оглавление
Конфигурация улья
Hive - это инструмент хранилища данных на основе Hadoop, который можно использовать для сортировки данных, обработки специальных запросов и анализа наборов данных, хранящихся в файлах Hadoop. У Hive низкий порог обучения, поскольку он предоставляет Hive QL, язык запросов, похожий на язык SQL реляционных баз данных. Он может быстро реализовать простую статистику MR с помощью операторов HiveQL. Сам Hive может автоматически преобразовывать операторы HiveQL в задачи MR для работы без необходимо реализовать разработку MR. api, поэтому он очень подходит для статистического анализа хранилищ данных;
Существует три режима развертывания Hive: однопользовательский, многопользовательский и режим удаленного сервера. Однопользовательский режим связан с базой данных в оперативной памяти Derby, обычно используемой для модульного тестирования; многопользовательский режим является наиболее часто используемым режимом развертывания, подключен к базе данных через сеть, база данных обычно выбирает MySQL для хранения метаданных Metastore; режим удаленного сервера То есть метаданные Metastore хранятся в базе данных на удаленном сервере, а клиент обращается к базе данных MetastoreServer через протокол Thrift.
Развертывание разделено на две части: сначала установите mysql и создайте пользователей и базы данных, а затем настройте Hive;
Конфигурация
1. Загрузите tar-пакет с официального сайта Mysql, 5.6.33 (64-битная универсальная версия Linux), адрес загрузки: https://dev.mysql.com/downloads/mysql/5.6.html#downloads ; в пути установки / usr / local / unzip переименуйте в mysql;
Примечание: getconf LONG_BIT получает системный бит
2. Создайте нового пользователя mysql (группа mysql), измените владельца и группу пути установки / usr / local / mysql на mysql, создайте новые пути к данным / var / lib / mysql и / var / lib / mysql / data, изменить Владелец и группа файла становятся mysql;
groupadd mysql
useradd -r -g mysql mysql
mkdir –p /var/lib/mysql/data
chown -R mysql:mysql /usr/local/mysql
chown -R mysql:mysql /var/lib/mysql3. Установить базу данных, передать параметры: каталог данных и каталог установки;
sudo ./scripts/mysql_install_db --basedir=/usr/local/mysql --datadir=/var/lib/mysql/data --user=mysql4. Модификация сценария запуска и конфигурационного файла:
./support-files/mysql.server и my.cnf; первый - это скрипт, который запускается при запуске, второй - конфигурация mysql, читаемая при запуске, если никаких настроек не сделано, по умолчанию используется / usr / local / mysql , Datadir - это / var / lib / mysql / data, если вы измените эти два параметра, вам придется изменить большую часть конфигурации;
Linux ищет my.cnf, чтобы при запуске службы MySQL сначала найти его в каталоге / etc, если он не найден, он будет искать «$ basedir / my.cnf», в каталоге / будет my.cnf. etc в операционной системе Linux. Этот файл необходимо переименовать в другое имя, например /etc/my.cnf.bak, в противном случае файл будет мешать правильной конфигурации и вызывать сбой при запуске.
sudo cp ./support-files/mysql.server/etc/init.d/mysqld
sudo chmod755/etc/init.d/mysqld
sudo cp./support-files/my-default.cnf/etc/my.cnf// Измените каталог данных и каталог установки в файле конфигурации my.cnf:
sudo vi/etc/init.d/mysqld
basedir=/usr/local/mysql/
datadir=/usr/local/mysql/data/mysql5. Запустите службу.
sudo service mysqld start![]()
// Закрываем службу mysql
sudo service mysqld stop# Просмотр статуса работы службы mysql
sudo service mysqld status- Задайте переменные среды, проверьте соединение и настройте права входа в систему:
#设置环境变量
export MYSQL=/usr/local/mysql
export PATH=${MYSQL}/bin:${PATH}
#赋权所有库下的所有表在任何IP地址或主机都可以被root用户连接
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;
#修改root用户的登录密码(须停服务,完成后重启)
UPDATE user SET Password=PASSWORD(‘123456’) where USER=’root’;
flush privileges;7. Создайте библиотеку улья и пользователя улья, чтобы сохранить информацию метаданных хранилища улья и предоставить пользователям улья следующие возможности:
create database hive character set latin1;
create user hive;Операция авторизации пользователя куста под таблицей mysql.user (опущена)
flush privileges;Метаданные Hive по умолчанию хранятся в Derby, здесь, чтобы изменить его базу метаданных на mysql, вам необходимо загрузить драйвер mysql, адрес: https://dev.mysql.com/downloads/file/?id=480090 , и скопировать драйвер в файл hive / lib.
