
A iQiyi construiu um data warehouse offline tradicional baseado no Hive para apoiar as decisões operacionais da empresa, crescimento de usuários, recomendações de vídeo, adesão, publicidade e outras necessidades de negócios. Nos últimos anos, as empresas têm requisitos mais elevados de dados em tempo real. Introduzimos a tecnologia de data lake baseada no Iceberg para melhorar significativamente o desempenho da consulta de dados e a eficiência geral da circulação. Do ponto de vista de desempenho e custo, é necessária a migração das tabelas Hive existentes para o data lake. No entanto, ao longo dos anos, centenas de petabytes de dados do Hive foram acumulados na plataforma de big data. Como migrar o Hive para o data lake tornou-se um grande desafio que enfrentamos. Este artigo apresenta a solução técnica da iQiyi para uma migração tranquila do data lake Hive para o Iceberg, ajudando as empresas a acelerar os processos de dados e melhorar a eficiência e a receita.
01
Colmeia VS Iceberg
Hive é uma plataforma de análise e armazenamento de dados baseada em Hadoop que fornece uma linguagem semelhante a SQL para suportar processamento e análise de dados complexos.
Iceberg é um formato de tabela de dados de código aberto projetado para fornecer armazenamento de tabelas escalonável, estável e eficiente para suportar cargas de trabalho analíticas. O Iceberg fornece garantias transacionais e consistência de dados semelhantes aos bancos de dados tradicionais e oferece suporte a operações complexas de dados, como atualizações, exclusões, etc.
A Tabela 1-1 lista a comparação entre o Hive e o Iceberg em termos de oportunidade, desempenho de consulta, etc.:
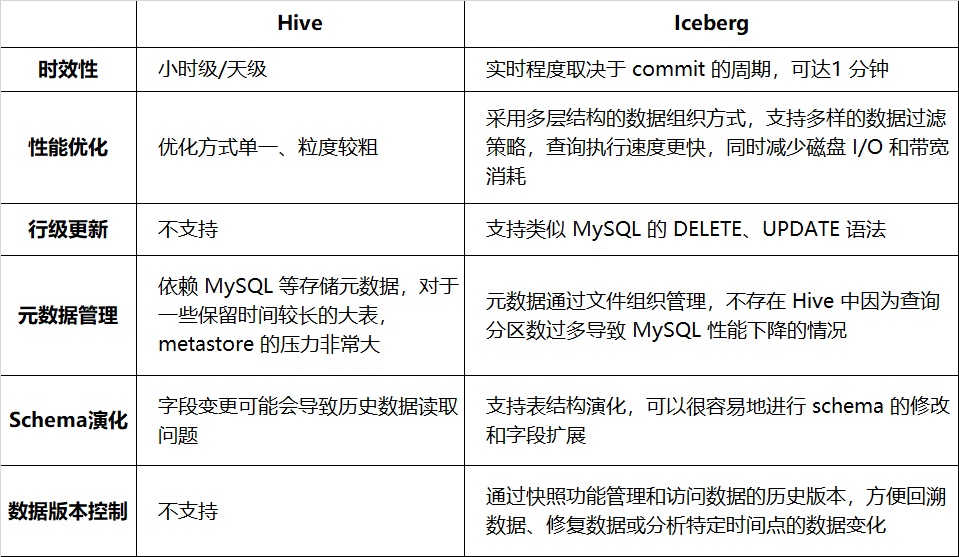
Tabela 1-1 Comparação entre Hive e Iceberg
Mudar para o Iceberg pode melhorar a eficiência e a confiabilidade do processamento de dados e fornecer melhor suporte para operações complexas de dados. Atualmente, ele está conectado a mais de uma dúzia de empresas, como publicidade, associação, registros Venus e auditoria. Para mais detalhes sobre a prática Iceberg da iQiyi, você pode ler a série anterior de artigos (ver citação no final do artigo).
02
Dados de estoque do Hive trocando suavemente o Iceberg
O Iceberg tem muitas vantagens sobre o Hive, mas os dados de negócios já estão em execução no ambiente Hive e a empresa não quer investir muita mão de obra na modificação das tarefas de inventário. Investigamos métodos de comutação comuns na indústria [1] e fornecemos a capacidade de alternar facilmente entre o autoatendimento Hive e o Iceberg na plataforma de data lake. Esta seção descreverá o plano de implementação específico.
1. Verifique a compatibilidade
Antes da mudança real, verificamos a compatibilidade do Spark com Hive e Iceberg.
