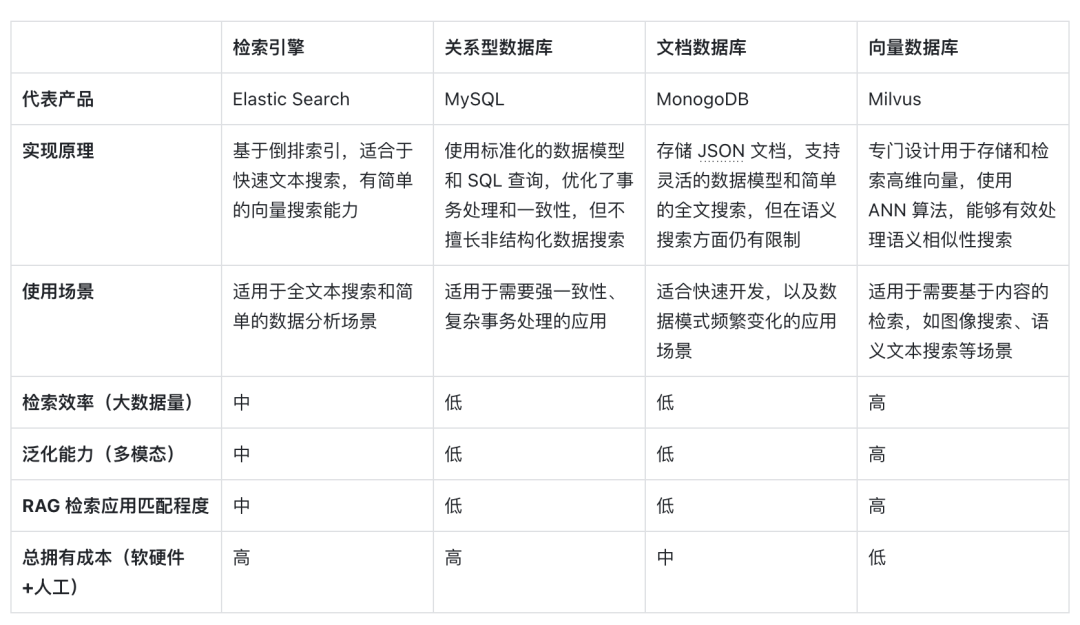
우선, 구현 원리 측면에서 벡터는 모델의 의미론적 의미 인코딩 형식입니다. 벡터 데이터베이스는 단순히 키워드 일치가 아닌 텍스트의 의미를 인코딩하는 딥러닝 모델의 기능을 활용하기 때문에 쿼리의 의미론적 내용을 더 잘 이해할 수 있습니다. . AI 모델의 개발로 인해 의미적 정확성도 꾸준히 향상되고 있습니다. 의미적 유사성을 표현하기 위해 벡터 거리 유사성을 사용하는 것이 NLP의 주류 형태로 발전했습니다. 따라서 표의 문자 삽입이 정보 매체 처리를 위한 첫 번째 선택이 되었습니다.
둘째, 검색 효율성 측면에서는 정보를 고차원 벡터로 표현할 수 있으므로 벡터에 특수한 인덱스 최적화 및 수량화 방법을 추가할 수 있어 검색 효율성이 크게 향상되고 데이터 양이 증가함에 따라 저장 비용을 줄일 수 있습니다. 벡터 데이터베이스는 수평으로 확장할 수 있으며 쿼리 응답 시간을 유지합니다. 이는 대량의 데이터를 처리해야 하는 RAG 시스템에 매우 중요하므로 벡터 데이터베이스는 매우 대규모의 비정형 데이터를 처리하는 데 더 좋습니다.
일반화 능력 측면 에서 볼 때 대부분의 기존 검색 엔진, 관계형 또는 문서 데이터베이스는 텍스트만 처리할 수 있으며 일반화 및 확장 기능이 좋지 않습니다. 벡터 데이터베이스는 텍스트 데이터에 국한되지 않고 이미지, 오디오 및 기타 비정형 데이터도 처리할 수 있습니다. . RAG 시스템을 더욱 유연하고 다양하게 만드는 임베딩 벡터 유형입니다.
마지막으로, 총 소유 비용 측면에서 다른 옵션에 비해 벡터 데이터베이스는 배포가 더 편리하고 사용하기가 더 쉽습니다. 또한 풍부한 API를 제공하므로 기존 기계 학습 프레임워크 및 워크플로와 쉽게 통합할 수 있어 인기가 높습니다. 그중에서도 많은 RAG 애플리케이션 개발자들이 가장 좋아하는 앱입니다.
벡터 검색은 의미론적 이해 능력, 높은 검색 효율성, 다중 양식에 대한 일반화 지원으로 인해 대형 모델 시대에 이상적인 RAG 검색기가 되었습니다. 미래에.
03.
