
LLM(Large Language Model) 기술의 발전으로 RAG(Retrieval Augmented Generation) 기술이 널리 논의되고 연구되었으며, 일반 RAG 검색에 비해 점점 더 발전된 RAG 검색 방법이 발견되었습니다. 더 심층적인 기술 세부정보와 더 복잡한 검색 전략을 통해 더 관련성이 높고 더 풍부한 정보 검색 결과를 얻을 수 있습니다. 이 기사에서는 먼저 이러한 기술에 대해 논의하고 Milvus를 기반으로 한 구현 사례를 제공합니다.
01.주니어RAG
기본 RAG의 정의
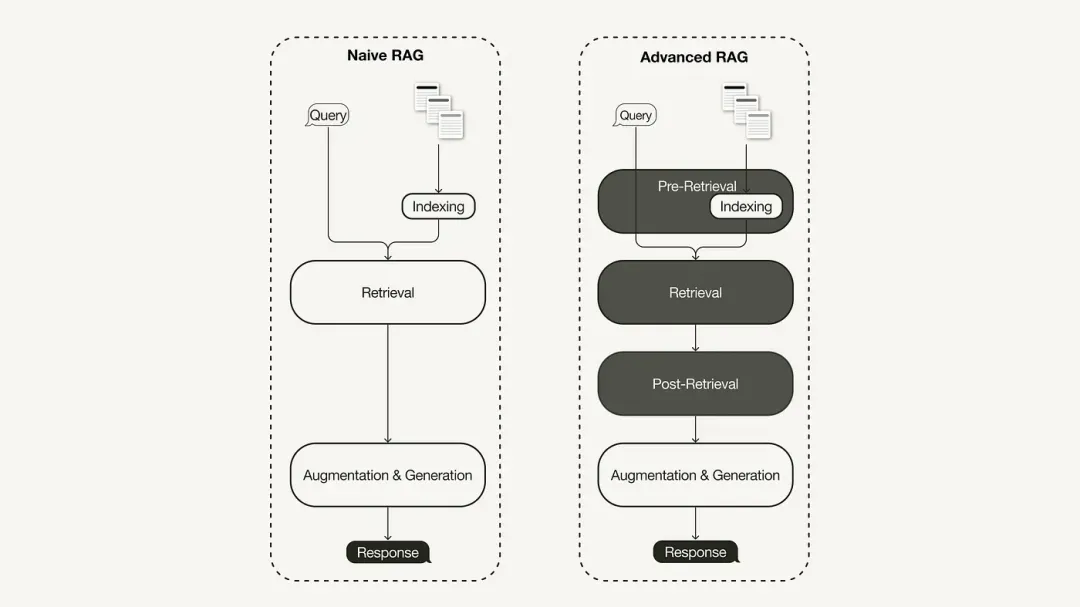
기본 RAG 연구 패러다임은 초기 방법론을 나타내며 ChatGPT가 널리 채택된 직후 중요성을 얻었습니다. 기본 RAG는 인덱싱, 검색 및 생성을 포함한 전통적인 프로세스를 따르며 종종 "검색-읽기" 프레임워크로 설명되며 해당 워크플로우에는 세 가지 주요 단계가 포함됩니다.
-
코퍼스는 개별 청크로 나누어지고 인코더 모델은 벡터 인덱스를 구축하는 데 사용됩니다.
-
RAG는 쿼리와 인덱싱된 청크 간의 벡터 유사성을 기반으로 청크를 식별하고 검색합니다.
-
모델은 검색된 청크에서 얻은 상황별 정보를 기반으로 답변을 생성합니다.
기본 RAG의 제한 사항
기본 RAG는 "검색", "생성" 및 "향상"이라는 세 가지 핵심 영역에서 중요한 과제에 직면해 있습니다.
기본 RAG의 검색 품질에는 정밀도가 낮고 재현율이 낮은 등 많은 문제가 있습니다. 정밀도가 낮으면 검색된 블록이 잘못 정렬될 뿐만 아니라 환각과 같은 잠재적인 문제가 발생할 수 있습니다. 회수율이 낮으면 관련 블록을 모두 검색할 수 없게 되어 LLM의 포괄적인 응답이 충분하지 않게 됩니다. 또한 오래된 정보를 사용하면 문제가 더욱 악화되고 부정확한 검색 결과가 나올 수 있습니다.
