
Em aplicativos de pesquisa, a pesquisa por palavra-chave tradicional sempre foi o principal método de pesquisa. Ela é adequada para cenários de consulta de correspondência exata e pode fornecer baixa latência e boa interpretabilidade de resultados. Nos últimos anos, a Pesquisa Semântica, uma tecnologia de aprimoramento de pesquisa baseada na tecnologia de recuperação de vetores, tornou-se cada vez mais popular. Ela usa modelos de aprendizado de máquina para converter objetos de dados (texto, imagens, áudio e vídeo, etc.) em vetores. a semelhança entre os objetos. Se o modelo utilizado for altamente relevante para o domínio do problema, muitas vezes pode compreender melhor o contexto e a intenção da pesquisa, melhorando assim a relevância dos resultados da pesquisa. no domínio do problema, o efeito será bastante reduzido.
Tanto a pesquisa por palavra-chave quanto a pesquisa semântica têm vantagens e desvantagens óbvias; portanto, a relevância geral da pesquisa pode ser melhorada combinando suas vantagens? A resposta é que combinações aritméticas simples não conseguem alcançar os resultados esperados por duas razões principais:
-
Primeiro, as pontuações de diferentes tipos de consultas não estão na mesma dimensão comparável, pelo que cálculos aritméticos simples não podem ser realizados diretamente.
-
Em segundo lugar, em um sistema de recuperação distribuído, as pontuações geralmente estão no nível do fragmento e as pontuações de todos os fragmentos precisam ser normalizadas globalmente.
Em resumo, precisamos encontrar um tipo de consulta ideal para resolver esses problemas. Ele pode executar cada cláusula de consulta individualmente, coletar os resultados da consulta no nível do fragmento e, finalmente, normalizar e mesclar as pontuações de todas as consultas para retornar o resultado final. é a solução de pesquisa híbrida.
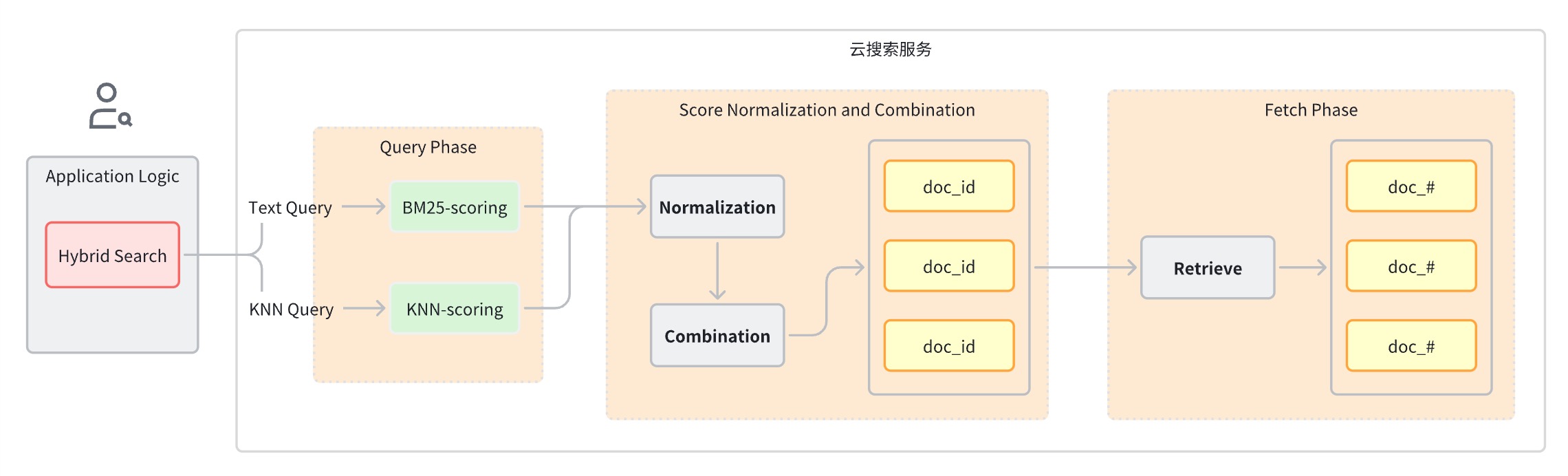
Normalmente, uma consulta de pesquisa híbrida pode ser dividida nas seguintes etapas:
-
Fase de consulta: use cláusulas de consulta mistas para pesquisa por palavra-chave e pesquisa semântica.