Файлы конфигурации, считываемые Hive: hive-default.xml и hive-site.xml. Вам не нужно изменять большое количество элементов конфигурации по умолчанию для первого, а информация о конфигурации последнего может перезаписать первый. на официальный сайт: Руководство по началу работы ;
1. Создайте новый путь метаданных улья на hdfs.
$HADOOP_HOME/bin/hadoop fs –mkdir /tmp
$HADOOP_HOME/bin/hadoop fs –mkdir /user/hive/warehouse
$HADOOP_HOME/bin/hadoop fs -chmod g+w /tmp
$HADOOP_HOME/bin/hadoop fs -chmod g+w /user/hive/warehouse2. Создайте и измените файл конфигурации hive-site.xml следующим образом (пользователь mysql, который читает и записывает метаданные в конфигурации, является пользователем root, а права доступа слишком высоки и требуют оптимизации):
cp hive-default.xml.template hive-site.xml
// Подробная конфигурация hive-site.xml:
<configuration>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://172.19.52.155:3306/hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
</configuration>3. Инициализируйте мета-базу данных куста и проверьте, успешно ли настроен mysql (после успеха в таблицах под библиотекой улья будет много таблиц метаданных куста);
schematool -dbType mysql -initSchema![]()
Запуск и проверка
После завершения вышеуказанной конфигурации запустите службу hive напрямую с помощью команды hive, чтобы протестировать и построить таблицу;
![]()
// У hdfs есть соответствующая папка, что свидетельствует об успешной настройке:

проблема
1. Сконфигурируйте mysql и начните успешно, но после изменения информации о конфигурации пользователя для входа в таблицу mysql.user перезапустите и обнаружите, что пользователь root на хосте localhost не может читать системную библиотеку mysql (библиотека mysql). Решение: выключите mysql обрабатывает и удаляет каталог данных. После того, как каталог данных будет повторно инициализирован;
2. Проблема разрешения входа в систему при настройке библиотеки mysql, расширении возможностей пользователей и хостов входа;
![]()
Конфигурация HBase
Hbase - это высоконадежная, высокопроизводительная, масштабируемая распределенная база данных с ориентацией на столбцы, которая в основном используется для хранения неструктурированных и полуструктурированных данных. Hbase может поддерживать сверхмалые хранилища данных и может использовать дешевые аппаратные кластеры для обработки наборов данных, состоящих из более чем 1 миллиарда элементов и миллионов столбцов элементов, посредством горизонтального расширения.
Конфигурация
Официальный сайт справки по конфигурации: Примеры конфигураций , вам нужно изменить 3 файла конфигурации: hbase-env.sh и hbase-site.xml и файлы regionserver;
1. hbase-env.sh измените JAVA_HOME, HBASE_CLASSPATH, BASE_MANAGES_ZK. Если вы используете отдельно установленный zk, измените HBASE_MANAGES_ZK на false и повторно используйте здесь ранее развернутый zk;
export JAVA_HOME=/home/stream/jdk1.8.0_144
export HBASE_CLASSPATH=/home/stream/hbase/conf
export HBASE_MANAGES_ZK=false2. Задайте адрес zk и другие настройки в файле hbase-site.xml:
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>172.19.72.155,172.19.72.156,172.19.72.157</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/stream/zk/zookeeper/dataDir</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://172.19.72.155/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/stream/hbase/temp</value>
</property>
</configuration>3. Измените файл регионального сервера и добавьте хост регионального сервера:
172.19.72.156
172.19.72.157
172.19.72.158
172.19.72.159Запуск и проверка
Запустите сценарий ./start-hbase.sh в каталоге bin, чтобы просмотреть процесс Hmaster, используйте команду оболочки hbase, чтобы запустить командную строку hbase для построения таблиц, и протестируйте;

Вы можете использовать zkCli.sh для ввода zk, чтобы просмотреть информацию об узле, зарегистрированную hbase:
![]()
проблема
1. Ошибка запуска: java.lang.ClassNotFoundException: org.apache.htrace.SamplerBuilder
Решение: cp $ HBASE_HOME / lib / client-Face-Thirdparty / htrace-core-3.1.0-incubating.jar $ HBASE_HOME / lib /
2 、 启动 报错 : Пожалуйста, проверьте значение конфигурации 'hbase.procedure.store.wal.use.hsync', чтобы установить желаемый уровень надежности и убедиться, что значение конфигурации 'hbase.wal.dir' указывает на монтируемую файловую систему, может предоставить это.