RAG 시나리오의 벡터 데이터베이스 요구 사항
虽然向量数据库成为了检索的重要方式,但随着 RAG 应用的深入以及人们对高质量回答的需求,检索引擎依旧面临着诸多挑战。这里以一个最基础的 RAG 构建流程为例:检索器的组成包括了语料的预处理如切分、数据清洗、embedding 入库等,然后是索引的构建和管理,最后是通过 vector search 找到相近的片段提供给 prompt 做增强生成。大多数向量数据库的功能还只落在索引的构建管理和搜索的计算上,进一步则是包含了 embedding 模型的功能。
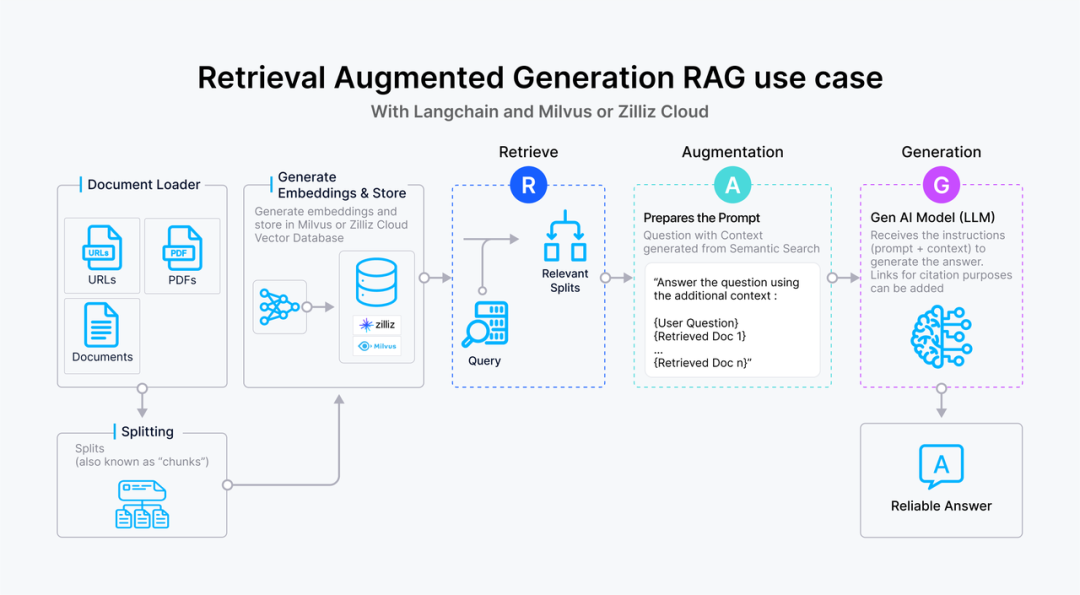
但在更高级的 RAG 场景中,因为召回的质量将直接影响到生成模型的输出质量和相关性,因此作为检索器底座的向量数据库应该更多的对检索质量负责。为了提升检索质量,这里其实有很多工程化的优化手段,如 chunk_size 的选择,切分是否需要 overlap,如何选择 embedding model,是否需要额外的内容标签,是否加入基于词法的检索来做 hybrid search,重排序 reranker 的选择等等,其中有不少工作是可以纳入向量数据库的考量之中。而检索系统对向量数据库的需求可以抽象描述为:
高精度的召回:向量数据库需要能够准确召回与查询语义最相关的文档或信息片段。这要求数据库能够理解和处理高维向量空间中的复杂语义关系,确保召回内容与查询的高度相关性。这里的效果既包括向量检索的数学召回精度也包括嵌入模型的语义精度。
快速响应:为了不影响用户体验,召回操作需要在极短的时间内完成,通常是毫秒级别。这要求向量数据库具备高效的查询处理能力,以快速从大规模数据集中检索和召回信息。此外,随着数据量的增长和查询需求的变化,向量数据库需要能够灵活扩展,以支持更多的数据和更复杂的查询,同时保持召回效果的稳定性和可靠性。
处理多模态数据的能力:随着应用场景的多样化,向量数据库可能需要处理不仅仅是文本,还有图像、视频等多模态数据。这要求数据库能够支持不同种类数据的嵌入,并能根据不同模态的数据查询进行有效的召回。
可解释性和可调试性:在召回效果不理想时,能够提供足够的信息帮助开发者诊断和优化是非常有价值的。因此,向量数据库在设计时也应考虑到系统的可解释性和可调试性。
RAG 场景中对向量数据库的召回效果有着严格的要求,不仅需要高精度和快速响应的召回这类基础能力,还需要处理多模态数据的能力以及可解释性和可调试性这类更高级的功能,以确保生成模型能够基于高质量的召回结果产生准确和相关的输出。在多模态处理、检索的可解释性和可调试性方面,向量数据库仍有许多工作值得探索和优化,而 RAG 应用的开发者也急需一套端到端的解决方案来达到高质量的检索效果。
本文作者


本文分享自微信公众号 - ZILLIZ(Zilliztech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。