
1. Introdução ao contexto
Consultas parametrizadas referem-se a um tipo de consulta que possui o mesmo modelo e difere apenas nos valores dos parâmetros de ligação de predicados. Elas são amplamente utilizadas em aplicativos de banco de dados modernos. Eles executam ações repetidamente, o que oferece oportunidades de otimização de desempenho.
No entanto, o método atual de tratamento de consultas parametrizadas em muitos bancos de dados comerciais otimiza apenas a primeira instância de consulta (ou instância especificada pelo usuário) na consulta, armazena em cache seu melhor plano e o reutiliza para instâncias de consulta subsequentes. Embora este método otimize o tempo de minimização, devido a diferentes planos ideais para diferentes instâncias de consulta, a execução do plano em cache pode ser arbitrariamente abaixo do ideal, o que não é aplicável em cenários de aplicação reais.
A maioria dos métodos de otimização tradicionais exige muitas suposições sobre o otimizador de consulta, mas essas suposições geralmente não correspondem aos cenários reais do aplicativo. Felizmente, com o surgimento do aprendizado de máquina, os problemas acima podem ser resolvidos de forma eficaz. Esta edição apresentará em detalhes dois artigos publicados em VLDB2022 e SIGMOD2023:
Passo 1:《Aproveitando Logs de Consulta e Aprendizado de Máquina para Otimização de Consultas Paramétricas》
Passo 2:《Kepler: Aprendizado Robusto para Otimização de Consultas Paramétricas Mais Rápida》
2. Essência do Artigo 1
"Aproveitando logs de consulta e aprendizado de máquina para otimização de consulta paramétrica" Este artigo separa a otimização de consulta parametrizada em dois problemas:
(1) PopulateCache: armazena em cache K planos para um modelo de consulta:
para cada instância de consulta, seleciona o melhor plano; os planos em cache.
A arquitetura do algoritmo deste artigo é mostrada na figura abaixo. É dividido principalmente em dois módulos: PopulateCache e módulo getPlan.
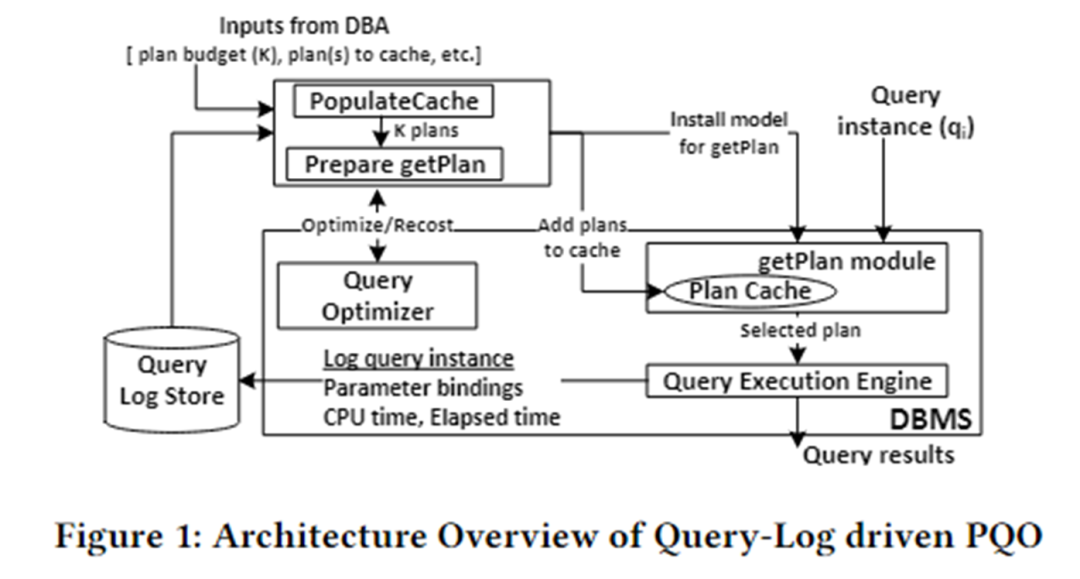
PopulateCache usa as informações no log de consulta para armazenar em cache K planos para todas as instâncias de consulta. O módulo getPlan primeiro coleta informações de custo entre K planos e instâncias de consulta interagindo com o otimizador e usa essas informações para treinar o modelo de aprendizado de máquina. Implante o modelo treinado no SGBD. Quando uma instância de consulta chega, o melhor plano para essa instância pode ser previsto rapidamente.
