Data lake como o vemos
Como equipe de data center da iQiyi, nossa principal tarefa é gerenciar e atender o grande número de ativos de dados dentro da empresa. No processo de implementação da governança de dados, continuamos a absorver novos conceitos e a introduzir ferramentas de ponta para refinar a gestão do nosso sistema de dados.
“Data lake” é um conceito que tem sido amplamente discutido na área de dados nos últimos anos, e seus aspectos técnicos também têm recebido ampla atenção da indústria. Nossa equipe conduziu pesquisas aprofundadas sobre a teoria e a prática dos data lakes. Acreditamos que os data lakes não são apenas uma nova perspectiva no gerenciamento de dados, mas também uma tecnologia promissora para integração e processamento de dados.
Data lake é uma ideia de governança de dados
O objetivo da implementação de um data lake é fornecer uma solução eficiente de armazenamento e gerenciamento para levar a facilidade de uso e a disponibilidade dos dados a um novo nível.
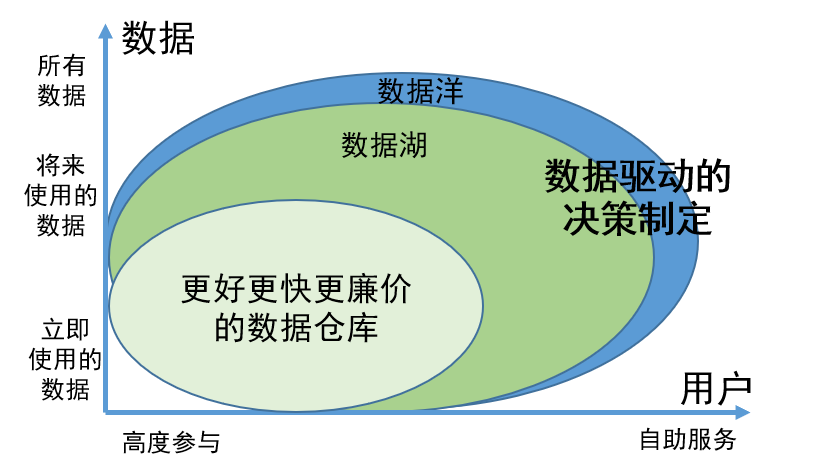
Sendo um conceito inovador de governação de dados, o valor do data lake reflecte-se principalmente nos dois aspectos seguintes:
1. A capacidade de armazenar de forma abrangente todos os dados, independentemente de os dados estarem em uso ou temporariamente indisponíveis, garante que as informações necessárias possam ser facilmente encontradas quando necessário e melhore a eficiência do trabalho;
2. Os dados no data lake foram gerenciados e organizados cientificamente, tornando mais fácil para os usuários encontrarem e usarem os dados por conta própria. Este modelo de gestão reduz muito o envolvimento dos engenheiros de dados. Os usuários podem realizar as tarefas de busca e utilização dos dados por conta própria, economizando assim muitos recursos humanos.
Para gerir todos os tipos de dados de forma mais eficaz, o data lake divide os dados em quatro áreas principais com base em diferentes características e necessidades, nomeadamente área original, área de produto, área de trabalho e área sensível:
Área bruta
: Esta área está focada em atender às necessidades de engenheiros de dados e cientistas de dados profissionais, e seu principal objetivo é armazenar dados brutos e não processados. Quando necessário, também pode ser parcialmente aberto para suportar requisitos de acesso específicos.
Área de produto
: A maioria dos dados na área de produto é processada e processada por engenheiros de dados, cientistas de dados e analistas de negócios para garantir a padronização e alto grau de gerenciamento de dados. Esse tipo de dados geralmente é amplamente utilizado em relatórios de negócios, análise de dados, aprendizado de máquina e outros campos.
Área de trabalho
: A área de trabalho é usada principalmente para armazenar dados intermediários gerados por vários trabalhadores de dados. Aqui, os usuários são responsáveis por gerenciar seus dados para oferecer suporte à exploração e experimentação flexível de dados para atender às necessidades de diferentes grupos de usuários.
Área sensível
: A área sensível concentra-se na segurança e é usada principalmente para armazenar dados confidenciais, como informações de identificação pessoal, dados financeiros e dados de conformidade legal. Esta área é protegida pelo mais alto nível de controle de acesso e segurança.
