O Volcano Engine Edge Cloud é um serviço de computação em nuvem baseado em tecnologia básica de computação em nuvem e poder de computação heterogêneo combinado com rede, construído em infraestrutura de ponta em larga escala, formando uma computação baseada em borda, rede, armazenamento, segurança, inteligência Uma nova geração de soluções de computação em nuvem distribuída com recursos essenciais.
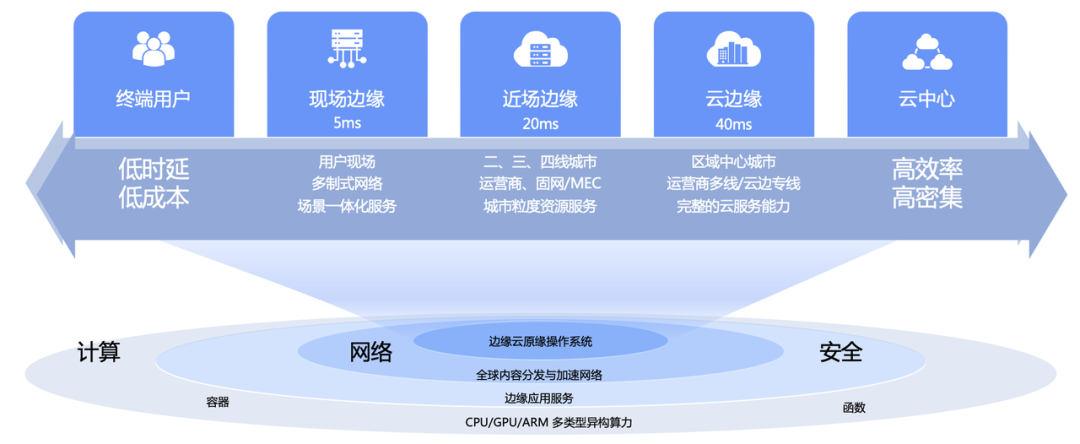
01- Desafios de armazenamento de cenas de borda
O armazenamento de borda é principalmente para cenários de negócios típicos que se adaptam à computação de borda, como renderização de borda. A renderização de borda do mecanismo do vulcão depende dos recursos maciços de poder de computação subjacentes, que podem ajudar os usuários a realizar o arranjo fácil de milhões de filas de quadros de renderização, o agendamento de tarefas de renderização próximas e a renderização paralela de multitarefas e vários nós , o que melhora muito a renderização. Apresente brevemente o armazenamento encontrado na questão de renderização de borda:
- É necessário unificar os metadados do armazenamento de objetos e do sistema de arquivos, para que após o upload dos dados pela interface de armazenamento de objetos, eles possam ser operados diretamente pela interface POSIX;
- Atende às necessidades de cenários de alto rendimento, principalmente na leitura;
- Implementa totalmente a interface S3 e a interface POSIX.
Para resolver os problemas de armazenamento encontrados na renderização de borda, a equipe passou quase meio ano conduzindo testes de seleção de armazenamento. Inicialmente, a equipe escolheu os componentes de armazenamento interno da empresa, que podem atender melhor às nossas necessidades em termos de sustentabilidade e desempenho. Mas quando se trata de cenas de borda, existem dois problemas específicos:
- Em primeiro lugar, os componentes internos da empresa são projetados para a sala de informática central, e há requisitos de recursos e quantidade de máquinas físicas, que são difíceis de atender em algumas salas de informática periféricas;
- Em segundo lugar, os componentes de armazenamento de toda a empresa são agrupados, incluindo: armazenamento de objetos, armazenamento em bloco, armazenamento distribuído, armazenamento de arquivos, etc., enquanto o lado da borda precisa principalmente de armazenamento de arquivos e armazenamento de objetos, que precisam ser adaptados e transformados, e um estábulo online também requer um processo.
Depois que a equipe discutiu, uma solução viável foi formada: gateway CephFS + MinIO . O MinIO fornece serviço de armazenamento de objetos, o resultado final é gravado no CephFS e o mecanismo de renderização monta o CephFS para executar as operações de renderização. Durante o processo de teste e verificação, quando o número de arquivos atingiu dezenas de milhões, o desempenho do CephFS começou a diminuir, ocasionalmente congelando, e o feedback do lado comercial não atendeu aos requisitos.