Решение: добавить конфигурацию в hbase-site.xml:
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>Конфигурация шторма
Strom - это распределенная высокодоступная вычислительная среда в реальном времени. Zookeeper отвечает за связь между узлом Nimbus и узлом Supervior, а также контролирует состояние каждого узла. Задача отправляется на узел Nimbus, узел Nimbus распределяет задачу через кластер zk, а супервизор - это то место, где задача фактически выполняется.
Узел Nimbus отслеживает состояние каждого узла Supervisor через кластер zk.При выходе из строя узла Supervisor Nimbus перераспределяет задачи на этом узле Supervisor другим узлам Supervisor для выполнения через кластер zk.
Если узел Nimbus откажет, вся задача не остановится, но это повлияет на управление задачей.В этом случае нам нужно только восстановить узел Nimbus.
Узлы Nimbus не поддерживают высокую доступность, что также является проблемой, с которой в настоящее время сталкивается Storm. Как правило, узлы Nimbus не находятся под давлением и обычно не возникают проблемы.
Конфигурация
Разархивируйте его прямо в каталог / home / stream. /Home/stream/apache-storm-0.9.5/conf/storm.yaml необходимо настроить. Общие элементы конфигурации и значения следующие:
//配置zk的地址和端口和storm存放在zookeeper里目录
storm.zookeeper.server:
- “192.168.159.145”
- “192.168.159.144”
- “192.168.159.143”
storm.zookeeper.port: 21810
storm.zookeeper.root: /storm_new10
//storm主节点的地址 web页面的端口
nimbus.host: “192.168.159.145”
ui.port: 8989
//每个worker使用的内存
worker.heap.memory.mb: 512
storm.local.dir: "/home/zyzx/apache-storm-0.9.5/data"
//配置工作节点上的进程端口。你配置一个端口,意味着工作节点上启动一个worker,在实际的生产环境中,我们需要根据实际的物理配置以及每个节点上的负载情况来配置这个端口的数量。在这里每个节点我象征性的配置5个端口。
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
- 6700
nimbus.thrift.max_buffer_size: 204876
worker.childopts: “-Xmx1024m”Запуск и проверка
Узел управления запускает nimbus и storm ui, другие узлы запускают узел супервизора, просматривают процесс через JPS, главный узел запускает процесс nimbus, а рабочий узел запускает процесс супервизора;
nohup storm ui &
nohup storm nimbus &
nohup storm supervisor &Файл конфигурации Storm storm.yaml предъявляет высокие требования к спецификациям формата. Лишние пробелы могут привести к сбою чтения конфигурации. После запуска всех узлов вы можете проверить количество узлов супервизора, уцелевших во время шторма, в корневом каталоге клиента zkCli программы zookeeper, чтобы проверим успешность запуска:

Запустите команду ./storm list в ~ / storm / bin, чтобы вывести список топологий, представленных в кластере:

Конфигурация Spark (на пряжи)
Spark написан на лаконичном и элегантном языке Scala, обеспечивает интерактивное программирование на основе Scala и предоставляет множество удобных и простых в использовании API. Spark следует концепции дизайна «программный стек соответствует различным сценариям приложений» и постепенно сформировал целостную экосистему (включая Spark, обеспечивающую среду вычислений памяти, специальные запросы SQL (Spark SQL), потоковые вычисления (Spark Streaming), машинное обучение ( MLlib), графические вычисления (Graph X) и т. Д.), Spark можно развернуть в диспетчере ресурсов пряжи, чтобы предоставить универсальное решение для больших данных, одновременно поддерживая пакетную обработку, потоковую обработку и интерактивные запросы.
