이제 데이터와 예산이 있고 모든 준비가 완료되었으며 대형 모델을 훈련할 준비가 되었다고 가정해 보겠습니다. 실력을 뽐내고 나면 "장안의 모든 꽃을 하루 만에 보는 것"이 얼마 남지 않은 것 같습니다. 모퉁이... 잠깐만요! 트레이닝은 이 두 단어의 발음처럼 단순하지 않으니 블룸의 트레이닝을 보시면 도움이 될 것 같습니다.
최근 몇 년 동안 언어 모델이 점점 더 커지는 것이 표준이 되었습니다. 사람들은 일반적으로 이러한 대형 모델의 정보 자체가 연구를 위해 공개되지 않고 대형 모델 학습 기술에 대한 지식에 대한 관심이 거의 없다고 비판합니다. 이 기사는 1,760억 개의 매개변수가 있는 언어 모델 BLOOM을 예로 들어 소프트웨어 및 하드웨어 엔지니어링과 그러한 모델을 교육하는 기술적인 요점을 명확히 하여 대형 모델 교육 기술에 대한 논의를 촉진하는 것을 목표로 합니다.
먼저, 우리 그룹이 1,760억 개의 매개변수 모델을 교육하는 놀라운 위업을 달성할 수 있도록 지원하거나 지원한 회사, 개인 및 그룹에 감사드립니다.
그런 다음 하드웨어 구성 및 주요 기술 구성 요소에 대해 논의하기 시작합니다.

다음은 프로젝트에 대한 간략한 요약입니다.
| 하드웨어 | 384개의 80GB A100 GPU |
| 소프트웨어 | Megatron-DeepSpeed |
| 모델 아키텍처 | GPT3 기반 |
| 데이터 세트 | 59개 언어로 된 3,500억 단어 |
| 훈련 시간 | 3.5개월 |
직원 구성
이 프로젝트는 세계 최대의 다국어 모델 숲에 서있는 모델을 훈련시킬뿐만 아니라 모든 사람이 사용할 수 있음 교육 결과에 대한 공개 액세스는 대부분의 사람들의 꿈을 실현합니다.
이 문서는 모델 학습의 엔지니어링 측면에 중점을 둡니다. BLOOM 이면에 있는 기술의 가장 중요한 부분 중 일부는 전문 지식을 공유하고 코딩 및 교육을 돕는 사람과 회사입니다.
우리는 주로 다음 6개 그룹에 감사해야 합니다.
- HuggingFace의 BigScience 팀은 6명 이상의 상근 직원을 교육의 연구 및 운영에 투입했으며 Jean Zay의 컴퓨터 이외의 모든 인프라도 제공하거나 상환했습니다.
- DeepSpeed를 개발하고 나중에 Megatron-LM과 통합한 Microsoft DeepSpeed 팀의 개발자는 프로젝트 요구 사항을 조사하는 데 몇 주를 보냈고 교육 전과 교육 중에 많은 실용적인 조언을 제공했습니다.
- Megatron-LM을 개발한 NVIDIA Megatron-LM 팀은 기꺼이 우리의 많은 질문에 답변하고 최고 수준의 사용 조언을 제공했습니다.
- Jean Zay 슈퍼컴퓨터를 관리하는 IDRIS/GENCI 팀은 상당한 컴퓨팅 성능과 강력한 시스템 관리 지원을 프로젝트에 기부했습니다.
- PyTorch 팀은 나머지 소프트웨어의 기반이 되는 강력한 프레임워크를 만들었으며 우리가 의존하는 PyTorch 구성 요소의 교육 유용성을 개선하고 몇 가지 버그를 수정하고 교육을 준비하는 데 큰 도움을 주었습니다.
- BigScience 엔지니어링 워킹 그룹 지원자
프로젝트의 엔지니어링 측면에 기여한 모든 뛰어난 사람들의 이름을 지정하기는 어렵기 때문에 지난 14개월 동안 프로젝트의 엔지니어링 토대를 마련한 Hugging Face 이외의 핵심 인물 몇 명만 언급하겠습니다.
Olatunji Ruwase, Deepak Narayanan, Jeff Rasley, Jared Casper, Samyam Rajbhandari, Rémi Lacroix
또한 직원들이 이 프로젝트에 기여하도록 허용한 모든 회사에 감사드립니다.
개요
BLOOM의 모델 아키텍처는 이 백서의 뒷부분에서 설명하는 몇 가지 개선 사항을 제외하면 GPT3와 매우 유사합니다.
이 모델은 GENCI가 관리하고 프랑스 국립 과학 연구 센터(CNRS)의 국가 컴퓨팅 센터인 IDRIS에 설치된 프랑스 정부 지원 슈퍼컴퓨터인 Jean Zay에서 훈련되었습니다. 교육에 필요한 컴퓨팅 성능은 GENCI(기부 번호 2021-A0101012475)에서 이 프로젝트에 아낌없이 기부했습니다.
교육 하드웨어:
- GPU: NVIDIA A100 80GB GPU 384개(노드 48개) + 예비 GPU 32개
- 노드당 8개의 GPU, 4개의 NVLink 카드 간 상호 연결, 4개의 OmniPath 링크
- CPU: AMD EPYC 7543 32코어 프로세서
- CPU 메모리: 노드당 512GB
- GPU 메모리: 노드당 640GB
- 노드 간 연결: OPA(Omni-Path Architecture) 네트워크 카드가 사용되며 네트워크 토폴로지는 비차단 팻 트리입니다.
- NCCL - 통신 네트워크: 완전 전용 서브네트워크
- 디스크 IO 네트워크: 다른 노드 및 사용자와 공유되는 GPFS
체크포인트:
- 주요 검문소
- 각 체크포인트는 fp32 정밀도의 옵티마이저 상태와 bf16+fp32 정밀도의 가중치를 포함하며 2.3TB의 저장 공간을 차지합니다. bf16의 무게만 저장하면 329GB의 저장 공간만 차지하게 됩니다.
데이터 세트:
- 46개 언어로 된 1.5TB의 중복 제거 및 정리된 텍스트, 350B 토큰으로 변환
- 모델의 어휘에는 250,680개의 토큰이 포함되어 있습니다.
- 자세한 내용은 The BigScience Corpus A 1.6TB Composite Multilingual Dataset을 참조하십시오.
176B BLOOM 모델의 학습은 2022년 3월부터 7월까지 약 3.5개월(약 100만 컴퓨팅 시간)이 소요되었습니다.