Da mesma forma, existe outra solução baseada no Ceph, que é usar o Ceph RGW + S3FS. Essa solução pode basicamente atender aos requisitos, mas o desempenho de gravação e modificação de arquivos não atende aos requisitos da cena.
Após mais de três meses de testes, esclarecemos vários requisitos básicos para armazenamento na renderização de borda:
- A operação e a manutenção não devem ser muito complicadas : o pessoal de P&D de armazenamento pode começar com os documentos de operação e manutenção; o trabalho de operação e manutenção de expansão posterior e tratamento de falhas on-line deve ser bastante simples.
- Confiabilidade dos dados : como o serviço de armazenamento é fornecido diretamente ao usuário, os dados gravados com sucesso não podem ser perdidos ou inconsistentes com os dados gravados.
- Use um conjunto de metadados e suporte armazenamento de objetos e armazenamento de arquivos : dessa forma, quando o lado comercial estiver usando, não será necessário fazer upload e download de arquivos várias vezes, reduzindo a complexidade do uso do lado comercial.
- Melhor desempenho para leitura : A equipe precisa resolver o cenário de mais leitura e menos escrita, então espera ter um melhor desempenho de leitura.
- Atividade da comunidade : uma comunidade ativa pode responder mais rapidamente ao resolver problemas existentes e promover ativamente a iteração de novas funções.
Depois de esclarecer os requisitos básicos, descobrimos que as três soluções anteriores não atendiam exatamente às necessidades.
02- Benefícios de usar o JuiceFS
A equipe de armazenamento de borda do Volcano Engine aprendeu sobre o JuiceFS em setembro de 2021 e teve algumas trocas com a equipe Juicedata. Após a comunicação, decidimos experimentá-lo no cenário de nuvem de ponta. A documentação oficial do JuiceFS é muito rica e altamente legível. Você pode aprender mais detalhes lendo a documentação.
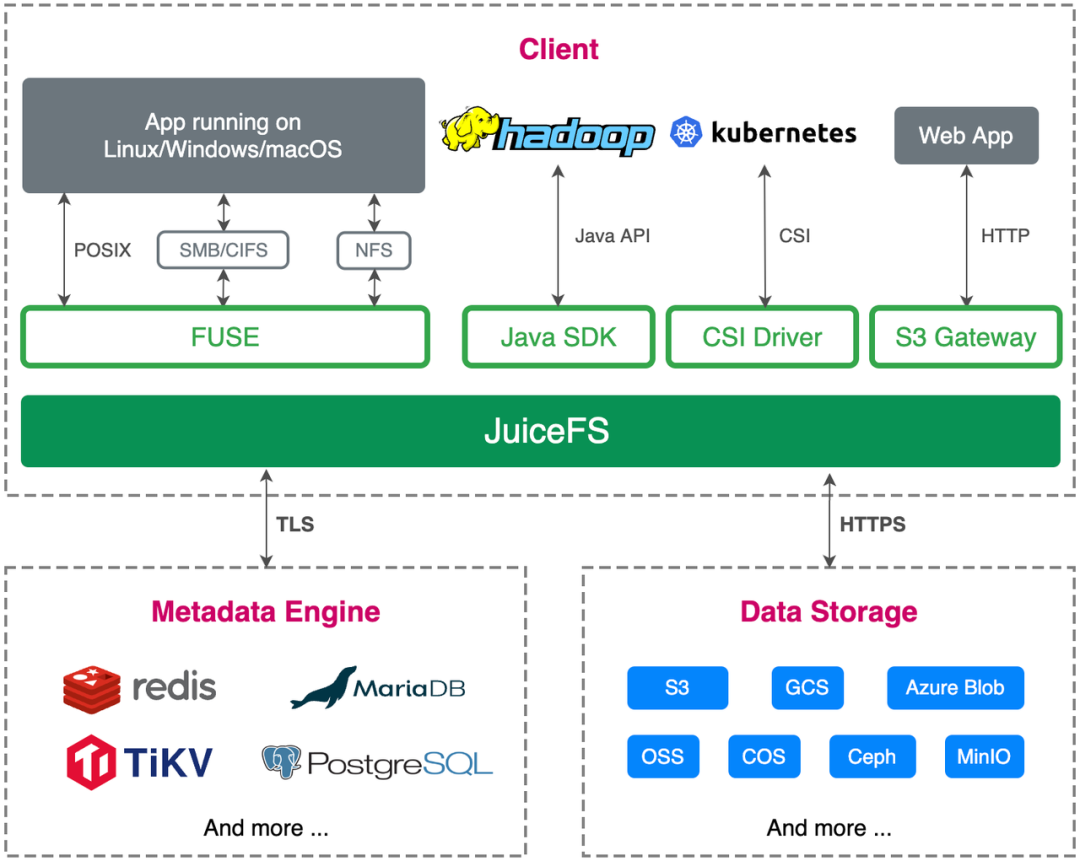
Portanto, passamos a fazer testes de PoC no ambiente de teste, com foco na verificação de viabilidade, complexidade de O&M e implantação e adaptação ao negócio upstream e se atende às necessidades do negócio upstream.