A sintaxe de consulta e gravação do Spark para tabelas Hive e Iceberg são basicamente as mesmas. As instruções SQL para consultar tabelas Hive podem consultar tabelas Iceberg sem modificação.
Porém, existem grandes diferenças entre o Iceberg e o Hive em termos de DDL, principalmente na forma de modificar a estrutura da tabela. Os detalhes estão descritos na Tabela 2-1. Deve haver uma correspondência individual entre o esquema real e o esquema do arquivo de dados, caso contrário, isso afetará a consulta de dados. Portanto, você deve ser mais cauteloso ao processar instruções DDL. tais instruções DDL com tarefas.
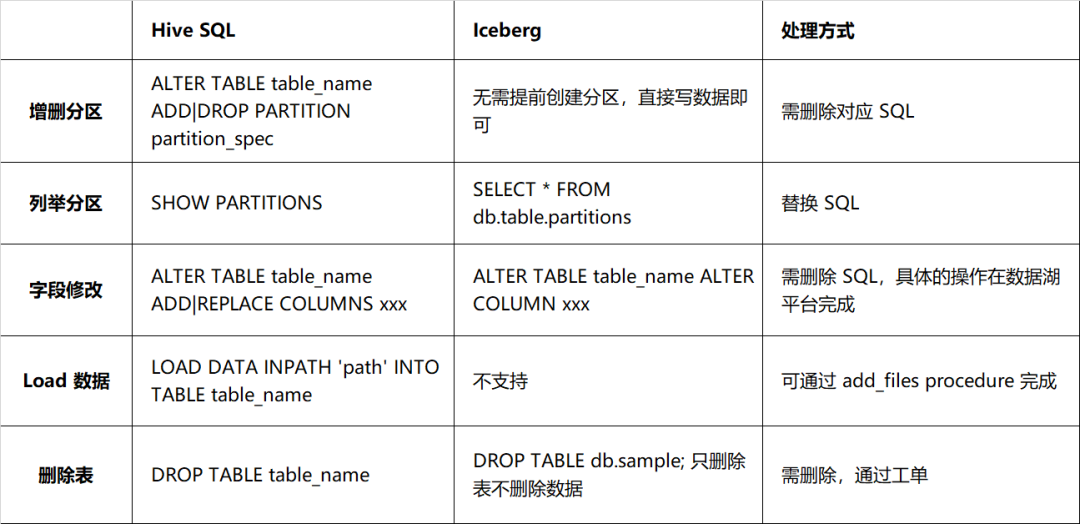
Tabela 2-1 Comparação de compatibilidade de sintaxe entre Hive e Iceberg
2. Solução de mudança de indústria
2.1 Comutação comercial de gravação dupla
A empresa replica o pipeline existente para implementar a escrita dupla de Hive e Iceberg. Depois que os pares de canais antigo e novo estiverem consistentes, mude para o canal Iceberg e faça logoff do canal original. Esta solução exige que a empresa invista mão de obra em desenvolvimento e cálculo, o que é demorado e trabalhoso.
2.2 Mude no lugar, o cliente para de escrever
Se a empresa puder parar de escrever por um período de tempo e mudar, os seguintes métodos poderão ser usados:
-
O procedimento de migração do Spark é uma função fornecida oficialmente pelo Iceberg, que pode mudar uma tabela Hive para o Iceberg no local.
CALL catalog_name.system.migrate('db.sample'); |
Este programa não modifica os dados originais, apenas verifica os dados da tabela original e depois constrói a metainformação do Iceberg, referenciando o arquivo original. Portanto, o programa de migração é executado muito rapidamente, mas os dados existentes não podem usar recursos como índices de arquivos para acelerar as consultas. Se quiser que os dados existentes também sejam acelerados, você pode usar o método rewrite_data_files do Spark para reescrever dados históricos.
O programa de migração não exclui a tabela Hive, mas a renomeia para sample__BACKUP__ O sufixo __BACKUP__ aqui é codificado permanentemente. Se precisar reverter, você pode descartar a tabela Iceberg recém-criada e renomear a tabela Hive.
-
Usando a instrução CTAS , o exemplo do Spark é o seguinte:
CREATE TABLE db.sample_iceberg USANDO Iceberg PARTICIONADO POR dt LOCALIZAÇÃO 'qbfs://....' TBLPROPERTIES('write.target-file-size-bytes' = '512m', ...) AS SELECT * FROM db.sample; |
Após a conclusão da escrita, o logaritmo é executado. Depois que os requisitos são atendidos, a troca é concluída com a renomeação.