Megatron-DeepSpeed
176B BLOOM 모델은 다음 두 가지 주요 기술을 결합한 Megatron-DeepSpeed를 사용하여 학습됩니다 .
- Megatron-DeepSpeed :
- DeepSpeed 는 분산 교육을 간단하고 효율적이며 효과적으로 만드는 딥 러닝 최적화 라이브러리입니다.
- Megatron-LM은 NVIDIA의 응용 딥 러닝 연구팀이 개발한 크고 강력한 변환기 모델 프레임워크입니다.
DeepSpeed 팀은 Megatron-LM의 Tensor Parallelism과 DeepSpeed 라이브러리의 ZeRO 샤딩 및 파이프라인 병렬 처리를 결합하여 3D 병렬 기반 체계를 개발했습니다. 각 구성 요소에 대한 자세한 내용은 아래 표를 참조하십시오.
BigScience의 Megatron-DeepSpeed 는 원래 Megatron-DeepSpeed 코드 기반을 기반으로 하며 여기에 꽤 많은 코드를 추가했습니다.
다음 표에는 BLOOM을 교육할 때 사용하는 두 가지 프레임워크의 각 구성 요소가 나열되어 있습니다.
| 구성 요소 | 딥스피드 | 메가트론-LM |
|---|---|---|
| 제로 데이터 병렬 | 예 | |
| 텐서 병렬 | 예 | |
| 파이프라인 병렬 | 예 | |
| BF16 옵티마이저 | 예 | |
| CUDA 퓨전 커널 기능 | 예 | |
| 데이터 로더 | 예 |
Megatron-LM과 DeepSpeed 모두 파이프라인 병렬 처리와 BF16 옵티마이저 구현이 있지만 ZeRO에 통합되어 있기 때문에 DeepSpeed의 구현을 사용합니다.
Megatron-DeepSpeed는 3D 병렬성을 구현하여 대형 모델을 매우 효율적인 방식으로 교육할 수 있습니다. 3D 구성요소가 무엇인지 간단히 살펴보겠습니다.
- DP(Data Parallelism) - 동일한 설정과 모델이 여러 번 복제되며 매번 다른 데이터 복사본이 제공됩니다. 처리는 병렬로 수행되며 각 교육 단계가 끝날 때 모든 공유가 동기화됩니다.
- 텐서 병렬성(TP) - 각 텐서는 청크로 분할되므로 전체 텐서가 단일 GPU에 상주하는 대신 텐서의 각 조각이 할당된 GPU에 상주합니다. 처리하는 동안 각 샤드는 다른 GPU에서 개별적으로 병렬로 처리되며 결과는 단계가 끝날 때 동기화됩니다. 이것은 수평으로 이루어지기 때문에 수평 병렬 처리라고 합니다.
- PP(Pipeline Parallelism) - 모델이 여러 GPU에 걸쳐 수직으로(즉, 레이어별로) 분할되어 하나 이상의 모델 레이어만 단일 GPU에 배치됩니다. 각 GPU는 파이프라인의 서로 다른 단계를 병렬로 처리하고 배치의 일부를 처리합니다.
- Zero Redundancy Optimizer(ZeRO) - 또한 TP와 유사한 텐서 샤딩을 수행하지만 전체 텐서는 정방향 또는 역방향 계산을 위해 적시에 재구성되므로 모델 수정이 필요하지 않습니다. 또한 제한된 GPU 메모리를 보완하기 위해 다양한 오프로딩 기술을 지원합니다.
데이터 병렬성
소수의 GPU만 사용하는 대부분의 사용자는 DistributedDataParallel해당 PyTorch 문서 인 (DDP)에 익숙할 것입니다 . 이 접근 방식에서는 모델이 각 GPU에 완전히 복제된 다음 모든 모델이 각 반복 후 상태를 서로 동기화합니다. 이 방법은 더 많은 GPU 리소스를 투자하여 훈련 속도를 높이고 문제를 해결할 수 있습니다. 그러나 모델이 단일 GPU에 맞는 경우에만 작동한다는 한계가 있습니다.
제로 데이터 병렬
다음 다이어그램은 ZeRO 데이터 병렬 처리를 잘 보여줍니다( 이 ).
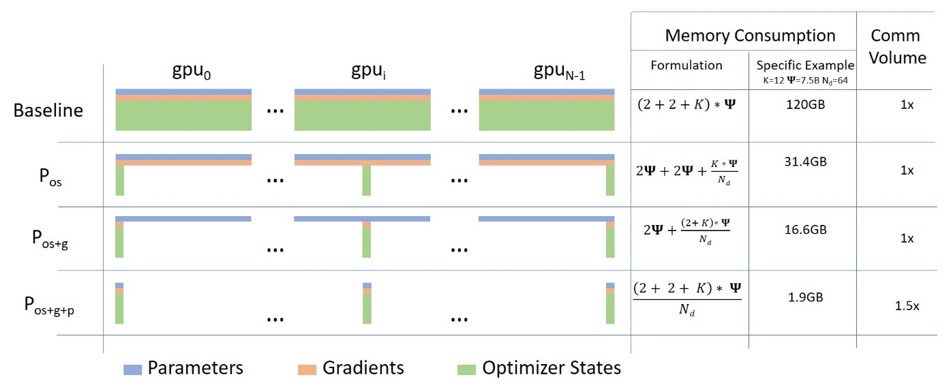
상대적으로 키가 커서 이해에 집중하기 어려울 수 있지만 사실 개념은 매우 간단합니다. 이는 각 GPU가 전체 모델 매개변수, 그래디언트 및 옵티마이저 상태를 복제하는 대신 일부만 저장한다는 점을 제외하면 일반적인 DDP입니다. 후속 실행 중에 주어진 레이어에 대한 전체 레이어 매개변수가 필요한 경우 모든 GPU가 동기화되어 누락된 조각을 서로 제공합니다.
이 구성 요소는 DeepSpeed에 의해 구현됩니다.
텐서 병렬
Tensor Parallelism(TP)에서 각 GPU는 텐서의 일부만 처리하고 집계 작업은 특정 연산자가 전체 텐서를 필요로 하는 경우에만 트리거됩니다.
이 섹션에서는 Megatron-LM 논문 Efficient Large-Scale Language Model Training on GPU Clusters 의 개념과 다이어그램을 사용합니다 .
Transformer 클래스 모델의 주요 모듈은 다음과 같습니다. nn.Linear비선형 활성화 계층이 뒤따르는 완전 연결 계층 GeLU.