Através desta divisão, o data lake pode gerenciar melhor diferentes tipos de dados, ao mesmo tempo que fornece acesso e utilização convenientes de dados para atender a diversas necessidades.
Aplicação de ideias de governança de dados de Data Lake em data center
O objetivo do data center é resolver problemas como calibres estatísticos inconsistentes, desenvolvimento repetido, resposta lenta às necessidades de desenvolvimento de indicadores, baixa qualidade de dados e altos custos de dados causados pelo aumento de dados e pela expansão dos negócios.
Os objetivos do data center e do data lake são consistentes. Ao combinar o conceito de data lake, o sistema de dados e a arquitetura geral do data center foram otimizados e atualizados.
Na fase inicial de construção do data center, integramos o sistema de data warehouse da empresa, conduzimos pesquisas aprofundadas sobre o negócio, classificamos as informações existentes de campo e dimensão, resumimos as dimensões de consistência, estabelecemos um sistema de indicadores unificados e formulamos a construção de data warehouse especificações. De acordo com esta especificação, construímos a camada de dados original (ODS), a camada de dados detalhada (DWD) e a camada de dados agregada (MID) do data warehouse unificado e estabelecemos uma biblioteca de dispositivos, incluindo uma biblioteca de dispositivos acumulada e um novo dispositivo biblioteca. Com base no data warehouse unificado, a equipe de dados construiu um data warehouse temático e um mercado de negócios com base em diferentes análises e direções estatísticas e necessidades de negócios. O armazém de dados em questão e o mercado de negócios incluem dados detalhados processados posteriormente, dados agregados e tabelas de dados da camada de aplicação. A camada de aplicação de dados usa esses dados para fornecer diferentes serviços aos usuários.
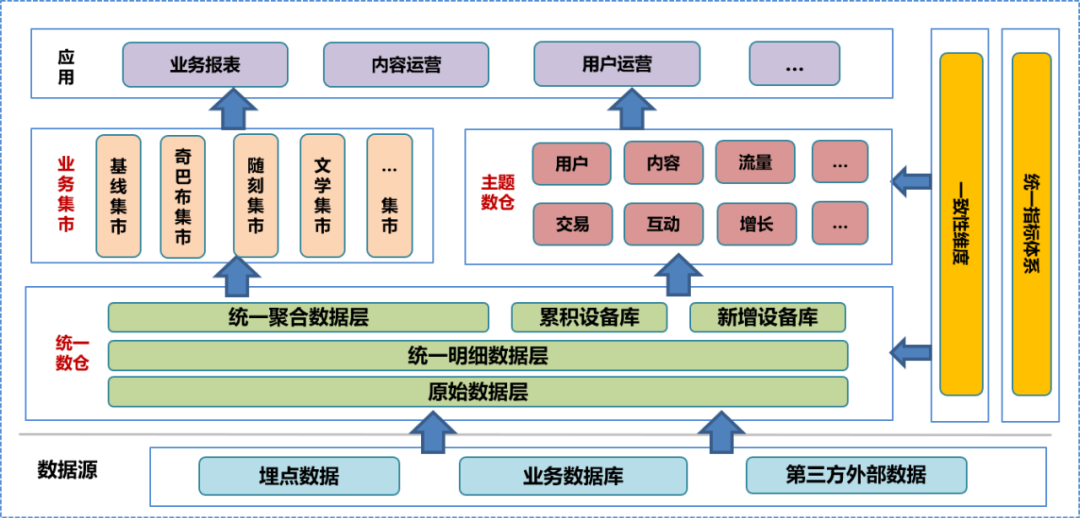
Em um sistema unificado de data warehouse, a camada de dados original e
abaixo
não são abertas ao público. Os usuários só podem usar engenheiros de dados para processar os dados processados, portanto, é inevitável que alguns detalhes dos dados sejam perdidos.
No trabalho diário, os usuários com recursos de análise de dados geralmente desejam acessar os dados brutos subjacentes para realizar análises personalizadas ou solucionar problemas.
O conceito de gerenciamento de dados de data lake pode resolver esse problema com eficácia. Depois de introduzir a ideia de governança de dados do data lake, classificamos e integramos os recursos de dados existentes, enriquecemos e expandimos os metadados de dados e construímos um centro de metadados de dados especificamente para gerenciar o centro de metadados.