생성된 응답의 품질은 환상적 문제에 직면합니다. 즉, LLM에서 생성된 답변은 제공된 컨텍스트를 기반으로 하지 않거나 컨텍스트와 관련이 없거나 생성된 응답에 유해하거나 차별적인 콘텐츠가 포함될 수 있는 잠재적인 위험이 있습니다.
향상 과정에서 기본 RAG는 검색된 구절의 맥락을 현재 세대 작업과 효과적으로 통합하는 방법에 대한 상당한 과제에 직면합니다. 비효율적인 통합은 일관되지 않거나 단편화된 출력을 초래할 수 있습니다. 중복성과 중복도 까다로운 문제입니다. 특히 검색된 여러 구절에 유사한 정보가 포함되어 있고 생성된 응답에 중복 콘텐츠가 나타날 수 있는 경우 더욱 그렇습니다.
02. 고급 RAG
기본 RAG의 단점을 해결하기 위해 고급 RAG가 탄생하고 그 기능을 목표로 강화했습니다. 먼저 검색 전 최적화, 검색 중간 최적화, 검색 후 최적화로 분류할 수 있는 이러한 기술에 대해 논의합니다.
검색 전 최적화
검색 전 최적화는 데이터 인덱스 최적화 및 쿼리 최적화에 중점을 둡니다. 데이터 인덱스 최적화 기술은 검색 효율성을 향상시키는 방식으로 데이터를 저장하는 것을 목표로 합니다.
-
슬라이딩 윈도우: 데이터 블록 간의 중첩을 사용하며 이는 가장 간단한 기술 중 하나입니다.
-
데이터 세분성 강화: 관련 없는 정보 제거, 사실의 정확성 확인, 오래된 정보 업데이트 등 데이터 정리 기술을 적용합니다.
-
필터링을 위한 날짜, 목적 또는 장 정보와 같은 메타데이터를 추가합니다.
-
인덱스 구조 최적화에는 블록 크기 조정 또는 다중 인덱스 전략 사용과 같은 다양한 데이터 인덱싱 전략이 포함됩니다. 이 기사에서 구현할 기술 중 하나는 문장 창 검색으로, 검색 시 개별 문장을 포함하고 추론 시 이를 더 큰 텍스트 창으로 대체합니다.
검색 중 최적화
검색 단계에서는 가장 관련성이 높은 컨텍스트를 식별하는 데 중점을 둡니다. 일반적으로 검색은 쿼리와 인덱싱된 데이터 간의 의미적 유사성을 계산하는 벡터 검색을 기반으로 합니다. 따라서 대부분의 검색 최적화 기술은 임베딩 모델을 중심으로 이루어집니다.
-
임베딩 모델 미세 조정: 임베딩 모델을 특정 도메인 컨텍스트에 맞게 사용자 정의합니다. 특히 발달 단계에 있거나 희귀한 용어가 있는 도메인의 경우 더욱 그렇습니다. 예를 들어
BAAI/bge-small-en미세 조정이 가능한 고성능 임베딩 모델이 있습니다. -
동적 임베딩: 단어당 하나의 벡터를 사용하는 정적 임베딩과 달리 단어가 사용되는 컨텍스트에 적응합니다. 예를 들어 OpenAI는
embeddings-ada-02상황에 따른 이해를 포착하는 복잡한 동적 임베딩 모델입니다. 벡터 검색 외에도 일반적으로 벡터 검색과 키워드 기반 검색을 결합한 개념을 의미하는 하이브리드 검색과 같은 다른 검색 기술이 있습니다. 이 검색 기술은 검색에 정확한 키워드 일치가 필요한 경우 유용합니다.
검색 후 최적화
검색된 컨텍스트 콘텐츠의 경우 창 제한을 초과하는 컨텍스트 또는 컨텍스트에 의해 발생하는 노이즈와 같은 노이즈가 발생하여 주요 정보에 대한 주의가 산만해집니다.
-
프롬프트 압축: 관련 없는 콘텐츠를 제거하고 중요한 컨텍스트를 강조하여 전체 프롬프트 길이를 줄입니다.
-
순위 재지정: 기계 학습 모델을 사용하여 검색된 컨텍스트의 관련성 점수를 다시 계산합니다.
검색 후 최적화 기술에는 다음이 포함됩니다.
03. Milvus + LlamaIndex 기반 고급 RAG 구현
우리가 구현한 고급 RAG는 OpenAI의 언어 모델, Hugging Face에서 호스팅되는 BAAI 재배치 모델 및 Milvus 벡터 데이터베이스를 사용합니다.
