


공유 게스트: Qiu Lu, Tang Chunxu, Wang Beinan
현재 인공지능(AI)과 머신러닝(ML) 분야는 빠르게 발전하고 있으며 훈련 중에 대규모 데이터 세트를 효과적으로 처리하는 것이 점점 더 중요해지고 있습니다. Ray는 효율적인 데이터 스트림 처리를 통해 대규모 데이터 세트 교육을 가능하게 하는 이 분야의 중요한 플레이어가 되었습니다. Ray는 대규모 데이터 세트를 관리 가능한 덩어리로 나누고 전체 데이터 세트를 훈련 기계에 로컬로 저장할 필요 없이 훈련 작업을 더 작은 작업으로 나눕니다. 그러나 이 혁신적인 접근 방식은 몇 가지 과제에도 직면해 있습니다.
Ray는 대규모 데이터세트로 훈련을 용이하게 하지만 데이터 로딩은 여전히 심각한 병목 현상을 발생시킵니다. 매 에포크마다 원격 스토리지에서 전체 데이터 세트를 다시 로드해야 하므로 GPU 사용률이 크게 감소하고 저장된 데이터의 전송 비용이 증가하므로 훈련 과정에서 데이터를 관리하고 효율성을 높이기 위한 보다 최적화된 방법이 필요합니다.
Ray는 주로 메모리를 사용하여 데이터를 저장하며, 메모리 내 객체 스토리지는 대용량 작업 데이터를 위해 설계되었습니다. 그러나 이 접근 방식은 대규모 작업에 필요한 데이터를 실행하기 전에 Ray의 메모리 저장소에 미리 로드해야 하기 때문에 데이터 집약적인 작업에서 병목 현상에 직면합니다. 객체 스토리지의 크기는 일반적으로 훈련 데이터 세트를 수용할 수 없기 때문에 여러 훈련 에포크에 걸쳐 데이터를 캐싱하는 데 적합하지 않습니다. 이는 또한 Ray 프레임워크를 위한 보다 확장 가능한 데이터 관리 솔루션의 필요성을 강조합니다.
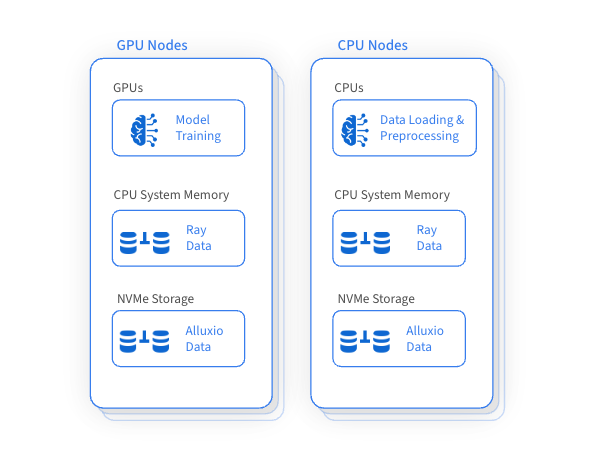
Ray의 중요한 장점 중 하나는 데이터 로딩 및 전처리에 CPU를 활용하면서 훈련에는 GPU를 활용한다는 것입니다. 이 방법은 Ray 클러스터 내에서 GPU, CPU 및 메모리 리소스의 효율적인 활용을 보장하지만 디스크 리소스의 활용도가 낮고 효과적인 관리가 부족합니다. 혁신적인 아이디어가 등장했습니다. 머신 전체에서 비효율적인 디스크 리소스를 지능적으로 관리하여 트레이닝 데이터 세트를 캐시하고 액세스하는 고성능 데이터 액세스 레이어를 구축하면 전반적인 트레이닝 성능이 크게 향상되고 원격 스토리지 액세스 빈도가 절감됩니다.
Alluxio는 분산 캐싱을 위해 GPU 및 인접 CPU 시스템에서 사용되지 않은 디스크 용량을 영리하고 효율적으로 활용하여 대규모 데이터 세트에 대한 교육을 가속화합니다. 이 혁신적인 접근 방식은 대규모 데이터 세트를 사용한 교육에 중요한 데이터 로딩 성능을 크게 향상시키는 동시에 원격 스토리지 및 관련 데이터 전송 비용에 대한 의존도를 줄입니다.
Alluxio를 통합하면 Ray의 데이터 관리 기능이 향상되고 다음과 같은 많은 이점이 제공됩니다.
√
확장성
데이터 액세스 및 캐싱은 확장성이 뛰어납니다.
√
데이터 액세스 속도 향상
고성능 디스크를 활용하여 데이터 캐시
Parquet와 같은 열 저장 파일 형식의 높은 동시성 무작위 읽기에 최적화되었습니다.
제로 카피
√
신뢰성과 가용성
단일 장애 지점 없음
가동 중단 시 강력한 원격 스토리지 액세스
√
유연한 자원 관리
워크로드 요구 사항에 따라 캐시 리소스를 동적으로 할당하고 해제합니다.
Ray는 기계 학습 워크플로를 효과적으로 조율하고 데이터 로딩, 전처리 및 교육 프레임워크와 원활하게 통합할 수 있습니다. 고성능 데이터 액세스 레이어인 Alluxio는 특히 원격 스토리지 데이터에 반복적으로 액세스해야 하는 경우 AI/ML 교육 및 추론 작업을 크게 최적화할 수 있습니다.
Ray는 PyArrow를 활용하여 데이터를 로드하고 데이터 형식을 Arrow 형식으로 변환한 후 다음 단계의 Ray 워크플로에서 사용합니다. PyArrow는 스토리지 연결 문제를 fsspec 프레임워크에 위임하고 Alluxio는 Ray와 기본 스토리지 시스템(예: S3, Azure Blob Storage 및 Hugging Face) 사이의 중간 캐시 계층 역할을 합니다.
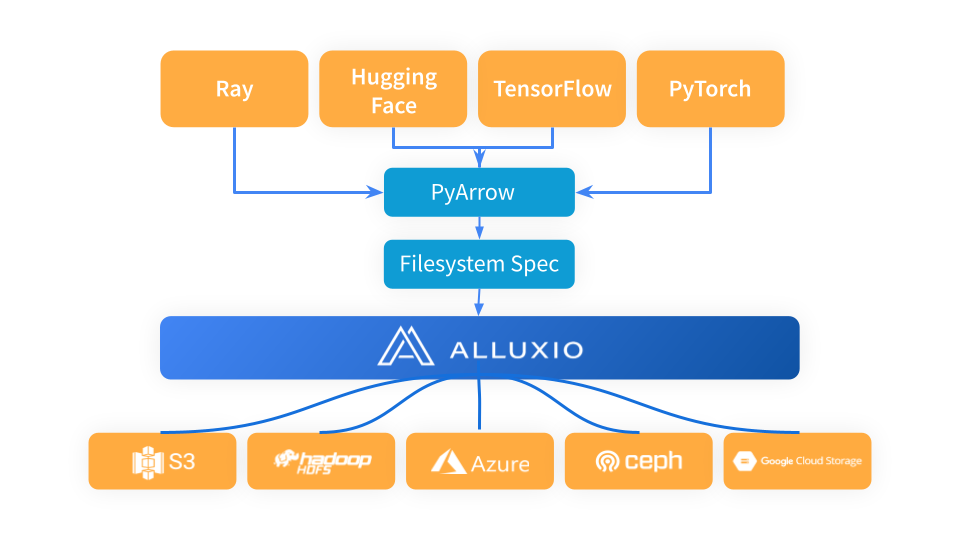
Alluxio를 Ray와 S3 사이의 캐싱 레이어로 사용하는 경우 간단히 Alluxiofs를 가져오고 Alluxio 파일 시스템을 초기화한 다음 Ray 파일 시스템을 Alluxio로 변경하면 됩니다.
# Import fsspec & alluxio fsspec implementationimport fsspecfrom alluxiofs import AlluxioFileSystemfsspec.register_implementation("alluxio", AlluxioFileSystem)# Create Alluxio filesystem with S3 as the underlying storage systemalluxio = fsspec.filesystem("alluxio", target_protocol=”s3”, etcd_host=args.etcd_host)# Ray read data from Alluxio using S3 URLds = ray.data.read_images("s3://datasets/imagenet-full/train", filesystem=alluxio)
우리는 Ray Data의 Ray Data 야간 테스트를 사용하여 서로 다른 훈련 시대에 동일한 지역에서 Alluxio와 S3의 데이터 로딩 성능을 비교합니다. 벤치마크 결과에 따르면 Alluxio를 Ray와 통합하면 스토리지 비용이 크게 절감되고 처리량이 향상될 수 있습니다.

