
편집자 주: 현재 RAG(Retrieval Enhanced Generation) 시스템은 대규모 지식을 대형 모델에 적용하는 핵심 기술 중 하나가 되었습니다. 그러나 반정형 및 비정형 데이터, 특히 문서의 표 형식 데이터를 효율적으로 처리하는 방법은 여전히 RAG 시스템이 직면한 주요 문제입니다.
이 기사의 저자는 이러한 문제점을 해결하기 위해 표 형식 데이터를 처리하는 새로운 솔루션을 제안합니다. 저자는 먼저 테이블 파싱, 인덱스 구조 설계 등 RAG 시스템의 테이블 처리 핵심 기술을 체계적으로 정리하고, 기존 오픈소스 솔루션 몇 가지를 검토한다. 이를 바탕으로 저자는 Nougat 도구를 사용하여 문서의 표 내용을 정확하고 효율적으로 구문 분석하고, 언어 모델을 사용하여 표와 제목을 요약하고, 마지막으로 새로운 문서 요약 색인 구조를 구축하는 자신만의 혁신을 제안했습니다. 완전한 코드 구현 세부 정보를 제공합니다.
이 방법의 장점은 테이블을 효과적으로 구문 분석할 수 있고 테이블 요약과 테이블 간의 관계를 충분히 고려할 수 있다는 점입니다. 다중 모드 LLM을 사용할 필요가 없으며 구문 분석 비용을 절약할 수 있습니다. 실제로 이 계획이 추가로 적용되고 개발되는 것을 기다려 보겠습니다.
저자 | 플로리안 준
편집됨 | 양유에
RAG 시스템의 구현은 특히 구조화되지 않은 문서의 테이블을 구문 분석하고 이해해야 하는 경우 어려운 작업입니다. 스캔 작업(스캔된 문서)으로 디지털화된 문서 또는 이미지 형식의 문서(이미지 형식의 문서)의 경우 이러한 작업을 구현하는 것이 훨씬 더 어렵습니다. 최소한 세 가지 과제가 있습니다.
- 스캔 작업으로 디지털화된 문서(스캔된 문서) 또는 이미지 형식의 문서(이미지 형식의 문서)는 문서 구조의 다양성과 같이 상대적으로 복잡하며, 문서에는 텍스트가 아닌 일부 요소가 포함될 수 있으며 문서에 동시에 존재하는 손으로 직접 작성하거나 인쇄한 콘텐츠는 양식 정보를 정확하고 자동으로 추출하는 데 어려움을 겪습니다. 부정확한 문서 구문 분석은 테이블 구조를 파괴합니다. 불완전한 테이블 정보를 벡터 표현(임베딩)으로 변환하면 테이블의 의미 정보를 효과적으로 캡처할 수 없을 뿐만 아니라 RAG의 최종 출력에서 문제가 쉽게 발생할 수 있습니다.
- 각 테이블의 제목을 추출하고 해당하는 특정 테이블과 연결하는 방법입니다.
- 합리적인 인덱스 구조 설계를 통해 테이블의 주요 의미 정보를 효율적으로 구성하고 저장하는 방법.
이 문서에서는 먼저 RAG(Retrieval Augmented Generation) 모델에서 테이블 형식 데이터를 관리하고 처리하는 방법을 소개합니다. 그런 다음 일부 기존 오픈 소스 솔루션을 검토하고 마지막으로 현재 기술을 기반으로 새로운 테이블 형식 데이터 관리 방법을 설계하고 구현합니다.
01 RAG 테이블 데이터 관련 핵심 기술 소개
1.1 테이블 파싱(Table Parsing) 테이블 데이터 파싱
이 모듈의 주요 기능은 구조화되지 않은 문서나 이미지에서 테이블 구조를 정확하게 추출하는 것입니다.
추가 요구 사항: 개발자가 테이블 제목을 테이블과 쉽게 연결할 수 있도록 해당 테이블 제목을 추출하는 것이 가장 좋습니다.
현재 내가 알고 있는 바에 따르면 그림 1과 같이 여러 가지 방법이 있습니다.
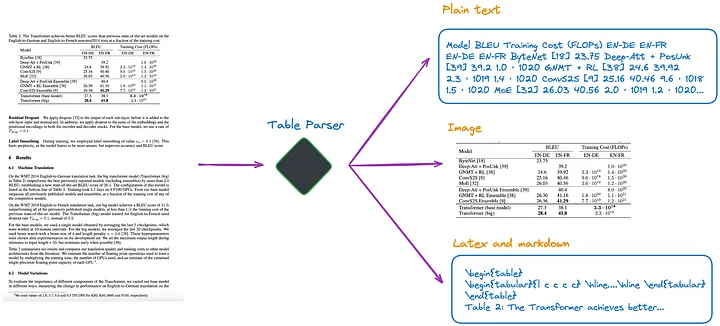
그림 1: 테이블 파서. 원본 작성자가 제공한 사진입니다.
(a) 다중 모드 LLM(예: GPT-4V[1])을 사용하여 테이블을 인식하고 각 PDF 페이지에서 정보를 추출합니다.
- 입력: 이미지 형식의 PDF 페이지
- 출력: JSON 또는 기타 형식의 표 형식 데이터입니다. 다중 모드 LLM이 표 형식 데이터를 추출할 수 없는 경우 PDF 이미지를 요약하고 콘텐츠 요약을 반환해야 합니다.
(b) 전문적인 테이블 감지 모델(예: Table Transformer[2])을 사용하여 테이블 구조를 식별합니다.
- 입력: PDF 페이지 이미지
- 출력: 테이블 이미지
(c) 구조화되지 않은[3] 또는 객체 감지 모델을 사용하는 기타 프레임워크와 같은 오픈 소스 프레임워크를 사용합니다(이 문서[4]에서는 구조화되지 않은 테이블 감지 프로세스에 대해 자세히 설명합니다). 이러한 프레임워크는 전체 문서를 완전히 구문 분석하고 구문 분석된 결과에서 테이블 관련 콘텐츠를 추출할 수 있습니다.
- 입력: PDF 또는 이미지 형식의 문서
- 출력: 일반 텍스트 또는 HTML 형식의 테이블(전체 문서를 구문 분석하여 얻음)
(d) Nougat[5] 및 Donut[6]과 같은 엔드투엔드 모델을 사용하여 전체 문서를 구문 분석하고 테이블 관련 콘텐츠를 추출합니다. 이 접근 방식에는 OCR 모델이 필요하지 않습니다.