Модель вычислений MapReduce имеет высокую задержку и не может удовлетворить потребности быстрых вычислений в реальном времени. Следовательно, она подходит только для автономных сценариев. Spark опирается на модель вычислений MapReduce, но имеет следующие преимущества:
- Spark предоставляет больше типов операций с наборами данных, а его модель программирования более гибкая, чем MapReduce;
- Spark выполняет вычисления в памяти и помещает результаты вычислений непосредственно в память, что снижает накладные расходы ввода-вывода при итерационных вычислениях и повышает эффективность вычислений.
- Spark - это механизм планирования выполнения задач на основе DAG, который более эффективен при итерациях;
На практике MapReduce должен писать много низкоуровневого кода, который недостаточно эффективен. Spark предоставляет множество высокоуровневых и кратких API-интерфейсов для реализации приложений с одной и той же функцией, а объем кода реализации намного меньше. чем MapReduce.
В качестве вычислительной среды Spark заменяет только вычислительную среду MapReduce в экосистеме Hadoop. Для реализации распределенного хранения данных требуется HDFS. Другие компоненты Hadoop по-прежнему играют важную роль в корпоративной системе больших данных;
Конфигурация Spark в режиме пряжи требует изменения только очень небольшого числа конфигураций и не использует команду запуска кластера искры.Когда вам нужно отправить задачу, вы должны указать задачу в пряжи.
Конфигурация
Для запуска Spark требуется язык Scala. Вы должны загрузить Scala и Spark и разархивировать его в домашний каталог, установить переменные среды текущего пользователя (~ / .bash_profile), увеличить пути SCALA_HOME и SPARK_HOME и немедленно вступить в силу; запустите команду scala и spark-shell, чтобы проверить их успешность; Если модификацию файла конфигурации Spark нелегко понять в соответствии с руководством по трубопроводной сети, обратитесь к блогу и отладите конфигурацию, завершенную здесь.
Spark необходимо изменить два файла конфигурации: spark-env.sh и spark-default.conf. В первом необходимо указать пути к файлам конфигурации Hadoop hdfs и yarn и адрес Spark.master.host, а во втором - указать пакет jar. адрес;
Файл конфигурации spark-env.sh изменяется следующим образом:
export JAVA_HOME=/home/stream/jdk1.8.0_144
export SCALA_HOME=/home/stream/scala-2.11.12
export HADOOP_HOME=/home/stream/hadoop-3.0.3
export HADOOP_CONF_DIR=/home/stream/hadoop-3.0.3/etc/hadoop
export YARN_CONF_DIR=/home/stream/hadoop-3.0.3/etc/hadoop
export SPARK_MASTER_HOST=172.19.72.155
export SPARK_LOCAL_IP=172.19.72.155Конфигурация spark-default.conf изменяется следующим образом:
// Увеличиваем адрес пакета jar,
spark.yarn.jars=hdfs://172.19.72.155/spark_jars/*Этот параметр указывает, что адрес jar определен на hdfs, и все пакеты jar по пути ~ / spark / jars должны быть загружены в / spark_jars / path (hadoop hdfs -put ~ / spark / jars / *) hdfs, в противном случае будет сообщено об ошибке. Невозможно найти ошибку скомпилированного пакета jar;
Запуск и проверка
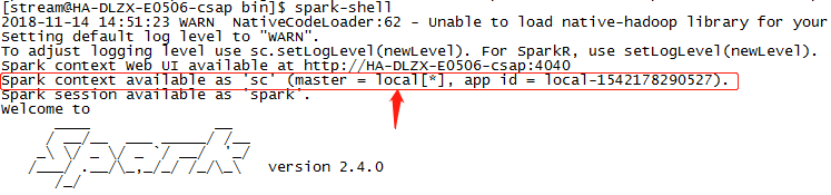
Запустите ./spark-shell напрямую без параметров, и он будет работать в локальном режиме:
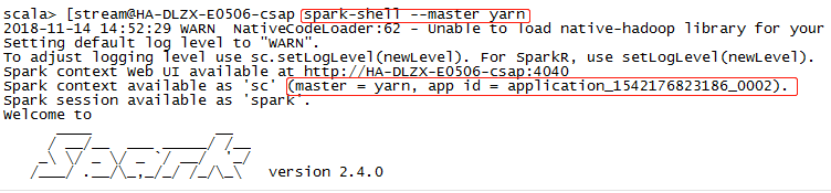
Запустите ./spark-shell –master yarn и запустите режим пряжи, если пряжа успешно настроена и доступна:
Создайте файл README.md в файловой системе hdfs и прочтите его в RDD. Используйте преобразование параметров, которое поставляется с RDD. RDD по умолчанию устанавливает каждую строку со значением:

Используйте ./spark-shell --master yarn, чтобы запустить Spark, и выполните команду: val textFile = sc.textFile ("README.md"), чтобы прочитать файл README.md на hdfs в RDD, и используйте встроенную функцию выполнить следующее испытание, указав, что конфигурация искры на пряже успешна;

проблема
При запуске spark-shell выдается сообщение об ошибке, что максимальный объем выделенной памяти, настроенный в Yarn-site.xml, недостаточен. Увеличьте это значение до 2048M, и вам необходимо перезапустить yarn, чтобы вступили в силу.

