O status atual do Apache Spark no iQiyi
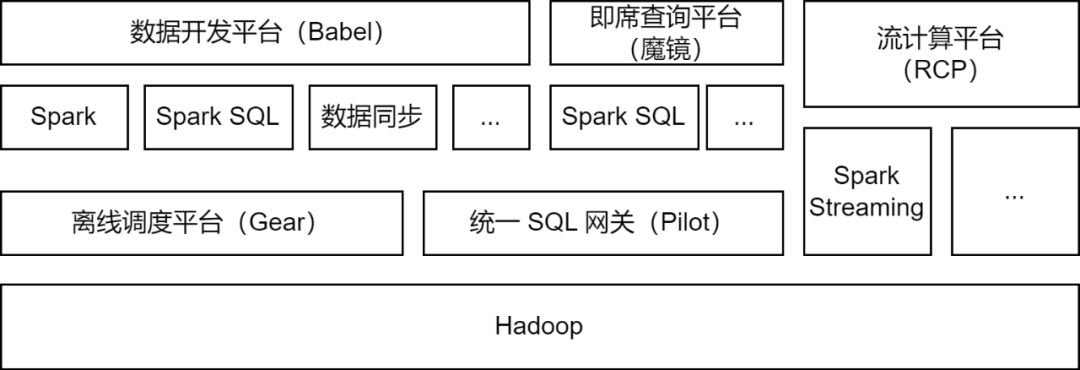
Apache Spark é a estrutura de computação offline usada principalmente pela plataforma de big data iQiyi e oferece suporte a algumas tarefas de computação de fluxo para processamento de dados, sincronização de dados, análise de consulta de dados e outros cenários:
-
Processamento de dados : a plataforma de desenvolvimento de dados oferece suporte aos desenvolvedores para enviar tarefas de pacote Spark Jar ou tarefas Spark SQL para processamento ETL de dados.
-
Sincronização de dados
: a ferramenta de sincronização de dados BabelX desenvolvida pela iQIYI é baseada na estrutura de computação Spark. Ela oferece suporte à troca de dados entre 15 fontes de dados, como Hive, MySQL e MongoDB. configuradas tarefas de sincronização de dados totalmente gerenciadas.
-
Análise de dados : Analistas de dados e estudantes de operações enviam SQL ou configuram consultas de indicadores de dados na plataforma de consulta ad hoc Magic Mirror e chamam o serviço Spark SQL por meio do gateway SQL unificado Pilot para análise de consulta.
Atualmente, o serviço iQiyi Spark executa mais de 200.000 tarefas Spark todos os dias, ocupando mais da metade dos recursos gerais de computação de big data.
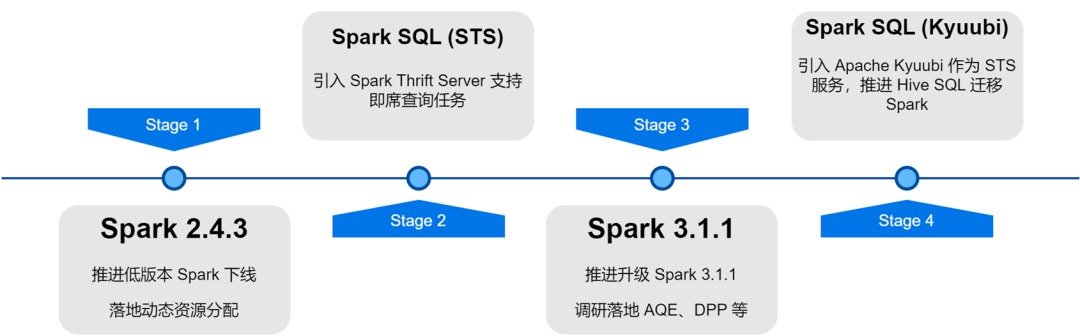
No processo de atualização e otimização da arquitetura da plataforma de big data iQiyi, o serviço Spark passou por iteração de versão, otimização de serviço, SQLização de tarefas e gerenciamento de custos de recursos, etc., o que melhorou muito a eficiência computacional e a economia de recursos de tarefas offline.
Otimização de aplicativos da estrutura de computação Spark
Com a atualização iterativa da versão interna do Spark, investigamos e implementamos alguns recursos excelentes da nova versão do Spark: alocação dinâmica de recursos, otimização de consulta adaptativa, remoção dinâmica de partição, etc.
-
Alocação dinâmica de recursos (DRA)
: há cegueira na aplicação do usuário em relação aos recursos, e os requisitos de recursos de cada estágio das tarefas do Spark também são diferentes. Lançamos o Serviço Shuffle Externo no Spark 2.4.3 e habilitamos a alocação dinâmica de recursos (DRA). Após ser habilitado, o Spark iniciará ou liberará dinamicamente o Executor com base nos requisitos de recursos do estágio de execução atual. Depois que o DRA ficou online, o consumo de recursos das tarefas do Spark foi reduzido em 20%.
-
Adaptive Query Optimization (AQE)
: Adaptive Query Optimization (AQE) é um excelente recurso introduzido no Spark 3.0. Com base nos indicadores estatísticos durante o tempo de execução do pré-estágio, ele otimiza dinamicamente o plano de execução dos estágios subsequentes e seleciona automaticamente o. estratégia de junção apropriada. Otimizar junção distorcida, mesclar partições pequenas, dividir partições grandes, etc. Após a atualização do Spark 3.1.1, o AQE foi ativado por padrão, o que resolveu efetivamente problemas como arquivos pequenos e distorção de dados e melhorou bastante o desempenho computacional do Spark. O desempenho geral aumentou cerca de 10%.