-
Estágio de normalização e fusão de pontuação, que segue o estágio de consulta.
-
Como cada tipo de consulta fornecerá um intervalo diferente de pontuações, este estágio executa uma operação de normalização nos resultados de pontuação de cada cláusula de consulta. Os métodos de normalização suportados são min_max, l2 e rrf.
-
Para combinar as pontuações normalizadas, os métodos de combinação incluem média_aritmética, média_geométrica e média_harmônica.
-
-
Os documentos são reordenados com base nas classificações combinadas e devolvidos ao usuário.
Ideias de implementação
A partir da introdução dos princípios anteriores, podemos ver que para implementar uma aplicação de recuperação híbrida, são necessárias pelo menos estas instalações técnicas básicas.
-
Mecanismo de pesquisa de texto completo
-
mecanismo de pesquisa vetorial
-
Modelo de aprendizado de máquina para incorporação de vetores
-
Pipeline de dados que converte texto, áudio, vídeo e outros dados em vetores
-
Classificação de fusão
A pesquisa em nuvem do Volcano Engine é baseada nos projetos de código aberto Elasticsearch e OpenSearch. Ele oferece suporte a recursos completos e maduros de recuperação de texto e recuperação de vetores desde o primeiro dia em que foi lançado. e evoluções para cenários de pesquisa híbrida, fornecendo uma solução de pesquisa híbrida que funciona imediatamente. Este artigo usará um aplicativo de pesquisa de imagens como exemplo para apresentar como desenvolver rapidamente um aplicativo de pesquisa híbrido com a ajuda da solução de serviço de pesquisa em nuvem Volcano Engine.