Megatron 논문의 표기법에 따라 내적 부분을 로 쓸 수 있습니다 Y = GeLU (XA). 여기서 X및 Y는 입력 및 출력 벡터 A이고 는 가중치 행렬입니다.
행렬 형식으로 표현하면 행렬 곱셈을 여러 GPU로 분할하는 방법을 쉽게 알 수 있습니다.
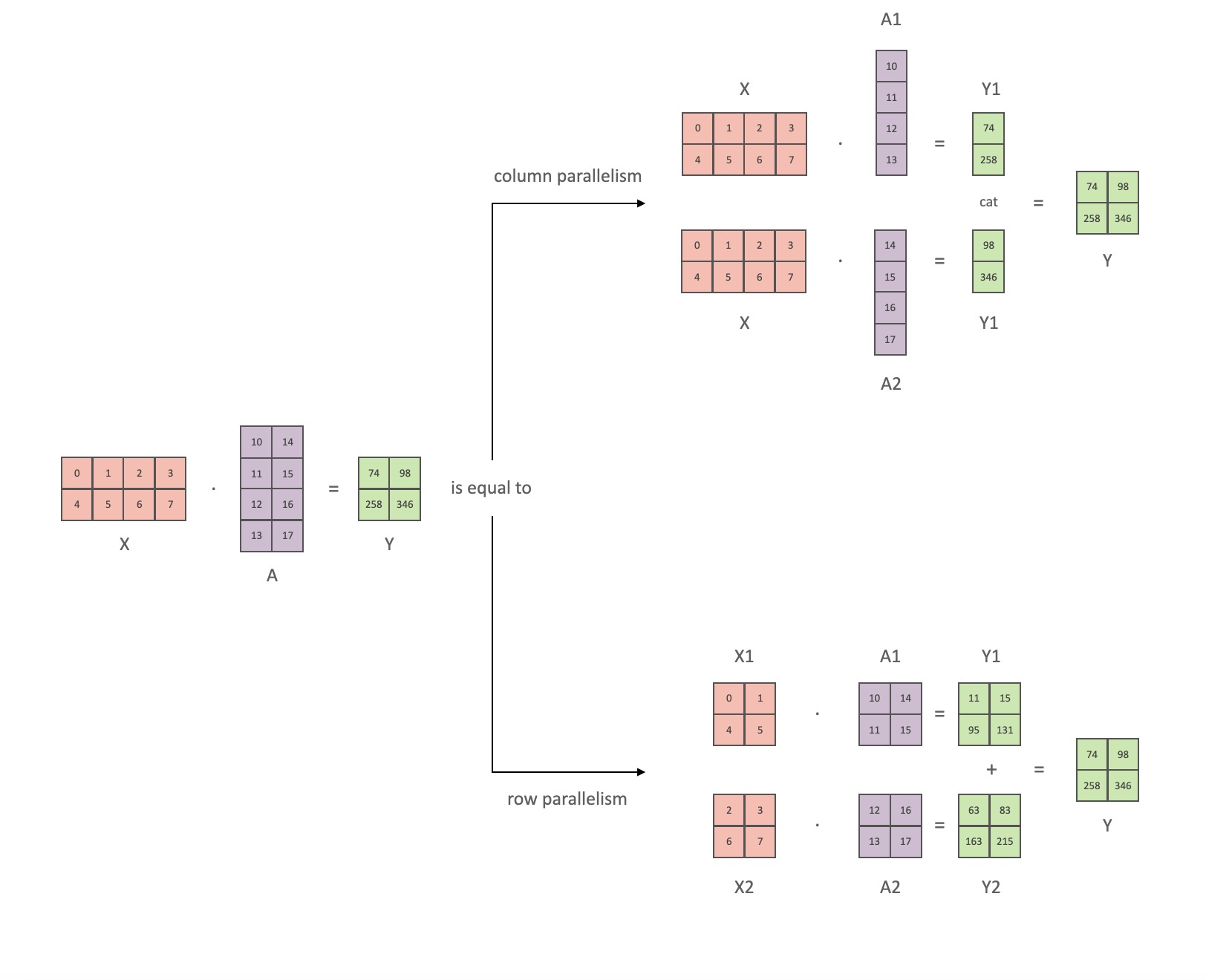
A열 별로 가중치 행렬을 NGPU로 분할한 다음 행렬 곱셈을 XA_1병렬로 하면 독립적으로 공급할 수 있는 출력 벡터가 됩니다XA_n .NY_1、Y_2、…… 、 Y_nGeLU
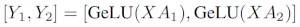
Y행렬이 열로 분할되기 때문에 후속 GEMM에 대해 행 분할 방식을 선택할 수 있으므로 추가 통신 없이 이전 레이어의 GeLU 출력을 직접 가져올 수 있습니다.
이 원칙을 사용하여 각 拆列 - 拆行시퀀스 . Megatron-LM 논문의 저자는 이에 대한 멋진 설명을 제공합니다.
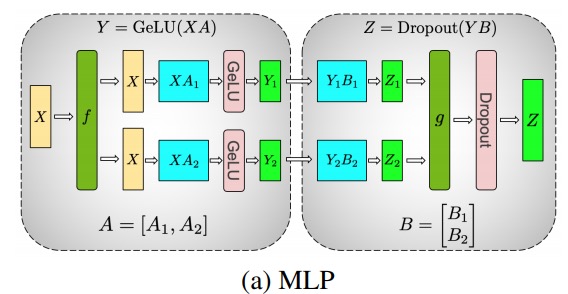
다음 f은 순방향 패스의 항등 연산자이고 역방향 패스의 모두 감소이며, g는 순방향 패스의 항등식이고 역방향 패스의 항등입니다.
멀티 헤드 어텐션 레이어의 병렬화는 여러 개의 독립적인 헤드로 인해 본질적으로 병렬이기 때문에 더욱 간단합니다!
