
Convidado de compartilhamento:
Fu Qingwu - arquiteto de big data do grupo de arquitetura de dados OPPO
Na aplicação real do OPPO, combinamos perfeitamente o Shuttle autodesenvolvido com o Alluxio, o que melhorou significativamente o desempenho de todo o Serviço Shuttle, basicamente duplicando o desempenho. Através desta otimização, reduzimos com sucesso a pressão do sistema em cerca de metade e duplicamos diretamente o rendimento. Esta combinação não só resolve problemas de desempenho, mas também injeta nova vitalidade no sistema de serviços da OPPO.
Assista ao compartilhamento completo
Versão em texto completo compartilhando conteúdo↓
Tópico de compartilhamento: "Prática da Alluxio em Data&AI Lake e Integração de Warehouse"
Arquitetura integrada de data lake warehouse com dados e IA
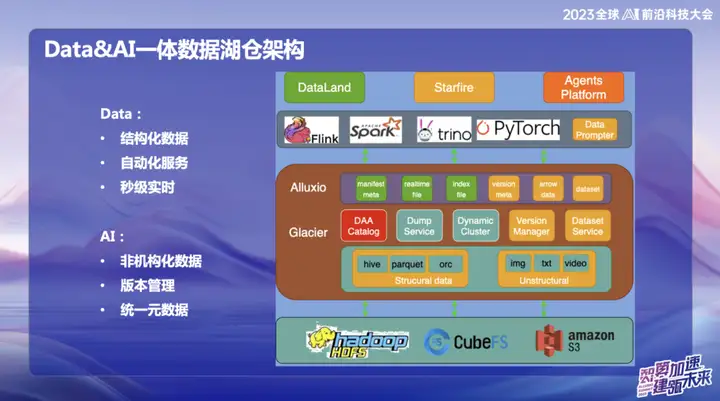
A imagem acima mostra a atual arquitetura geral do OPPO, que está dividida principalmente em duas partes:
1、Dados
2、IA
Na área de dados, o OPPO concentra-se principalmente em dados estruturados, ou seja, dados que normalmente são processados em SQL. No campo da IA, o foco principal está nos dados não estruturados. Para conseguir uma gestão unificada de dados estruturados e não estruturados, a OPPO estabeleceu um sistema denominado Dados e Catálogo, que é gerido sob a forma de metadados de Catálogo. Ao mesmo tempo, este também é um serviço de data lake, no qual a camada superior de acesso a dados utiliza cache distribuído Alluxio.
Por que escolhemos usar o Alluxio?
Devido à grande escala da sala de informática doméstica da OPPO, a quantidade de memória ociosa nos nós de computação é considerável. Estimamos que, em média, cerca de 1 PB de memória fica ociosa todos os dias e esperamos torná-la totalmente utilizada por meio deste sistema de gerenciamento de memória distribuída. A parte laranja representa o gerenciamento de dados não estruturados. Nosso objetivo é usar serviços de data lake para tornar os dados não estruturados tão fáceis de gerenciar quanto os dados estruturados e fornecer aceleração para o treinamento em IA.
Catálogo DAA
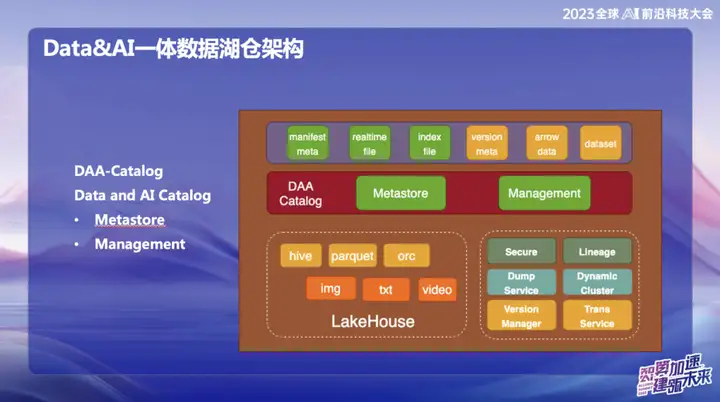
DAA-Catalog, ou Catálogo de Dados e IA, é o objetivo perseguido pela nossa equipa na base da arquitetura de dados. Escolhemos este nome porque a OPPO está empenhada em competir com as melhores empresas do setor. Atualmente, acreditamos que a Databricks é uma das empresas que mais se destacam na área de Data&AI. Quer se trate de tecnologia, conceitos avançados ou modelos de negócios, o Databricks teve um bom desempenho.