- 입력: PDF 또는 이미지 형식의 문서
- 출력: LaTeX 또는 JSON 형식의 테이블(전체 문서를 구문 분석하여 얻음)
테이블 정보를 추출하기 위해 어떤 방법을 사용하더라도 테이블 제목도 추출되어야 한다는 점에 유의해야 한다 . 왜냐하면 대부분의 경우 표 제목은 문서 작성자나 논문 작성자가 표에 대해 간략하게 설명하는 것이므로 표 전체의 내용을 상당 부분 요약할 수 있기 때문입니다.
위의 네 가지 방법 중 (d) 방법이 테이블 제목을 보다 편리하게 검색할 수 있다. 이는 테이블 제목을 테이블과 연결할 수 있으므로 개발자에게 큰 이점입니다. 다음 실험에서는 이를 더 자세히 설명합니다.
1.2 인덱스 구조가 표 형식 데이터를 인덱스하는 방법
인덱싱 방법에는 대략 다음과 같은 유형이 있습니다.
(e) 이미지 형식의 인덱스 테이블만.
(f) 일반 텍스트 또는 JSON 형식의 인덱스 테이블만.
(g) LaTeX 형식의 인덱스 테이블만 해당됩니다.
(h) 테이블의 초록만 색인됩니다.
(i) Small-to-big (번역자 주: 각 행 또는 테이블 요약을 인덱싱하는 것과 같은 세분화된 인덱싱과 이미지, 일반 텍스트 또는 LaTeX의 전체 테이블을 인덱싱하는 것과 같은 거친 인덱싱을 모두 포함합니다. 유형 데이터를 사용하여 계층적 소형부터 대형 인덱스 구조를 형성합니다.) 또는 그림 2와 같이 테이블 요약을 사용하여 인덱스 구조를 구축합니다.
테이블의 각 행이나 요약 정보를 독립적인 작은 데이터 블록으로 처리하는 등 작은 청크(번역자 주: 세분화된 인덱스 수준에 해당하는 데이터 블록)의 내용입니다.
빅 청크(역자 주: 대략적인 인덱스 수준에 해당하는 데이터 블록)의 내용은 이미지 형식, 일반 텍스트 형식 또는 LaTeX 형식의 전체 테이블일 수 있습니다.
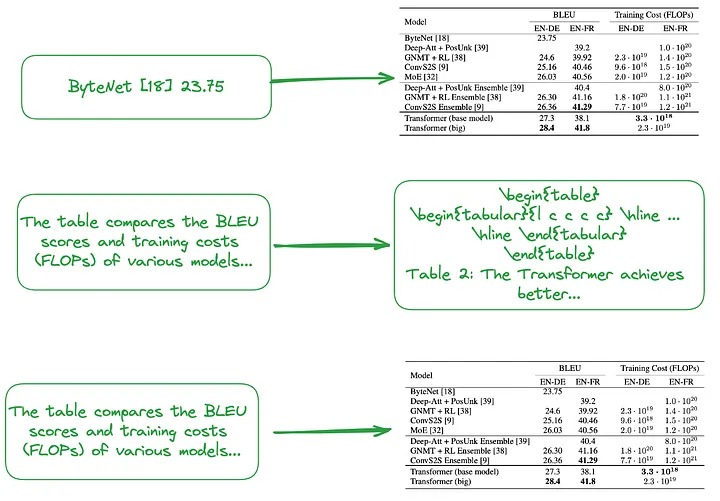
그림 2: 작은 것부터 큰 것까지 색인화(상단) 및 테이블 요약 사용(중간, 하단). 원본 작성자가 제공한 사진입니다.
위에서 언급한 것처럼 표 형식 요약은 일반적으로 LLM 처리를 사용하여 생성됩니다.
- 입력: 이미지 형식, 텍스트 형식 또는 LaTeX 형식의 테이블
- 출력: 테이블 요약
1.3 테이블 구문 분석, 인덱스 구축 또는 RAG 기술 사용이 필요하지 않은 접근 방식
일부 알고리즘에는 표 형식 데이터의 구문 분석이 필요하지 않습니다.
(j) 관련 이미지(PDF 문서 페이지)와 사용자의 쿼리를 VQA 모델(예: DAN [7] 등)로 보냅니다. (번역자 주: Visual Question Answering 모델의 약어입니다. 컴퓨터 모델의 조합입니다. 이미지 콘텐츠에 대한 자연어 질문에 답하는 데 사용할 수 있는 비전 및 자연어 처리 기술) 또는 다중 모드 LLM 및 답변 반환.
- 색인화할 콘텐츠: 이미지 형식의 문서
- VQA 모델 또는 다중 모달 LLM에 보낼 내용: 쿼리 + 해당 문서 페이지를 이미지로
(k) 해당 텍스트 형식의 PDF 페이지와 사용자의 쿼리를 LLM에 보낸 다음 답변을 반환합니다.
- 색인화할 콘텐츠: 텍스트 형식 문서
- LLM으로 전송된 콘텐츠: 쿼리 + 텍스트 형식의 해당 문서 페이지
(l) 관련 문서 이미지(PDF 문서 페이지), 텍스트 블록 및 사용자 쿼리를 다중 모달 LLM(예: GPT-4V 등)으로 보낸 다음 답변을 직접 반환합니다.
- 색인화할 콘텐츠: 이미지 형식의 문서 및 텍스트 형식의 문서 청크
- 멀티모달 LLM으로 전송된 콘텐츠: 쿼리 + 해당 이미지 형식의 문서 + 해당 텍스트 청크
또한 그림 3과 4에 표시된 것처럼 인덱싱이 필요하지 않은 몇 가지 방법은 다음과 같습니다.
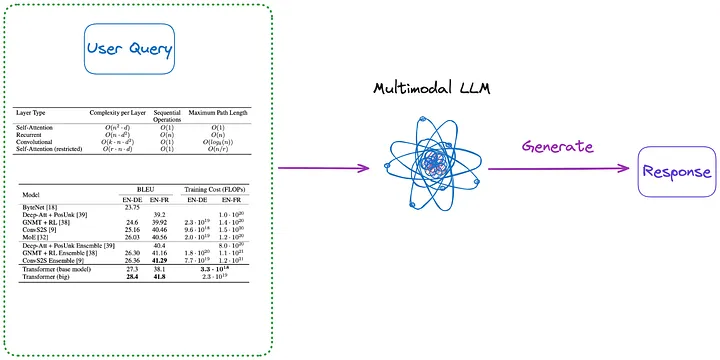
그림 3: 카테고리(m)(번역자 주: 아래 첫 번째 단락에 소개된 내용). 원본 작성자가 제공한 사진입니다.
