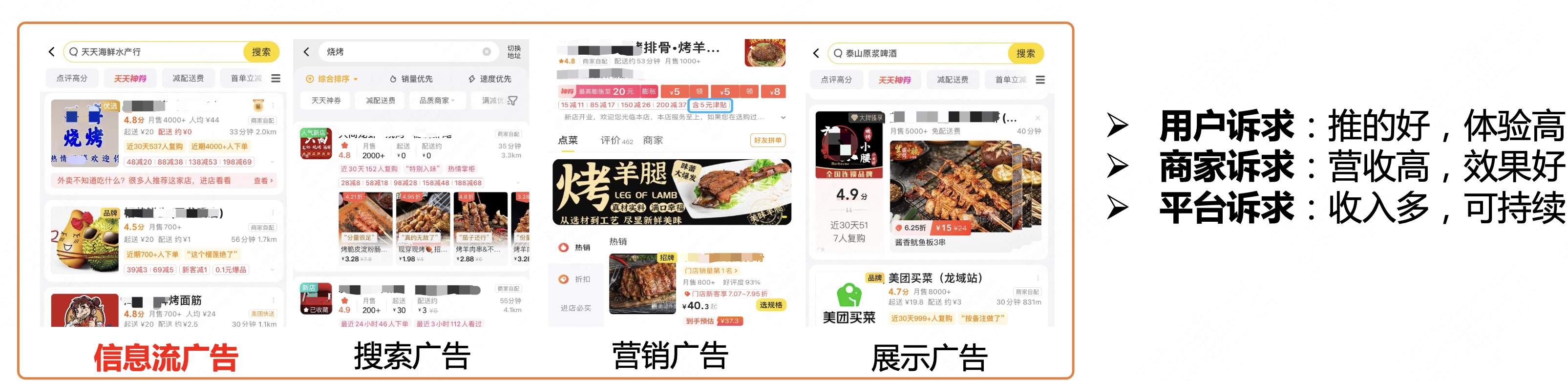
Este artigo foi compilado a partir da 81ª edição do Meituan Technology Salon "Exploração e prática da Meituan no campo de algoritmos de publicidade" (Bilibili Video). O artigo primeiro apresenta o status atual do negócio de publicidade de fluxo de informações e da tecnologia de previsão da Meituan e, em seguida, concentra-se no compartilhamento da prática específica de previsão de publicidade de fluxo de informações na Meituan, com foco em caminhos de tomada de decisão, modelagem ultralonga e ultralarga e modelagem de redução completa Cada dimensão foi compartilhada e, finalmente, há alguns resumos e perspectivas, espero que possa ser útil ou inspirador para todos.

1 Situação atual dos negócios de publicidade de fluxo de informações e tecnologia de previsão
1.1 Características do negócio de publicidade com fluxo de informações
Atualmente, a publicidade da Meituan Waimai inclui principalmente publicidade de fluxo de informações, publicidade de pesquisa, publicidade de marketing, publicidade gráfica, etc. O negócio de takeaway tem características típicas de negócios:
- O comportamento do usuário é altamente consistente : os usuários têm intenções claras de refeição, geralmente concluem a refeição em 10 minutos e a taxa de pedidos UV é alta.
- Informações de exibição ricas : as informações do cartão abrangem pontuações, avaliações, descontos, entrega e outras informações, o que tem um forte impacto na tomada de decisão dos usuários.
- Muitas informações de texto : em cenários de comércio eletrônico, as imagens de produtos geralmente desempenham um papel importante como imagens candidatas, mas em cenários de entrega, os comerciantes são candidatos mais complexos. Informações de texto, como nomes de comerciantes, avaliações e pratos populares, podem influenciar. decisões dos usuários.
1.2 Visão geral da tecnologia e estágio de evolução
Aqui, apresentamos primeiro o status atual da tecnologia de previsão. Do ponto de vista técnico, a figura a seguir mostra o processo geral do sistema de entrega de publicidade:

De modo geral, o sistema de publicidade para viagem é relativamente semelhante ao nosso sistema de promoção de busca na indústria, incluindo recall, classificação aproximada, classificação precisa e vários mecanismos. No entanto, a maior diferença entre a publicidade para viagem e os cenários da indústria é o recall, porque se baseia em serviços de localização (LBS) e o processo em si tem certas restrições. Portanto, investiremos mais poder de computação e recursos no ajuste fino e nos níveis de mecanismo, a fim de maximizar a melhoria do link geral.
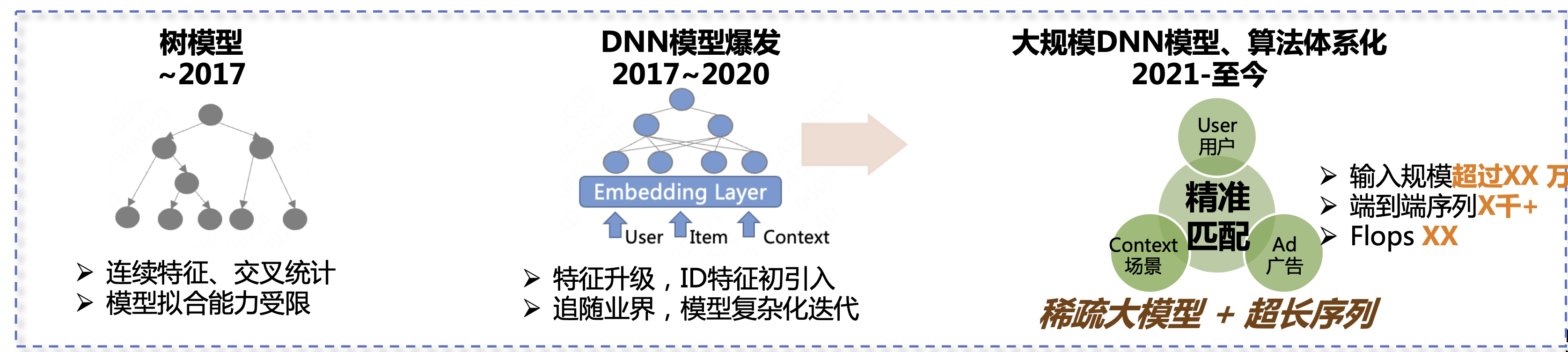
Nos últimos seis ou sete anos, o algoritmo de previsão de publicidade doméstica passou por três estágios de desenvolvimento. O primeiro estágio foi o modelo de árvore, incluindo recursos contínuos, estatísticas cruzadas, etc. A segunda etapa é de 2017 a 2020. Durante esta etapa, os modelos DNN começaram a explodir. Atualizamos recursos e começamos a acompanhar o ritmo da indústria, introduzindo modelos mais complexos para melhorar continuamente os resultados do negócio. A terceira etapa é de 2021 até o presente. Nossa direção principal são modelos grandes e esparsos + sequências ultralongas para melhorar ainda mais os efeitos nos negócios.
1.3 Situação técnica estimada
No nível técnico de previsão de publicidade do fluxo de informações, as principais direções de exploração são a direção do usuário, a direção do link e a direção da PNL (conforme mostrado na figura abaixo). É claro que se esta imagem fosse mais abrangente, também incluiria direções cruzadas, múltiplas cenas e múltiplos alvos, etc. Não escolhemos outras direções, principalmente porque em termos de direções cruzadas, descobrimos que, com o desenvolvimento contínuo da indústria da Internet, os comportamentos dos usuários se tornarão cada vez mais complexos, e as direções cruzadas só podem trazer capacidades de aprendizagem profunda em nível de contexto ., não pode continuar a ser a fonte do efeito. Por outro lado, embora a tecnologia cruzada também esteja se desenvolvendo, a direção do desenvolvimento também é da correspondência de ID para a correspondência de sequência, e a capacidade de modelo cruzado de recursos de categoria plana simples tem desenvolvimento limitado. Considerando vários fatores, não repetimos o crossover como uma direção de longo prazo.