Implantamos dois conjuntos de ambientes, um baseado em Redis + Ceph de nó único e outro baseado em MySQL + Ceph de instância única .
Em termos de construção geral do ambiente, porque Redis, MySQL e Ceph (implantados através do Rook) são relativamente maduros, e os materiais de referência para implantação do plano de operação e manutenção são relativamente abrangentes. Ao mesmo tempo, o cliente JuiceFS também pode conectar esses bancos de dados e Ceph de forma simples e prática.O processo de implantação é muito tranquilo.
Em termos de adaptação de negócios, a nuvem de borda é desenvolvida e implantada com base na nuvem nativa. JuiceFS suporta a API S3, é totalmente compatível com o protocolo POSIX e suporta montagem CSI, que atende totalmente às nossas necessidades de negócios.
Após testes abrangentes, descobrimos que o JuiceFS atende totalmente às necessidades do lado comercial e pode ser implantado e executado em produção para atender às necessidades online do lado comercial.
Benefício 1: Otimização de processos de negócios
Antes de usar o JuiceFS, a renderização de borda usava principalmente o serviço de armazenamento de objeto interno (TOS) da ByteDance. Os usuários carregavam dados para o TOS, e o mecanismo de renderização baixava os arquivos carregados pelos usuários do TOS para o local, e o mecanismo de renderização lia os arquivos locais. , para gere o resultado da renderização e, em seguida, carregue o resultado da renderização de volta ao TOS e, finalmente, o usuário baixa o resultado da renderização do TOS. Existem vários links no processo geral de interação, e muita rede e cópia de dados estão envolvidas no meio, portanto, haverá instabilidade na rede ou grande atraso nesse processo, o que afetará a experiência do usuário.
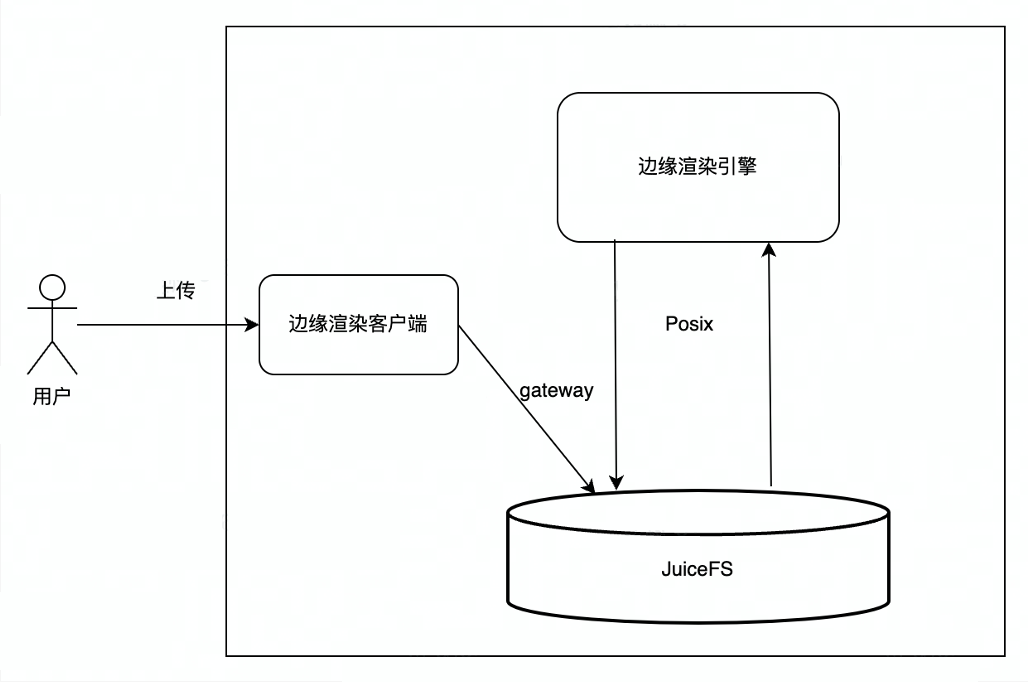
Depois de usar o JuiceFS, o processo torna-se o upload do usuário por meio do gateway JuiceFS S3. Como o JuiceFS realiza a unificação do armazenamento de objetos e metadados do sistema de arquivos, o JuiceFS pode ser montado diretamente no mecanismo de renderização e o mecanismo de renderização usa a interface POSIX para processar arquivos. Ler e escrever, o usuário final baixa diretamente o resultado da renderização do gateway JuiceFS S3, o processo geral é mais conciso, eficiente e mais estável.