(m) 먼저 (a)부터 (d)까지의 방법 중 하나를 사용하여 문서의 모든 테이블을 이미지 형식으로 구문 분석합니다. 그런 다음 모든 테이블 이미지와 사용자 쿼리가 다중 모드 LLM(예: GPT-4V 등)으로 직접 전송되고 답변이 반환됩니다.
- 색인화할 콘텐츠: 없음
- 멀티모달 LLM으로 전송된 콘텐츠: 쿼리 + 이미지 형식으로 변환된 모든 테이블
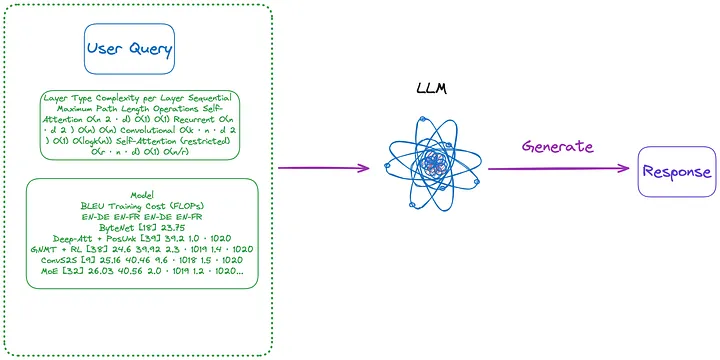
그림 4: 범주(n)(번역자 주: 아래 첫 번째 단락에 소개된 내용). 원본 작성자가 제공한 사진입니다.
(n) (m) 메소드로 추출된 이미지 형식의 테이블을 사용하고, OCR 모델을 사용하여 테이블의 모든 텍스트를 식별한 후, 테이블의 모든 텍스트와 사용자의 Query를 LLM으로 직접 보냅니다. , 그리고 직접 답변을 반환합니다.
- 색인화할 콘텐츠: 없음
- LLM으로 전송되는 콘텐츠: 사용자 쿼리 + 모든 테이블 콘텐츠(텍스트 형식으로 전송)
문서의 테이블을 처리할 때 일부 방법에서는 RAG(Retrieval-Augmented Generation) 기술을 사용하지 않는다는 점에 주목할 필요가 있습니다.
- 첫 번째 유형의 방법은 LLM을 사용하지 않지만 특정 데이터 세트를 학습하므로 AI 모델(예: Transformer 아키텍처를 기반으로 하고 BERT에서 영감을 받은 다른 언어 모델)이 다음과 같은 테이블 이해 작업 처리를 더 잘 지원할 수 있습니다. 타파스 [8].
- 두 번째 유형의 방법은 사전 훈련, 미세 조정 방법 또는 프롬프트 단어 엔지니어링을 사용하여 LLM을 사용하여 LLM이 GPT4Table [9]과 같은 테이블 이해 작업을 완료할 수 있도록 하는 것입니다.
02 테이블 프로세싱을 위한 기존 오픈소스 솔루션
이전 섹션에서는 RAG 시스템의 표 형식 데이터 처리를 위한 핵심 기술을 요약하고 분류했습니다. 이 기사에서 구현할 솔루션을 제안하기 전에 몇 가지 오픈 소스 솔루션을 살펴보겠습니다.
LlamaIndex는 네 가지 방법을 제안하며[10], 처음 세 가지 방법은 모두 다중 모드 모델을 사용합니다.
- 관련 PDF 페이지 이미지를 검색하여 사용자 Query에 대한 응답으로 GPT-4V로 보냅니다.
- 각 PDF 페이지를 이미지 형식으로 변환하고 GPT-4V가 각 페이지에서 이미지 추론을 수행하도록 합니다. 이미지 추론 과정을 위해 Text Vector Store 인덱스를 설정하고(역자 주: 이미지에서 유추한 텍스트 정보를 벡터 형태로 변환하여 인덱스 생성), Image Reasoning Vector Store를 사용한다(역자 주: 이전 인덱스여야 함) , 이전에 생성된 텍스트 벡터 저장소 색인)을 쿼리하여 답을 찾습니다.
- Table Transformer를 사용하여 검색된 이미지에서 테이블 정보를 자른 다음 이렇게 자른 테이블 이미지를 GPT-4V로 보내 쿼리 응답을 얻습니다(번역가 참고 사항: 모델에 쿼리를 보내고 모델에서 반환된 답변 얻기).
- 자른 테이블 이미지에 OCR을 적용하고 데이터를 GPT4/GPT-3.5로 보내 사용자의 쿼리에 응답합니다.
위의 네 가지 방법을 요약하면 다음과 같습니다.
- 첫 번째 방법은 이 기사에서 소개한 방법 (j)와 유사하며 테이블 구문 분석이 필요하지 않습니다. 하지만 이미지에 정답이 있음에도 불구하고 정답이 나오지 않는 것으로 나타났습니다.
- 두 번째 방법은 테이블 구문 분석을 포함하며 방법 (a)에 해당합니다. 인덱스 콘텐츠는 방법 (f) 또는 (h)에 해당할 수 있는 GPT-4V에서 반환된 결과에 전적으로 의존하는 표 형식 콘텐츠 또는 콘텐츠 요약일 수 있습니다. 이 접근 방식의 단점은 문서 이미지에서 테이블을 식별하고 해당 내용을 추출하는 GPT-4V의 기능이 일관되지 않는다는 것입니다. 특히 문서 이미지에 테이블, 텍스트 및 기타 이미지(PDF 문서에서 일반적임)가 포함된 경우 더욱 그렇습니다.
- 세 번째 방법은 방법 (m)과 유사하며 인덱싱이 필요하지 않습니다.
- 네 번째 방법은 방법 (n)과 유사하며 인덱싱이 필요하지 않습니다. 그 결과 오답의 원인은 이미지에서 표 형식의 정보를 효과적으로 추출할 수 없기 때문인 것으로 나타났습니다.