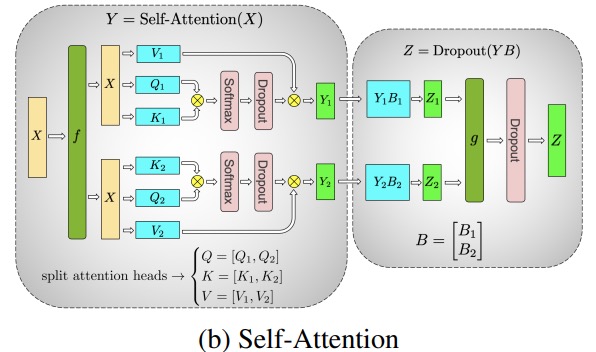
특별 고려 사항: 순방향 및 역방향 패스에서 레이어당 두 개의 전체 감소가 있으므로 TP는 장치 간에 매우 빠른 상호 연결이 필요합니다. 따라서 매우 빠른 네트워크가 아닌 경우 여러 노드에서 TP를 수행하지 않는 것이 좋습니다. BLOOM 교육을 위한 하드웨어 구성에서 노드 간 속도는 PCIe보다 훨씬 느립니다. 실제로 노드에 4개의 GPU가 있는 경우 최대 TP 등급 4가 더 좋습니다. TP 등급 8이 필요한 경우 GPU가 8개 이상인 노드를 사용해야 합니다.
이 구성 요소는 Megatron-LM에 의해 구현됩니다. Megatron-LM은 최근 텐서 병렬 기능을 확장했으며, LayerNorm과 같이 앞서 언급한 분할 알고리즘을 사용하기 어려운 연산자를 위해 시퀀스 병렬 기능을 추가했습니다. Reducing Activation Recomputation in Large Transformer Models 문서에서 이 기술에 대한 세부 정보를 제공합니다. 시퀀스 병렬 처리는 BLOOM 훈련 후에 개발되었으므로 BLOOM은 이 기술 없이 훈련되었습니다.
파이프라인 병렬
나이브 파이프라인 병렬 처리(나이브 PP)는 모델 레이어를 여러 GPU에 걸쳐 그룹으로 분산하고 마치 하나의 대형 복합 GPU인 것처럼 GPU에서 GPU로 데이터를 이동하기만 하면 됩니다. 메커니즘은 비교적 간단합니다. .to()메서드를 이제 데이터가 이러한 레이어에 들어가거나 나올 때마다 레이어가 데이터를 레이어와 동일한 장치로 전환하고 나머지는 동일하게 유지됩니다.
대부분의 모델의 토폴로지를 그리는 방법을 기억한다면 실제로 모델의 레이어를 수직으로 분할하기 때문에 이것은 실제로 수직 모델 병렬 처리입니다. 예를 들어 아래 이미지가 8계층 모델을 표시하는 경우:
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
GPU0 GPU1
GPU0에 레이어 0-3을 배치하고 GPU1에 레이어 4-7을 배치하여 세로로 두 부분으로 자릅니다.
이제 데이터가 레이어 0에서 레이어 1로, 레이어 1에서 레이어 2로, 레이어 2에서 레이어 3으로 전달될 때 단일 GPU에서 일반적인 순방향 전달과 같습니다. 그러나 데이터가 레이어 3에서 레이어 4로 전달되어야 하는 경우 GPU0에서 GPU1로 데이터를 전송해야 하므로 통신 오버헤드가 발생합니다. 참여하는 GPU가 동일한 컴퓨팅 노드(예: 동일한 물리적 머신)에 있으면 전송이 매우 빠르지만 GPU가 다른 컴퓨팅 노드(예: 여러 머신)에 있으면 통신 오버헤드가 훨씬 커질 수 있습니다.
그런 다음 레이어 4-5-6-7은 다시 일반 모델과 같으며 레이어 7이 완료되면 일반적으로 레이블이 있는 레이어 0으로 데이터를 다시 보내야 합니다(또는 레이블을 마지막 레이어로 보내야 함). 이제 손실을 계산할 수 있고 옵티마이저를 사용하여 매개변수를 업데이트할 수 있습니다.
질문:
- 이 방법을 순진한 와 단점은 무엇입니까? 주로 구성표가 주어진 순간에 하나의 GPU를 제외하고 모두 유휴 상태이기 때문입니다. 따라서 4개의 GPU를 사용하는 경우 단일 GPU의 메모리 양은 거의 4배가 되며 계산과 같은 다른 리소스는 거의 쓸모가 없습니다. 장치 간에 데이터를 복사하는 오버헤드를 추가합니다. 따라서 순진한 파이프라인을 사용하여 병렬로 연결된 4개의 6GB 카드는 데이터 전송 오버헤드가 없기 때문에 더 빠르게 훈련되는 1개의 24GB 카드와 동일한 크기의 모델을 보유할 수 있습니다. 그러나 예를 들어 40GB 카드가 있지만 45GB 모델을 실행해야 하는 경우 4x 40GB 카드를 사용할 수 있습니다(비디오 메모리가 필요한 그래디언트 및 옵티마이저 상태도 있기 때문에 이 정도면 충분합니다).
- 임베딩을 공유하려면 GPU 간에 앞뒤로 복사해야 할 수 있습니다. 우리가 사용하는 파이프라인 병렬 처리(PP)는 위의 순진한 PP와 거의 동일하지만 들어오는 배치를 마이크로 배치로 청크하고 서로 다른 GPU가 동시에 계산 프로세스에 참여할 수 있도록 하는 파이프라인을 인위적으로 생성하여 GPU 유휴 문제를 해결합니다.
아래 그림은 GPipe 논문 에서 가져온 것입니다. 상단은 순진한 PP 방식을 나타내고 하단은 PP 방식을 나타냅니다.

그림의 아래쪽 절반에서 PP의 데드 존(GPU가 유휴 상태임을 의미)이 적다는 것, 즉 "버블"이 적다는 것을 쉽게 알 수 있습니다.
그림에서 두 방식의 병렬도는 4, 즉 파이프라인은 4개의 GPU로 구성된다. 따라서 F0, F1, F2 및 F3의 네 가지 순방향 경로가 있고 B3, B2, B1 및 B0의 역방향 경로가 있습니다.
PP는 튜닝을 위한 새로운 하이퍼파라미터인 块 (chunks). 동일한 파이프 레벨을 통해 순차적으로 전송되는 데이터 블록 수를 정의합니다. 예를 들어, 그림의 아래쪽 절반에서 를 볼 수 있습니다 chunks = 4. GPU0은 청크 0, 1, 2, 3(F0,0, F0,1, F0,2, F0,3)에서 동일한 정방향 경로를 실행한 다음 GPU0이 다시 작동하기 전에 다른 GPU가 작업을 완료할 때까지 기다립니다. 블록 3, 2, 1 및 0(B0,3, B0,2, B0,1, B0,0)에 대한 역방향 경로.
