
escreva na frente
Este artigo apresenta principalmente o artigo "Kepler: Robust Learning for Faster Parametric Query Optimization" publicado no SIGMOD em 2023. Este artigo combina otimização de consulta parametrizada e otimização de consulta para consultas parametrizadas, com o objetivo de reduzir o tempo de planejamento de consulta e, ao mesmo tempo, melhorar a eficiência da consulta.
Para tanto, o autor propõe um método de otimização de consultas paramétricas baseado em aprendizado profundo de ponta a ponta chamado Kepler (K-plan Evolution for Parametric Query Optimization: Learned, Empirical, Robust).
Consulta numérica refere-se a um tipo de consulta que possui a mesma estrutura SQL e difere apenas nos valores dos parâmetros vinculados. Como exemplo, considere a seguinte estrutura de consulta:
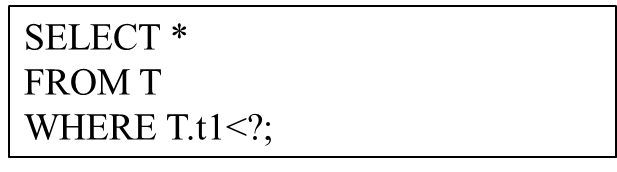
A estrutura da consulta pode ser considerada um modelo de uma consulta parametrizada e o "?" representa diferentes valores de parâmetros. Todas as instruções SQL executadas pelo usuário possuem essa estrutura de consulta, mas os valores reais dos parâmetros podem ser diferentes. Esta é uma consulta parametrizada. Essas consultas parametrizadas são usadas com muita frequência em bancos de dados modernos. Como ele executa continuamente o mesmo modelo de consulta repetidamente, traz oportunidades para melhorar o desempenho de sua consulta.
A otimização de consulta parametrizada (PQO) é usada para otimizar o desempenho das consultas parametrizadas mencionadas acima. O objetivo é reduzir ao máximo o tempo de planejamento da consulta, evitando a regressão de desempenho. As abordagens existentes dependem muito do otimizador de consulta integrado do sistema, tornando-as sujeitas à subotimização inerente do otimizador. O autor acredita que o sistema ideal para consultas parametrizadas não deve apenas reduzir o tempo de planejamento de consultas por meio de PQO, mas também melhorar o desempenho de execução de consultas do sistema por meio de otimização de consultas (QO).
A otimização de consulta (QO) é usada para ajudar uma consulta a encontrar seu plano de execução ideal. A maioria dos métodos existentes para melhorar a otimização de consultas aplica aprendizado de máquina, como estimadores de cardinalidade/custo baseados em aprendizado de máquina. No entanto, o método atual de otimização de consulta baseado na aprendizagem tem algumas deficiências: (1) O tempo de inferência é muito longo; (2) A capacidade de generalização é fraca; (3) A melhoria do desempenho não é clara; e o desempenho pode diminuir o retorno.
As deficiências acima representam desafios para os métodos baseados em aprendizagem, pois não podem garantir a melhoria no tempo de execução dos resultados da previsão. Para resolver os problemas acima, o autor propõe o Kepler: um método de otimização de consultas parametrizadas baseado em aprendizagem ponta a ponta.
Os autores separam a otimização de consultas paramétricas em dois problemas: geração de planos candidatos e estruturas de previsão baseadas em aprendizagem. É dividido principalmente em três etapas: geração de novos planos candidatos, coleta de dados de treinamento e design robusto de modelo de rede neural. A combinação dos três reduz o tempo de planejamento da consulta e melhora o desempenho da execução da consulta, ao mesmo tempo em que atende às metas de PQO e QO. A seguir, primeiro apresentamos a arquitetura geral do Kepler e, em seguida, explicamos detalhadamente o conteúdo específico de cada módulo.
Arquitetura geral
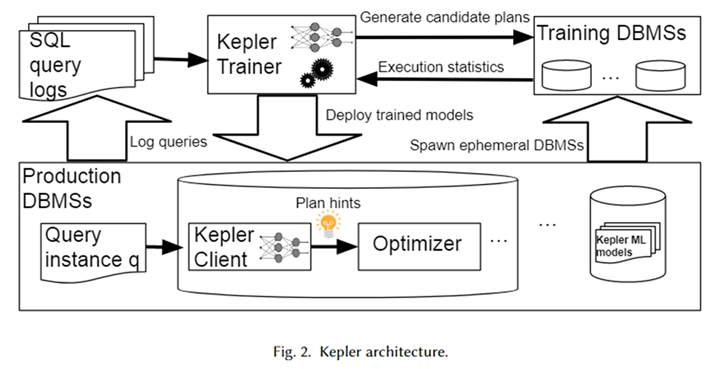
A arquitetura geral do Kepler é mostrada na figura acima. Primeiro, obtenha o modelo de consulta parametrizado e a instância de consulta correspondente (ou seja, a consulta com valores de parâmetros reais) do log do sistema de banco de dados para formar uma carga de trabalho. O Kepler Trainer é usado para treinar um modelo preditivo de rede neural para esta carga de trabalho. Primeiro, ele gera planos candidatos para toda a carga de trabalho e os executa em um sistema de banco de dados temporário para obter o tempo real de execução da consulta.