Seu processo ponta a ponta é resumido da seguinte forma:
-
Configurar e criar objetos relacionados
-
Pipeline de ingestão: oferece suporte à chamada automática do modelo para armazenar vetores de conversão de imagem no índice
-
Pipeline de pesquisa: oferece suporte à conversão automática de instruções de consulta de texto em vetores para cálculo de similaridade
-
Índice k-NN: o índice onde o vetor está armazenado
-
-
Grave os dados do conjunto de dados de imagem na instância do OpenSearch e o OpenSearch chamará automaticamente o modelo de aprendizado de máquina para converter o texto em um vetor de incorporação.
-
Quando o cliente inicia uma consulta de pesquisa híbrida, o OpenSearch chama o modelo de aprendizado de máquina para converter a consulta recebida em um vetor de incorporação.
-
OpenSearch realiza processamento de solicitação de pesquisa híbrida, combina pontuações de pesquisa por palavra-chave e pesquisa semântica e retorna resultados de pesquisa.
Planeje o combate real
Preparação ambiental
-
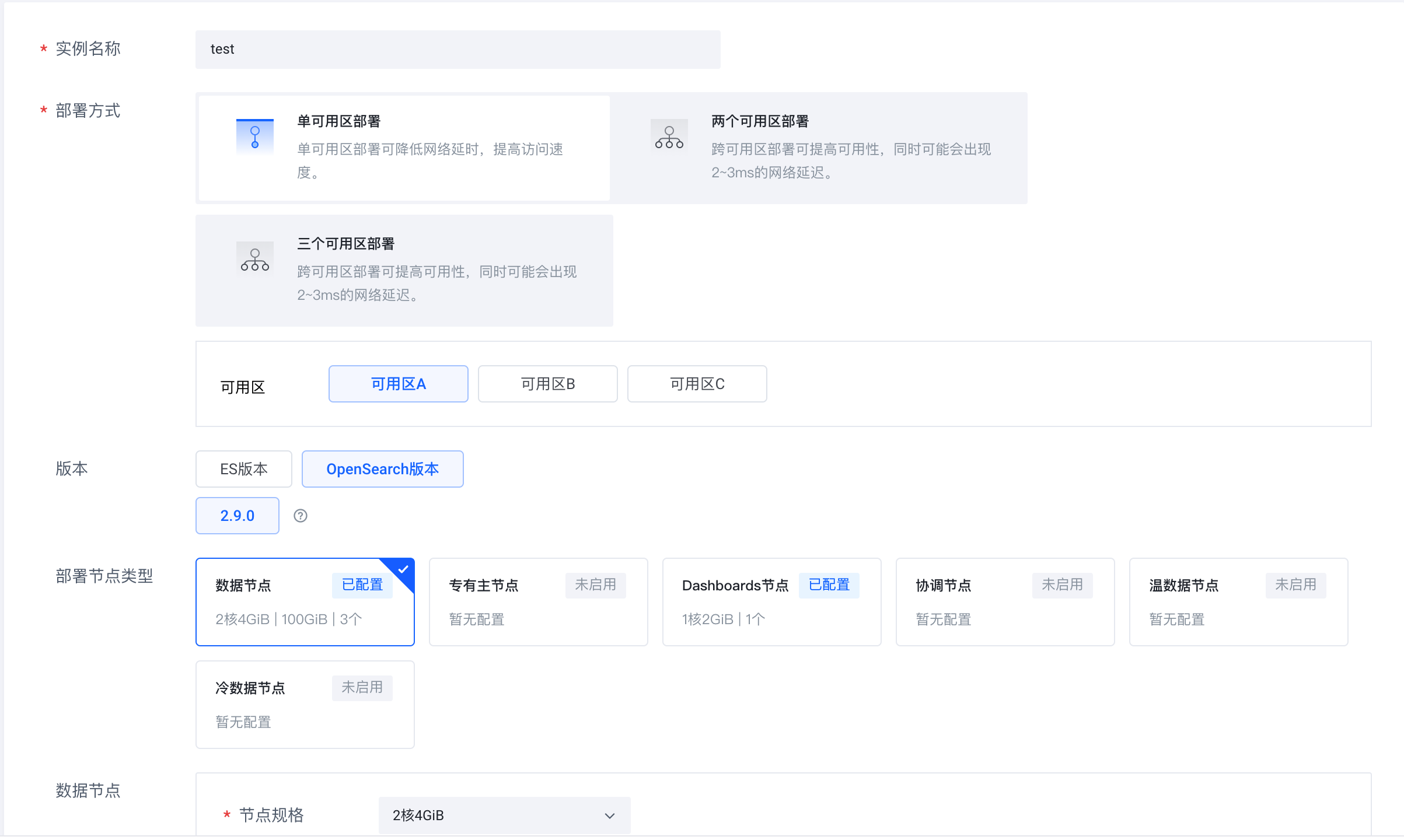
Faça login no serviço de pesquisa em nuvem do Volcano Engine (https://console.volcengine.com/es), crie um cluster de instância e selecione OpenSearch 2.9.0 para a versão.
-
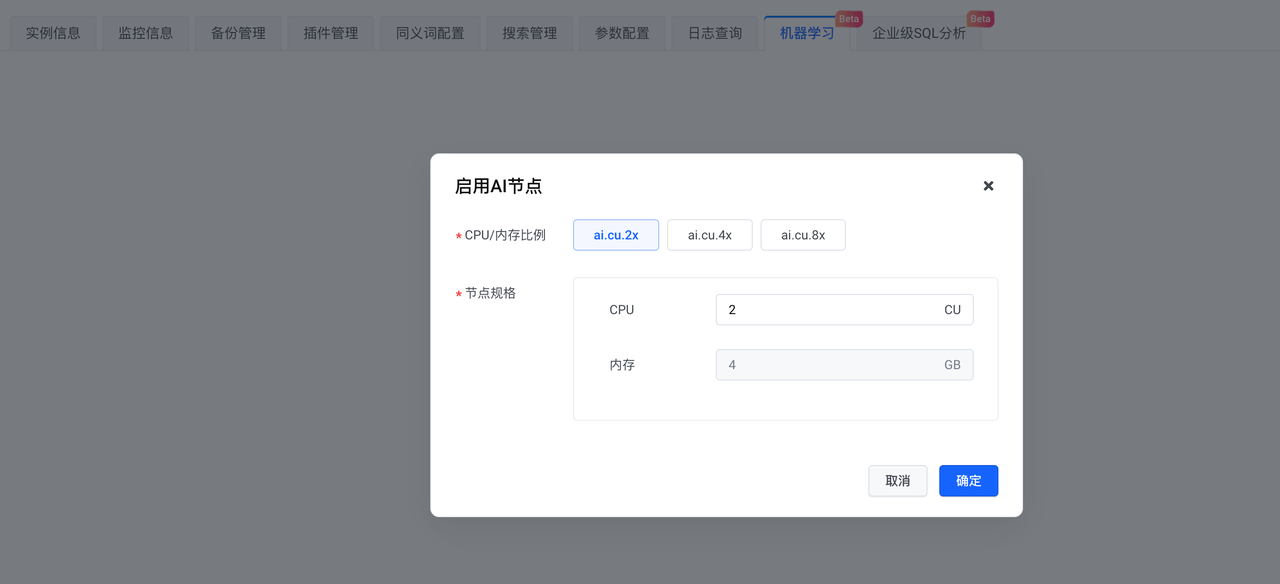
Após a criação da instância, habilite o nó AI.