Benefício 2: Aceleração da leitura de arquivos e gravação sequencial de arquivos grandes
Graças ao mecanismo de cache do lado do cliente do JuiceFS, podemos armazenar em cache arquivos lidos com frequência localmente no mecanismo de renderização, acelerando bastante a leitura de arquivos. Fizemos um teste comparativo para abrir o cache e descobrimos que a taxa de transferência pode ser aumentada em cerca de 3 a 5 vezes após o uso do cache .
Da mesma forma, como o modelo de gravação do JuiceFS é gravar a memória primeiro, quando um pedaço (padrão 64M) está cheio ou quando o aplicativo chama a interface de gravação forçada (fechar e interface fsync), os dados serão carregados no armazenamento de objetos, e o upload dos dados foi bem-sucedido Depois disso, atualize o mecanismo de metadados. Portanto, ao gravar arquivos grandes, grave primeiro na memória e depois no disco, o que pode melhorar muito a velocidade de gravação de arquivos grandes.
Atualmente, os cenários de uso do edge são principalmente de renderização, o sistema de arquivos lê mais e escreve menos, e a gravação de arquivos também é principalmente para arquivos grandes. Os requisitos desses cenários de negócios são muito consistentes com os cenários aplicáveis do JuiceFS. Depois que o lado comercial substituiu o armazenamento pelo JuiceFS, a avaliação geral também é muito alta.
03- Como usar JuiceFS em cenas de borda
O JuiceFS é implantado principalmente no Kubernetes. Cada nó possui um contêiner DaemonSet responsável por montar o sistema de arquivos JuiceFS e, em seguida, montá-lo no pod do mecanismo de renderização na forma de HostPath. Se o ponto de montagem falhar, o DaemonSet cuidará da restauração automática do ponto de montagem.
Em termos de controle de autoridade, o armazenamento de borda usa o serviço LDAP para autenticar a identidade dos nós do cluster JuiceFS, e cada nó do cluster JuiceFS é autenticado pelo cliente LDAP e pelo serviço LDAP.