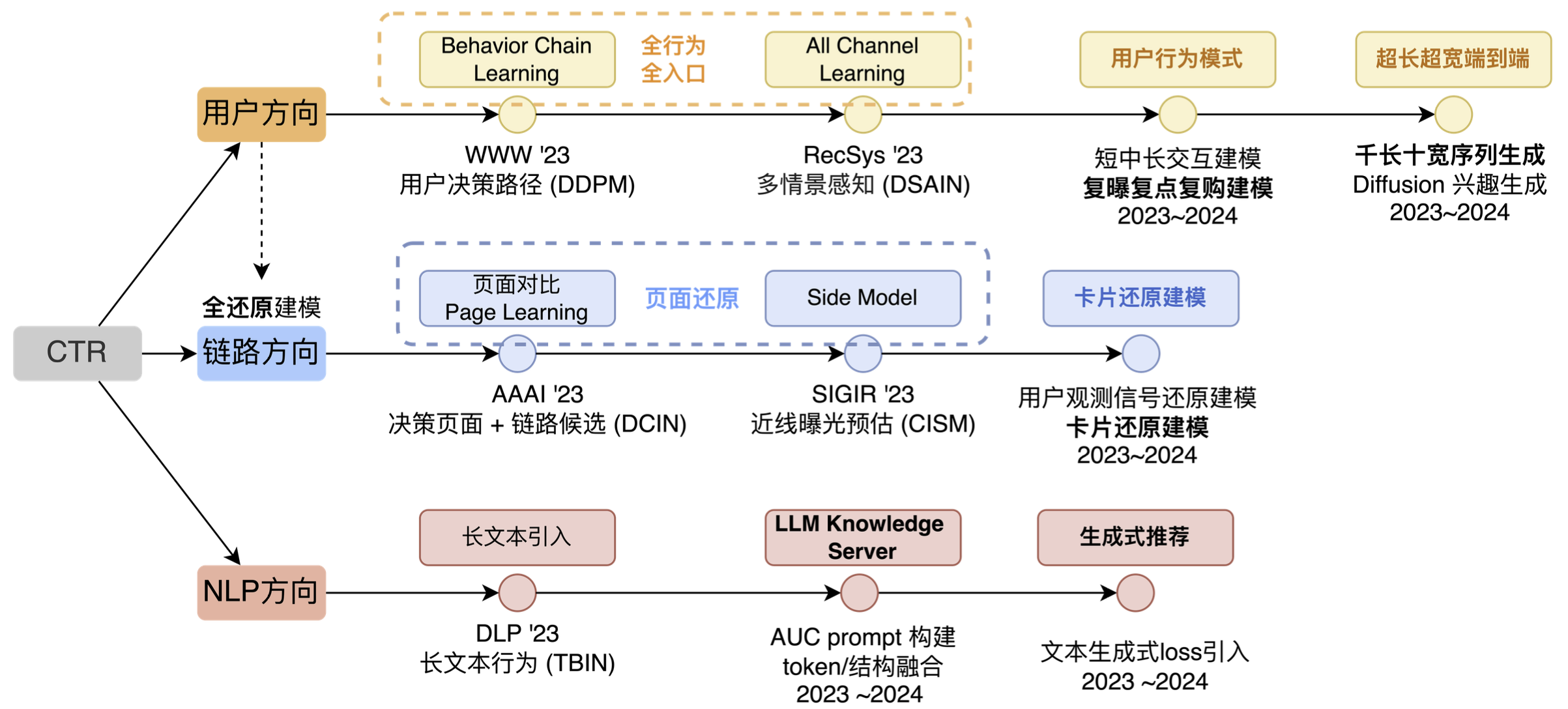
Há também uma direção multicena. Na verdade, já fizemos algumas iterações nessa direção antes e provocamos uma onda de efeitos, mas depois descobrimos que essa tecnologia é mais adequada para vincular várias cenas pequenas. Se a empresa que você atende tiver apenas 1 ou 2 cenários relativamente grandes e as diferenças nas necessidades dos usuários, nos formulários de exibição e na oferta de candidatos desses cenários não forem grandes, é improvável que você consiga exercer suas capacidades técnicas e sua função em esta direção.
Nossa ideia geral é desde a correspondência de elementos do usuário, correspondência de páginas, correspondência de caminhos e, finalmente, correspondência de interesses de longo prazo. Essencialmente, eles estão realizando um trabalho relacionado à correspondência de usuários em diferentes níveis. Entre eles, a correspondência de elementos e a correspondência de páginas se enquadram na direção do link. A razão é que a direção do link é mais para resolver "problemas invisíveis" e, em seguida, usar essas informações "vistas" para fazer a modelagem correspondente, então listamos a direção do link separadamente.
- Na direção do usuário, também passamos por aproximadamente três estágios. O primeiro estágio é expandir do ponto único original e comportamento de entrada única para comportamento completo e entrada completa. O segundo estágio é expandir a entrada existente. exploraremos mais padrões comportamentais; no terceiro estágio, faremos principalmente alguma extração automatizada de padrões, ou em outras palavras, a capacidade da rede de ajustar comportamentos automaticamente será mais forte.
- Na direção do link, nos concentramos principalmente em duas coisas: uma é a restauração da página e a outra é a restauração do cartão, usando algoritmos e recursos de engenharia para restaurar o que os usuários "vêem" nas decisões do modelo.
- Na direção da PNL, costumávamos ter outra direção chamada multimodalidade, mas objetivamente falando, com a popularidade do LLM, as tecnologias externas também nos dão mais informações, então listamos separadamente o LLM IN CTR como uma direção técnica importante.
2 A prática da publicidade com fluxo de informação em Meituan
2.1 Visão geral das ideias de modelagem de usuários
A direção geral do usuário é dividida em três direções reversas: a primeira é a linha do tempo, a segunda é a linha do espaço e a terceira é o padrão de comportamento sob a ação conjunta do tempo e do espaço. Quando o desmontamos, também nos referimos aos principais métodos iterativos na indústria e nos círculos acadêmicos, incluindo modelagem de sessão, modelagem de comportamento ultralongo, modelagem multicomportamento, modelagem de longo e curto prazo, etc. Com base na academia e na indústria, aliadas aos problemas e características dos negócios, para melhor integrar tecnologia e negócios, temos o seguinte detalhamento técnico.
No cronograma, acreditamos que a integração multinível de longo e curto prazo é mais importante. Por um lado, existem diferenças significativas no foco dos interesses dos usuários em diferentes níveis de “segmentos”, como comparação de tendências de páginas, interesses mais contínuos no caminho, usuários fazendo refeições leves por um período de tempo, etc. precisa dividir isso em diferentes níveis de segmentos. Extrair padrões de comportamento do usuário. Portanto, por um lado, combinamos curto e longo prazo através de mais páginas e caminhos, ao mesmo tempo, aumentamos o interesse de médio prazo em níveis diários e semanais, interagimos com curto prazo, médio prazo, e curto prazo para melhorar a conexão no comportamento da linha do tempo. Por outro lado, alguns métodos ponta a ponta são adicionados ao modelo para descobrir automaticamente padrões comportamentais. Esta é a questão chave que a linha do tempo aborda.
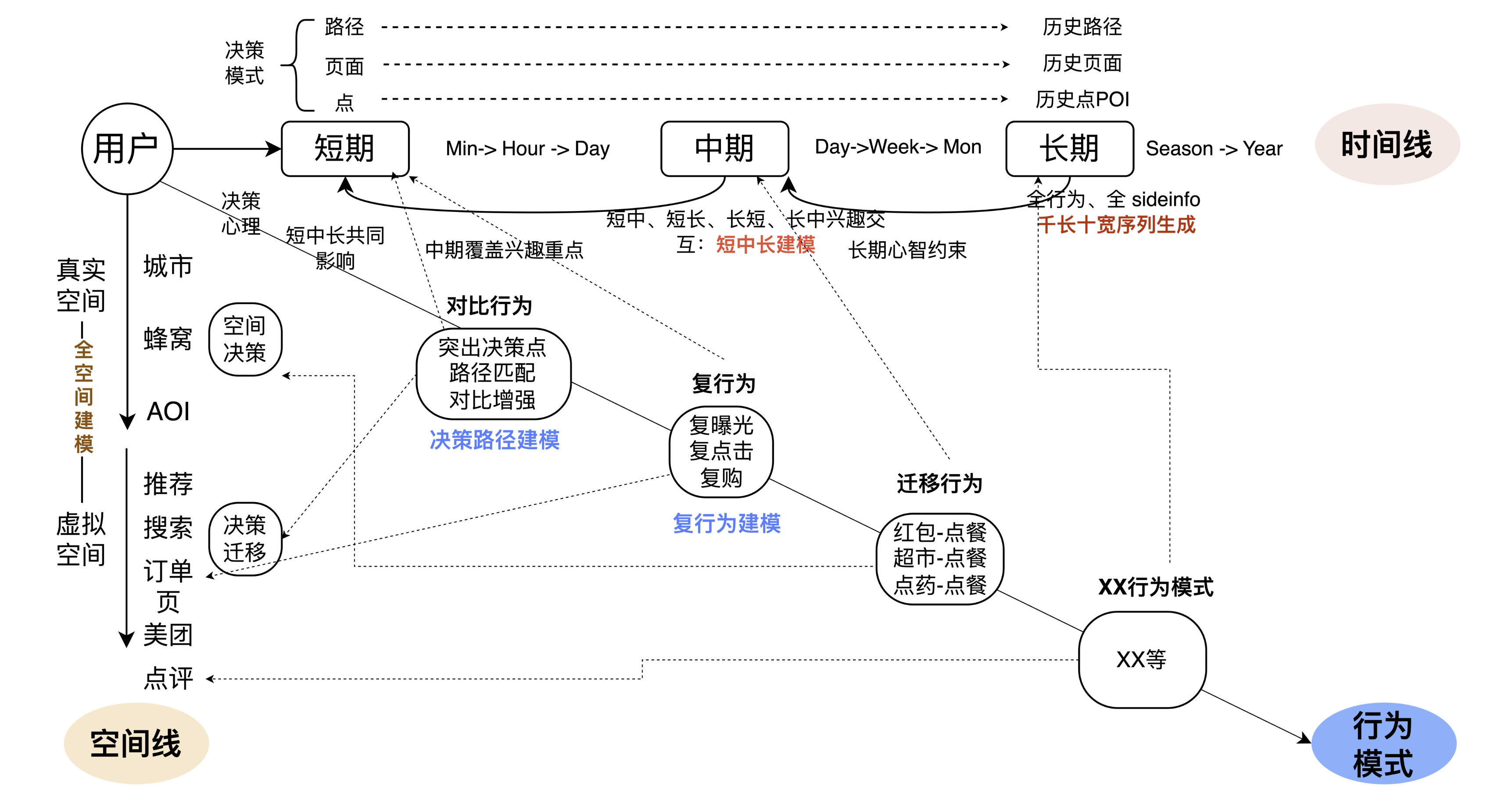
Na linha do espaço, na dimensão do espaço físico real, os problemas que enfrentamos são relativamente claros. Em diferentes locais, como quando vamos para o trabalho e quando estamos em casa, os interesses das pessoas não são exactamente os mesmos. espaço, todos nós recomendamos. No espaço virtual, por exemplo, quando os usuários usam entradas diferentes, como Meituan App e Dianping App, os interesses e intenções das pessoas também mudam muito. Um exemplo notável é que os usuários prestam atenção muito diferente às ofertas na página inicial e na entrada do membro. O problema resolvido pelas linhas espaciais é combinar o espaço real e o espaço virtual para determinar a verdadeira intenção ou padrão de comportamento do usuário.
