
01
voltarcenae status quo
1. Características dos dados na área publicitária
Os dados na área de publicidade podem ser divididos em: características de valor contínuo Diferente da imagem, vídeo, voz e outros campos de IA , os dados originais no campo são apresentados principalmente na forma de ID, como ID do usuário, ID de publicidade, sequência de ID de publicidade interagindo com o usuário, etc., e o ID a escala é grande, formando o campo publicitário As características distintivas dos dados esparsos de alta dimensão.
-
Existem características estáticas (como a idade do usuário) e dinâmicas baseadas no comportamento do usuário (como o número de vezes que um usuário clica em um anúncio em um determinado setor). -
A vantagem é que possui boa capacidade de generalização. A preferência de um usuário por um setor pode ser generalizada para outros usuários que tenham as mesmas características estatísticas do setor. -
A desvantagem é que a falta de capacidade de memória resulta em baixa discriminação. Por exemplo, dois usuários com as mesmas características estatísticas podem ter diferenças significativas de comportamento. Além disso, recursos de valor contínuo também exigem muita engenharia manual de recursos.
-
Recursos de valor discreto são recursos refinados. Existem enumeráveis (como gênero do usuário, ID do setor) e também existem outros de alta dimensão (como ID do usuário, ID de publicidade). -
A vantagem é que possui memória forte e alta distinção. Recursos de valor discreto também podem ser combinados para aprender informações cruzadas e colaborativas. -
A desvantagem é que a capacidade de generalização é relativamente fraca.
-
Codificação one-hot -
Incorporação de recursos (incorporação)
-
Conflito de recursos: se o vocabulário_size for definido muito grande, a eficiência do treinamento cairá drasticamente e o treinamento falhará devido ao OOM da memória. Portanto, mesmo para recursos de valor discreto de ID de usuário de nível bilhão, configuraremos apenas um espaço de hash de ID de 100.000 níveis. A taxa de conflito de hash é alta, as informações do recurso estão danificadas e não há benefício positivo na avaliação offline. -
IO ineficiente: como recursos como ID de usuário e ID de publicidade são de alta dimensão e esparsos, ou seja, os parâmetros atualizados durante o treinamento representam apenas uma pequena parte do total. No mecanismo de incorporação estático original do TensorFlow, o acesso ao modelo precisa ser processado. Todo o Tensor denso trará uma enorme sobrecarga de IO e não pode suportar o treinamento de modelos grandes e esparsos.
02
Prática de modelo grande esparso de publicidade
-
A API TFRA é compatível com o ecossistema Tensorflow (reutilizando o otimizador e inicializador originais, a API tem o mesmo nome e comportamento consistente), permitindo que o TensorFlow suporte o treinamento e inferência de grandes modelos esparsos do tipo ID de uma forma mais nativa; o custo de aprendizagem e uso é baixo e não altera os hábitos de modelagem dos engenheiros de algoritmos. -
A expansão e contração dinâmica da memória economiza recursos durante o treinamento; evita efetivamente conflitos de Hash e garante que as informações dos recursos não tenham perdas.
-
A incorporação estática é atualizada para incorporação dinâmica: Para a lógica Hash artificial de recursos de valor discreto, a incorporação dinâmica TFRA é usada para armazenar, acessar e atualizar parâmetros, garantindo assim que a incorporação de todos os recursos de valor discreto seja livre de conflitos na estrutura do algoritmo e garantindo que todos os valores discretos Aprendizagem de recursos sem perdas. -
Uso de recursos de ID esparsos de alta dimensão: conforme mencionado acima, ao usar a função de incorporação estática do TensorFlow, os recursos de ID do usuário e ID de publicidade não têm lucro na avaliação offline devido a conflitos de Hash. Após a atualização da estrutura do algoritmo, os recursos de ID do usuário e ID de publicidade são reintroduzidos e há benefícios positivos tanto offline quanto online. -
O uso de recursos de ID combinados esparsos e de alta dimensão: Apresentando os recursos de valor discreto combinados de ID de usuário e ID de granulação grossa de publicidade, como a combinação de ID de usuário com ID da indústria e nome do pacote de aplicativo, respectivamente. Ao mesmo tempo, combinados com a função de acesso a recursos, são introduzidos recursos discretos usando uma combinação de IDs de usuário e IDs de publicidade mais esparsos.

2. Atualização do modelo
-
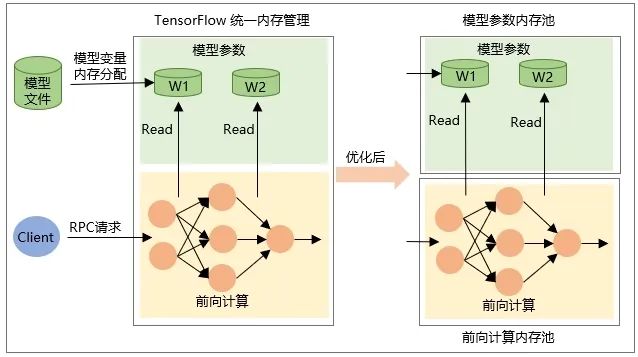
A alocação da própria variável Tensor quando o modelo é restaurado, ou seja, a memória é alocada quando o modelo é carregado, e a memória é liberada quando o modelo é descarregado. -
A memória do Tensor de saída intermediária é alocada durante o cálculo de encaminhamento da rede durante a solicitação RPC e é liberada após a conclusão do processamento da solicitação.
03
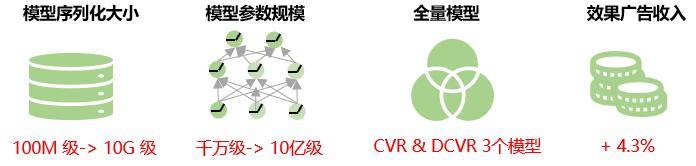
benefício geral
04
perspectiva futura
Atualmente, todos os valores de recursos do mesmo recurso no modelo esparso de publicidade grande recebem a mesma dimensão de incorporação. Nos negócios reais, a distribuição de dados de recursos de alta dimensão é extremamente desigual, um número muito pequeno de recursos de alta frequência representa uma proporção muito alta e o fenômeno da cauda longa é sério usando dimensões de incorporação fixas para todos os valores de recursos ; reduzirá a capacidade de incorporação de aprendizagem de representação. Ou seja, para recursos de baixa frequência, a dimensão de incorporação é muito grande e o modelo corre o risco de se ajustar demais para recursos de alta frequência, porque há uma riqueza de informações que precisam ser representadas e aprendidas, a incorporação; a dimensão é muito pequena e o modelo corre o risco de ser subajustado. Portanto, no futuro, exploraremos maneiras de aprender de forma adaptativa a dimensão de incorporação de recursos para melhorar ainda mais a precisão da previsão do modelo.
Ao mesmo tempo, exploraremos a solução de exportação incremental do modelo, ou seja, carregar apenas os parâmetros que mudam durante o treinamento incremental para o TensorFlow Serving, reduzindo assim a transmissão da rede e o tempo de carregamento durante a atualização do modelo, alcançando atualizações em nível de minuto de grandes modelos esparsos e melhorando a natureza em tempo real do modelo.

Processo de otimização de lance duplo de publicidade de desempenho iQIYI
Este artigo é compartilhado pela conta pública do WeChat - iQIYI Technology Product Team (iQIYI-TP).
Se houver alguma violação, entre em contato com [email protected] para exclusão.
Este artigo participa do “ Plano de Criação da Fonte OSC ”. Você que está lendo é bem-vindo para participar e compartilhar juntos.
{{o.nome}}
{{m.nome}}