ALTER TABLE db.sample RENAME TO db.sample_backup; ALTER TABLE db.sample_iceberg RENAME TO db.sample; |
A vantagem do CTAS em comparação com a migração é que os dados existentes são reescritos, para que possa otimizar o particionamento, classificação de colunas, formatos de arquivo, arquivos pequenos, etc. A desvantagem é que, se houver muitos dados existentes, a reescrita será demorada e consumirá muitos recursos.
As duas soluções acima têm as seguintes características:
vantagem:
A solução é simples, basta executar o SQL existente
Pode ser revertido, a tabela Hive original ainda está lá
deficiência:
Gravação/leitura não validada: exceções de gravação ou consulta podem ocorrer após a mudança para a tabela Iceberg
Exigir que o processo de mudança pare de escrever é inaceitável para algumas empresas
3. Plano de migração suave iQiyi
Considerando as deficiências da solução acima, projetamos uma solução de gravação dupla no local + comutação transparente para obter uma migração suave, conforme mostrado na Figura 2-1:
-
Criação de tabela : crie uma tabela Iceberg com o mesmo esquema do Hive e sincronize metainformações como TTL e permissões da tabela Hive para a tabela Iceberg. -
Migrando dados históricos para o Iceberg : os dados históricos do Hive são adicionados ao Iceberg por meio do procedimento add_file . Esta operação construirá os metadados do Iceberg com base nos dados do Hive. -
Gravação dupla de dados incrementais : o gateway Pilot SQL desenvolvido pela iQIYI detecta tarefas de gravação na tabela Hive, copia e grava SQL automaticamente e substitui a saída pela tabela Iceberg para obter gravação dupla. -
数据一致性 校验: 当历史数据同步完成且增量双写到一定次数之后,后台会自动发起对数,校验 Hive 和 Iceberg 中的数据是否一致。对于历史数据与增量数据会选取一部分数据进行 count 以及字段 CRC 数值校验。 -