테스트를 통해 세 번째 방법이 전체적으로 가장 좋은 효과를 갖는 것으로 나타났습니다. 그러나 제가 수행한 테스트에 따르면 세 번째 방법은 테이블 제목과 테이블 내용을 올바르게 추출하고 연관시키는 것은 물론이고 테이블을 감지하는 데 어려움을 겪었습니다.
Langchain은 또한 반구조적 데이터 RAG(Semi-structured RAG)[11] 기술에 대한 몇 가지 솔루션을 제안했습니다. 핵심 기술은 다음과 같습니다.
- 클래스(c) 메서드인 테이블 구문 분석에는 구조화되지 않은 방법을 사용합니다.
- index 방식은 클래스 (i) 방식에 속하는 문서 요약 색인(번역자 주: 문서 요약 정보를 색인 내용으로 사용)입니다. 세분화된 인덱스 수준에 해당하는 데이터 블록: 테이블 요약 콘텐츠, 대략적인 인덱스 수준에 해당하는 데이터 블록: 원본 테이블 콘텐츠(텍스트 형식).
그림 5에 표시된 대로:
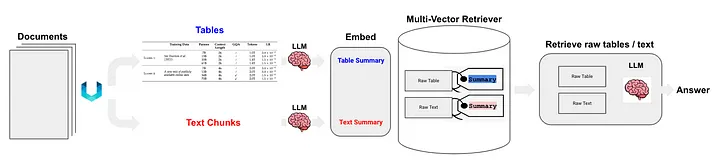
그림 5: Langchain의 반구조화된 RAG 솔루션. 출처: 반구조화된 RAG[11]
반구조화 및 다중 모드 RAG[12]는 그림 6에 아키텍처가 표시된 세 가지 솔루션을 제안했습니다.
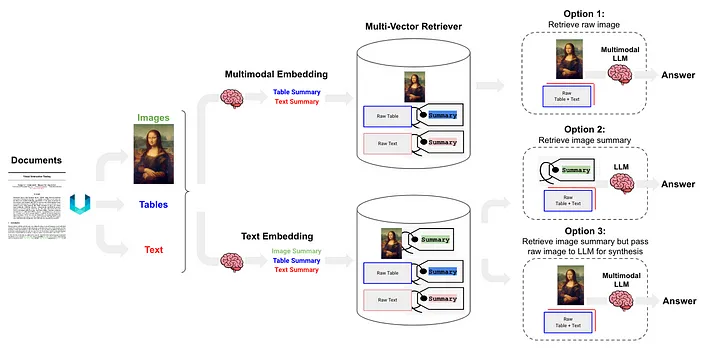
그림 6: Langchain의 반구조화 및 다중 모드 RAG 체계. 출처: 반구조적 및 다중 모드 RAG[12].
옵션 1은 위의 방법(l)과 유사합니다. 이 접근 방식에는 다중 모드 임베딩(예: CLIP [13])을 사용하여 이미지와 텍스트를 임베딩 벡터로 변환한 다음 유사성 검색 알고리즘을 사용하여 두 가지를 모두 검색하고 처리되지 않은 이미지 및 텍스트 데이터를 다중 모드 LLM으로 전달하여 변환합니다. 함께 처리되어 질문에 대한 답변을 생성합니다.
옵션 2 는 다중 모드 LLM(예: GPT-4V[14], LLaVA[15] 또는 FUYU-8b[16])을 사용하여 이미지를 처리하여 텍스트 요약을 생성합니다. 그런 다음 텍스트 데이터는 임베딩 벡터로 변환되고, 이러한 벡터는 사용자가 제기한 쿼리와 일치하는 텍스트 콘텐츠를 검색하는 데 사용되며 답변을 생성하기 위해 LLM에 전달됩니다.
- 테이블 데이터는 클래스 (d) 메소드에 속하는 비구조화를 사용하여 구문 분석됩니다.
- 인덱싱 방식은 (i) 클래스 방식에 속하는 문서 요약 인덱스(역자 주: 문서 요약 정보를 인덱스 내용으로 사용)이며, 세분화된 인덱스 수준: 테이블 요약 내용에 해당하는 데이터 블록입니다. 대략적인 인덱스 수준에 해당하는 블록: 텍스트 형식 테이블 콘텐츠.
옵션 3 은 다중 모드 LLM(예: GPT-4V [14], LLaVA [15] 또는 FUYU-8b [16])을 사용하여 이미지 데이터에서 텍스트 요약을 생성한 다음 이러한 임베딩 벡터를 사용하여 이러한 텍스트 요약을 벡터에 임베드합니다. , 이미지 요약은 검색된 각 이미지 요약에서 원시 이미지에 대한 해당 참조(원시 이미지에 대한 참조)가 유지됩니다. 이는 마지막으로 처리되지 않은 이미지 데이터에 속합니다. 답변을 생성하기 위해 텍스트 블록이 다중 모드 LLM으로 전달됩니다.
03 이 글에서 제안하는 솔루션
이전 기사에서는 핵심 기술과 기존 솔루션을 요약, 분류 및 논의했습니다. 이를 바탕으로 그림 7과 같이 다음과 같은 솔루션을 제안합니다. 단순화를 위해 Re-ranking 및 쿼리 재작성과 같은 일부 RAG 모듈은 그림에서 생략되었습니다.