A terceira linha é integrá-lo ao negócio. Por exemplo, se um usuário realizar alguma operação no App (receber um envelope vermelho), qual será o impacto desse comportamento no pedido de comida? Essencialmente, o modelo entende qual impacto o usuário terá no próximo comportamento após realizar algumas operações, para que o modelo possa aprender diferentes padrões de comportamento do usuário e prever melhor o comportamento do usuário. O texto acima é a ideia geral de nossa modelagem de usuário.
2.1.1 Modelagem do caminho de decisão
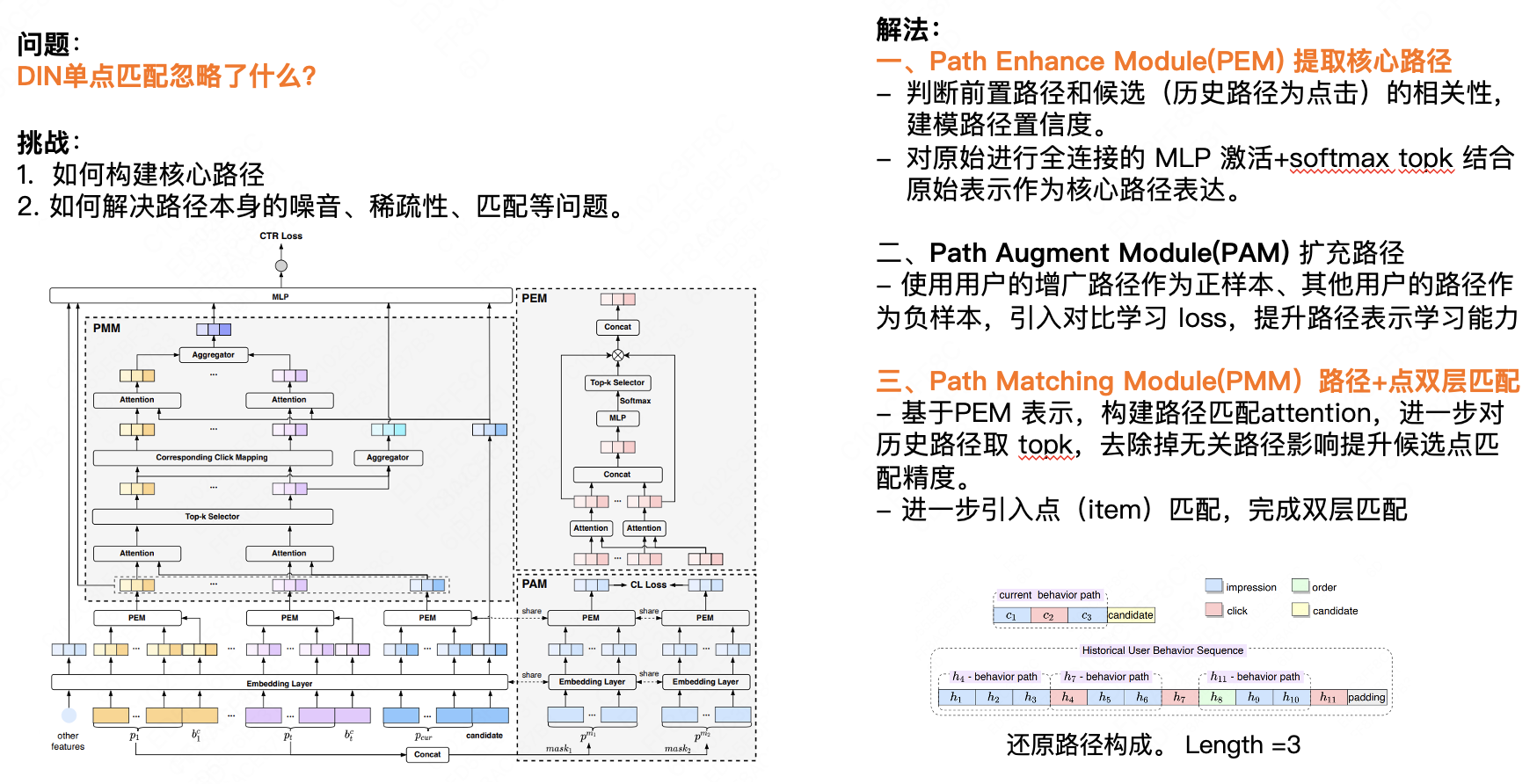
Esta seção apresentará a modelagem do caminho de decisão. A primeira questão central é: o que a correspondência de ponto único DIN ignora? Acreditamos que a correspondência de ponto único ignora o impacto do comportamento anterior no comportamento subsequente do usuário. Para a maioria das empresas de comércio eletrônico, o comportamento dos usuários durante um período de tempo tem um certo grau de consistência. Podemos prever o próximo comportamento com base nos dados históricos de comportamento do usuário. Existem dois desafios aqui: primeiro, como construir o caminho principal; segundo, como resolver o ruído, a dispersão, a correspondência e outros problemas do próprio caminho. Nossa solução tem principalmente três pontos:
Primeiro, o Path Enhance Module (PEM) extrai o caminho principal.
- Determine a correlação entre o caminho anterior e o candidato (o caminho histórico é o clique) e modele a confiança do caminho.
- A ativação MLP totalmente conectada original + Softmax Top K é combinada com a representação original como a expressão do caminho principal.
Em segundo lugar, o Path Augment Module (PAM) expande o caminho.
- Usando o caminho aumentado do usuário como uma amostra positiva e os caminhos de outros usuários como amostras negativas, a perda de aprendizagem comparativa é introduzida para melhorar as capacidades de aprendizagem de representação de caminho.
Terceiro, caminho do Path Matching Module (PMM) + correspondência de camada dupla de ponto.
- Com base na representação PEM, a atenção de correspondência de caminho é construída e os K principais de caminhos históricos são selecionados para remover a influência de caminhos irrelevantes e melhorar a precisão de correspondência de pontos candidatos.
- Introduza ainda a correspondência de pontos (item) para completar a correspondência de camada dupla.
2.1.2 Modelagem do comportamento do usuário para ultralongos e ultralargos
Acredito que muitos estudantes sabem que a modelagem ultralonga é basicamente implementada por meio de tecnologias aproximadas, como clustering e hashing local. A introdução da modelagem ultra-ampla ocorre essencialmente porque precisamos reunir todas as entradas, portanto, é necessário um modelo maior e mais complexo para lidar com as coisas. No entanto, na prática, não percebemos isso totalmente porque o poder computacional atual não consegue suportá-lo. Fizemos um acordo. O comprimento está no nível de 1000 (Comprimento) e a largura está atualmente no nível de 10+. Off-line pode suportar escalas maiores e o efeito foi bastante melhorado para o nível de 10.000, mas. a eficiência da iteração, online A pressão será bastante limitada.
Aqui também nos deparamos com duas questões: A primeira questão é por que o SIM/ETA não traz resultados? Essa direção foi proposta pela primeira vez por plataformas de comércio eletrônico. O SIM usa principalmente filtragem rígida. Por exemplo, quando os usuários navegam por comportamentos relacionados a calçados no site, eles também analisam várias outras coisas. para sapatos. Produtos relacionados a "sapatos" podem ser filtrados, ruídos não relacionados a sapatos podem ser filtrados e as preferências de calçados do usuário podem ser aprendidas. Pedir comida para viagem é relativamente diferente para um candidato a hambúrguer, filtrar comportamentos não relacionados ao hambúrguer por meio da categoria hambúrguer perderá mais informações sobre o gosto do usuário. Isso é provocado por diferenças comerciais.