-
Limpeza de partição dinâmica (DPP)
: em mecanismos de computação SQL, o pushdown de predicado geralmente é usado para reduzir a quantidade de dados lidos da fonte de dados, melhorando assim a eficiência da computação. Um novo método de empilhamento é introduzido no Spark3: remoção dinâmica de partição e filtro de tempo de execução. Ao calcular primeiro a tabela pequena do Join, a tabela grande do Join é filtrada com base nos resultados do cálculo, reduzindo assim a quantidade de dados lidos pelo grande. mesa. Realizamos pesquisas e testes nesses dois recursos e ativamos o DPP por padrão. Em alguns cenários de negócios, o desempenho aumentou 33 vezes. No entanto, descobrimos que no Spark 3.1.1, ativar o DPP fará com que a análise SQL com muitas subconsultas seja particularmente lenta. Portanto, implementamos uma regra de otimização: calcule o número de subconsultas e, quando ultrapassar 5
, desative
a otimização DPP.
No processo de utilização do Spark, também encontramos alguns problemas. Acompanhando o progresso mais recente da comunidade, descobrimos e implementamos alguns patches para resolvê-los. Além disso, também fizemos algumas melhorias no Spark para torná-lo adequado para vários cenários de aplicação e melhorar a estabilidade da estrutura de computação.
-
Suporta escrita simultânea
Como o Spark 3.1.1 converte tabelas de formato Hive Parquet no Parquet Writer integrado do Spark por padrão, use o operador InsertIntoHadoopFsRelationCommand para gravar dados (spark.sql.hive.convertMetastoreParquet=true). Ao escrever uma partição estática, o diretório temporário será construído diretamente sob o caminho da tabela. Quando várias tarefas de gravação de partição estática gravam em partições diferentes da mesma tabela ao mesmo tempo, há o risco de falha na gravação da tarefa ou perda de dados (quando uma tarefa é confirmada, todo o diretório temporário será limpo, resultando em perda de dados para outras tarefas).
Adicionamos um parâmetro forceUseStagingDir ao operador InsertIntoHadoopFsRelationCommand e usamos o diretório de teste específico da tarefa como o diretório temporário. Desta forma, diferentes tarefas utilizam diferentes diretórios temporários, resolvendo assim o problema de escrita simultânea. Enviamos o problema relevante [SPARK-37210] à comunidade.
-
Suporte para consulta de subdiretórios
Depois que o Hive for atualizado para 3.x, o mecanismo Tez será usado por padrão. Quando a instrução Union for executada, o subdiretório HIVE_UNION_SUBDIR será gerado. Como o Spark ignora dados em subdiretórios, nenhum dado pode ser lido.
Este problema pode ser resolvido recorrendo ao Parquet/Orc Reader para o Hive Reader, adicionando os seguintes parâmetros:

No entanto, usar o Parquet Reader integrado do Spark terá melhor desempenho, então desistimos do plano de voltar ao Hive Reader e, em vez disso, transformamos o Spark. Como o Spark já suporta a leitura de subdiretórios de tabelas não particionadas por meio do parâmetro recursiveFileLookup, estendemos isso para oferecer suporte à leitura de subdiretórios de tabelas particionadas. Para obter detalhes, consulte: [SPARK-40600].
-
Aprimoramentos na fonte de dados JDBC
Há um grande número de tarefas de fonte de dados JDBC em aplicativos de sincronização de dados. Para melhorar a eficiência operacional e se adaptar a vários cenários de aplicativos, fizemos as seguintes modificações na fonte de dados JDBC integrada do Spark:
Push down de condições de sharding
:
depois que o Spark fragmenta a fonte de dados JDBC, ele insere condições de sharding por meio de subconsultas. Descobrimos que no MySQL 5.x, as condições de subconsulta não podem ser empurradas para baixo, então adicionamos um espaço reservado que representa a posição da condição. , e ao inserir a condição de fragmentação no Spark, ela é empurrada para dentro da subconsulta, realizando assim a capacidade de empurrar para baixo a condição de fragmentação.
Vários modos de gravação
:
implementamos vários modos de gravação para fontes de dados JDBC no Spark.
-
Normal: Modo normal, use o INSERT INTO padrão para escrever
-
Upsert: atualiza quando a chave primária existe, escrita no modo INSERT INTO...ON DUPLICATE KEY UPDATE
-
Ignorar: Ignore quando a chave primária existir, escreva no modo INSERT IGNORE INTO
Modo silencioso:
quando ocorre uma exceção durante a gravação JDBC, apenas o log de exceções é impresso e a tarefa não é finalizada.
Tipo de mapa de suporte
: usamos a fonte de dados JDBC para ler e gravar dados do ClickHouse. O tipo de mapa no ClickHouse não é compatível com a fonte de dados JDBC, portanto, adicionamos suporte para o tipo de mapa.
-
Limite de tamanho de gravação em disco local
Operações como Shuffle, Cache e Spill no Spark irão gerar alguns arquivos locais. Quando muitos arquivos locais são gravados, o disco do nó de computação pode ficar cheio, afetando assim a estabilidade do cluster.