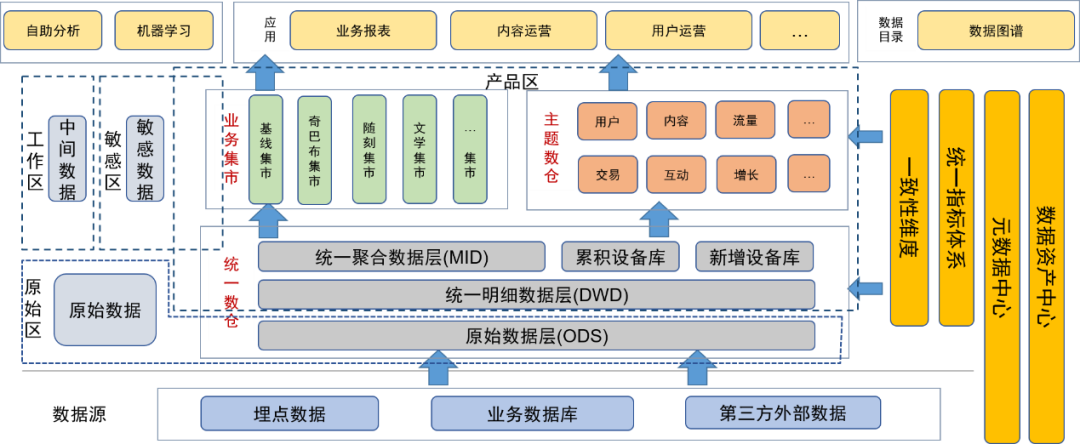
Depois de introduzir o conceito de data lake para governança de dados, colocamos a camada de dados original e outros dados originais (como arquivos de log originais) na área de dados original. Os usuários com capacidade de processamento de dados podem solicitar permissão para usar os dados nesta área.
A camada detalhada, a camada de agregação, o data warehouse temático e o business mart do data warehouse unificado são colocados na área do produto. Esses dados foram processados pelos engenheiros de dados da equipe de dados e fornecidos aos usuários como produtos de dados finais. nesta área foi processado pelo gerenciamento de dados, portanto a qualidade dos dados é garantida.
Também definimos áreas sensíveis para dados confidenciais e nos concentramos no controle dos direitos de acesso.
Tabelas temporárias ou tabelas pessoais geradas diariamente por usuários e desenvolvedores de dados são colocadas na área temporária. Essas tabelas de dados são de responsabilidade dos próprios usuários e podem ser abertas a outros usuários condicionalmente.
Os metadados de cada dado são mantidos através do centro de metadados, incluindo informações de tabela, informações de campo e as dimensões e indicadores correspondentes aos campos. Ao mesmo tempo, também mantemos a linhagem de dados, incluindo relacionamentos de linhagem em nível de tabela e em nível de campo.
Mantenha as características dos ativos dos dados por meio do centro de ativos de dados, incluindo o gerenciamento do nível, da confidencialidade e das permissões dos dados.
Para facilitar que os usuários utilizem melhor os dados por conta própria, fornecemos um mapa de dados como um diretório de dados na camada de aplicativo para os usuários consultarem dados, incluindo metadados como uso de dados, dimensões, indicadores e linhagem. Ao mesmo tempo, a plataforma também pode ser utilizada como portal para solicitação de permissão.
Além disso, também fornecemos uma plataforma de análise de autoatendimento para fornecer aos usuários de dados recursos de análise de autoatendimento.
Ao mesmo tempo em que otimizamos o sistema de dados, também atualizamos a arquitetura da plataforma intermediária de dados com base no conceito de data lake.