Inspirado no Unicatalog do Databricks, vemos que os dados de serviço e o processo de treinamento de IA do Databricks giram principalmente em torno do Unity Catalog. Portanto, decidimos construir o DAA-Catalog para perseguir nosso objetivo de competir com os melhores do setor no espaço de data lake warehousing.
Especificamente, esta funcionalidade está dividida em dois módulos principais:
- Metastore (armazenamento de metadados) : Esta parte é responsável pelo gerenciamento de metadados, e a camada subjacente é baseada no gerenciamento de metadados Iceberg. Inclui confirmações simultâneas e gerenciamento do ciclo de vida. Ao mesmo tempo, utilizamos o Down Service para gerenciamento, pois nossos dados entrarão primeiro no enorme pool de cache de memória do Alluxio e realizarão a inserção e consulta em tempo real de cada registro.
- Gerenciamento : Esta parte é o serviço DOM. Por que escolher o Down Service? Como os dados são armazenados primeiro na memória do Alluxio após serem inseridos, ele atinge um desempenho de segundo nível em tempo real. Durante todo o processo, os dados irão automaticamente para o Iceberg através do Catálogo após sua entrada, e os metadados estão basicamente no Alluxio.
Por que precisamos implementar essa função de segundo nível em tempo real?
Principalmente porque encontramos um problema sério ao usar o Iceberg antes. Basicamente, ele requer um commit a cada 5 minutos. Cada commit irá gerar um grande número de arquivos pequenos, o que coloca muita pressão no sistema de computação do Flink e nos metadados do HDFS. Ao mesmo tempo, esses arquivos também precisam ser limpos e mesclados manualmente. Através do serviço Alluxio os dados podem ser inseridos diretamente na memória, e o Down Service também é gerenciado através do Catálogo. Durante todo o processo, os dados irão automaticamente para o Iceberg após serem inseridos, e os metadados estão basicamente todos no Alluxio.
Como o OPPO tem muita cooperação com o Alluxio, fizemos alguns ajustes com base na versão 2.9 e o desempenho foi bastante melhorado. A leitura e a gravação de arquivos de streaming são implementadas no data lake. Cada dado pode ser tratado como um commit sem a necessidade de commit do arquivo inteiro.
Aceleração de dados estruturados
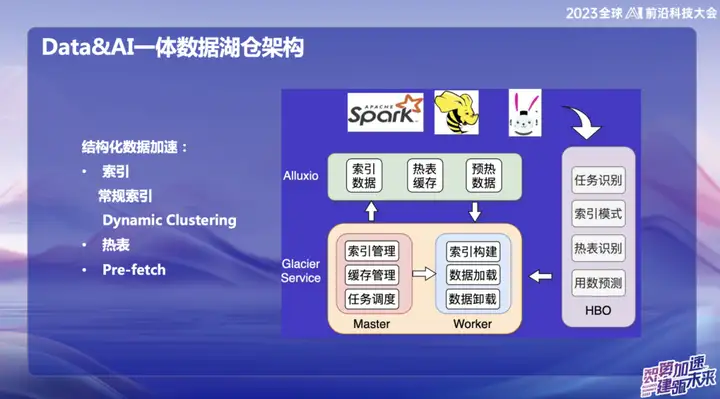
Com o desenvolvimento do big data, muitas infraestruturas tornaram-se bastante completas, resolvendo problemas nos mais diversos cenários. No entanto, nosso foco está em como utilizar recursos ociosos e memória com mais eficiência. Portanto, nos comprometemos a partir de dois aspectos: um é a aceleração do cache e o outro é a otimização de tabelas e índices quentes.
Propusemos um conceito denominado “Cluster Dinâmico”, que é uma função de agregar dados dinamicamente, inspirado em uma tecnologia de Databricks. Embora a curva Hallway também seja usada internamente, implementamos algoritmos de classificação "a ordem" e "incremental a ordem" sobre ela, fundindo-os para formar o Cluster Dinâmico. Esta inovação pode agregar dados dinamicamente após a entrada de dados para melhorar a eficiência da consulta. Comparado com a curva Hallway, o algoritmo de “ordem” é mais eficiente, mas a curva Hallway é superior em mudanças em tempo real. Essa integração nos fornece uma maneira mais flexível e eficiente de consultar e agregar dados.