-
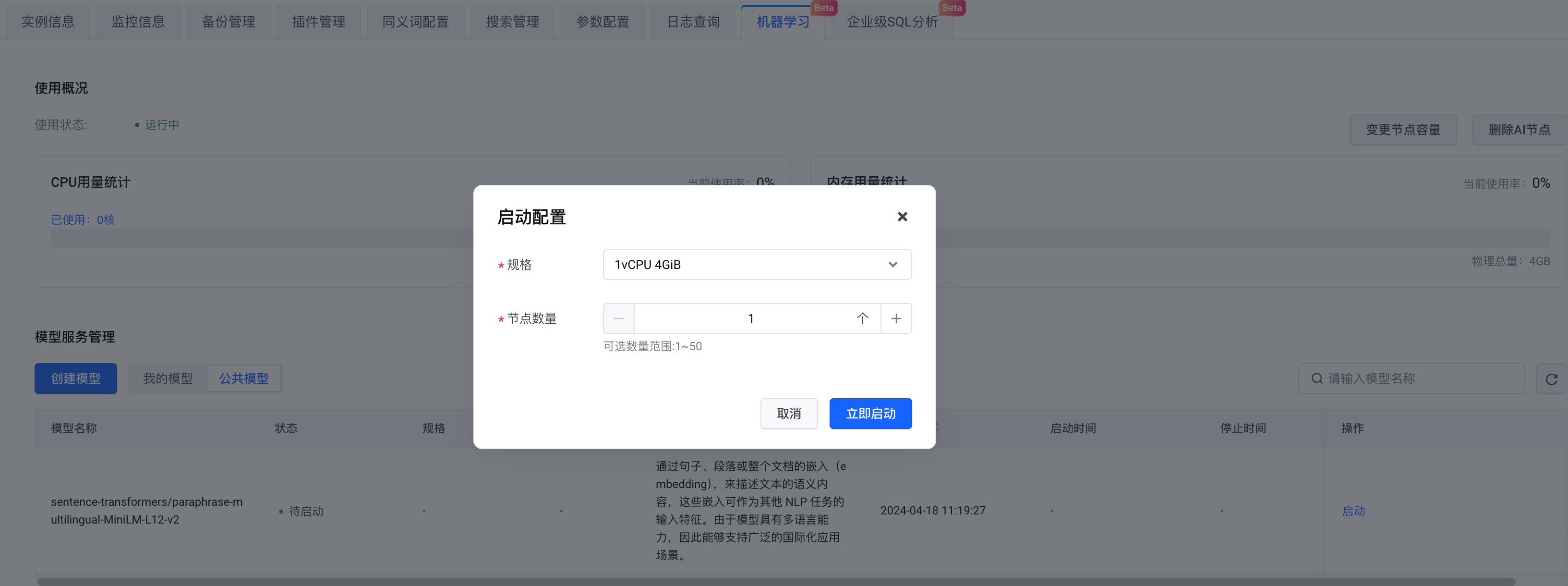
Em termos de seleção de modelos, você pode criar seu próprio modelo ou escolher um modelo público. Aqui selecionamos o modelo público . Após concluir a configuração, clique em Iniciar agora .
Neste ponto, a instância do OpenSearch e o serviço de aprendizado de máquina do qual a pesquisa híbrida depende estão prontos.
Preparação do conjunto de dados
Use o conjunto de dados do Amazon Berkeley Objects (https://registry.opendata.aws/amazon-berkeley-objects/) como conjunto de dados. O conjunto de dados não precisa ser baixado localmente e é carregado diretamente no OpenSearch por meio da lógica de código. conteúdo do código abaixo para obter detalhes.