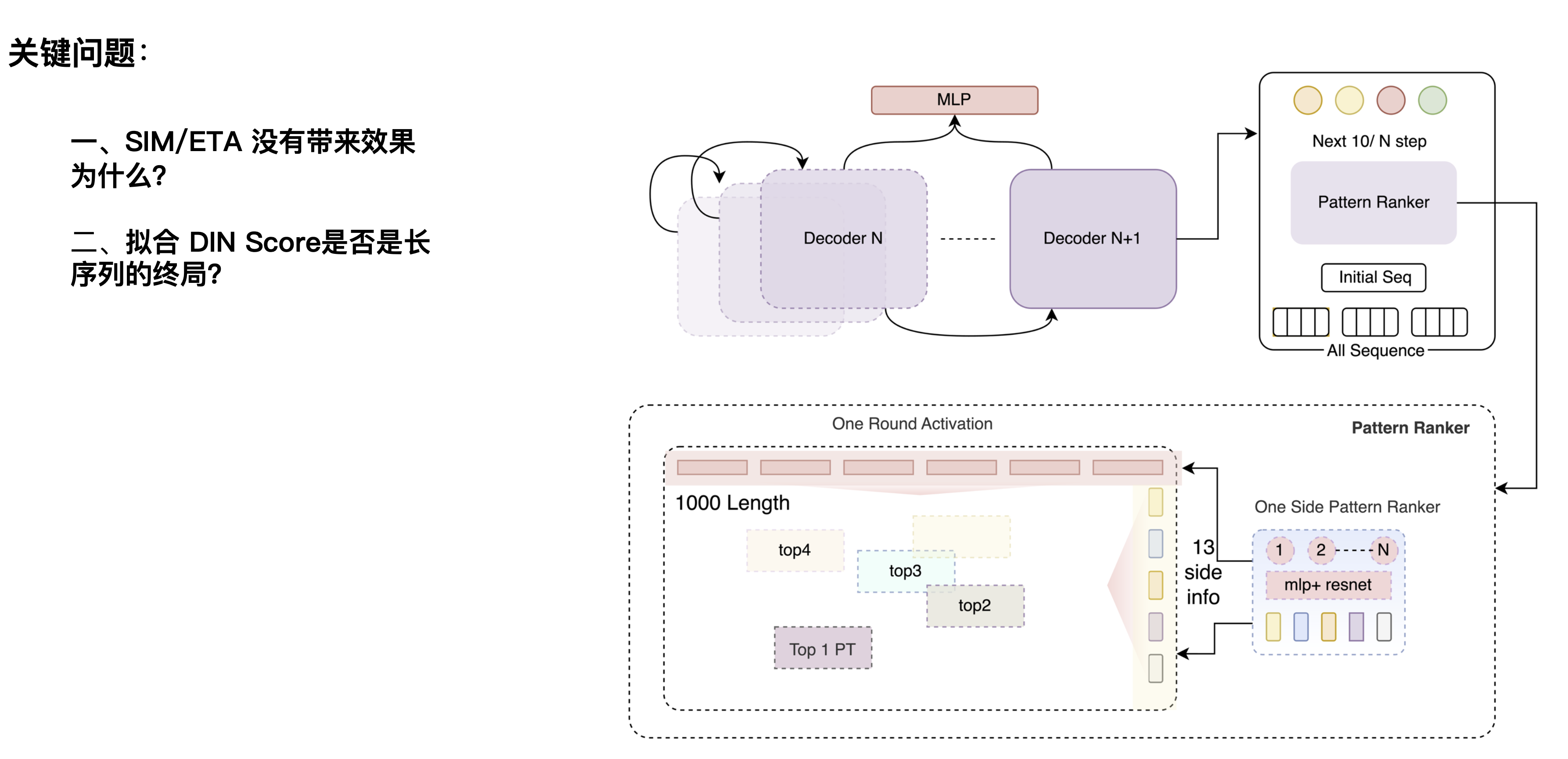
A segunda questão é: ajustar o DIN Score é o fim do jogo para sequências longas? Houve um artigo anterior na indústria que acreditava que a pontuação DIN é a referência. A expansão linear pode trazer efeitos, e uma expansão adicional para o nível 10.000 ou 100.000 pode maximizar o efeito. Porém, por meio de experimentos, a expansão linear de nossa cena CTR para o nível ultralongo não continuou a trazer efeitos, mas diminuiu após um certo período. Acreditamos que a capacidade de eliminação de ruído da rede DIN em si não é muito forte, ou que a sua capacidade estrutural para extrair resultados de Label não é suficientemente forte. Se não for uma rede particularmente forte, a informação que pode acomodar será relativamente limitada quando for expandida.
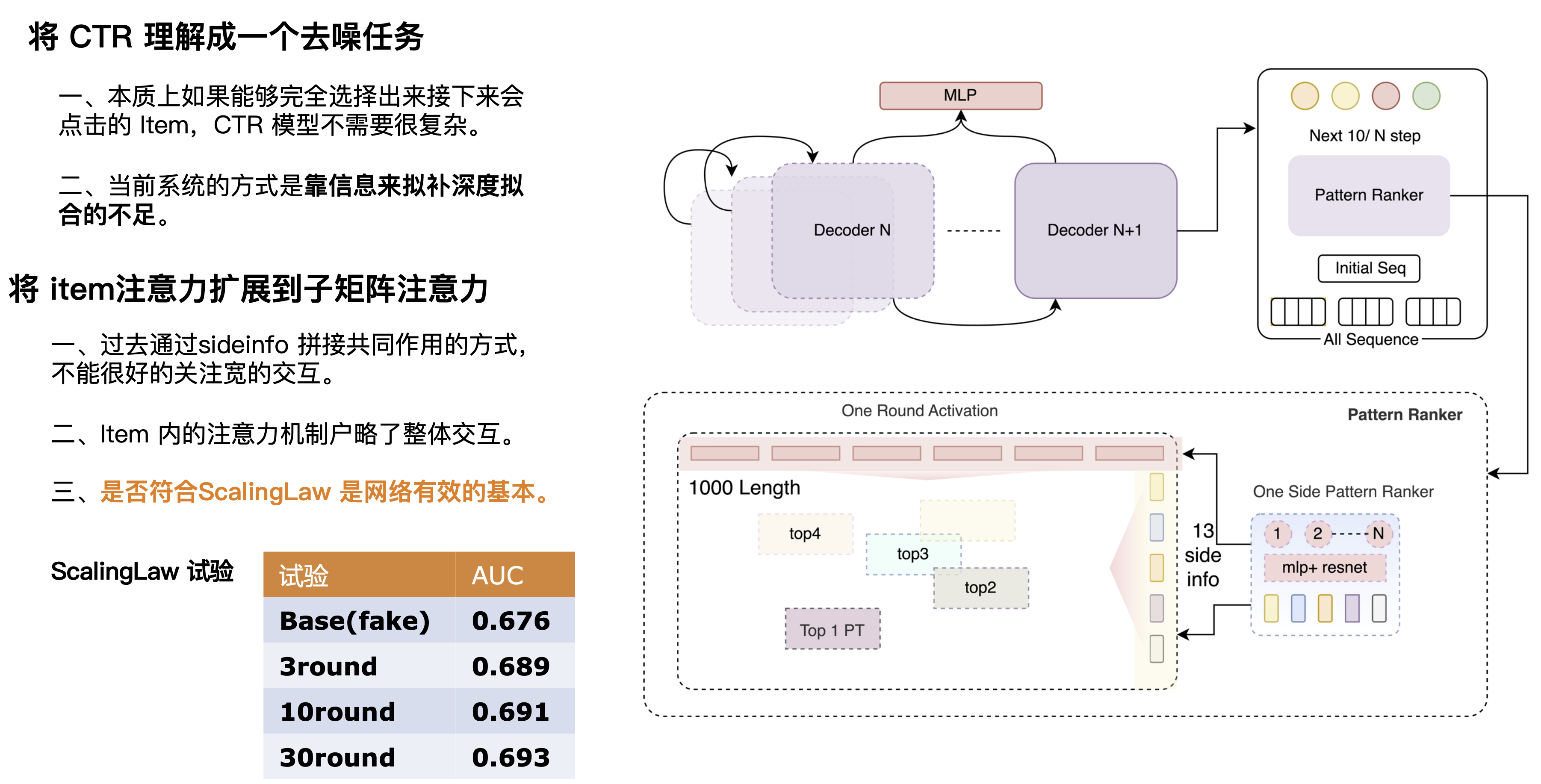
Podemos entender o CTR como uma tarefa de eliminação de ruído, que é essencialmente o processo de combinar usuários e candidatos com base no histórico do usuário e nos cenários atuais. Descobrimos que se pudermos prever com precisão ou remover todo o ruído, como combinar as informações de cruzamento do rótulo POI com o alvo, também poderemos ter uma AUC alta usando uma rede simples. Portanto, acreditamos que a rede CTR perfeita deve ser uma combinação de rede de previsão forte + rede de correspondência fraca. A rede de predição deve ser uma rede muito poderosa que pode sobrepor múltiplas camadas para extrair informações e obter um resultado de predição mais preciso para corresponder ao alvo. Portanto, projetamos um decodificador multicamadas, e cada camada do decodificador pode integrar informações. Ao selecionar continuamente matrizes eficazes e sobrepor repetidamente informações eficazes, podemos tornar as informações mais precisas. Aqui conduzimos um conjunto de experimentos de Lei de Escala para verificar a eficácia dos resultados através da sobreposição de múltiplas rodadas de redes. Pode-se observar que à medida que o número de rodadas aumenta, a capacidade da rede de aprender o comportamento do usuário (a AUC aumenta camada por camada) também aumenta.
2.2 Modelagem de restauração completa
Em primeiro lugar, o que é modelagem de redução total? Uma definição que damos é restaurar o que o usuário vê. A tarefa do CTR é determinar se o usuário clica com base nas informações que o usuário vê. O ponto mais importante é incorporar todas as informações vistas no modelo. No passado, a simples modelagem por meio da representação do ID ignorava o contexto e exibia as informações. trouxe maior lacuna de informação.