Gerenciamento de dados não estruturados
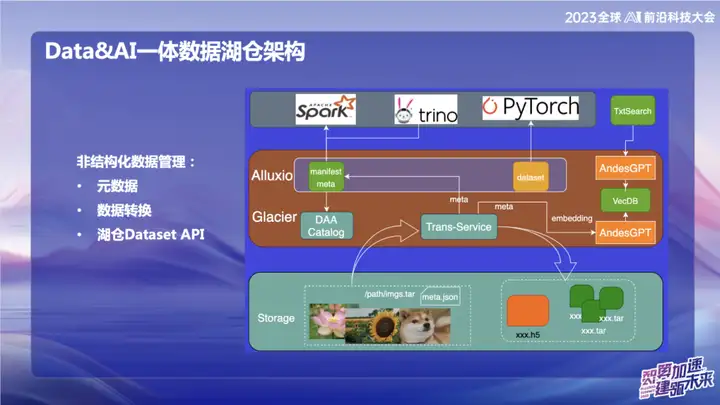
A imagem acima mostra alguns dos nossos trabalhos na área de dados não estruturados, principalmente relacionados à área de IA. No OPPO, as ferramentas usadas para treinamento de IA no início são relativamente antigas. Os dados geralmente são lidos diretamente por meio de scripts ou armazenados no armazenamento de objetos na forma de arquivos txt ou de imagem simples. Com o serviço de transferência, podemos importar dados automaticamente para o data lake e cortar os dados da imagem empacotada no formato do conjunto de atualização. No campo da IA, especialmente no campo do processamento de imagens, o conjunto de atualização é uma interface de conjunto de dados eficiente. Ele não é apenas compatível com interfaces de conjunto de dados da web, mas também pode ser convertido para o formato H5.
Nosso objetivo é tornar o gerenciamento de dados não estruturados tão conveniente quanto os dados estruturados, por meio do processamento de metadados. Durante o processo de conversão de dados, os metadados dos dados não estruturados são gravados no Catálogo. Ao mesmo tempo, combinamos com o modelo grande e escrevemos algumas informações dos metadados no banco de dados vetorial para facilitar a consulta dos dados no lake warehouse usando o modelo grande ou linguagem natural. O objetivo deste trabalho de integração é melhorar a eficiência do gerenciamento de dados não estruturados e torná-los mais consistentes com o gerenciamento de dados estruturados.
Dados não estruturados – exemplo de gerenciamento de metadados
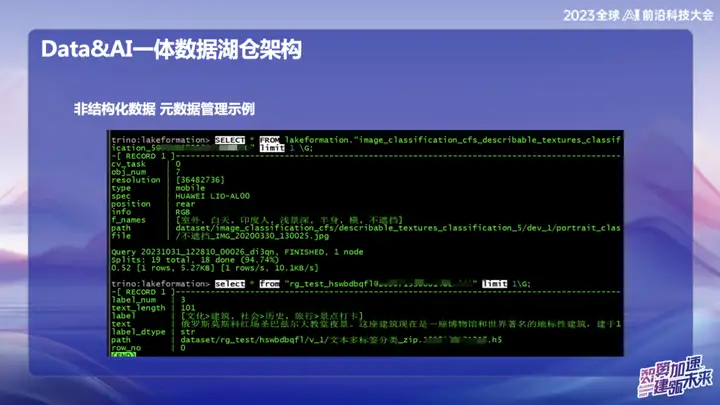
A imagem acima é um exemplo de gerenciamento de dados não estruturados do OPPO, que pode pesquisar a localização de textos e imagens como SQL.
DataPrompte r
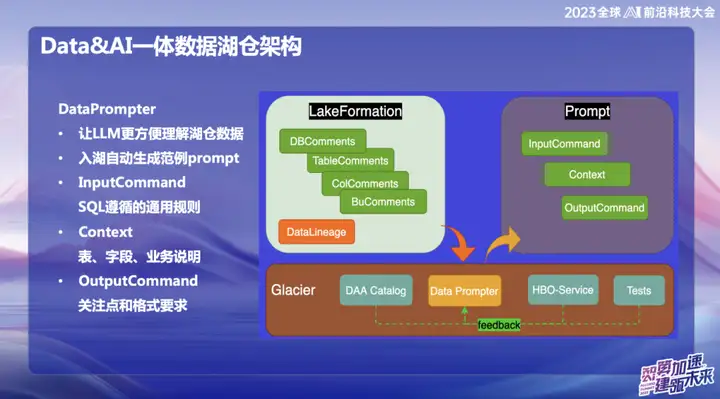
A intenção original de optar pela construção do DataPrompter decorre da busca por melhor aproveitamento de grandes modelos. A OPPO está comprometida com a combinação de dados com modelos grandes e lançou um produto chamado Data Chart. Através do software de chat interno, os usuários podem consultar facilmente todos os dados. Por exemplo, os usuários podem verificar facilmente o volume de vendas de telefones celulares ontem ou comparar a diferença de vendas com as vendas de telefones celulares Xiaomi e realizar análises de dados por meio de linguagem natural.