Use esse tempo de consulta para treinar um modelo de rede neural. Após a conclusão do treinamento, ele é implantado no sistema de banco de dados do ambiente de produção, denominado Kepler Client. Quando o usuário insere uma instância de consulta, o Cliente Kepler pode prever o melhor plano de execução para ela e entregá-lo ao otimizador na forma de dica de plano para gerar e executar o melhor plano.
Geração de plano candidato: evolução da contagem de linhas
O objetivo da geração de planos candidatos é construir um conjunto de planos que contenha um plano de execução quase ideal para cada instância de consulta na carga de trabalho. Além disso, deve ser o menor possível para evitar sobrecarga excessiva no processo subsequente de coleta de dados de treinamento. Os dois limitam-se mutuamente e como equilibrar estes dois objectivos é um grande desafio na geração de planos candidatos.
A Equação 1 formula metas específicas de geração de planos. Entre eles, está uma instância de consulta na carga de trabalho W, é o plano de execução selecionado pelo otimizador, é o plano ideal no plano definido em circunstâncias ideais e ExecTime é o tempo de execução do plano correspondente na instância. Portanto, a conotação da Equação 1 é a aceleração no tempo de execução do conjunto de planos candidatos em comparação com o conjunto de planos gerado pelo otimizador durante toda a carga de trabalho. O algoritmo é projetado para maximizar essa aceleração.
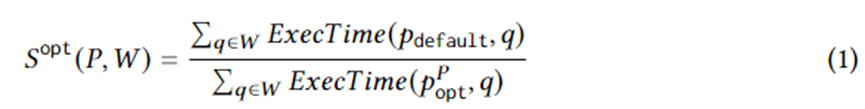
Para tanto, este artigo propõe Row Count Evolution (RCE), um algoritmo que gera novos planos perturbando aleatoriamente a estimativa de cardinalidade do otimizador. Ele gera uma série de planos para cada instância de consulta, combinados em um conjunto de planos candidatos para toda a carga de trabalho. A ideia por trás deste algoritmo é que a estimativa incorreta da base é a principal razão para a subotimização do otimizador. Ao mesmo tempo, o estágio de geração do plano candidato não precisa encontrar um plano específico (quase) ideal para cada instância de consulta, mas apenas incluir o plano (quase) ideal.
O algoritmo RCE gera continuamente novos planos por meio de iteração. Primeiro, o plano de iteração inicial é o plano gerado pelo otimizador. Para construir iterações subsequentes, primeiro é necessária uma amostragem aleatória uniforme do plano de geração anterior. Para cada plano amostrado, perturbe (altere) a cardinalidade de seu subplano de junção.
O método de perturbação consiste em amostrar aleatoriamente dentro do intervalo exponencial de sua cardinalidade estimada atual. A cardinalidade perturbada é entregue ao otimizador para gerar o plano ideal correspondente. Repita cada plano N vezes para gerar muitos planos de execução, entre os quais os planos de execução que não apareceram são retidos como o plano da próxima geração, e o processo acima é repetido.
Damos um exemplo específico para ilustrar visualmente o algoritmo acima, conforme mostrado na figura abaixo. Em primeiro lugar, o Plano Base é o melhor plano selecionado pelo otimizador. Ele tem dois subplanos de junção, A junta-se a B e C junta-se a D. Suas bases estimadas são 40 e 17, respectivamente.
A seguir, conjuntos de perturbações são gerados para os dois subplanos de junção do intervalo exponencial 10-1~101, que são [4,40,400] e [1,17,170], respectivamente. Amostras aleatórias são retiradas do conjunto de perturbações e entregues ao otimizador para seleção do plano. O Plano 1 é o novo plano selecionado pelo otimizador quando a cardinalidade é 400 e 17 respectivamente. Repetidos N vezes, os planos C1 são finalmente gerados como a próxima geração. Em seguida, experimente os planos S deles e repita o processo acima para cada plano para formar o plano de 2ª geração.