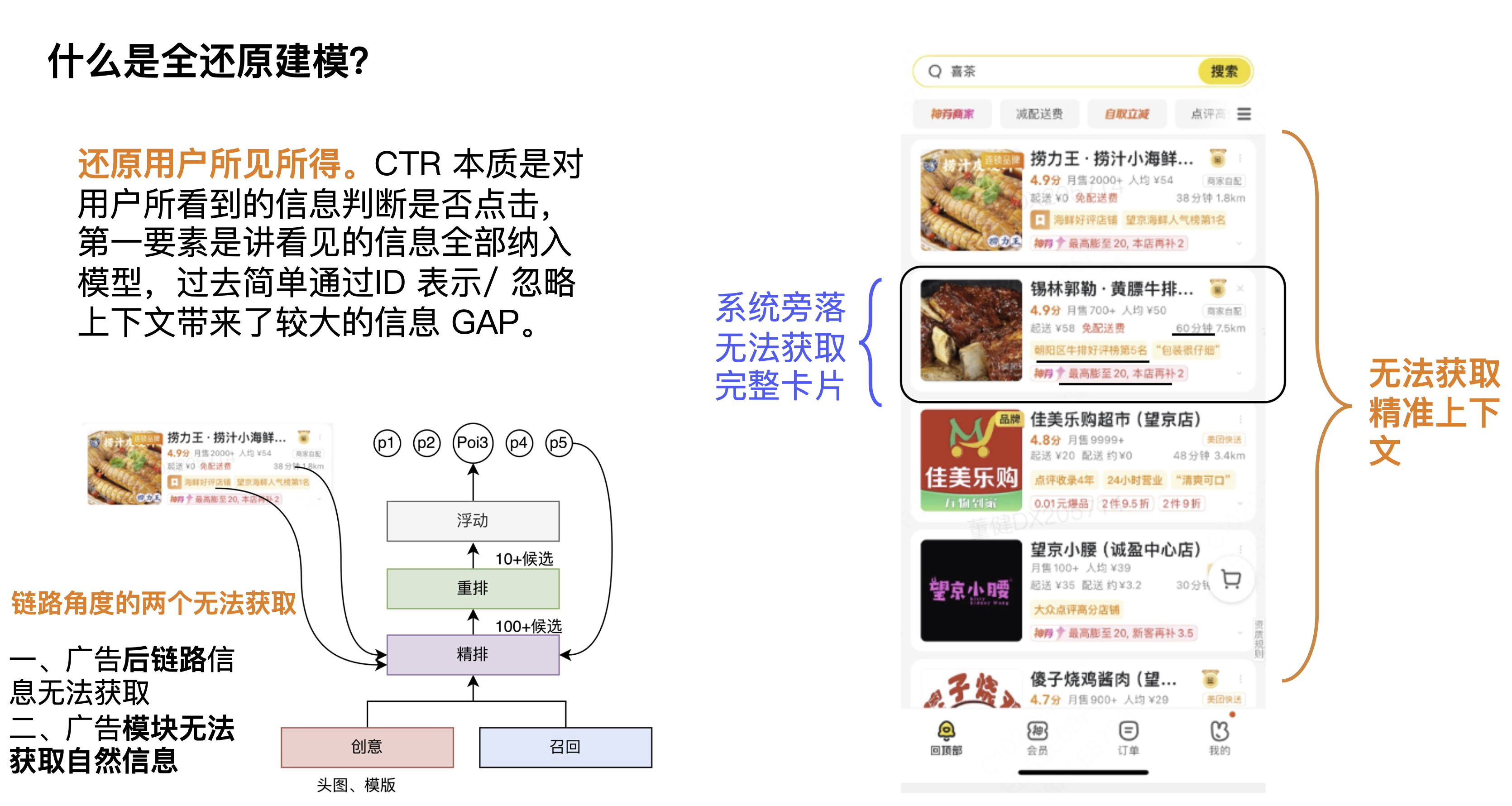
Na primeira perspectiva, os cartões de contexto não estão disponíveis. As informações contextuais são muito importantes para o CTR do candidato atual e do cartão atual. Alguns alunos podem pensar que o rearranjo pode resolver este problema, mas sempre acreditamos que as informações de contexto pertencem às informações de link. Acreditamos que cada módulo precisa aprender informações de contexto. É claro que cada módulo pode ter um foco de aprendizagem diferente e, de fato, pode trazer. certos efeitos. A segunda perspectiva é do ponto de vista do poder computacional Como o poder computacional no lado da estimativa é relativamente alto, o escopo de seu impacto será maior e pode realmente trazer mais espaço de efeito.
Olhando a imagem do canto inferior esquerdo, na perspectiva do link, existem dois módulos que não podem ser obtidos, nomeadamente o módulo de estimativa e o módulo de publicidade. A primeira é que as informações do backlink do anúncio não podem ser obtidas, o que inclui as informações de entrega exibidas, taxas de entrega, informações precisas sobre descontos, etc.; a segunda é que as informações naturais não podem ser obtidas, o que inclui o contexto natural; Portanto, a restauração de outra perspectiva é como quebrar as restrições do link e usar informações de travessia.
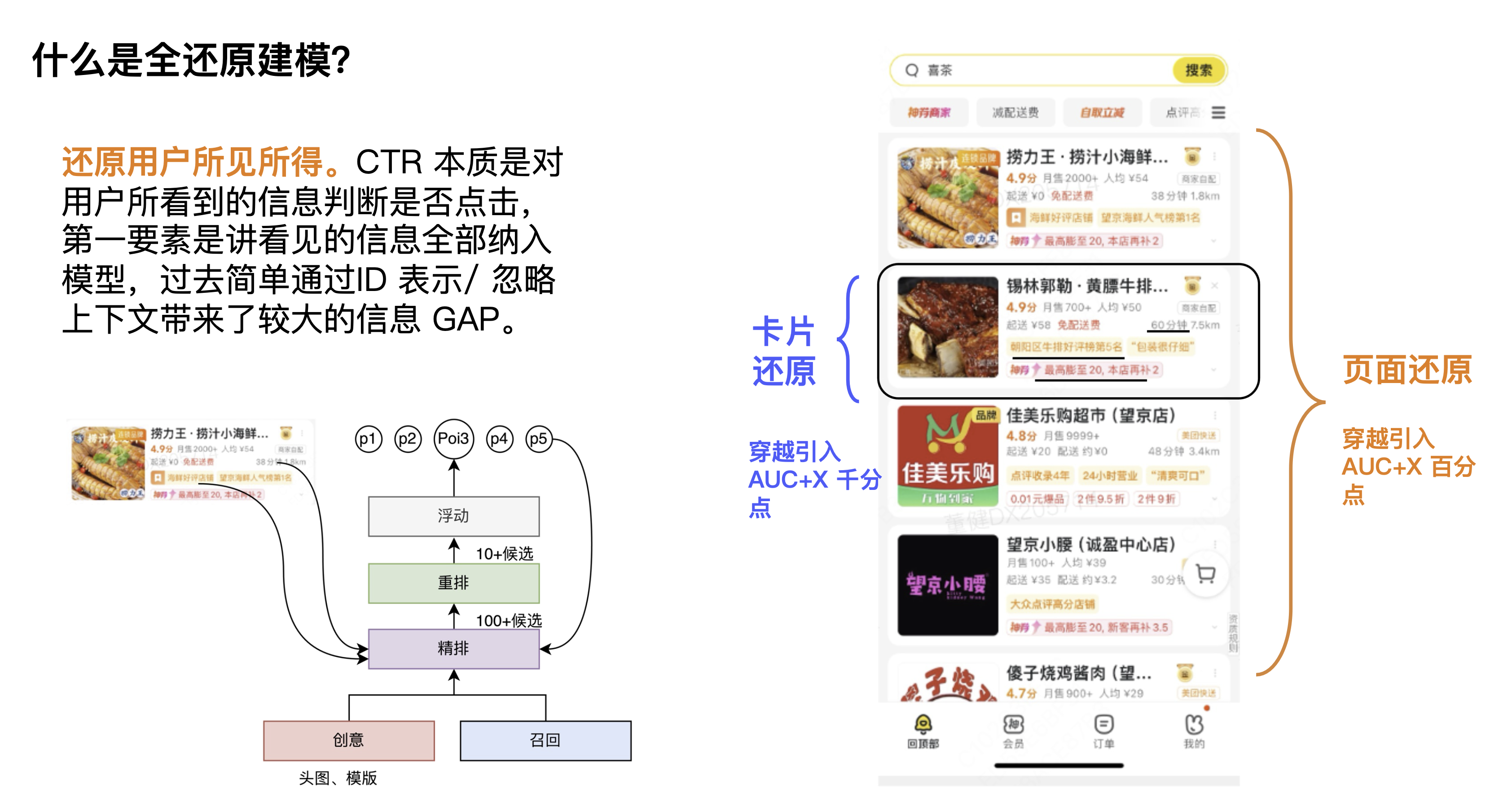
Esses são alguns dos problemas enfrentados pela modelagem de restauração completa, que na verdade podem ser resumidos em duas direções: uma é a restauração do cartão e a outra é a restauração da página. No início, fizemos um julgamento de espaço. Colocamos as informações do cartão e da página completamente e observamos o aumento da AUC para julgar o espaço geral. Os resultados mostraram que as informações da página estavam no nível do percentil e as informações do cartão. foi vários milésimos de ponto mais alto.