Durante o processo de construção do produto, as tabelas de dados em cada campo exigem que pessoal comercial profissional insira o Prompter. Isso traz desafios para a promoção de todo o data lake warehouse ou produto, pois o Prompter de cada tabela leva muito tempo. Por exemplo, se você deseja inserir dados da tabela financeira, é necessário preencher detalhadamente as informações profissionais e técnicas, como os campos da tabela, o significado do domínio de negócios e as tabelas de dimensão expandida.
Nosso objetivo final é permitir que o modelo grande compreenda facilmente os dados de nível superior depois que os dados entram no lake warehouse. Durante o processo de entrada de dados no lago, a empresa precisa exibir algumas informações prescritas, combinadas com nossa experiência acumulada em Data Prompter, e usar algumas consultas comuns fornecidas pelo HBO Service para finalmente gerar um modelo de Prompter que torne o modelo grande fácil de entender . Essa combinação visa permitir que o modelo compreenda melhor os dados de negócios e torne mais suave a integração do Hucang e de grandes modelos.
Alluxio ajuda a entrar no lago em tempo real em segundos
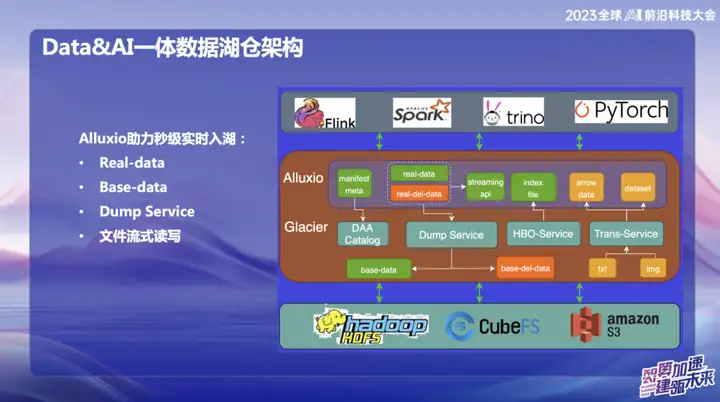
O Alluxio ajuda a entrar no lago em tempo real em segundos, que se divide principalmente em:
1、Dados reais
2、Dados base
3. Serviço de despejo
4. Leitura e gravação de streaming de arquivos
A prática de Alluxio na arquitetura Hucang
Alluxio combinado com Spark RSS
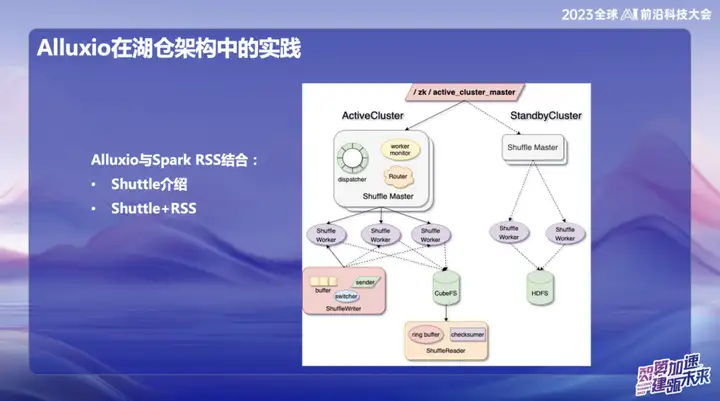
Inicialmente optamos por combinar o Alluxio com o serviço Spark RSS através do Spark Shuttle Service autodesenvolvido e abri-lo em nome de Shuttle. Inicialmente, nossa base era baseada em um sistema de arquivos distribuído, mas depois encontramos alguns problemas de desempenho, então encontramos o Alluxio.