PreencherCache
O módulo PolulateCache é responsável por identificar um conjunto de planos de cache para uma determinada consulta parametrizada. A fase de pesquisa utiliza duas APIs otimizadas:
- Chamada do otimizador: Retorna o plano selecionado pelo otimizador para uma instância de consulta;
- Chamada de Recost: Retorna o custo estimado pelo otimizador para uma instância de consulta e plano correspondente;
O fluxo do algoritmo é o seguinte:
- Fase de coleta de plano: Chamada do otimizador para coletar planos candidatos para n instâncias de consulta no log de consulta;
- Fase de plano-recusto: Para cada instância de consulta e cada plano candidato, chame a chamada de recusto para formar uma matriz de plano-recusto;
- Fase de identificação do conjunto K: adota um algoritmo ganancioso e usa a matriz de recomposição do plano para armazenar em cache K planos para minimizar a subotimização.
obterPlan
O módulo getPlan é responsável por selecionar um dos K planos armazenados em cache para execução para uma determinada instância de consulta. O algoritmo getPlan pode considerar dois objetivos: minimizar o custo estimado pelo otimizador ou minimizar o custo real de execução entre K planos de cache.
Considere a meta 1: usar a matriz plano-recusto para treinar um modelo de ML supervisionado e considerar classificação e regressão.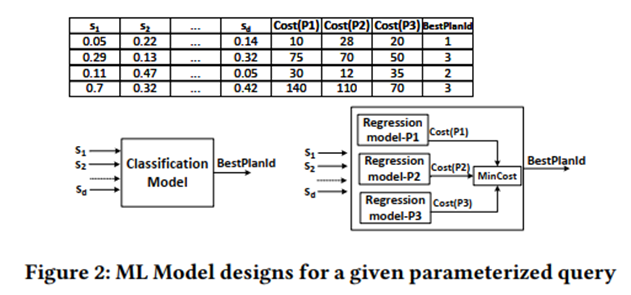
Considere o objetivo 2: Usar o modelo de treinamento de aprendizagem por reforço baseado no Multi-Armed Bandit.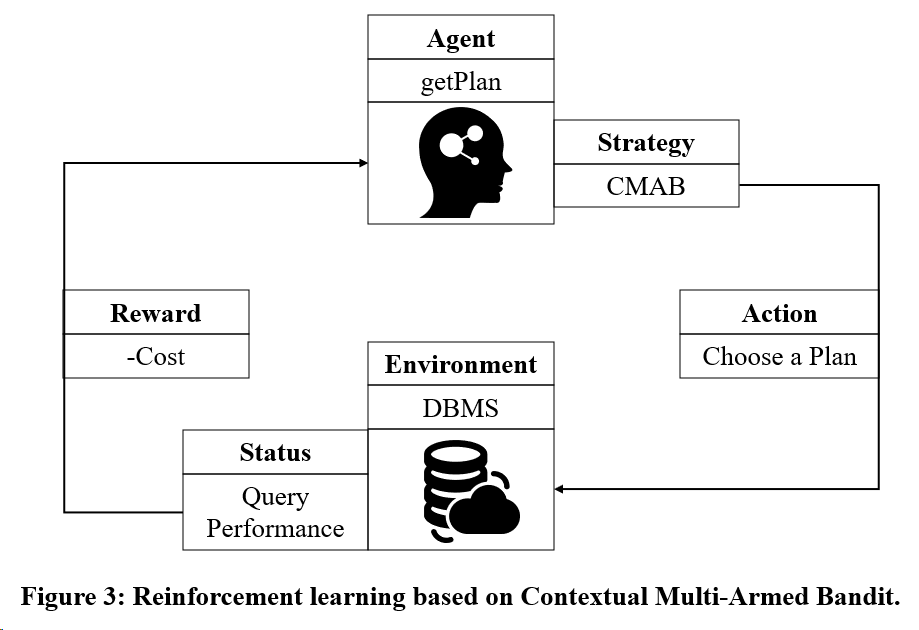
3. Essência do Artigo 2
"Kepler: aprendizado robusto para otimização de consulta paramétrica mais rápida" Este artigo propõe um método de otimização de consulta paramétrica baseado em aprendizado de ponta a ponta, que visa reduzir o tempo de otimização de consulta e melhorar o desempenho de execução de consulta.
A arquitetura do algoritmo é a seguinte. O Kepler também separa o problema em duas partes: geração de planos e previsão de planos baseada em aprendizagem. É dividido principalmente em três etapas: estratégia de geração de plano, fase de execução de consulta de treinamento e modelo robusto de rede neural.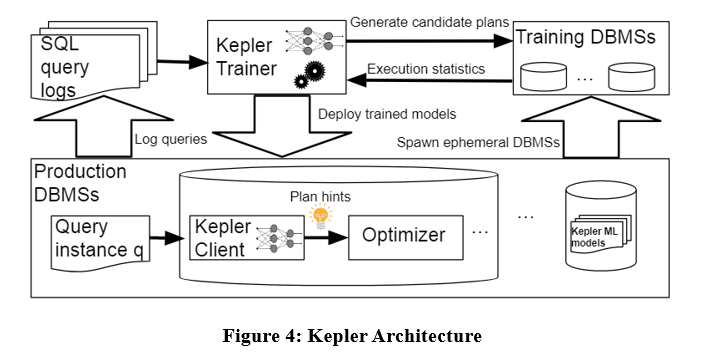
Conforme mostrado na figura acima, insira a instância de consulta no log de consulta no Kepler Trainer. O Kepler Trainer primeiro gera um plano candidato e, em seguida, coleta informações de execução relacionadas ao plano candidato como dados de treinamento para treinar o modelo de aprendizado de máquina. o modelo é implantado no DBMS. Quando uma instância de consulta chega, o Kepler Client é usado para prever o melhor plano e executá-lo.