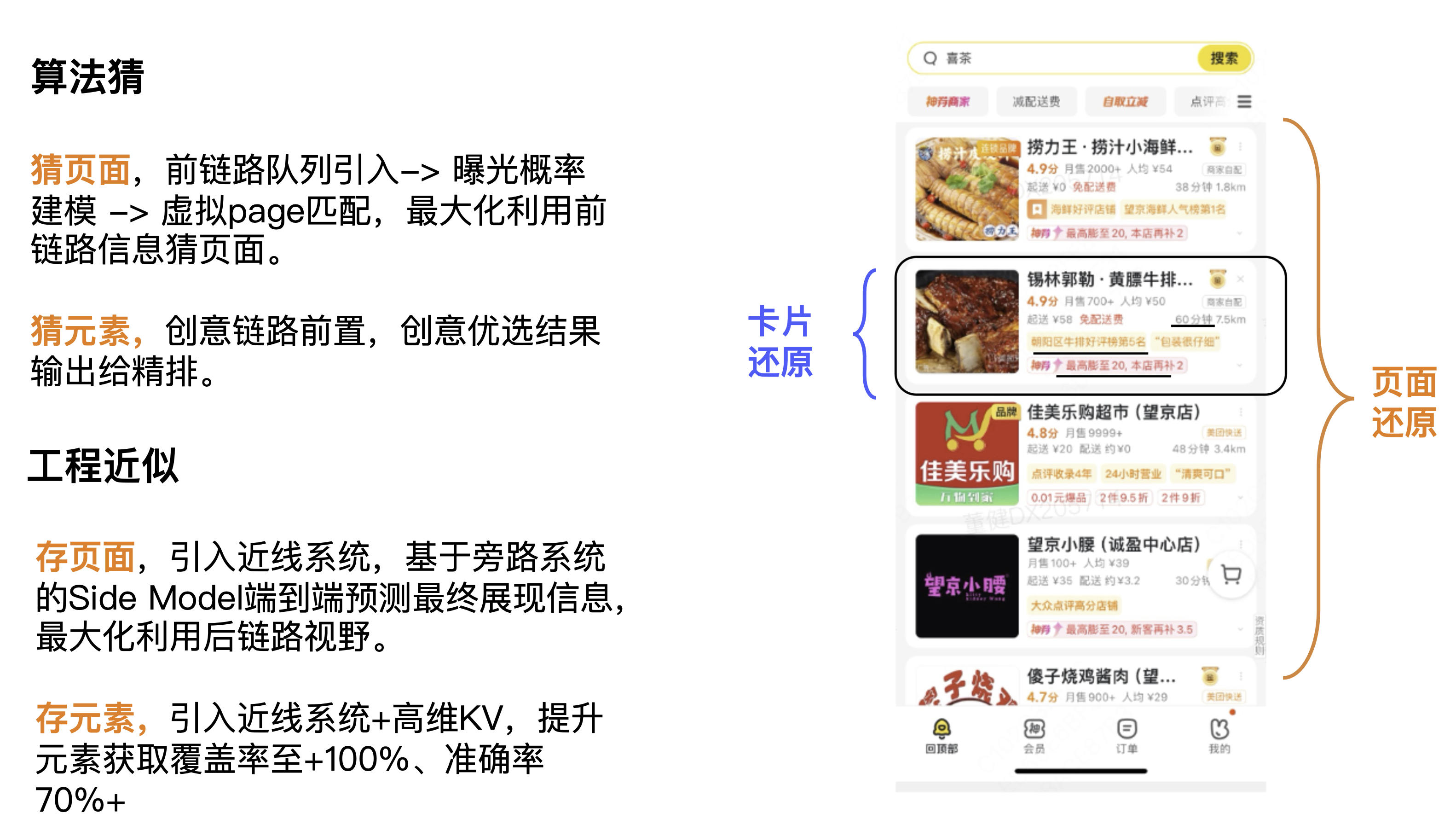
Ideia geral de solução
Expanda restauração de página e restauração de cartão aqui. Em primeiro lugar, em termos de pensamento, resolvemos principalmente a partir de duas dimensões: algoritmo e engenharia. No nível do algoritmo, o primeiro é adivinhar a página, maximizando o uso das informações do link anterior para adivinhar a página; o segundo é adivinhar o elemento, com o link do criativo na frente, e os resultados da otimização do criativo são enviados; boa classificação. No nível de engenharia, o primeiro é salvar páginas, introduzir um sistema quase linear e usar a previsão ponta a ponta do modelo lateral com base no sistema de desvio para finalmente exibir informações e maximizar o uso da visão de back-link. A segunda é armazenar elementos, que introduz sistema near-line + KV de alta dimensão para aumentar a cobertura de aquisição de elementos para +100% e a precisão para 70%+.
Conforme mencionado anteriormente, as informações contextuais têm um impacto maior no clique final. Como o módulo CTR não consegue obter o contexto, a solução anterior era introduzir o rearranjo para modelar uma fila de pequena escala, o que reduzia o impacto das informações contextuais do link. A seguir, o desafio que enfrentamos é:
- O contexto inclui duas partes: conjunto e sequência. Como construir um módulo de previsão de contexto?
- Como interagem os contextos simulados e os candidatos?
- Como melhorar ainda mais a precisão da página simulada por meio da destilação?
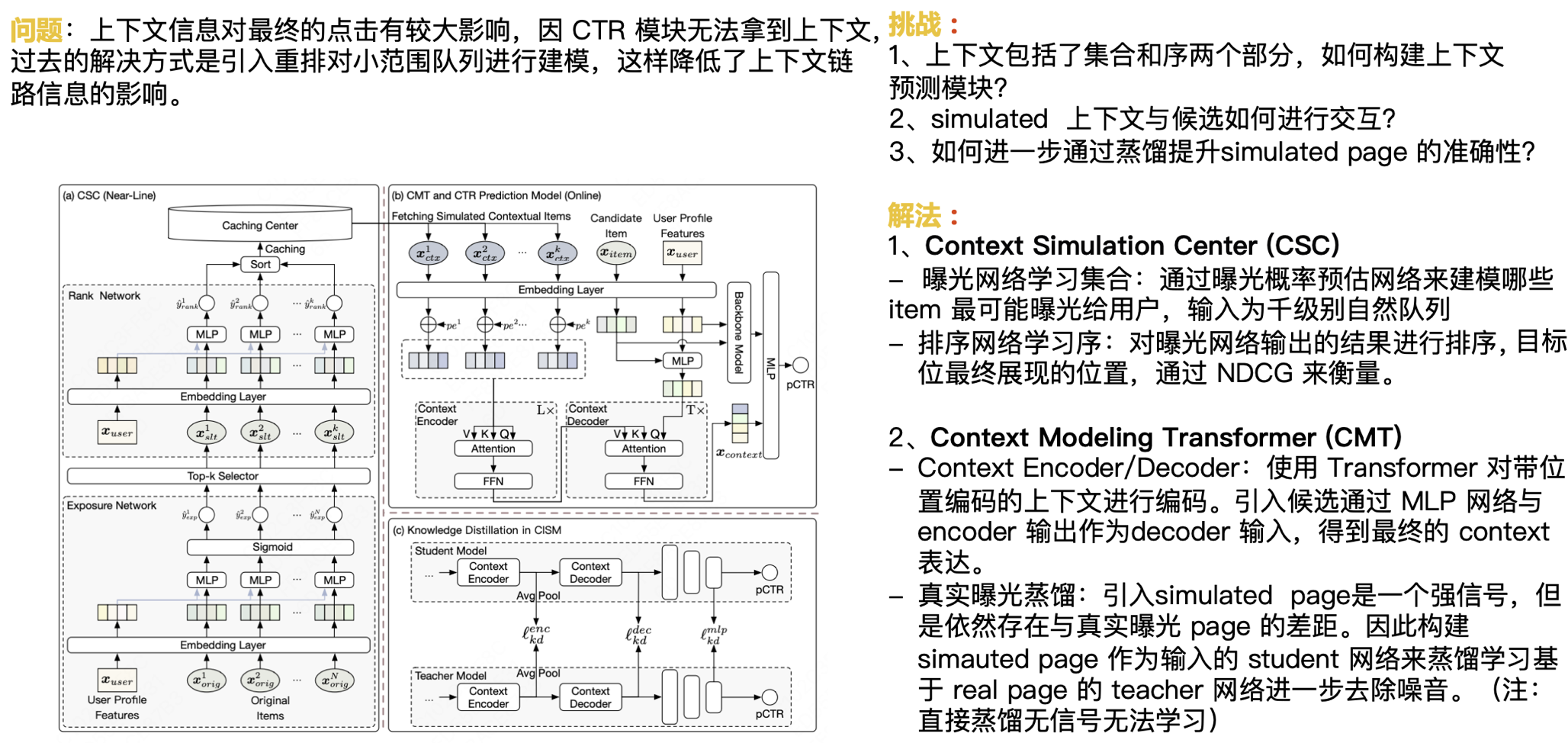
Nossa solução é:
Centro de Simulação de Contexto (CSC)
- Conjunto de aprendizagem da rede de exposição: Use a rede de estimativa de probabilidade de exposição para modelar quais itens têm maior probabilidade de serem expostos aos usuários, e a entrada é uma fila natural de mil níveis.
- Sequência de aprendizagem da rede de classificação: Classifique os resultados produzidos pela rede de exposição e a posição final da posição alvo é medida pelo NDCG.
Transformador de Modelagem de Contexto (CMT)
- Codificador/Decodificador de Contexto: Use o Transformer para codificar o contexto com codificação posicional. O candidato é introduzido através da rede MLP e a saída do Encoder é usada como entrada do Decodificador para obter a expressão de Contexto final.
- Destilação da exposição real: A introdução da página simulada é um sinal forte, mas ainda há uma lacuna em relação à página de exposição real. Portanto, a rede do Aluno com Página Simulada como entrada é construída para destilar e aprender a rede do Professor com base na Página Real para remover ainda mais o ruído. (Nota: a destilação direta não tem sinal e não pode ser aprendida)
Introduzimos estratégias de configuração de cache e previsão, juntamente com destilação real, para nos ajudar a melhorar ainda mais o efeito, que faz parte da restauração da página.