A combinação perfeita entre Shuttle e Alluxio melhorou significativamente o desempenho de todo o Serviço Shuttle, basicamente duplicando o desempenho. Através desta otimização, reduzimos com sucesso a pressão do sistema em cerca de metade e duplicamos diretamente o rendimento. Esta combinação não só resolve o problema de desempenho, mas também injeta nova vitalidade no nosso sistema de serviços.
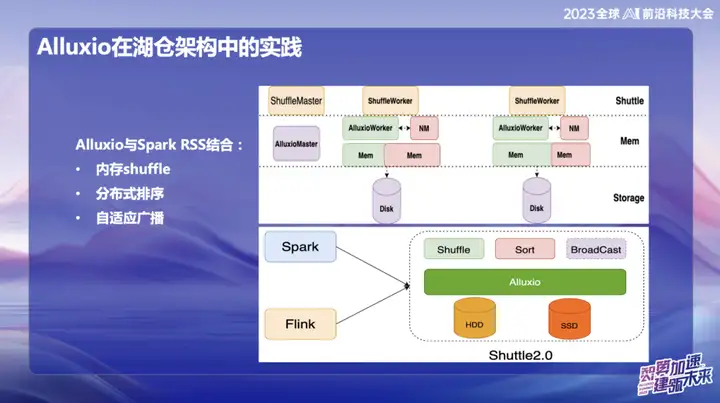
Na investigação e desenvolvimento subsequentes da OPPO, a estrutura baseada no Alluxio+Shuttle alcançou mais inovações. Otimizamos o operador Shuttle e o operador de transmissão para o nível de dados da memória. Por meio da interação eficiente dos dados da memória, especialmente ao processar a redução de ponto único, quando os dados são distorcidos, a operação de classificação que originalmente levava até 50 minutos pode ser migrada. Após a adoção da nova solução, o tempo de processamento foi reduzido com sucesso para menos de 10 minutos. Essa otimização não apenas melhora muito a eficiência do processamento, mas também alivia efetivamente o impacto da distorção dos dados no desempenho do sistema.
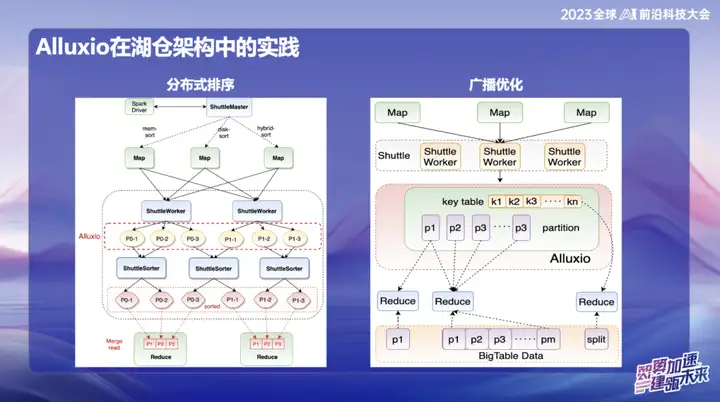
Os resultados de transmissão são muito significativos, especialmente no Spark. O tamanho de transmissão padrão é 10M. Como todos os dados de transmissão devem ser armazenados no lado Java, eles estão sujeitos à expansão após a serialização do Java, o que por sua vez causa problemas de OOM (falta de memória). .Isso acontece muito em ambientes online.
Para resolver este problema, atualmente armazenamos dados de transmissão no Alluxio. Isso permite a transmissão de quase qualquer tamanho de dados, até 10 gigabytes. Esta inovação foi implementada com sucesso em vários casos online na OPPO e teve um impacto significativo na melhoria da eficiência.