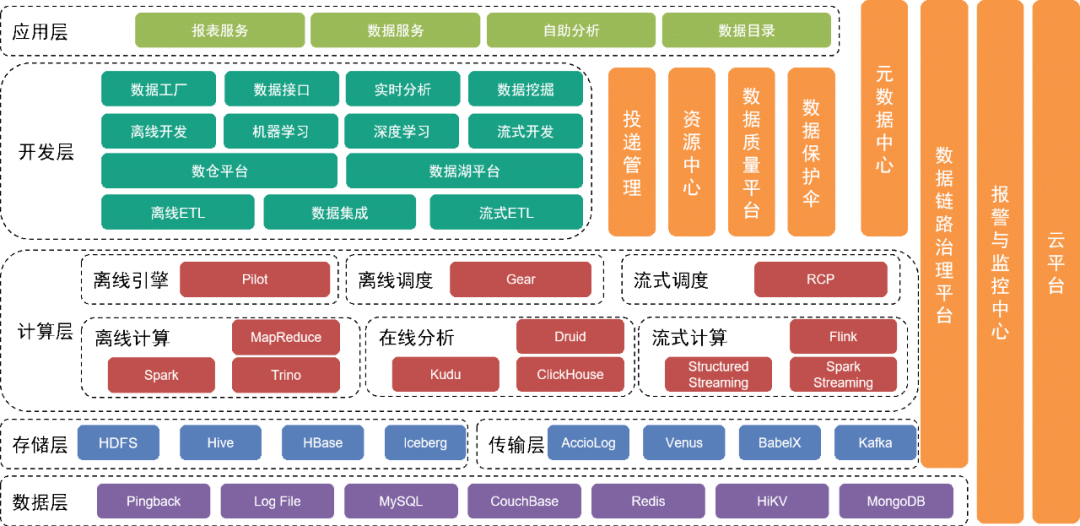
A camada inferior é a camada de dados , que inclui várias fontes de dados, como dados Pingback, que são usados principalmente para coletar o comportamento do usuário. Os dados de negócios são armazenados em vários bancos de dados relacionais e bancos de dados NoSQL.
Esses dados são armazenados na camada de armazenamento por meio de diferentes ferramentas de coleta na camada de transporte.
Acima da camada de dados está a camada de armazenamento
, que é baseada principalmente em HDFS, um sistema de arquivos distribuído, para armazenar arquivos originais. Outros dados estruturados ou não estruturados são armazenados no Hive, Iceberg ou HBase.
Mais acima está a camada de computação
, que usa principalmente o mecanismo offline Pilot para acionar Spark ou Trino para cálculos offline, e usa o mecanismo de agendamento Gear, mecanismo de fluxo de trabalho offline para agendamento de fluxo de trabalho agendado. A plataforma de computação em tempo real RCP é responsável por agendar a computação em fluxo. Após várias rodadas de iterações, a computação de fluxo atualmente usa principalmente o Flink como mecanismo de computação.
A camada de desenvolvimento acima da camada de computação
encapsula ainda mais cada módulo de serviço da camada de computação e da camada de transmissão para fornecer funções para o desenvolvimento de fluxos de trabalho de processamento de dados offline, integração de dados, desenvolvimento de fluxos de trabalho de processamento em tempo real e desenvolvimento de implementações de engenharia de aprendizado de máquina e conjuntos de ferramentas intermediárias. serviços para concluir o trabalho de desenvolvimento. A plataforma de data lake gerencia as informações de cada arquivo de dados e tabela de dados no data lake, enquanto a plataforma de data warehouse gerencia o modelo de dados do data warehouse, modelo físico, dimensões, indicadores e outras informações.
Ao mesmo tempo, fornecemos uma variedade de ferramentas e serviços de gerenciamento verticalmente. Por exemplo, a ferramenta de gerenciamento de entrega gerencia metainformações, como especificações ocultas do Pingback, campos, dicionários e prazos de entrega; são usados para manter tabelas de dados ou arquivos de dados e garantir a segurança dos dados e a plataforma de gerenciamento de links monitoram a qualidade dos dados e o status de produção dos links de dados, notificam prontamente as equipes relevantes para salvaguardas e respondem rapidamente a problemas e falhas online. com base nos planos existentes.
Os serviços subjacentes são fornecidos pela equipe de serviços em nuvem para fornecer suporte à nuvem privada e à nuvem pública.
A camada superior da arquitetura fornece um mapa de dados como um diretório de dados para os usuários encontrarem os dados de que precisam. Além disso, fornecemos aplicativos de autoatendimento, como Magic Mirror e Beidou, para atender às necessidades dos usuários em diferentes níveis para trabalho de dados de autoatendimento.
Após a transformação de todo o sistema de arquitetura, a integração e o gerenciamento de dados são mais flexíveis e abrangentes. Reduzimos o limite do usuário otimizando ferramentas de autoatendimento, atendendo às necessidades dos usuários em diferentes níveis, melhorando a eficiência do uso de dados e aumentando o valor dos dados.
Aplicação da tecnologia data lake em data center
Num sentido amplo, data lake é um conceito de governança de dados. Em sentido estrito, data lake também se refere a uma tecnologia de processamento de dados.