Evolução da contagem de linhas
Este artigo propõe um algoritmo de geração de planos candidatos denominado Row Count Evolution (RCE), que gera planos candidatos perturbando a estimativa de cardinalidade do otimizador.
A ideia deste algoritmo vem de: a estimativa incorreta da cardinalidade é a principal causa da subotimização do otimizador, e o estágio de geração do plano candidato só precisa conter o plano ideal de uma instância, em vez de selecionar um único plano ideal.
O algoritmo RCE primeiro gera o plano ideal para a instância de consulta, depois perturba a cardinalidade de junção de seus subplanos dentro do intervalo de intervalo exponencial, repete-o várias vezes e executa múltiplas iterações e, finalmente, usa todos os planos gerados como planos candidatos. Exemplos específicos são os seguintes: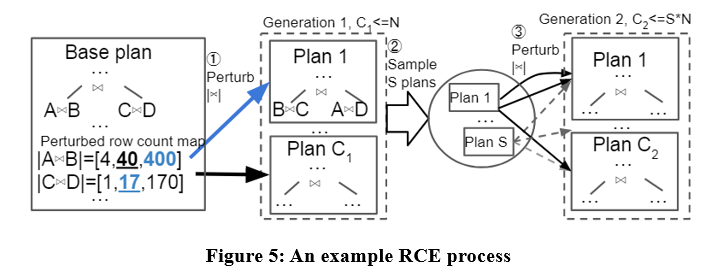
Com o algoritmo RCE, os planos candidatos gerados podem ser melhores que o plano produzido pelo otimizador. Porque o otimizador pode ter erros de estimativa de cardinalidade e o RCE pode produzir um plano ideal correspondente à cardinalidade correta, perturbando continuamente a estimativa de cardinalidade.
Coleta de dados de treinamento
Após obter o conjunto de planos candidatos, cada plano é executado na carga de trabalho de cada instância de consulta, e o tempo real de execução é coletado para treinamento do modelo supervisionado de previsão do plano ideal. O processo acima é relativamente complicado. Este artigo propõe alguns mecanismos para acelerar a coleta de dados de treinamento, como execução paralela, mecanismo de tempo limite adaptativo, etc.
Previsão robusta do melhor plano
Os dados de execução real resultantes são usados para treinar uma rede neural para prever o plano ideal para cada instância de consulta. A rede neural utilizada é um processo neural gaussiano normalizado espectral. Este modelo garante a estabilidade da rede e a convergência do treinamento, podendo fornecer estimativas de incerteza para previsões. Quando a estimativa de incerteza é maior que um certo limite, cabe ao otimizador selecionar um plano de execução. A regressão de desempenho é evitada até certo ponto.
4. Resumo
Os dois artigos acima separam consultas parametrizadas em populateCache e getPlan. A comparação entre os dois é mostrada na tabela abaixo.
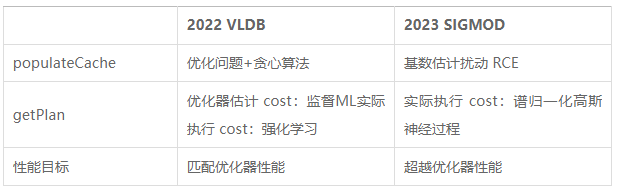
Embora os algoritmos baseados em modelos de aprendizado de máquina tenham um bom desempenho na previsão de planos, seu processo de coleta de dados de treinamento é caro e os modelos não são fáceis de generalizar e atualizar. Portanto, os métodos existentes de otimização de consultas parametrizadas ainda podem ser melhorados.
本文图示来源: 1) Kapil Vaidya & Anshuman Dutt, 《Leveraging Query Logs and Machine Learning for Parametric Query Optimization》, 2022 VLDB, https://dl.acm.org/doi/pdf/10.14778/3494124.3494126 2)LYRIC DOSHI & VINCENT ZHUANG, 《Kepler: aprendizagem robusta para otimização de consulta paramétrica mais rápida》, 2023 SIGMOD, https://dl.acm.org/doi/pdf/10.1145/3588963
Decidi desistir do software industrial de código aberto . Grandes eventos - OGG 1.0 foi lançado, a Huawei contribuiu com todo o código-fonte do Ubuntu 24.04 LTS foi oficialmente demitido . ". O Fedora Linux 40 foi lançado oficialmente. Uma conhecida empresa de jogos lançou novos regulamentos: os presentes de casamento dos funcionários não devem exceder 100.000 yuans. A China Unicom lança a primeira versão chinesa Llama3 8B do mundo do modelo de código aberto. Pinduoduo é condenado a compensar 5 milhões de yuans por concorrência desleal Método de entrada na nuvem doméstica - apenas a Huawei não tem problemas de segurança de upload de dados na nuvem.