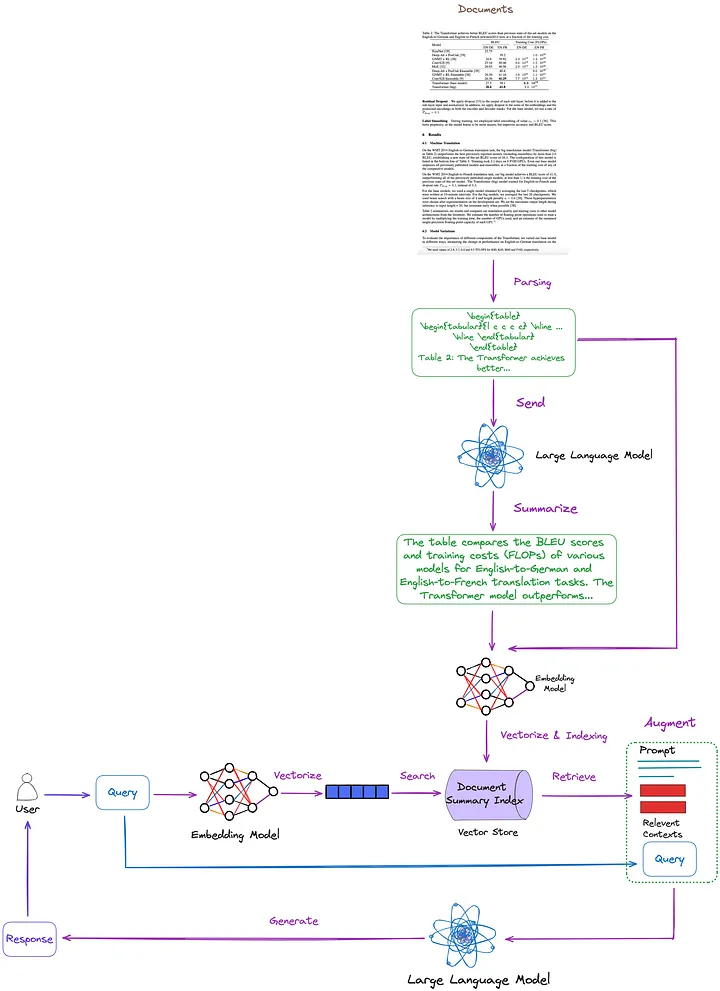
그림 7: 이 기사에서 제안된 솔루션. 원본 작성자가 제공한 사진입니다.
- 테이블 구문 분석 기술: Nougat((d) 클래스 방법) 사용. 내 테스트에 따르면 이 도구의 테이블 감지 기능은 구조화되지 않은(유형(c) 기술) 것보다 더 효과적입니다. 또한, Nougat는 테이블 제목 추출도 매우 잘하여 테이블과의 연계가 매우 편리합니다.
- 문서 요약 색인화 및 검색을 위한 색인 구조(클래스 (i)의 방법): 세분화된 색인 수준에는 표 형식의 내용 요약이 포함되고, 대략적으로 세분화된 색인 수준에는 LaTeX 형식의 해당 테이블과 텍스트 형식의 테이블 제목이 포함됩니다. 우리는 다중 벡터 검색기[17](번역자 주: 쿼리와 관련된 문서 요약을 효율적으로 검색하기 위해 여러 벡터를 동시에 처리할 수 있는 문서 요약 인덱스의 콘텐츠를 검색하는 검색기)를 사용하여 수행합니다.
- 표 내용 요약을 얻는 방법: 내용 요약을 위해 표와 표 제목을 LLM에 보냅니다.
이 방법의 장점은 테이블을 효과적으로 구문 분석하고 테이블 요약과 테이블 간의 관계를 충분히 고려할 수 있다는 것입니다. 다중 모드 LLM을 사용할 필요가 없어 비용이 절감됩니다.
3.1 누가의 작동 원리
Nougat [18]는 Donut [19] 아키텍처를 기반으로 개발되었으며, 이 접근 방식은 OCR 관련 입력이나 모듈 없이 암시적인 방식으로 텍스트를 자동으로 인식할 수 있는 알고리즘을 사용합니다.
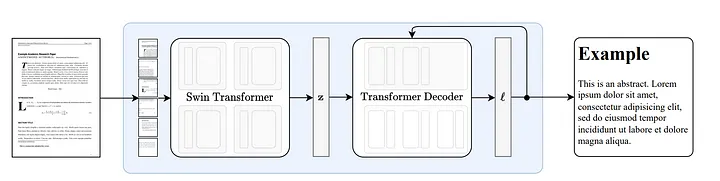
그림 8: Donut[19]을 따르는 엔드투엔드 아키텍처. Swin Transformer 인코더는 문서 이미지를 가져와 이를 잠재 임베딩(역자 참고: 이미지 정보는 잠재 공간에 인코딩됨)으로 변환한 다음 이를 자동 회귀 방식으로 토큰 시퀀스로 변환합니다. 출처: Nougat: 학술 문서에 대한 신경 광학적 이해.[18]
Nougat의 수식 구문 분석 기능은 인상적이지만[20], 테이블 구문 분석 기능도 탁월합니다. 그림 9에 표시된 것처럼 테이블 제목과 연결할 수 있어 매우 편리합니다.

그림 9: Nougat 실행 결과 결과 파일은 Mathpix Markdown 형식이며(vscode 플러그인을 통해 열 수 있음) 테이블은 LaTeX 형식으로 표시됩니다.
12개의 논문을 대상으로 실시한 테스트에서 표 제목은 항상 표의 다음 행에 고정되어 있다는 사실을 발견했습니다. 이러한 일관성은 이것이 우연이 아님을 시사합니다. 따라서 우리는 누가가 이 기능을 어떻게 구현하는지에 더 관심이 있습니다.
중간 결과가 없는 엔드투엔드 모델이라는 점을 감안할 때 성능은 훈련 데이터에 크게 의존할 가능성이 높습니다.
코드 분석에 따르면 테이블 헤더 섹션이 저장되는 위치와 방식은 훈련 데이터에 있는 테이블의 구성 형식 과 일치하는 것으로 보입니다(그리고 바로 \end{table} 다음으로 ).caption_parts
def format_element(
element: Element, keep_refs: bool = False, latex_env: bool = False
) -> List[str]:
"""
Formats a given Element into a list of formatted strings.
Args:
element (Element): The element to be formatted.
keep_refs (bool, optional): Whether to keep references in the formatting. Default is False.
latex_env (bool, optional): Whether to use LaTeX environment formatting. Default is False.
Returns:
List[str]: A list of formatted strings representing the formatted element.
"""
...
...
if isinstance(element, Table):
parts = [
"[TABLE%s]\n\begin{table}\n"
% (str(uuid4())[:5] if element.id is None else ":" + str(element.id))
]
parts.extend(format_children(element, keep_refs, latex_env))
caption_parts = format_element(element.caption, keep_refs, latex_env)
remove_trailing_whitespace(caption_parts)
parts.append("\end{table}\n")
if len(caption_parts) > 0:
parts.extend(caption_parts + ["\n"])
parts.append("[ENDTABLE]\n\n")
return parts
...
...
3.2 누가의 장점과 단점
이점:
- 누가(Nougat)는 수식, 표 등 기존 파싱 도구로는 파싱하기 어려웠던 부분을 LaTeX 소스코드로 정확하게 파싱할 수 있습니다.
- Nougat의 구문 분석 결과는 Markdown과 유사한 반구조화된 문서입니다.
- 테이블 제목을 쉽게 얻고 이를 테이블과 쉽게 연결하는 기능.