切换 : 数据一致性校验完成后,进行 Hive 和 Iceberg 的切换,用户不需要修改任务,直接使用原来的表名进行访问即可。正常切换过程耗时在几分钟之内。
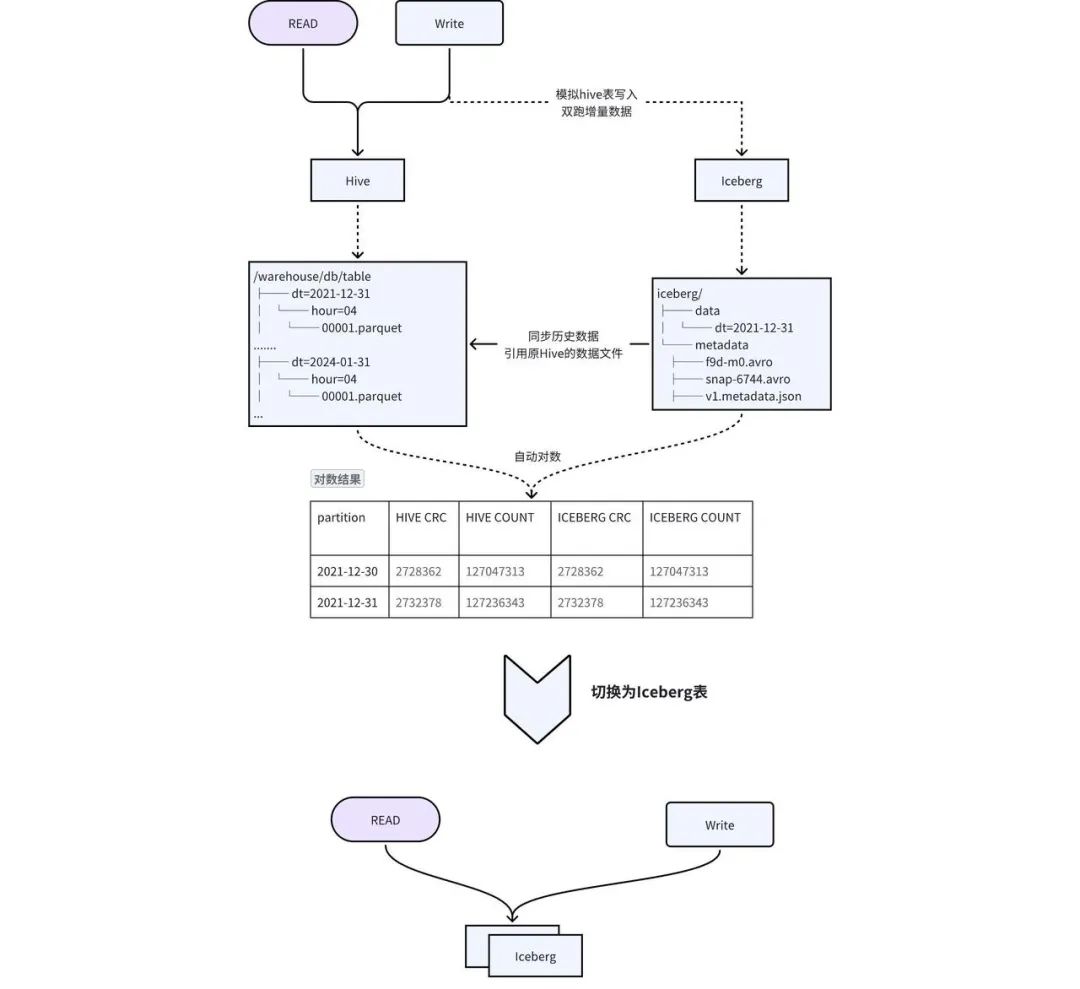
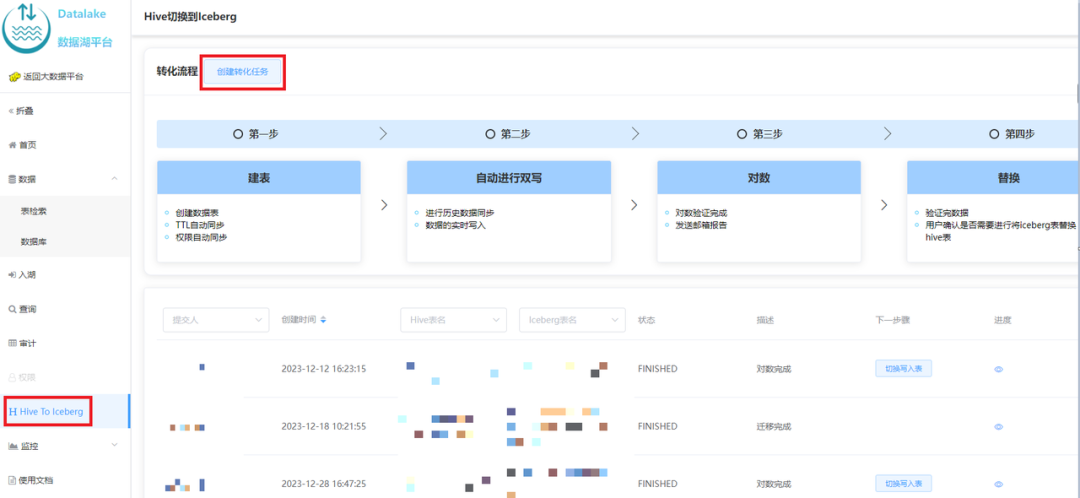
03
核心收益 - 加速查询
1. Iceberg 查询加速技术
2. Iceberg 加速技巧
-
配置分区:使用分区剪裁的方式使查询只针对特定分区的数据执行,而不需要扫描整个数据集。 -
指定排序列:通过对数据分布进行合理的组织,最大限度的发挥文件级别的过滤效果,使得查询只集中在特定的文件。例如通过下面的方式使得写入 sample 表的数据按照 category, id 降序写入,注意由于多了一个排序的环节,这种方式会比非排序的写入耗时长。
|
|
-
高基数列应用布隆过滤器:在查询数据时,会自动应用布隆过滤器来快速验证查询数据是否存在于某个数据块,避免不必要的磁盘访问。
|
|
-
使用 Trino 代替 Spark:由于 Trino 自身 MPP 的架构,在查询上相较于 Spark 更有优势,并且 Trino 自身对 Iceberg 也有相应的优化,因此如果有秒级查询的需求,可将引擎由 Spark 切换到 Trino。 -
Alluxio 缓存:使用 Alluxio 作为数据缓存层,将数据缓存在内存中。在查询时可以直接从内存中获取数据,避免从磁盘读取数据的开销,可大大提高查询速度,也可防止 HDFS 抖动对任务的影响。 -
ORC 代替 Parquet:由于 Trino 对 ORC 格式有特定的优化,使得 ORC 的读取性能要优于 Parquet,可以将文件格式设置为 ORC 加速查询。 -
配置合并:写 Iceberg 的任务往往会出现写入文件较小但数量较多的情况,通过将小文件合并成一个或少量更大的文件,有利于减少读取的文件数,降低磁盘 I/O。
3. 性能评测
3.1 文件内过滤性能提升