이것은 개념적으로 기울기 누적 단계(GAS)와 동일합니다. PyTorch가 호출 块하고 DeepSpeed가 호출합니다 GAS.
때문에 块PP는 마이크로 배치(MBS)의 개념을 도입합니다. DP는 전역 배치 크기를 작은 배치 크기로 분할하므로 DP 정도가 4인 경우 전역 배치 크기 1024는 4개의 작은 배치 크기로 분할되고 각 작은 배치 크기는 256(1024/4)입니다. 그리고 块숫자(또는 GAS)가 32이면 마이크로 배치 크기가 8(256/32)이 됩니다. 각 튜브 단계는 한 번에 하나의 마이크로 배치를 처리합니다.
DP+PP 설정에 대한 전역 배치 크기를 계산하는 공식은 mbs * chunks * dp_degree( 8 * 32 * 4 = 1024)입니다.
돌아가서 사진을 다시 봅시다.
순진한 PP를 사용 chunks=1하면 매우 비효율적인 순진한 PP가 됩니다. 그리고 매우 큰 块숫자를 작은 마이크로 배치 크기로 끝나게 되므로 그다지 효율적이지 않을 수도 있습니다. 따라서 GPU를 가장 효율적으로 사용하는 块숫자를 .
그래프는 마지막 단계가 파이프라인이 완료될 때 까지 기다려야 forward하기 때문에 병렬화할 수 없는 "데드" 타임 버블이 있음을 보여줍니다 . backward그러면 모든 참여 GPU가 높은 동시 사용률을 달성할 수 있도록 최적의 块수를 실제로 거품의 수를 최소화하는 것으로 변환됩니다.
이 스케줄링 메커니즘을 이라고 합니다 全前全后. 다른 옵션으로는 Tandem 및 Interleaved Tandem 이 있습니다 .
Megatron-LM과 DeepSpeed 모두 자체 PP 프로토콜 구현을 가지고 있지만 Megatron-DeepSpeed는 DeepSpeed의 다른 기능과 통합되어 있기 때문에 DeepSpeed 구현을 사용합니다.
여기서 또 다른 중요한 문제는 단어 임베딩 행렬의 크기입니다. 일반적으로 워드 임베딩 행렬은 Transformer 블록보다 적은 메모리를 필요로 하지만 250k 어휘가 있는 BLOOM의 경우 임베딩 레이어는 bf16 가중치에 대해 7.2GB가 필요한 반면 Transformer 블록의 경우 4.9GB만 필요합니다. 따라서 Megatron-Deepspeed가 임베딩 레이어를 트랜스포머 블록으로 취급하도록 해야 했습니다. 따라서 우리는 72단계의 파이프라인을 가지고 있으며 그 중 2개는 임베딩 전용입니다(첫 번째와 마지막). 이를 통해 GPU의 메모리 소비 균형을 맞출 수 있습니다. 이렇게 하지 않으면 첫 번째 단계와 마지막 단계에서 많은 GPU 메모리를 사용하게 되고 GPU 메모리 사용량의 95%는 매우 적기 때문에 훈련이 매우 비효율적일 것입니다.
DP+PP
DeepSpeed Pipeline Parallel Tutorial 에는 아래와 같이 DP와 PP를 결합하는 방법을 보여주는 그림이 있습니다.
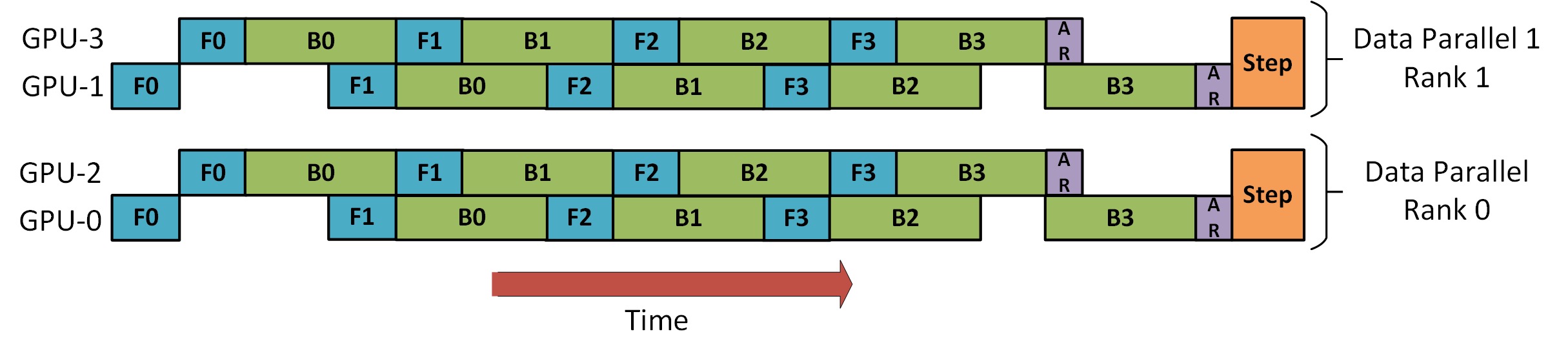
여기서 이해해야 할 중요한 점은 DP 등급 0은 GPU2를 볼 수 없고 DP 등급 1은 GPU3을 볼 수 없다는 것입니다. DP의 경우 GPU 0과 1만 있고 여기에 데이터가 공급됩니다. GPU0은 PP를 사용하여 일부 부하를 GPU2로 "비밀스럽게" 오프로드합니다. 마찬가지로 GPU1도 GPU3의 도움을 받습니다.
각 차원에 최소 2개의 GPU가 필요하므로 여기서는 최소 4개의 GPU가 필요합니다.
DP+PP+TP
보다 효율적인 교육을 위해 아래 그림과 같이 PP, TP 및 DP를 결합할 수 있으며 이를 3D 병렬 처리라고 합니다.
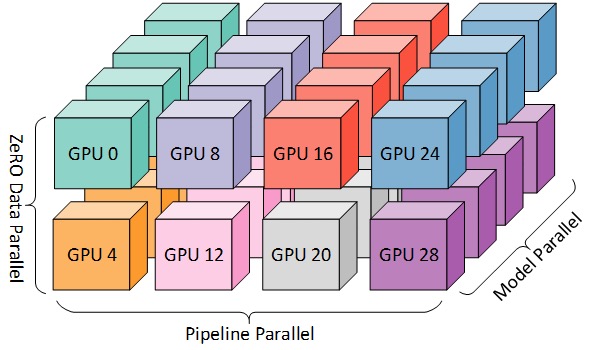
이 그림은 블로그 게시물 3D Parallelism: Scaling to Trillion Parameter Models )에서 가져온 것으로, 이 역시 좋은 기사입니다.