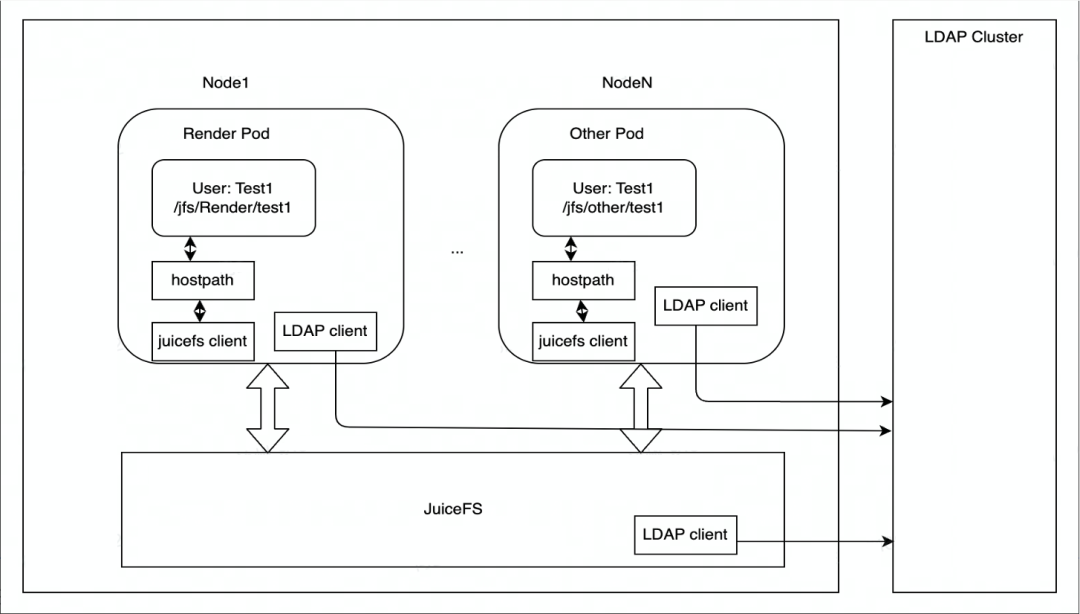
Nossos cenários de aplicativos atuais são baseados principalmente em renderização e serão expandidos para mais cenários de negócios no futuro. Em termos de acesso a dados, o armazenamento de borda atualmente é acessado principalmente por meio de HostPath.Se houver necessidade de expansão elástica no futuro, o JuiceFS CSI Driver será considerado para implantação.

04- Experiência prática em ambiente de produção
mecanismo de metadados
O JuiceFS oferece suporte a muitos mecanismos de metadados (como MySQL, Redis) e o ambiente de produção de armazenamento de ponta do mecanismo do vulcão usa MySQL . Depois de avaliar a escala do volume de dados e número de arquivos (o número de arquivos é de dezenas de milhões, provavelmente dezenas de milhões, o cenário de mais leituras e menos gravações), bem como o desempenho de gravação e leitura, descobrimos que o MySQL está em operação e manutenção, confiabilidade de dados, E o lado comercial tem se saído melhor.
Atualmente, o MySQL adota dois esquemas de implantação: instância única e instância múltipla (um mestre e dois escravos), que podem ser selecionados de forma flexível para diferentes cenários na borda. Em um ambiente com poucos recursos, uma única instância pode ser utilizada para implantação, e o throughput do MySQL é relativamente estável dentro de um determinado intervalo. Ambos os esquemas de implantação usam discos de nuvem de alto desempenho (fornecidos por clusters Ceph) como discos de dados MySQL, o que pode garantir que os dados MySQL não sejam perdidos mesmo em implantações de instância única.
Em cenários com recursos abundantes, várias instâncias podem ser usadas para implantação. A sincronização mestre-escravo de várias instâncias é realizada através do componente orquestrador fornecido pelo MySQL Operator ( https://github.com/bitpoke/mysql-operator) . É considerado OK somente se duas instâncias escravas forem sincronizadas com sucesso, mas um tempo limite período também é definido. Se a sincronização não for concluída após o tempo limite expirar, ela retornará com sucesso e um alarme será emitido. Após a conclusão do plano de recuperação de desastre posterior, o disco local pode ser usado como o disco de dados do MySQL para melhorar ainda mais o desempenho de leitura e gravação, reduzir a latência e aumentar a taxa de transferência.
Recursos do contêiner de configuração de instância única do MySQL :
- CPU: 8C
- Memória: 24G
- Disco: 100G (com base no Ceph RBD, os metadados ocupam cerca de 30G de espaço em disco no cenário de armazenamento de dezenas de milhões de arquivos)
- Imagem do contêiner: mysql:5.7
my.cnfConfiguração do Mysql :
ignore-db-dir=lost+found # 如果使用 MySQL 8.0 及以上版本,需要删除这个配置
max-connections=4000
innodb-buffer-pool-size=12884901888 # 12G
armazenamento de objetos
O armazenamento de objetos usa um cluster Ceph autocriado , que é implantado por meio do Rook. O ambiente de produção atual usa a versão Octopus. Com o Rook, os clusters do Ceph podem ser operados e mantidos de maneira nativa da nuvem, e os componentes do Ceph podem ser gerenciados e controlados por meio do Kubernetes, o que reduz bastante a complexidade da implantação e do gerenciamento do cluster do Ceph.