Prática de aplicação Alluxio em nuvem pública/nuvem híbrida
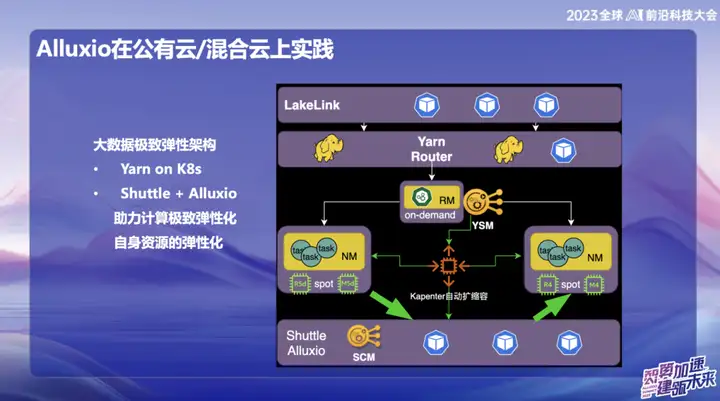
No sistema de big data em nuvem pública da OPPO, especialmente em Cingapura, usamos principalmente AWS como infraestrutura. Nos estágios iniciais, usamos o serviço de computação elástica (EMR) fornecido pela AWS. No entanto, nos últimos anos, a situação económica global da indústria tem sido menos optimista e muitas empresas estão a procurar reduzir custos e melhorar a eficiência. Diante dessa tendência, propusemos soluções autodesenvolvidas na área de nuvem pública no exterior, usando recursos elásticos na nuvem para construir uma nova arquitetura. O núcleo desta solução inovadora está na combinação Alluxio+Shuttle, que fornece suporte fundamental para nosso sistema de big data.

A vantagem significativa da solução Alluxio+Shuttle é que o cluster Alluxio não é exclusivo do Shuttle e pode fornecer suporte para outros serviços, incluindo cache de dados e cache de metadados. Na nuvem pública, sabemos que as operações de lista no S3 consomem muito tempo durante o envio. Ao combinar o Alluxio e as soluções de código aberto Magic commit e Shuttle, obtivemos efeitos significativos de redução de custos, reduzindo os custos de computação em aproximadamente 80%. .
Em um ambiente de nuvem híbrida, prestamos serviços para equipes de IA. Como há armazenamento de objetos na parte inferior do data lake, usamos a placa GPU no Alibaba Cloud durante o processo de treinamento e também a combinamos com recursos de GPU autoconstruídos. Devido à largura de banda limitada e ao alto custo das linhas dedicadas, é necessária uma camada de cache eficaz para a cópia de dados. Inicialmente adotamos uma solução fornecida pela equipe de armazenamento, mas sua escalabilidade e desempenho não eram os ideais. Após a introdução do Alluxio, alcançamos várias vezes a aceleração de IO em vários cenários, fornecendo suporte mais eficiente para processamento de dados.
Panorama

A escala do cluster OPPO atingiu dezenas de milhares de unidades na China, formando uma escala bastante grande. Planejamos nos aprofundar nos recursos de memória no futuro para utilizar mais plenamente o espaço de armazenamento interno. A equipe possui a estrutura de computação em tempo real Flink e a estrutura de processamento offline Spark. Os dois podem aprender com a experiência de aplicação do Alluxio um do outro para alcançar um desenvolvimento integrado e profundo do Alluxio e do data lake.
Na onda de combinar big data e machine learning, acompanhamos as tendências do setor. Integre profundamente a arquitetura de dados com inteligência artificial (IA) de baixo para cima para fornecer serviços de alta qualidade para IA como prioridade máxima. Esta integração não é apenas um avanço tecnológico, mas também um plano estratégico para o desenvolvimento futuro.
Por fim, exploraremos ainda mais as vantagens do Alluxio para nos ajudar a reduzir custos em ambientes de nuvem pública. Isto não envolve apenas a otimização técnica, mas também inclui uma gestão mais eficaz dos recursos de computação em nuvem, proporcionando um suporte sólido para o desenvolvimento sustentável da empresa.
Os recursos piratas de "Qing Yu Nian 2" foram carregados no npm, fazendo com que o npmmirror suspendesse o serviço unpkg. Zhou Hongyi: Não resta muito tempo para o Google. Sugiro que todos os produtos sejam de código aberto . time.sleep(6) aqui desempenha um papel. Linus é o mais ativo em “comer comida de cachorro”! O novo iPad Pro usa 12 GB de chips de memória, mas afirma ter 8 GB de memória. O People’s Daily Online analisa o carregamento estilo matryoshka do software de escritório: Somente resolvendo ativamente o “conjunto” poderemos ter um futuro . novo paradigma de desenvolvimento para Vue3, sem a necessidade de `ref/reactive `, sem necessidade de `ref.value` MySQL 8.4 LTS Manual chinês lançado: Ajuda você a dominar o novo domínio de gerenciamento de banco de dados Tongyi Qianwen nível GPT-4 modelo principal preço reduzido em 97%, 1 yuan e 2 milhões de tokens