차원당 최소 2개의 GPU가 필요하므로 완전한 3D 병렬 처리를 위해서는 최소 8개의 GPU가 필요합니다.
제로 DP+PP+TP
DeepSpeed의 주요 기능 중 하나인 ZeRO는 확장성이 뛰어난 DP의 향상된 버전으로 [ZeRO Data Parallel](#ZeRO-Data Parallel) 섹션에서 논의했습니다. 일반적으로 독립 기능이며 PP 또는 TP가 필요하지 않습니다. 그러나 그것은 또한 PP, TP와 결합될 수 있습니다.
ZeRO-DP가 PP(따라서 TP)와 결합되면 일반적으로 최적화 상태만 샤딩하는 ZeRO 1단계만 활성화됩니다. ZeRO 2단계도 그래디언트를 샤딩하고 3단계도 모델 가중치를 샤딩합니다.
이론적으로 파이프라인 병렬 처리와 함께 ZeRO 2단계를 사용할 수 있지만 성능에 나쁜 영향을 미칠 수 있습니다. 각 마이크로 배치에는 샤딩 전에 경사도를 집계하기 위해 추가적인 축소-분산 통신이 필요하므로 잠재적으로 상당한 통신 오버헤드가 추가됩니다. 파이프라인의 병렬 특성에 따라 작은 마이크로 배치를 사용하고 산술 강도(마이크로 배치 크기)와 파이프라인 거품 최소화(마이크로 배치 수) 간의 절충에 중점을 둘 것입니다. 따라서 통신 오버헤드가 증가하면 파이프라인 병렬 처리가 손상됩니다.
또한 PP로 인해 레이어 수가 이미 정상보다 적기 때문에 메모리를 많이 절약하지 못합니다. PP는 그래디언트 크기를 줄였으므로 1/PP이 기준에 따른 그래디언트 슬라이스는 순수한 DP에 비해 많은 메모리를 절약하지 못합니다.
ZeRO 3단계도 이 크기의 모델을 훈련하는 데 사용할 수 있지만 DeepSpeed 3D보다 병렬로 더 많은 통신이 필요합니다. 1년 전 우리 환경을 면밀히 평가한 결과 Megatron-DeepSpeed 3D 병렬 처리가 가장 잘 수행되는 것으로 나타났습니다. ZeRO Phase 3의 성능은 그 이후로 크게 향상되었으며 오늘 재평가한다면 Phase 3을 선택할 것입니다.
BF16 옵티마이저
FP16으로 거대한 LLM 모델을 교육하는 것은 불가능합니다.
우리는 Tensorboard 에서 볼 수 있듯이 완전히 실패한 104B 모델을 몇 달 동안 교육 이를 입증했습니다 . 계속해서 달라지는 lm-loss에 맞서 싸우는 과정에서 우리는 많은 것을 배웠습니다.
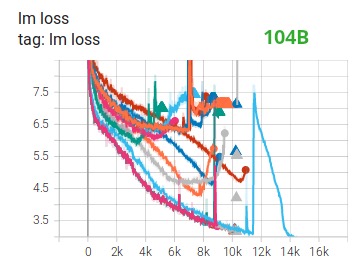
Megatron-LM 및 DeepSpeed 팀이 530B 모델을 교육한 후 동일한 제안을 받았습니다 . 최근 출시된 OPT-175B 도 FP16에서 매우 열심히 훈련했다고 보고했습니다.
그래서 1월에 우리는 BF16 형식을 지원하는 A100에서 훈련할 것이라는 것을 알았습니다. Olatunji Ruwase는 BLOOM 훈련을 위해 "BF16Optimizer"를 개발했습니다.
이 데이터 형식에 익숙하지 않은 경우 비트 . BF16 형식의 핵심은 FP32와 같은 지수를 가지므로 오버플로가 발생하지 않지만 FP16은 종종 오버플로됩니다! FP16의 최대 값 범위는 64k이며 더 작은 숫자만 곱할 수 있습니다. 예를 들어 할 수 250*250=62500있지만 시도하면 255*255=65025오버플로가 발생하여 교육 문제의 주요 원인입니다. 이것은 체중을 작게 유지해야 함을 의미합니다. 손실 스케일링이라는 기술이 이 문제를 완화하는 데 도움이 되지만 FP16의 작은 범위는 모델이 매우 커질 때 여전히 문제가 될 수 있습니다.
BF16에는 이 문제가 없으며 쉽게 할 수 있습니다 10_000*10_000=100_000_000. 전혀 문제가 없습니다.
물론 BF16과 FP16은 2바이트로 같은 크기이기 때문에 공짜는 없고, BF16을 사용할 때 단점은 정밀도가 매우 떨어진다는 것입니다. 그러나 우리가 훈련에 사용한 확률적 경사 하강 방법과 그 변형은 약간 비틀거림과 같다는 것을 기억해야 합니다. 이 단계에서 완벽한 방향을 찾지 못하더라도 괜찮습니다. 다음 단계에서 수정하겠습니다. 단계 소유.
BF16을 사용하든 FP16을 사용하든 항상 FP32에 있는 가중치 사본이 있습니다. 이것은 옵티마이저에 의해 업데이트되는 것입니다. 따라서 16비트 형식은 계산에만 사용되며 옵티마이저는 FP32 가중치를 전체 정밀도로 업데이트한 다음 다음 반복을 위해 16비트 형식으로 변환합니다.
모든 PyTorch 구성 요소는 FP32에서 누적을 수행하도록 업데이트되어 정밀도 손실이 발생하지 않습니다.
관건은 파이프라인 병렬화의 주요 특징 중 하나인 기울기 축적인데, 이는 각 마이크로 배치에서 처리되는 기울기가 누적되기 때문입니다. 훈련 정확도를 위해 FP32에서 그래디언트 누적을 구현하는 것이 중요하며 이것이 바로 BF16Optimizer수행된 것 .
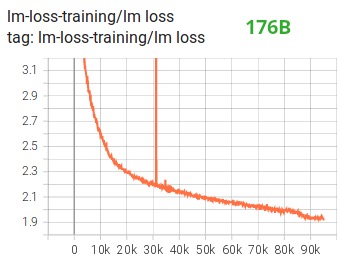
다른 개선 사항 중 BF16 혼합 정밀도 교육을 사용하면 다음 lm 손실 플롯에서 볼 수 있듯이 잠재적인 악몽이 비교적 원활한 프로세스로 바뀌었다고 생각합니다.
