1. 시계열 데이터 및 그 특성
시계열 데이터는 1년 이내의 다우존스 지수, 하루 다른 시점에서 측정된 온도 등 비교적 안정적인 빈도를 기준으로 지속적으로 생성되는 일련의 지표 모니터링 데이터입니다. 시계열 데이터에는 다음과 같은 특징이 있습니다.
- 과거 데이터의 불변성
- 데이터 가용성
- 데이터의 적시성
- 구조화된 데이터
- 데이터의 양
둘째, 시계열 데이터베이스의 기본 구조
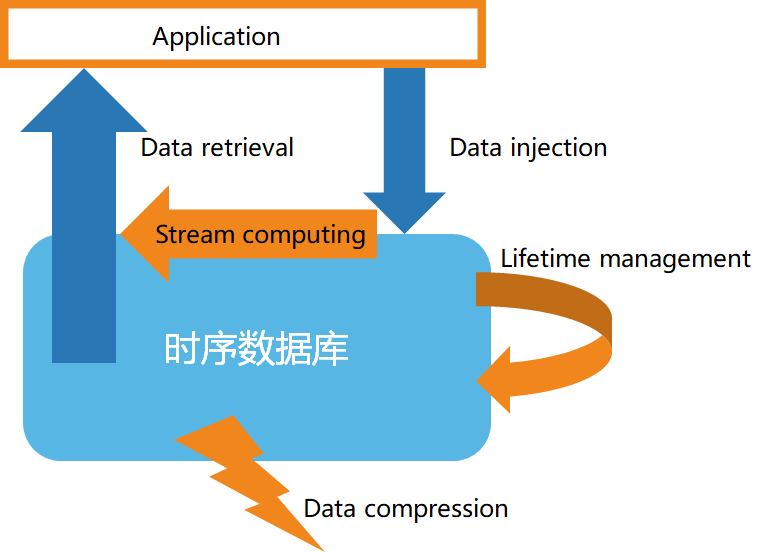
시계열 데이터의 특성에 따라 시계열 데이터베이스는 일반적으로 다음과 같은 특징을 갖는다.
- 고속 데이터 저장
- 데이터 수명 주기 관리
- 데이터의 스트림 처리
- 효율적인 데이터 쿼리
- 맞춤형 데이터 압축
3. 스트림 컴퓨팅 소개
스트림 컴퓨팅은 주로 다양한 데이터 소스에서 대량의 데이터를 실시간으로 수집하고 가치 있는 정보를 얻기 위해 실시간으로 분석 및 처리하는 것을 말합니다. 일반적인 비즈니스 시나리오에는 실시간 이벤트에 대한 신속한 대응, 시장 변화에 대한 실시간 경보, 실시간 데이터의 대화형 분석 등이 포함됩니다. 스트림 컴퓨팅에는 일반적으로 다음 기능이 포함됩니다.
1) 필터링 및 변환(필터 및 맵)
2) 집계 및 창 함수(축소, 집계/창)
3) 여러 데이터 스트림 병합 및 패턴 일치(결합 및 패턴 감지)
4) 스트림에서 블록 처리로
4. 스트림 컴퓨팅을 위한 시계열 데이터베이스 지원
-
사례 1: 다음 예제와 같이 사용자 지정 스트림 컴퓨팅 API를 사용합니다.
from(bucket: "mydb")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "mymeasurement")
|> map(fn: (r) => ({ r with value: r.value * 2 }))
|> filter(fn: (r) => r.value > 100)
|> aggregateWindow(every: 1m, fn: sum, createEmpty: false)
|> group(columns: ["location"])
|> join(tables: {stream1: {bucket: "mydb", measurement: "stream1", start: -1h}, stream2: {bucket: "mydb", measurement: "stream2", start: -1h}}, on: ["location"])
|> alert(name: "value_above_threshold", message: "Value is above threshold", crit: (r) => r.value > 100)
|> to(bucket: "mydb", measurement: "output", tagColumns: ["location"])
-
사례 2: 다음과 같이 SQL 유사 명령어를 사용하여 스트림 컴퓨팅을 생성하고 스트림 컴퓨팅 규칙을 정의합니다.
CREATE STREAM current_stream
TRIGGER AT_ONCE
INTO current_stream_output_stb AS
SELECT
_wstart as start,
_wend as end,
max(current) as max_current
FROM meters
WHERE voltage <= 220
INTEVAL (5S) SLIDING (1s);
{{o.이름}}
{{이름}}