InnoDB две категории индекса
-
Кластерный индекс (кластерный индекс)
-
Общий индекс (вторичный индекс)
Лист узел хранит строки InnoDB кластерного индекс, следовательно, должен быть Ьшо, и только один кластерный индекс
(1) Если таблица определена PK, ПК является кластерным индексом;
(2) Если таблица не определена ПК, то первый столбец не NULL, уникальный кластерный индекс;
(3) В противном случае, InnoDB создаст скрытую строку-идентификатор в качестве кластерного индекса;
Voiceover: Так PK запросы очень быстро, расположены непосредственно строки.
InnoDB общего индекса листовой узел хранит значение первичного ключа.
VO: Обратите внимание, что вместо строки указателя памяти головки записи, запись указатель индекса листовой узел хранит MyISAM.

Индекс два дерева В + приведены выше:
(1), как идентификатор ПК, кластерный индекс, лист узел хранит строки;
(2) наименование в качестве ключа, общего индекса, листьев узел хранит значений PK, то есть, идентификатор;
Так как общий показатель не может быть расположен непосредственно строки, и что общий индекс процесса запроса рода, как это?
Как правило, код должен быть отсканированы в два раза дерево индекса.
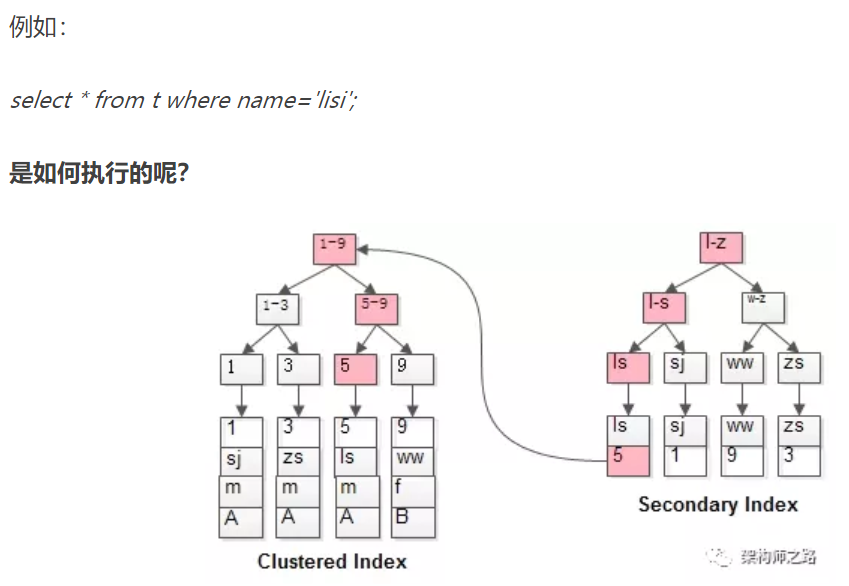
Это называется обратно в запрос таблицы, сначала найдите значение первичного ключа, а затем найдите запись строки, его производительность ниже, чем развертки по индексному дереву.
Фактическая цитата:


Фиг структура комбинации индекс:
создать таблицу t1 (в Int первичный ключ, б Int, C, D Int Int, е VARCHAR (20));
создать индекс idx_t1_bcd на t1 (B, C, D);
вставка в значения t1 (4,3,1,1, 'd');
вставка в значения t1 (1,1,1,1, 'а');
вставка в значения t1 (8,8,8,8, 'Н'):
вставка в значения t1 (2,2,2,2, 'б');
вставка в значения t1 (5,2,3,5, 'е');
вставка в значения t1 (3,3,2,2, 'с');
вставить в значения t1 (7,4,5,5, 'г');
вставить в t1 значений (6,6,4,4, 'е');