CUDA 퓨전 커널 기능
GPU는 주로 두 가지 일을 합니다. 비디오 메모리에서 데이터를 쓰고 읽을 수 있으며 해당 데이터에 대한 계산을 수행할 수 있습니다. GPU가 데이터를 읽고 쓰는 중일 때 GPU의 컴퓨팅 장치는 유휴 상태입니다. GPU를 효율적으로 활용하려면 유휴 시간을 최소한으로 유지해야 합니다.
커널 함수는 특정 PyTorch 작업을 구현하는 명령 집합입니다. 예를 들어 를 호출 torch.add하면 입력 텐서 및 기타 변수의 값을 기반으로 실행할 코드를 결정하는 PyTorch 스케줄러를 거쳐 최종적으로 실행됩니다. CUDA 커널은 CUDA를 사용하여 이러한 코드를 구현하므로 NVIDIA GPU에서만 실행됩니다.
이제 GPU를 사용하여 계산할 c = torch.add (a, b); e = torch.max ([c,d])때 일반적 으로a PyTorch가 수행하는 작업은 두 개의 개별 커널을 실행 하는 것입니다. 이 경우 GPU 는 비디오 메모리에서 합계를 가져오고 추가를 수행한 다음 결과를 다시 비디오 메모리에 씁니다. 그런 다음 작업을 수행하고 수행하며 결과를 비디오 메모리에 다시 씁니다.bcdabcdmax
이 두 작업을 융합한다면, 즉 "융합된 커널 기능"에 넣은 다음 c중간 결과를 비디오 메모리에 쓰는 대신 해당 커널을 시작하면 GPU 레지스터에 보관하고 Gets만 수행하면 됩니다 d. 최종 계산. 이렇게 하면 많은 오버헤드가 절약되고 GPU가 유휴 상태가 되지 않으므로 전체 작업이 훨씬 더 효율적입니다.
퓨전 커널 기능이 바로 그런 역할을 합니다. 그들은 주로 데이터 이동이 거의 없는 융합된 계산으로 비디오 메모리와의 데이터 이동 및 여러 이산 계산을 대체합니다. 또한 일부 퓨전 커널은 특정 계산 조합을 더 빠르게 수행할 수 있도록 작업을 수학적으로 변환합니다.
BLOOM을 빠르고 효율적으로 훈련시키려면 Megatron-LM에서 제공하는 여러 맞춤형 CUDA 융합 커널 기능을 사용해야 합니다. 특히 LayerNorm 퓨전 커널과 퓨전 스케일링, 마스킹 및 소프트맥스 작업의 다양한 조합을 위한 커널이 있습니다. Bias Add는 PyTorch의 JIT 기능을 통해 GeLU와도 통합됩니다. 이러한 작업은 모두 메모리에 바인딩되어 있으므로 각 비디오 메모리를 읽은 후 계산량을 최대화하기 위해 함께 융합하는 것이 중요합니다. 예를 들어 메모리에 병목 현상이 있는 GeLU 작업을 실행하는 동안 Bias Add를 실행해도 실행 시간이 늘어나지 않습니다. 이러한 커널 기능은 Megatron-LM 코드 라이브러리 에서 찾을 수 있습니다 .
데이터 세트
Megatron-LM의 또 다른 중요한 기능은 효율적인 데이터 로더입니다. 첫 번째 교육이 시작되기 전에 각 데이터 세트의 각 샘플은 고정 시퀀스 길이(BLOOM은 2048)의 샘플로 나뉘고 각 샘플에 번호를 매기기 위해 인덱스가 생성됩니다. 학습 하이퍼파라미터를 기반으로 각 데이터셋이 참여해야 하는 에포크 수를 결정하고 이를 기반으로 샘플 인덱스의 정렬된 목록을 만든 다음 섞습니다. 예를 들어 데이터 세트에 2 epoch 동안 훈련해야 하는 10개의 샘플이 있는 경우 시스템은 먼저 샘플 인덱스를 [0, ..., 9, 0, ..., 9]순서 순서를 섞어 데이터 세트에 대한 최종 전역 순서를 생성합니다. 이는 교육이 단순히 전체 데이터 세트를 반복하고 반복하는 것이 아니라 다른 샘플을 보기 전에 동일한 샘플을 두 번 볼 수 있지만 교육이 끝나면 모델은 각 샘플을 두 번만 볼 수 있음을 의미합니다. 이것은 훈련 전반에 걸쳐 부드러운 훈련 곡선을 보장하는 데 도움이 됩니다. 원래 데이터 세트에 있는 각 샘플의 오프셋을 포함한 이러한 인덱스는 훈련이 시작될 때마다 다시 계산하지 않도록 파일에 저장됩니다. 마지막으로, 이러한 데이터 세트 중 일부는 교육에 사용되는 최종 데이터에 서로 다른 가중치와 혼합될 수 있습니다.
임베드 LayerNorm
104B 모델의 발산을 방지하기 위한 노력의 일환으로 첫 번째 단어 임베딩 레이어 뒤에 추가 LayerNorm을 추가하면 학습이 더 안정적이라는 것을 발견했습니다.
이 통찰력은 균일한 xavier 함수로 초기화된 LayerNorm을 사용한 정상적인 임베딩 작업이 있는 bitsandbytes를StableEmbedding 사용한 실험 에서 나온 것입니다.
위치 코드
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation 논문을 기반으로 정상적인 위치 임베딩을 AliBi로 대체하여 모델 훈련에 사용되는 입력 시퀀스보다 긴 입력 시퀀스의 외삽을 허용합니다. 따라서 길이 2048의 시퀀스로 훈련하더라도 모델은 추론 중에 더 긴 시퀀스를 처리할 수 있습니다.
훈련의 어려움
아키텍처, 하드웨어 및 소프트웨어가 준비되어 2022년 3월 초에 교육을 시작할 수 있었습니다. 그러나 그 이후로 모든 것이 순조롭게 진행되지는 않았습니다. 이 섹션에서는 우리가 직면한 몇 가지 주요 장애물에 대해 논의합니다.