Configuração de hardware do servidor Ceph:
- 128 CPU nuclear
- RAM de 512 GB
- Disco do sistema: 2T * 1 NVMe SSD
- Disco de dados: 8T * 8 NVMe SSD
Configuração do software do servidor Ceph:
- SO: Debian 9
- Kernel: modifique /proc/sys/kernel/pid_max
- Versão Ceph: Polvo
- Back-end de armazenamento Ceph: BlueStore
- Número de réplicas do Ceph: 3
- Desligue a função de ajuste automático do grupo de posicionamento
O foco principal da renderização de borda é baixa latência e alto desempenho, portanto, em termos de seleção de hardware do servidor, configuramos o cluster com discos SSD NVMe. Outras configurações são baseadas principalmente na versão mantida pelo motor do vulcão, e o sistema operacional que escolhemos é o Debian 9. Para redundância de dados, três cópias são configuradas para o Ceph.Em um ambiente de computação de borda, o EC pode ser instável devido a restrições de recursos.
Cliente JuiceFS
O cliente JuiceFS suporta conexão direta com o Ceph RADOS (melhor desempenho que o Ceph RGW), mas esta função não é habilitada por padrão no binário oficial, então o cliente JuiceFS precisa ser recompilado. Você precisa instalar librados antes de compilar. Recomenda-se que a versão librados corresponda à versão Ceph. Debian 9 não tem um pacote librados-dev que corresponda à versão Ceph Octopus (v15.2.*), então você precisa baixar você mesmo o pacote de instalação.
Depois de instalar o librados-dev, você pode começar a compilar o cliente JuiceFS. Usamos o Go 1.19 para compilar aqui. No 1.19, foi adicionado o recurso de controle da alocação máxima de memória ( https://go.dev/doc/gc-guide#Memory_limit), o que pode impedir que o cliente JuiceFS ocupe muito em casos extremos, OOM ocorre devido a mais memória.
make juicefs.ceph
Depois de compilar o cliente JuiceFS, você pode criar um sistema de arquivos e montar o sistema de arquivos JuiceFS no nó de computação. Para etapas detalhadas, consulte a documentação oficial do JuiceFS.
05- Futuro e Perspectivas
O JuiceFS é um produto de sistema de armazenamento distribuído no campo nativo da nuvem. Ele fornece um componente CSI Driver que pode suportar muito bem os métodos de implantação nativos da nuvem. Ele fornece aos usuários opções muito flexíveis em termos de implantação de operação e manutenção. Os usuários podem escolher a nuvem , Você também pode escolher a implantação privatizada, que é relativamente simples em termos de expansão de armazenamento, operação e manutenção. É totalmente compatível com o padrão POSIX e usa o mesmo conjunto de metadados do S3, o que torna muito conveniente realizar o processo de operação de upload, processamento e download. Como seu armazenamento de back-end é um recurso de armazenamento de objetos, há um grande atraso na leitura e gravação de pequenos arquivos aleatórios e o IOPS é relativamente baixo. Para cenários com mais gravação e menos, o JuiceFS tem uma vantagem relativamente grande, o que é muito adequado para as necessidades de negócios de cenários de renderização de borda .
Os planos futuros da equipe de nuvem de ponta do Volcano Engine relacionados ao JuiceFS são os seguintes:
- Mais cloud-native : JuiceFS é atualmente usado na forma de HostPath. Posteriormente, considerando alguns cenários de dimensionamento elástico, podemos mudar para usar JuiceFS na forma de CSI Driver;
- Atualização do mecanismo de metadados : abstraia o serviço gRPC de um mecanismo de metadados, que fornece recursos de cache de vários níveis para melhor adaptação a cenários com mais leituras e menos gravações. O armazenamento de metadados subjacente pode considerar a migração para TiKV para suportar um número maior de arquivos. Comparado com o MySQL, ele pode aumentar melhor o desempenho do mecanismo de metadados por meio da expansão horizontal;
- Novas funções e correções de bugs : Para o cenário de negócios atual, algumas funções serão adicionadas e alguns bugs serão corrigidos, e esperamos contribuir com relações públicas para a comunidade e retribuir à comunidade.
Se você for útil, preste atenção ao nosso projeto Juicedata/JuiceFS ! (0ᴗ0✿)