
01
fundo
02
Introdução à plataforma de registro Venus
Venus é uma plataforma de serviço de log desenvolvida pela iQiyi. Ela fornece coleta, processamento, armazenamento, análise e outras funções. É usada principalmente para solução de problemas de log, análise de big data, monitoramento e alarmes dentro da empresa. 1. mostrado.
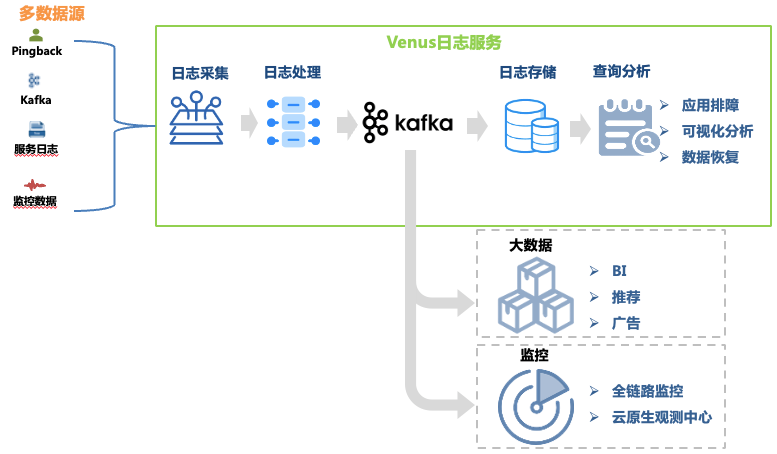 Figura 1 Link Vênus
Figura 1 Link Vênus
Este artigo se concentra na evolução arquitetônica do link de solução de problemas de log. Seus links de dados incluem:
Coleta de logs : Ao implantar agentes de coleta em máquinas e hosts de contêineres, os logs de front-end, back-end, monitoramento e outras fontes de cada linha de negócios são coletados, e o negócio também tem suporte para auto-entrega de logs que atendem aos requisitos de formato . Mais de 30.000 agentes foram implantados, oferecendo suporte a 10 fontes de dados, como Kafka, MySQL, K8s e gateways.
Processamento de log : após a coleta de log, ele passa por processamento padronizado, como extração regular e extração de analisador integrado, e é gravado uniformemente no Kafka no formato JSON e, em seguida, gravado no sistema de armazenamento pelo programa de despejo.
Armazenamento de logs : Venus armazena quase 10.000 fluxos de logs de negócios, com um pico de gravação de mais de 10 milhões de QPS e novos logs diários superiores a 500 TB. À medida que a escala de armazenamento muda, a seleção de sistemas de armazenamento passa por muitas mudanças, do ElasticSearch ao data lake.
Análise de consulta : Venus fornece análise de consulta visual, consulta contextual, disco de log, reconhecimento de padrões, download de log e outras funções.
Para atender ao armazenamento e análise rápida de dados de log massivos, a plataforma de log Venus passou por três grandes atualizações de arquitetura, evoluindo gradualmente da arquitetura ELK clássica para um sistema autodesenvolvido baseado em data lakes. durante a transformação da arquitetura e soluções de Vênus.
03
Venus 1.0: Baseado na arquitetura ELK
O Venus 1.0 começou em 2015 e foi construído com base no então popular ElasticSearch+Kibana, conforme mostrado na Figura 2. ElasticSearch é responsável pelas funções de armazenamento e análise de logs, e Kibana fornece consulta visual e recursos de análise. Você só precisa consumir Kafka e gravar logs no ElasticSearch para fornecer serviços de log.
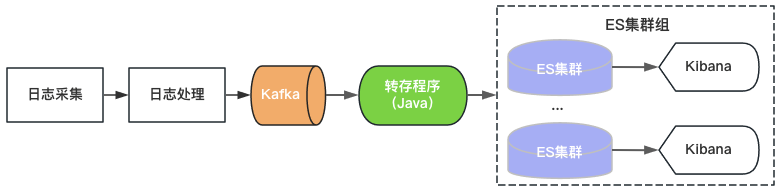 Figura 2 Arquitetura Vênus 1.0
Figura 2 Arquitetura Vênus 1.0
Como existem limites máximos de rendimento, capacidade de armazenamento e número de fragmentos de índice de um único cluster ElasticSearch, a Venus continua a adicionar novos clusters ElasticSearch para lidar com a crescente demanda de log. Para controlar os custos, a carga de cada ElasticSearch é de alto nível e o índice é configurado com 0 cópias. Problemas como gravação repentina de tráfego, grandes consultas de dados ou falhas de máquina que levam à indisponibilidade do cluster são frequentemente encontrados. Ao mesmo tempo, devido ao grande número de índices no cluster, à grande quantidade de dados e ao longo tempo de recuperação, os logs ficam indisponíveis por um longo período e a experiência de uso do Vênus torna-se cada vez pior.