Установленный адрес hdfs конфликтует. Параметр hdfs-site.xml в файле конфигурации hdfs не имеет порта, но значение spark.yarn.jars в spark-default.conf имеет порт. Измените адрес конфигурации для spark-default .conf должен быть таким же, как прежний Consistent:

Конфигурация Flink (на пряжи)
Flink - это вычислительная среда с распределенной памятью для потоковой передачи данных и пакетных данных. Идеи дизайна в основном заимствованы из Hadoop, баз данных MPP, систем потоковых вычислений и т.д. Основным сценарием, обрабатываемым Flink, является потоковая передача данных. По умолчанию все задачи обрабатываются как потоковые данные. Пакетные данные - это только частный случай потоковой передачи данных, который поддерживает локальную быструю итерацию и некоторые задачи итерации цикла.
Flink строит программный стек в виде иерархической системы. Стеки различных уровней строятся на основе его нижних уровней. Его характеристики следующие:
- Предоставляет DataStreaming API для потоковой обработки и DataSet API для пакетной обработки. DataSet API поддерживает Java, Scala и Pyhton, а DataStreaming API поддерживает Java и Scala.
- Предоставление множества возможных решений для развертывания, таких как локальный режим (Local), кластерный режим (Cluster), облачный режим (Cloud), для кластеров, автономный режим (Standalone) или пряжа;
- Обеспечивает лучшую совместимость с Hadoop, не только поддерживает пряжу, но также поддерживает такие источники данных, как HDFS и Hbase;
Flink поддерживает инкрементные итерации и имеет функцию самооптимизации итераций, поэтому производительность задач, представленных на yarn, немного лучше, чем у Spark. Flink обрабатывает данные построчно. Spark - это небольшая пакетная обработка на основе RDD, поэтому Spark неизбежно увеличит некоторые задержки при потоковой обработке данных, а производительность в реальном времени будет хуже, чем у Flink. Flink и Storm могут поддерживать вычислительные ответы миллисекундного уровня, в то время как Spark может поддерживать только ответы второго уровня. Влияние Spark на рынок и активность сообщества значительно сильнее, чем у Flink, что в определенной степени ограничивает пространство разработки Flink;
Конфигурация
Разархивируйте, войдите в каталог bin и запустите ./yarn-session.sh –help, чтобы просмотреть справку и проверить, успешно ли сконфигурирована пряжа, ./yarn-session.sh –q отображает все ресурсы узла nodeManager для пряжи;

Flink предоставляет два способа отправки задач на пряжу: запуск текущего сеанса YARN (отдельный режим) и запуск задачи Flink на YARN (клиентский режим). Flink нужно только изменить конфигурацию conf / flink-conf.yaml, для получения подробных параметров, посетите официальный сайт:
Общая конфигурация: конфигурация , конфигурация высокой доступности : высокая доступность (HA)
// Вам нужно установить параметр fs.hdfs.hadoopconf в conf / flink-conf.yaml, чтобы найти конфигурацию YARN и HDFS;
// В режиме пряжи jobmanager.rpc.address указывать не нужно, потому что контейнер, который используется в качестве jobManager, определяется Yarn, а не конфигурацией Flink; taskmanager.tmp.dirs указывать тоже не нужно, это Параметр будет указан параметром tmp пряжи, по умолчанию. То есть в каталоге / tmp сохранить некоторые файлы jar или lib для загрузки в ResourceManager. Параметр Parrallelism.default указывать не нужно, потому что при запуске yarn количество слотов для каждого диспетчера задач указывается параметром -s.