A tecnologia de data lake abrange o formato de armazenamento de tabelas de dados e a tecnologia de processamento de dados após a entrada no lago.
Existem três soluções principais de armazenamento em data lakes na indústria: Delta Lake, Hudi e Iceberg. Uma comparação dos três é a seguinte:
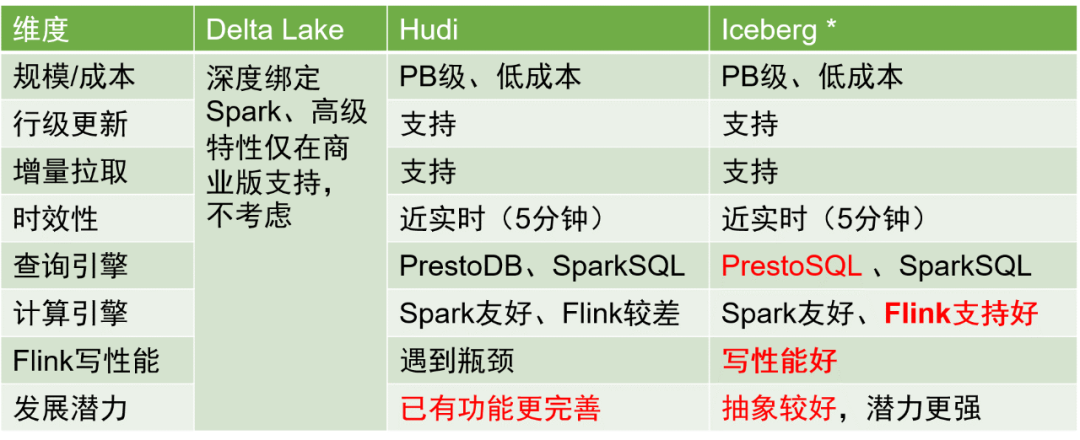
Após consideração abrangente, escolhemos Iceberg como formato de armazenamento da tabela de dados.
Iceberg é um formato de armazenamento de tabela que organiza arquivos de dados no sistema de arquivos subjacente ou armazenamento de objetos.
Aqui estão as principais comparações entre Iceberg e Hive:
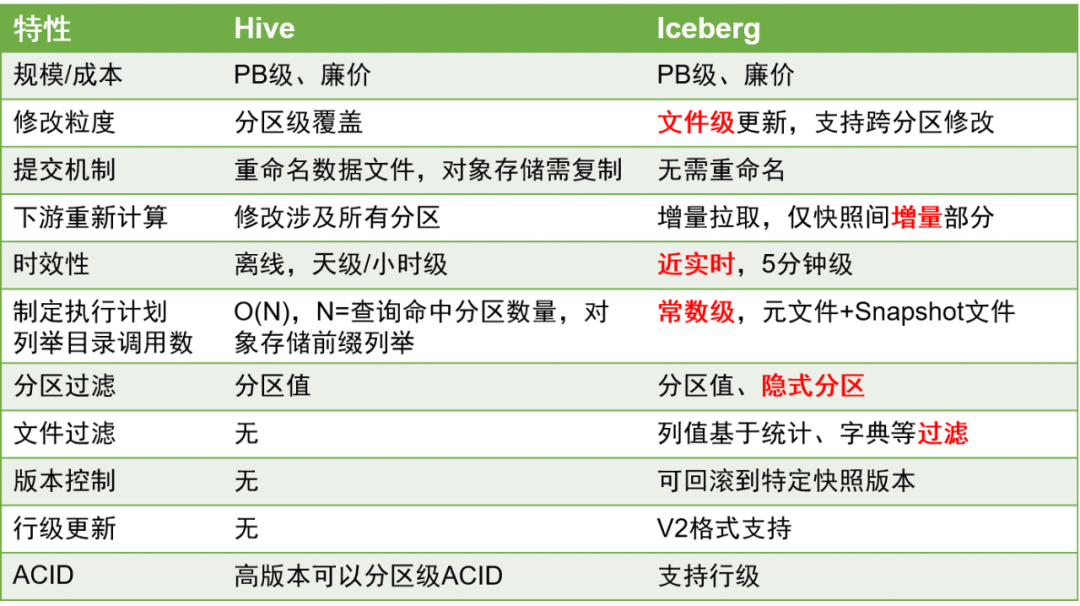
Em comparação com as tabelas Hive, as tabelas Iceberg têm vantagens significativas porque podem suportar melhor atualizações em nível de linha e a pontualidade dos dados pode ser melhorada ao nível minuto.