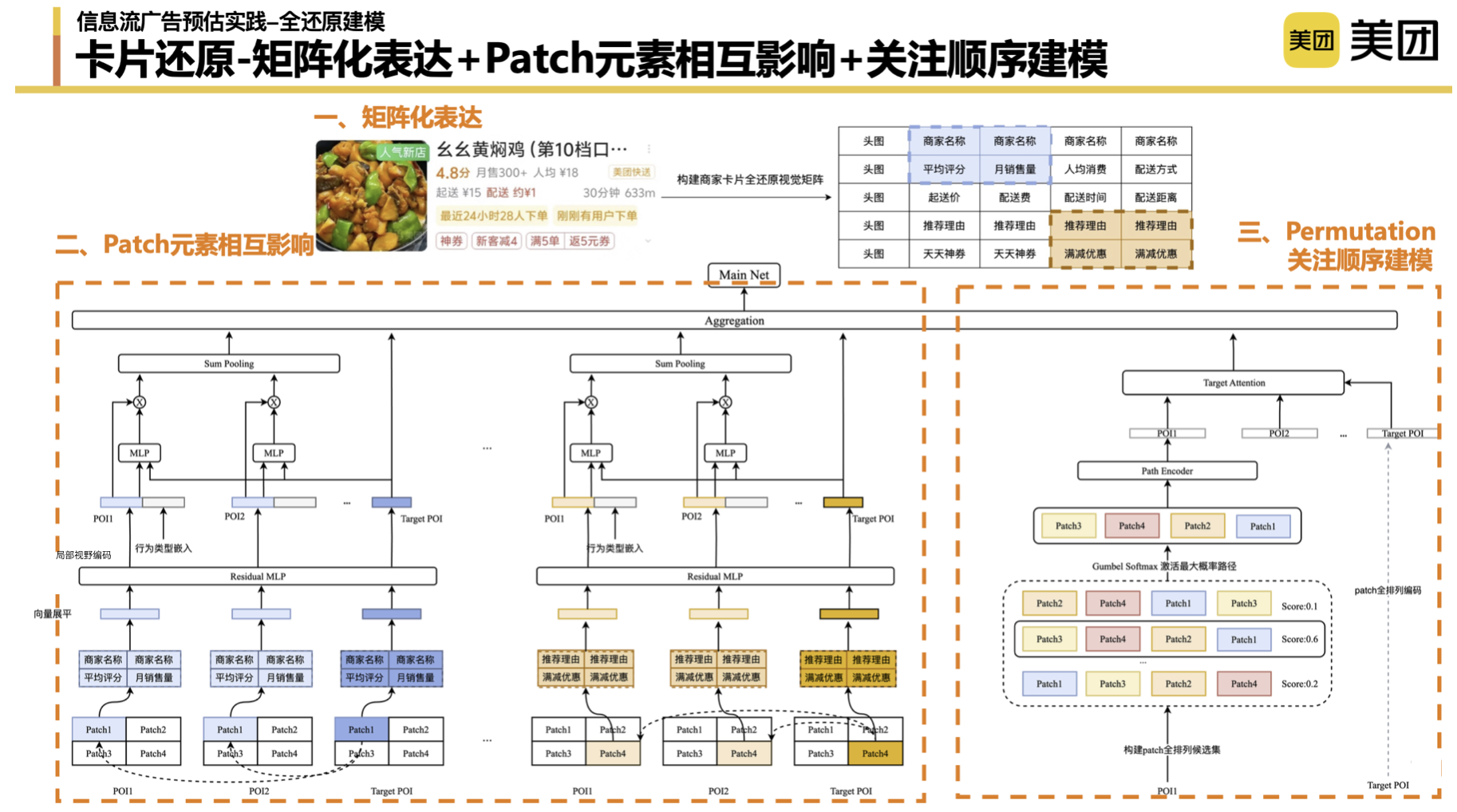
A ideia geral da restauração do cartão é dividida em três partes: a primeira parte é obter as informações do cartão, a segunda parte é formar os cartões que o usuário vê;
Pensando no plano do cartão : Devido aos módulos seriais e paralelos do sistema de busca e promoção, não conseguimos obter alguns dados. Na fase inicial, estivemos pensando se existe um “plano final”. No início, usávamos puro tiling (pure ID) para restaurar as informações vistas pelos usuários, mas existe uma maneira melhor? Por exemplo, apresente diretamente as imagens que os usuários veem. No entanto, as capacidades técnicas atuais não suportam a gravação completa de toda a imagem, muito menos a expressão de modelagem completa e precisa das informações da imagem. Ao final, optamos por compor os cartões através de uma matriz para simular as informações que o usuário vê.
Expressão matricial, modelagem em nível de patch : Primeiro, usamos a expressão matricial para formar a forma do cartão e construir a relação entre os elementos superiores e inferiores que o usuário vê e ganha. Ao nível da apresentação, diferentes métodos de construção de matrizes terão um certo impacto nos resultados, e os detalhes não serão discutidos aqui. No segundo aspecto, também pegamos emprestadas algumas ideias do campo da imagem e introduzimos o conceito de Patch para nos ajudar a transformar imagens em Tokens e aprender ainda mais a interação entre os diferentes elementos de exibição. No processo de prática, também precisamos ajustar alguns parâmetros, como se o patch é 2*2 ou 3*3. Incluindo a passada, descobrimos que quanto mais curta for a passada, melhor será o efeito. Também conduzimos muitos experimentos durante todo o processo de correspondência em nível de patch. Nossa conclusão preliminar é que o efeito final da correspondência de patches de posição única e patches globais é melhor.
Modelagem de sequência de atenção : a modelagem de sequência simula ainda mais a sequência de navegação do usuário com base em quais elementos o usuário presta atenção. Logicamente falando, não podemos realmente obter esta parte dos dados sem monitorização ocular. Aqui, fizemos um pequeno truque para organizar completamente as matrizes desses quatro patches, listar todos os caminhos do usuário no nível do patch e deixar o modelo aprender as pontuações implícitas de diferentes permutações e combinações. A combinação de ordem de patch com a pontuação de ativação mais alta é agregada em uma expressão de ordem de atenção por meio do codificador para corresponder ainda mais à combinação de ordem de atenção do POI do Target.
2.3 LLM em CTR
Por fim, compartilhe a aplicação de grandes modelos em CTR. Fizemos algumas pesquisas preliminares e descobrimos que muitas equipes técnicas atualmente têm ideias gerais semelhantes. A figura abaixo mostra a comparação entre tarefas de CTR e tarefas de PNL. Você pode ver que há grandes diferenças desde a entrada até a arquitetura do modelo, até o modo de aprendizagem e o modo de tarefa. A tarefa da PNL é token de linguagem natural + transformador em grande escala + capacidade de compreensão e raciocínio. A tarefa CTR é entrada de ID + rede projetada artificialmente + forte capacidade de memória. Ao mesmo tempo, para o CTR, a maioria das empresas utiliza apenas os seus próprios dados de negócio, carecendo de conhecimento externo e compreensão completa da tarefa.
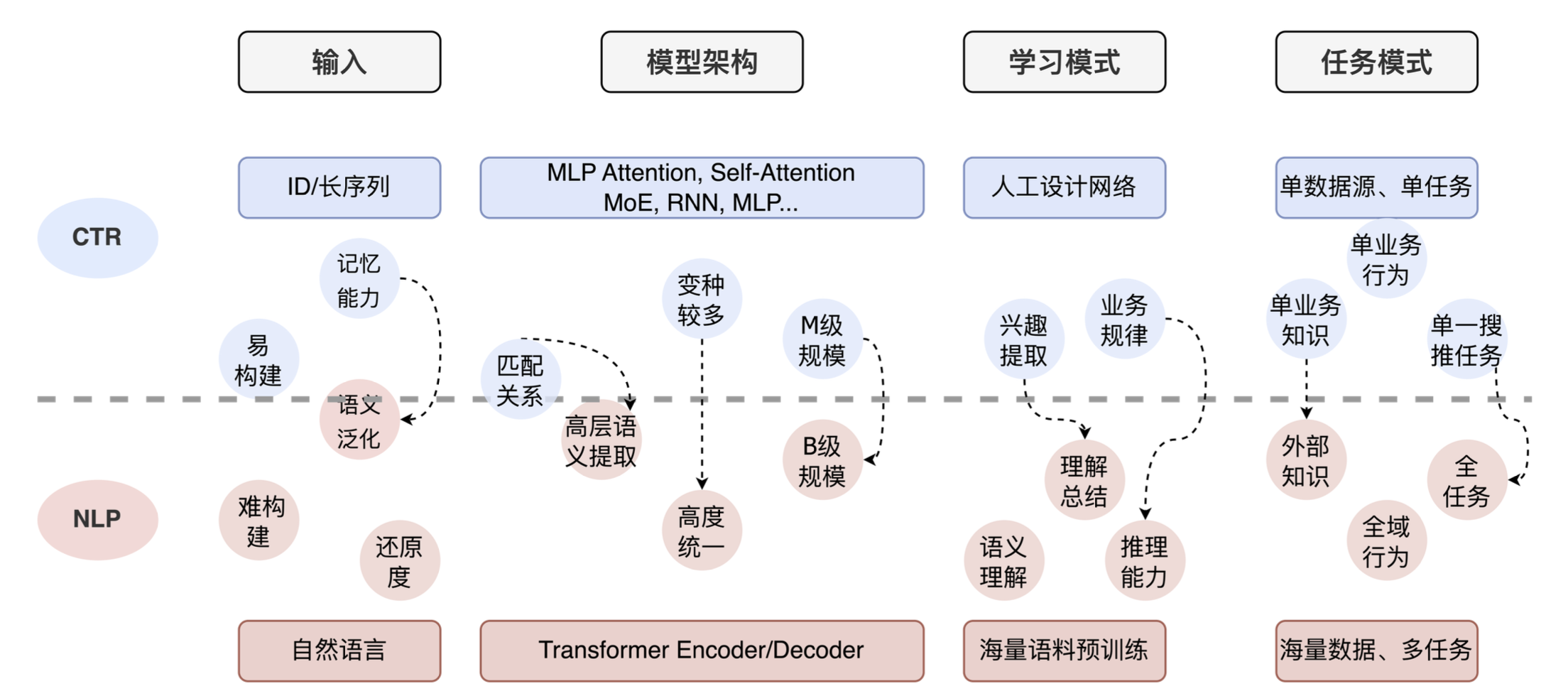
Portanto, com base nos aspectos acima, realizamos três aspectos do trabalho:
- O primeiro nível, injeção de conhecimento, é colocar no modelo o conhecimento externo e real que falta ao CTR atual. Muitas empresas estão fazendo esta parte do trabalho, e isso requer principalmente capacidades de engenharia imediata. Como os resultados gerados não são necessariamente os que o CTR necessita, precisamos fazer um bom trabalho de adaptação. De acordo com as características do CTR, palavras de alta frequência e palavras de baixa frequência podem ser distinguidas. Ao mesmo tempo, também é necessário algum trabalho de pós-processamento relacionado à fusão imediata para melhorar a correspondência com as tarefas de CTR.