Passos
Instale dependências do Python
pip install -U elasticsearch7==7.10.1
pip install -U pandas
pip install -U jupyter
pip install -U requests
pip install -U s3fs
pip install -U alive_progress
pip install -U pillow
pip install -U ipythonConecte-se ao OpenSearch
# Prepare opensearch info
from elasticsearch7 import Elasticsearch as CloudSearch
from ssl import create_default_context
# opensearch info
opensearch_domain = '{{ OPENSEARCH_DOMAIN }}'
opensearch_port = '9200'
opensearch_user = 'admin'
opensearch_pwd = '{{ OPENSEARCH_PWD }}'
# remote config for model server
model_remote_config = {
"method": "POST",
"url": "{{ REMOTE_MODEL_URL }}",
"params": {},
"headers": {
"Content-Type": "application/json"
},
"advance_request_body": {
"model": "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
}
}
# dimension for knn vector
knn_dimension = 384
# load cer and create ssl context
ssl_context = create_default_context(cafile='./ca.cer')
# create CloudSearch client
cloud_search_cli = CloudSearch([opensearch_domain, opensearch_port],
ssl_context=ssl_context,
scheme="https",
http_auth=(opensearch_user, opensearch_pwd)
)
# index name
index_name = 'index-test'
# pipeline id
pipeline_id = 'remote_text_embedding_test'
# search pipeline id
search_pipeline_id = 'rrf_search_pipeline_test'-
Preencha o endereço do link OpenSearch e as informações de nome de usuário e senha. model_remote_config é a configuração de conexão do modelo de aprendizado de máquina remoto, que pode ser visualizada nas informações de chamada do modelo. Copie todas as configurações de remote_config nas informações de chamada para model_remote_config .
-
Na seção Informações da Instância- > Acesso ao Serviço , baixe o certificado para o diretório atual.
-
Dado um nome de índice, ID do pipeline e ID do pipeline de pesquisa.
Criar pipeline de ingestão
Crie um pipeline de ingestão, especifique o modelo de aprendizado de máquina a ser usado, converta os campos especificados em vetores e incorpore-os novamente. A seguir, converta
o
campo de legenda em um vetor e armazene-o em
caption_embedding
.
# Create ingest pipeline
pipeline_body = {
"description": "text embedding pipeline for remote inference",
"processors": [{
"remote_text_embedding": {
"remote_config": model_remote_config,
"field_map": {
"caption": "caption_embedding"
}
}
}]
}
# create request
resp = cloud_search_cli.ingest.put_pipeline(id=pipeline_id, body=pipeline_body)
print(resp)Criar pipeline de pesquisa
Crie o Pipeline necessário para consultar e configurar o modelo remoto.
Métodos de normalização e métodos de soma ponderada suportados:
-
Método de normalização:
min_max,l2,rrf -
Método de soma ponderada:
arithmetic_mean,geometric_mean,harmonic_mean
O método de normalização rrf é selecionado aqui.
# Create search pipeline
import requests
search_pipeline_body = {
"description": "post processor for hybrid search",
"request_processors": [{
"remote_embedding": {
"remote_config": model_remote_config
}
}],
"phase_results_processors": [ # normalization and combination
{
"normalization-processor": {
"normalization": {
"technique": "rrf", # the normalization technique in the processor is set to rrf
"parameters": {
"rank_constant": 60 # param
}
},
"combination": {
"technique": "arithmetic_mean", # the combination technique is set to arithmetic mean
"parameters": {
"weights": [
0.4,
0.6
]
}
}
}
}
]
}
headers = {
'Content-Type': 'application/json',
}
# create request
resp = requests.put(
url="https://" + opensearch_domain + ':' + opensearch_port + '/_search/pipeline/' + search_pipeline_id,
auth=(opensearch_user, opensearch_pwd),
json=search_pipeline_body,
headers=headers,
verify='./ca.cer')
print(resp.text)Criar índice k-NN
-
Configure o Ingest Pipeline pré-criado no campo index.default_pipeline ;
-
Ao mesmo tempo, configure as propriedades e defina caption_embedding como knn_vector. Aqui usamos hnsw em faiss.
# Create k-NN index
# create index and set settings, mappings, and properties as needed.
index_body = {
"settings": {
"index.knn": True,
"number_of_shards": 1,
"number_of_replicas": 0,
"default_pipeline": pipeline_id # ingest pipeline
},
"mappings": {
"properties": {
"image_url": {
"type": "text"
},
"caption_embedding": {
"type": "knn_vector",
"dimension": knn_dimension,
"method": {
"engine": "faiss",
"space_type": "l2",
"name": "hnsw",
"parameters": {}
}
},
"caption": {
"type": "text"
}
}
}
}
# create index
resp = cloud_search_cli.indices.create(index=index_name, body=index_body)
print(resp)Carregar conjunto de dados
Leia o conjunto de dados na memória e filtre alguns dos dados que precisam ser usados.