결점:
- Nougat의 구문 분석 속도는 느리기 때문에 대규모 애플리케이션에서는 어려움을 겪을 수 있습니다.
- Nougat의 학습 데이터 세트는 기본적으로 과학 논문이므로 이 기술은 유사한 구조를 가진 문서에서 잘 작동합니다. 라틴어가 아닌 텍스트 문서를 처리할 때 성능이 저하됩니다.
- 누가 모델은 한 번에 과학 논문의 한 페이지만 학습하고 다른 페이지에 대한 지식은 부족합니다. 이로 인해 구문 분석된 콘텐츠에 일부 불일치가 발생할 수 있습니다. 따라서 인식 효과가 좋지 않은 경우 PDF를 별도의 페이지로 분할하고 페이지별로 구문 분석하는 것을 고려할 수 있습니다.
- 2열 논문의 테이블 구문 분석은 단일 열 논문만큼 좋지 않습니다.
3.3 코드 구현
먼저 관련 Python 패키지를 설치합니다.
pip install langchain
pip install chromadb
pip install nougat-ocr
설치가 완료되면 Python 패키지 버전을 확인해야 합니다.
langchain 0.1.12
langchain-community 0.0.28
langchain-core 0.1.31
langchain-openai 0.0.8
langchain-text-splitters 0.0.1
chroma-hnswlib 0.7.3
chromadb 0.4.24
nougat-ocr 0.1.17
작업 환경 설정 및 패키지 가져오기:
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
import subprocess
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
"Attention Is All You Need"[21] 논문을 경로에 다운로드하고 YOUR_PDF_PATH, nougat를 실행하여 PDF 파일을 구문 분석하고, 구문 분석 결과에서 라텍스 형식의 테이블 데이터와 텍스트 형식의 테이블 제목을 가져옵니다. 프로그램을 처음 실행하면 필요한 모델 파일이 로컬 환경에 다운로드됩니다.
def june_run_nougat(file_path, output_dir):
# Run Nougat and store results as Mathpix Markdown
cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"]
res = subprocess.run(cmd)
if res.returncode != 0:
print("Error when running nougat.")
return res.returncode
else:
print("Operation Completed!")
return 0
def june_get_tables_from_mmd(mmd_path):
f = open(mmd_path)
lines = f.readlines()
res = []
tmp = []
flag = ""
for line in lines:
if line == "\begin{table}\n":
flag = "BEGINTABLE"
elif line == "\end{table}\n":
flag = "ENDTABLE"
if flag == "BEGINTABLE":
tmp.append(line)
elif flag == "ENDTABLE":
tmp.append(line)
flag = "CAPTION"
elif flag == "CAPTION":
tmp.append(line)
flag = "MARKDOWN"
print('-' * 100)
print(''.join(tmp))
res.append(''.join(tmp))
tmp = []
return res
file_path = "YOUR_PDF_PATH"
output_dir = "YOUR_OUTPUT_DIR_PATH"
if june_run_nougat(file_path, output_dir) == 1:
import sys
sys.exit(1)
mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"
tables = june_get_tables_from_mmd(mmd_path)
june_get_tables_from_mmd 함수는 그림 10과 같이 mmd 파일에서 모든 내용을 추출하는 데 사용됩니다(from \begin{table} 에서 까지 \end{table}, 그 뒤의 첫 번째 줄도 포함 ).\end{table}

그림 10: Nougat 실행 결과 결과 파일은 Mathpix Markdown 형식이고(vscode 플러그인을 통해 열 수 있음) 구문 분석된 테이블 콘텐츠는 latex 형식입니다. june_get_tables_from_mmd 함수의 기능은 빨간색 상자에 있는 테이블 정보를 추출하는 것입니다. 원본 작성자가 제공한 사진입니다.
그러나 표 제목을 표 아래에 배치해야 한다거나 표가 \begin{table}로 시작하고 \end{table}로 끝나야 한다는 공식 문서는 없습니다. 따라서 June_get_tables_from_mmd는 경험적 방법입니다.
PDF 문서의 테이블 구문 분석 결과는 다음과 같습니다.
Operation Completed!
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{l c c c} \hline \hline Layer Type & Complexity per Layer & Sequential Operations & Maximum Path Length \ \hline Self-Attention & (O(n^{2}\cdot d)) & (O(1)) & (O(1)) \ Recurrent & (O(n\cdot d^{2})) & (O(n)) & (O(n)) \ Convolutional & (O(k\cdot n\cdot d^{2})) & (O(1)) & (O(log_{k}(n))) \ Self-Attention (restricted) & (O(r\cdot n\cdot d)) & (O(1)) & (O(n/r)) \ \hline \hline \end{tabular}
\end{table}
Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operations for different layer types. (n) is the sequence length, (d) is the representation dimension, (k) is the kernel size of convolutions and (r) the size of the neighborhood in restricted self-attention.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{l c c c c} \hline \hline \multirow{2}{*}{Model} & \multicolumn{2}{c}{BLEU} & \multicolumn{2}{c}{Training Cost (FLOPs)} \ \cline{2-5} & EN-DE & EN-FR & EN-DE & EN-FR \ \hline ByteNet [18] & 23.75 & & & \ Deep-Att + PosUnk [39] & & 39.2 & & (1.0\cdot 10^{20}) \ GNMT + RL [38] & 24.6 & 39.92 & (2.3\cdot 10^{19}) & (1.4\cdot 10^{20}) \ ConvS2S [9] & 25.16 & 40.46 & (9.6\cdot 10^{18}) & (1.5\cdot 10^{20}) \ MoE [32] & 26.03 & 40.56 & (2.0\cdot 10^{19}) & (1.2\cdot 10^{20}) \ \hline Deep-Att + PosUnk Ensemble [39] & & 40.4 & & (8.0\cdot 10^{20}) \ GNMT + RL Ensemble [38] & 26.30 & 41.16 & (1.8\cdot 10^{20}) & (1.1\cdot 10^{21}) \ ConvS2S Ensemble [9] & 26.36 & **41.29** & (7.7\cdot 10^{19}) & (1.2\cdot 10^{21}) \ \hline Transformer (base model) & 27.3 & 38.1 & & (\mathbf{3.3\cdot 10^{18}}) \ Transformer (big) & **28.4** & **41.8** & & (2.3\cdot 10^{19}) \ \hline \hline \end{tabular}
\end{table}