교육을 시작하기 전에 알아내야 할 질문이 많습니다. 특히 작은 규모가 아닌 48개 노드에서 훈련을 시작한 후에야 나타나는 몇 가지 문제를 발견했습니다. 예를 들어 프레임워크가 중단되지 않도록 CUDA_LAUNCH_BLOCKING=1하려면 옵티마이저 그룹을 더 작은 그룹으로 나누어야 합니다. 그렇지 않으면 프레임워크가 다시 중단됩니다. 이에 대한 자세한 내용은 Pre-Training Chronicles에서 확인할 수 있습니다 .
교육 중에 발생하는 주요 문제 유형은 하드웨어 오류입니다. 이것은 약 400개의 GPU가 있는 새로운 클러스터이므로 평균적으로 일주일에 1-2개의 GPU 오류가 발생합니다. 3시간마다 체크포인트를 저장합니다(100회 반복). 결과적으로 하드웨어 충돌로 인해 주당 평균 1.5시간의 교육을 잃게 됩니다. 그러면 Jean Zay 시스템 관리자가 결함이 있는 GPU를 교체하고 노드를 복원합니다. 그동안 예비 노드를 사용할 수 있습니다.
또한 5~10시간의 가동 중지 시간을 여러 번 초래하는 다양한 다른 문제가 있었습니다. 일부는 PyTorch의 교착 상태 버그와 관련이 있고 다른 일부는 디스크 공간 부족으로 인해 발생했습니다. 세부 사항에 관심이 있는 경우 훈련 .
이 모든 중단 시간은 이 모델 교육의 타당성 분석에서 계획되었으며 적절한 모델 크기와 그에 따라 모델이 소비할 데이터 양을 선택했습니다. 그래서 이러한 중단 시간 문제에도 불구하고 예상 시간 내에 교육을 완료할 수 있었습니다. 앞에서 언급했듯이 완료하는 데 약 100만 컴퓨팅 시간이 걸립니다.
또 다른 문제는 SLURM이 한 그룹의 사람들이 사용하도록 설계되지 않았다는 것입니다. SLURM 작업은 단일 사용자가 소유하며 주변에 없으면 그룹의 다른 구성원은 실행 중인 작업에 대해 아무 것도 할 수 없습니다. 프로세스를 시작한 사용자가 없어도 그룹의 다른 사용자가 현재 프로세스를 종료할 수 있는 종료 체계가 있습니다. 이것은 문제의 90%에서 훌륭하게 작동합니다. SLURM 설계자가 이 글을 읽는다면 SLURM 작업을 그룹이 소유할 수 있도록 Unix 그룹의 개념을 추가하십시오.
훈련이 24시간 연중무휴로 진행되기 때문에 대기 중인 사람이 필요합니다. 하지만 유럽과 캐나다 서해안에 사람이 있기 때문에 호출기를 들고 다닐 사람이 필요하지 않으며 서로를 잘 지원해 줍니다. 물론 주말 훈련은 지켜봐야 한다. 하드웨어 충돌에서 자동으로 복구하는 것을 포함하여 대부분의 작업을 자동화하지만 때때로 사람의 개입이 여전히 필요합니다.
결론적으로
훈련에서 가장 힘들고 스트레스가 많은 부분은 훈련 시작 2개월 전입니다. 우리는 가능한 한 빨리 교육을 시작해야 한다는 압박을 많이 받았고 리소스에 할당된 제한된 시간 때문에 마지막 순간까지 A100에 액세스할 수 없었습니다. 그래서 마지막 순간에 작성된 BF16Optimizer것을 . 우리는 그것을 디버깅하고 다양한 버그를 수정해야 했습니다. 이전 섹션에서 언급했듯이 소규모가 아닌 48개 노드에서 훈련을 시작한 후에야 나타나는 새로운 문제를 발견했습니다.
하지만 문제가 해결되자 훈련 자체는 큰 문제 없이 놀라울 정도로 순조롭게 진행되었습니다. 대부분의 경우 우리 중 한 명만 지켜보고 문제 해결에 관여하는 사람은 소수에 불과합니다. 우리는 교육 중에 발생하는 대부분의 요구 사항을 신속하게 해결한 Jean Zay의 경영진으로부터 큰 지원을 받았습니다.
전반적으로 매우 강렬했지만 보람있는 경험이었습니다.
대규모 언어 모델을 교육하는 것은 여전히 어려운 작업이지만 이 기술을 공개적으로 구축하고 공유함으로써 다른 사람들이 우리의 경험을 통해 배울 수 있기를 바랍니다.
자원
중요한 링크
논문 및 기사
이 기사에서 모든 것을 자세히 설명하는 것은 불가능하므로 여기에 제시된 기술이 호기심을 자극하고 더 배우고 싶게 만드는 경우 다음 문서를 읽으십시오.
메가트론-LM:
딥스피드:
- ZeRO: 수조 매개변수 모델 훈련을 위한 메모리 최적화
- Zero-Offload: 수십억 규모의 모델 교육 민주화
- ZeRO-Infinity: 극한 규모의 딥 러닝을 위해 GPU 메모리 벽을 허물다
- DeepSpeed: 모두를 위한 대규모 모델 교육
Megatron-LM과 Deepspeedeed 결합:
구실:
- 짧은 훈련, 긴 테스트: 선형 편향으로 주의를 기울이면 입력 길이 외삽이 가능합니다.
- GPU 시간이 100만 시간이면 학습할 언어 모델은 무엇입니까? - 궁극적으로 ALiBi를 선택하게 된 실험을 찾을 수 있습니다.
비트N바이트:
- Block-wise Quantization을 통한 8비트 옵티마이저 옵티마이저 메모리를 절약하기 위한 DeepSpeed-ZeRO).
블로그 게시물 감사
좋은 질문을 해주시고 기사의 가독성을 높이는 데 도움을 주신 다음 분들에게 감사드립니다(알파벳순).
- 브리트니 뮬러,
- 두웨 키엘라,
- 자레드 캐스퍼,
- 제프 라슬리,
- 줄리앙 로네이,
- 레안드로 폰 베라,
- 오마르 산세비에로,
- 스테판 슈베터와
- 토마스 왕.
이 기사의 차트는 주로 Chunte Lee가 작성했습니다.
영어 원문: https://hf.co/blog/bloom-megatron-deepspeed
원작자: Stas Bekman
번역자: Intel 딥 러닝 엔지니어인 Matrix Yao(Yao Weifeng)는 다양한 모달 데이터에 변압기 제품군 모델을 적용하고 대규모 모델의 교육 및 추론 작업을 수행합니다.
교정 및 조판: zhongdongy (아동)