Nesse sentido, adicionamos um indicador de volume de gravação de disco no Spark, lançamos uma exceção quando o volume de gravação de disco atinge o limite e julgamos a exceção de falha de tarefa no TaskScheduler e chamamos DagScheduler quando a exceção de limite de gravação de disco é capturada. método interrompe tarefas com uso excessivo de disco.
Ao mesmo tempo, também adicionamos o indicador Executor Disk Usage no ExecutorMetric para expor o uso atual do disco do Spark Executor, facilitando a observação de tendências e a análise de dados.
O serviço Spark consome muitos recursos de computação. Desenvolvemos uma plataforma de gerenciamento de exceções para auditar e gerenciar recursos de computação para tarefas de processamento em lote do Spark e tarefas de computação em fluxo, respectivamente.
Na operação e manutenção diária, descobrimos que um grande número de tarefas do Spark apresenta problemas como desperdício de memória e baixa utilização da CPU. Para encontrar tarefas com esses problemas, fornecemos indicadores de recursos quando as tarefas do Spark estão em execução ao Prometheus para analisar a utilização de recursos da tarefa e obter detalhes de configuração e cálculo de recursos analisando o Spark EventLog.
Ao otimizar os parâmetros de recursos das tarefas e permitir a alocação dinâmica de recursos, a utilização dos recursos de computação das tarefas do Spark é efetivamente melhorada. A atualização da versão do Spark também traz muita economia de recursos.
A otimização dos parâmetros de recursos é dividida em otimização de memória e CPU. A plataforma de gerenciamento de exceções recomenda configurações razoáveis de parâmetros de recursos com base no pico de uso de recursos da tarefa nos últimos sete dias, melhorando assim a utilização de recursos das tarefas Spark.
Tomando a otimização de memória como exemplo, os usuários geralmente resolvem o problema de estouro de memória (OOM) aumentando a memória, mas ignoram a investigação aprofundada das causas do OOM. Isso faz com que os parâmetros de memória de um grande número de tarefas do Spark sejam definidos muito altos e a proporção entre a memória do recurso da fila e a CPU fique desequilibrada. Obtemos indicadores de memória do Spark Executor e enviamos ordens de serviço de exceção para notificar os usuários e orientá-los a configurar adequadamente os parâmetros de memória e o número de partições.
Após quase um ano de gestão de auditoria de recursos, a plataforma de gestão de exceções emitiu mais de 1.600 ordens de serviço, economizando um total de cerca de 27% dos recursos computacionais.
Implementação e otimização do serviço Spark SQL
O serviço iQiyi Spark SQL passou por vários estágios, desde o serviço Thrift Server nativo do Spark até a versão Kyuubi 0.7 e Apache Kyuubi 1.4, que trouxe grandes melhorias na arquitetura e estabilidade do serviço.
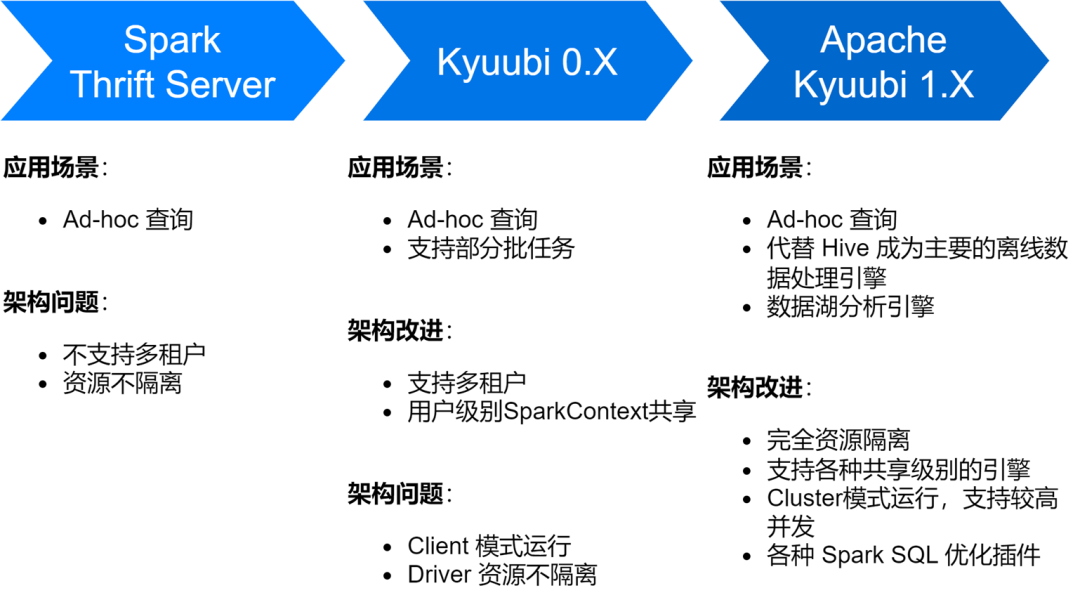
Atualmente, o serviço Spark SQL substituiu o Hive como principal mecanismo de processamento de dados offline do iQiyi, executando em média cerca de 150.000 tarefas SQL todos os dias.
-
Otimize o armazenamento e a eficiência da computação
Também encontramos alguns problemas durante a exploração do serviço Spark SQL, incluindo principalmente a geração de um grande número de arquivos pequenos, armazenamento maior e cálculos mais lentos. Por esse motivo, também realizamos uma série de otimizações de armazenamento e eficiência computacional.