Table 2: The Transformer achieves better BLEU scores than previous state-of-the-art models on the English-to-German and English-to-French newstest2014 tests at a fraction of the training cost.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{c|c c c c c c c c|c c c c} \hline \hline & (N) & (d_{\text{model}}) & (d_{\text{ff}}) & (h) & (d_{k}) & (d_{v}) & (P_{drop}) & (\epsilon_{ls}) & train steps & PPL & BLEU & params \ \hline base & 6 & 512 & 2048 & 8 & 64 & 64 & 0.1 & 0.1 & 100K & 4.92 & 25.8 & 65 \ \hline \multirow{4}{*}{(A)} & \multicolumn{1}{c}{} & & 1 & 512 & 512 & & & & 5.29 & 24.9 & \ & & & & 4 & 128 & 128 & & & & 5.00 & 25.5 & \ & & & & 16 & 32 & 32 & & & & 4.91 & 25.8 & \ & & & & 32 & 16 & 16 & & & & 5.01 & 25.4 & \ \hline (B) & \multicolumn{1}{c}{} & & \multicolumn{1}{c}{} & & 16 & & & & & 5.16 & 25.1 & 58 \ & & & & & 32 & & & & & 5.01 & 25.4 & 60 \ \hline \multirow{4}{*}{(C)} & 2 & \multicolumn{1}{c}{} & & & & & & & & 6.11 & 23.7 & 36 \ & 4 & & & & & & & & 5.19 & 25.3 & 50 \ & 8 & & & & & & & & 4.88 & 25.5 & 80 \ & & 256 & & 32 & 32 & & & & 5.75 & 24.5 & 28 \ & 1024 & & 128 & 128 & & & & 4.66 & 26.0 & 168 \ & & 1024 & & & & & & 5.12 & 25.4 & 53 \ & & 4096 & & & & & & 4.75 & 26.2 & 90 \ \hline \multirow{4}{*}{(D)} & \multicolumn{1}{c}{} & & & & & 0.0 & & 5.77 & 24.6 & \ & & & & & & 0.2 & & 4.95 & 25.5 & \ & & & & & & & 0.0 & 4.67 & 25.3 & \ & & & & & & & 0.2 & 5.47 & 25.7 & \ \hline (E) & \multicolumn{1}{c}{} & \multicolumn{1}{c}{} & & \multicolumn{1}{c}{} & & & & & 4.92 & 25.7 & \ \hline big & 6 & 1024 & 4096 & 16 & & 0.3 & 300K & **4.33** & **26.4** & 213 \ \hline \hline \end{tabular}
\end{table}
Table 3: Variations on the Transformer architecture. Unlisted values are identical to those of the base model. All metrics are on the English-to-German translation development set, newstest2013. Listed perplexities are per-wordpiece, according to our byte-pair encoding, and should not be compared to per-word perplexities.
----------------------------------------------------------------------------------------------------
\begin{table}
\begin{tabular}{c|c|c} \hline
**Parser** & **Training** & **WSJ 23 F1** \ \hline Vinyals & Kaiser et al. (2014) [37] & WSJ only, discriminative & 88.3 \ Petrov et al. (2006) [29] & WSJ only, discriminative & 90.4 \ Zhu et al. (2013) [40] & WSJ only, discriminative & 90.4 \ Dyer et al. (2016) [8] & WSJ only, discriminative & 91.7 \ \hline Transformer (4 layers) & WSJ only, discriminative & 91.3 \ \hline Zhu et al. (2013) [40] & semi-supervised & 91.3 \ Huang & Harper (2009) [14] & semi-supervised & 91.3 \ McClosky et al. (2006) [26] & semi-supervised & 92.1 \ Vinyals & Kaiser el al. (2014) [37] & semi-supervised & 92.1 \ \hline Transformer (4 layers) & semi-supervised & 92.7 \ \hline Luong et al. (2015) [23] & multi-task & 93.0 \ Dyer et al. (2016) [8] & generative & 93.3 \ \hline \end{tabular}
\end{table}
Table 4: The Transformer generalizes well to English constituency parsing (Results are on Section 23 of WSJ)* [5] Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. Learning phrase representations using rnn encoder-decoder for statistical machine translation. _CoRR_, abs/1406.1078, 2014.
그런 다음 LLM을 사용하여 표 형식의 데이터를 요약합니다.
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Get table summaries
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
print(table_summaries)
다음은 그림 11에 표시된 "Attention Is All You Need"[21]의 4개 테이블 내용을 요약한 것입니다.
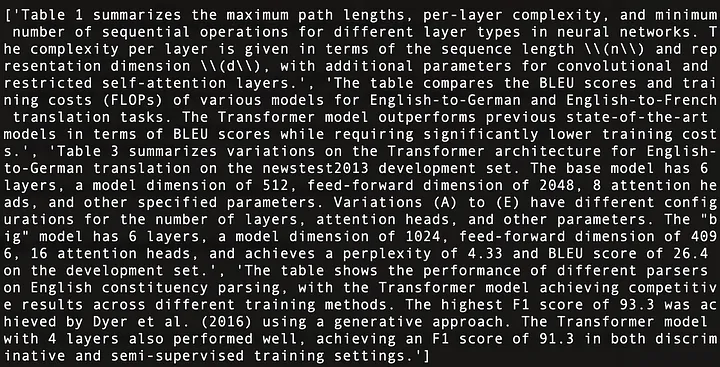
그림 11: "Attention Is All You Need"[21]에 있는 4개 테이블의 내용 요약.
Multi-Vector Retriever를 사용한다. (역자 주: 문서 요약 인덱스의 내용을 검색하는 검색기. 검색기는 여러 벡터를 동시에 처리하여 Query와 관련된 문서 요약을 효과적으로 검색할 수 있다.) 문서 요약 인덱스 구조 구축 [17] (역자 주: 문서의 요약 정보를 저장하는 데 사용되는 색인 구조이며, 이러한 요약 정보는 필요에 따라 검색하거나 쿼리할 수 있습니다.)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key = id_key,
search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1
)
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content = s, metadata = {id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
모든 것이 준비되면 간단한 RAG 파이프라인을 설정하고 사용자 쿼리를 실행합니다.
# Prompt template
template = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
# Simple RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1
print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2
print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
실행 결과는 그림 12와 같이 이러한 질문에 정확하게 답변되었습니다.