Isto é de grande importância no processamento de dados, porque a melhoria da pontualidade dos dados pode melhorar muito a eficiência do processamento de dados ETL.
Portanto, podemos transformar facilmente a arquitetura Lambda existente para obter uma arquitetura integrada de streaming em lote:
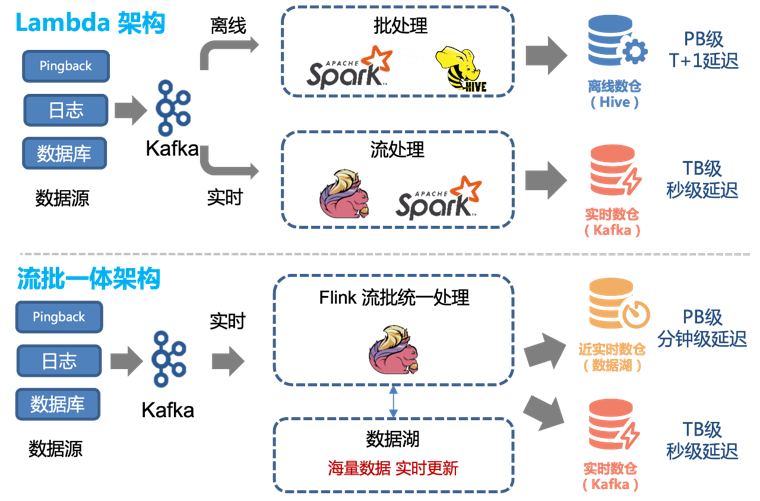
Antes da introdução da tecnologia de data lake, usávamos uma combinação de processamento offline e processamento em tempo real para fornecer data warehouse offline e data warehouse em tempo real.
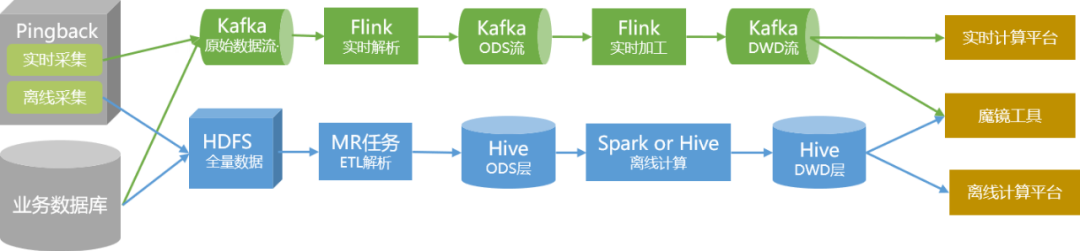
A quantidade total de dados é incorporada aos dados do data warehouse por meio de métodos tradicionais de análise e processamento off-line
e é armazenada no cluster na forma de tabelas Hive.
Para dados com altos requisitos de tempo real, nós os produzimos separadamente por meio de links em tempo real e os fornecemos aos usuários na forma de Tópicos no Kafka.
No entanto, esta arquitetura tem os seguintes problemas:
-
Os dois canais, em tempo real e offline, precisam manter dois conjuntos diferentes de lógica de código. Quando a lógica de processamento muda, os canais em tempo real e offline precisam ser atualizados ao mesmo tempo, caso contrário ocorrerá inconsistência de dados.
-
Atualizações horárias de links off-line e um atraso de cerca de 1 hora significam que os dados às 00h01 não podem ser consultados antes das 02h00. Para alguns serviços downstream com elevados requisitos em tempo real, isto é inaceitável, pelo que as ligações em tempo real precisam de ser suportadas.
-
Embora o desempenho em tempo real do link em tempo real possa atingir o segundo nível, seu custo é alto. Para a maioria dos usuários, uma atualização de cinco minutos é suficiente. Ao mesmo tempo, consumir fluxos Kafka não é tão conveniente quanto operar diretamente tabelas de dados.
Esses problemas podem ser melhor resolvidos usando o método integrado de processamento de dados de tabelas Iceberg e lotes de streaming.

Durante o processo de otimização, realizamos principalmente a transformação Iceberg nas tabelas da camada ODS e da camada DWD e reconstruímos a análise e o processamento de dados em tarefas Flink.