Habilite a compactação ZStandard para melhorar a taxa de compactação
Zstd é o algoritmo de compactação de código aberto do Meta. Comparado com outros formatos de compactação, possui maior taxa de compactação e eficiência de descompactação. Nossos resultados reais de medição mostram que a taxa de compactação do Zstd é equivalente à do Gzip e a velocidade de descompactação é melhor que a do Snappy. Portanto, usamos o formato de compactação Zstd como formato de compactação de dados padrão durante o processo de atualização do Spark e também definimos os dados Shuffle para compactação Zstd, o que trouxe grande economia para o armazenamento do cluster. Quando aplicado em cenários de dados de publicidade, a taxa de compactação melhorou em 3,3 vezes. , economizando 76% dos custos de armazenamento.
Adicione a fase Rebalance para evitar a geração de arquivos pequenos
O problema do arquivo pequeno é um problema importante no Spark SQL: muitos arquivos pequenos colocarão grande pressão no Hadoop NameNode e afetarão a estabilidade do cluster. A estrutura nativa de computação Spark não possui uma boa solução automatizada para resolver o problema de arquivos pequenos. A este respeito, também investigamos algumas soluções da indústria e finalmente utilizamos a solução de otimização de pequenos arquivos que acompanha o serviço Kyuubi.
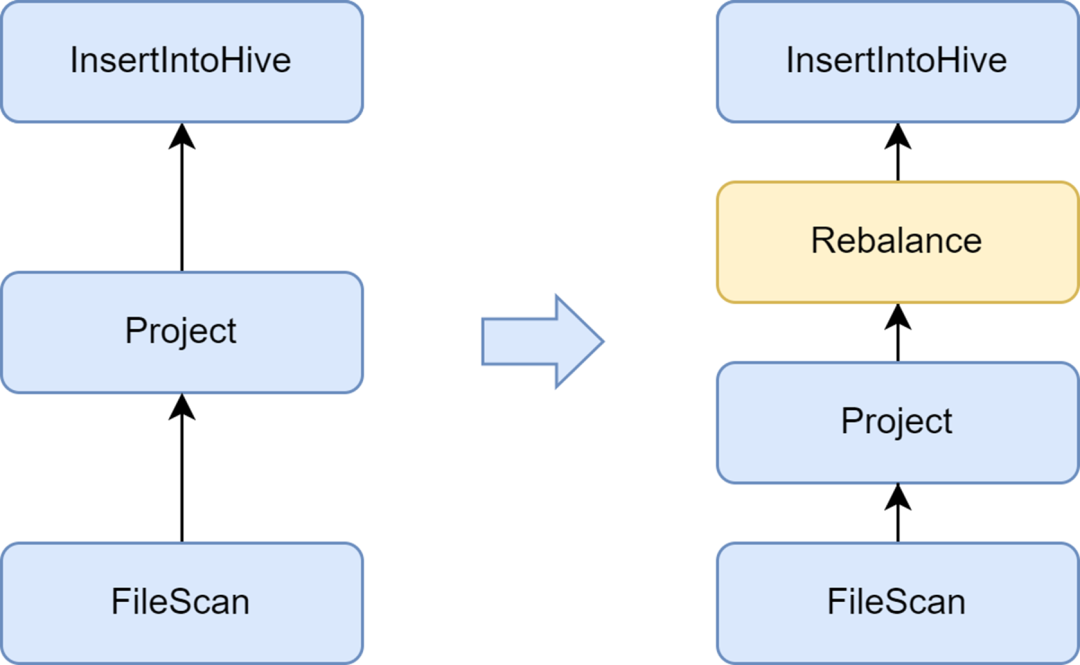
O otimizador insertRepartitionBeforeWrite fornecido pela Kyuubi pode inserir o operador Rebalance antes do operador Insert. Combinado com a lógica do AQE para mesclar automaticamente pequenas partições e dividir partições grandes, ele realiza o controle do tamanho do arquivo de saída e resolve efetivamente o problema de arquivos pequenos.
Após habilitá-lo, o tamanho médio do arquivo de saída do Spark SQL é otimizado de 10 MB para 262 MB, evitando a geração de um grande número de arquivos pequenos.
Habilite a inferência de classificação de repartição para melhorar ainda mais a taxa de compactação
Depois de ativar a otimização de arquivos pequenos, descobrimos que o armazenamento de dados de algumas tarefas tornou-se muito maior. Isso ocorre porque a operação Rebalance inserida na otimização de arquivos pequenos utiliza campos de partição ou partições aleatórias para particionamento, e os dados são espalhados aleatoriamente, resultando em uma redução na eficiência de codificação do arquivo no formato Parquet, o que por sua vez leva a uma redução na taxa de compactação do arquivo.