√
향상된 데이터 액세스 성능: Ray의 객체 스토리지가 메모리 압박의 영향을 받지 않을 때 Alluxio의 처리량은 동일한 영역에서 S3의 처리량의 2배입니다.
√
이점은 메모리 압박에서 더욱 분명해집니다. Ray의 객체 스토리지가 메모리 압박에 직면할 때 Alluxio의 성능 이점이 크게 증가하고 처리량이 S3보다 5배 더 높다는 점은 주목할 가치가 있습니다.
Ray 작업의 경우 사용되지 않는 디스크 리소스를 분산 캐시용 스토리지로 사용하는 것은 전략적으로 매우 중요합니다. 이 방법은 데이터 로딩 성능을 크게 향상시키며, 여러 시대에 걸쳐 동일한 데이터 세트를 사용하여 훈련하거나 조정할 때 특히 유용합니다. 또한 Ray는 메모리 부족에 직면할 때 이러한 시나리오에서 데이터 관리 프로세스를 최적화하고 단순화하기 위한 실용적인 솔루션을 제공할 수 있습니다.
✦
[더 많은 정보를 얻으려면 어시스턴트를 추가하세요]
✦

✦
【최근 인기】
✦

✦
【바오뎬 시장】
✦






이 기사는 WeChat 공개 계정인 Alluxio(Alluxio_China)에서 공유되었습니다.
침해가 있는 경우 [email protected]에 연락하여 삭제를 요청하세요. 이 글은 " OSC 소스 생성 계획
" 에 참여하고 있습니다 . 이 글을 읽고 계신 여러분의 많은 참여와 공유 부탁드립니다.