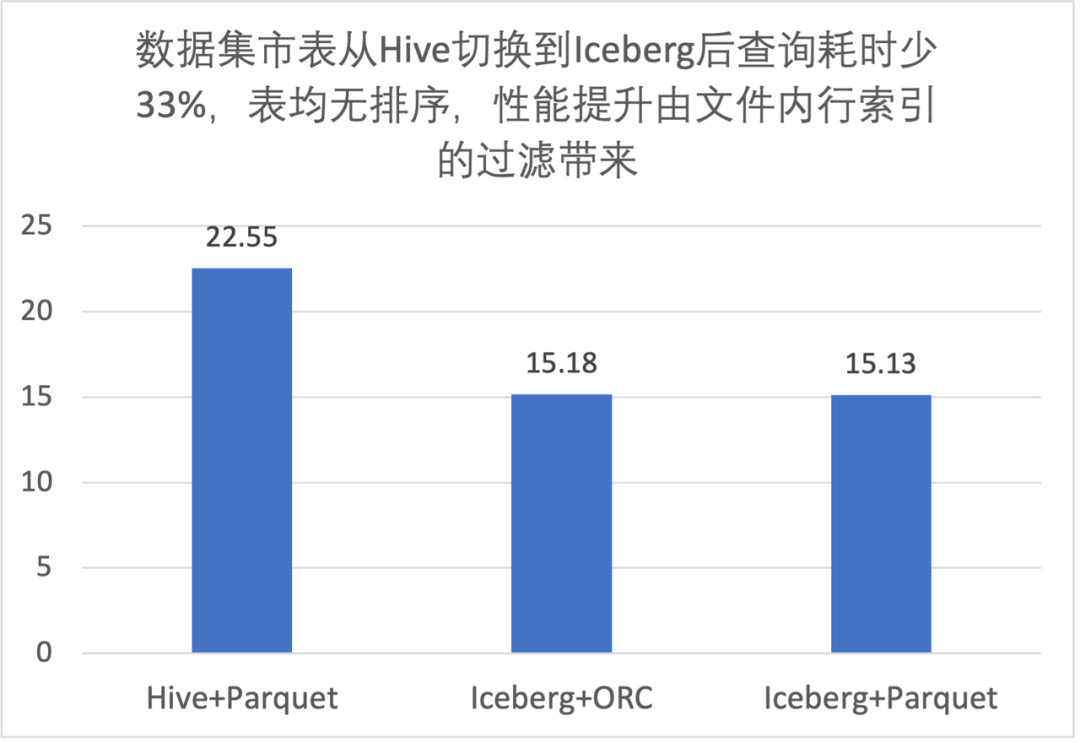
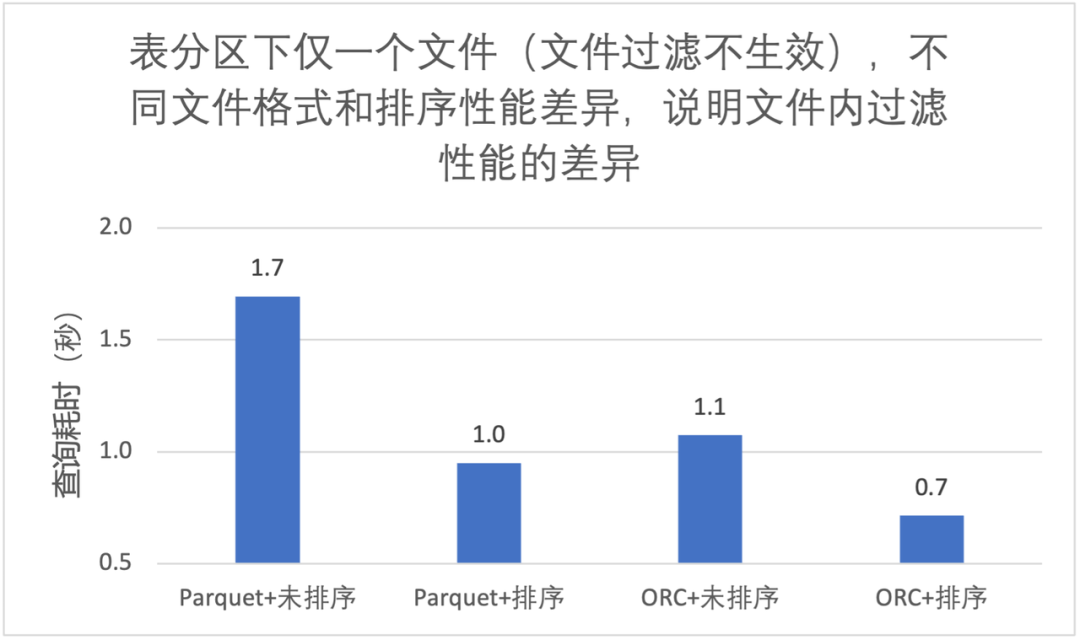
3.2 列排序对文件内过滤性能提升
-
同样的文件格式,排序后文件内过滤效果更好,大致能快 40%; -
ORC 查询性能优于 Parquet; -
使用 Trino 查询,我们推荐 Iceberg 表 + ORC 文件格式 + 列排序;
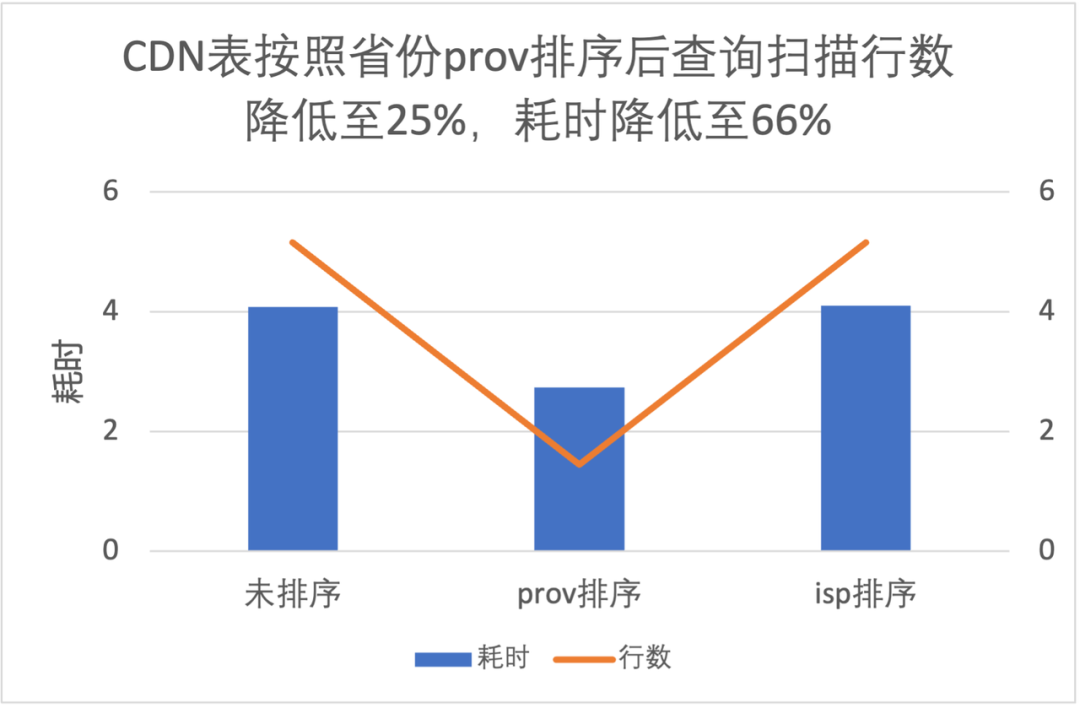
3.3 列排序对文件级过滤性能提升
|
|
-
按照 prov 排序查询读取数据量是不排序的 25%,耗时是 66%; -
按照 isp 排序提升不明显,这是因为 isp 数据量有明显的倾斜,条件中 isp 值占比高达 90%;
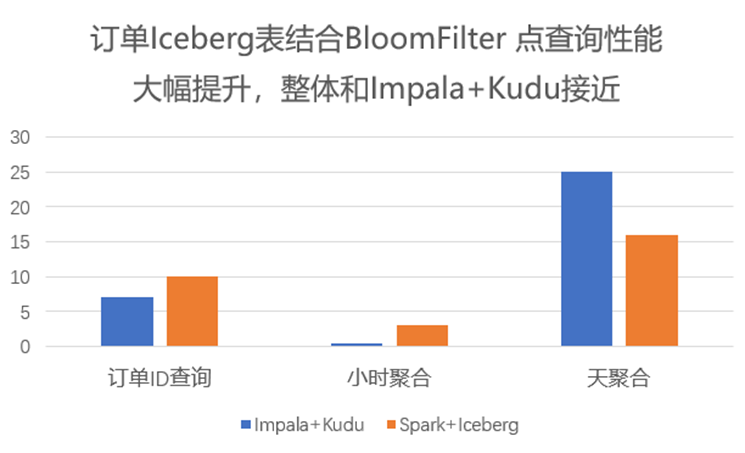
3.4 布隆过滤器的性能提升
3.5 Spark 和 Trino 性能比较
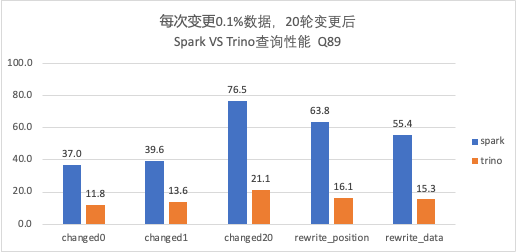
-
Trino 对于 V2 表查询结果与 Spark 一致,且在相同核数性能优于 Spark,耗时是 Spark 的 1/3 左右; -
随着变更轮次的增加(Data File 和 Postition Delete File 数量增加),Trino 查询性能也会逐渐变慢,需要定期进行合并。
04
核心收益 - 支持变更
1. 变更在业务使用场景
-
ETL 计算:如广告计费,通过接入 Iceberg 实现变更,简化业务逻辑,实现了更长时间范围的转化回收; -
数据修正:批量修正,如对某个数据的状态进行修改、批量删除等; -
隐私相关:如播放记录、搜索记录,用户需要删除历史条目等; -
CDC 同步:如订单业务,需要将 MySQL 中的数据进行大数据分析,通过 Flink CDC 技术很方便地将 MySQL 数据入湖,实时性可达到分钟级。
2. Hive 如何实现变更
-