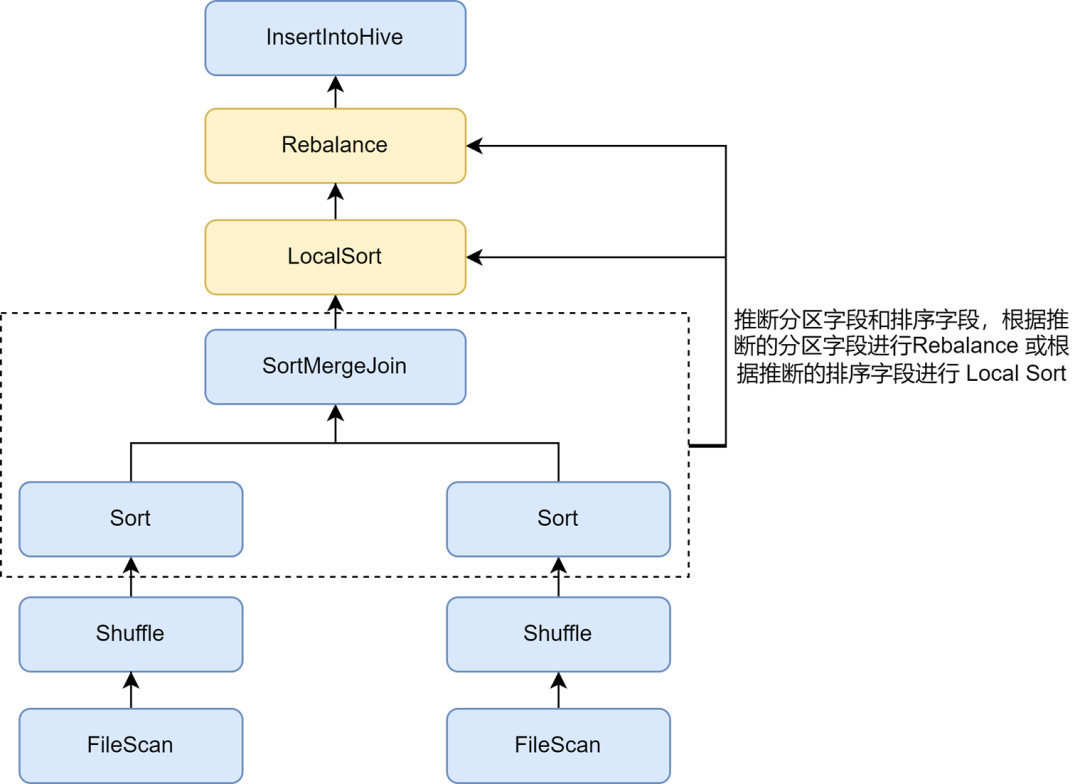
Nas regras de otimização de arquivos pequenos Kyuubi, a inferência automática de partições e campos de classificação pode ser habilitada por meio do parâmetro spark.sql.optimizer.inferRebalanceAndSortOrders.enabled Para escrita de partição não dinâmica, operadores como Join, Aggregate e Sort no. o plano de pré-execução é usado. Os campos de particionamento e classificação são inferidos das chaves, e os campos de partição inferidos são usados para Rebalanceamento, ou os campos de classificação inferidos são usados para Classificação Local antes do Rebalanceamento, para que a distribuição de dados do finalmente inserido. O operador de rebalanceamento é o mais consistente possível com o pré-plano e evita a gravação. Os dados recebidos são espalhados aleatoriamente, melhorando efetivamente a taxa de compactação.
Habilite a otimização do Zorder para melhorar a taxa de compactação e a eficiência da consulta
A classificação Zorder é um algoritmo de classificação multidimensional. Para formatos de armazenamento colunar como Parquet, algoritmos de classificação eficazes podem tornar os dados mais compactos, melhorando assim a taxa de compactação de dados. Além disso, como dados semelhantes são coletados na mesma unidade de armazenamento, por exemplo, o intervalo estatístico de mínimo/máximo é menor, a quantidade de dados ignorados durante o processo de consulta pode ser aumentada, melhorando efetivamente a eficiência da consulta.
A otimização de classificação de cluster Zorder é implementada em Kyuubi. Os campos Zorder podem ser configurados para tabelas e a classificação Zorder será adicionada automaticamente durante a gravação. Para tarefas existentes, o comando Otimizar também é suportado para otimização Zorder de dados existentes. Adicionamos a otimização Zorder internamente a algumas empresas importantes, reduzindo o espaço de armazenamento de dados em 13% e melhorando o desempenho da consulta de dados em 15%.
Introduzir configuração AQE independente no estágio final para aumentar o paralelismo computacional
Durante o processo de migração de algumas tarefas do Hive para o Spark, descobrimos que a velocidade de execução de algumas tarefas ficou mais lenta. A análise de análise descobriu que, como o operador Rebalance foi inserido antes da gravação e combinado com o Spark AQE para controlar arquivos pequenos, alteramos o spark do AQE. sql. A configuração adaptive.advisoryPartitionSizeInBytes é definida como 1024M, o que faz com que o paralelismo da fase Shuffle intermediária se torne menor, o que por sua vez torna a execução da tarefa mais lenta.