# Prepare dataset
import pandas as pd
import string
appended_data = []
for character in string.digits[0:] + string.ascii_lowercase:
if character == '1':
break
try:
meta = pd.read_json("s3://amazon-berkeley-objects/listings/metadata/listings_" + character + ".json.gz",
lines=True)
except FileNotFoundError:
continue
appended_data.append(meta)
appended_data_frame = pd.concat(appended_data)
appended_data_frame.shape
meta = appended_data_frame
def func_(x):
us_texts = [item["value"] for item in x if item["language_tag"] == "en_US"]
return us_texts[0] if us_texts else None
meta = meta.assign(item_name_in_en_us=meta.item_name.apply(func_))
meta = meta[~meta.item_name_in_en_us.isna()][["item_id", "item_name_in_en_us", "main_image_id"]]
print(f"#products with US English title: {len(meta)}")
meta.head()
image_meta = pd.read_csv("s3://amazon-berkeley-objects/images/metadata/images.csv.gz")
dataset = meta.merge(image_meta, left_on="main_image_id", right_on="image_id")
dataset.head()Carregar conjunto de dados
Faça upload do conjunto de dados para Opensearch e passe image_url e legenda para cada dado. Não há necessidade de passar
caption_embedding
, ele será gerado automaticamente através do modelo de aprendizado de máquina remoto.
# Upload dataset
import json
from alive_progress import alive_bar
cnt = 0
batch = 0
action = json.dumps({"index": {"_index": index_name}})
body_ = ''
with alive_bar(len(dataset), force_tty=True) as bar:
for index, row in (dataset.iterrows()):
if row['path'] == '87/874f86c4.jpg':
continue
payload = {}
payload['image_url'] = "https://amazon-berkeley-objects.s3.amazonaws.com/images/small/" + row['path']
payload['caption'] = row['item_name_in_en_us']
body_ = body_ + action + "\n" + json.dumps(payload) + "\n"
cnt = cnt + 1
if cnt == 100:
resp = cloud_search_cli.bulk(
request_timeout=1000,
index=index_name,
body=body_)
cnt = 0
batch = batch + 1
body_ = ''
bar()
print("Total Bulk batches completed: " + str(batch))Consulta de pesquisa híbrida
Tomemos como exemplo a consulta de
sapatos
match
. A consulta contém duas cláusulas de consulta, uma é consulta e a outra é
remote_neural
consulta. Ao consultar, especifique o Search Pipeline criado anteriormente como um parâmetro de consulta. O Search Pipeline converterá o texto recebido em um vetor e o armazenará no campo
caption_embedding
para consultas subsequentes.
# Search with search pipeline
from urllib import request
from PIL import Image
import IPython.display as display
def search(text, size):
resp = cloud_search_cli.search(
index=index_name,
body={
"_source": ["image_url", "caption"],
"query": {
"hybrid": {
"queries": [
{
"match": {
"caption": {
"query": text
}
}
},
{
"remote_neural": {
"caption_embedding": {
"query_text": text,
"k": size
}
}
}
]
}
}
},
params={"search_pipeline": search_pipeline_id},
)
return resp
k = 10
ret = search('shoes', k)
for item in ret['hits']['hits']:
display.display(Image.open(request.urlopen(item['_source']['image_url'])))
print(item['_source']['caption'])Exibição de pesquisa híbrida

O texto acima toma o aplicativo de pesquisa de imagens como exemplo para apresentar o processo prático de como desenvolver rapidamente um aplicativo de pesquisa híbrido com a ajuda da solução de serviço de pesquisa em nuvem Volcano Engine. Bem-vindos a fazer login no console do Volcano Engine para operar!
O serviço de pesquisa em nuvem Volcano Engine é compatível com Elasticsearch, Kibana e outros softwares e plug-ins de código aberto comumente usados. Ele fornece recuperação de múltiplas condições, estatísticas e relatórios para texto estruturado e não estruturado. dimensionamento, operação e manutenção simplificadas e criação rápida de análises de logs, análise de recuperação de informações e outros recursos de negócios.
{{o.nome}}
{{m.nome}}