- O segundo nível, injeção de pensamento, é introduzir as capacidades estruturais do grande modelo ou introduzir o processo de julgamento do grande modelo.
- A terceira camada é a iteração de paradigma. Recentemente, Meta parece apontar um caminho para recomendações generativas. Quando exploramos essa direção no ano passado, nossa ideia principal era mudar o formulário de entrada e substituí-lo por um token de menor escala, provavelmente com apenas dezenas de milhares de tamanho, para resolver o problema Softmax em grande escala. Então, por meio da superposição Transform, combinada com a semântica de agregação, desde a fusão do modelo até a autorregressão ponta a ponta, os dados podem ser analisados. Descobrimos que se a entrada for particularmente barulhenta, o Transformer não consegue lidar com isso muito bem, mas para informações com semântica relativamente clara, o Transformer tem um bom desempenho na compreensão contextual, então primeiro criamos uma camada de agregação semântica para reduzir o ruído da sequência de entrada. . Em geral, através de tokens de pequena escala, agregação semântica e arquitetura Transformer, trouxemos uma onda de melhorias nos efeitos comerciais.
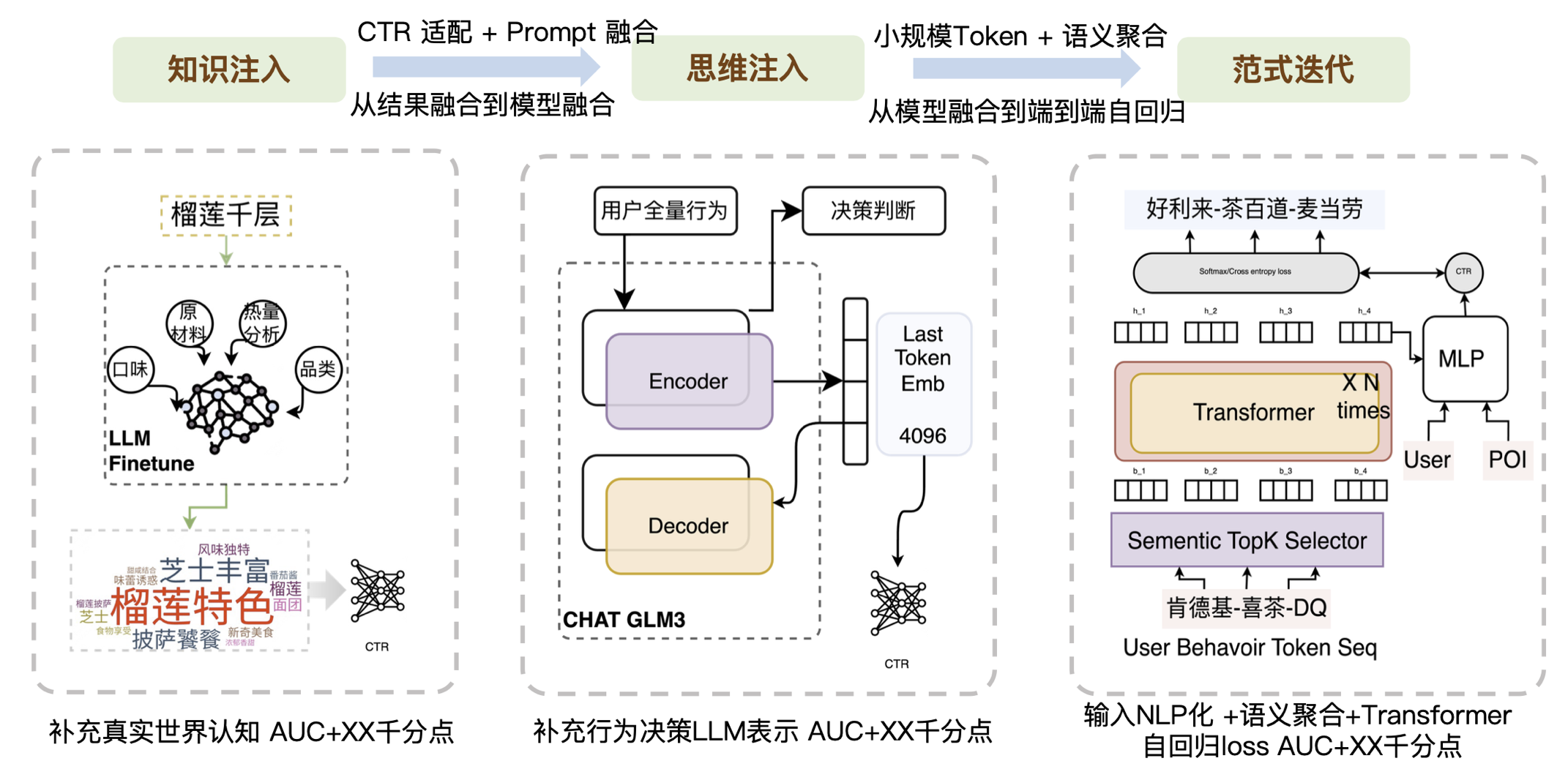
Resumindo, a essência é compensar as capacidades que o CTR não possui por meio de modelos grandes. Dividimos as habilidades que o CTR atualmente não possui em habilidades de conhecimento, habilidades de generalização e habilidades de raciocínio. Da mesma forma, também listamos alguns dos resultados que tentamos, conforme mostrado na figura abaixo:

03 Resumo e Perspectivas
Em geral, a essência da estimativa é descobrir as reais necessidades dos usuários. Por um lado, nos referimos à indústria e, por outro lado, nos aprofundamos no negócio para descobrir mais padrões de comportamento dos usuários. explorar se existe uma maneira mais automatizada de combinar vários aspectos. Os problemas do usuário são resolvidos. A modelagem restaurativa é uma melhoria trazida pelos esforços conjuntos de algoritmos e engenharia. Em última análise, a combinação de algoritmo e engenharia pode trazer mudanças maiores.
A combinação de grandes modelos e recomendações está recebendo cada vez mais atenção de todos, mas falando objetivamente, este ainda é um trabalho de longo prazo. Neste momento, ainda precisamos encontrar um caminho viável e continuar a otimizar e melhorar. espere usar um Será muito difícil resolver todos os problemas com "grande movimento". A recomendação ponta a ponta de grandes modelos é a expectativa comum de todos, mas com base nisso, acreditamos que a escala de entrada é a garantia do efeito, e o poder computacional é a garantia dos dois acima. Somente a poderosa combinação de software e hardware pode conquistar o futuro.
| Palavras-chave de resposta como [produtos de ano novo de 2023], [produtos de ano novo de 2022], [produtos de ano novo de 2021], [produtos de ano novo de 2020], [produtos de ano novo de 2019], [produtos de ano novo de 2018], [produtos novos de 2017 Produtos do ano] e outras palavras-chave na caixa de diálogo da barra de menu da conta oficial da Meituan Confira a coleção de artigos técnicos da equipe técnica da Meituan ao longo dos anos.

| Este artigo foi produzido pela equipe técnica da Meituan e os direitos autorais pertencem à Meituan. Você está convidado a reimprimir ou usar o conteúdo deste artigo para fins não comerciais, como compartilhamento e comunicação. Indique "O conteúdo é reproduzido pela equipe técnica da Meituan" . Este artigo não pode ser reproduzido ou usado comercialmente sem permissão. Para quaisquer atividades comerciais, envie um e-mail para [email protected] para solicitar autorização.
Está se tornando cada vez mais intratável, e os relatórios diários e semanais detalhados estão dificultando as coisas para os touros e cavalos de TI! Como quebrar a situação? A AMD abriu o código-fonte de seu primeiro modelo de linguagem pequena AMD-135M no Dia Nacional. Voltei para minha cidade natal em Anhui, mas como faço para acessar a rede da empresa de Hangzhou? A versão nativa de Hongmeng iniciou um teste limitado de exclusão de arquivos. A Bolsa de Valores de Xangai testou o sistema de negociação de licitações hoje e recebeu 270 milhões de pedidos: O desempenho geral é normal, 2 vezes o pico histórico A Apple pode lançar seu primeiro display inteligente e sistema operacional com suporte para homeOS FFmpeg 7.1 em 2025. "Péter" lança Zhipu. AI e anuncia o menor desconto de 10% em todos os modelos Open Source Daily | Rust faz com que as vulnerabilidades do Android diminuam significativamente; OpenAI planeja aumentar as taxas de assinatura do ChatGPT; Quem está no controle do OpenAI agora? Redis 7.4.1 lançado