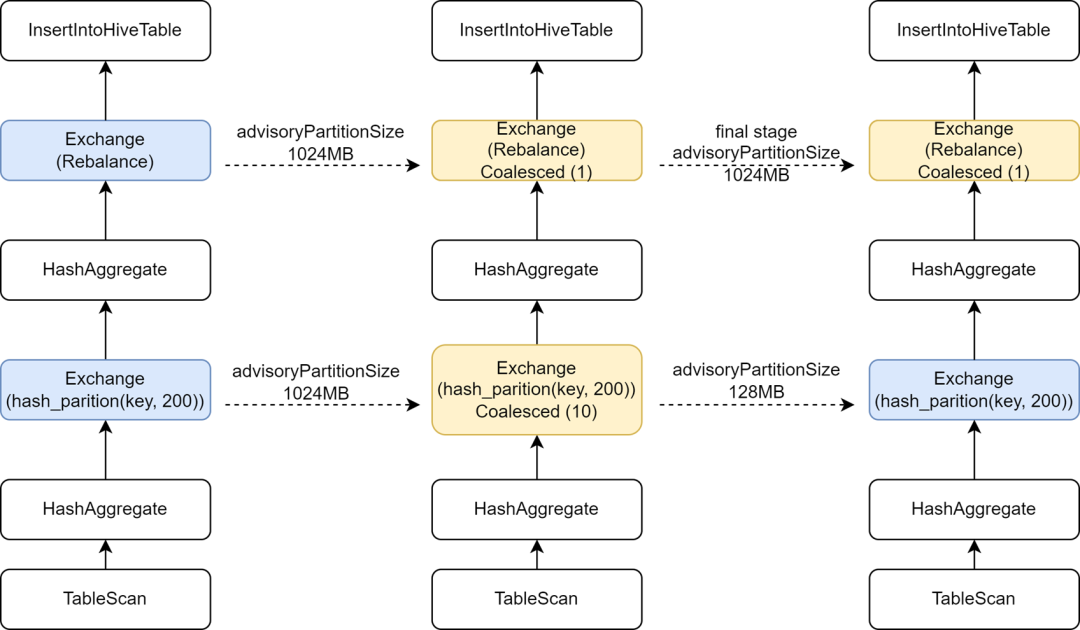
Kyuubi fornece otimização da configuração do estágio final, permitindo adicionar algumas configurações separadamente para o estágio final, para que possamos adicionar um advisoryPartitionSizeInBytes maior para o estágio final de controle de arquivos pequenos, e usar um advisoryPartitionSizeInBytes menor para os estágios anteriores para aumentar o paralelismo de cálculos e reduz o estouro do disco durante o estágio Shuffle, melhorando efetivamente a eficiência da computação. Depois de adicionar essa configuração, o tempo geral de execução das tarefas do Spark SQL é reduzido em 25% e os recursos são economizados em aproximadamente 9%.
Inferir a gravação dinâmica de tarefas de partição única para evitar partições Shuffle excessivamente grandes
Para gravação de partição dinâmica, a otimização de arquivos pequenos da Kyuubi usará o campo de partição dinâmica para rebalanceamento. Para tarefas que usam particionamento dinâmico para gravar em uma única partição, todos os dados do Shuffle serão gravados na mesma partição do Shuffle. iQIYI usa internamente o Apache Uniffle como o Remote Shuffle Service. Grandes partições causarão um único ponto de pressão no Shuffle Server e até mesmo acionarão a limitação de corrente e causarão redução na velocidade de gravação. Para tanto, desenvolvemos uma regra de otimização para capturar as condições de filtro de partição escrita e inferir se os dados de uma única partição são gravados de forma dinâmica para tais tarefas, não usamos mais campos de partição dinâmica para Rebalanceamento, mas usamos aleatório; Rebalance, isso evita a geração de uma partição Shuffle maior. Para detalhes, consulte: [KYUUBI-5079].
-
Detecção e interceptação anormais de SQL
Quando há problemas com a qualidade dos dados ou os usuários não estão familiarizados com a distribuição dos dados, é fácil enviar algum SQL anormal, o que pode levar a sério desperdício de recursos e baixa eficiência computacional. Adicionamos alguns indicadores de monitoramento ao serviço Spark SQL e detectamos e interceptamos alguns cenários de computação anormais.
Na iQiyi, os analistas de dados enviam SQL para análise de consulta ad-hoc por meio da plataforma de consulta ad-hoc Magic Mirror, que fornece aos usuários recursos de consulta de segundo nível. Usamos o mecanismo compartilhado da Kyuubi como mecanismo de processamento de back-end para evitar iniciar um novo mecanismo para cada consulta, o que desperdiça tempo de inicialização e recursos de computação. A presença permanente do mecanismo compartilhado em segundo plano pode trazer aos usuários uma experiência interativa mais rápida.
Para o mecanismo compartilhado, várias solicitações irão aproveitar recursos umas das outras. Mesmo se habilitarmos a alocação dinâmica de recursos, ainda há situações em que os recursos são ocupados por algumas consultas grandes, fazendo com que outras consultas sejam bloqueadas. A este respeito, implementamos a função de interceptar grandes consultas no plug-in Spark da Kyuubi. Ao analisar operações como Table Scan no plano de execução SQL, podemos contar o número de partições consultadas e a quantidade de dados verificados. exceder o limite especificado, ele será determinado para consultas grandes e execução de interceptação.
Com base nos resultados da determinação, a plataforma Magic Mirror alterna grandes consultas para um mecanismo independente para execução. Além disso, o Magic Mirror define um tempo limite de minuto. As tarefas que usam o mecanismo compartilhado para executar horas extras serão canceladas e convertidas automaticamente para execução independente do mecanismo. Todo o processo é insensível aos usuários, impedindo efetivamente o bloqueio de consultas comuns e permitindo que consultas grandes continuem em execução usando recursos independentes.
Monitore o excesso de dados
Algumas operações como Explode, Join e Count Distinct no Spark SQL causarão expansão de dados. Se a expansão de dados for muito grande, poderá causar estouro de disco, Full GC ou até mesmo OOM, e também piorar a eficiência do cálculo. Podemos ver facilmente se a expansão dos dados ocorreu com base no número de indicadores de linhas de saída dos nós anteriores e seguintes no diagrama do plano de execução SQL da página da guia SQL da UI do Spark.