04
Vênus 2.0: baseado em ElasticSearch + Hive
Classificação de cluster: os clusters ElasticSearch são divididos em duas categorias: alta qualidade e baixa qualidade. As principais empresas usam clusters de alta qualidade, a carga do cluster é controlada em um nível baixo e o índice é habilitado com uma configuração de 1 cópia para tolerar falhas de nó único. As empresas não-chave usam um cluster de baixa qualidade, a carga; é controlado em alto nível e o índice ainda usa uma configuração de cópia 0.
Classificação de armazenamento: ElasticSearch e Hive de gravação dupla para logs de armazenamento longo. O ElasticSearch salva os logs dos últimos 7 dias e o Hive salva os logs por um período de tempo mais longo, o que reduz a pressão de armazenamento do ElasticSearch e também reduz o risco de o ElasticSearch ser interrompido por grandes consultas de dados. No entanto, como o Hive não pode realizar consultas interativas, os logs no Hive precisam ser consultados por meio de uma plataforma de computação offline, resultando em uma experiência de consulta ruim.
Portal de consulta unificado: fornece um portal visual unificado de consulta e análise semelhante ao Kibana, protegendo o cluster ElasticSearch subjacente. Quando um cluster falha, os logs recém-gravados são agendados para outros clusters sem afetar a consulta e a análise de novos logs. Agende de forma transparente o tráfego entre clusters quando a carga do cluster estiver desequilibrada.
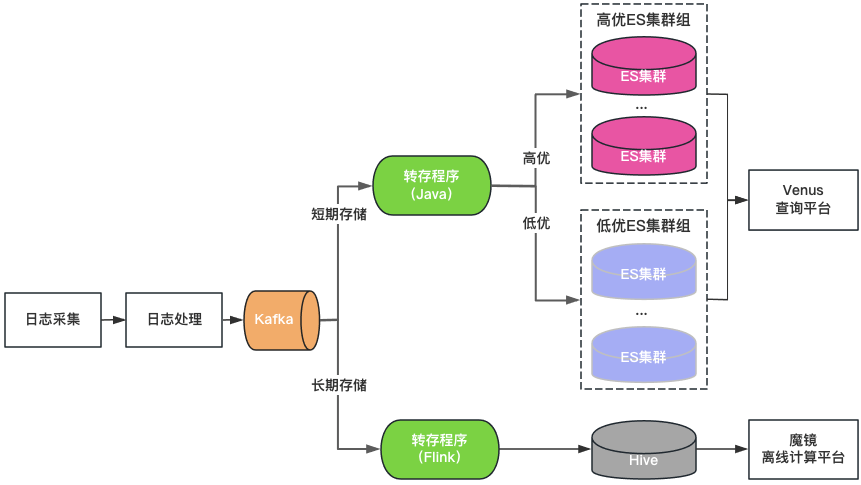
Figura 3 Arquitetura Vênus 2.0
A Venus 2.0 é uma solução de compromisso para proteger as principais empresas e reduzir o risco e o impacto das falhas. Ainda apresenta problemas de custos elevados e de fraca estabilidade:
ElasticSearch tem curto tempo de armazenamento: Devido à grande quantidade de logs, ElasticSearch pode armazenar apenas 7 dias, o que não pode atender às necessidades diárias de negócios.
Existem muitas entradas e fragmentação de dados: mais de 20 clusters ElasticSearch + 1 cluster Hive, existem muitas entradas de consulta, o que é muito inconveniente para consulta e gerenciamento.
Alto custo: embora o ElasticSearch armazene logs apenas por 7 dias, ele ainda consome mais de 500 máquinas.