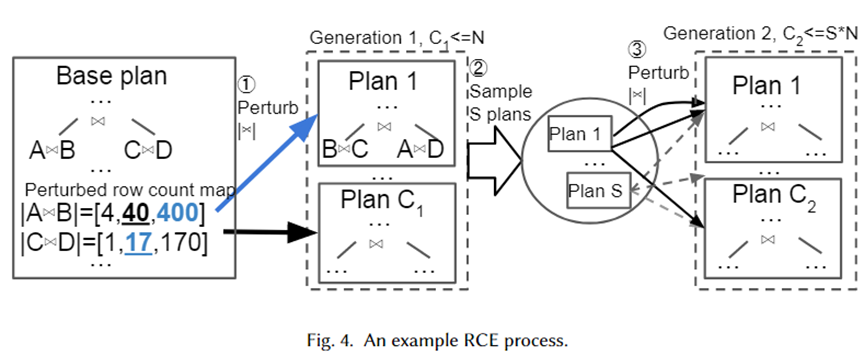
A razão pela qual os autores adotaram um intervalo exponencial como conjunto de perturbações é para ajustar a distribuição do erro de estimativa de cardinalidade do otimizador. Pode-se observar no algoritmo acima que, desde que o número de perturbações seja grande o suficiente, muita cardinalidade e seus planos correspondentes serão gerados. Dessa forma, quando uma instância de consulta chega, deve haver um plano em nosso conjunto de planos que esteja próximo da cardinalidade verdadeira, que pode ser considerado o plano (quase) ideal para a instância.
Coleta de dados de treinamento
Depois de gerar o conjunto de planos candidatos, cada plano é executado na carga de trabalho e os dados de tempo de execução são gerados para previsão do plano ideal supervisionado. Usar dados de execução reais em vez do custo estimado pelo otimizador pode evitar as limitações causadas pela subotimização do otimizador. O processo de execução é paralelizável. No entanto, executar todos os planos é uma despesa significativa. Portanto, os autores propõem duas estratégias para reduzir o desperdício de recursos causado pela execução desnecessária e subótima do plano.
Tempos limite adaptativos e reordenação de execução de planos, tempos limites adaptativos e reordenação de execução de planos. Os autores empregam um mecanismo de tempo limite para limitar a execução de planos abaixo do ideal. Para cada instância de consulta, ao executar cada plano, o tempo mínimo de execução atual pode ser registrado.
Uma vez que o tempo de execução de um plano excede um determinado intervalo de tempo mínimo de execução, ele não pode mais ser executado porque definitivamente não é o plano de execução ideal. Ao mesmo tempo, o tempo mínimo de execução é atualizado constantemente. Além disso, a execução de planos de consulta em ordem crescente de tempo de execução com base na execução de cada plano em outras instâncias de consulta pode ser usada como heurística para acelerar o mecanismo de tempo limite.
Plano online cobrindo poda, poda de conjunto de plano online. Após todos os planos terem sido executados para as primeiras N instâncias de consulta, eles são podados em K planos usando o problema Set Cover. A coleta de dados subsequente e o treinamento do modelo usam esses planos K. O problema Set Cover é definido conforme mostrado abaixo.
No contexto deste artigo, representa todas as instâncias de consulta, que podem ser representadas como planos diferentes, sendo cada plano um plano quase ideal para alguma instância de consulta. Portanto, o problema pode ser formulado usando o menor conjunto possível de planos para fornecer quase otimização para todas as instâncias de consulta. O problema é NP, então o autor usa um algoritmo ganancioso para resolvê-lo.

Previsão robusta do melhor plano
Depois de coletar dados de treinamento sobre o tempo real de execução do conjunto de planos candidatos, o aprendizado de máquina supervisionado é usado para prever o melhor plano para qualquer instância de consulta. O objetivo do treinamento pode ser expresso logicamente pela seguinte equação. onde representa o melhor plano escolhido pelo modelo para a instância de consulta. O significado desta equação é o speedup resultante do plano escolhido pelo modelo comparado ao plano escolhido pelo otimizador. Seu limite superior é a Equação 1. Em outras palavras, o modelo deve capturar tanto quanto possível a aceleração trazida pelos planos candidatos gerados pelo RCE.