Os indicadores no gráfico do plano de execução do Spark SQL são relatados ao Driver por meio de eventos de execução de tarefas e eventos de Heartbeat do Executor e são agregados no Driver.
Para coletar indicadores de tempo de execução de maneira mais oportuna, estendemos o SQLOperationListener na Kyuubi, ouvimos o evento SparkListenerSQLExecutionStart para manter sparkPlanInfo e, ao mesmo tempo, ouvimos o evento SparkListenerExecutorMetricsUpdate, capturamos as mudanças nos indicadores estatísticos SQL do nó em execução e comparou o número de indicadores de linhas de saída do nó em execução atual e o número de indicadores de linhas de saída dos nós filhos anteriores, calcule a taxa de expansão de dados para determinar se ocorre uma expansão grave de dados e colete eventos anormais ou intercepte tarefas anormais quando. ocorre expansão de dados.
Chave de inclinação de junção de posição
O problema de distorção de dados é um problema comum no Spark SQL e afeta o desempenho. Embora existam algumas regras para otimizar automaticamente a distorção de dados no Spark AQE, elas nem sempre são eficazes. mal-entendido dos dados. A lógica de análise errada é escrita porque o entendimento não é profundo o suficiente ou os próprios dados têm problemas de qualidade dos dados, por isso é necessário analisarmos a tarefa de distorção dos dados e localizar o valor-chave distorcido.

Podemos determinar facilmente se ocorreu distorção de dados na tarefa por meio das estatísticas de tarefas de estágio na IU do Spark. Conforme mostrado na figura acima, o valor máximo da duração da tarefa e da leitura aleatória excede o valor do 75º percentil, portanto, é óbvio que os dados. ocorreu uma distorção.
No entanto, para calcular os valores de chave que causam distorção na tarefa de distorção, geralmente é necessário dividir manualmente o SQL e, em seguida, calcular a distribuição de chaves em cada estágio usando Count Group By Keys para determinar o valor de chave distorcido. geralmente é uma tarefa relativamente demorada.
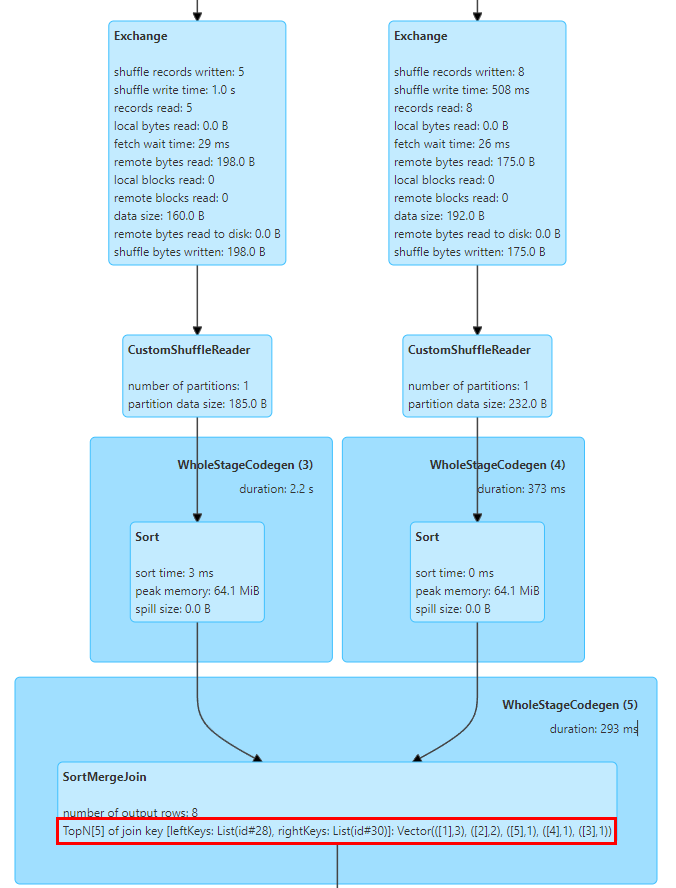
Nesse sentido, implementamos estatísticas TopN Keys em SortMergeJoinExec.
A implementação de SortMergeJoin consiste em classificar a chave primeiro e depois realizar a operação Join, para que possamos contar facilmente os valores TopN da chave por meio da acumulação.
Implementamos um acumulador TopNAccumulator, que mantém internamente um objeto do tipo Map[String, Long]. Ele utiliza o valor da chave do Join como a chave do mapa e mantém o valor da contagem da chave no valor do mapa, para cada linha de dados. Para cálculo cumulativo, como os dados estão em ordem, basta acumular as Chaves inseridas, e ao inserir novas Chaves, determinar se o valor N foi atingido e eliminar a menor Chave.
Além disso, o Spark suporta apenas a exibição de indicadores estatísticos do tipo Long. Também modificamos a lógica de exibição dos indicadores estatísticos SQL para se adaptar aos valores do tipo Map.
A figura acima mostra os 5 principais valores da chave de junção das duas tabelas para Join, onde a chave é o campo id e há 3 linhas com id=1.