Leitura e escrita integradas: O servidor ElasticSearch é responsável por ler e escrever ao mesmo tempo, afetando um ao outro.
Muitas falhas: as falhas do ElasticSearch são responsáveis por 80% do total de falhas do Venus. Após as falhas, a leitura e a gravação são bloqueadas, os logs são facilmente perdidos e o processamento é difícil.
05
Venus 3.0: Nova arquitetura baseada em data lake
Pensando em introduzir o data lake
Após uma análise aprofundada do cenário logístico de Vénus, resumimos as suas características da seguinte forma:
Grande quantidade de dados : quase 10.000 fluxos de log de negócios com capacidade máxima de gravação de 10 milhões de QPS e armazenamento de dados em nível de PB.
Escreva mais e verifique menos : as empresas geralmente consultam os logs apenas quando há necessidade de solução de problemas. A maioria dos logs não tem requisitos de consulta em um dia, e o QPS geral da consulta também é extremamente baixo.
Consulta interativa : os logs são usados principalmente para solucionar problemas urgentes que exigem várias consultas consecutivas e exigem uma experiência de consulta interativa de segundo nível.
Em relação aos problemas encontrados ao usar o ElasticSearch para armazenar e analisar logs, acreditamos que ele não corresponde exatamente ao cenário de log de Vênus pelos seguintes motivos:
Um único cluster tem QPS de gravação e escala de armazenamento limitados, portanto, vários clusters precisam compartilhar o tráfego. Questões complexas de estratégia de agendamento, como tamanho do cluster, tráfego de gravação, espaço de armazenamento e número de índices, precisam ser consideradas, o que aumenta a dificuldade de gerenciamento. Como o tráfego de log de negócios varia muito e é imprevisível, para resolver o impacto do tráfego repentino na estabilidade do cluster, muitas vezes é necessário reservar mais recursos ociosos, resultando em um enorme desperdício de recursos do cluster.