그림 12: 세 가지 사용자 쿼리에 대한 답변. Attention Is All You Need의 첫 번째 행은 표 1에 해당하고, 두 번째 행은 표 2에, 세 번째 행은 표 4에 해당합니다.
전체 코드는 다음과 같습니다.
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"
import subprocess
import uuid
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_vector import MultiVectorRetriever
from langchain.storage import InMemoryStore
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
from langchain_core.runnables import RunnablePassthrough
def june_run_nougat(file_path, output_dir):
# Run Nougat and store results as Mathpix Markdown
cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"]
res = subprocess.run(cmd)
if res.returncode != 0:
print("Error when running nougat.")
return res.returncode
else:
print("Operation Completed!")
return 0
def june_get_tables_from_mmd(mmd_path):
f = open(mmd_path)
lines = f.readlines()
res = []
tmp = []
flag = ""
for line in lines:
if line == "\begin{table}\n":
flag = "BEGINTABLE"
elif line == "\end{table}\n":
flag = "ENDTABLE"
if flag == "BEGINTABLE":
tmp.append(line)
elif flag == "ENDTABLE":
tmp.append(line)
flag = "CAPTION"
elif flag == "CAPTION":
tmp.append(line)
flag = "MARKDOWN"
print('-' * 100)
print(''.join(tmp))
res.append(''.join(tmp))
tmp = []
return res
file_path = "YOUR_PDF_PATH"
output_dir = "YOUR_OUTPUT_DIR_PATH"
if june_run_nougat(file_path, output_dir) == 1:
import sys
sys.exit(1)
mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"
tables = june_get_tables_from_mmd(mmd_path)
# Prompt
prompt_text = """You are an assistant tasked with summarizing tables and text. \
Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """
prompt = ChatPromptTemplate.from_template(prompt_text)
# Summary chain
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()
# Get table summaries
table_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})
print(table_summaries)
# The vectorstore to use to index the child chunks
vectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())
# The storage layer for the parent documents
store = InMemoryStore()
id_key = "doc_id"
# The retriever (empty to start)
retriever = MultiVectorRetriever(
vectorstore = vectorstore,
docstore = store,
id_key = id_key,
search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1
)
# Add tables
table_ids = [str(uuid.uuid4()) for _ in tables]
summary_tables = [
Document(page_content = s, metadata = {id_key: table_ids[i]})
for i, s in enumerate(table_summaries)
]
retriever.vectorstore.add_documents(summary_tables)
retriever.docstore.mset(list(zip(table_ids, tables)))
# Prompt template
template = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
# LLM
model = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")
# Simple RAG pipeline
chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1
print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2
print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
04 결론
본 논문에서는 RAG 시스템의 테이블 처리 작업을 위한 핵심 기술과 기존 솔루션에 대해 논의하고 솔루션과 구현을 제안합니다.
이 기사에서는 Nougat를 사용하여 테이블을 구문 분석했습니다. 그러나 더 빠르고 효율적인 구문 분석 도구를 사용할 수 있게 되면 Nougat 교체를 고려할 것입니다. 도구에 대한 우리의 태도는 특정 도구에 의존하기보다 먼저 올바른 아이디어를 갖고 이를 구현하기 위한 도구를 찾는 것입니다.
이 기사에서는 모든 테이블 내용을 LLM에 입력합니다. 그러나 실제 시나리오에서는 테이블 크기가 LLM 컨텍스트 길이를 초과하는 상황을 고려해야 합니다. 효율적인 청킹 방법을 사용하여 이 문제를 해결할 수 있습니다.
읽어 주셔서 감사합니다!
——
플로리안 준
인공지능 연구자로서 주로 대규모 언어 모델, 데이터 구조 및 알고리즘, NLP에 관한 기사를 작성합니다.
끝
참고자료
[1] https://openai.com/research/gpt-4v-system-card
[2] https://github.com/microsoft/table-transformer
[3] https://unstructured-io.github.io/unstructured/best_practices/table_extraction_pdf.html
[4] https://pub.towardsai.net/advanced-rag-02-unveiling-pdf-parsing-b84ae866344e
[5] https://github.com/facebookresearch/nougat
[6] https://github.com/clovaai/donut/
[7] https://arxiv.org/pdf/1611.00471.pdf
[8] https://aclanthology.org/2020.acl-main.398.pdf
[9] https://arxiv.org/pdf/2305.13062.pdf
[10] https://docs.llamaindex.ai/en/stable/examples/multi_modal/multi_modal_pdf_tables.html
[13] https://openai.com/research/clip
[14] https://openai.com/research/gpt-4v-system-card
[16] https://www.adept.ai/blog/fuyu-8b
[17] https://python.langchain.com/docs/modules/data_connection/retrievers/multi_Vector
[18] https://arxiv.org/pdf/2308.13418.pdf
[19] https://arxiv.org/pdf/2111.15664.pdf
[21] https://arxiv.org/pdf/1706.03762.pdf
이 기사는 Baihai IDP가 원저자의 승인을 받아 편집한 것입니다. 번역물을 재인쇄해야 하는 경우 당사에 연락하여 승인을 받으시기 바랍니다.
원본 링크:
https://ai.plainenglish.io/advanced-rag-07-exploring-rag-for-tables-5c3fc0de7af6
알려지지 않은 오픈 소스 프로젝트가 얼마나 많은 수익을 가져올 수 있습니까? Microsoft의 중국 AI 팀은 수백 명의 사람들을 모아 미국으로갔습니다. Huawei는 Yu Chengdong의 직업 변경이 15년 동안 "FFmpeg Pillar of Shame"에 못 박혔다 고 공식 발표했습니다. 이전에는 그랬지만 오늘은 우리에게 감사해야 합니다.— Tencent QQ Video가 과거의 굴욕을 복수한다고요? Huazhong University of Science and Technology의 오픈 소스 미러 사이트가 외부 액세스 보고를 위해 공식적으로 공개되었습니다 . Django는 여전히 74%의 개발자가 선택한 제품입니다. Zed 편집자는 유명한 오픈 소스 회사의 전직 직원이었습니다 . 소식을 전했습니다: 기술 리더는 부하 직원의 도전을 받은 후 격노하고 무례하게 행동하여 해고되었으며 임신했습니다. 여직원 Alibaba Cloud가 공식적으로 Tongyi Qianwen 2.5를 출시했습니다. Microsoft는 Rust Foundation에 100만 달러를 기부했습니다.