Após uma série de pesquisas e testes, descobrimos que o Spark SQL melhorou significativamente o desempenho e o uso de recursos em comparação com o Hive. No entanto, também encontramos muitos problemas durante a migração do Hive SQL para o Spark. Ao fazer algumas modificações e adaptações de compatibilidade no serviço Spark SQL, migramos com sucesso a maioria das tarefas do Hive SQL para o Spark.
O suporte do Spark SQL para Hive UDF tem alguns problemas no uso real. Por exemplo, as empresas costumam usar a função de reflexão para chamar métodos estáticos Java para processar dados. Quando ocorre uma exceção na chamada de reflexão, o Hive retornará um valor NULL e o Spark SQL lançará uma exceção e fará com que a tarefa falhe. Para esse fim, modificamos a função reflect do Spark para capturar exceções de chamada de reflexão e retornar valores NULL, consistentes com o Hive.
Outro problema é que o Spark SQL não oferece suporte ao construtor privado do Hive UDAF, o que fará com que o UDAF de algumas empresas não seja inicializado. Transformamos a lógica de registro de função do Spark para oferecer suporte aos construtores privados Hive UDAF.
-
Compatibilidade de funções integradas
Existem diferenças na lógica de cálculo da função GROUPING_ID integrada entre o Spark SQL e o Hive versão 1.2, resultando em inconsistência de dados durante a fase de execução dupla. Na versão Hive 3.1, a lógica de cálculo desta função foi alterada para ser consistente com a lógica do Spark, por isso encorajamos os usuários a atualizar a lógica SQL e adaptar a lógica desta função no Spark para garantir a correção da lógica de cálculo.
Além disso, a função hash do Spark SQL usa o algoritmo Murmur3 Hash, que é diferente da lógica de implementação do Hive. Recomendamos que os usuários registrem manualmente a função hash integrada do Hive para garantir a consistência dos dados antes e depois da migração.
-
Compatibilidade de conversão de tipo
O Spark SQL introduziu a especificação ANSI SQL desde a versão 3.0. Em comparação com o Hive SQL, ele possui requisitos mais rígidos de consistência de tipo. Por exemplo, a conversão automática entre String e tipos numéricos é proibida. Para evitar anomalias de conversão automática causadas por definições de tipos de dados não padrão no negócio, recomendamos que os usuários adicionem CAST ao SQL para conversão explícita. Para transformações em grande escala, a configuração spark.sql.storeAssignmentPolicy=LEGACY pode ser adicionada temporariamente. para reduzir a verificação de tipo do nível Spark SQL para evitar exceções de migração.
A função str_to_map no Hive reterá automaticamente o último valor para chaves repetidas, enquanto no Spark, uma exceção será lançada e a tarefa falhará. Nesse sentido, recomendamos que os usuários auditem a qualidade dos dados upstream ou adicionem a configuração spark.sql.mapKeyDedupPolicy=LAST_WIN para reter o último valor duplicado, consistente com o Hive.
-
Outra compatibilidade de sintaxe
A sintaxe Hint do Spark SQL e do Hive SQL é incompatível e os usuários precisam excluir manualmente as configurações relevantes durante a migração. As dicas comuns do Hive incluem a transmissão de tabelas pequenas. Como a função Spark AQE é mais inteligente para transmitir tabelas pequenas e otimizar a inclinação da tarefa, nenhuma configuração adicional geralmente é exigida pelo usuário.
Existem também alguns problemas de compatibilidade entre o Spark SQL e as instruções DDL do Hive. Geralmente recomendamos que os usuários usem a plataforma para executar operações DDL em tabelas do Hive. Para alguns comandos de operação de partição, como: exclusão de partições não existentes [KYUUBI-1583], instruções Alter Partition desiguais e outros problemas de compatibilidade, também estendemos o plug-in Spark para compatibilidade.
Resumo e Perspectiva
Atualmente, migramos a maioria das tarefas do Hive na empresa para o Spark, então o Spark se tornou o principal mecanismo de processamento offline do iQiyi. Concluímos trabalhos preliminares de auditoria de recursos e otimização de desempenho no motor Spark, o que trouxe economias consideráveis para a empresa. No futuro, continuaremos a otimizar o desempenho e a estabilidade dos serviços Spark e das estruturas de computação. Também promoveremos ainda mais a migração das poucas tarefas restantes do Hive.
Com a implementação do data lake da empresa, cada vez mais empresas estão migrando para o data lake Iceberg. À medida que o Iceberg continua a melhorar as funções do Spark DataSourceV2, o Spark 3.1 não pode mais atender a algumas novas necessidades de análise de data lake, por isso estamos prestes a atualizar para o Spark 3.4. Ao mesmo tempo, também conduzimos pesquisas sobre alguns novos recursos, como Filtro de Tempo de Execução, Junção Particionada de Armazenamento, etc., na esperança de melhorar ainda mais o desempenho da estrutura de computação Spark com base nas necessidades de negócios.
Além disso, para promover o processo de computação de big data nativo da nuvem, introduzimos o Apache Uniffle, um serviço de embaralhamento remoto (RSS). Durante o uso, descobrimos que há problemas de desempenho quando combinados com Spark AQE, como otimização de inclinação BroadcastHashJoin [SPARK-44065], o problema de partição grande mencionado anteriormente e como executar melhor o planejamento de partição AQE. no futuro. Isso levará a pesquisas e otimização mais aprofundadas.
Talvez você também queira ver