A indexação de texto completo durante a gravação consome muita CPU, levando à expansão de dados e a um aumento significativo nos custos de computação e armazenamento. Em muitos cenários, o armazenamento de registos de análise requer mais recursos do que recursos de serviço em segundo plano. Para cenários como logs em que há muitas gravações e poucas consultas, pré-computar o índice de texto completo é mais luxuoso.
Os dados de armazenamento e os cálculos estão na mesma máquina. Consultas de grandes volumes de dados ou análises agregadas podem facilmente afetar a gravação, causando atrasos na gravação ou até mesmo falhas no cluster.
为了解决上述问题,我们调研了ClickHouse、Iceberg数据湖等替代方案。其中,Iceberg是爱奇艺内部选择的数据湖技术,是一种存储在HDFS或对象存储之上的表结构,支持分钟级的写入可见性及海量数据的存储。Iceberg对接Trino查询引擎,可以支持秒级的交互式查询,满足日志的查询分析需求。
针对海量日志场景,我们对ElasticSearch、ElasticSearch+Hive、ClickHouse、Iceberg+Trino等方案做了对比评估:
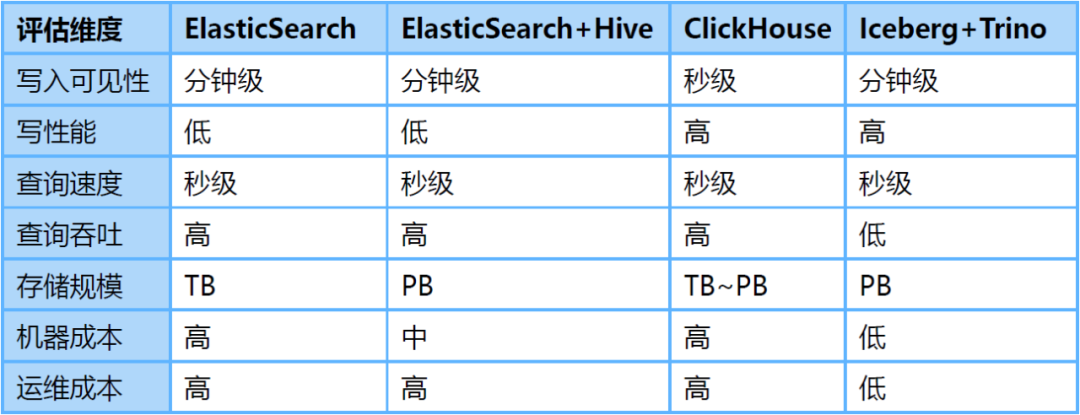
-
存储空间大:Iceberg底层数据存储在大数据统一的存储底座HDFS上,意味着可以使用大数据的超大存储空间,不需要再通过多个集群分担存储,降低了存储的维护代价。 -
存储成本低:日志写入到Iceberg不做全文索引等预处理,同时开启压缩。HDFS开启三副本相比于ElasticSearch的三副本存储空间降低近90%,相比ElasticSearch的单副本存储空间仍然降低30%。同时,日志存储可以与大数据业务共用HDFS空间,进一步降低存储成本。 -
计算成本低:对于日志这种写多查少的场景,相比于ElasticSearch存储前做全文索引等预处理,按查询触发计算更能有效利用算力。 -
存算隔离:Iceberg存储数据,Trino分析数据的存算分离架构天然的解决了查询分析对写入的影响。
基于数据湖架构的建设
通过上述评估,我们基于Iceberg和Trino构建了Venus 3.0。采集到Kafka中的日志由转存程序写入Iceberg数据湖。Venus查询平台通过Trino引擎查询分析数据湖中的日志。架构如图4所示。
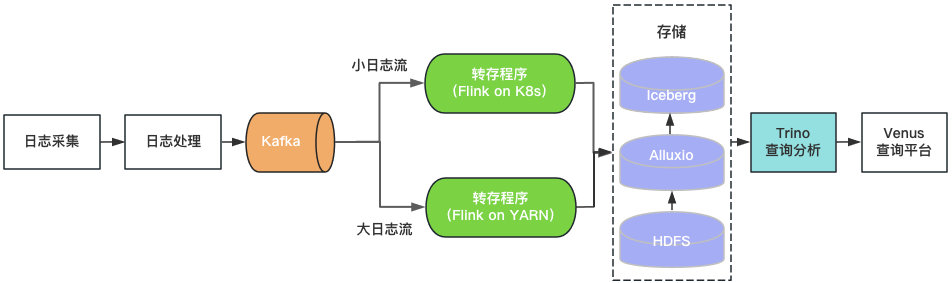 图4 Venus 3.0架构
图4 Venus 3.0架构
-
日志存储
-
查询分析
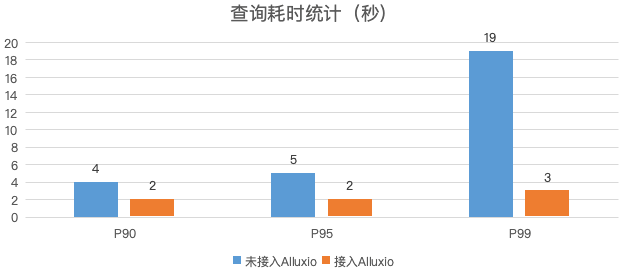
图5 日志查询性能对比
-
转存程序
-
落地效果
-
存储空间 :日志的物理存储空间降低30%,考虑到ElasticSearch集群的磁盘存储空间利用率较低,实际存储空间降低50%以上。 -
计算资源 :Trino使用的CPU核数相比于ElasticSearch减少80%,转存程序资源消耗降低70%。 -
稳定性提升:迁移到数据湖后,故障数降低了85%,大幅节省运维人力。
06
总结与规划
-
Iceberg+Trino的数据湖架构支持的查询并发较低,我们将尝试使用Bloomfilter、Zorder等轻量级索引提升查询性能,提高查询并发,满足更多的实时分析的需求。 -
目前Venus存储了近万个业务日志流,日新增日志超过500TB。计划引入基于数据热度的日志生命周期管理机制,及时下线不再使用的日志,进一步节省资源。 -
如图1所示,Venus同时也承载了大数据分析链路的Pingback用户数据的采集与处理,该链路与日志数据链路比较类似,参考日志入湖经验,我们对Pingback数据的处理环节进行基于数据湖的流批一体化改造。目前已完成一期开发与上线,应用于直播监控、QOS、DWD湖仓等场景,后续将继续推广至更多的湖仓场景。详细技术细节将在后续的数据湖系列文章中介绍。

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。