分区覆写 例如修改某个 id 的相关内容,先筛选出要修改的目标行,更新后与历史数据进行合并,最后覆盖原表。这种方式对不需要修改的数据进行了重写,浪费计算资源;且覆写的粒度最小是分区级别,数据无法进一步细分,任务耗时相对较长。 -
标记删除 通常的做法是添加标志位,数据初始写入时标志位置 0,需要删除时,插入相同的数据,且标志位置 1,查询时过滤掉标志位为 1 的数据即可。这种方式在语义上未实现真正的删除,历史数据仍然保存在 Hive 中,浪费空间,而且查询语句较为复杂。
3. Iceberg 支持的变更类型
-
Delete:删除符合指定条件的数据,例如
|
|
-
Update:更新指定范围的数据,例如
|
|
-
MERGE:若数据已存在 UPDATE,不存在执行 INSERT,例如
|
|
4. Iceberg 变更策略
-
Copy on Write(写时合并):当进行删除或更新特定行时,包含这些行的数据文件将被重写。写入耗时取决于重写的数据文件数量,频繁变更会面临写放大问题。如果更新数据分布在大量不同的文件,那么更新的执行速度比较慢。这种方式由于结果文件数较少,读取的速度会比较快,适合频繁读取、低频批次更新的场景。 -
Merge on Read(读时合并):文件不会被重写,而是将更改写入新文件,当读取数据时,将新文件合并到原始数据文件得到最终结果。这使得写入速度更快,但读取数据时必须完成更多工作。写入新文件有两种方式,分别是记录删除某个文件对应的行(position delete)、记录删除的数据(equality detete)。 -
Position Delete:当前 Spark 的实现方式,记录变更对应的文件及行位置。这种方式不需要重写整个数据文件,只需找到对应数据的文件位置并记录,减少了写入的延迟,读取时合并的代价较小。 -
Equality Delete:当前 Flink 的实现方式,记录了删除数据行的主键。这种方式要求表必须有唯一的主键,写入过程无需查询数据文件,延迟最低;然而它的读取代价最大,这是由于读取时需要将 equality delete 记录和所有的原始文件进行 JOIN。