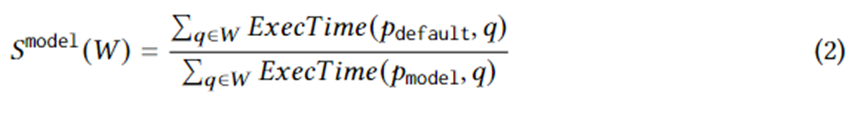
A estrutura do modelo adota uma rede neural direta e aplica os mais recentes progressos em incerteza de aprendizado de máquina, ou seja, Processos Gaussianos Neurais Normalizados Espectrais (SNGPs). Combiná-lo com a rede neural pode melhorar a convergência do modelo e, ao mesmo tempo, permitir que a rede neural produza a incerteza da previsão. Quando a incerteza é superior a um limite, o trabalho de previsão do plano é devolvido ao otimizador, que determina o melhor plano.
O modelo é caracterizado utilizando os valores reais de cada parâmetro. Para inserir os valores reais dos parâmetros na rede neural, é necessário algum pré-processamento, especialmente para dados do tipo string. Para dados do tipo string, o autor usa um vocabulário de tamanho fixo e baldes que não estão no vocabulário para representá-los como um vetor one-hot e adiciona uma camada de incorporação para aprender a incorporação do vetor one-hot e, em seguida, ser capaz de lidar com dados do tipo string.
Efeito experimental
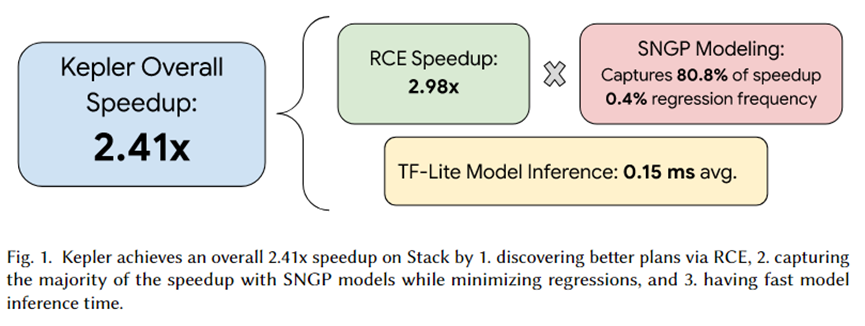
O autor deste artigo integrou o Kepler ao PostgreSQL e organizou uma série de experimentos. O resumo do experimento é mostrado na figura acima. O efeito de aceleração total trazido pelo Kepler é de 2,41 vezes. Entre eles, o conjunto de planos candidatos gerado pelo RCE pode trazer aceleração de cerca de 2,92 vezes, 80,8% é capturado pelo modelo de previsão SNGP e apenas 0,4% da regressão é alcançada. Além disso, o tempo de inferência do modelo é de apenas 0,15ms em média.
Resumir
Este artigo propõe o Kepler, uma abordagem baseada em aprendizagem que acelera de forma robusta consultas parametrizadas. Ele gera um plano candidato definido por meio do algoritmo Row Count Evolution (RCE), executa-o na carga de trabalho para obter o tempo de execução real e usa o tempo de execução real para treinar o modelo de previsão.
O modelo de predição adota Processos Gaussianos Neurais Normalizados Espectrais (SNGPs), o mais recente avanço na estimativa de incerteza de aprendizado de máquina, para melhorar a convergência enquanto gera a incerteza da predição. Com base nessa incerteza, é selecionado se o modelo ou o otimizador completa a predição. previsão do plano. Experimentos provaram que o RCE pode trazer efeitos de alta aceleração, e o SNGP pode capturar os efeitos de aceleração trazidos pelo RCE tanto quanto possível, evitando a regressão. Portanto, os objetivos de PQO e QO são alcançados ao mesmo tempo, ou seja, ao mesmo tempo que reduz o tempo de planejamento da consulta, o desempenho de execução da consulta é melhorado.
Decidi desistir do software industrial de código aberto . Grandes eventos - OGG 1.0 foi lançado, a Huawei contribuiu com todo o código-fonte do Ubuntu 24.04 LTS foi oficialmente demitido . ". O Fedora Linux 40 foi lançado oficialmente. Uma conhecida empresa de jogos lançou novos regulamentos: os presentes de casamento dos funcionários não devem exceder 100.000 yuans. A China Unicom lança a primeira versão chinesa Llama3 8B do mundo do modelo de código aberto. Pinduoduo é condenado a compensar 5 milhões de yuans por concorrência desleal Método de entrada na nuvem doméstica - apenas a Huawei não tem problemas de segurança de upload de dados na nuvem.