Milvus 지수 생성
from llama_index.core import VectorStoreIndex
from llama_index.vector_stores.milvus import MilvusVectorStore
from llama_index.core import StorageContext
vector_store = MilvusVectorStore(dim=1536,
uri="http://localhost:19530",
collection_name='advance_rag',
overwrite=True,
enable_sparse=True,
hybrid_ranker="RRFRanker",
hybrid_ranker_params={"k": 60})
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex(
nodes,
storage_context=storage_context
)
인덱스 최적화 예: 문장 창 검색
문장 창 검색 기술을 구현하기 위해 LlamaIndex에서 SentenceWindowNodeParser를 사용합니다.
from llama_index.core.node_parser import SentenceWindowNodeParser
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
SentenceWindowNodeParser는 두 가지 작업을 수행합니다.
문서를 포함된 별도의 문장으로 분리합니다.
각 문장에 대해 컨텍스트 창을 만듭니다. window_size = 3을 지정하면 결과 창에는 포함된 문장 앞의 문장부터 시작하여 뒤의 문장까지 세 개의 문장이 포함됩니다. 이 창은 메타데이터로 저장됩니다. 검색하는 동안 쿼리와 가장 일치하는 문장이 반환됩니다. 검색 후에는 a를 정의 MetadataReplacementPostProcessor하고 목록에서 사용하여 node_postprocessors메타데이터에서 문장을 전체 창으로 대체 해야 합니다 .
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
postproc = MetadataReplacementPostProcessor(
target_metadata_key="window"
)
...
query_engine = index.as_query_engine(
node_postprocessors = [postproc],
)
검색 최적화 예: 하이브리드 검색
LlamaIndex에서 하이브리드 검색을 구현하려면 기본 벡터 데이터베이스가 하이브리드 검색 쿼리를 지원하는 경우 쿼리 엔진에 대해 두 가지 매개 변수만 변경하면 됩니다. Milvus 버전 2.4에서는 이전에는 하이브리드 검색을 지원하지 않았지만 최근 출시된 버전 2.4에서는 이미 이 기능을 지원합니다.
query_engine = index.as_query_engine(
vector_store_query_mode="hybrid", #Milvus 2.4开始支持, 在2.4版本之前使用 Default
)
검색 후 최적화 예: 순위 재지정
고급 RAG에 순위 재지정을 추가하려면 다음 세 가지 간단한 단계만 필요합니다.
먼저 Hugging Face 를 사용하여 re-ranking 모델을 정의합니다 BAAI/bge-reranker-base.
node_postprocessors쿼리 엔진에서 목록 에 재정렬 모델을 추가합니다 .
더 많은 컨텍스트 조각을 검색하려면 쿼리 엔진을 늘리십시오 similarity_top_k. 이는 재배열 후 top_n으로 줄일 수 있습니다.
from llama_index.core.postprocessor import SentenceTransformerRerank
rerank = SentenceTransformerRerank(
top_n = 3,
model = "BAAI/bge-reranker-base"
)
...
query_engine = index.as_query_engine(
similarity_top_k = 3,
node_postprocessors = [rerank],
...,
)
자세한 구현 코드는 Baidu Netdisk 링크를 참조하세요: https://pan.baidu.com/s/1Cj_Fmy9-SiQFMFNUmO0OZQ?pwd=r2i1 추출 코드: r2i1
"Qing Yu Nian 2"의 불법 복제된 리소스가 npm에 업로드되어 npmmirror가 unpkg 서비스를 중단하게 되었습니다. Zhou Hongyi: Google에 남은 시간이 많지 않습니다. time.sleep(6) 여기서는 어떤 역할을 합니까? 리누스는 '개사료 먹기'에 가장 적극적입니다! 새로운 iPad Pro는 12GB의 메모리 칩을 사용하지만 8GB의 메모리를 가지고 있다고 주장합니다. People's Daily Online은 사무용 소프트웨어의 마트료시카 스타일 충전을 검토합니다. "세트"를 적극적으로 해결해야만 Flutter 3.22 및 Dart 3.4 출시가 가능 합니다. 'ref/reactive'가 필요 없는 Vue3의 새로운 개발 패러다임, 'ref.value'가 필요 없음 MySQL 8.4 LTS 중국어 매뉴얼 출시: 데이터베이스 관리의 새로운 영역을 마스터하는 데 도움 Tongyi Qianwen GPT-4 수준 메인 모델 가격 인하 97% 증가, 1위안 200만 토큰