// Вам нужно изменить yarn.resourcemanager.am.max-plays в конфигурации yarn-site.xml так, чтобы количество повторных попыток для соединения с менеджером ресурсов было 4, а по умолчанию - 2; в то же время добавьте пряжу .application- во flink-conf.yaml попыток: 4;
// HA кластера flink-on-yarn полагается на собственный кластерный механизм Yarn, но Flink Job полагается на моментальные снимки, созданные контрольными точками при восстановлении. Эти моментальные снимки настраиваются в hdfs, но их метаданные хранятся в zookeeper, поэтому мы все еще должны настроить информация HA zookeeper; пространство имен recovery.zookeeper.path. также может быть отменено параметром -z при запуске Flink на Yarn.
Полная конфигурация flink-conf.yaml выглядит следующим образом:
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
# The heap size for the JobManager JVM
jobmanager.heap.size: 1024m
# The heap size for the TaskManager JVM
taskmanager.heap.size: 1024m
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 1
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
# env
HADOOP_CONF_DIR:/home/stream/hadoop-3.0.3/etc/hadoop
YARN_CONF_DIR:/home/stream/hadoop-3.0.3/etc/hadoop
# Fault tolerance and checkpointing
state.backend:filesystem
state.checkpoints.dir:hdfs://172.19.72.155/yzg/flink-checkpoints
state.savepoints.dir:hdfs://172.19.72.155/yzg/flink-checkpoints
# hdfs
#The absolute path to the Hadoop File System’s (HDFS) configuration directory
fs.hdfs.hadoopconf:/home/stream/hadoop-3.0.3/etc/hadoop
#The absolute path of Hadoop’s own configuration file “hdfs-site.xml” (DEFAULT: null).
fs.hdfs.hdfssite:/home/stream/hadoop-3.0.3/etc/hadoop/hdfs-site.xml
#HA
high-availability: zookeeper
high-availability.zookeeper.quorum: 172.19.72.155:2181,172.19.72.156:2181,172.19.72.157:2181
high-availability.storageDir: hdfs:///yzg/flink/recovery
high-availability.zookeeper.path.root: /flink
yarn.application-attempts: 4В режиме HA вам необходимо настроить zk и изменить zoo.cfg в разделе conf; конфигурация zoo.cfg выглядит следующим образом:
dataDir=/home/stream/zk/zookeeper/logs
# The port at which the clients will connect
clientPort=2181
# ZooKeeper quorum peers
server.1=172.19.72.155:2888:3888
server.1=172.19.72.156:2888:3888
server.1=172.19.72.157:2888:3888Запуск и проверка
Используйте отдельный режим для запуска сеанса Flink Yarn. После отправки он сообщает, что приложение yarn успешно отправлено в yarn, и возвращает идентификатор. Используйте приложение yarn -kill application_id, чтобы остановить задачу, отправленную на yarn;
yarn-session.sh -n 3 -jm 700 -tm 700 -s 8 -nm FlinkOnYarnSession -d –stВы можете напрямую отправить встроенный пример использования статистики частоты слов, чтобы проверить, успешно ли настроен режим on yarn:
~/bin/flink run -m yarn-cluster -yn 4 -yjm 2048 -ytm 2048 ~/flink/examples/batch/WordCount.jarподводить итоги
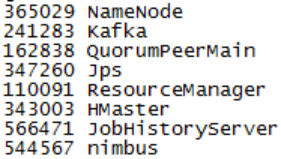
Вышеупомянутое в основном завершает развертывание базовых компонентов платформы больших данных (включая пакетную и потоковую). Таким образом, массовое развертывание на основе apache Hadoop более проблематично, вам необходимо самостоятельно адаптировать компоненты, а конфигурация компонентов более сложна, конфигурация более громоздка; в настоящее время завершенные компоненты выглядят следующим образом (искры и мигают на режим пряжи не имеет процессов):