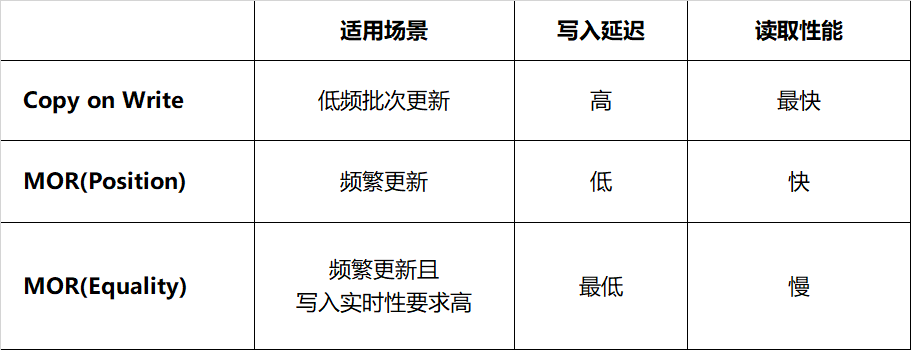 表 4-1 Iceberg 不同变更策略对比
表 4-1 Iceberg 不同变更策略对比
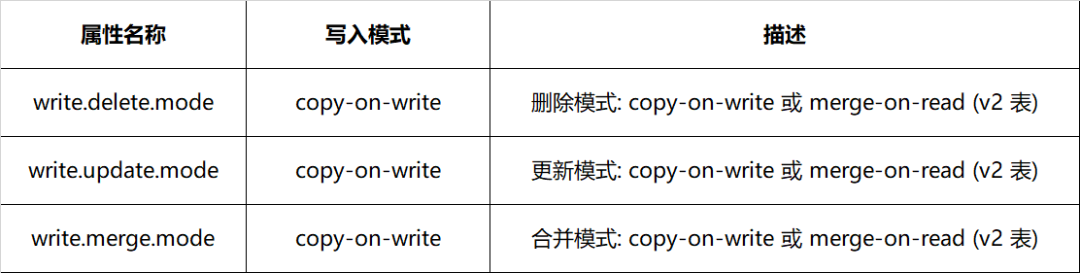 表 4-2 Iceberg 变更属性配置方式
表 4-2 Iceberg 变更属性配置方式
5. 业务接入
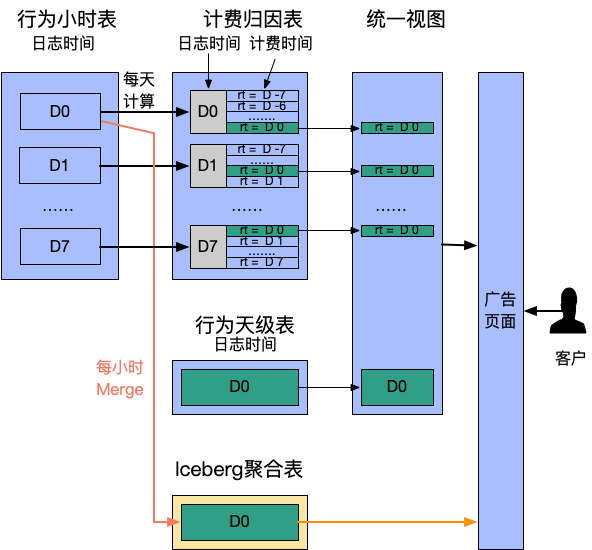
5.1 广告计费转换
-
每天触发一次计算,从行为表聚合出过去 7 天的“计费时间”数据。此处用 rt 字段代表计费时间 -
提供统一视图合并行为数据和计费时间数据,计费归因表 rt as dt 作为分区过滤查询条件,满足同时检索曝光和计费转化的需求
|
|
-
时效性提升:从天级缩短到小时级,客户更实时观察成本,有利于预算引入; -
计算更长周期数据:原先为计算效率仅提供 7 日内转换,而真实场景转换周期可能超过 1 个月; -
表语义清晰:多表联合变为单表查询。
5.2 数据修正
|
|
05
总结
06
引用
-
From Hive Tables to Iceberg Tables: Hassle-Free -
通过数据组织优化加速基于Apache Iceberg的大规模数据分析 -
Row-Level Changes on the Lakehouse: Copy-On-Write vs. Merge-On-Read in Apache Iceberg -
《爱奇艺数据湖实战 - 综述》 -
《爱奇艺数据湖实战 - 广告》 -
《爱奇艺数据湖实战 - 基于数据湖的日志平台架构演进》 -
《爱奇艺数据湖实战 - 数据湖技术在爱奇艺BI场景的应用》 -
《爱奇艺在Iceberg落地相关性能优化与实践》

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。