Para garantir que a estabilidade e a precisão da produção de dados não sejam afetadas durante o processo de transformação, tomamos as seguintes medidas:
1. Comece a mudar com dados não essenciais. Com base nas condições reais de negócios, usamos a entrega QOS e a entrega personalizada como projetos piloto.
2. Ao abstrair a lógica de análise offline, um SDK de armazenamento de análise Pingback unificado é formado, que realiza a implantação unificada de tempo real e offline e torna o código mais padronizado.
3. Após a implantação da tabela Iceberg e do novo processo de produção, executamos operações paralelas de link duplo durante dois meses e realizamos monitoramento comparativo regular dos dados.
4. Após confirmar que não há problemas com dados e produção, realizamos uma mudança imperceptível para a camada superior.
5. Para os dados de inicialização e reprodução relacionados aos dados principais, realizaremos o streaming integrado e a transformação em lote depois que a verificação geral estiver estável.
Após a transformação, os benefícios são os seguintes:
1. O qos e os links de dados de entrega personalizados foram implementados quase em tempo real como um todo. Os dados com atraso de hora em hora podem ser atualizados no nível de cinco minutos.
2. Exceto em circunstâncias especiais, o link integrado de streaming e lote pode atender às necessidades em tempo real. Portanto, podemos desativar os links em tempo real existentes e os links de análise offline relacionados ao QOS e à personalização, economizando recursos.
Através da transformação do processamento de dados, nosso link de dados será como mostrado na figura abaixo no futuro:
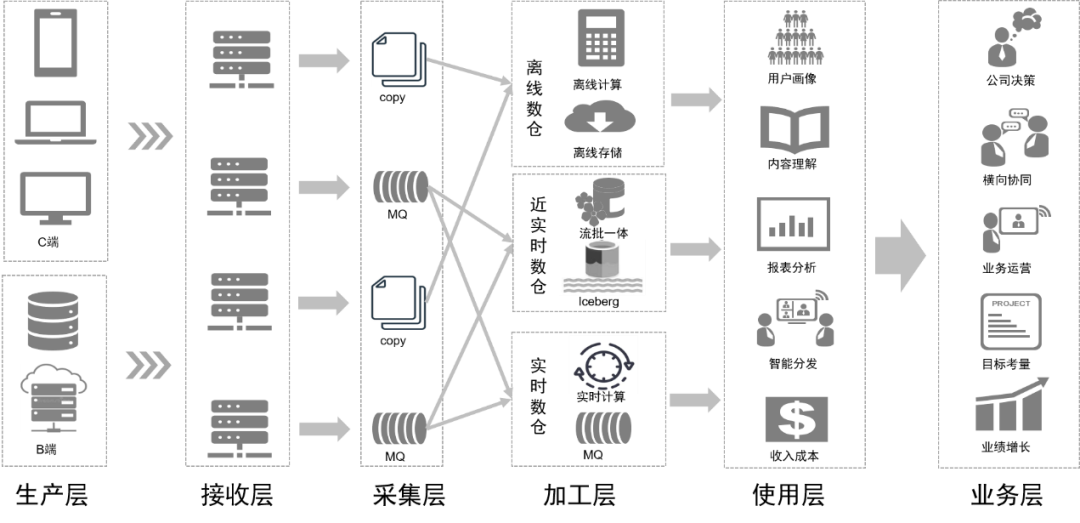
Planejamento de acompanhamento
Para o planejamento subsequente da aplicação do data lake no data center, existem dois aspectos principais:
Do nível arquitetônico, continuaremos a refinar o desenvolvimento de cada módulo para tornar os dados e serviços fornecidos pelo data center mais abrangentes e fáceis de usar, para que diferentes usuários possam utilizá-los de forma conveniente;
A nível técnico, continuaremos a transformar a ligação de dados numa integração stream-batch e, ao mesmo tempo, continuaremos a introduzir ativamente tecnologias de dados adequadas para melhorar a produção de dados e a eficiência da utilização e reduzir os custos de produção.
6. Alex Gorelik. O Big Data Lake Corporativo.
Talvez você também queira ver
Este artigo é compartilhado pela conta pública do WeChat - iQIYI Technology Product Team (iQIYI-TP).
Se houver alguma violação, entre em contato com [email protected] para exclusão.
Este artigo participa do “ Plano de Criação da Fonte OSC ”. Você que está lendo é bem-vindo para participar e compartilhar juntos.
